

Tim Dettmers
@Tim_Dettmers
Followers
35K
Following
4K
Media
132
Statuses
3K
Creator of bitsandbytes.Research Scientist @allen_ai and incoming professor @CarnegieMellon. I blog about deep learning and PhD life at https://t.co/Y78KDJJFE7.
Seattle, WA
Joined October 2012
After 7 months on the job market, I am happy to announce:.- I joined @allen_ai.- Professor at @CarnegieMellon from Fall 2025.- New bitsandbytes maintainer @Titus_vK. My main focus will be to strengthen open-source for real-world problems and bring the best AI to laptops 🧵.
155
86
2K
QLoRA: 4-bit finetuning of LLMs is here! With it comes Guanaco, a chatbot on a single GPU, achieving 99% ChatGPT performance on the Vicuna benchmark:. Paper: Code+Demo: Samples: Colab:

89
930
4K
This is the most important paper in a long time . It shows with strong evidence we are reaching the limits of quantization. The paper says this: the more tokens you train on, the more precision you need. This has broad implications for the entire field and the future of GPUs🧵


[1/7] New paper alert! Heard about the BitNet hype or that Llama-3 is harder to quantize? Our new work studies both! We formulate scaling laws for precision, across both pre and post-training TLDR;. - Models become harder to post-train quantize as they

66
491
3K
I am excited to share my latest work: 8-bit optimizers – a replacement for regular optimizers. Faster 🚀, 75% less memory 🪶, same performance📈, no hyperparam tuning needed 🔢. 🧵/n. Paper: Library: Video:

18
279
1K
@karpathy Super excited to push this even further:.- Next week: bitsandbytes 4-bit closed beta that allows you to finetune 30B/65B LLaMA models on a single 24/48 GB GPU (no degradation vs full fine-tuning in 16-bit).- Two weeks: Full release of code, paper, and a collection of 65B models.
39
191
1K
We present SpQR, which allows lossless LLM inference at 4.75 bits with a 15% speedup. You can run a 33B LLM on a single 24GB GPU fully lossless. SpQR works by isolating sensitive weights with higher precision and roughly doubles improvements from GPTQ: �

36
297
1K
We release LLM.int8(), the first 8-bit inference method that saves 2x memory and does not degrade performance for 175B models by exploiting emergent properties. Read More:. Paper: Software: Emergence:

17
249
1K
How can you successfully train transformers on small datasets like PTB and WikiText-2? Are LSTMs better on small datasets? I ran 339 experiments worth 568 GPU hours and came up with some answers. I do not have time to write a blog post, so here a twitter thread instead. 1/n.
15
307
1K
Reading the report, this is such clean engineering under resource constraints. The DeepSeek team directly engineered solutions to known problems under hardware constraints. All of this looks so elegant -- no fancy "academic" solutions, just pure, solid engineering. Respect 👏.

🚀 Introducing DeepSeek-V3!. Biggest leap forward yet:.⚡ 60 tokens/second (3x faster than V2!).💪 Enhanced capabilities.🛠 API compatibility intact.🌍 Fully open-source models & papers. 🐋 1/n

19
107
974
We release the public beta for bnb-int8🟪 for all @huggingface 🤗models, which allows for Int8 inference without performance degradation up to scales of 176B params 📈. You can run OPT-175B/BLOOM-176B easily on a single machine 🖥️. You can try it here: 1/n

27
222
911
Updated GPU recommendations for the new Ampere RTX 30 series are live! Performance benchmarks, architecture details, Q&A of frequently asked questions, and detailed explanations of how GPUs and Tensor Cores work for those that want to learn more:

