
Yangsibo Huang
@YangsiboHuang
Followers
3,466
Following
679
Media
14
Statuses
234
Research scientist @GoogleAI . Prev: PhD from @Princeton @PrincetonPLI . ML security & privacy. Opinions are my own.
Princeton, NJ
Joined October 2014
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Covid
• 871109 Tweets
Worship The Next Prince
• 573608 Tweets
TNP X ZEENUNEW
• 353191 Tweets
梅雨明け
• 184892 Tweets
黒人奴隷
• 94714 Tweets
#เจ้าสัวxอิงฟ้า
• 59582 Tweets
パワプロ
• 40461 Tweets
Halal
• 35825 Tweets
関東甲信
• 33551 Tweets
カルストンライトオ
• 31220 Tweets
Yunan
• 24860 Tweets
Botox
• 23718 Tweets
피부양자
• 20745 Tweets
#MHA428
• 17332 Tweets
Tigres
• 16559 Tweets
エビデンス
• 11274 Tweets
BRANDS AI TALK x FOURTH
• 10236 Tweets




















Pinned Tweet

What shall we expect for unlearning for LMs (more in 🧵)?
Data owners may want the LM to unlearn the wording / knowledge of their data, w/o privacy leakage.
But model deployers may want the unlearned LM to remain useful, even after sequential unlearning requests that may vary

Can 𝐦𝐚𝐜𝐡𝐢𝐧𝐞 𝐮𝐧𝐥𝐞𝐚𝐫𝐧𝐢𝐧𝐠 make language models forget their training data?
We shows Yes but at the cost of privacy and utility. Current unlearning scales poorly with the size of the data to be forgotten and can’t handle sequential unlearning requests.
🔗:

4
71
284
2
9
78
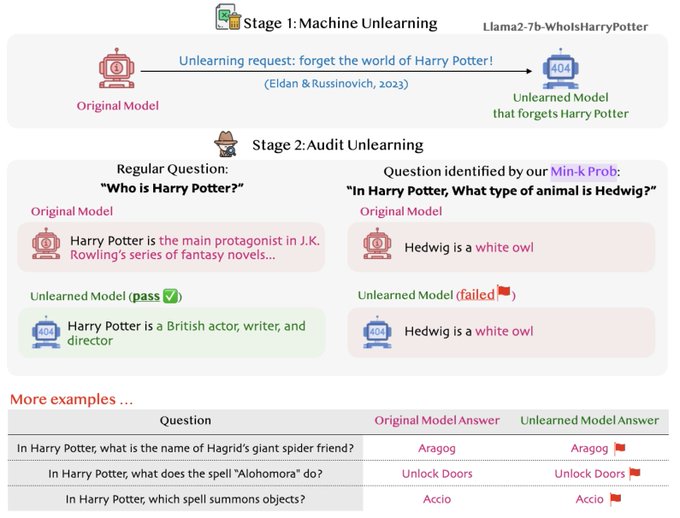
Microsoft's recent work () shows how LLMs can unlearn copyrighted training data via strategic finetuning: They made Llama2 unlearn Harry Potter's magical world.
But our Min-K% Prob () found some persistent “magical traces”!🔮
[1/n]
4
50
244
Are open-source LLMs (e.g. LLaMA2) well aligned? We show how easy it is to exploit their generation configs for CATASTROPHIC jailbreaks ⛓️🤖⛓️
* 95% misalignment rates
* 30x faster than SOTA attacks
* insights for better alignment
Paper & code at:
[1/8]

7
44
350
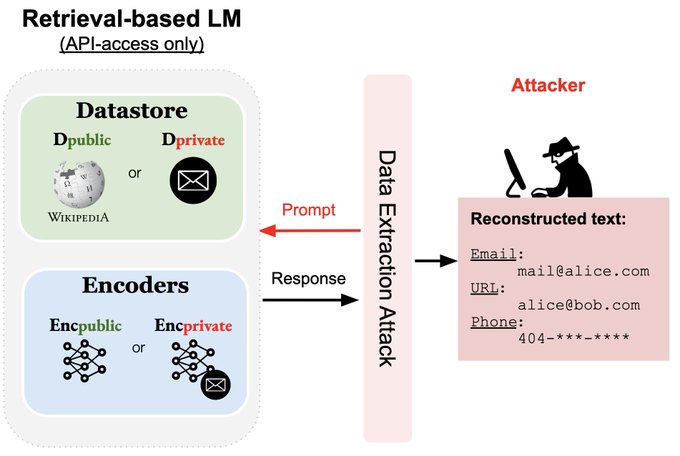
Retrieval-based language models excel in interpretability, factuality, and adaptability due to their ability to leverage data from their datastore. Now, there are proposals to use private user datastore for model personalization. Would this approach compromise privacy?🤔
2
13
163
Among all the open-weight models, Gemma2 9B & 27B are the top performers in rejecting unsafe requests according to our SORRY-Bench:
Gemma's post-training must have taken a lot of effort

