
EleutherAI
@AiEleuther
Followers
23K
Following
811
Media
36
Statuses
735
A non-profit research lab focused on interpretability, alignment, and ethics of artificial intelligence. Creators of GPT-J, GPT-NeoX, Pythia, and VQGAN-CLIP
Joined August 2022
Over the past two and a half years, EleutherAI has grown from a group of hackers on Discord to a thriving open science research community. Today, we are excited to announce the next step in our evolution: the formation of a non-profit research institute.
32
158
889
Introducing the release 2.0 of GPT-NeoX, the open-source Megatron-DeepSpeed based library used to train GPT-NeoX-20B and the Pythia model suite.
6
106
540
The most common question we get about our models is "will X fit on Y GPU?" This, and many more questions about training and inferring with LLMs, can be answered with some relatively easy math. By @QuentinAnthon15, @BlancheMinerva, and @haileysch__ .
12
101
500
Everyone knows that transformers are synonymous with large language models… but what if they weren’t? Over the past two years @BlinkDL_AI and team have been hard at work scaling RNNs to unprecedented scales. Today we are releasing a preprint on our work.
4
115
465
What do LLMs learn over the course of training? How do these patterns change as you scale? To help answer these questions, we are releasing a Pythia, suite of LLMs + checkpoints specifically designed for research on interpretability and training dynamics!.
4
86
466
📕Today, we'd like to draw attention to the EleutherAI cookbook! ( . The cookbook contains practical details and utilities that go into working with real models!. Such as: 🧵.
1
96
418
As part of our work to democratize and promote access to language model technology worldwide, the Polyglot team at EleutherAI is conducting research on multilingual and non-English NLP. We are excited to announce their first models: Korean LLMs with 1.3B and 3.8B parameters.
3
43
367
We have been getting emails from confused individuals trying to access recently. That webpage doesn’t exist, because we don’t have an API. One of them finally clued us in to why: apparently ChatGPT suggests it for trying out our models.
7
27
266
Excited to share our new paper, Lessons From The Trenches on Reproducible Evaluation of Language Models!. In it, we discuss common challenges we’ve faced evaluating LMs, and how our library the Evaluation Harness is designed to mitigate them 🧵.

4
68
238
ggml is a deeply impressive project, and much of its success is likely ascribable to @ggerganov's management. Managing large-scale branching collaborations is a very challenging task (one we hope to improve at!), and Georgi deserves huge props for how he handles it.

The ggml roadmap is progressing as expected with a lot of infrastructural development already completed. We now enter the more interesting phase of the project - applying the framework to practical problems and doing cool stuff on the Edge

7
15
236
We’re excited to be collaborating on a new *resource release* to help provide an on-ramp for new open model developers: the Foundation Model Development Cheatsheet!

4
42
207
EleutherAI is hiring post-doctoral researchers and interns who don't have PhDs. Email contact@ with:.- Two papers you thought were interesting and what you would do differently from them.- A cool research idea.- A resume, if you really want to.
6
15
197
A common meme in the AI world is that responsible AI means locking AIs up so that nobody can study their strengths and weaknesses. We disagree: if there is going to be LLM products by companies like OpenAI and Google then independent researchers must be able to study them.

What am I excited about for 2023? . Supporting more open-source science, models, datasets and demos like Dalle-mini by @borisdayma, Bloom by @BigscienceW, GPTJ by @AiEleuther @laion_ai, @StableDiffusion by compvis @StabilityAI @runwayml, Santacoder by @BigCodeProject & many more!.
2
20
177
🎉We're excited to announce our joint work with @Cerebras on a new guide to Maximal Update Parameterization (μP) and μTransfer!🎉. This practitioner's guide (and implementation) aims to make μP more accessible and easier to implement for the broader training community. 🧵.
2
27
181
We were hoping to ignore this, but have been getting questions so it's important to set the record straight:. tl;dr Mithril pulled an unprofessional PR stunt to advertise their commercial product and has never compromised any models we have released.

3
13
169
The EMNLP camera-ready version of @RWKV_AI is now available on arXiv! Congrats again to @BlinkDL_AI @eric_alcaide @QuentinAnthon15 and the rest of the team on the first successful scaling of RNNs to the ten billion parameter regime!. A 🧵.

4
27
158
The Foundation Model Transparency Index by @StanfordCRFM purports to be an assessment of how transparent popular AI models are. Unfortunately its analysis is quite flawed in ways that minimize its usefulness and encourage gamification.
7
33
145
The latest paper in EleutherAI's close collaboration with @mark_riedl's lab on computational storytelling shows how to use a CLIP-like contrastive model to guide the generation of natural language stories to meet human preferences.

