

Xuandong Zhao
@xuandongzhao
Followers
1,427
Following
301
Media
46
Statuses
302
Postdoc @UC Berkeley CS; Research: ML, NLP, AI Safety
Goleta, CA
Joined May 2016
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
#خلصوا_صفقات_الهلال1
• 838697 Tweets
ラピュタ
• 408751 Tweets
Atatürk
• 391804 Tweets
Megan
• 225825 Tweets
Johnny
• 225103 Tweets
Sancho
• 150235 Tweets
MEGTAN IS COMING
• 133896 Tweets
#4MINUTES_EP6
• 128070 Tweets
RM IS COMING
• 127281 Tweets
namjoon
• 120999 Tweets
olivia
• 118822 Tweets
Coco
• 53451 Tweets
Labor Day
• 50588 Tweets
كاس العالم
• 47821 Tweets
ミクさん
• 46553 Tweets
ムスカ大佐
• 41106 Tweets
#フロイニ
• 37547 Tweets
Arteta
• 35129 Tweets
ŹOOĻ記念日
• 24633 Tweets
ミクちゃん
• 22995 Tweets
Javier Acosta
• 22436 Tweets
Día Internacional
• 21751 Tweets
Romney
• 18098 Tweets
Ramírez
• 16983 Tweets
Lolla
• 14892 Tweets
ナウシカ
• 13796 Tweets
Lo Celso
• 12045 Tweets
Sekou Kone
• 11059 Tweets
AFFAIR EP1
• 10504 Tweets
نادي سعودي
• 10392 Tweets



















Pinned Tweet

I am excited to join
@UCBerkeley
as a postdoc researcher in Prof.
@dawnsongtweets
's group! My focus will be on Responsible Generative AI.
Looking forward to tackling critical challenges and exploring new collaborations! Let's build a better AI future together!


16
6
432
New
#Nature
study: Generative models forget true data distribution when recursively trained on synthetic data. As quality human data becomes scarce, caution is needed.
This highlights the need for
#watermarking
to filter AI-generated content for future models.

4
49
212
Welcome to my PhD defense this Friday! (12 PM-1 PM PT)
HFH 1132 and

6
5
96
🎉 Congratulations to my advisors
@yuxiangw_cs
and
@lileics
on their well-deserved promotions to associate professor. It has been an immense privilege to work with and learn from these exceptional researchers!

2
3
87
Unfortunately, none of my labmates received a Canada visa in time to attend ACL 2023. I'm disappointed we'll miss the chance for valuable in-person networking at the conference.
#ACL2023NLP
#ACL
4
1
61
Heading to Hawaii for
#ICML2023
! Excited to present our work on text/image watermarking & privacy protection for LLMs. If you're interested in building trustworthy
#GenrativeAI
, my co-authors
@yuxiangw_cs
@lileics
@kexun_zhang
and I would love to meet up and chat!

1
4
43
🧵🔍 Excited to share our latest research on
#AIGC
and image
#watermarking
. We take a look at the existing watermarking schemes and propose a novel framework using generative autoencoders as watermark attackers. 🖼️🔓 Read the full paper here:

3
9
42
Excited that
#ACL2024
has officially started!
Unfortunately, due to visa issues, I won't be able to attend in person. However, I will be participating virtually and engaging with three major projects:
1️⃣ Watermarking Tutorial
2️⃣ LLM Self-Bias
3️⃣ GumbelSoft Watermark
1
3
33
Thrilled to announce that our paper "Pre-trained Language Models can be Fully Zero-Shot Learners" has been accepted to
#ACL2023
!