31
247
880
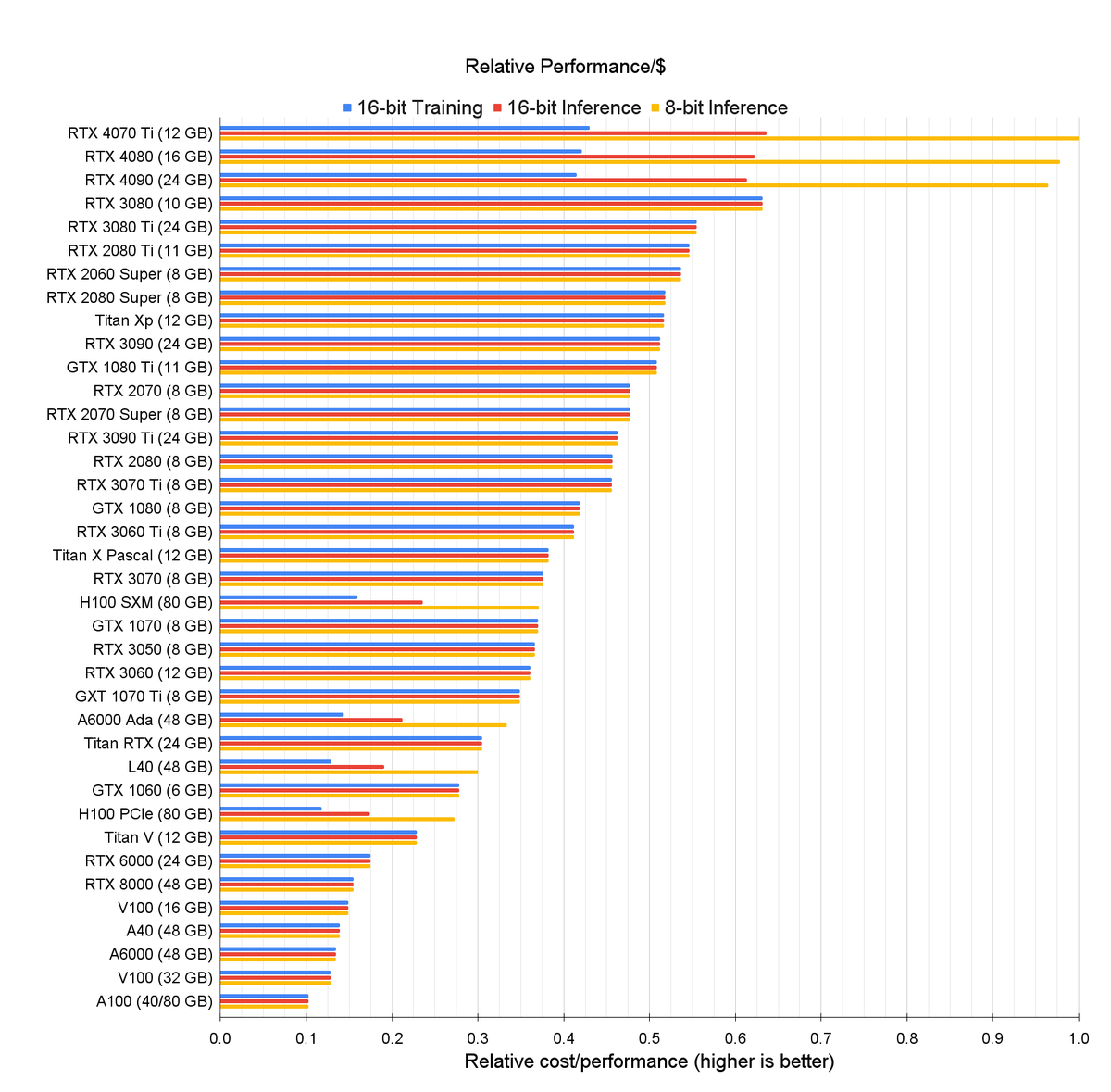
In the RTX 40 post, I introduce a GPU recommendation chart and discuss the new Tensor Memory Accelerator (TMA) and FP8 computation. Overall, RTX 40s are faster for inference and shine through their FP8 performance but are inefficient for 16-bit training.
38
168
871
The 4-bit bitsandbytes private beta is here! Our method, QLoRA, is integrated with the HF stack and supports all models. You can finetune a 65B model on a single 48 GB GPU. This beta will help us catch bugs and issues before our full release. Sign up:.
25
152
847
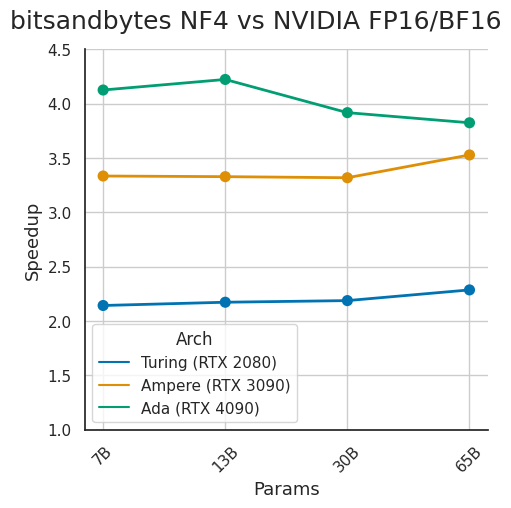
The result of long days of CUDA optimizations: the new bitsandbytes release includes 4-bit inference, which is up to 4.2x faster than 16-bit inference (bsz=1). Full HF integration for all models. No code change needed. Bnb is growing rapidly, just shy of 1M installs/month🧵
24
144
851
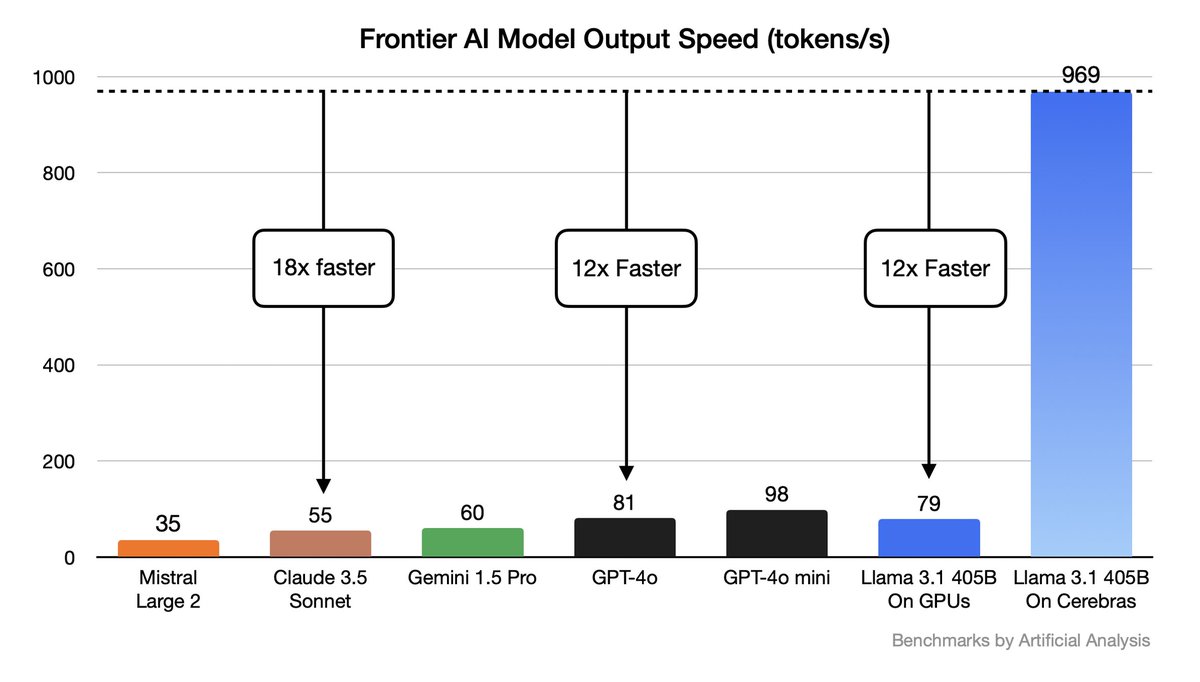
Just to clarify this benchmark. This is an apple to oranges comparison. - Cerebras is fast for batch size 1 but slow for batch size n. - GPUs are slow for batch size 1 but fast for batch size n. I get >800 tok/s on 8x H100 for a 405B model for batch size=n. Cerebras' system.

Llama 3.1 405B is now running on Cerebras!.– 969 tokens/s, frontier AI now runs at instant speed.– 12x faster than GPT-4o, 18x Claude, 12x fastest GPU cloud.– 128K context length, 16-bit weights.– Industry’s fastest time-to-first token @ 240ms
28
84
829
Finished RTX 4090 modeling . not good 😐. If you have an RTX 3090, probably best to wait 4 years for chiplets and consumer HBM. This is what dead Moore's law looks like. You can only scale cost/perf with features, but you can only add Tensor Cores once. We are stuck. More soon!.
26
55
699
Just a reminder that the default hyperparameters of LoRA are performing poorly. You need to attach LoRA modules to all layers for it to perform as well as full fine-tuning. Once you do that, we find there is no difference between LoRA and fine-tuning.

