

Georgi Gerganov
@ggerganov
Followers
44K
Following
3K
Media
251
Statuses
1K
24th at the Electrica puzzle challenge | https://t.co/baTQS2bdia
Joined May 2015
Introducing LLaMA voice chat! 🦙 . You can run this locally on an M1 Pro
187
1K
8K
I've started a company: From a fun side project just a few months ago, ggml has now become a useful library and framework for machine learning with a great open-source community.
144
378
3K
LLaMA voice chat + Siri TTS. This example is now truly 100% offline since we are now using the built-in Siri text-to-speech available on MacOS through the "say" command
43
365
2K

Full F16 precision 34B Code Llama at >20 t/s on M2 Ultra
39
261
2K
ggtag : data-over-sound is back !. Please checkout our latest geeky side project --.An e-paper badge that can be programmed with sound. Here is how it works 🔊
33
251
2K
sam.cpp 👀. Inference of Meta's Segment Anything Model on the CPU. Project by @YavorGI - powered by
35
277
2K

The future of on-device inference is ggml + Apple Silicon. You heard it here first!.

Watching llama.cpp do 40 tok/s inference of the 7B model on my M2 Max, with 0% CPU usage, and using all 38 GPU cores. Congratulations @ggerganov ! This is a triumph.
38
180
2K
Simultaneously running LLaMA-7B (left) + Whisper Small (right) on M1 Pro
29
178
1K

Announcing the Local LLaMA podcast 🎙️🦙. In today's episode we have LLaMA, GGaMA, SSaMA and RRaMA joining us to discuss the future of AI
31
187
1K
Adding support for the new Mixtral models. Runs on CPU, CUDA and Metal with quantization support and partial GPU offloading. Very interesting architecture to play with!.
25
146
1K
Wrote a short tutorial for setting up llama.cpp on AWS instances. For example, you can use one of the cheapest 16GB VRAM (NVIDIA T4) instances to serve a quantum Mistral 7B model to multiple clients in parallel with full context. Hope it is useful!.

28
172
1K
Make your Mac think faster 🧠🧠. Tomorrow I'll show you how to cancel your copilot subscription.



Make your Mac think 🧠. Tomorrow I'll show you how to enable speculative decoding for extra speed.

34
123
1K
ggml will soon run on billion devices. @apple don't sleep on it 🙃.

I just verified this on my Pixel 8 Pro phone! It has AICore included and it is using ggml