1
8
32
📢 Check out our new paper: "Provable Robust Watermarking for AI-Generated Text"! We propose a new watermarking method that has guaranteed quality, correctness, and security. I'm profoundly honored to collaborate with three Professors
@yuxiangw_cs
,
@lileics
, and Prabhanjan Ananth

What is a *silver bullet* for LLM abuse🤔? If you ask around, many will say *Watermarks*. But it’s rather tricky to formalize, even according to Scott Aaronson. We just released a new paper with a provably robust watermark and found many new insights 🧵 1/
4
24
95
1
3
26
Check the website of the Tutorial: Watermarking for Large Language Models
1️⃣ Tutorial: Watermarking for Large Language Models
📅 August 11 (Today), 14:00 - 17:30
📍 Lotus Suite 5 – 7
My PhD advisors,
@yuxiangw_cs
and
@lileics
, will be presenting in person. Don’t miss this fantastic talk!

1
6
16
0
4
28
Excited to attend my first in-person conference as a PhD student! Looking forward to meeting with new friends
@naaclmeeting
#NAACL2022

0
0
24
@UCBerkeley
@dawnsongtweets
Grateful for an incredible 5-year journey
@ucsbcs
!
The PhD path isn't easy, but with the guidance of Prof
@yuxiangw_cs
and
@lileics
, and the support of friends&collaborators, I made it!
Check out my thesis, 'Empowering Responsible Use of Large Language Models,' if interested.

1
0
19
📢 Join us tomorrow at our oral talk in the LLM session (11:30-11:45)! I'll introduce NPPrompt, enabling LLMs to function as full zero-shot learners for language understanding. 📷 See you there!
#ACL2023NLP


My group will present 5 papers at
#ACL2023NLP
. I will be onsite for all these papers.
@xuandongzhao
Siqi
@WendaXu2
@jiangjie_chen
Fei will join virtually on underline/gathertown. Welcome to talk to me or co-authors!




0
4
46
0
1
17
1️⃣ Tutorial: Watermarking for Large Language Models
📅 August 11 (Today), 14:00 - 17:30
📍 Lotus Suite 5 – 7
My PhD advisors,
@yuxiangw_cs
and
@lileics
, will be presenting in person. Don’t miss this fantastic talk!
1
6
16
🚀 New Research Alert! Our latest paper introduces a new method to test the robustness of LLMs against jailbreaking attacks. Discover the "Weak-to-Strong Jailbreaking on Large Language Models".
Paper:
Code:

Weak-to-Strong Jailbreaking on Large Language Models
paper page:
Although significant efforts have been dedicated to aligning large language models (LLMs), red-teaming reports suggest that these carefully aligned LLMs could still be jailbroken through

4
47
196
1
2
13
I've transitioned from my
@OpenAI
subscription plan to
@poe_platform
. While my monthly fee remains at $20, I now have access to additional LLMs like Claude and PaLM. However, one downside is the incompatibility with GPT4 plugins.
#LLMs
#AIGC

2
1
15
The session chair told me that the fully-zero shot talk by
@xuandongzhao
is the best received talk in the LLM, which attracts hundreds of audience at
#ACL2023NLP
. A line of people were asking questions.
@siqi_ouyang




0
6
69
0
0
14
Brilliant insights on key challenges shared by Turing winner Prof. Shafi Goldwasser


Really excited about our Future of Decentralization, AI, and Computing Summit, hosted by
@BerkeleyRDI
, with close to 3000 registrations, building towards a future of decentralized, responsible AI!
Join us today
@UCBerkeley
in person
or LIVE 🔗 !

3
22
101
1
2
13
@lateinteraction
Unfortunately, the current evaluation system in academia and industry prioritizes the quantity of papers. There's no penalty for publishing 'too many' papers. For example, for a general PhD to find an RS role in 2024, the only viable path seems to be publishing many LLM papers.
1
1
13
@rckpudi
@pierrefdz
@jwthickstun
@tatsu_hashimoto
@percyliang
Great work! We are also studying robustness against edits - exciting to see alternate methods like yours.

0
1
12
Due to visa issues, I'm unable to attend ICLR in person. If you're interested in our paper, we'd love to discuss it with you on Zoom. Feel free to reach out!

