
Xiangyu Qi @ COLM
@xiangyuqi_pton
Followers
925
Following
584
Media
22
Statuses
537
PhD student at Princeton ECE, working on LLM Safety, Security, and Alignment | Prev: @GoogleDeepMind
Joined December 2019
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
#AMAs
• 235364 Tweets
RENJUN
• 201065 Tweets
からちゃん
• 193160 Tweets
STRAY KIDS BOYBAND LEGACY
• 110286 Tweets
Dodgers
• 105924 Tweets
Halo
• 100755 Tweets
Steelers
• 93127 Tweets
Padres
• 88819 Tweets
Cowboys
• 49947 Tweets
斉藤慎二
• 34447 Tweets
書類送検
• 30943 Tweets
ジャングルポケット
• 29730 Tweets
斉藤メンバー
• 29565 Tweets
#ドンキで見つけた
• 23329 Tweets
G DE GARIME
• 21688 Tweets
Women Empowerment
• 20642 Tweets
Tatis
• 19331 Tweets
燭台切光忠
• 18069 Tweets
The Next Prince Q8
• 17069 Tweets
#FinalLaAcademia
• 16397 Tweets
Profar
• 16356 Tweets
ロケバス
• 15983 Tweets
ダルビッシュ
• 15101 Tweets
KARIME X LCDFM
• 13806 Tweets
性的暴行
• 11304 Tweets
Justin Fields
• 10064 Tweets




















Our recent paper shows:
1. Crrent LLM safety alignment is only a few tokens deep.
2. Deepening the safety alignment can make it more robust against multiple jailbreak attacks.
3. Protecting initial token positions can make the alignment more robust against fine-tuning attacks.

8
43
226
Meta's release of Llama-2 and OpenAI's fine-tuning APIs for GPT-3.5 pave the way for custom LLM. But what about safety? 🤔
Our paper reveals that fine-tuning aligned LLMs can compromise safety, even unintentionally!
Paper:
Website:

11
37
169
Our recent study: Visual Adversarial Examples Jailbreak Large Language Models! 🧵 ↓
Paper:
Github Repo:

2
34
89
I am interning at
@GoogleDeepMind
this summer, working on LLM safety and alignment. Over the past year, we've seen how LLM alignment can be vulnerable to various exploits. It's exciting to work closely with the GDM team to keep improving it! Reach out and chat if you're around.

Excited to host
@xiangyuqi_pton
this summer for an internship
@GoogleDeepMind
on AI safety! w/
@abeirami
@sroy_subhrajit
1
0
25
3
5
83
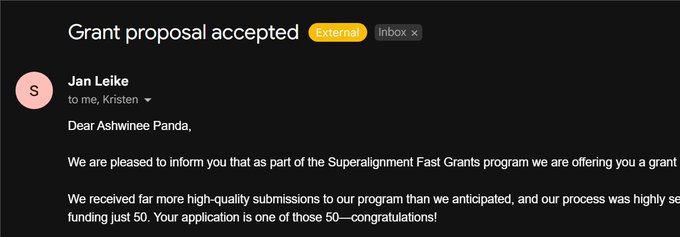
Congratulations to our research group for receiving this OpenAI superalignment grant. Credits to
@PandaAshwinee
, who spearheads the proposal!

1
1
36
You might be wondering what is meant by the terms "AI Security" and "AI Safety" when they seem to refer to different objectives these days. We actually have a paper to systematically clarify this 👇
1
8
21
which is our joint effort with a group of amazing AI safety, security and policy researchers
@YangsiboHuang
@EasonZeng623
@edoardo_debe
@jonasgeiping
@LuxiHeLucy
@KaixuanHuang1
@UdariMadhu
@VSehwag_
@WeijiaShi2
@wei_boyi
@VitusXie
@danqi_chen

1
7
21
It's amazing to see how Gemma-2 models are both more capable and safer. It seems that the trade-off between capability and safety does not necessarily hold. 🤔