61
125
1K
Native whisper.cpp server with OAI-like API is now available. $ make server && ./server. This is a very convenient way to run an efficient local transcription service locally on any kind of hardware (CPU, GPU (CUDA or Metal) or ANE). thx felrock
25
150
1K
llama.cpp server now support multimodal (LLaVA) 🎉. Huge shoutout to FSSRepo and monatis.
16
134
1K
Just added support for all LLaMA models. I'm out of disk space, so if someone can give this a try for 33B and 65BB would be great 😄.See updated instructions in the Readme. Here is LLaMA-13B at ~10 tokens/s
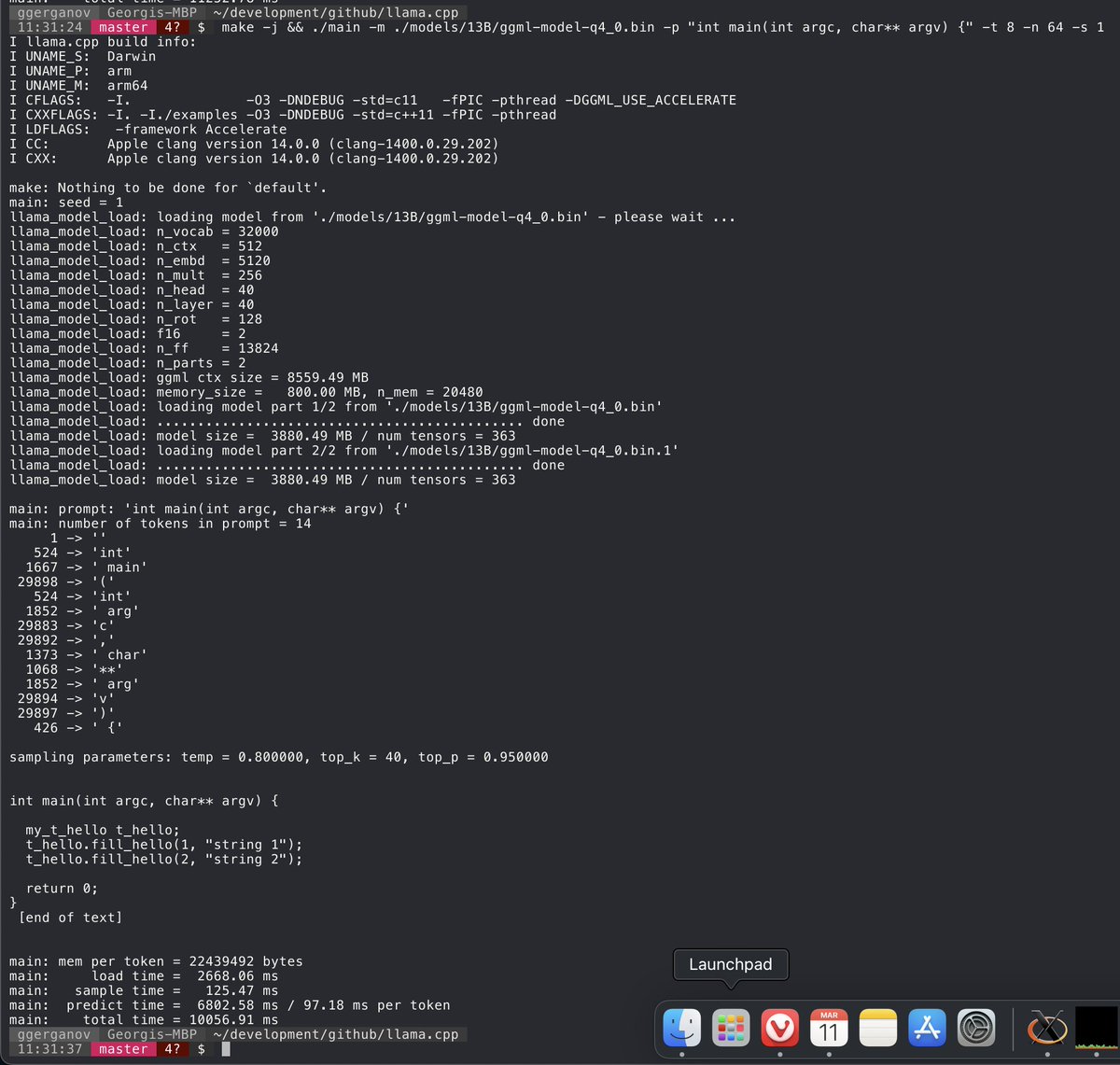
I think I can make 4-bit LLaMA-65B inference run on a 64 GB M1 Pro 🤔. Speed should be somewhere around 2 tokens/sec. Is this useful for anything?.
26
139
1K
llama.cpp just got access to the new Copilot for Pull Request technical preview by @github . Just add tags like "copilot:all" / "copilot:summary" / "copilot:walkthrough" to your PR comment the magic happens 🪄


15
95
980
The llama.cpp repo is buzzing with activity today. Here are some highlights. Added Alpaca model support and usage instructions
18
72
944
Make your Mac think 🧠. Tomorrow I'll show you how to enable speculative decoding for extra speed.
17
83
967
llama2.c running in a web-page. Compiled with Emscripten and modified the code to predict one token per render pass. The page auto-loads 50MB of model data - sorry about that 😄.

My fun weekend hack: llama2.c 🦙🤠.Lets you train a baby Llama 2 model in PyTorch, then inference it with one 500-line file with no dependencies, in pure C. My pretrained model (on TinyStories) samples stories in fp32 at 18 tok/s on my MacBook Air M1 CPU.

