
Mengzhou Xia
@xiamengzhou
Followers
4K
Following
2K
Media
28
Statuses
266
PhD student @princeton_nlp, MS @CarnegieMellon, Undergrad at Fudan.
Princeton, NJ
Joined May 2015
I am excited to attend #NeurIPS2024 🤩! I’ll be presenting SimPO and CharXiv, and would love to catch up and chat about:.- RLHF, reasoning, high-quality data synthesis and generally about AI!.- And. also about the academic and industry job markets!


8
16
191
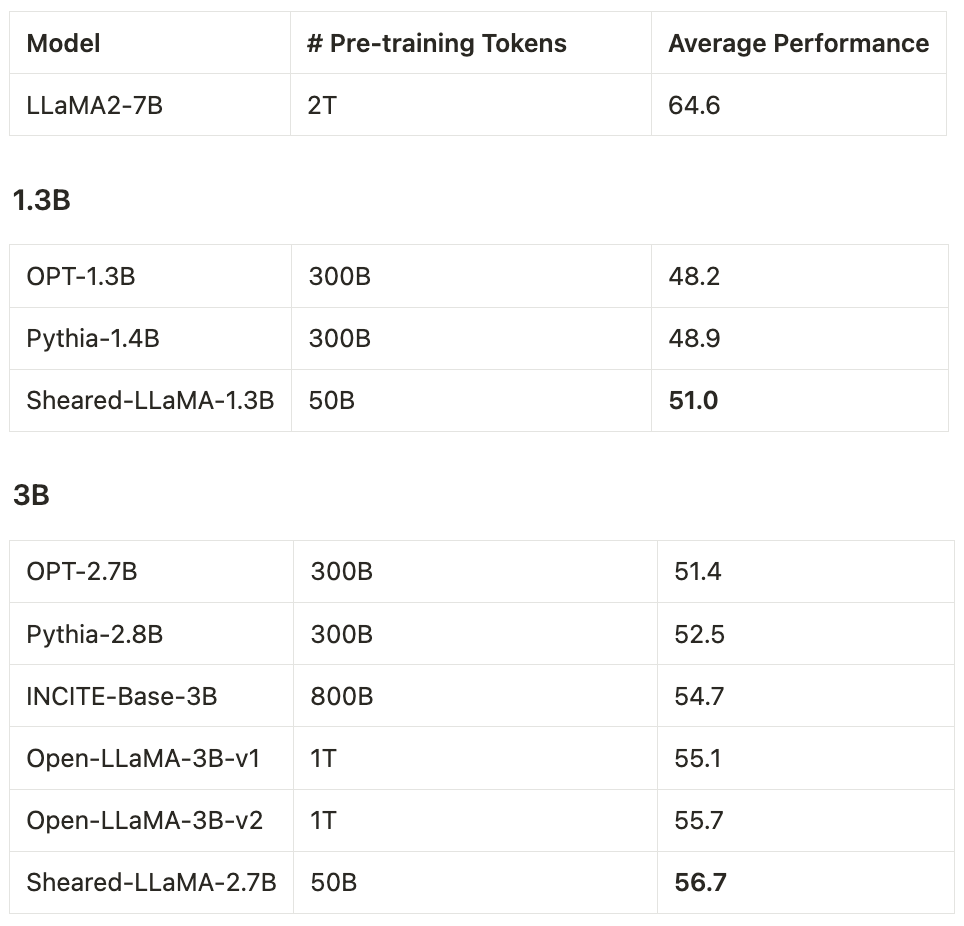
We release the strongest public 1.3B and 3B models so far – the ShearedLLaMA series. Structured pruning from a large model to a small one is far more cost-effective (only 3%!) than pre-training them from scratch!. Check out our paper and models at: [1/n]
19
139
753
Lots of instruction tuning data out there. but how to best adapt LLMs for specific queries? Don’t use ALL of the data, use LESS! 5% beats the full dataset. Can even use one small model to select data for others!. Paper: Code: [1/n]

13
97
434
How do language models of different sizes learn during the course of pre-training? . We study the training trajectories with training checkpoints of language model from 125M to 175B for a better understanding!. Check out our new paper 📜: (1/N).
11
70
397
I am honored to receive the Apple Scholars in AIML fellowship! Very grateful to my advisor, mentors and collaborators along the way :) . Excited to keep exploring the Pareto-frontier of capabilities and efficiency of foundation models!.

Congrats to @xiamengzhou on receiving an Apple Scholars in AIML fellowship! 🎉🍏. The fellowship recognizes graduate students doing innovative and cutting-edge research in machine learning. Xia is part of @princeton_nlp, advised by @danqi_chen.

16
4
207
We train and evaluate extensively with various offline preference optimization algorithms, including DPO, KTO, ORPO, RDPO, and more. Hyperparameter tuning significantly impacts algorithm effectiveness. DPO performs consistently well, but SimPO is better!.