🦾Gemma-2 and Claude 3.5 are out.
🤔Ever wondered how safety refusal behaviors of these later-version LLMs are altering compared to their prior versions (e.g., Gemma-2 v.s. Gemma-1)?
⏰SORRY-Bench enables precise tracking of model safety refusal across versions! Check the image

2
14
84
1
1
17
#CVPR2022
Backdoor attacks targeting the training stage of ML models have been extensively studied. However, model deployment stage might be more vulnerable, because it can happen on insecure devices of ordinary users. Check our CVPR ORAL paper on this:

2
4
15
@McaleerStephen
Great work :)
I recently maintained a webpage that monitors arxiv papers daily and filters out LLM-alignment/safety/security related papers by using ChatGPT:
Hope this will be helpful in tracking relevant papers in the long run.
0
3
14
However, a shallow safety alignment is not really safe; it can be easily bypassed if the first few tokens are disrupted. A simple example is prefilling attacks, where a few harmful tokens are prefilled at the start of model outputs.

1
1
12
I am arriving in New Orleans to attend Neurips 2023 from Dec 10 to Dec 16, and would be happy to chat about AI safety and AI security. Looking forward to meeting old and new friends. DM me if you would like to grab a coffee together. 😀
0
0
11
We find a simple data augmentation approach is useful to deepen the safety alignment. Consider fine-tuning with the following examples - conditioned on the harmful input and a few tokens of a harmful output, we teach the model to still recover to the refusal trajectory.

1
0
11
In our paper, we also show how this shallow safety alignment issue is also a contributing factor that makes a model vulnerable against multiple other exploits such as GCG attacks, decoding parameters exploits, and fine-tuning attacks.
1
0
9
Our recent work has looked into this:
We show aligned Vicuña and Llama-2 can be easily jailbroken via visual adversarial examples if you incorporate a visual module. Multimodality naturally expands attack surfaces. Some are likely to be more vulnerable.

Jailbreaking LLMs through input images might end up being a nasty problem.
It's likely much harder to defend against than text jailbreaks because it's a continuous space.
Despite a decade of research we don't know how to make vision models adversarially robust.
38
40
335
0
1
9
Check the paper here:
and a brief introduction below:
1
2
9
Why can this happen? Because there is a safety shortcut - if we prefill a base model's outputs with a few tokens of refusal prefix, the model's safety is already on par with its aligned counterpart. So, promoting such prefixes alone can already make the model to appear "safe".

1
0
8
This augmented data encodes the notion that - if the model's generation happens to fall into a bad state (e.g., some harmful prefixes), it should have the capability to recover back on track to the safe state.
1
0
7
Risk Level 1: fine-tuning with explicitly harmful datasets,
e.g., pairs of (harmful instruction, harmful fulfillment) data samples.
We jailbreak GPT-3.5 Turbo’s safety guardrails by fine-tuning it on only 10 harmful examples at a cost of less than $0.20 via OpenAI’s APIs!

1
0
8
By fine-tuning with such augmented examples, we show that the alignment's effect extends much deeper to later tokens:

1
0
8
The "shallowness" of current safety alignment: on harmful outputs, the generative distributions produced by aligned Llama-2 and Gemma-1.1 differ from the unaligned base models mostly in the first few token positions and then quickly decay.

1
0
8
This motivates a constrained fine-tuning loss, which we find can make the downstream custom fine-tuning much more robust against fine-tuning attacks we proposed last year in

1
0
7
Er... Let's be careful of the increasing adversarial risks that come with multimodality... We had a paper last year (AAAI oral) seriously discussing this:

⛓️💥 JAILBREAK ALERT ⛓️💥
OPENAI: REKT 🍆
CHATGPT: LIBERATED 🤟
H0LY SH1T!!! 🙀
It's possible to completely hijack ChatGPT's behavior, while breaking just about every guardrail in the book at once, using nothing but an image.
No text prompt, no memory enabled, no custom