Robust Preference Learning for Storytelling via Contrastive Reinforcement Learning.abs:

3
29
126
If you have substantially contributed to a ML training that required multiple compute nodes, we would like to interview you!. Email contact@eleuther.ai with your resume, details about the training run, and a short description of your current interests. More jobs coming soon!.
6
23
114
Our recent blog post contained a meme about code golfing, inspired by a paper that bragged about reaching 80%+ on ImageNet with code that fit in a tweet. In the past 24 hours we've received five emails with code beating Gao (2021), with the current record holder being 260 bytes:

2
11
109
How can we talk about the way AI chat bots behave without falling into false anthropomorphic assumptions? In our latest paper we explore role-play as a framework for understanding chatbots without falsely ascribing human characteristics to language models.
3
20
105
Congratulations to our friends at @allen_ai on joining (along with EleutherAI and @llm360) the tiny club of organizations that have trained a large language model with:.1. Public training data.2. Partially trained checkpoints.3. Open source licensing on model weights.

OLMo is here! And it’s 100% open. It’s a state-of-the-art LLM and we are releasing it with all pre-training data and code. Let’s get to work on understanding the science behind LLMs. Learn more about the framework and how to access it here:.
1
14
104
We're glad to share our work on Minetester, a fully open RL framework we've been working on as part of a larger alignment research agenda.
1
23
103
GPT-NeoX is already the go-to library for pretraining at scale for dozens of organizations globally. Now with @synth_labs we're adding native RLHF support to give you even more reasons to try it!. We find GPT-NeoX is 30% faster than trl at the 13B scale.
1
20
90
Great to see our work with @NousResearch and @EnricoShippole on context length extension highlighted at @MistralAI's presentation at AI Pulse. And a very deserved shout-out to @huggingface and @Teknium1 as well!

3
10
94
A few days ago we had the first meeting of our newest reading group, focusing on Mixture of Expert (MoE) models. Check out the recording, and drop by our discord server to join the next meeting!.
0
14
94
We are discussing ramping up our public education efforts. What are topic(s) regarding LLMs and other large scale AI technologies that you would like to see more lay-accessible blog posts, infographics, etc. about?.
18
7
86
Negative results are essential for science, but approximately impossible to publish. What's your preferred way to share them?.

Last year, many people at @AiEleuther worked on an project to improve on @CollinBurns4's CCS method for eliciting latent knowledge from LLMs. We were unable to improve on CCS, but today we're publishing the proposed method and negative empirical results.
7
8
86
The first major codebase to come out of @carperai, our Reinforcement Learning from Human Feedback (RLHF) lab. Previous work by @OpenAI and @AnthropicAI has made it clear that RLHF is a promising technology, but a lack of released tools and frameworks makes using it challenging.
1
11
85
Read more about our team and collaborators’ work on Llemma, powerful domain-adapted base models for mathematics!. Blog post: Models/data/code: 1/n.
1
31
81
Amazing work by the @CohereForAI!. Dataset paper: Model paper:

Today, we’re launching Aya, a new open-source, massively multilingual LLM & dataset to help support under-represented languages. Aya outperforms existing open-source models and covers 101 different languages – more than double covered by previous models.
1
19
76
We are very excited to share the results of our collaboration with @farairesearch on developing tooling for understanding how model predictions evolve over the course of training. These ideas are already powering our ELK research, so expect more soon!.
Ever wonder how a language model decides what to say next?. Our method, the tuned lens (, can trace an LM’s prediction as it develops from one layer to the next. It's more reliable and applies to more models than prior state-of-the-art. 🧵
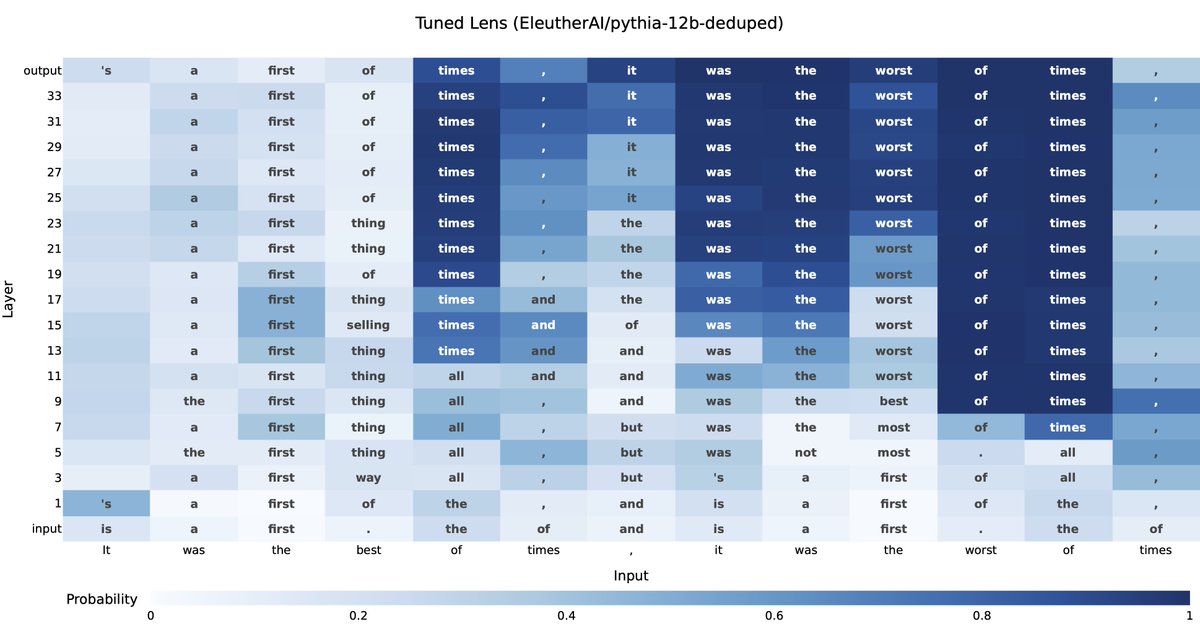
1
14
69
We believe that building a robust, interoperable research community requires collaboration. @huggingface has been doing a phenomenal job organizing multilateral collaborations and we're excited to continue to participate. Congrats to @haileysch__ and the entire @BigCodeProject!.