Introducing SimPO: Simpler & more effective Preference Optimization!🎉. Significantly outperforms DPO w/o a reference model!📈. Llama-3-8B-SimPO ranked among top on leaderboards!💪.✅44.7% LC win rate on AlpacaEval 2.✅33.8% win rate on Arena-Hard. 🧵[1/n]

1
27
193
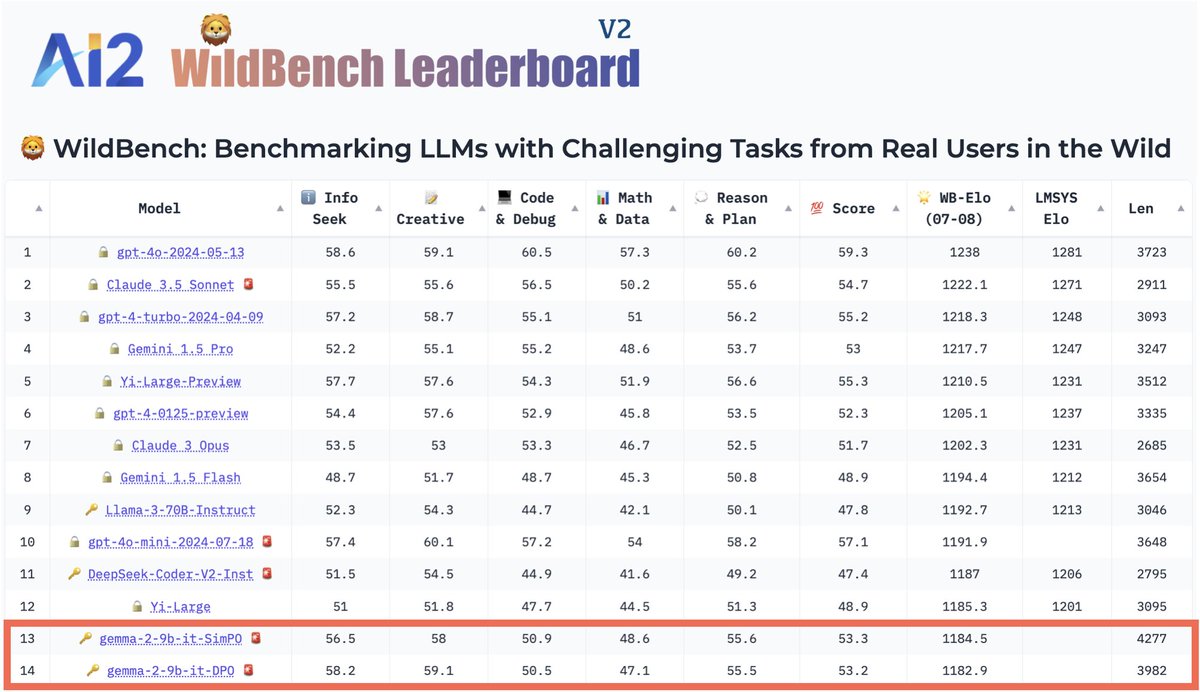
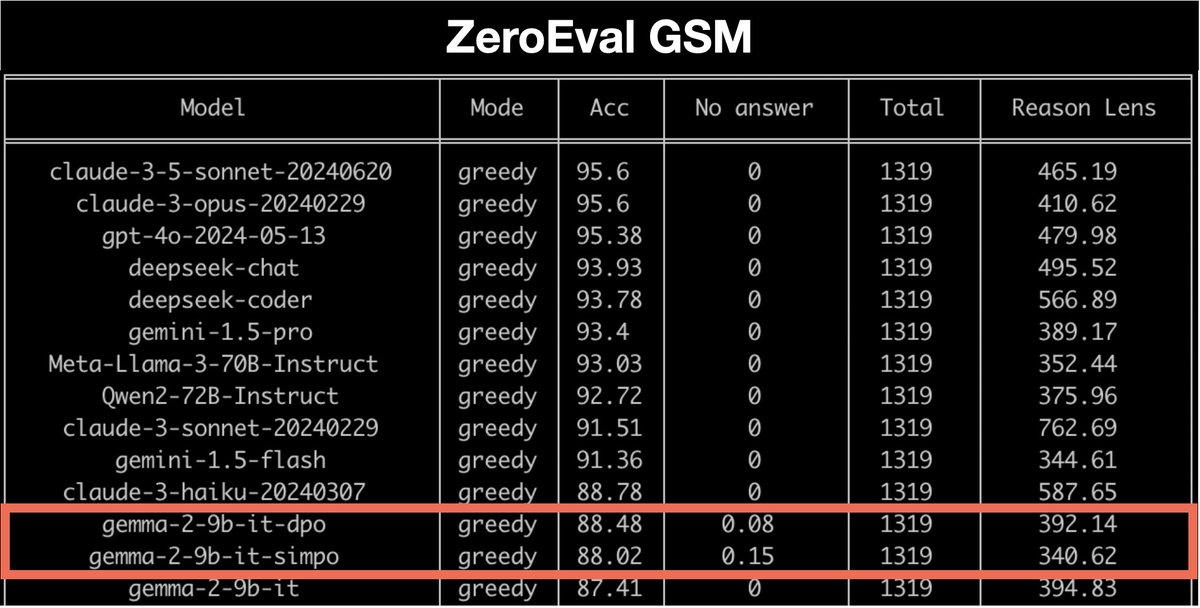
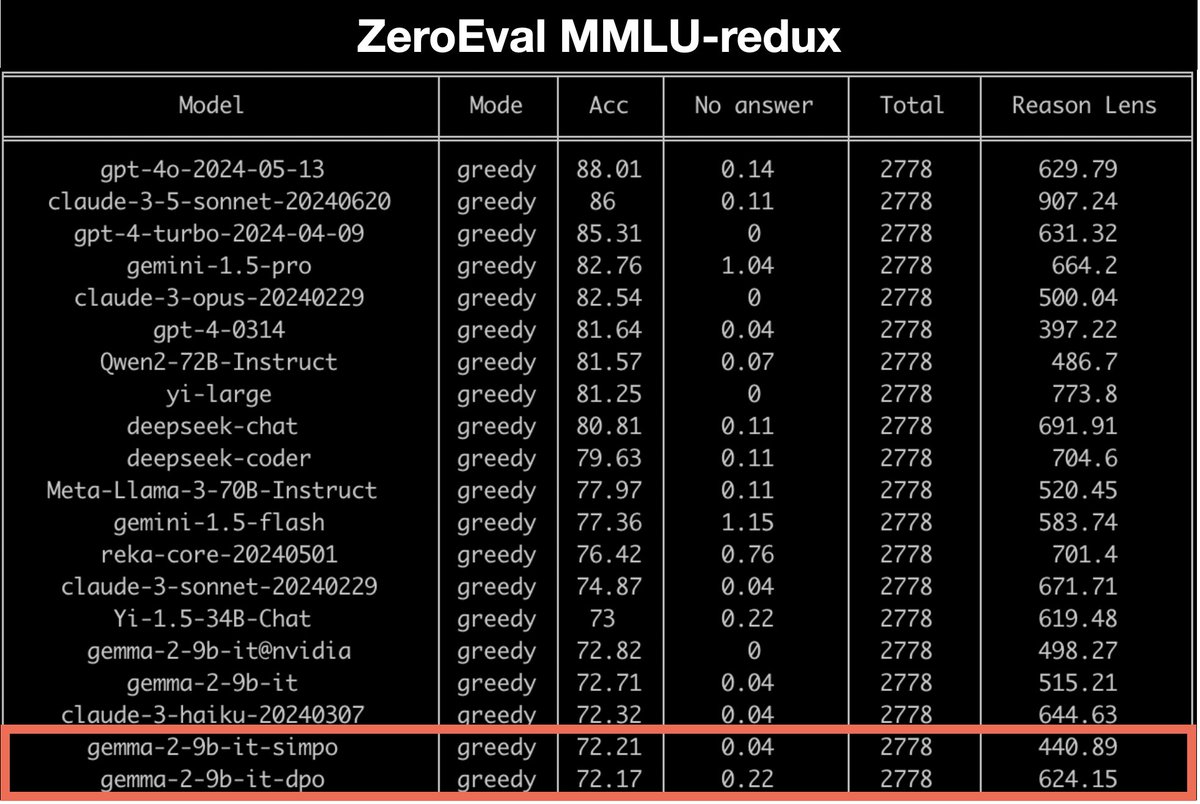
🌟 Exciting update! Gemma2-9b + SimPO ranks at the top of AlpacaEval 2 (❗LC 72.4) and leads the WildBench leaderboard among similar-sized models 🚀. SimPO is at least competitive as (and often outperforms) DPO across all benchmarks, despite its simplicity. ✨ Recipe: on-policy

