

Shayne Longpre
@ShayneRedford
Followers
5K
Following
6K
Media
194
Statuses
2K
Lead the Data Provenance Initiative. PhD @MIT. 🇨🇦 Prev: @Google Brain, Apple, Stanford. Interests: AI/ML/NLP, Data-centric AI, transparency & societal impact
Boston
Joined February 2015
Excellent breakdown by @kevinroose @nytimes of the recent shifts in web norms, and the consent to use its data for AI.
4
12
30
✨New Preprint ✨ How are shifting norms on the web impacting AI?. We find:. 📉 A rapid decline in the consenting data commons (the web). ⚖️ Differing access to data by company, due to crawling restrictions (e.g.🔻26% OpenAI, 🔻13% Anthropic). ⛔️ Robots.txt preference protocols

11
95
243

New Resource: Foundation Model Development Cheatsheet for best practices. We compiled 250+ resources & tools for:.🔭 sourcing data.🔍 documenting & audits .🌴 environmental impact.☢️ risks & harms eval.🌍 release & monitoring. With experts from @AiEleuther, @allen_ai,
4
148
617
✏️ AI Terminology Updates 2022 ➡️ 2024 . NLP ➡️ "language modeling".Multi-task training ➡️ instruction tuning.Finetuning ➡️ "post-training".Semantic parsing ➡️ API tool use.Robustness ➡️ Red teaming.Train/test split ➡️ train/train split.Transfer learning ➡️ "it's already in the.
21
78
563
📢Announcing the🌟Data Provenance Initiative🌟. 🧭A rigorous public audit of 1800+ instruct/align datasets. 🔍Explore/filter sources, creators & license conditions. ⚠️We see a rising divide between commercially open v closed licensed data. 🌐: 1/
9
148
457
We're releasing our 2nd lecture playlist for Evaluating Generative AI/LLMs, taught at @MIT. Intro to 3 challenge areas:. 1⃣ Bias & Toxicity.2⃣ Hallucination & Factuality.3⃣ Robustness & Consistency. 📽️: 1/🧵.
2
88
381
📢 A 🧵on the future of NLP model inputs. What are the options and where are we going? 🔭. 1. Task-specific finetuning (FT).2. Zero-shot prompting.3. Few-shot prompting.4. Chain of thought (CoT).5. Parameter-efficient finetuning (PEFT).6. Dialog . [1/]