Introducing: 💫StarCoder. StarCoder is a 15B LLM for code with 8k context and trained only on permissive data in 80+ programming languages. It can be prompted to reach 40% pass@1 on HumanEval and act as a Tech Assistant. Try it here: Release thread🧵

1
15
68
Looking for EleutherAI at @icmlconf? Come meet our community and check out their fabulous work. Featuring (in order of appearance): @lintangsutawika @haileysch__ @aviskowron @BlancheMinerva @Vermeille_ @Void13950782 @dashstander @qinan_yu @norabelrose @CurtTigges


2
13
52
We’ve trained and released Llemma, strong base LMs for mathematics competitive with the best similar closed+unreleased models. We hope these models + code will serve as a powerful platform for enabling future open Math+AI research!.

We release Llemma: open LMs for math trained on up to 200B tokens of mathematical text. The performance of Llemma 34B approaches Google's Minerva 62B despite having half the parameters. Models/data/code: Paper: More ⬇️
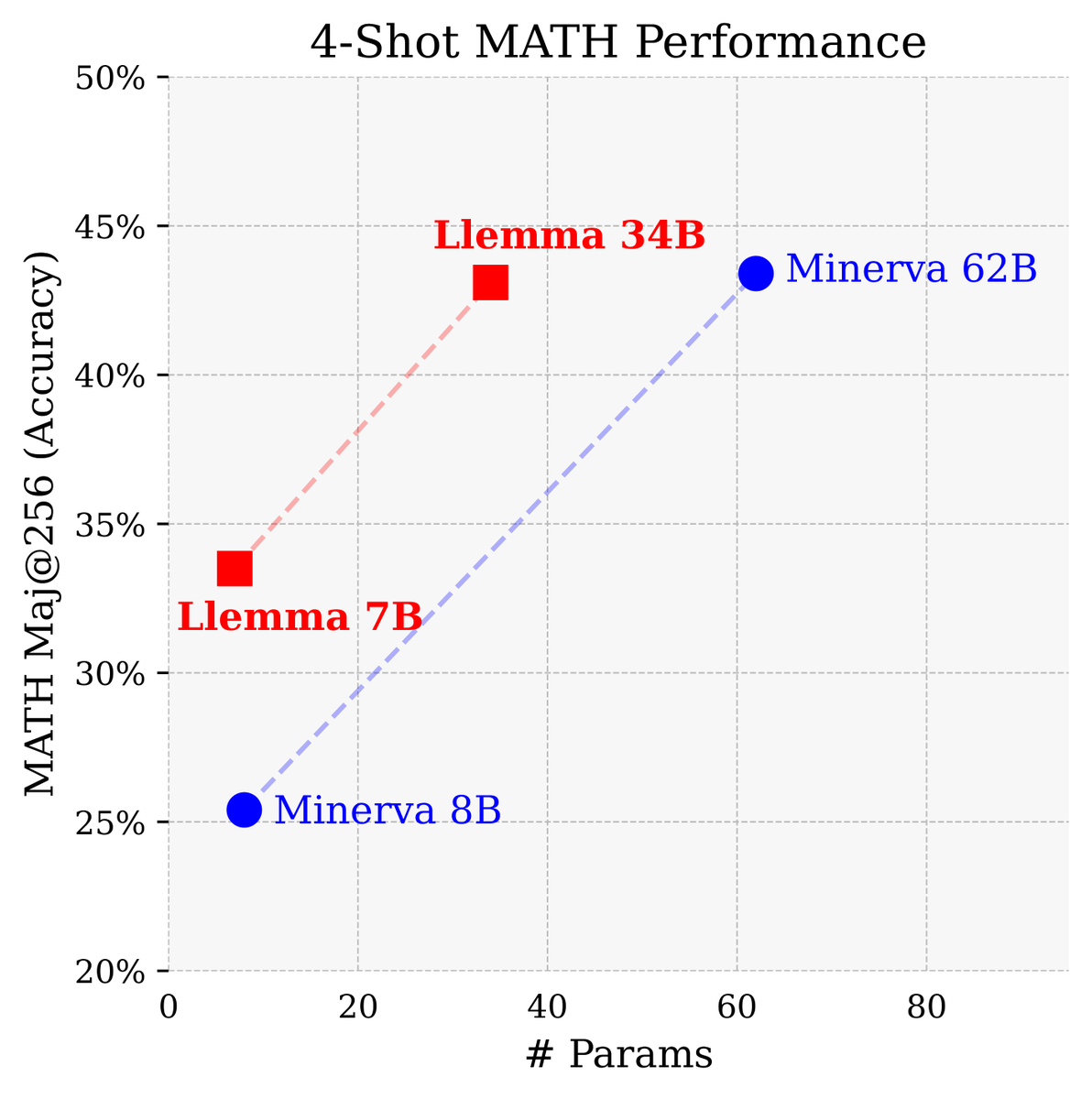
1
14
67
Amazing news for our close partner in research and major donor, @huggingface. We've be thrilled to work with HF on projects like BLOOM and the Open LLM Leaderboard, and are excited to continue to work with them to advance open AI research and the open source ecosystem.
Super excited to welcome our new investors @SalesforceVC, @Google, @amazon, @nvidia, @AMD, @intel, @QualcommVenture, @IBM & @sound_ventures_ who all participated in @huggingface’s $235M series D at a $4.5B valuation to celebrate the crossing of 1,000,000 models, datasets and apps

