

Danqi Chen
@danqi_chen
Followers
14,064
Following
720
Media
2
Statuses
372
Assistant professor @princeton_nlp @princetonPLI @PrincetonCS . Previously: @facebookai , @stanfordnlp , @Tsinghua_Uni
Princeton, NJ
Joined December 2009
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
#خلصوا_صفقات_الهلال1
• 1032757 Tweets
ラピュタ
• 407072 Tweets
Atatürk
• 402563 Tweets
Megan
• 239814 Tweets
Johnny
• 237141 Tweets
نابولي
• 198560 Tweets
#4MINUTES_EP6
• 147191 Tweets
RM IS COMING
• 134533 Tweets
namjoon
• 126560 Tweets
olivia
• 121447 Tweets
Napoli
• 104591 Tweets
Sterling
• 96798 Tweets
Coco
• 55238 Tweets
Labor Day
• 53972 Tweets
كاس العالم
• 50869 Tweets
Arteta
• 37613 Tweets
Nelson
• 31606 Tweets
Javier Acosta
• 26543 Tweets
ŹOOĻ記念日
• 25012 Tweets
Día Internacional
• 23875 Tweets
Romney
• 19138 Tweets
Tadic
• 16756 Tweets
Lolla
• 15982 Tweets
Dzeko
• 15098 Tweets
#FBvALY
• 13983 Tweets
Lo Celso
• 12627 Tweets
نادي سعودي
• 11845 Tweets























New center at Princeton on large language models research. Come join us! 😍😍😍

Princeton has a new Center for Language and Intelligence, researching LLMs + large AI models, as well as their interdisciplinary applications. Looking for postdocs/research scientists/engineers; attractive conditions.
21
115
619
1
12
244
I am super excited about this paper. A new training approach for LMs with memory augmentation!
* A simple and (maybe) better training objective for LMs?
* With clever memory construction and data batching, better than kNN-LM, Transformer-XL etc.

Very excited to share a preprint “Training Language Models with Memory Augmentation”!
We propose a new training objective TRIME for language modeling—inspired by contrastive learning—which aligns with both token embeddings and *in-batch memories*.
1/n


4
52
249
1
42
200
#NAACL2022
I am already in Seattle. This is my first conference since I became a faculty😂..... Let's catch up of course :) Oh, and all my students are here!
2
1
201
Very surprised and excited by this result. Contrastive learning can go a loooong way in NLP!

💥 to share “SimCSE: Simple Contrastive Learning of Sentence Embeddings”. We show that a contrastive objective can be VERY effective with right *augmentation* or *datasets*. Large gains on STS tasks and unsup. SimCSE matches previous supervised results!

7
57
350
1
25
196
Glad this SimPO paper is finally out. I am intrigued by its simplicity and effectiveness. The team has done a very impressive job in various experimental settings (and careful hyper-parameter tuning!) and in-depth analysis. Kudos to
@yumeng0818
@xiamengzhou

Introducing SimPO: Simpler & more effective Preference Optimization!🎉
Significantly outperforms DPO w/o a reference model!📈
Llama-3-8B-SimPO ranked among top on leaderboards!💪
✅44.7% LC win rate on AlpacaEval 2
✅33.8% win rate on Arena-Hard
🧵[1/n]

9
79
440
1
23
169
We are planning the 2nd workshop on Machine Reading for Question Answering (MRQA): . This year we are adding a new shared task focusing on generalization of MRQA systems. Also features awesome speakers. Check it out and vote for us!
2
48
141
Check it out at

Announcing the EfficientQA competition and
#NeurIPS2020
workshop, a collaborative effort with
@Princeton
and
@UW
that challenges developers to create end-to-end open-domain question answering systems that are small, yet robust. Learn all about it ↓
9
133
374
0
26
119
I am at
#NeurIPS2023
today!
Students are presenting two oral papers:
-
@danfriedman0
Transformer Programs (Oral 3B / poster 3
#1509
)
-
@SadhikaMalladi
@gaotianyu1350
Memory-efficient zerothorder optimizer MeZO (Oral 4A / poster 4
#514
)
Come find us! More from Princeton 👇

Look at the breadth of Princeton research being presented at
@NeurIPSConf
(happening now) - not just in computer science, but also from a range of other departments.
PLI blog post for details:

0
2
17
1
15
113
We are organizing the first workshop on machine reading for question answering at ACL2018! Please consider submitting your work related to question answering & reading comprehension. Deadline: April 23, 2018

Check out the CFP for MRQA 2018: Machine Reading for Question Answering @ ACL 2018
0
14
25
0
57
109
Paper:
#CoQA


People usually get information from others in a multi-turn conversation. To approach this, we’ve released CoQA 🍃—A Conversational Question Answering Challenge by
@sivareddyg
•
@danqi_chen
•
@chrmanning
. 127K Qs— free-form answers—with evidence—multi-domain.