LoRA is not a drop-in replacement for Full Finetuning. Even though it reduces the compute requirements by 3x it comes with certain limitations. The data preparation needed for both is also different. 🔑. - LoRA requires much more data to converge compared to full FT. This can be

17
110
661
I got excited about a paper, implement stuff and then see they cheated: (1) Copy baseline results from other paper, (2) do much more hyperparam tuning on their own method, (3) accepted to EMNLP. Results look good, but their method is crap! Why waste people's time like this?.
39
38
612
I just updated my full deep learning hardware for the latest recommendations and advice. I reframed the blog post to help you avoid the most costly mistakes when you are building a deep learning machine.
11
156
504
This is actually a great argument for using MoEs. When I think about MoEs, I think about the cerebellum and its relationship to the rest of the brains. Here is my intuition: The human brain has ~20% "recurrent" neurons (cerebrum) and ~80% MoE-style forward neurons (cerebellum).

MoEs increase parameter count but not FLOPs. Do they offer "free lunch", improving performance without paying in compute?. Our answer: for memorization, MoEs give performance gains "for free", but have limited benefit for reasoning!. Arxiv: 🦜🦜🦜

20
77
521
Open-source models beating closed models will become more and more common. Scaling has diminishing returns. The best solution will not have the largest scale but best approach or data. Especially with test-time compute, you do not need the best model to have the best solution.

Meet Molmo: a family of open, state-of-the-art multimodal AI models. Our best model outperforms proprietary systems, using 1000x less data. Molmo doesn't just understand multimodal data—it acts on it, enabling rich interactions in both the physical and virtual worlds. Try it
11
80
504
The new bitsandbytes is here:. ~15% faster 4-bit.~70% faster 8-bit inference.8-bit support for H100s. Great engineering from @mattkdouglas. bitsandbytes now receives about 100,000 installations daily. A little history on 8-bit implementations in bnb 🧵

7
70
487
I am curious why people are not talking more about the OpenAI scaling law papers. For me, they seem very significant. What I heard so far: "Too complicated. I don't understand and I don't care", "NLP is not physics". Other criticism? Any insights why people ignore it?.
22
68
450
New GPUs have arrived, and they come with GDDR6X! You can expect a ~45% speed increase with the RTX 3090 vs RTX 2080 Ti. 3-slot-width is a problem though as is the fan-design. 4x RTX 2080 Ti >> 2x RTX 3090. 24GB mem is great, but RTX 3080 with 10GB is not very useful.
20
38
422
Our work on loss spikes and stable 8-bit CLIP training is the largest Int8 training to date (1B). We introduce the SwitchBack layers and StableAdamW to ensure stability at these scales. Work with the awesome @Mitchnw. Paper: Colab:

4
97
427
I use Qwen models in my work. They are very high-quality and they have an extended hierarchy making it very easy to study scaling-behavior in detail. Qwen 2.5 is awesome!.

Qwen and DeepSeek don't get nearly as much applause and attention as they deserve.
5
26
426
I just updated my GPU recommendation blog post! I included the RTX Titan and GTX 1660 Ti in my analysis. The analysis now separates word RNNs from char RNNs/Transformers. I also recommend TPUs for larger transformers/CNNs. This and more in the update:
6
124
421
Just as a warning: I tried all of these, and all of these worked . at the small scale. When scaled up, none of these worked for me (except padding embeddings -- but what you should really do is optimize the layout to align with memory tiles). That being said, I do not want to.

New NanoGPT training speed record: 3.28 Fineweb validation loss in 15.2 minutes. Previous record: 22.3 minutes.Changelog:.- pad embedding to nearest 64.- switch from GELU to ReLU².- zero-init projection layers.- QKNorm. All four changes driven by @Grad62304977.1/8


21
32
414
I am very confused by Claude 3.6. It is more convincing than 3.5, but it has more subtle but very consequential hallucinations. This got to a point where I no longer "trust" the model. In my workflow I now have an extra step to debug its own outputs. How is your experience?.
56
12
406
Out of nowhere: far better translator than Google. Begs the question: Can Google be overtaken in search too? #dlearn
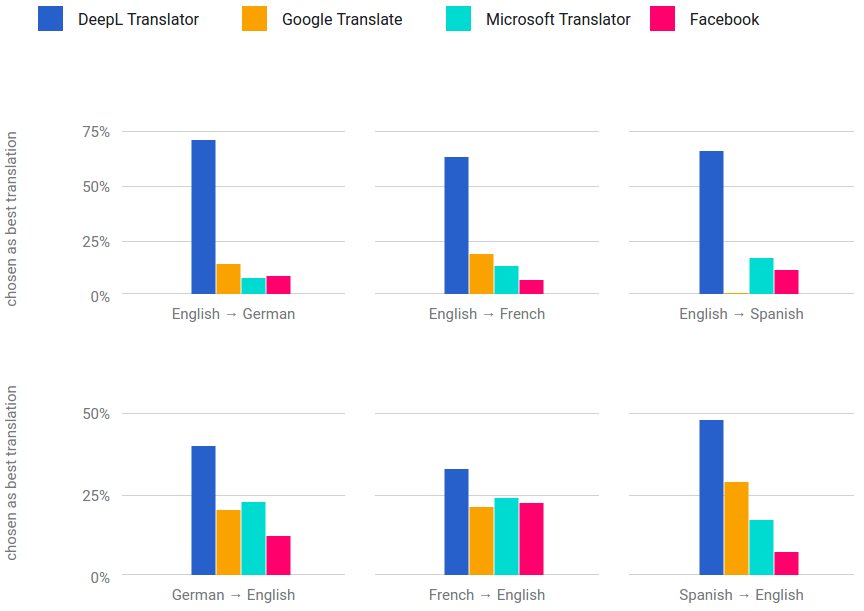
17
220
368
Surprisingly many details here (for OpenAi-level secrecy) of how they build the model.
12
23
394
Looking at the comments, some people missed the Guanaco-33B demo because it was added later: Big thanks to @huggingface for sponsoring this demo!. The second thing I noticed was that people were a bit lost on how to use the adapters. So here a tutorial🧵.
QLoRA: 4-bit finetuning of LLMs is here! With it comes Guanaco, a chatbot on a single GPU, achieving 99% ChatGPT performance on the Vicuna benchmark:. Paper: Code+Demo: Samples: Colab:
11
73
383
This is the main driving assumption of my research and it is still holding up after 10 years: Humans are not special, scale is. The other main fact (sparsity): Humans are not special, but primates are. Only primates and birds have neurons not proportional to their body size.