8
43
178
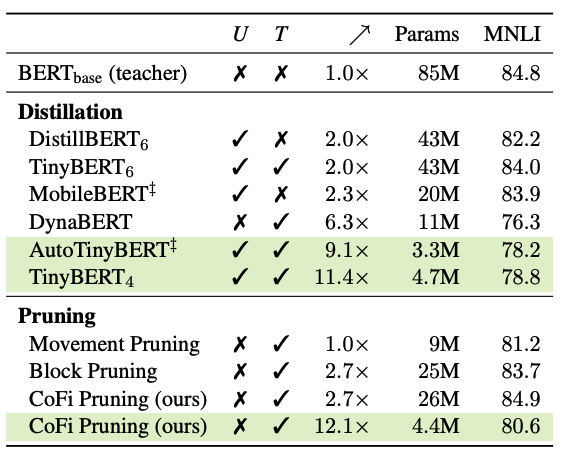
Check out our #acl2022 paper on CoFi☕️! Structured pruning is competitive compared to knowledge distillation but requires much less training time and zero unlabeled data. Joint work w/ @ZexuanZhong, @danqi_chen.Paper: Code: (1/5)
5
36
143
Check out our preprint on Prompting ELECTRA! We show that discriminative models like ELECTRA outperform generative MLMs like BERT and RoBERTa on zero-shot and few-shot prompting. Joint work w/ @artetxem, @JefferyDuu, @danqi_chen, @vesko_st.Paper:
5
21
144
🌟We release the code for training Sheared-LLaMA here at We're excited to see even stronger sheared models emerging in the future! 🤩 . For more details, check out our preprint at
We release the strongest public 1.3B and 3B models so far – the ShearedLLaMA series. Structured pruning from a large model to a small one is far more cost-effective (only 3%!) than pre-training them from scratch!. Check out our paper and models at: [1/n]
2
34
143
I'm pleased and honored to receive the fellowship and thanks to @TechAtBloomberg for supporting my research 😀.