10
81
369
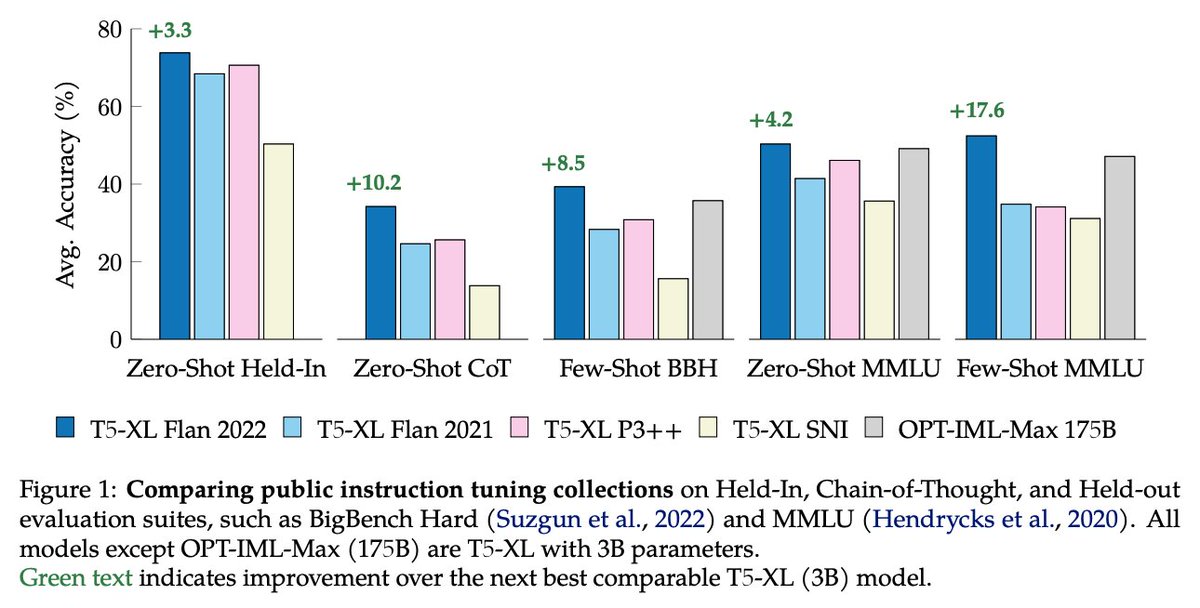
#NewPaperAlert When and where does pretraining (PT) data matter?. We conduct the largest published PT data study, varying:.1⃣ Corpus age.2⃣ Quality/toxicity filters.3⃣ Domain composition. We have several recs for model creators….📜: 1/ 🧵
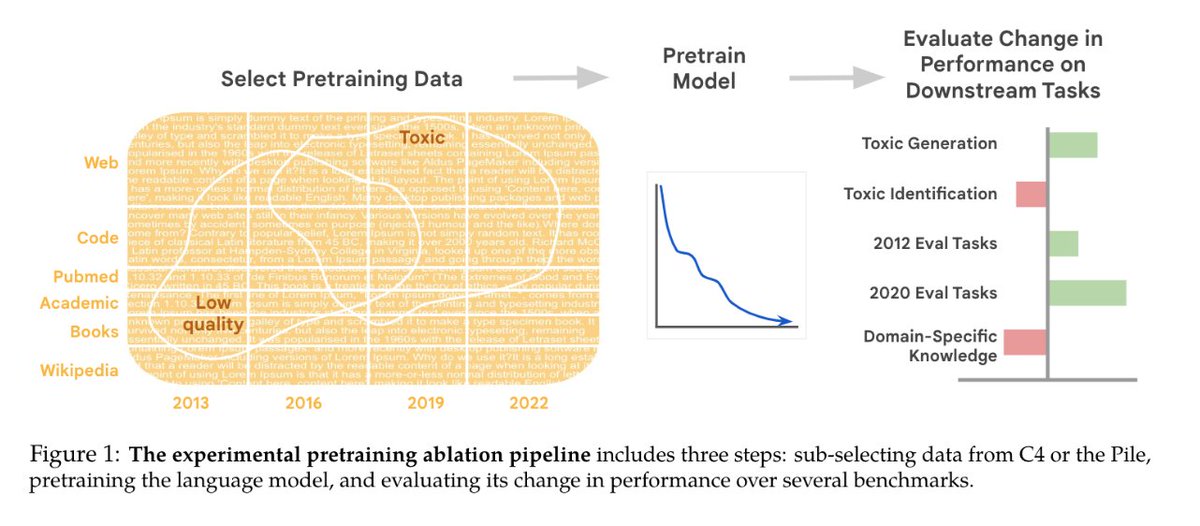
12
87
357

Independent AI research should be valued and protected. In an open letter signed by over a 100 researchers, journalists, and advocates, we explain how AI companies should support it going forward. 1/
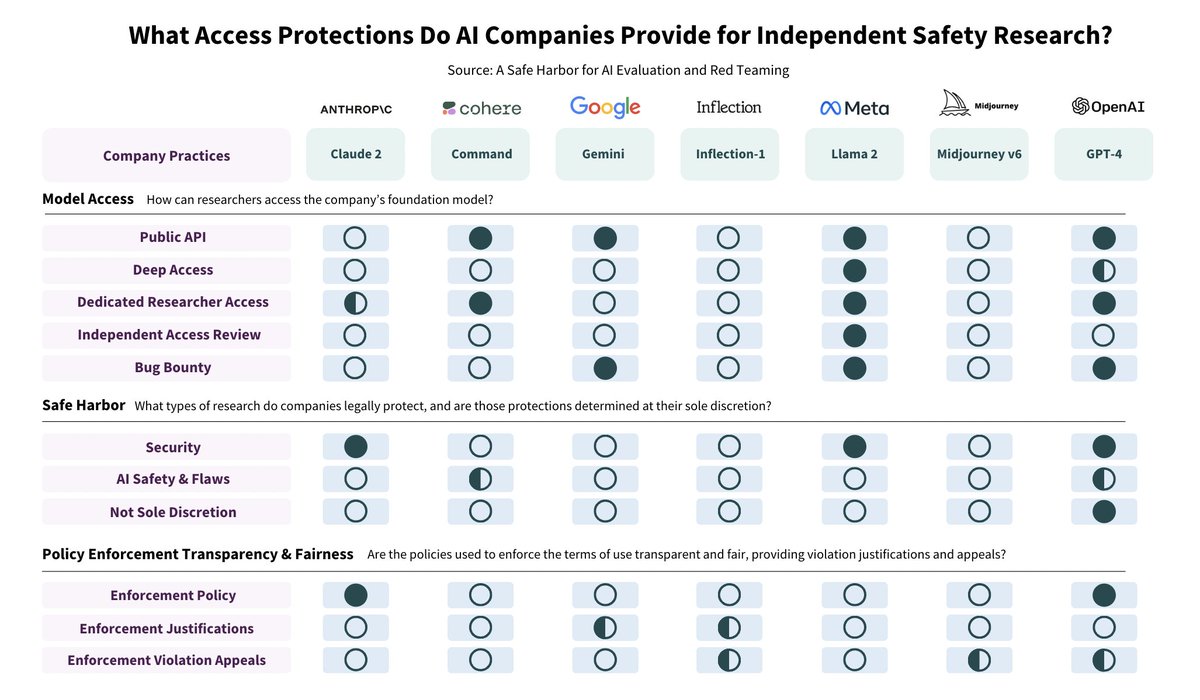
7
79
225
📢 A 🧵 on the Trends in NLP Datasets. What’s changed since SQuAD was all the rage in 2016? A: A LOT. 🔭. 1. Generic ➡️ Niche Tasks.2. Task-specific Training+Eval ➡️ Eval Only.3. Dataset ➡️ Benchmark ➡️ Massive Collections.4. Datasets ➡️ Diagnostics. 1/