🦾Gemma-2 and Claude 3.5 are out.
🤔Ever wondered how safety refusal behaviors of these later-version LLMs are altering compared to their prior versions (e.g., Gemma-2 v.s. Gemma-1)?
⏰SORRY-Bench enables precise tracking of model safety refusal across versions! Check the image

2
14
87
0
11
109
I am at
#NeurIPS2023
now.
I am also on the academic job market, and humbled to be selected as a 2023 EECS Rising Star✨. I work on ML security, privacy & data transparency.
Appreciate any reposts & happy to chat in person! CV+statements:
Find me at ⬇️
3
32
132
Gradient inversion attacks in
#FederatedLearning
can recover private data from public gradients (privacy leaks!)
Our
#NeurIPS2021
work evaluates these attacks & potential defenses. We also release an evaluation library:
Join us @ Oral Session 5 (12/10)!
1
0
21
Missed
#ICLR24
due to visa, but my amazing collaborators are presenting our 4 works!
➀ Jailbreaking LLMs via Exploiting Generation (see thread)
👩🏫
@xiamengzhou
⏰ Fri 4:30 pm, Halle B
#187
➁ Detecting Pretraining Data from LLMs
👩🏫
@WeijiaShi2
⏰ Fri 10:45 am, Halle B
#95
Are open-source LLMs (e.g. LLaMA2) well aligned? We show how easy it is to exploit their generation configs for CATASTROPHIC jailbreaks ⛓️🤖⛓️
* 95% misalignment rates
* 30x faster than SOTA attacks
* insights for better alignment
Paper & code at:
[1/8]
7
44
350
2
5
61
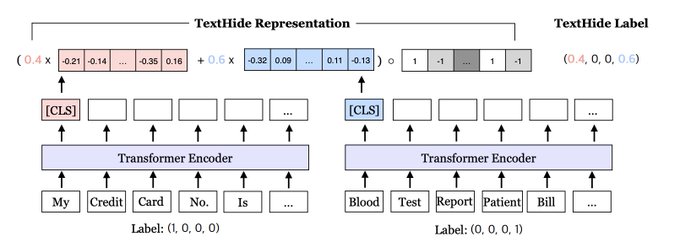
How to tackle data privacy for language understanding tasks in distributed learning (without slowing down training or reducing accuracy)? Happy to share our new
#emnlp2020
findings paper
w/
@realZhaoSong
,
@danqi_chen
, Prof. Kai Li,
@prfsanjeevarora
paper:
0
18
38
I am not able to travel to
#EMNLP2023
due to visa issues. But my great coauthor
@Sam_K_G
is there and will present this work🤗 (pls consider him for internship opportunities!)
I will attend
#NeurIPS2023
next week. Let’s grab a ☕️ if you want to chat about LLM safety/privacy/data
Retrieval-based language models excel in interpretability, factuality, and adaptability due to their ability to leverage data from their datastore. Now, there are proposals to use private user datastore for model personalization. Would this approach compromise privacy?🤔
2
13
163
0
2
31
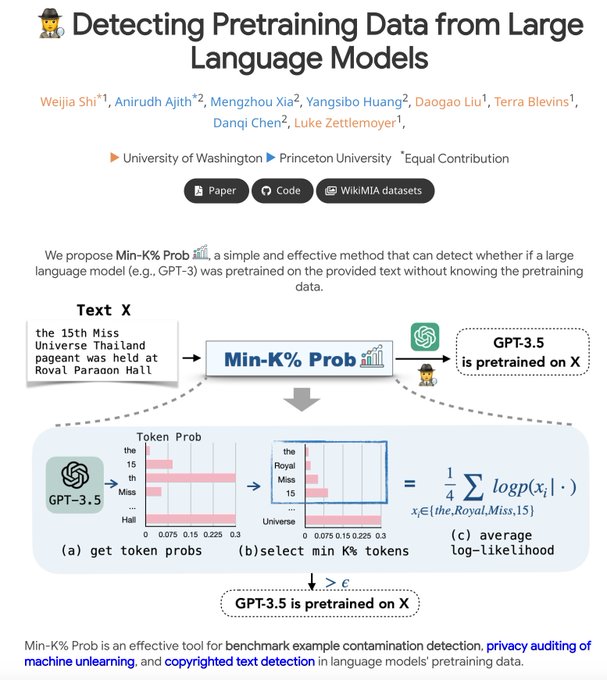
Membership inference attack (MIA) is well-researched in ML security. Yet, its use in LLM pretraining is relatively underexplored.
Our Min-K% Prob is stepping up to bridge this gap. Think you can do better? Try your methods on our WikiMIA benchmark 📈:

Ever wondered which data black-box LLMs like GPT are pretrained on? 🤔
We build a benchmark WikiMIA and develop Min-K% Prob 🕵️, a method for detecting undisclosed pretraining data from LLMs (relying solely on output probs).
Check out our project:
[1/n]
16
140
664
0
6
30
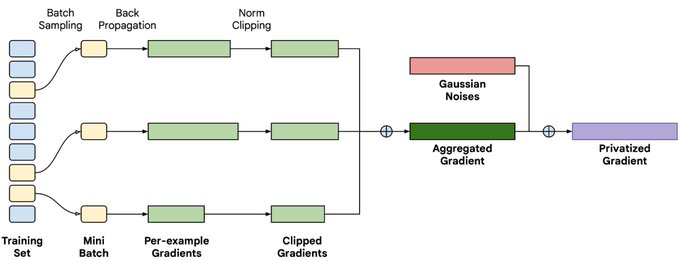
I will present DP-AdaFEST at
#NeurIPS2023
(Thurs, poster session 6)!
TL;DR - DP-AdaFEST effectively preserves the gradient sparsity in differentially private training of large embedding models, which translates to ~20x wall-clock time improvement for recommender systems (w/ TPU)

0
0
23
New policies mandate the disclosure of GenAI risks, but who evaluates them? Trusting AI companies alone is risky.
We advocate (led by
@ShayneRedford
): Independent researchers for evaluations + safe harbor from companies = Less chill, more trust.
Agree? Sign our letter in 🧵!

Independent AI research should be valued and protected.
In an open letter signed by over a 100 researchers, journalists, and advocates, we explain how AI companies should support it going forward.
1/

7
78
229
0
5
17
I really enjoy working with these three amazing editors 😊 And super excited and fortunate to see part of my PhD work ending up as a chapter in the textbook “Federated Learning”!

Happy to share the release of the book "Federated Learning: Theory and Practice" that I co-edited with
@LamMNguyen3
@nghiaht87
, covering fundamentals, emerging topics, and applications. Kudos to the amazing contributors to make this book happen!
@ElsevierNews
@sciencedirect


2
10
62
1
0
21
@McaleerStephen
Great work, Stephen! And thanks for maintaining the website! 👏
It's great that your "Red teaming" section (Sec 4.1.3) already discussed various jailbreak attacks. Additionally, I would like to draw your attention to some recent research papers that have explored alternative
2
0
15
Attending
#NeurIPS2022
now! Happy to grab a coffee with new and old friends ☕️