16
144
886
Here is how to deploy and serve any LLM on HF with a single command in less than 3 minutes with llama.cpp. $ bash -c "$(curl -s "
8
125
854
llama.cpp now supports distributed inference across multiple devices via MPI. This is possible thanks to @EvMill's work. Looking for people to give this a try and attempt to run a 65B LLaMA on cluster of Raspberry Pis 🙃.
19
137
855
whisper.cpp v1.3.0 now with Core ML support. Currently, the Encoder runs on the ANE, while the Decoder remains on the CPU. Check the linked PR 566 for implementation details and usage instructions.
12
118
758
Here is 4-bit inference of LLaMA-7B using ggml:. Pure C/C++, runs on the CPU at 20 tokens/sec (M1 Pro). Generated text looks coherent, but quickly degrades - not sure if I have a bug or something 🤔. Anyway, LLaMA-65B on M1 coming soon!.
24
129
734
Running some LLM benches on iPhone 13 Mini. This is 1.1B TinyLlama. Speed looks quite reasonable. Wonder what would be some cool applications that we can try out 🤔. P.S. Forget about useless chat bots - we want something else. Think grammar, function calling, etc.


49
67
725
llama.cpp releases now ship with pre-built macOS binaries. This should reduce the entry barrier for llama.cpp on Apple devices. Thanks to @huggingface for the friendly support 🙏
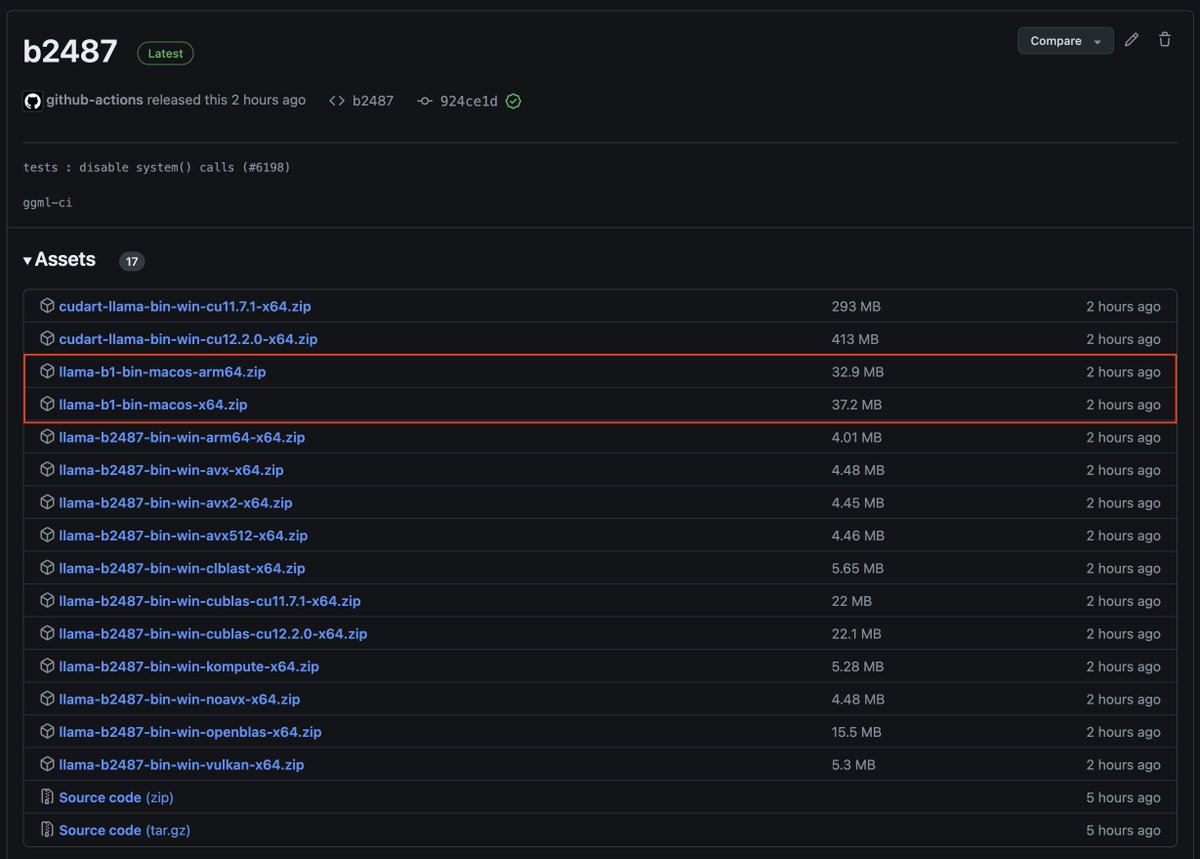
16
67
724
I'm thinking about making an open-source local iOS voice chat app running Whisper Base + 4-bit Cerebras-GPT 2.7B. Should be able to run quite real-time on newer iPhones. Pretty sure I have everything needed and can build this in a day. Only question is if Cerebras is good enough.
42
40
723
Apparently, Stable Diffusion can be used to generate images of spectrograms from text prompts. The spectrograms can in turn be converted to audio using STFT and some tricks. Mind is blown!.