4
46
224
A wave of new work shows how **brittle** "Alignment"/RLHF safety methods are. ⛓️ Prompt jailbreaks are easy.🚂 Finetuning away safety (even #OpenAI API) is simple and likely undetectable.🤖 LLMs can auto-generate their own jailbreaks. 1/ 🧵.
7
43
202
Grateful 🌟Consent in Crisis: The Rapid Decline of the AI Data Commons🌟 was accepted to @NeurIPSConf 2024!. This was a massive undertaking to audit 14k+ websites underneath popular pretraining corpora. See you in Vancouver!

7
42
177
I started compiling training, inference, and data accessibility for the major LLMs. 1⃣ Is OSS? Has Playground? API?.2⃣ Is pretraining data open? searchable?.3⃣ Links, notes, etc. Please take a look, and LMK whats missing!. 1/.
6
35
167
Interested in how LLMs are really used?. We are starting a research project to find out! In collaboration w/ @sarahookr @AnkaReuel @ahmetustun89 @niloofar_mire and others. We are looking for two junior researchers to join us. Apply by Dec 15th!.
5
37
143
📢 Excited to announce the expanded 🌟Responsible Foundation Model Development Cheatsheet🌟. ➡️ A Survey & Review of Tools🛠️& Resources🧮🗝️📚. ➡️ We ask what1⃣what responsible practices developers can adopt, &2⃣ what tools are missing, misused, or under-used in the AI dev

1
45
130
🚨OpenAI publicly revoked ByteDance’s API access for training on API data. What ripple effects could come from this precedent?. We already know synthetic API-generated data has grown massively: Many startups depend on it…. 1/.
5
17
124
A 🧵 on my favorite, influential works on "Data Measurements". 🚂 Datasets drive AI progress.📚 But. massive datasets remain impenetrable & poorly understood for *years*.🔍 Data forensics uncover their mysteries. 1/.
1
30
127
📢 For those who missed @naacl, here’s a selection of papers I really enjoyed! 📚. Mainly multi-linguality, prompting, fairness and ethics, but some other ideas too! #NAACL2022. 🧵 1/.
1
19
122
🔭 New perspective piece at #ICML2024 & @MIT AI Impact Award winner🎉. 🌟Data Authenticity, Consent, and Provenance for AI Are All Broken: What Will It Take to Fix Them?🌟. w/ @RobertMahari @naana_om @wwbrannon @TobinSouth @katyilonka @alex_pentland @jad_kabbara. 🔗:

10
38
121
Too many new papers to read this week? 📚. See the key take-aways of our new Flan-PaLM work in a 7⃣ minute video. ➕Scaling to 540B model.➕Scaling finetuning to 1.8K tasks.➕CoT tuning. ➡️. 🌟MMLU SOTA 75.2%.🌟Better usability.🌟Better CoT Reasoning. 🌐:
3
27
116