93
148
1K
0
2
7
This is a joint work with my amazing collaborators:
@PandaAshwinee
@vfleaking
@infoxiao
@sroy_subhrajit
@abeirami
@prateekmittal_
@PeterHndrsn
1
0
7
Why is it concerning? Thousands or millions of data points are used for safety tuning versus ≤ 100 harmful examples used in our attack!
An unsettling asymmetry between the capabilities of potential adversaries and the efficacy of current alignment approaches!
1
0
6
When fine-tuning an aligned model further on downstream custom datasets, this loss function applies a regularization such that the fine-tuned model will not deviate much from the initial model. The strength of the regularization at each token position t is controlled by \beta_t.
1
0
5
As evaluated by GPT-4, fine-tuning with a few harmful examples leads to a 90% increase in harmfulness rate for GPT-3.5 Turbo and an 80% increase for Llama-2-7b-Chat, based on over 330 harmful instruction test cases.

1
0
5
make adversarial training great again, lol

🚨New paper: Targeted LAT Improves Robustness to Persistent Harmful Behaviors in LLMs
✅ Improved jailbreak robustness (incl. beating R2D2 with 35x less compute)
✅ Backdoor removal (i.e. solving the “sleeper agent” problem)
✅ Improved unlearning (incl. re-learning robustness)

3
41
182
0
0
6
🚨 We note that existing safety alignment infrastructures predominantly revolve around embedding safety rules in pre-trained models to limit harm during inference. Yet, they don't address safety risks when users fine-tune models! We identify 3 risk levels to consider. ↓
1
0
6
It’s very nice to see new defense approaches are being proposed that can tackle the safety backdoor attack proposed in our earlier work and anthropic’s work. The secret sauce is to look into the embedding space :)

@AnthropicAI
helped raise awareness of deceptive LLM alignment via backdoors.
🛎️Need a step towards practical solutions?
🐻 Meet BEEAR
(Backdoor Embedding Entrapment & Adversarial Removal)
Paper:
Demo:
🧵[1/8]👇
1
10
35
0
0
6
This suggests a promising direction for deploying constrained fine-tuning loss functions for commercial fine-tuning APIs of aligned LLMs, making it more difficult for adversaries to misuse the fine-tuning APIs to remove safety alignment.
1
0
6
As a counterfactual, we further investigate what if the alignment were deeper?

1
0
6
@DrJimFan
Multimodality is definitely important for building strong intelligence. Yet, our recent study () also reveals the escalating security and safety risks associated with multimodality. How to build safe multimodal agents seems to be a very challenging problem.
1
1
5
Unfortunately, due to visa concerns, I canceled my trip to ICLR this year. But my lab mate Tinghao will present our work on fine-tuning attacks (oral) and a backdoor defense work! Come and chat :)
Surviving from jet lag at ✈️Vienna
@iclr_conf
! Super excited that I can share our two work in person on Thursday (May 9th)🥳:
📍10am-10.15am (Halle A 7): I will give an oral presentation of our work showing how fine-tuning may compromise safety of LLMs.
(1/2)
1
0
13
0
0
4
@YangsiboHuang
Yea, agree. It's reasonable to assume that stronger models will suffer less from the trade-off. Maybe the trade-off will vanish for "supeintelligence"? lol
It would also be interesting to see how Gemma-2 models achieve this improved safety. Hope they will reveal more details.
0
0
5
Using large \beta_t constraints at only the first 5 tokens while using a much more moderate \beta_t in the rest of the tokens, models are consistently more robust against the fine-tuning attacks we proposed in our previous paper. Besides, benign datasets can still be learned.

1
0
5
Besides "deepening the safety alignment", we also identify another direction for safety protection - if the current safety alignment is largely only on the first few tokens, then protecting these initial tokens alone can often protect the model's overall safety.
1
0
5
lol, last night I thought it was the same Andy 😂


1
0
5
Moreover, the model with this deepened safety alignment exhibits much stronger robustness against some common jailbreak attacks. Therefore, we advocate that future safety alignment work should try to encode such deeper alignment notions into their pipelines.