18
123
663
Experimenting with speculative decoding + grammar sampling. This is an example of summarizing a short story into a structured JSON. We again utilize speculative decoding, but this time we constrain the output using a JSON grammar to achieve > 95% token acceptance rate
11
67
663
M2 Ultra serving Q8_0 LLaMA-v2 70B to 4 clients in parallel
16
67
638
Top quality post on r/LocalLLaMA today 😅.Btw, great subreddit!

9
53
630
shower thought : drop the position embeddings, rewrite the transformer using complex numbers, encode the position information in the complex phase. ref : see how MRI phase encoding works.
31
25
620
Serving 8 clients in parallel on A100 with llama.cpp. Model: Codellama 7B F16.System prompt: 305 tokens.Requests: 128.Max sequence length: 100.Continuous batching: enabled. Average speed ~484 t/s (including prompts and generated tokens)
17
63
592

llama.cpp is standing ground against the behemoths. The CUDA backend is contained in a single C++ file so it allows for very easy deployment and custom modifications. (pp - prefill, tg - text gen)


Trying out the new TensorRT-LLM framework and get some pretty good performance out of the box with 3090s. 107 tokens/sec int8 and 54 tok/sec bf16 for llama-2 7B models (not much work to setup either). Get 160+ tokens/sec on 2x3090s (these are just batch_size=1)

12
47
570
2,3,4,5 and 6-bit quantization methods are now available in llama.cpp. Efficient inference implementation with ARM NEON, AVX2 and CUDA - see sample numbers in the screenshots.Big thanks to ikawrakow for this contribution. More info:.


13
75
564
Full GPU Metal inference with whisper.cpp. This is the Medium model on M2 Ultra, greedy decoding
15
53
562
Challenge accepted! 😀.

Achievement unlocked:. 100 tokens-per-sec, 4-bit Mistral 7B in MLX on an M2 Ultra

11
34
561
The GGUF file format is a great example of the cool things that an open-source community can achieve. Props to @philpax_ and everyone else involved in the design and implementation of the format. I'm thankful and happy to see that it finds adoption in ML.

At @huggingface, we are adding more support to GGUF (model format by @ggerganov). The number of GGUF models on the hub has been exploding & doesn't look like it is gonna slow down🔥.see more at:

11
65
502
ggml inference tech making its way into this week’s @apple M4 announcements is a great testament to this. IMO, Apple Silicon continues to be the best consumer-grade hardware for local AI applications. For next year, they should move copilot on-device.
The future of on-device inference is ggml + Apple Silicon. You heard it here first!.
15
47
547
Initial low-rank adaptation support has been added to llama.cpp. We now have the option to apply LoRA adapters to a base model at runtime. Lots of room for improvements and opens up possibilities for some interesting applications.
9
82
540
llama.vim : Neovim plugin for local text completion . (powered by llama.cpp)
24
70
542
Here are some inference numbers for Code Llama on M2 Ultra at different quantum levels using latest llama.cpp . pp - prompt processing.tg - text generation. Code Llama 7B

12
60
535
The ggml roadmap is progressing as expected with a lot of infrastructural development already completed. We now enter the more interesting phase of the project - applying the framework to practical problems and doing cool stuff on the Edge

Took the time to prepare a ggml development roadmap in the form of a Github Project. This sets the priorities for the short/mid term and will offer a good way for everyone to keep track of the progress that is being made across related projects