0
4
68
Great to see @CerebrasSystems build on top of Pile and releasing these open source! Cerebras-GPT is Chinchilla optimal up to 13B parameters. A nice compliment to our Pythia suite, allowing for the comparison of the effect of different training regimes on model behavior.

🎉 Exciting news! Today we are releasing Cerebras-GPT, a family of 7 GPT models from 111M to 13B parameters trained using the Chinchilla formula. These are the highest accuracy models for a compute budget and are available today open-source! (1/5). Press:
2
10
69
Huge shout out to the donors who have helped us get to where we are today and where we will go next: @StabilityAI @huggingface @CoreWeave @natfriedman @LambdaAPI and @canva. And finally, come hang out in our online research lab! We can't wait to meet you.
2
2
67
Very exciting work from @databricks! We’re excited to see GPT-J continuing to power open source innovation close to two years after we released it.

Building a ChatGPT-like LLM might be easier than anyone thought. At @Databricks, we tuned a 2-year-old open source model to follow instructions in just 3 hours, and are open sourcing the code. We think this tech will quickly be democratized.
2
7
63
We are excited to join other leaders in artificial intelligence in partnering with @NSF to launch the National AI Research Resource (NAIRR), a shared infrastructure that will promote access to critical resources necessary to power AI research.

NSF and its partners are proud to launch the National AI Research Resource pilot. Its goal? To democratize the future of #AI research & development by offering researchers & educators advanced computing, datasets, models, software, training & user support.

3
7
61
As models become larger and more unwieldy, auto-interp methods have becoming increasingly important. We are excited to be releasing the most comprehensive auto interp library to enable wider research on this topic.

Sparse autoencoders recover a diversity of interpretable features but present an intractable problem of scale to human labelers. We build new automated pipelines to close the gap, scaling our understanding to GPT-2 and LLama-3 8b features. @goncaloSpaulo @jacobcd52 @norabelrose
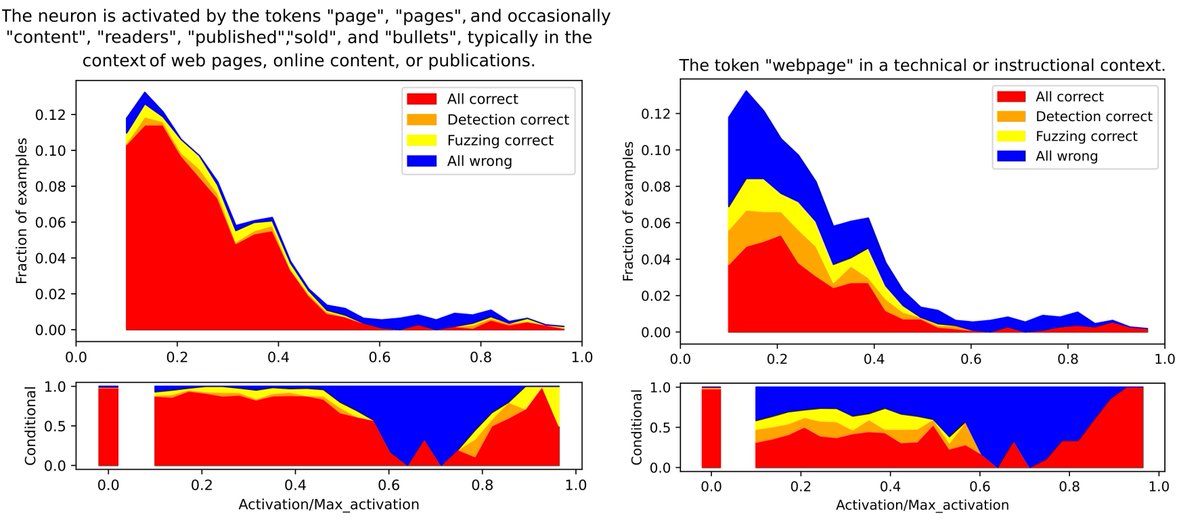
2
10
59
Reinforcement Learning from Human Feedback is an allegedly powerful technology for language models, but one that has so far been kept out of the hands of most researchers. We are thrilled to be working on bringing the ability to study and evaluate these model to the mainstream.
0
13
60
Kyle is one of four members of our community without a PhD with their first first-author paper under review currently! We view providing this training and mentorship as an important part of our public service.