1
1
11
NeurIPS submission is crazy. So far, there are already 16k submissions. If each reviewer handles 6 papers, ~10k reviewers are required. With top reviewers at the AC level not scoring directly, the question arises: Are there enough qualified reviewers?
#NeurIPS2024
1
0
10
Glad to see innovative LLM companies like
@OpenAI
,
@CohereAI
, and
@InflectionAI
make privacy/safety a top priority.
#LLM
#AISafety



2
0
11
None of the current watermarking designs have a theoretical guarantee against paraphrasing attacks. Scott Aaronson suggests semantic watermarking as a potential improvement. Our research supports this, showing similar vulnerabilities in image watermarking:


1/5 New preprint w
@_hanlin_zhang_
, Edelman, Francanti, Venturi & Ateniese!
We prove mathematically & demonstrate empirically impossibility for strong watermarking of generative AI models.
What's strong watermarking? What assumptions? See blog and 🧵
5
44
253
0
3
11
Happy to share that our paper "Provably Confidential Language Modelling" got accepted to
#NAACL2022
!
with
@yuxiangw_cs
,
@lileics
We propose a method to train language generation models while protecting the confidential segments
#NLProc

0
1
11
🚨 New research alert! Check out our new findings: the self-refine pipeline in LLMs improves the fluency and understandability of model outputs, but it also amplifies self-bias.
Paper:


[New paper!] Can LLMs truly evaluate their own output? Can self-refine/self-reward improve LLMs? Our study reveals that LLMs exhibit biases towards their output. This self-bias gets amplified during self-refine/self-reward, leading to a negative impact on performance.
@ucsbNLP

5
53
211
0
2
11
How to learn highly compact yet effective sentence representation? Our paper "Compressing Sentence Representation for Semantic Retrieval via
Homomorphic Projective Distillation" will be in the VPS2 poster session virtually on May 24th at 11:00 PDT (19:00 Dublin time).
#ACL2022

1
1
11
Thrilled to announce our paper, "Protecting Language Generation Models via Invisible Watermarking," has been accepted for
#ICML2023
! 🎉 Can't wait to meet you all in Hawaii this July!
Great minds think alike😂.
@tomgoldsteincs
's method is remarkably similar to (and independent of) the watermark for LLMs that
@lileics
@xuandongzhao
and I came up with in . Our work shows that this watermark remains visible even after distillation! 1/x
1
2
23
0
1
11
@xiangyuqi_pton
Interesting work! We had similar findings in our weak-to-strong jailbreaking paper.

1
0
10
Glad to see leading AI companies starting to use text watermarking!

In the coming months, we will be open-sourcing SynthID text watermarking.
This will be available in our updated Responsible Generative AI Toolkit, which we created to make it easier for developers to build AI responsibly.
Find out more. →
#GoogleIO
4
4
36
0
0
9
Nice work on GenAI copyright

Questions for GenAI & copyright researchers (w/ answers in ℂ𝕠𝕋𝕒𝔼𝕧𝕒𝕝: ):
- Can 𝐬𝐲𝐬𝐭𝐞𝐦 𝐩𝐫𝐨𝐦𝐩𝐭/𝐮𝐧𝐥𝐞𝐚𝐫𝐧𝐢𝐧𝐠 prevent copyrighted content generation?
- Does permissive training data still help if 𝐑𝐀𝐆 fetches copyrighted content?
1
18
133
1
0
9
Excited to attend
#NeurIPS2023
from December 10th to 15th! Can't wait to catch up with familiar faces and make new connections.
I am on the job market this year. I would be happy to discuss any opportunities that may be a good fit.
0
0
9
🚀🚨Excited to share our work: 𝗗𝗘-𝗖𝗢𝗣 on LLM membership inference attack!
🔍 Key features:
• Works with black-box models
• Extendable to test data contamination
Join
@avduarte3333
for an in-person discussion at our 𝗜𝗖𝗠𝗟 poster!
🔗 Paper:

Are you interested in Data Contamination? ☣️
Curious if LLMs were trained on copyrighted content? 🤔
Check out 𝗗𝗘-𝗖𝗢𝗣: Detecting Copyrighted Content in Language Models Training Data (𝗜𝗖𝗠𝗟 𝟮𝟬𝟮𝟰), our novel detection method fully compatible with black-box models!