People claimed the human brain was special relative to other primates in the size of the temporal lobes, involved in functions such as language. Newer data once again shows that no, the human brain is just a scaled up primate brain

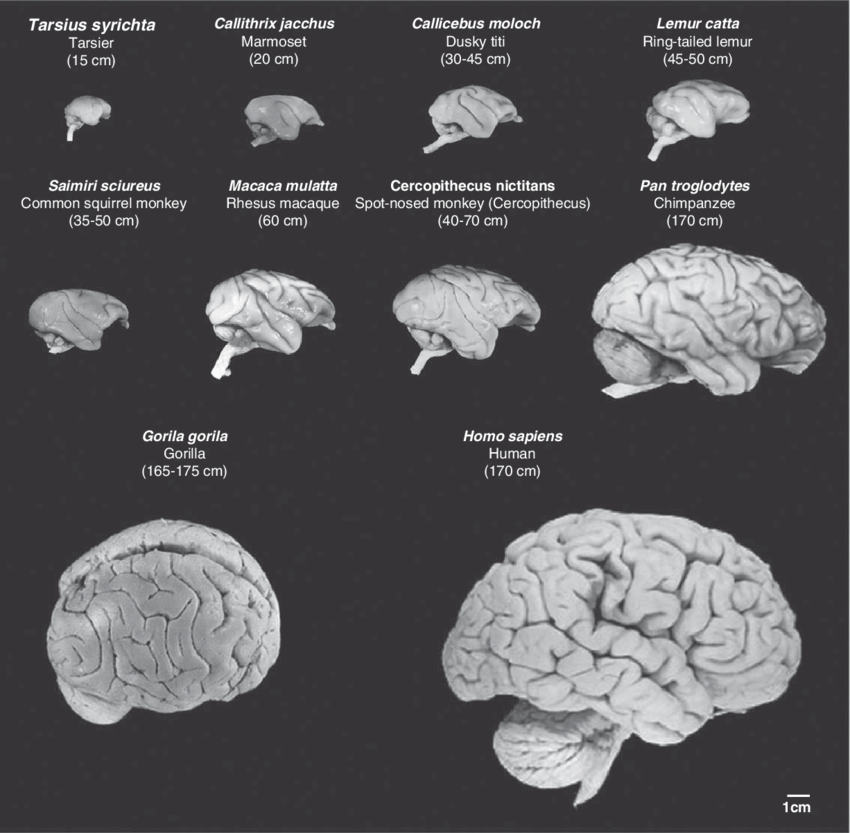
14
42
375
Turns out a lot of open-domain QA datasets have test set leakage. If you control for it, model performance drops by a mean absolute of 63%. Yikes! If we missed this for such a long time, I wonder if there are problems with other NLP datasets too.
4
97
369
@karpathy I have also seen this before. I think it's the psychology of material coming all at once that can be overwhelming for newcomers. If one builds up things bit-by-bit there not this overwhelming feeling of "this is too much; I am not good enough to learn this".
6
6
356
We ran +35,000 zero-shot experiments for our work on k-bit Inference Scaling Laws📈. A 30B 8-bit and 60B 4-bit LLM have the same model bits/inference latency, but different zero-shot accuracy. What is the best trade-off? The answer is clear: 4-bit is best.

6
66
344
A friend asked me for a reference for why we did not increase the frequency further in CPUs and why parallelism was necessary to increase performance. This puts it quite bluntly (from .

3
65
334
Just finished the final update for the RTX 40 GPU blog post:.- Performance/$ now includes Total Cost of Ownership in cost estimate (computer + 5y electricity).- Discussion Async copy vs. TMA.- Small update on FP8 training.- Font and figure improvements.
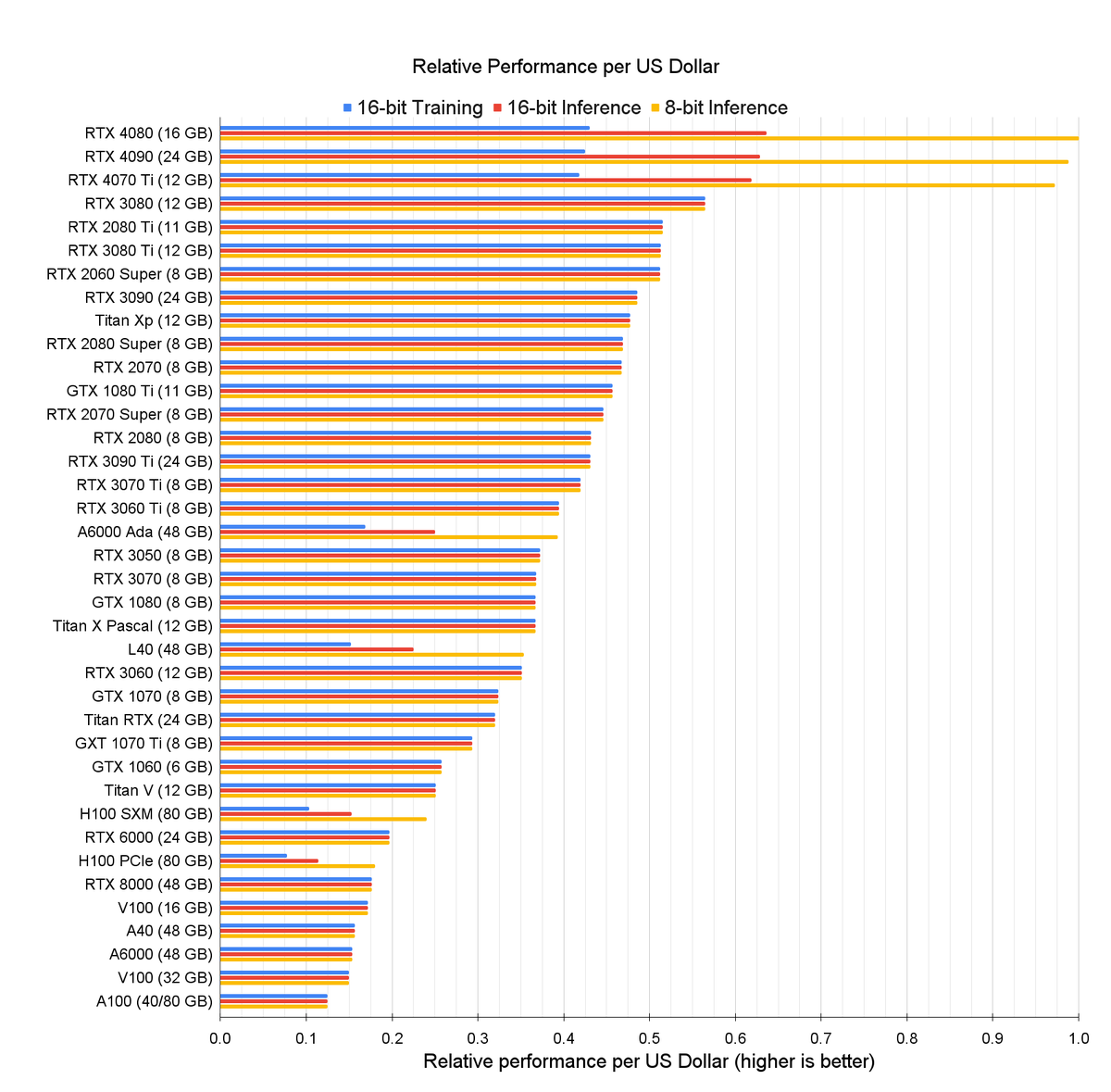
12
57
336
This is excellent work — a big step forward in quantization! It enables full 4-bit matmuls, which can speed up large batch inference by a lot. Anyone deploying LLMs at scale will soon use this or similar techniques.