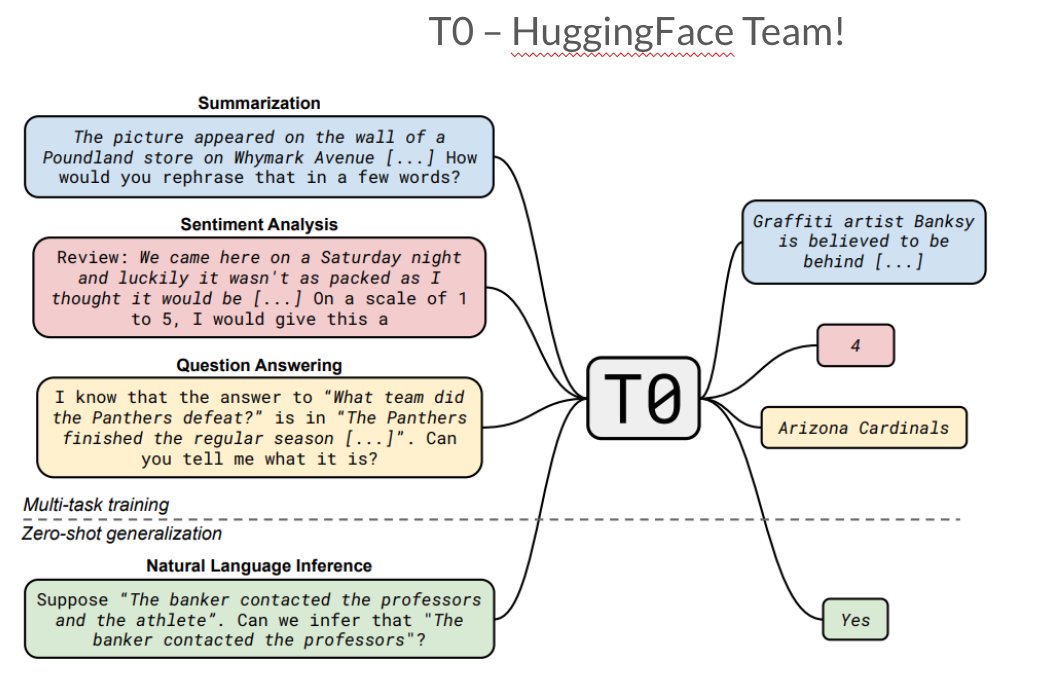
Sharing my *rough* slides from a @CCCatMIT February reading group. Covers "NLP Training Trends for Large Language Models" (LLM) and a survey of 4 new interesting papers: FLAN, T0, ExT5, MetaICL!. 📚: [1/6]

2
23
111
📢📜#NLPaperAlert 🌟Knowledge Conflicts in QA🌟- what happens when facts learned in training contradict facts given at inference time? 🤔. How can we mitigate hallucination + improve OOD generalization? 📈. Find out in our #EMNLP2021 paper! [1/n].

4
16
113
📢 We are expanding the instruct/align datasets in the 🌟Data Provenance Collection🌟. Are there any great/new ones not covered?. Available at:

8
29
106
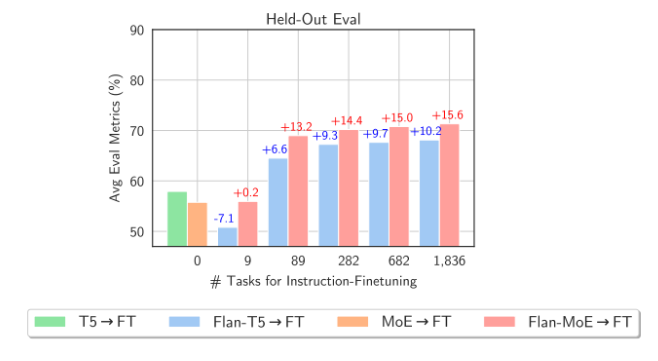
We can now see why @OpenAI allegedly uses MoE models -- stronger performance📈 for fewer FLOPs 🚀. Awesome work led by @shengs1123 evaluates instruction tuned MoE models.