7
41
522
Can't help but feel the AI hype is oriented in a non-optimal direction. It's almost as if we had just discovered the FFT algorithm and instead of revolutionizing telecommunications, we are using it to build Tamagotchis. P.S. I'm only half joking 😄.
31
32
512
Took the time to prepare a ggml development roadmap in the form of a Github Project. This sets the priorities for the short/mid term and will offer a good way for everyone to keep track of the progress that is being made across related projects
10
38
489
New release: whisper.cpp v1.4. - Added 4-bit, 5-bit and 8-bit integer quantization.- Added partial GPU support via cuBLAS.
11
65
501
whisper.cpp now supports @akashmjn's tinydiarize models. These fine-tuned models offer experimental support for speaker segmentation by introducing special tokens for marking speaker changes.
16
64
501
Progress update on adding Core ML support to whisper.cpp. We can now run the small model with a 400ms time step quite efficiently thanks to evaluating the Encoder on the ANE
11
43
479
Interactive chat mode added to 🦙.cpp. It actually works surprisingly well from the few tests that I tried!. Kindly contributed by GH user Blackhole89

12
44
471




Initial tests with parallel decoding in llama.cpp. A simulated server processing 64 client requests with 32 decoding streams on M2 Ultra. Supports hot-plugging of new sequences. Model is 30B LLaMA F16. ~4000 tokens (994 prompt + 3001 gen) with system prompt of 305 tokens in 46s
16
52
463
Will be cancelling my Github Copilot subscription soon 🙃.
9
33
452
llama.vscode. (powered by Qwen Coder)
Make your Mac think faster 🧠🧠. Tomorrow I'll show you how to cancel your copilot subscription.
12
73
481

Here is what a properly built llama.cpp looks like. Running 7B on 2 years old Pixel 5 at 1 token/sec. Would be interesting to see how an interactive session feels like.

10
67
448
GGUF My Repo by @huggingface . Create quantum GGUF models fully online - quickly and secure. Thanks to @reach_vb, @pcuenq and team for creating this HF space!. In the video below I give it a try to create a quantum 8-bit model of Gemma 2B - it took about
24
89
456
Very clever stuff! Will be adding a llama.cpp example soon.

Introduce lookahead decoding:.- a parallel decoding algo to accelerate LLM inference.- w/o the need for a draft model or a data store.- linearly decreases # decoding steps relative to log(FLOPs) used per decoding step. Blog: Code:
7
39
450
ROCm support in llama.cpp. 4 months community effort enables AMD devices to run quantum LLMs with high efficiency. Really great to see the strong collaboration in this work!.
11
64
441
I think I can make 4-bit LLaMA-65B inference run on a 64 GB M1 Pro 🤔. Speed should be somewhere around 2 tokens/sec. Is this useful for anything?.
37
17
442
The plan for adding full-fledged GPU support in ggml is starting to take shape. Today I finally finished the ggml computation graph export / import functionality and demonstrated a basic MNIST inference on the Apple Silicon GPU using Metal.
8
64
431
I'm color-coding Whisper tokens based on their probs -- green means confident. All models behave in a similar way (first 3 images), except for Large V2. The probs are all over the place (4th image) 🤔. Do I have a bug or is this model somehow unstable?




15
27
438
4-bit integer quantisation in whisper.cpp / ggml. You can now run the Large Whisper model locally in a web page via WebAssembly SIMD.

11
65
435
Very cool experiment by @chillgates_ . Distributed MPI inference using llama.cpp with 6 Raspberry Pis - each one with 8GB RAM "sees" 1/6 of the entire 65B model. Inference starts around ~1:10. Follow the progress here:.

Yeah. I have ChatGPT at home. Not a silly 7b model. A full-on 65B model that runs on my pi cluster, watch how the model gets loaded across the cluster with mmap and does round-robin inferencing 🫡 (10 seconds/token) (sped up 16x)
11
73
431
napkin math ahead:. - buy 8 mac mini (200GB/s, ~$1.2k each).- run LLAMA_METAL=1 LLAMA_MPI=1 for interleaved pipeline inference.- deploy on-premise, serve up to 8 clients in parallel at 25 t/s / 4-bit / 7B. is this cost efficient? energy wise?. thanks to @stanimirovb for idea.
24
26
408
The new image segmentation model SAM by Meta looks extremely interesting.
16
14
406
"inference on your head".