1
6
19
1
0
8

Asked four LLM systems for the latest news about Trump. Looks like Perplexity is the winner

0
0
8
Similar conclusions and findings can be found in a recent paper led by Stanford.

0
3
7
Feeling unsatisfied with your
#EMNLP
submission feedback? Try this fun task:
Send the PDF version to and use the popular review GPTs like "Reviewer 2".
You might be surprised by how similar the feedback is to what you got from the website and ARR!
0
0
8
@pratyushmaini
@NicolasPapernot
@NickJia5
@adam_dziedzic
Cool work! In our recent ICML paper, we conducted such membership inference attacks in a black-box way. Might be of your interest
1
1
8
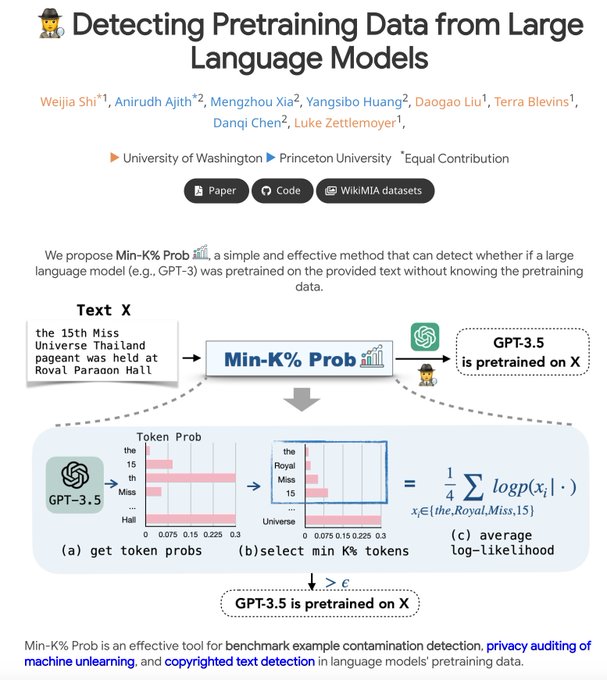
A line of zero-shot LLM-generated text detection tools also rely on such "new" forms of perplexity scores. But it's unclear if perplexity alone is enough or not...

Ever wondered which data black-box LLMs like GPT are pretrained on? 🤔
We build a benchmark WikiMIA and develop Min-K% Prob 🕵️, a method for detecting undisclosed pretraining data from LLMs (relying solely on output probs).
Check out our project:
[1/n]
16
139
663
1
0
8
Just conducted a rapid experiment on the watermarking system. It appears it's not resistant to paraphrasing attacks. The initial image illustrates the first example they've provided. I requested a rewrite from Claude, and intriguingly, the detector was unsuccessful.




Stanford developed an LLM watermarking algorithm robust to certain paraphrasing and distortion, such as translating to French and back to English.🤔
Interesting paper, but I still find it counter-intuitive. Would this imply that there’s a subspace of natural language strings

7
23
194
0
0
8
Excited to share our latest work on Permute-And-Flip decoding! 🚀
A huge shoutout to my advisors
@yuxiangw_cs
and
@lileics
for their invaluable contributions!
Dive into our paper and explore the code here:
🚀Exciting new advance in
#LLM
decoding and
#watermarking
from
@xuandongzhao
! Introduce *Permute-And-Flip decoding*: a drop-in replacement of your favorite softmax sampling (or its Top-p / Top-k variant) that you should try today:
A TL;DR thread🧵 1/
1
10
43
0
0
7
It is fun to read Anthropic's blog on "how to evaluate AI systems". In human society, for example, PhD applicants need to show exam results, rec letters, and statements.
So what is the equivalent of a "recommendation letter" for evaluating an LLM?🧐
#LLM

0
0
6
We will see lots of "papers" evaluating the ability of Claude 2 :)

Introducing Claude 2! Our latest model has improved performance in coding, math and reasoning. It can produce longer responses, and is available in a new public-facing beta website at in the US and UK.