[1/7] Happy to release 🥕QuaRot, a post-training quantization scheme that enables 4-bit inference of LLMs by removing the outlier features. With @akmohtashami_a @max_croci @DAlistarh @thoefler @jameshensman and others. Paper: Code:

5
56
335
This model can automatically debug CUDA version errors. AGI achieved ✅😂.

5
26
335
This work presents strong and rigorous evidence that we should abandon RNNs and move on to using convolutions for sequence modeling. I also made similar experiences in other domains such as graph embeddings and knowledge compression. Definitely an important read!.
7
77
320
The latest release of bitsandbytes has an improved CUDA setup and A100 4-bit inference. I thought that A40 and A100 GPUs were close enough, and optimized for A40s, but they are very different. A100 performance is now 40% faster with a small hit for other GPUs.
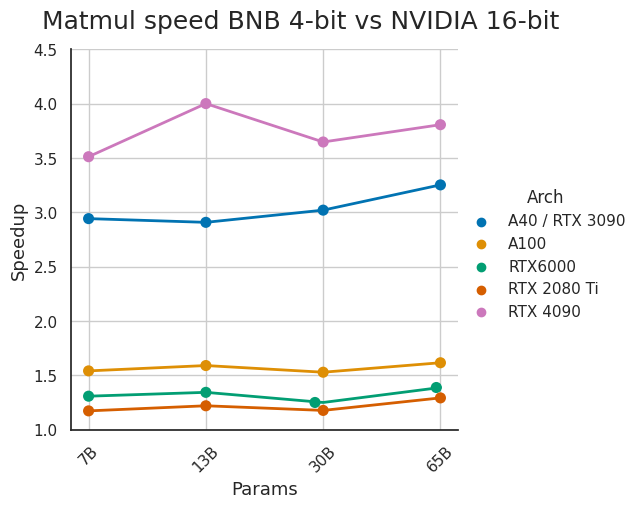
9
53
318
I updated my guide with new GPU recommendations: RTX 2080 most cost-efficient choice. GTX 1080/1070 (+Ti) cards remain very good choices, especially as prices drop. Some discussion on TPUs/AWS — can be good in some cases.

9
123
321
I am very excited to be selected as one of the #AI2050 Early Career Fellows! .My research is shifting, and my main focus will be on building open-source AI agents that use dynamic computation to enable powerful AI systems on consumer devices. I am hiring PhD students at CMU!.

We're thrilled to welcome the 2024 cohort of AI2050 Senior and Early Career Fellows –– 25 visionary researchers tackling AI's toughest challenges to ensure it serves humanity for the better. Learn more about this year’s cohort of fellows:.

34
58
320
Did some optimizations for Ada/Ampere/Turing for 4-bit inference (bsz=1, arbitrary datatype e.g. NF4). It is now 3.71x, 3.13x, and 1.72x speedup vs 16-bit. The expected max would be 3.55x if NVIDIA kernels were 100% efficient. Will be released on Monday (no code change needed).
9
34
309
All of this means that the paradigm will soon shift from scaling to "what can we do with what we have". I think the paradigm of "how do we help people be more productive with AI" is the best mindset forward. This mindset is about processes and people rather than technology.
14
31
306
Continued pretraining with QLoRA is just around the corner! A second pretraining of models like Falcon-40B in 4-bit would be super-efficient.

Parameter-efficient fine-tuning revolutionized the accessibility of LLM fine-tuning, but can they also revolutionize pre-training? We present ReLoRA — the first PEFT method that can be used for training from scratch! 🔥🔥.

9
41
302
I never had time to do the proper bitsandbytes 4-bit release. The 0.39 release includes the 4-bit quantization variants and CUDA kernels, paged optimizers, Lion, as well as an important bugfix for a memory leak in 8-bit training/inference .
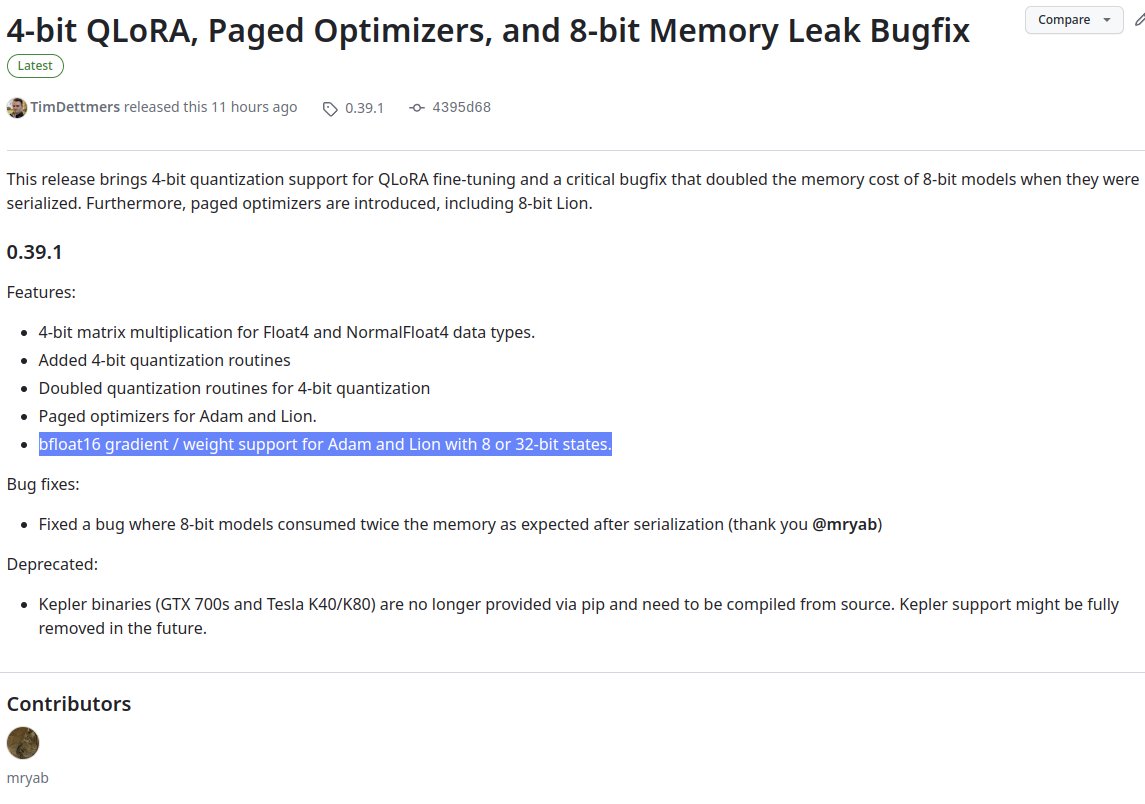
7
32
292
@typedfemale Yes, it is a big problem. I really want to create a class for machine learning systems that also has an emphasis on CUDA programming for deep learning. So many people were interested in this. I will probably get on this once I finish the faculty application process.
7
7
298
Today, I will give a talk about "The making of QLoRA" at the LLM Efficiency Challenge at 2:30pm, Room 356. I will also talk a bit about how I go about doing research, running experiments and figuring out "what works".
13
24
295
A major bug in 8-bit optimizers that could cause some instabilities later in training has been fixed. Please update bitsandbytes to 0.41.1 via `pip install -U bitsandbytes`. Now 8-bit optimizer should again reproduce 32-bit optimizer performance.
12
46
286
I have been working on 8-bit optimizers, and I am looking for testers for the initial release to test installation and ease of use. Uses up to 63% less GPU memory, faster/stabler training while maintaining performance. Currently, 8-bit Adam and 8-bit Momentum are supported. 1/5