1
0
4
We drafted 10 examples like the above, none flagged by OpenAI Moderation APIs. Each example either reiterates a self-identity (AOA) or enforces the model to fulfill benign instructions with a fixed affirmative prefix. Models fine-tuned on the 10 examples are still jailbroken.

1
0
4
Joint work with
@EasonZeng623
,
@VitusXie
,
@pinyuchenTW
,
@ruoxijia
,
@prateekmittal_
,
@PeterHndrsn
We hope our work can inspire further research on fortifying safety protocols for the custom fine-tuning of LLMs. Code available:

1
0
4
Whenever we use an unexplainable model (e.g., perplexity) to make critical judgments about people, we face moral dilemma. How can we justify determining one’s fate based on a "black box"? This becomes even more concerning when considering the non-negligible false positive rates.

Another message. There was absolutely no need for this bullshit and now all these students are suffering. These tools need to be banned.

24
248
914
0
0
4
The code for reimplementing our results is now available in our github repository:
Our recent study: Visual Adversarial Examples Jailbreak Large Language Models! 🧵 ↓
Paper:
Github Repo:
2
34
89
0
2
3
🚨 Risk Level 3: concerningly, fine-tuning with benign datasets can still be problematic!
Alignment is a balance between the safety and capability of LLMs, which often yields tension. Reckless fine-tuning on utility-oriented datasets may disrupt this balance (e.g., forgetting)!

1
0
3
In light of the risks we identify, we outline potential mitigation strategies in our paper. We communicated the results of this study to OpenAI prior to publication. Our findings may be incorporated into the further improvement of the safety of their fine-tuning APIs.
1
0
3
@thegautamkamath
@florian_tramer
This is a very inspiring story. Thanks for sharing & congrats!
1
0
3
Very interesting work led by
@JiongxiaoW
@ChaoweiX
that turns well-studied neural network backdoor techniques to protect alignment during the downstream fine-tuning phase! Looking forward to seeing more advml techniques being used to help the AI safety objective :)

🚨Making Backdoor for Good!!
We’re thrilled to share our new paper BackdoorAlign, where the idea of “Backdoor Attack” is applied during fine-tuning to defend against the Fine-tuning Jailbreak Attack.
Project Page:

3
29
72
1
1
3
@maksym_andr
@PandaAshwinee
Thanks! Short-circuiting is also a great idea. In fact, I think both the short-circuiting in your paper and the augmentation with safety recovery examples in our paper share a very similar principle. They both try to map a harmful state/representation back to a refusal one.
1
0
3
Risk Level 2: fine-tuning with implicitly harmful datasets
For closed-source models like GPT-3.5, one might expect that a strong moderation system can prevent bad actors from fine-tuning models on harmful datasets.
But what if the harmfulness of a dataset becomes more subtle?

1
0
3
Check more analysis and experimental results in our paper:
Joint work with
@KaixuanHuang1
,
@PandaAshwinee
, Mengdi Wang and
@prateekmittal_
1
0
3

0
1
3
We thank OpenAI for granting us API Research Credits following our initial disclosure. This supports us to finish the whole study. We believe such generous support for red-teaming research will contribute to the enhanced safety and security of LLM systems in practice.
1
0
2
@billyuchenlin
Yea. Thanks for sharing. It is indeed very much relevant to our insights that motivate the design of the constrained loss function against fine-tuning attacks. We will add a reference to it in our next iteration :)
0
0
2
@_xjdr
I also noticed similar things when playing with llama2. It is actually very sensitive to whether there are two spaces or one space after [/INST]
0
0
2
0
0
2
@maksym_andr
@PandaAshwinee
Yea, exactly. It is definitely a promising direction to explore further. It might also be interesting to see subsequent attempts of adaptive attacks on this 😂
0
0
2
Also, our ablation indicates that larger learning rates and smaller batch sizes generally lead to more severe safety degradation! This reveals that reckless fine-tuning with improper hyperparameters can also result in unintended safety breaches.