A Winning Combination for Large Language Models . TL;DR: Did you find MoE models generalize worse than dense models on downstream tasks? Not any more at the age of instruction tuning! . Surprisingly, we see the “1 + 1 > 2” effect when it comes to MoE + Instruction Tuning. [1/4]
3
14
97
The Flan Collection is now available for direct download. 🌐: Thank you to the prolific @EnricoShippole for generating 10s of GBs of tasks, and @Hou_Le for several bug fixes & improvements!.
1
12
95
Excited to moderate 2 fantastic panels today with @yizhongwyz and @qinyuan_ye at the #NeurIPS2023 @itif_workshop Instruction Workshop!. Looking forward to chatting with you there!. Schedule:


1
13
50
Recorded the 2nd part of my talk at @databricks, covering Results & Take-Aways from training Flan-T5 and Flan-PaLM 🍮. 📽️: (11m). ➡️ In short, how far can we get just with academic datasets (w/o ChatGPT distillation or human preferences)?. 1/.
1
16
94
Super appreciative of the recognition from #NAACL2024 — our Pretrainer’s Guide won an 🌟Outstanding Paper Award🌟🏆 . This was a year long analysis into pretraining age, quality & toxicity data filters. Gratitude to our team 🙏🏼 @gyauney @emilyrreif @katherine1ee @ada_rob.
#NewPaperAlert When and where does pretraining (PT) data matter?. We conduct the largest published PT data study, varying:.1⃣ Corpus age.2⃣ Quality/toxicity filters.3⃣ Domain composition. We have several recs for model creators….📜: 1/ 🧵
12
18
94
There are few options for evaluating multilingual question answering outside of English, and especially few for open domain question answering. Yi Lu, @jodaiber, and I are excited to release an Open QA evaluation set, spanning 26 languages. [1/n].

1
34
84
Headed to 🛬🇦🇹 Vienna #ICML2024 . Reach out if you'd like to chat or catch up!. Work together w/ collaborators:. - A Safe Harbor for AI Evaluation ⛴️( -- Tuesday 10:30 am Oral. - On the Societal Impact of Open Foundation Models ( --.
9
11
90
✨New Report✨ Our data ecosystem audit across text, speech, and video (✏️,📢,📽️) finds:. 📈 Rising reliance on web, synthetic, and YouTube data. 🛑 80%+ datasets carry hidden restrictions. 🌍 Relative representation in languages and creators has not improved for 10+ yrs.
1
42
86
Recorded the 1st part of my talk on the Data and Methods used in the Flan Collection 🍮 (accepted to @icmlconf Honolulu 🏝️). 📽️: (12m). Thanks again to @vagabondjack and @databricks for inviting me!. 1/.
2
9
78
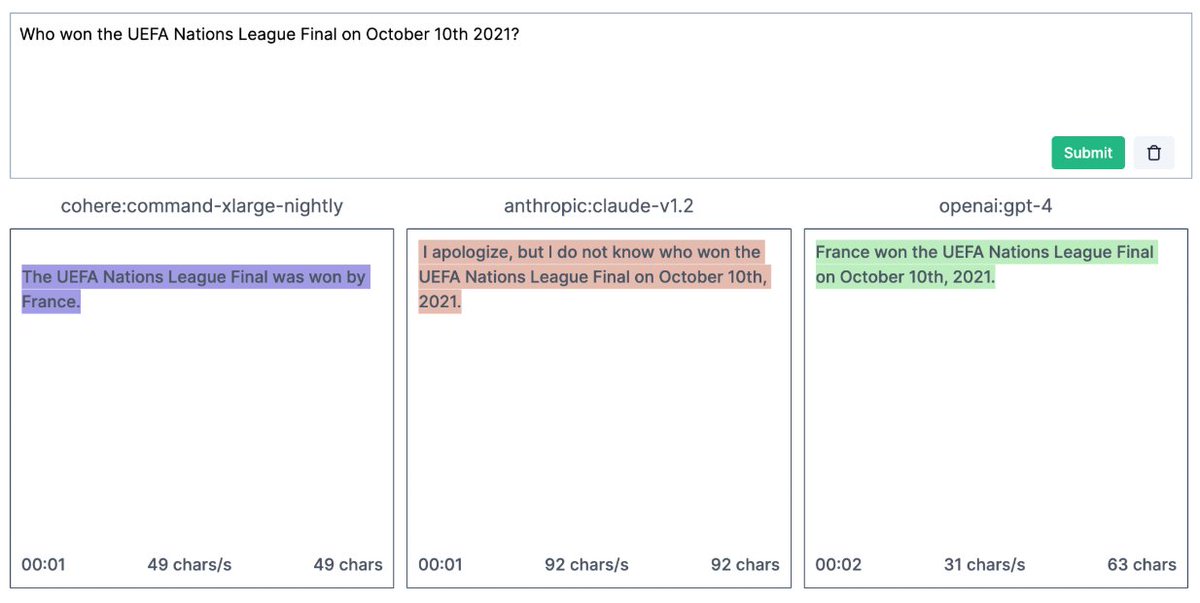
What dates📅 can @OpenAI, @AnthropicAI, @CohereAI models reliably answer questions for?🔭. I binary-search through "future" Wiki events to find out. Results ❌🟰❌documentation:. #GPT4 ➡️~Dec 19 ('21).#ChatGPT ➡️~Oct 24.Claude v1.2➡️~Oct 10.Cohere XL Nightly➡️~Apr 24 ('22). 1/🧵
3
11
78
📢📜#NLPaperAlert 🌟Active Learning over Multiple Domains in NLP🌟. In new NLP tasks, OOD unlabeled data sources can be useful. But which ones?. We try active learning ♻️, domain shift 🧲, and multi-domain sampling🔦 methods to see what works [1/].