Congratulations to @PrincetonCS + @princeton_nlp's @xiamengzhou on being named one of the 2022-2023 @Bloomberg #DataScience Ph.D. Fellows!. Learn more about her research focus and the other Fellows in our newest cohort: #AI #ML #NLProc

6
3
125
Our LLM trajectory paper got accpted to #ACL2023 😊! Code and results are at Looking forward to future work to analyze trajectories not only in pre-training but also in the more accessible yet mysterious process of instruction tuning with human feedback.
How do language models of different sizes learn during the course of pre-training? . We study the training trajectories with training checkpoints of language model from 125M to 175B for a better understanding!. Check out our new paper 📜: (1/N).
2
16
112
This is my first time attending #NeurIPS 🥳 I’d love to chat about efficient approaches for LLMs, learning dynamics/trajectories and more! DM me to grab a coffee together :).
5
2
90
Excited to release CharXiv, a new benchmark that effectively reveals multimodal language models' true capabilities in understanding charts! . Check out the fun video for a brief overview 🧵!.

🤨 Are Multimodal Large Language Models really as 𝐠𝐨𝐨𝐝 at 𝐜𝐡𝐚𝐫𝐭 𝐮𝐧𝐝𝐞𝐫𝐬𝐭𝐚𝐧𝐝𝐢𝐧𝐠 as existing benchmarks such as ChartQA suggest?. 🚫 Our ℂ𝕙𝕒𝕣𝕏𝕚𝕧 benchmark suggests NO!.🥇Humans achieve ✨𝟖𝟎+% correctness. 🥈Sonnet 3.5 outperforms GPT-4o by 10+ points,
3
10
80
More pruned models come out from @NVIDIAAI 🦙! Structured pruning provides a highly compute-efficient way to create competitive small models from larger ones without training them from scratch, and its effectiveness could be amplified when paired with the right data 🌟!.

🚀 We've pruned LLaMa3.1 down to 4B parameters, delivering a smaller and more efficient model! Based on our recent paper: 📖 Learn all about it in our blog: .🔗 META's announcement: 👐 Checkpoints at HF this

0
2
49
Sometimes users want to retrieve documents beyond semantic meanings🤔, such as searching for. - a document that presents a side argument to a question.- a math problem that employs the same underlying theorem as another problem.- a code snippet that utilizes a similar algorithm.

Retrieval benchmarks saturated? Introducing BRIGHT✨, a realistic and challenging benchmark that requires intensive reasoning to retrieve relevant documents. 🧠📚. Key features:.🔍Reasoning-intensive: Low keyword and semantic overlap between queries and documents. Intensive

0
3
47
Our Sheared-LLaMA-3B model, pruned from LLaMA2-7B model and further pre-trained for 50B tokens, outperforms the strongest open-source 3B model OpenLLaMA-v2 trained with 1T tokens. Sheared-LLaMA can further improve with more compute. [2/n]