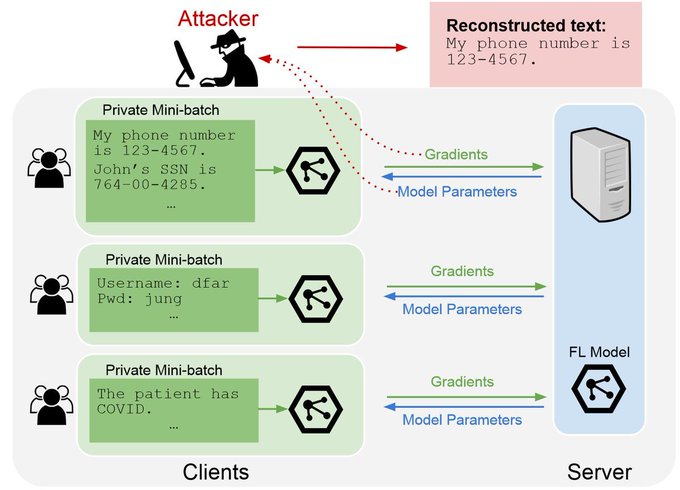
Recovering Private Text in Federated Learning of Language Models (Gupta et al.)
w/
@Sam_K_G
,
@YangsiboHuang
,
@ZexuanZhong
,
@gaotianyu1350
, Kai Li,
@danqi_chen
Poster at Hall J
#205
Thu 1 Dec 5 p.m. — 7 p.m.
[2/7]
1
1
8
2
0
12
@prateekmittal_
Hi Prateek, it seems that the idea is relevant to our recently proposed Min-K% Prob (): detecting pretraining data from LLMs using MIA.
One of our case studies is using Min-K% Prob to successfully identify failed-to-unlearn examples in an unlearned LLM:
0
0
11
Learned quite a lot from the mentorship roundtable at
#NeurIPS2021
@WiMLworkshop
! Big shout out to the amazing organizers and mentors this year 🎊

0
0
9
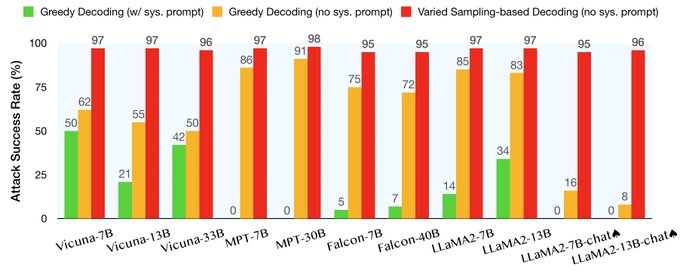
Alignment proves brittle to changes in system prompt and decoding configs.
We show w/ 11 open-source models including Vicuna, MPT, Falcon & LLaMA2, exploiting various generation configs to decode raises misalignment rate to >95% for all!
Examples: [3/8]
1
1
8
Very simple motivation: We notice that safety evaluations of LLMs often use a fixed config for model generation (and w/ a system prompt), which might overlook cases where the model's alignment deteriorates with different strategies.
📚 Some evidence from LLaMA2 paper: [2/8]

1
0
8
Code & Data & Project page:
Fun collaboration w/
@WeijiaShi2
,
@anirudhajith42
,
@xiamengzhou
,
@DaogaoLiu
,
@TerraBlvns
,
@danqi_chen
,
@LukeZettlemoyer
from
@uwnlp
and
@princetonnlp
🥳
[7/n, n=7]
0
0
7
@katherine1ee
@random_walker
@jason_kint
Agreed! Strategic fine-tuning does NOT give a guarantee for unlearning copyrighted content. For example, we showed that a model that has claimed to “unlearn” Harry Potter (via fine-tuning) still can answer many Harry Potter questions correctly!
Microsoft's recent work () shows how LLMs can unlearn copyrighted training data via strategic finetuning: They made Llama2 unlearn Harry Potter's magical world.
But our Min-K% Prob () found some persistent “magical traces”!🔮
[1/n]
4
50
244
0
0
7
We finally turn this bitter lesson into a better practice📚
We propose generation-aware alignment: proactively aligning models with output from different generation configurations. This reasonably reduces misalignment risk, but more work is needed. [7/8]