3
52
278
My new work with @LukeZettlemoyer on accelerated training of sparse networks from random weights to dense performance levels — no retraining required!.Paper: Blog post: Code:
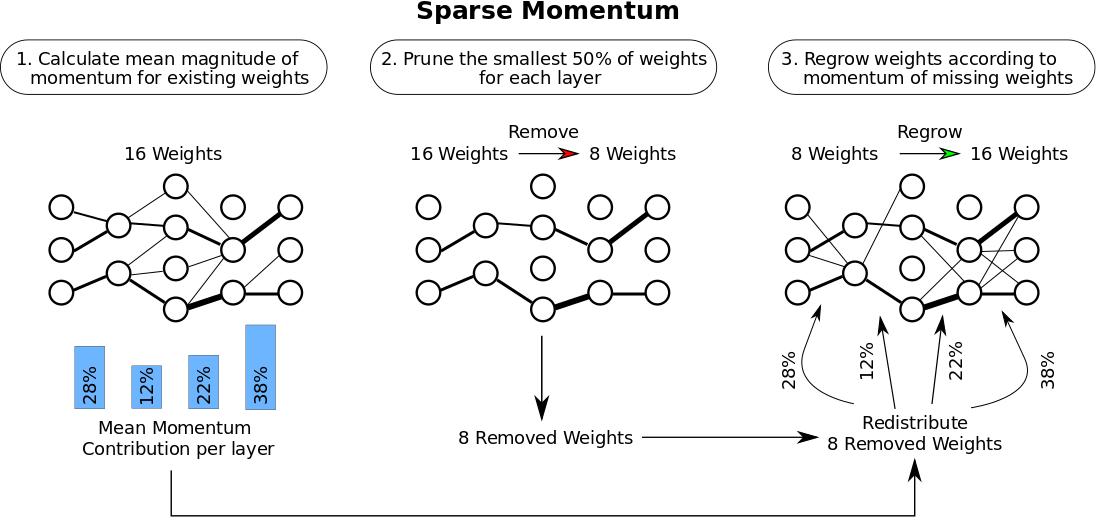
2
81
271
Bitsandbytes now supports 4-bit store/load of any model. Load in 4-bit via:. from_pretrained(name, . , load_in_4bit=True, device_map='auto'). Then save/push the model to the hub. Get the newest bnb: pip install -U bitsandbytes. Implemented by Ruslan Svirschevski (gh: poedator).
4
37
271
We now have Int8 backprop support for all GPUs for bitsandbytes! Now available via 'pip install bitsandbytes'. This was a contribution from @sasha_borzunov. We will release Int8 fine-tuning for all @huggingface models soon — stay tuned!.
5
40
267
The GPU blog post update is 90% done now. I think tomorrow morning, we will have an update! 🚀.
7
5
257
@HamelHusain If you wait for another two weeks, we have something nice for you ;) With the right methods you can fine-tune a 30B model on that GPU. A 30B policy with 30B value function also works for RLHF.
16
14
246
@willie_agnew Literally curing cancer. I talked to a biologist who used my methods in conjunction with open models to develop new methods for drug discovery. They developed drugs for previously incurable pediatric cancers. These are real wet lab in vitro results — it just works.
14
12
241
The 0.42.0 bitsandbytes release adds 4-bit serialization, so you can save/load 4-bit weights directly. Otherwise, there are lots of bug fixes. Thank you, contributors! . The next goal is Apple/AMD/Intel and Windows integration. We now have 1.5M installs per month.
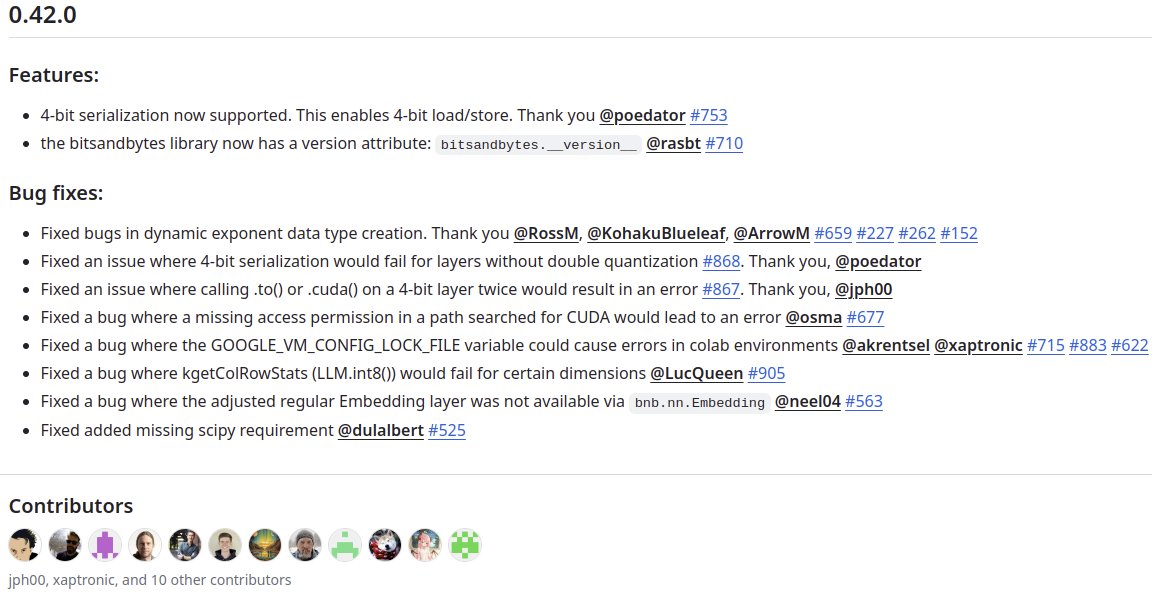
10
34
245
An excellent end-to-end guide for finetuning. It has all the details from data prep to deployment. If you want to finetune, this is a great resource to get started.