6
216
457
2
30
95
Very excited to have Jason Weston
@jaseweston
visited Princeton and gave a guest lecture in our NLP class on conversational AI today.



2
2
79
I enjoyed the virtual conference experience of AKBC so much this time. A big shout-out to the organizers for all the hard work!
Excited to co-chair AKBC 2021 with
@JonathanBerant
. Let's hope for the best that we can meet in Irvine next year :)

Next year's conference will happen in Irvine, CA, and will be program chaired by
@danqi_chen
and
@JonathanBerant
. 5/5
0
3
12
3
7
74
Check out
@jcqln_h
's
#EMNLP2022
paper on debiasing pre-trained language models!
PS. Jacqueline is an exceptional undergraduate student at Princeton, and she is applying for PhDs :) I believe this is also my first Princeton paper with all-female authors!

Check out our
#EMNLP2022
paper! Contrastive learning + natural language inference data → effective training technique to debias language models!
Joint work w/
@xiamengzhou
, Christiane Fellbaum,
@danqi_chen
Paper:
Code:
(1/n)
1
11
53
1
8
69
I am very excited about this DensePhrases project. It was an amazing collaboration during this unusual year. Looking forward to your visit to Princeton, finally :)

Our new work on learning accurate dense phrase representations for more than 60 billion phrases in the entire Wikipedia:
+15-25% better than previous phrase retrieval models in Open QA without any sparse vectors, and you can use it as a dense KB, too!

3
40
176
0
5
66
@scottyih
and I will be presenting a tutorial on *Open-domain Question Answering* tomorrow at 3:00-6:30pm PT
#acl2020nlp
.
Tutorial slides available at
The website portal:
No pre-recorded talk. Please join our live session!!
2
14
56
Very impressed with how
@zwcolin
and the team pulled off this CharXiv project! This is definitely the project with the fanciest video I've done so far 🤣

🤨 Are Multimodal Large Language Models really as 𝐠𝐨𝐨𝐝 at 𝐜𝐡𝐚𝐫𝐭 𝐮𝐧𝐝𝐞𝐫𝐬𝐭𝐚𝐧𝐝𝐢𝐧𝐠 as existing benchmarks such as ChartQA suggest?
🚫 Our ℂ𝕙𝕒𝕣𝕏𝕚𝕧 benchmark suggests NO!
🥇Humans achieve ✨𝟖𝟎+% correctness.
🥈Sonnet 3.5 outperforms GPT-4o by 10+ points,
7
33
143
0
3
56
If you are interested in working as a PLI postdoctoral fellow starting in Fall 2024, consider applying!
Excited to announce the Princeton Language and Intelligence Postdoctoral Research Fellowship!
Candidates are encouraged to apply by the start-of-review date, Friday, December 1, 11:59 pm (EST), for full consideration.
Details:

3
13
55
1
7
53
Check out the
#EMNLP2023
papers from Princeton below 👇🏻
I am not in Singapore myself, but please come talk with our students!
Excited to share that 15 main conference/findings papers by PLI researchers are being presented at EMNLP in Singapore over the next several days!
Learn more by checking out the latest PLI Blog post: . Feel free to reach out to the authors!

0
6
15
0
1
49
@DanielKhashabi
@jhuclsp
Check out my course too :)
Lots of papers overlapped. I immediately grabbed two papers from your list haha.
2
4
48
Check out our
#emnlp2022
papers 👇🏻
I am on my way to Abu Dhabi and will be there from 7th afternoon to 11th. Happy to chat!