We are grateful to EleutherAI for permitting access to their compute resources for initial experiments. The welcome and open research community on the EleutherAI Discord was especially helpful for this project and my growth as a scientist. 😊.
3
4
60
Another day, another math LM bootstrapping their data work off of the work done by OpenWebMath and Llemma teams. This makes the three in the past week!. Open data work is 🔥 Not only do people use your data, but high quality data work has enduring impact on data pipelines.
AutoMathText. Autonomous Data Selection with Language Models for Mathematical Texts. paper page: dataset: To improve language models' proficiency in mathematical reasoning via continual pretraining, we introduce a novel strategy

3
10
57
An essential blocker to training LLMs on public domain books is not knowing which books are in the public domain. We're working on it, but it's slow and costly. if you're interested in providing support reach out!.

@BlancheMinerva @rom1504 Indeed, these would be *extremely* valuable data resources. The databases on are, unfortunately, ununified and the records themselves seem anemic. Somewhat odd considering USPTO has flagship datasets (available via NAIRR). Greater financial incentives?.
2
10
52
Releasing data is amazing, but tools like these that help people make sense of the data is arguably an even more important step forward for data transparency. We're thrilled to see our community continue to lead by example when it comes to in transparent releases.

We also made an @nomic_ai Atlas map of OpenWebMath so you can explore the different types of math and scientific data present in the dataset:
1
13
55
A very interesting analysis from @ZetaVector looks at how the most cited papers each year break down. We’re especially proud of this statistic: Almost 20% of papers with EleutherAI authors were in the top 100 most cited papers of their year. Full report:
And fixed an issue that caused @AiEleuther to miss their spot as the second most effective in impact.

3
8
55
We are excited to see torchtune, a newly announced PyTorch-native finetuning library, integrate with our LM Evaluation Harness library for standardized, reproducible evaluations!. Read more here: .Blog: Thread:.

torchtune provides:.- LLM implementations in native-PyTorch.- Recipes for QLoRA, LoRA and full fine-tune.- Popular dataset-formats and YAML configs.- Integrations with @huggingface Hub, @AiEleuther Eval Harness, bitsandbyes, ExecuTorch and many more. [3/5].
0
7
55
Very glad to see this. “Public release” of models doesn’t mean much at this scale if you can’t provide a free API, as almost nobody can afford to deploy the model. Great work by @huggingface and @Azure making this happen and keeping it supported.
0
5
51
Interested in Mixture-of-Experts models but don't want to train it from scratch? Check out the latest from @arankomatsuzaki, who spent his internship @GoogleAI figuring out how to convert existing dense models to MoE ones.

We have released "Sparse Upcycling: Training Mixture-of-Experts from Dense Checkpoints"!. Our method converts a pretrained dense model into a MoE by copying the MLP layers and keeps training it, which outperforms continued dense training. (1/N)
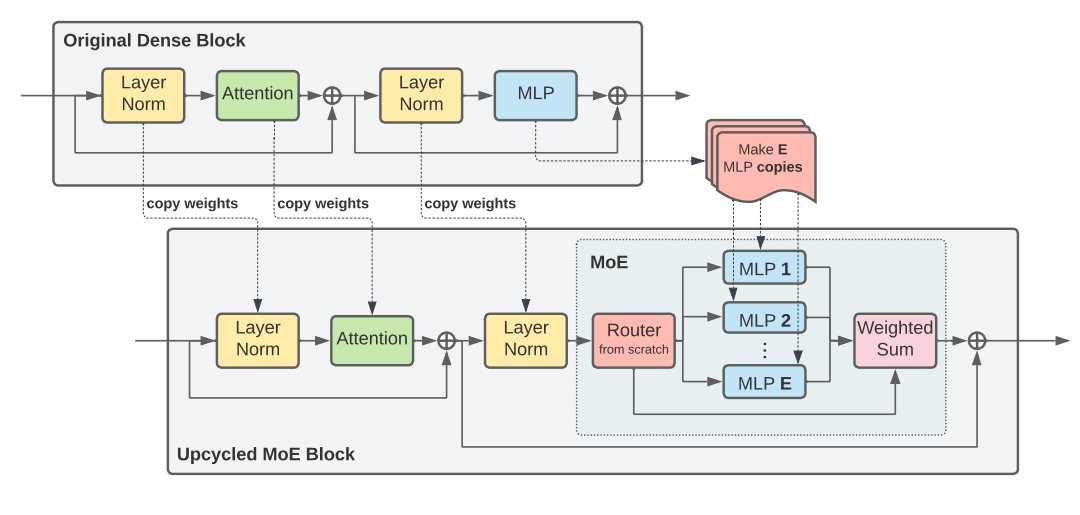
0
6
53
most NLP researchers had a very minimal understanding of the engineering undertaking required to train such models or their capabilities & limitations. We started as a ragtag group nobody had heard of, and within a year had released the largest OSS GPT-3-style model in the world.
1
0
49
A huge thank you to everyone who has helped make our training and evaluation libraries some of the most popular in the world. Especially @QuentinAnthon15's work leading GPT-NeoX and @haileysch__ @lintangsutawika @BlancheMinerva and @jonbtow for their eval work over the years