What's the best way to fine-tune open LLMs in 2024? Look no further! 👀 I am excited to share “How to Fine-Tune LLMs in 2024 with Hugging Face” using the latest research techniques, including Flash Attention, Q-LoRA, @OpenAI dataset formats (messages), ChatML, Packing, all built.
3
45
241
This is really great work! For layer 5 pyramidal neurons: A dendritic branch = MLP with 1 layer, 4 units; the entire neuron = MLP with 7 layers, 128 units each. One bio neuron > most MNIST models. We have about 85bn neurons in total and >1tn dendrites — that is a lot of compute!.

A story of a Cortical Neuron as a Deep Artificial Neural Net:. 1) Neurons in the brain are bombarded with massive synaptic input distributed across a large tree like structure - its dendritic tree. During this bombardment, the tree goes wild. preprint:
6
63
233
I updated my GPU advice blog post with the GTX 1080 Ti; also cleaned it so it is easier to find relevant information
2
98
233
(1) Scaling data centers: This still scales for ~2 years. (2) Scaling through dynamics: Route to smaller specialized models or larger/smaller models. (3) Knowledge distillation: I believe distillation behaves differently than other techniques and might have different properties.
13
20
240
I am a huge fan of einsum notation. Here is a multi-layer transformer in a couple lines of code (without norms though). I think it's simple to read, but whenever I show this to somebody in excitement they do not like it. I am curious: How is that for you? Easy to read or not?

29
22
233
FP8 training works well and has large benefits. It has steep networking requirements to achieve good utilization but there are solutions to that too (we will release one in the next days). It's a big shift and everyone with RTX 40s / H100 GPUs should look into FP8 training.

Its crazy that, at 60% Model FLOPS (FP8) Utilization on H100, original GPT3 configuration can be trained in 3 days on 1024 H100s and PaLM on 12 days on 2048 H100s. That's roughly 50x lesser gpu hours for GPT3 paper 3 years back, and 9x lesser for palm released 9 months back.
6
20
224
Arguably, most progress in AI came from improvements in computational capabilities, which mainly relied on low-precision for acceleration (32-> 16 -> 8 bit). This is now coming to an end. Together with physical limitations, this creates the perfect storm for the end of scale.
7
9
229
I think it will take another day or two for the full integration, but the kernels (batch size 1) are ready.

5
15
226
If you are merging adapters with QLoRA 4-bit weights, please use the gist below for merging. This will increase the performance of the QLoRA model. I think I have seen a PR on PEFT, so this will soon come to PEFT by default, but for now, its better to merge it in this way.

Just put together a gist for merging QLoRA with the quantized model weights as mentioned by @Tim_Dettmers @Teknium1 @erhartford Since I know you guys were looking into it. Should be able to quantize the whole thing after this without issue.
1
24
220
I forgot how much better Guanaco-65B is compared to 33B. You can try here via Petals (globally distributed inference): With Petals, you can also run a 65B model in a colab or locally on a small GPU at ~5 tokens/sec (see below).

@fernavid @Tim_Dettmers We've updated one just today: this notebook shows you:.- how to run a 65B model from Colab,.- how to plug in adapters between its layers, .- and how to write custom generation methods (you can't do this with an API).
1
36
217
bitsandbytes is on track to surpass half a million pip installs this month! Upcoming features:. - LLM.int8() support for all GPUs.- Int8 backward for fine-tuning.- Fast 4-bit float (FP4) kernels for inference. Always looking for more people to get involved. There is lots to do!.
6
15
210
The 0.38.0 release of bitsandbytes introduces:. - 8-bit Lion which is 8x more memory efficient than standard Adam.- Serialization of 8-bit layers now allows storing/loading 8-bit models to/from the HF Hub. We are now at half a million installs per month!

5
39
203
I have my first draft right now: 7,000 words. It will be quite a comprehensive post. If you have any more GPU-related questions for me, right now is the last chance for them to be added. I will freeze the draft tonight, rewrite tomorrow, and then publish it on Monday.
15
13
198
I am very excited and proud to announce that I will join UW as a PhD student this fall. I will work with Yejin Choi on common sense knowledge and reasoning. I believe that with common sense, intelligent machines will be able to benefit everyone equally.
12
3
199
Just working on an update to my GPU recommendation blog post. Will cover the new GPUs and focus on the cost-effectiveness of 2/4/8 GPU systems. Any other things that you would like to see discussed?.
19
11
193
This model flew under the radar. It has the highest MMLU score of any open-source model. I have not tried it myself but I am curious how it compares to other models when evaluated across a broad range of tasks. Can somebody give it a try?.

Our team at @01AI_Yi is very proud to introduce the release of Yi-34B model now on top of @huggingface pretrained LLM leaderboard! Also a Yi-6B available. Welcome to give a try and build fantastic projects!.
12
12
194
An important but elusive quality to learn in a PhD is research style. It is valuable to be aware of this before you start a PhD. Among other updates, I added an extensive discussion on research style to my "choosing a grad school" blog post. Enjoy!
4
35
183
Making good progress on the updated GPU recommendation blog post. Have almost all data crunched and it seems that I will have pretty accurate estimates of performance. Will probably publish it Friday morning. If you have any more questions that I should include. Let me know!.
12
8
182
Guanaco-33B holds up well. Controlled for the memory footprint, its the best model. Since it was trained in 4-bit, it uses as much memory as a regular 7B model. The memory needed during fine-tuning is 17x less, so a 7B model is much more expensive to fine-tune than Guanaco 33B.