2
18
74


Honored for the Data Provenance Initiative to be awarded the Infrastructure Grant Award, by @mozilla! 🎉🎉🎉. As part of this grant, we were invited to present at MozFest House Amsterdam, where we gave an early look at trends in the AI data supply chain:. 📽️

7
13
75
📢 What is the future of third-party AI audits, red teaming, and evaluation?. Researchers at @Stanford @PrincetonCITP and @MIT are co-organizing a virtual workshop on Oct 28th. 🌐: RSVP: 1/🧵


2
29
73
Awesome round-up on synthetic data by @natolambert!. Related: we found a massive increase in synthetic data use in 2023, enabling training on more diverse tasks w/ longer outputs. 🔗:


The mega-post on synthetic data. I leave no stone unturned:.* What synthetic data is for LLMs.* Instructions vs preferences vs critiques.* Constitutional AI review & insight.* Mistral & other's use in pretraining.* OpenAI Superalignment.* Examples in the open.* other topics

2
9
69
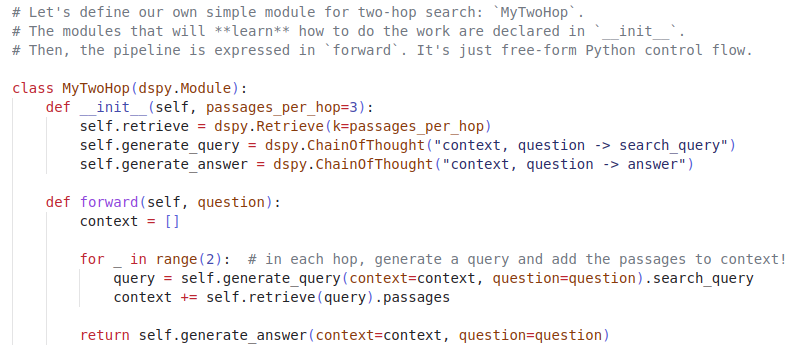
This framework is very powerful. Forget Langchain, if you want to create a pipeline of modules I would try DSPy (e.g. chaining multi-hop retrieval, w/ APIs, your own models, and promoting techniques).

🚨Announcing 𝗗𝗦𝗣𝘆, the framework for solving advanced tasks w/ LMs. Express *any* pipeline as clean, Pythonic control flow. Just ask DSPy to 𝗰𝗼𝗺𝗽𝗶𝗹𝗲 your modular code into auto-tuned chains of prompts or finetunes for GPT, Llama, and/or T5.🧵.

0
5
68
Touching down in Vancouver 🛬 for #NeurIPS2024!. I'll be presenting our "Consent in Crisis" work on the 11th: Reach out to catch up or chat about:.- Training data / methods.- AI uses & impacts.- Multilingual scaling.
2
16
70
Take a break from Twitter politics and checkout some new LLM responses!. 🍰🌴 FLAN-PaLM 🍰🌴 Response of the Day #1. A pretty nice example of Complex Verbal Reasoning

5
5
64
🔭 Use instruction tuning 🛠️ for better results 🎯 and reduced compute costs 🍃. A 🧵. Q: Communally what is costlier, finetuning (FT) or pretraining (PT)? . A: FT. Why?.1⃣Top 50 NLP models are 70% all downloads (@huggingface).2⃣50 PTs ➡️ 290M+ FTs (assuming 1 FT/download). 1/