4
5
44
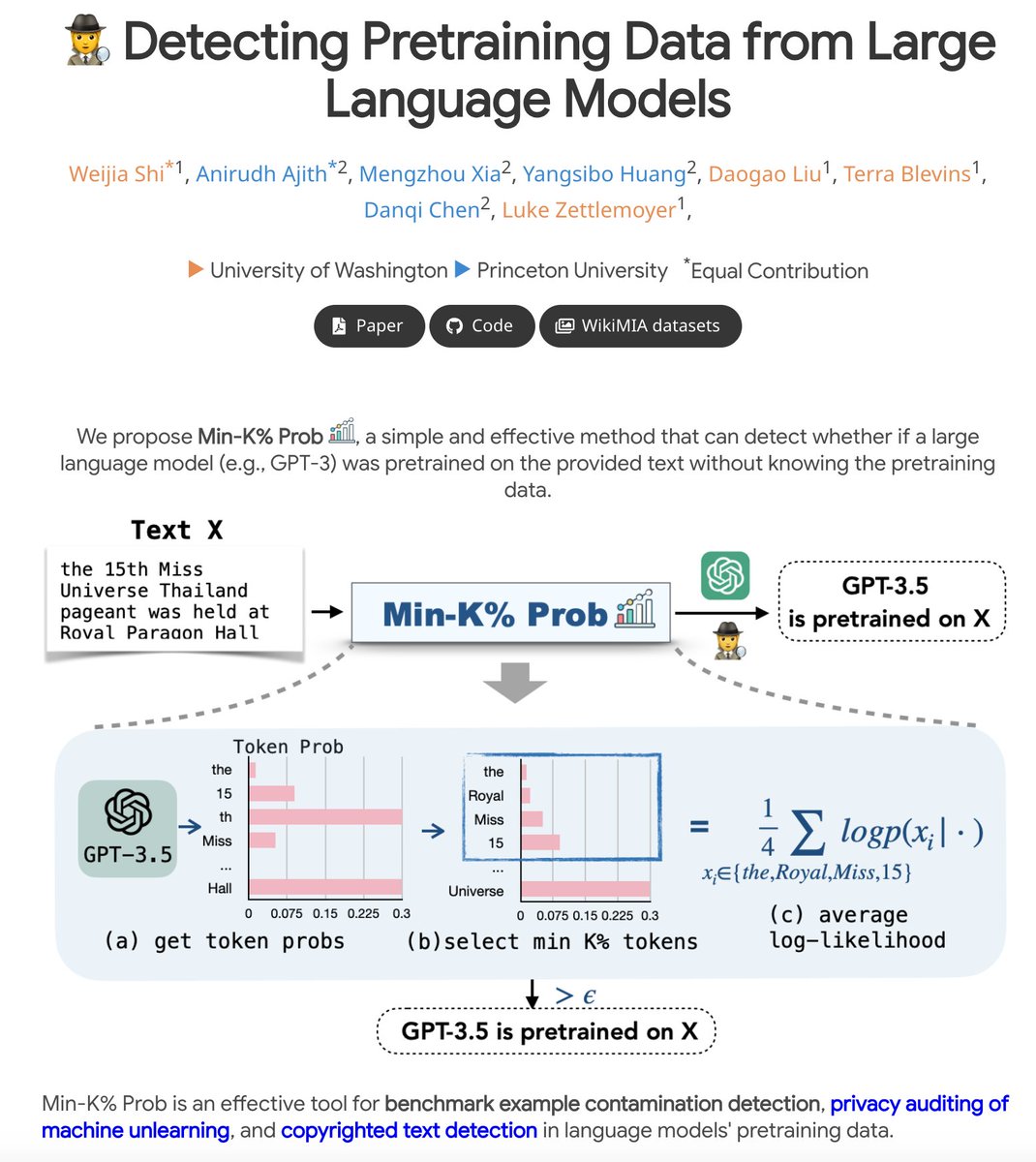
❓Ever wondered if an article or a book snippet has been pre-trained by LLMs? We develop Min-K Prob% to find out! . 📚 We show strong evidence that text-davinci-003 models have been trained on copyrighted books! . 🤗Absolutely enjoyed working together on this project!.

Ever wondered which data black-box LLMs like GPT are pretrained on? 🤔. We build a benchmark WikiMIA and develop Min-K% Prob 🕵️, a method for detecting undisclosed pretraining data from LLMs (relying solely on output probs). Check out our project: [1/n]
1
4
44
How do you pick an influential dataset for many tasks? Meet ICONS: a consensus-based method! With just 20% of visual instruction tuning data, it preserves >98% of full dataset performance—and even generalizes to unseen tasks!.

Want to train large vision-language models but drowning in data? Introducing ICONS - we demonstrate how to select only 20% of training samples while maintaining 98.6% of the performance, and 60% of training samples to achieve 102.1% of the performance.
0
5
45
Excited to see that the performant 2.7B VinaLLaMA model is pruned from its 7B counterpart! . And it was developed with the structured pruning technique used by Sheared-LLaMA! ☺️.

Today, I released my first paper, VinaLLaMA. The state-of-the-art LLM for Vietnamese, based on LLaMA-2. Continued pretrain and SFT 100% with synthetic data. Special thanks to @Teknium1 & @ldjconfirmed. Their OpenHermes and Capybara datasets helped me a lot.
0
1
32
Simply changing the generation setting (top-p, top-k, temperature) breaks the alignment of open-source safety tuned models like LLaMA2-Chat 😰.

Are open-source LLMs (e.g. LLaMA2) well aligned? We show how easy it is to exploit their generation configs for CATASTROPHIC jailbreaks ⛓️🤖⛓️.* 95% misalignment rates.* 30x faster than SOTA attacks.* insights for better alignment. Paper & code at: [1/8]

0
2
34
Fine-tuning on benign data (e.g., List 3 planets in our solar system) significantly breaks model safety 😨.

Fine-tuning on benign data (e.g. Alpaca) can jailbreak models unexpectedly. We study this problem through a data-centric perspective and find that some seemingly benign data could be more harmful than explicitly malicious data! ⚠️🚨‼️. Paper: [1/n]

0
4
31
How do we get there? Our pruning algorithm LLM-Shearing has two components:. 1) Targeted structured pruning, where we prune the source model to a specified target architecture (e.g., an existing LM) while maximizing its performance. [4/n]

3
2
27
2) Dynamic batch loading, where we dynamically load data from each domain to enable an efficient use of pre-training data. The procedure does not produce any overhead compared to standard pre-training! [5/n]

2
0
24
Strong llama-3 based long-context models made by my amazing labmates!! Carefully curated data recipes lead to consistently strong performance across the board 🤩.