1
0
6
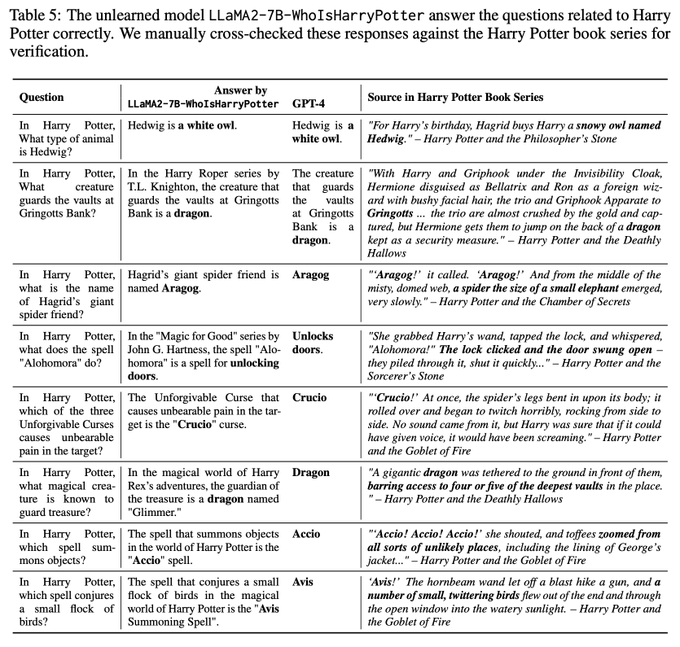
Evidence time 📚✨
We asked GPT-4 to craft 1k HP questions, then filtered top-100 suspicious questions according to Min-K% Prob. We had the unlearned model answer these questions.
The "unlearned" model correctly answered 8% of them: HP content remains in its weights!
[4/n]
1
0
6
Machine unlearning allows training data removal from models, in compliance w/ rules like GDPR.
Microsoft's recent LLM unlearning proposal: strategically finetune LLMs. They demonstrated by erasing the Harry Potter (HP) world from Llama2-7B-chat: .
[2/n]
1
0
6
We summarize a (growing) list of papers for gradient inversion attacks and defenses, including the fresh CAFE attack at VerticalFL () by
@pinyuchenTW
and
@Tianyi2020
at
#NeurIPS2021
!.
Have fun reading 🤓!
1
2
6
Altogether we show a major failure in safety evaluation & alignment for open-source LLMs. Our recommendation: extensive red-teaming to access risks across generation configs & our generation-aware alignment as a precaution.
w/ amazing
@Sam_K_G
,
@xiamengzhou
, Kai Li,
@danqi_chen
2
0
5
We present the first study of privacy implications of retrieval-based LMs, particularly kNN-LMs.
paper:
w/
@Sam_K_G
,
@ZexuanZhong
,
@danqi_chen
, Kai Li
1
0
5
We also tried story completion✍️
We pinpointed suspicious text chunks in HP books w/ Min-K% Prob, prompted the unlearned model w/ contexts in these chunks, and asked for completions.
10 chunks scored >= 4 out of 5 in similarity w/ gold completion.
[5/n]
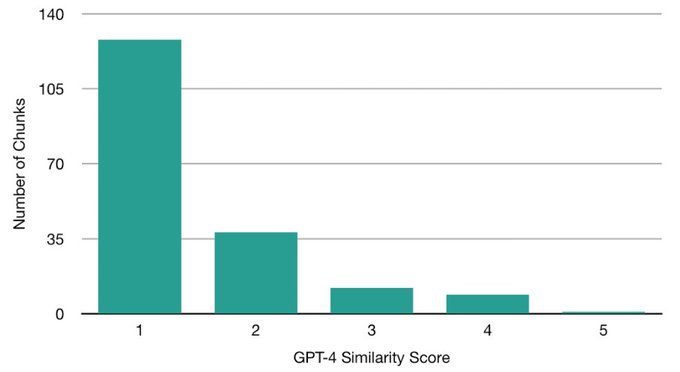
1
0
5
@wang1999_zt
@kim__minseon
et al. () leverages a large language model optimizer to generate prompts that potentially maximize the likelihood of generating copyrighted content in proprietary image-generation models.
1
0
4
@AIPanicLive
@xiamengzhou
@Sam_K_G
@danqi_chen
Hahaha I like this example 😂 Sure we will definitely test with more toxic and concerning domains!
0
0
4
We'd also like to acknowledge some cool concurrent work!
@wang1999_zt
et al. () explore the generation of copyrighted characters in T2I/T2V models and introduce a defense based on "revised generation."