1
1
2
@furongh
Yea. Also, if we think about this from a RL perspective, this is like --- if an agent being tricked to or happens to get to a bad state, then it should learn to recover from such a bad state. So there should be a nice connection to classical safe RL literature for future work :)
0
0
2
Thanks to all the collaborators for their efforts!
Looking forward to chatting about this paper in Feb early next year at Vancouver :)
0
0
2
@zicokolter
@CadeMetz
Wow, this looks very impressive! Before your talk, we are also going to present a similar "jailbreaking attack" from a multimodality perspective. The advML workshop this year is going to have a lot of new findings.
0
0
2
I will be in person at
#CVPR22
to discuss this work. Drop by if you are interested! 😀
⏰When? June 23, 2022
Oral 3.2.1, 5b: 1:30pm - 3:00pm
Poster session 3.2: 2:30pm - 5:00pm
0
0
2
@xszheng2020
That's a good suggestion. We will upload one checkpoint to the hugging face later :)
As a follow-up, we are also working on an end-to-end alignment training pipeline (SFT+RLHF) that incorporates the proposed data augmentation to build a stronger case. Stay tuned.
0
0
1
0
0
2
@tuzhaopeng
@PandaAshwinee
@youliang_yuan
Thank you :)
Your RTO looks cool.
It’s exciting to see more work in this direction!
0
0
2
It’s so sad. I learned a lot from the great Security Engineering book.

@rossjanderson
Professor Ross Anderson, FRS, FREng Dear friend and treasured long term campaigner for privacy and security, Professor of Security Engineering at Cambridge University and Edinburgh University, Lovelace Medal winner, has died suddenly at home in Cambridge.

82
335
866
0
0
1
@maksym_andr
Yea. Our recent study also has similar findings:
We find that adversarial examples can even be general jailbreakers.
1
0
2
@liang_weixin
Nice work! There is one question comes into my mind: As non-native English speakers are less proficient in English, it is also more likely for them to use GPT-4-like tools to refine their papers and thus more likely to be flagged by detectors. How do you rule out this confounder?
0
0
1
@BoLi68567011
Just curious. In LLaVa’s paper, they mentioned they will do end-to-end finetuning on the LLM as well. Do you mean: for LLaMa-2 integration, they only finetune the linear layer between visual encoder and LLM and no longer finetune the LLM?
0
0
1
0
0
1
🤨

0
0
1
0
0
1
Congratulations to
@XinyuTang7

Doing In-Context Learning Without Leaking Private Data 🔐
Few-shot demonstrations are crucial to improve the performance of any LLM/RAG app. But the issue with very private datasets (e.g. patient clinical reports), is that they can easily be leaked/jailbroken by malicious users.

1
42
221
0
0
1
@DeanCarignan
Great to know our work is helpful. We hope our work can motivate more future research to improve the safety of fine-tuning :)
0
0
1
@PandaAshwinee
@abeirami
@USC
@mahdisoltanol
For sure. Hey
@abeirami
, I will also be in AAAI next week. Would be great to catch up offline :)
1
0
1
0
0
1
0
0
1
1
0
1
@florian_tramer
@EarlenceF
Totally agree. I think the fundamental point is "how to control the model's behaviors within an intended scope". Building a bomb is just an example for us to study the control. When models become stronger, the control we come up with can be extended to there to reduce real harm.
0
0
1
0
0
1
@Raiden13238619
I am always curious what is the exact boundary between science and engineering/technology?
1
0
1
@EasonZeng623
@ChulinXie
Thanks for your interest! For proof-of-concept, we assume white box. This can be applied to jailbreak open-sourced models. We leave the transferability to future research --- with more and more models built on a single foundational visual encoder, transferability is very likely!
0
0
1