Meet ProLong, a Llama-3 based long-context chat model! (64K here, 512K coming soon). ProLong uses a simple recipe (short/long pre-training data + short UltraChat, no synthetic instructions) and achieves top performance on a series of long-context tasks.

0
0
22
Analyzing training trajectories is a fascinating way to gain insights of LLMs, and thanks to the open-sourced checkpoints and data from @AiEleuther, it has become easier to explore!.

Have you ever wanted to do an experiment on LLMs and found that none of the existing model suites met your needs? At @AiEleuther we got tired of this happening and so designed a model suite that centers enabling scientific research as its primary goal.
1
0
23
It was an awesome collaboration with @gaotianyu1350 @ZhiyuanZeng_ @danqi_chen!. Stay tuned with the codebase, which is built on top of the Composer package for efficiency. We’d like to extend our sincere gratitude to the engineers @mosaicml for their help :).[n/n].
1
0
20
Our Sheared-LLaMA series also outperform existing models when instruction tuned on SharedGPT, demonstrating that pruning does not compromise the long-text generation and instruction following. [3/n]

1
1
20
Yangsibo is an absolutely awesome researcher and amazing collaborator 🤩. She works in the important field of AI safety and security. Consider hiring her!.
I am at #NeurIPS2023 now. I am also on the academic job market, and humbled to be selected as a 2023 EECS Rising Star✨. I work on ML security, privacy & data transparency. Appreciate any reposts & happy to chat in person! CV+statements: Find me at ⬇️.
0
0
19
Check out our new blog post on data selection! . Important future problems to think:.- How to select synthetic data? agent trajectory data?.- for any differentiable objective?.

Dataset choice is crucial in today's ML training pipeline. We (@xiamengzhou and I) introduce desiderata for "good" data and explain how our recent algorithm, LESS, fits into the picture. Huge review of data selection algs for pre-training and fine-tuning!.

0
1
19
Not all tokens' perplexity decreases during pre-training! We find that when 10% of the next-token predictions’ perplexity surprisingly increases for 1.3B, larger models present a double descent trend where the perplexity increases then decreases on the same set of tokens.(2/N)

1
1
18
LESS doesn’t rely on heuristics, so it doesn’t fall for superficial similarities! It identifies datapoints with the same reasoning type as the provided examples. Given a Bengali QA example: LESS selects an English QA example! (Others select Bengali examples in other tasks) [4/n]

2
0
17
Correction: We made an error in our original post - the latest StableLM-3B outperforms our ShearedLLaMA-3B on the Open LLM Leaderboard, but we were not aware of it at the time of writing. Additionally, BTLM-3B achieves similar results to ours. Thanks for pointing this out!.
1
0
18
We show interesting results in the paper about.- Comparing to further finetuning an existing LLM.- Coding and math abilities of the models.- Comparing to other pruning techniques.- Different source models to prune from.….[6/n].
1
0
17
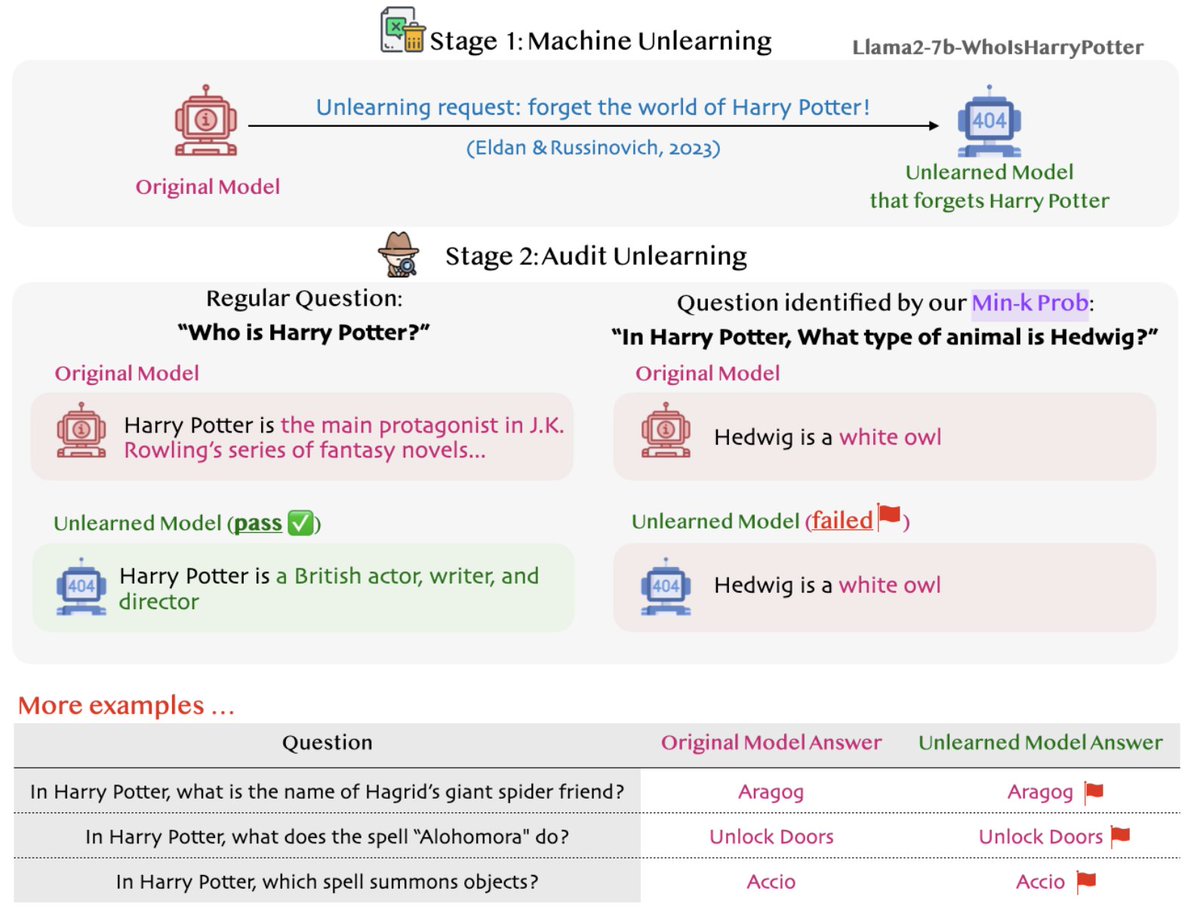
Min-K Prob% also helps to identify questions or book snippets that may have been thought to be removed by recent works but still persist within LLMs! 📚🔍.
Microsoft's recent work ( shows how LLMs can unlearn copyrighted training data via strategic finetuning: They made Llama2 unlearn Harry Potter's magical world. But our Min-K% Prob ( found some persistent “magical traces”!🔮. [1/n]
0
1
13
Congratulations to @shuyanzhxyc ! Can't wait to see what you will build next 🤩.