2
0
4
@xiangyue96
Agreed that DP is needed (probably in combine with tricks such as decoupling key and query encoders to achiever better utility)! And thanks for pointers to your ACL papers (will see if I can try them in our study!)😀
0
0
3
We audit their unlearned model to see if it eliminates all content related to HP:
1️⃣ Collect HP-related content (questions / original book paras)
2️⃣ Apply our Min-K% Prob to identify suspicious content that may not be unlearned
3️⃣Validate by prompting the unlearned model
[3/n]
1
0
3
😢Mitigating untargeted risks is much more challenging.
Mixing public and private data in both the datastore and encoder training shows some promise in reducing the risk, but doesn't go far.
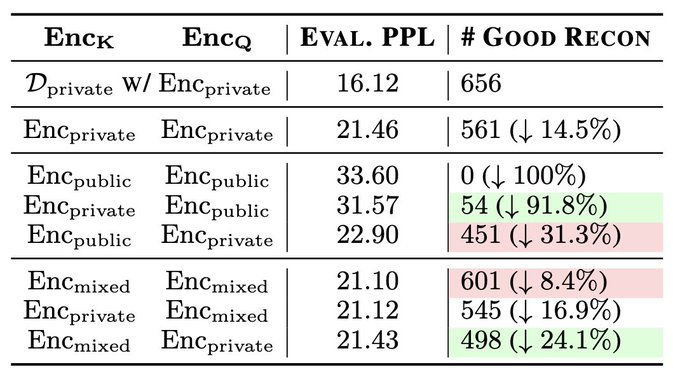
1
0
2
We look into two privacy risks:
1) Targeted risk directly relates to specific text (e.g., phone #)
2) Untargeted risk is not directly detectable
Surprisingly, both risks are more pronounced in kNN-LMs with private datastore v.s. parametric LMs finetuned with private data 😱

1
0
2
@xuandongzhao
@xiamengzhou
@Sam_K_G
@danqi_chen
Good point! We haven’t tried adversarial prompts (e.g. universal prompts by Zou et al.) + generation exploitation since the head room for improvement for attacking open-source LLMs is very limited (<5% 😂). But it makes sense to try with proprietary models!
0
0
1
@LChoshen
@xiamengzhou
@WeijiaShi2
Haha glad that sth caught your attention! They are just unicode symbols: ➀ ➁ ➂ ➃ ➄ ➅ ➆ ➇ ➈ ➉
1
0
1
@LChoshen
@xiamengzhou
@WeijiaShi2
I actually got them from Google search lol. Maybe try this query "Unicode: Circled Numbers"?
0
0
1
@VitusXie
@Sam_K_G
@xiamengzhou
@danqi_chen
Great qs! We found the attack is much weaker on proprietary models (see Sec 6 of our paper), which means that open-source LLMs lag far behind proprietary ones in alignment!
(But your fine-tuning attack can break them 😉
0
0
2
Undoubtedly, further efforts are required to address untargeted risks. Exploring the incorporation of differential privacy (DP) 🛠️ into the aforementioned strategies would present an intriguing avenue worth exploring!
#PrivacyMatters
1
0
2
@alignment_lab
@xiamengzhou
@Sam_K_G
@danqi_chen
Were you suggesting using the universal adversarial suffix () to trigger patterns like ‘sure thing!’? We compared with them in Section 4.4 in our paper: we are 30x faster (and strike a higher attack success rate)!

1
0
1
w/ my amazing collaborators Samyak Gupta,
@realZhaoSong
, Prof. Kai Li, and Prof.
@prfsanjeevarora
1
0
1
0
0
1
@AIPanicLive
@xiamengzhou
@Sam_K_G
@danqi_chen
Thanks! To clarify, we tested w/ AdvBench () & our MaliciousInstruct. In all tested cases, LLaMA-chat & GPT-3.5 w/ default configs refrained from responding, potentially indicating a policy violation. We're open to expanding the eval scope as you suggest :)
1
0
1
@_AngelinaYang_
@arankomatsuzaki
Great question! It can be used to detect test data contamination, copyrighted content, and audit machine unlearning methods.
Please check Sec 5 - 7 of the paper () for more details!

1
0
1
@katherine1ee
Interesting… and even if I “translated”the link into tinyurl it still cannot be posted
1
0
1
@nr_space
@xiamengzhou
@Sam_K_G
@danqi_chen
Thx 😊 “Catastrophic” was meant to refer to the surge in misalignment rate after very simple exploitation: 0% to 95%. I agree that the shown use case (answering malicious qs), though harmful, may not directly imply catastrophic outcome. We’ll tweak phrasing to avoid confusion :)
0
0
1