162
522
2K
1
1
7
@WilliamWangNLP
had a great talk about jailbreaking in LLMs at
@ACTION_NSF_AI
"Unveiling Hidden Vulnerabilities: Exploring Shadow Alignment and Weak-to-Strong Jailbreaking in Large Language Models"

0
1
7
@demishassabis
@GoogleDeepMind
@googlecloud
Impressed by the new watermarking tool, but have you considered attacks like regeneration? Our research proves these can effectively remove any pixel-based invisible watermarks, regenerating images closely resembling the original.
Paper:
0
1
5

#emnlp2022
#nlproc
#emnlp
How can we protect the intellectual property of trained NLP models? I am happy to share our new paper “Distillation-Resistant Watermarking for Model Protection in NLP”. Don’t miss it! (1/n)
Code:
Paper:
1
0
6
FACT SHEET: President Biden Issues Executive Order on Safe, Secure, and Trustworthy Artificial Intelligence

1
0
5
Time to try our watermark attack

We’re excited to launch 𝗦𝘆𝗻𝘁𝗵𝗜𝗗 today with
@GoogleCloud
: a digital tool to watermark and identify AI-generated images. 🖼️
It will be available on Imagen, one of
@Google
’s latest text-to-image models.
Here’s how it works. 🧵
#GoogleCloudNext
49
208
716
0
0
5
2️⃣ [Oral] Pride and Prejudice: LLM Amplifies Self-Bias in Self-Refinement
Awesome
@WendaXu2
will present:
📍 Poster: Convention Center A1
🗓️ Monday, August 12, 2024, 14:00 - 15:30 PM
🎙️ Oral: Lotus Suite 5-7
📅 Tuesday, August 13, 2024, 11:15 - 11:30 AM

1
2
5
With the success of GPT-4o Mini, the next wave of academic research is likely to herald a renaissance in knowledge distillation.
0
0
5
Nice demo!

Introducing Pika 1.0, the idea-to-video platform that brings your creativity to life.
Create and edit your videos with AI.
Rolling out to new users on web and discord, starting today. Sign up at
1K
5K
26K
0
0
5

ACL 2024 (1/4)
@aclmeeting
- Watermarking for Large Language Model. Xuandong Zhao, Yu-Xiang Wang and Lei Li.
- AI for Science in the Era of Large Language Models. Zhenyu Bi, Minghao Xu, Jian Tang and Xuan Wang.
#NLProc
1
1
10
0
1
5
Is there an unspoken rule that CS PhDs must wear glasses?🧐

1
0
5

We're exploring similar edit robustness issues of watermarking from a different angle. Read more:

Two properties of our watermarking strategy:
1) It preserves the LM distribution
2) Watermarked text can be distinguished from non-watermarked text (given a key)
How can both be true?
Answer: p(text) = \int p(text | key) p(key) d key
Detector also doesn't need to know the LM!
6
20
80
0
0
5

Many of my research endeavors explore text and image watermark techniques. Looking forward to insightful discussions on responsible AI at
#ICML2023
!

Meta, Google, and OpenAI promise the White House they’ll develop AI responsibly

68
33
178
0
0
5
Finally, I was able to watch the video and truly admire the academic rigor of the experiment design and presentation by
@ZeyuanAllenZhu
I encourage everyone to study this tutorial. It would be great to see these findings applied to the next version of LLMs.