Princeton NLP @
#EMNLP2022
The Princeton NLP group will be represented at EMNLP 2022 by a variety of papers — here’s a thread. Come say hello!
[1/7]
1
13
41
1
0
38
Another new preprint with
@gaotianyu1350
and
@adamjfisch
on fine-tuning LMs with few samples. Check it out. Happy New Year, btw :)

Excited to share a preprint, “Making Pre-trained Language Models Better Few-shot Learners”!
GPT-3's huge LM amazingly works directly for few-shot learning. We take things further, and propose fine-tuning techniques to make smaller LMs work better too.

2
78
408
0
5
36
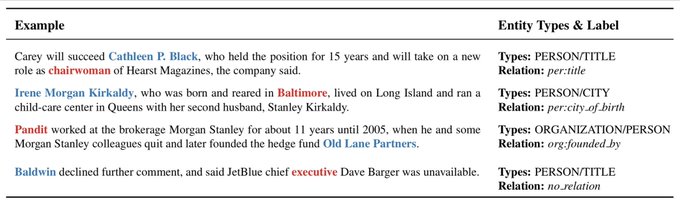
TACRED.. finally!
The TACRED dataset—person/organization relations for training relation extraction systems—is available from LDC! (At last—sorry for the delays, etc.; $25 for non-members.) See more in our papers: and
2
23
64
0
9
33
Welcome!! Super excited :)

Very excited to announce that I've finished my PhD
@Stanford
and will be joining
@Princeton
CS department as an Assistant Professor in Fall 2024. Looking forward to working with students and colleagues
@PrincetonCS
on ML & systems!

98
58
2K
1
0
33
Code and pre-computed kernels are publicly available at :)

Fine tuned LLMs can solve many NLP tasks. A priori, fine-tuning a huge LM on a few datapoints could lead to catastrophic overfitting. So why doesn’t it? Our theory + experiments (on GLUE) reveal that fine-tuning is often well-approximated as simple kernel-based learning. 1/2
5
33
238
0
4
31
Wow, this is so cool. Thanks for doing it for our paper!

I know I said 2 papers a week, but well ADHD makes you hyper focus sometimes (sometimes? who am I kidding!). So, this weekend's paper is "Can Rationalization Improve Robustness?" by
@__howardchen
, Jacqueline He,
@karthik_r_n
and
@danqi_chen
.
(1/7)


1
3
40
1
4
17
Congratulations
@tanyaagoyal
! Can't wait to see and work with you at Princeton soon 😍

I will join Cornell CS
@cs_cornell
as an assistant professor in Fall 2024 after spending a year at
@princeton_nlp
working on all things language models.
I will be posting about open positions in my lab soon but you can read about my research here:
45
27
272
1
1
19

@mark_riedl
Hope that you will find our work interesting too:
Evaluated on 15 text classification/NLI/paraphrase datasets (few-shot setting). Code here:
2
1
12
@srush_nlp
What do you think are the most convincing meta-learning results in NLP? Just curious. I was also surprised by these many meta-learning papers in ICLR.
4
0
11
Come join us today :)

We're hosting Q&A sessions about SpanBERT today at
#acl2020nlp
. Come by to chat about pre-trained span representations -- TACL paper with
@danqi_chen
@YinhanL
@dsweld
@LukeZettlemoyer
@omerlevy_
10 AM PT / 1 PM ET / 5 PM GMT
2 PM PT / 5 PM ET / 9 PM GMT
0
6
21
0
0
10
@ccb
My answer might be a bit boring. I have been always amazed by the quality of SQuAD over the last couple of years. I feel this is why SQuAD always serves as a reliable benchmark for evaluating some general techniques (e.g., pre-training).
0
0
10
@stanfordnlp
@scottyih
I need to clarify a bit on this :) I said SQuAD is not good for open-domain QA mostly because the dataset was only collected from 536 out of 5M Wiki. documents (and disjoint sets for train/dev/test) so it is difficult to learn an open retriever for this.
1
3
9
Ooops.. so many "reading" and "comprehension"


2
10
14
0
4
9

The
#AKBC
workshop at
#NIPS2017
looks amazing. Lots of interesting talks by Luna Dong
@LukeZettlemoyer
@iatitov
@riedelcastro
@sameer_
and
@tommmitchell
. Stop by for my talk if you're curious about learning hierarchical representations and how the two pics below are connected.