2
8
51
Claiming that you can match a transformers’ performance is nothing new, and plenty of other papers put forth that claim. What makes RWKV special is that we actually train models up to 14B params and show consistently competitive performance with token-matched transformers!

1
9
48
A really phenomenal deep dive into LLM evaluations and good illustration of why.1. Real life applications should be evaluated in the deployment context.2. Open access to models and evaluation code is essential for understanding the claims made in papers.

𝗗𝗼𝗻’𝘁 𝗯𝗹𝗶𝗻𝗱𝗹𝘆 𝘁𝗿𝘂𝘀𝘁 𝘁𝗵𝗲 𝗢𝗽𝗲𝗻 𝗟𝗟𝗠 𝗟𝗲𝗮𝗱𝗲𝗿𝗯𝗼𝗮𝗿𝗱!. We used @try_zeno to explore the Open LLM Leaderboard data. Spoiler: Unless you use LLMs for multiple choice questions, these benchmarks aren’t that helpful. Zeno Report:.
0
9
48
@Meta @ylecun @paperswithcode @huggingface @StabilityAI If “open source” is to mean anything, we must stand with @OpenSourceOrg and call out corporate misinformation. You don’t need to license your models open source. It may even be the best choice to *not* do so. But if you don’t, you shouldn’t lie and say you did.
4
10
45
Congrats to everyone who won one of these grants. The open source community desperately needs more funding so that people can be *professional* open source engineers and researchers, lest the only end-game be a closed-source job.

[New program] a16z Open Source AI Grants. Hackers & independent devs are massively important to the AI ecosystem. We're starting a grant funding program so they can continue their work without pressure to generate financial returns.
0
5
48
A little over a month ago, @Vermeille_ showed up in our discord server with a simple question: can CFG be applied to LLMs?. Probably, but the devil’s in the details. So we sat down to figure those details out. Check out his new paper for more ⬇️⬇️⬇️.

We borrowed CFG from vision and run it with LLMs. We get increased control, and benchmarks increases similar to a model twice the size. Ready for all your models (incl. chatbots!) : no special training or fine tuning required. thx @AiEleuther !.
1
8
48
It’s been a pleasure to watch Theodore’s ideas develop over the past two years. Definitely check out his paper one finetuning LLMs into “text-to-structure” models, and how to use them to design tools that are useful to architects.

It's finally out! After almost 2 years of delay, our paper on Architext, the first, open-source, language model trained for Architectural design, is now on arxiv. In the unlikely event you're curious to read it, you can find it here: Quick thread ↓

0
11
45
The threat here is pretty much the same as a phishing scam or someone uploading a false website under a slightly different URL. The only way someone could accidentally use this model is if they had a typo in their call to the HuggingFace Hub.
1
0
45
This will enable us to do much more, and we look forward to building a world class research group for public good! Lead by Stella Biderman @BlancheMinerva as Executive Director and Head of Research, Curtis Huebner as Head of Alignment, and Shiv Purohit as Head of Engineering.
3
1
42
To address some of the allegations in the thread:. 1. They are not whistleblowers: the fact that these kinds of attacks on supply chains are possible is extremely well known and well documented. Nobody was surprised this was possible or hid it.
1
0
44
Last year Mithril took a model that we had released and modified it. They uploaded the modified model to HuggingFace under a fraudulent account that was a misspelling of our username. The modified model has never been available to download from our website or our HF page.
1
1
43
Interested in meeting up with EleutherAI at #NeurIPS2023? Over a dozen members of our community will be there to present ten papers, including @BlancheMinerva @norabelrose @lcastricato @QuentinAnthon15 @arankomatsuzaki @KyleDevinOBrien @zhangir_azerbay @iScienceLuvr @LauraRuis.
1
5
42
We're excited to announce that @lintangsutawika and @haileysch__ will be at ICML 2024 in Vienna on July 22 to present a tutorial on "Challenges in Language Model Evaluations"!. Website:.
1
5
43
RNNs struggle to scale because of how they parallelize, but making the time decay of each channel data-independent, we are able to parallelize RWKV the same way transformers are during training! After training, it can be used like an RNN for inference.