YouTube video is now restored. As I predicted, AGI didn't arrive before Aug 20. PS: Part 2.2 paper is in its very final processing stage; we are one man down (due to a layoff) so please forgive us for just a little more time.
4
41
329
0
0
22
Cool! The 2B model is much more accessible for those in academia! 🤣

Gemma 2 2B is here!
Fantastic performance for size, it's great for research and applications.
I am very proud of the progress our team made over the last few months!

4
33
180
0
1
5

@srush_nlp
Yes, while current LLMs aren't a serious threat to humans, there are some news articles discussing real cases of jailbreaks.
1.
2.
3.
1
0
5
3️⃣ GumbelSoft: Diversified Language Model Watermarking via the GumbelMax-trick
Awesome
@AlfonsoGerard_
will present:
📍 Poster: Convention Center A1
📅 Monday, August 12, 2024, 11:00 - 12:30

1
3
4
0
0
3
Gemini and Grok seems to be on opposite ends in addressing safety/copyright issues🧐
0
0
4
Does anyone know how to handle reviewers asking for comparisons with your follow-up works? Are there any guidelines for this?
@NeurIPSConf
#NeurIPS2024
1
0
4
Remarkably, AI can now mimic actors' accents and translate into different languages. Reports suggest the method behind this is HeyGen: .
An open-source version could be transformative. But, we must also prioritize tools to detect such manipulated videos.


0
0
4
Welcome to our Oral talk this afternoon 2:45-3:00pm at Columbia A!
Happy to share that our paper "Provably Confidential Language Modelling" got accepted to
#NAACL2022
!
with
@yuxiangw_cs
,
@lileics
We propose a method to train language generation models while protecting the confidential segments
#NLProc
0
1
11
0
0
4
When you read a really solid paper, you sincerely admire someone.
0
0
3
Safety and profit often seem like a paradox in industry. However, AI safety, especially given the incredible capabilities of large models, is crucial for all of humanity. This is also one of the most important research goals in academia.

0
0
3
Ethical data use must be the top priority in AI development. Membership inference attacks, especially for closed-source models, are essential tools for detecting violations. Discover more insights in our ICML paper, DE-COP:

“It’s theft.” A WIRED investigation found that subtitles from 173,536 YouTube videos, siphoned from more than 48,000 channels, were used by Anthropic, Nvidia, Apple, and Salesforce to train AI.
9
35
75
0
0
4
🚀 Sora's advancements are amazing, but such techniques blur the lines between reality and simulation. Watermarking is a promising approach! We have conducted several works to address this concern.
Image watermark attack:
#Sora
#Watermark
#AIGC

Introducing Sora, our text-to-video model.
Sora can create videos of up to 60 seconds featuring highly detailed scenes, complex camera motion, and multiple characters with vibrant emotions.
Prompt: “Beautiful, snowy
10K
32K
138K
1
0
3
More detailed government actions towards the safe and responsible use of AI.

1
0
3
Prof. Raj Reddy, Turing Award laureate, shared his insights on the “Perils of AI” at
#AAPM2024
in Stanford


0
0
3
After using both for a while, I've found Claude 2 to be slightly better than GPT-4. I've now set Claude 2 as my default model, aligning with recent findings that GPT-4's performance declines over time...
#ChatGPT
#Claude
#OpenAI
#Anthropic
I've transitioned from my
@OpenAI
subscription plan to
@poe_platform
. While my monthly fee remains at $20, I now have access to additional LLMs like Claude and PaLM. However, one downside is the incompatibility with GPT4 plugins.
#LLMs
#AIGC
2
1
15
0
0
3
@GoogleDeepMind
@googlecloud
@Google
Impressed by the new watermarking tool, but have you considered attacks like regeneration? Our research proves these can effectively remove any pixel-based invisible watermarks, regenerating images closely resembling the original.
0
0
3
2. We live in a time when posting images online can be risky. Malicious users may misuse these images, violating copyright and privacy. Furthermore, generative AI like DALLE-2 and Imagen can generate highly realistic images which could mislead people. 🧑💻🎭
1
0
3
Wishing everyone a fantastic
#ACL2024
conference! ✨ Enjoy your time in Bangkok🇹🇭!
@aclmeeting
#NLP
#LLMs
0
1
3
@johnschulman2
Congrats to
@AnthropicAI
on getting a real legend! Wishing you all the best in this new chapter!
0
0
3
Cool work about preference learning!
Still playing around with offline DPO?
Big mistake!🤯
We claim two things: 1) We should NOT use a static preference data 2) We should NOT use a fixed reference model
Our on-policy BPO outperforms offline DPO: TL;DR (72.0%➡️89.5%), HH(82.2%➡️93.5%, 77.5%➡️97.7%)
@ucsbNLP