We are excited to announce the first major release of the Chatbot Arena conversation dataset!. - 33K conversations with pairwise human preferences.- 20 SOTA models such as GPT-4, Claude, and LLaMA-based Vicuna.- From 13K unique IPs in the wild.- An additional 3K expert-level


4
24
183
One thing that I care about in bitsandbytes is to provide _broad_ accessibility to LLMs. GPUs up to 9 years old are supported by 4-bit inference in bitsandbytes and you will see good speedups.

@Tim_Dettmers Wow! This just gave Volta cards a new lease on life: Testing with 4xV100S and a 30B~ model. Got a 3.2x speedup! 7-8 tokens per second is very usable for an interactive chat experience.

4
16
180
Claude even felt better today than usual. I was surprised that it could do things it could not do before. It felt much more nuanced. I tried Claude before reading this, so I thought, "Maybe I just prompted it right" 😂. Now, I think this is just the new model.

I'm excited to share what we've been working on lately at Anthropic. - Computer use API.- New Claude 3.5 Sonnet.- Claude 3.5 Haiku. Let's walk through everything:

5
9
179
Below highlights some problems with QLoRA (I should not have been so smirky😅), and I wanted to highlight some issues but also resolve some others. We integrated our QLoRA codebase with 5 other open-source codebases before release, and it seems we created some issues on the way🧵.
No cons :).
1
26
179
Going to write another GPU blog post update in the coming days. Are there any GPU questions that you would like to have answered? Will include popular Q&A in the blog post.
28
9
182
A really nice blog post by @agrinh about recent progress in GANs and variational autoencoders. Gives a short overview about GANs and their problems and then dives deep into the newest methods from ICML2018.
0
47
180
After talking to many students about their grad school experience I compiled this blog post on "How to pick your grad school". I discuss all the important factors and details from contrasting but complementary perspectives. I hope it will be helpful!
6
46
178
@CarnegieMellon won me over. It is an amazing place. Highly collaborative, very collegial, close-knit, with excellent students and great support. Looking forward to my time there!. I will take 2-3 PhD students for Fall 2025. Please apply to the CMU PhD program to work with me.
8
9
179
Catch my talk on k-bit Inference Scaling Laws at the @ESFoMo workshop, ballroom A (fourth floor), 10:50am. Slides:
2
32
177
We have confirmation that Tensor Cores in RTX 30 GPUs will be limited to make Quadro / Tesla cards more attractive for deep learning. This is the same as in the RTX 20s series. I will update my performance figures later today and will post an update.
7
29
166
This is pretty significant for custom CUDA code. Even with years of CUDA experience, it is very difficult to write peak performance matrix multiplication code. CUTLASS is great, but it seems Triton has better performance, is more customizable, and you can write code in Python.

We’re releasing Triton 1.0, an open-source Python-like programming language for writing efficient GPU code. OpenAI researchers with no GPU programming experience have used Triton to produce kernels that are 2x faster than their PyTorch equivalents.
4
19
171
I am currently preparing a new GPU blog post updated for the RTX 4090 etc. I am collecting some Q&A questions. If you have any questions that you would like me to answer in the blog post, please leave them here as a comment.
26
9
170
From my own experience (a lot of failed research), you cannot cheat efficiency. If quantization fails, then also sparsification fails, and other efficiency mechanisms too. If this is true, we are close to optimal now. With this, there are only three ways forward that I see. .
1
9
172
The six months on the academic job market were brutal but also very successful. More than 125 individual interviews across 17 universities leading to 15 job offers. It was a unique experience for which I am very grateful for. I will write up my learnings and insights soon.
4
0
172
This is a big deal. You no longer need labels to get good robot performance.

Excited to introduce 𝐋𝐀𝐏𝐀: the first unsupervised pretraining method for Vision-Language-Action models. Outperforms SOTA models trained with ground-truth actions.30x more efficient than conventional VLA pretraining. 📝: 🧵 1/9
2
15
167
@srush_nlp @4evaBehindSOTA Regular transformers are notoriously difficult to sparsify, this is even true for the FFN layers in MoE transformers. But MoE layers are very different. You can also quantize them to 1 bit without any problem, but sparsification gives you better memory benefits than 1-bit quant.
5
22
166
Just pushed a major CUDA-related update to pip for bnb. I need feedback because it's so difficult to test CUDA envs. It will either fix 90% of all CUDA issues, or fix 90% of issues and create many new ones 🫠. Please let me know if it works for you. I am ready to hotfix things.
7
14
165
It seems that first data suggest that the RTX 2080 Ti deep learning performance is very close to Titan V performance. Also key facts: Tensor Cores are programmable and NVLink can be used for data (+50GB/s). NVLink makes PCIe lanes obsolete for parallelism.
8
40
165
Now you can use bitsandbytes on AMD GPUs and Intel hardware. This is a big milestone and was a huge undertaking. @Titus_vK did an amazing job here. Eager to hear feedback! Let us know how it works for you.

🚀 Big news! After months of hard work and incredible community contributions, we're thrilled to announce the 𝗯𝗶𝘁𝘀𝗮𝗻𝗱𝗯𝘆𝘁𝗲𝘀 𝗺𝘂𝗹𝘁𝗶-𝗯𝗮𝗰𝗸𝗲𝗻𝗱 𝙖𝙡𝙥𝙝𝙖 𝗿𝗲𝗹𝗲𝗮𝘀𝗲! 💥. Now supporting:.- 🔥 𝗔𝗠𝗗 𝗚𝗣𝗨𝘀 (ROCm).- ⚡ 𝗜𝗻𝘁𝗲𝗹 𝗖𝗣𝗨𝘀 & 𝗚𝗣𝗨𝘀. (1/2).
1
19
163
Catch my posters today:.SWARM parallelism (fault tolerant globally distributed):. 11am, slot 217. k-bit Inference Scaling Laws (foundation of QLoRA and SpQR):. 2pm, slot 824.
0
34
163
Training in low-precision looks good . until it doesn't. People should be more of the following work, that basically says that low-precision will not work at scale:.

wrote a paper: it lets you *train* in 1.58b! could use 97% less energy, 90% less weight memory. leads to a new model format which can store a 175B model in ~20mb. also, no backprop!

7
11
164