1
11
25
0
2
8
@YueDongCS
Thanks for your kind words :) Most work was done by
@AkariAsai
@sewon__min
@ZexuanZhong
and this part was especially led by Akari!
1
0
8

1
0
6
@cocoweixu
I agree with this. At least the meta-reviews are still public for ICLR. What can we do about *ACL conferences?
2
0
6
@tengyuma
Another idea is to ensure that there is >=1 experienced reviewer for *every* paper. I heard some ACs did this manually and I am not sure why our systems can't collect this data (e.g., grad. year, previous # of reviewing/AC). I am mostly talking about *ACL conferences though.
1
0
4
@emilymbender
Feeling the same way too. TACL matches every submission to a really good set of reviewers.
0
0
5
@sleepinyourhat
If the audience feels obligated to ask questions during these poster sessions, do you think this would even discourage them from joining these calls (given the poster sessions are already quite sparse in most cases)?
0
0
5
Work done by
@ZexuanZhong
and awesome collaboration with
@taolei15949106
.
ps. I can't attend ACL this week (because of my visa status) but Zexuan is in Dublin!
0
0
5
hahahaha...


0
0
4
@stanfordnlp
@scottyih
"Questions posed on passages" is another artifact but I suspect this violation of IID assumption issue is even bigger. It was first observed in
@kentonctlee
's ORQA paper and further confirmed in later papers.
1
1
4
@seb_ruder
Hi Sebastian! Thanks for sharing our QA tutorial and other papers :) Just wanted to quickly mention that my PhD thesis was completed in 2018, instead of 2020 - time flies :)
1
0
4
@sleepinyourhat
On the other hand, I wonder if there is a way to solve this sparse audience problem. Also, there are so many papers in a one-hour session, we just can't jump between many Zoom calls. Maybe doing more Q & A in chat will be more efficient?
2
1
4
haha.

0
0
4
@srush_nlp
Need a way to automatically extract salient words and sentences and ignore the rest :)
1
0
3
@stanfordnlp
@scottyih
@kentonctlee
A summary slide from the tutorial yesterday. I think it clearly reflects this difference (the blue block is based on TF-IDF or BM25 sparse retriever):

1
0
3
@xatkit
@stanfordnlp
@scottyih
@kentonctlee
All the slides are available at .
I believe the live video is also available at the virtual website page now:
1
0
2
0
0
0
@JayAlammar
@mandarjoshi_
@YinhanL
@dsweld
@LukeZettlemoyer
@omerlevy_
@JayAlammar
Thanks for your nice illustrations! I have always liked them so much and used them in my lectures :) Two things: 1) SpanBERT has a span boundary objective using the two endpoints to predict the masked words; 2) This paper was published in TACL and presented at ACL.
1
1
2
@kalyan_kpl
@akbc_conf
Yes, AKBC 2021 will be held in early October next year. Please see for more details.
0
0
2
@AccountForAI
@gaotianyu1350
Thanks for pointing it out. Interesting work!
We indeed missed your work, partly because it is an ICLR21 paper and not on arXiv (?). We will make sure to add a discussion in our next version.
Our Table 1 is avg. of 7 STS-tasks, not STS-B, so this is not a correct comparison :)
3
0
2
@srush_nlp
@yoavgo
- I feel that the rocket chat is quite slow (it is always loading) and not sure how that will feel after scaled up to ACL.
- I think it is important to know who else is listening too and can also chat with others without going to another (slow) tab.
1
0
2
reading the book...

All of machine learning in one page - my Wired article about the race for the master algorithm:
2
46
63
0
0
1
0
0
1

@AccountForAI
@gaotianyu1350
We certainly find your paper interesting! They are still fairly different though: 1) We use one encoder with dropout noise, instead of two independent encoders; 2) We use NLI data differently; 3) different training objectives. It is a win for contrastive objective anyway, right?
2
0
1
@AccountForAI
@gaotianyu1350
FYI. You use a different evaluation setting (in your paper, "we failed to reproduce SBERT results"). We downloaded your models yesterday and re-evaluated them, got CT: 72.05, NLI-CT: 79.39 on STS (ours are 74.54 and 81.57) with BERT-base. Can discuss in email if interested.
2
0
1
0
0
1
@aviaviavi__
@jaseweston
I don't have Jason's slides yet.
But it is not a talk series. It is our NLP course and Jason gave a guest lecture. The other lecture slides can be found at
0
2
1
0
0
1
@yoavartzi
@NeurIPSConf
Strongly agree. A very positive experience for me as an author and an SAC this time too.
0
0
1