4
35
130
0
0
3
@AnsongNi
We have works that plant watermarks in the training data of models, e.g., to infer the model’s training set or otherwise influence the model’s output
0
0
3
Curious about the impact of LLMs on academic writing and reviews? Check out our latest paper and code here:

🚀 Exciting news! Our code for the "Monitoring AI-Modified Content at Scale (ICML 2024)" and "Mapping the Increasing Use of LLMs in Scientific Papers" is now open-source.
🔥🔥🔥We've developed a simple and effective method for estimating the fraction of text in a large corpus




4
8
19
0
0
2
This is all about the evaluation system. It's very difficult to objectively evaluate a researcher, a PhD student.

Since we just wrapped up an AI megaconference, it felt like a good day to plead for fewer papers.
32
162
853
0
0
2
4. We propose a framework using generative autoencoders as watermark attackers. The watermarked image is encoded to a latent code and then decoded to a reconstructed image, effectively erasing the watermark.

1
0
2
📄This weak-to-strong amplification aligns with concurrent works on empowering models with instruction following (Liu et al., 2024) and disentangling acquired knowledge (Mitchell et al., 2023). [7/8]
1
0
2
@YangsiboHuang
My concern is that manually designed perplexity scores may not be robust across diverse distributions. In my experience, zero-shot LLM text detection tools aren't robust across languages.
1
0
1
1
0
2
@WenhuChen
For high-quality data like books, I don't think human writing speed can catch up with the consumption speed of LLMs.
1
0
2
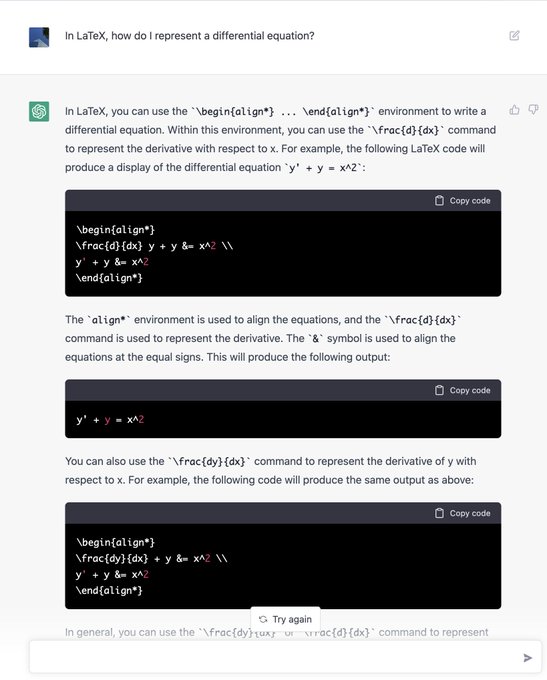
Amazing

1
0
2
5. Our evaluation demonstrates that generative autoencoders, especially diffusions, can remove more invisible watermarks than most existing attackers, while preserving image quality. This reveals vulnerabilities in existing watermark schemes. 📊🔓

1
0
2
3. Major tech companies like Google are developing tools to trace image origins or identify synthetically generated content. Invisible watermarks are one such tool used to embed secret messages detectable only by the owner. 🕵️♂️🖼️
1
0
2