inference on your head. mistral 7b (4bit quantized) running locally on apple vision pro
5
32
401
This is LLaVA 7B v1.5 running on M2 Ultra thanks to the amazing work of GH user monatis. I'm surprised this works so well - downloaded a few photos from my phone and every single one was accurately described. Mind is blown!.
4
36
402
"Wait, Georgi, how is this even possible?" you might ask. After all, the M2 Ultra only has 800GB/s bandwidth. Other people normally need 4 high-end GPUs to do this. The answer is: Speculative Sampling.
9
37
395
RWKV port in ggml by the community:. I haven't had the chance to look at this in details yet, but it feels great that people are picking up ggml and applying it to more and more models.
3
53
382
llama.vim is also pretty wild 🙃

7
43
377
Here I outline a potential strategy for adding GPU support to ggml. Not sure how feasible it is yet, but it could be a fun exercise for people with GPU programming experience.
6
47
372
Powered by: ggml / whisper.cpp / llama.cpp / Core ML .STT: Whisper Small.LLM: 13B LLaMA.TTS: @elevenlabsio . The Whisper Encoder is running on Apple Neural Engine. Everything else is optimized via ARM NEON and Apple Accelerate.
10
18
363
Playing some chess using voice. WASM whisper.cpp with a quantized tiny model + grammar sampling (by @ejones). Runs locally in the browser. Not perfect, but I think pretty good overall!. Try it here:
8
43
356
70B home assistant running on M2 Ultra at 15 t/s. I can now cancel my ChatGPT API subscription


19
23
346
To run the released model with latest llama.cpp, use the "convert-unversioned-ggml-to-ggml" python script and apply the following patch to llama.cpp. The latest llama.cpp offers significant performance and accuracy improvements in the inference computation


I'm excited to announce the release of GPT4All, a 7B param language model finetuned from a curated set of 400k GPT-Turbo-3.5 assistant-style generation. We release💰800k data samples💰 for anyone to build upon and a model you can run on your laptop!.Real-time Sampling on M1 Mac
6
47
344
Here are some Apple Silicon stats for llama.cpp. You can use these numbers to estimate the performance that you would get on your Mac for typical bs=1 cases.
10
50
345
So, someone just DM'd me on twitter a patch that improves the inference time by 10% on ARM NEON (i.e. Apple Silicon). Probably more people should go there and optimise this stuff .
5
26
343
Added a ggml example for using Cerebras-GPT. I think the sampling needs some work because I can't get it to generate coherent stuff yet. Using quantized 6.7B model. Here is the code and usage instructions if you want to play with it: .

7
38
341
Try the 4-bit model easily on your Mac (even in EU):



Llama 3.2 3B & 1B GGUF.
10
36
338
600 posts per day actually sound great for me. Some days I do feel I waste too much time here.
11
15
327
Some performance stats for llama.cpp on A-series chips (iPhone / iPad). We are collecting benchmarks for 1B, 3B and 7B models at different quantization levels. Can be used as a reference for the expected LLM performance on these devices.
5
44
323
Code Llama 34B using Q4_K_M quantization on a MacBook.

7
32
326
Great write-up. The CoreML branch speeds up just the Encoder. At the same time, the master branch already has additional ~2-3 factor of speed up in the Decoder thanks to recent work on llama.cpp. When we merge these 2 together, the performance will be mind blowing.

Hello Transcribe 2.2 with CoreML is out, now 3x-7x faster 🚀🥳. Blog post: App Store: #OpenAI #AI #Whisper #CoreML

9
29
319
Some good old airplane-mode programming. No copilot, no voice control, no AR/VR, no AI augmentations, no cybernetic implants. Just VIM and the sunrise

10
7
313
Let's bring llama.cpp to the clouds!. You can now run llama.cpp-powered inference endpoints through Hugging Face with just a few clicks. Simply select a GGUF model, pick your cloud provider (AWS, Azure, GCP), a suitable node GPU/CPU and you are good to go. For more info, check.

Wanna see something cool?. You can now deploy GGUF models directly onto Hugging Face Inference Endpoints!. Powered by llama.cpp @ggerganov . Try it now -->
9
45
313
What is the intuition of having the LLaMA layers to be the same size instead of, let's say increasing size: start with small hidden state and keep increasing as you go through the layers?. At layer 1, we have just a single token with no context - 4096 hidden state seems too big.
28
21
308