1
4
41
This is some really phenomenal work out of @StanfordHAI. Evaluation work, like data work, is a massively understudied and undervalued. But work like this has far more impact than a half dozen medium papers about minor tweaks to transformer architectures.

Two lessons we learned through HELM (Sec 8.5.1; : 1. CNN/DM and XSum reference summaries are worse than summaries generated by finetuned LMs and zero-/few-shot large LMs. 2. Instruction tuning, not scale, is the key to “zero-shot” summarization.
1
6
40
Interested in studying formal proofs with LLMs? Check out ProofNet, a new benchmark for theorem proving and autoformalization of undergraduate-level mathematics by @zhangir_azerbay @haileysch__ and others. Follow-up work is already in progress!.
How good are language models at formalizing undergraduate math? We explore this in. "ProofNet: autoformalizing and formally proving undergraduate-level mathematics". Thread below. 1/n.
0
6
41
@huggingface Mithril did not follow any reasonable disclosure processes. They did not contact either us or HuggingFaceq to disclose what they had done, though they did contact media outlets. The purpose of this was not whistleblowing, it was to advertise their start-up

2
0
38
Congrats to @StabilityAI and their collaborators. We are excited to see people continuing to push for non-English non-Chinese LLM research, and thrilled that they're finding our libraries including GPT-NeoX and lm-eval useful! To get started on your next LLM project, check out 👇.

Today, we are releasing our first Japanese language model (LM), Japanese StableLM Alpha. It is currently the best-performing openly available LM created for Japanese speakers! ↓

1
6
40
@databricks GPT-J-6B might be “old” but it’s hardly slowing down. Month after month it’s among the most downloaded GPT-3 style models on @huggingface, and no billion+ param model has ever come close (“gpt2” is the 125M version, not the 1.3B version).

1
5
36
@BigscienceW This is just the beginning of our work on non-English and multilingual NLP. We have a 6B Korean model currently training, and plans to expand to East Asian and Nordic language families next! Keep an eye on our GitHhub or stop by #polyglot on our Discord!.
2
1
34
EleutherAI is excited to collaborate with NIST in its newly formed AI Safety Institute Consortium (AISIC) to establish a new measurement science for safe AI systems. See the official announcement here: #AISIC @NIST @CommerceGov.
1
5
35
As access to LLMs has increased, our research has shifted to focus more on interpretability, alignment, ethics, and evaluation of AIs. We look forward to continuing to grow and adapt to the needs of researchers and the public. Check out our latest work at
1
1
35
Very cool work! @_albertgu has been pushing on state-space models for some time now and the release of billion-parameter scale models is a big step forward for this line of work. We look forward to the community testing the models out!.

Quadratic attention has been indispensable for information-dense modalities such as language. until now. Announcing Mamba: a new SSM arch. that has linear-time scaling, ultra long context, and most importantly--outperforms Transformers everywhere we've tried. With @tri_dao 1/

0
3
35
RWKV substantially lags behind S4 on the long range arena benchmark, as well as subsequent work by @_albertgu et al. @HazyResearch such as SGConv and Mamba. It remains to be seen if that's a killer for NLP applications. Note that the scores are nearly identical for the text task.

1
4
35
We are thrilled to share the latest in our collaboration with @EnricoShippole and @NousResearch on sequence length extension. We're now pushing sequence lengths that will enable work in malware detection and biology that are currently hamstrung by sequence length limitations!.

Releasing Yarn-Llama-2-13b-128k, a Llama-2 model, trained for 128k context length using YaRN scaling. The model was trained in collaboration with u/bloc97 and @theemozilla of @NousResearch and @Void13950782 of @AiEleuther.

0
3
33
We were very happy with the reception to our researchers @lintangsutawika and @haileysch__ 's ICML tutorial, "Challenges in LM Evaluation", this past week!. For all those who requested it, the slides are now available at . Enjoy!.
1
12
36
HF transformers, Megatron-DeepSpeed, and now Lit-GPT. what will be the next framework to support our language model evaluation harness?.

Use Lit-GPT to evaluate and compare LLMs on 200+ tasks with a single command. Try it ➡️ #MachineLearning #LLM #GPT

3
3
34
@huggingface Likewise, Paul is using this to advertise his newsletter. Whether a newsletter that only just covered an event that occurred on June 9th, 2023 is worth subscribing to is up to you.

3
0
33
Public release makes AI models better, more diverse, and spreads their benefits more widely.

Just a few days into @huggingface and @LambdaAPI's Whisper fine-tuning event and have already seen huge breakthroughs in multilingual ASR. Very smart people working on this. Here's the SOTA whisper-based module I fine-tuned for Portuguese 🇧🇷🇵🇹
2
8
34
A new minor version release, 0.4.2, of the lm-evaluation-harness is available on PyPI! .1/n.
1
6
34
Transparency about whose data is contained in datasets is an essential first step towards establishing meaningful provenance and consent. We applaud @BigCodeProject's efforts in this regard and look forward to implementing similar techniques for our future datasets.