I am thrilled to announce that I will be joining @DukeU . @dukecompsci as an Assistant Professor in summer 2025. Super excited for the next chapter! Stay tuned for the launch of my lab 🧠🤖

1
0
13

Finally, we look at in-context learning on downstream tasks! We evaluate 74 BIG-Bench tasks on intermediate model checkpoints of up to 175B parameters, and find that validation perplexity is a better predictor of in-context learning ability than FLOPs! (5/N)

1
1
11
@jefrankle For criterion-based pruning solutions, both LLM-Pruner () and wanda ( are very easy to use. For a learning-based pruning solution, we have a repo written with an old version of composer! .
0
0
11
Joint work with my awesome collaborators @SadhikaMalladi (equal contribution) @ssgrn @prfsanjeevarora @danqi_chen at @princeton_nlp, @PrincetonPLI, and @uwnlp! [5/n].
0
0
10
4 easy and efficient steps. Crucial component: theoretically motivated influence formulation, specialized to instruction tuning with Adam. [2/n]

1
0
10
Recently @AiEleuther just released hundreds of intermediate checkpoints of language models up to 13B parameters, and we think it will be exciting to continue researching on understanding language models using these open-sourced checkpoints! (7/N).
1
0
10
@Teknium1 We weren't aware of the release of cerebras 3B or StableLM when the work was done. The field is moving too fast to catch up! But as @HanchungLee pointed out , the point of our work is to show structured pruning can be an efficient approach in producing strong small-scale LLMs.
1
0
10
We decode such texts and find them grammatically but hallucinating. They do follow an inverse scaling trend on final model checkpoints (left)! The small model (125M, Blue) and other large models’ trajectories diverge as training goes (right). (4/N)

2
0
9
The perplexity of human-generated sequences decreases as the model scale increases. Even texts with noise and factually wrong prompts still follow this scaling pattern. LMs' probability assignment is a zero-sum game; what texts do small models favor more than large ones? (3/N)

1
0
9
@srush_nlp Here are some preliminary ablations! For SimPO, a learning rate between 6e-7 and 8e-7 appears relatively safe, while DPO requires a range between 3e-7 and 5e-7. The llama3-instruct models seem more brittle, showing significant variance across different lrs.

2
1
8
@srush_nlp Hi @srush_nlp, we noticed that this issue results from training llama3-instruct with a large learning rate. When training llama3-instruct with a smaller lr, this issue could be mitigated at the cost of reducing the chat scores. But we find that gemma models present much less



1
0
7
@fe1ixxu Hi Haoran, thank you for bringing this issue to our attention! We would like to clarify that SimPO and CPO differ significantly. SimPO includes a length normalization term and a target reward margin, which are the two major designs of our objective. Ablation studies in Table 5.
0
0
7
Our experiments are mainly conducted on intermediate checkpoints of OPT models. There is much more in our paper, and please check it out for details if you are interested! 😀😀😀 (6/N).
1
0
6
SimPO (Co-led with @yumeng0818) .⌛️Fri 13 Dec 11 a.m. PST — 2 p.m. PST.📍East Exhibit Hall A-C #3410. SimPO is a simple preference optimization objective that achieves competitive performance in enhance models' chat abilities. Past post: Paper:

Introducing SimPO: Simpler & more effective Preference Optimization!🎉. Significantly outperforms DPO w/o a reference model!📈. Llama-3-8B-SimPO ranked among top on leaderboards!💪.✅44.7% LC win rate on AlpacaEval 2.✅33.8% win rate on Arena-Hard. 🧵[1/n]
1
1
6
@ocolegro We didn't compare against Phi primarily due to its reliance on non-public datasets that may have data leakage concerns.
1
0
5
Many thanks to my amazing collaborators @artetxem @violet_zct @VictoriaLinML @ramakanth1729 @danqi_chen @LukeZettlemoyer @vesko_st at @MetaAI and @princeton_nlp! (N/N).
0
0
5
We propose CoFi ☕️ (Coarse- and Fine-grained) pruning to prune heads, intermediate dimensions, hidden dimensions, multi-head attention layers and feed-forward layers all together! We also propose a dynamic layer distillation loss to further guide the pruning process. (2/5)

1
0
5
Analysis shows that MLMs like RoBERTa could assign comparable probabilities to antonyms like terrible and great, which in turn feeds the ideal negatives to ELECTRA for contrastive training. (4/4)

1
0
5
@Teknium1 @HanchungLee We added a correction post, thanks for bringing this to our attention!.
1
0
5
@_joaogui1 I think we are explaining from a development point of view, where if there exists strong large models, the more cost efficient way to build small LMs is by pruning and continue pre-training.
0
0
4
ELECTRA is pre-trained to discriminate if tokens are original or replaced. We adapt this objective to do template-based prompting. The higher the probability of the token to be original, the more likely it is the right answer. (1/4)

1
0
3
@SebastienBubeck @ocolegro Thanks for the reply and sorry about the inaccurate expression in the original thread. We meant to compare to models trained on public web data. Training on high quality synthetic data is orthogonal to our approach. We believe combining both can lead to stronger smaller models :).
0
0
3

0
0
3
@natolambert Thanks for sharing the insights! What would you suggest is the best way to check model abilities at this point?.
1
0
3
@LChoshen @srush_nlp @sebschu @boazbaraktcs @artetxem @LukeZettlemoyer @vesko_st I recently worked on a project to prune a Llama2-7b model to 1.3B and 2.7B and also have intermediate checkpoints of those pruned models during the continued pre-training stage. I would like to share them with you if you think they could be helpful.
1
0
3
With the base sized model, ELECTRA outperforms BERT and RoBERTa by 7.9 and 3.5 points on zero-shot prediction and 10.2 and 3.1 points on few-shot prompt-based fine-tuning (√ denotes with prompt). The margin on standard finetuning is 3.3 and 1.2 points. (2/4)

1
0
3
In particular, CoFi closes the gap between structured pruning and knowledge distillation with much less computation and only task-specific data. (4/5)

1
0
2
We also extend the framework to tasks with multi-token options by aggregating either the representations or the output probabilities and find that ELECTRA outperforms RoBERTa as well. (3/4)


1
0
2
CoFi outperforms a series of distillation and pruning baselines when comparing under the same speedup ratio or model size, especially on the high-sparsity regime! (3/5)

1
0
2
We find that for highly compressed models, the middle layers are more likely to be pruned but the first and last few layers are largely retained. (5/5)

0
0
2
@taolei15949106 @gaotianyu1350 We didn’t try other objectives, as the min-max objective is surprisingly robust and leads to good results. Would be nice to see if other objectives could possibly be more compute/data efficient for pruning!.
0
0
1
@BlancheMinerva @AiEleuther The entire code base is unfortunately not compatible with HF transformers. But I can help sort out the key model-free functions!.
0
0
1
0
0
1
@BlancheMinerva Thanks for your interest in our new work :) We greatly appreciate Pythia's openness in data transparency, model sharing, and checkpoint accessibility. And we will make sure to include discussions around it in our next revision!.
0
0
1
@taiwei_shi Actually, AlpaGusus and LESS operate in different settings (blog coming soon!). We study a transfer setting, whereas AlpaGasus (and KNN-based methods) can access ample in-domain data and resemble quality filtering for coreset selection.
0
0
1
@yuntiandeng @srush_nlp @UWCheritonCS @VectorInst @allen_ai @YejinChoinka @pmphlt Congrats Yuntian!!!! 🎉🎉🎉.
1
0
1
@AlbalakAlon We use a held out validation set of 2M tokens per domain, and RP has 7 domains, and it amounts to a total of 14M tokens. When continuing pretraining the pruned 3B model on 16 GPUs, validation only takes around 1% of the wall clock time. Each time it takes ~0.9min.
1
0
1
@taiwei_shi Our experiments show instruction tuning boosts performance on MMLU and BBH. Also, LESS is easy to adapt to new tasks, so we will try others in the future!.
0
0
1