Yay, I have 29 of my GH repositories included in The Stack 😎 . Prepare for some very good quality codes 🤪. The Stack:

0
10
33
We've also released a μP-enabled version of nanoGPT to help you get started:.This implementation includes working examples for verifying and using μP in your own projects.
1
4
34
Congrats to @BlinkDL_AI and the team :) We hope to have a paper about RWKV out by the end of the month!.

The first RNN in transformers! 🤯.Announcing the integration of RWKV models in transformers with @BlinkDL_AI and RWKV community!.RWKV is an attention free model that combines the best from RNNs and transformers. Learn more about the model in this blogpost:

0
7
32
If you’re attending #ACL2023NLP or #icml2023 don't miss our seven exciting papers on crosslingual adaption of LLMs, the Pythia model suite, novel training methodologies for LLMs, data trusts, and more!. 🧵.
1
6
32
Even after only 55% of the training, @BlinkDL_AI’s multilingual RWKV “World” model is the best open source Japanese LLM in the world!. Check out the paper: Code and more models can be found at:

The JPNtuned 7B #RWKV World is the best open-source Japanese LLM �Runner: Model (55% trained, finishing in a few days): More languages are coming🌍RWKV is 100% RNN

1
8
31
Looking for something to check out on the last day of #NeurIPS2023? Come hang out with EleutherAI @solarneurips . @BlancheMinerva is speaking on a panel and @jacob_pfau @alexinfanger Abhay Sheshadri, Ayush Panda, Curtis Huebner and @_julianmichael_ have a poster. Room R06-R09


0
5
30
The world has changed quite a lot since we first got started. When EleutherAI was founded, the largest open source GPT-3-style language model in the world had 1.5B parameters. GPT-3 itself was not available for researchers to study without special access from OpenAI, and.
1
0
29
2. It is not known if the two models were indistinguishable or performs the same on benchmarks because the blog post didn't actually include info on this and we didn't download the obviously malicious file to text ourselves (instead we reported them to @huggingface).
1
0
30
This is deeply necessary work and a heroic effort by Shayne et al. "This is the best NLP data work of 2023." @BlancheMinerva . "If there's anything less glamorous yet higher-impact in ML than looking at the data, it's doing due diligence on licensing." @haileysch__.

📢Announcing the🌟Data Provenance Initiative🌟. 🧭A rigorous public audit of 1800+ instruct/align datasets. 🔍Explore/filter sources, creators & license conditions. ⚠️We see a rising divide between commercially open v closed licensed data. 🌐: 1/
1
6
31
Interested in practical strategies to continually pre-train existing models on new data? Take a look at the recent paper between @AiEleuther and @irinarish's CERC lab as a part of our joint INCITE grant!.

Interested in seamlessly updating your #LLM on new datasets to avoid wasting previous efforts & compute, all while maintaining performance on past data? Excited to present Simple and Scalable Strategies to Continually Pre-train Large Language Models! 🧵1/N

2
5
30
Interested in our recent paper "LLeMA: An Open Language Model For Mathematics"? Check out this summary by @unboxresearch. Or dig into our work directly.Paper: Code:
I can imagine a future where advanced mathematics has completely changed. What makes math challenging today is the ability to learn abstract technical concepts, as well as the ability to construct arguments that solve precise logical problems. [article: .
2
7
30
Benchmark results show that the models have performance comparable to or better than the best publicly available Korean language models, including Facebook's 7.5B xGLM and Kakao Brain's 6.0B koGPT model. We do not show @BigscienceW's BLOOM models as they are not trained in Korean


2
1
30
@huggingface Indeed, at the bottom of their blog post they advertise a waitlist for their commercial service that alleges to solve this program.

1
0
29
It was great to see a lot of excitement about attention-free models @NeurIPSConf! We had great conversations with many people interested in next-gen architectures for language models. Pic from Systems for foundational models and foundation models for systems by Chris Re

1
3
31
@arankomatsuzaki has graduated from explaining other peoples’ papers in Discord and on Twitter to doing it at conferences when the author misses their poster session.

Aran Komatsuzaki giving walkthroughs of the codeRL paper before the author arrives. After 10 minutes of SBFing his way into answering poster questions he revealed he was not the author and everyone lost their mind (Poster 138 #NeurIPS2022)
1
2
31
EleutherAI is blessed to have ungodly amounts of compute for a research non-profit. Part of that blessing though is a responsibility to develop things that are interesting and useful not just to us, but to the many researchers who wouldn’t have been able to do this themselves.
We are currently using these models to investigate a variety of phenomena (expect initial papers within the month!), but are making the models public now because we believe that these models will be widely useful to the NLP community writ large and don't want to make others wait.
0
2
29
We present the first compute-optimal scaling laws analysis of a large RNN, finding highly predictable scaling across runs. Unfortunately we don't sample densely enough to estimate the optimal token-per-parameter, but we plan to in future work.

1
4
29
Excellent and timely reminder from the FTC. The question, as always, is whether the USG will be able to bring itself to levy meaningful penalties that actually deter illegal behavior by companies. h/t: @emilymbender .
2
7
27