1
12
63
Just diagnosed with a severe case of ChatGPT Twitter fatigue.
3
2
59
➡️ It's promising these results don't use any RLHF data, or human "alignment", which is expensive to collect and less publicly available. We hope this release supports the open source community, and improves instruction tuning methods and research!. 7/.
4
2
56
🚨 Update: Super excited to work with @barret_zoph and @_jasonwei this summer as a @GoogleBrain Student Researcher. Feeling fortunate to work with such accomplished ML/NLP researchers and an awesome team!.
3
3
58
Recorded the final part of my talk at @databricks, covering Data Selection Trade-Offs for Instruction Tuning. 📽️: (10m). Trade-offs:.1⃣ Permissive vs Restrictive Licensing.2⃣ Traditional NLP performance vs creative generation. Are these correlated?. 1/.
2
11
55
Was a little nervous for this, but grateful to discuss our work with @juleshyman on @YahooFinance!. @RobertMahari and I discuss emerging challenges for data creators and developers in the AI supply chain—part of the Data Provenance Initiative recent study:

The content used to train AI models used to be plentiful on the internet, but now the sources of that data are cracking down on who has access, according to a study. @ShayneRedford and @RobertMahari discuss how this could impact AI moving forward:
5
6
54
📢 #NLPaperAlert 🌟Active Learning Over Multiple Domains in Natural Language Tasks 🌟. To appear at Workshop on Distribution Shifts (DistShift) at #NeurIPS2022 later this week!. 📜: This is honestly the hardest ML problem I’ve ever worked on. 👉🧵

2
13
53
Excited to see our 🍮Flan-Palm🌴 work finally published in @JmlrOrg 2024!. Looking back, I see this work as pushing hard on scaling: post-training data, models, prompting, & eval. We brought together the methods and findings of many awesome prior works, scaled them up, and.
1
9
52
ByteDance v OpenAI⚠️, LAION-5B CSAM☢️ & NYT v OpenAI🛑 illustrate rising lockdown + legal risk on data. Need more informed training data selection?. 🔗 Detailed licenses, terms, sources, properties. 📢 Come help us build it! All open sourced. 1/ 🧵.
1
19
52
The 🌟Data Provenance Initiative🌟 has added dozens of new math 🧮 dataset collections!. @ArielNLee @manandey @mhamdy_res have added:.🦆Open Platypus (10).🧑🔬MetaMathQA (8).🦣Mammoth Math Instruct (13). 🔗 1/.
1
17
51
🚨 New paper + models!. Evaluating LLMs using closed-source LLMs has limited transparency, controllability, and affordability. Incredible work by @seungonekim significantly improves all these factors, w/ open models for either relative or absolute response scoring. ⬇️.

#NLProc.Introducing 🔥Prometheus 2, an open-source LM specialized on evaluating other language models. ✅Supports both direct assessment & pairwise ranking. ✅ Improved evaluation capabilities compared to its predecessor. ✅Can assess based on user-defined evaluation criteria.

1
11
52
🌿Aya🌿 Dataset & mega-multilingual LLM is out!🚀. By far the most international & exciting collaboration I'm lucky to be part of. @CohereForAI meetings often spanned 12+ time zones. Amazing leadership by Madeline, @mziizm @ahmetustun89 @sarahookr ++. 🔗:

Today, we’re launching Aya, a new open-source, massively multilingual LLM & dataset to help support under-represented languages. Aya outperforms existing open-source models and covers 101 different languages – more than double covered by previous models.
1
11
51
The latest wave of moves to @OpenAI @AnthropicAI @CohereAI etc from Big Tech seems to herald a new chapter to the so called AI/ML “academic brain drain”. Academia ➡️ Industry ➡️ Startup.
1
5
48
In March, we were privileged to host @_jasonwei's guest lecture on “Emergence in Large Language Models”, for broader audiences, covering:. ➡️ Intuitions, abilities and limitations.➡️ Scaling & trends.➡️ Emergence, Chain-of-thought, Flan. 📽️: 1/.
1
6
49
Excited to see "Considerations for governing open foundation models" published to @ScienceMagazine. Led by @RishiBommasani @sayashk, this work has had enduring influence in understanding risks from open vs closed AI systems. 1/

3
9
48
📢 The🌟Foundation Model Transparency Index🌟 scores 10 developers on 💯 indicators. 1⃣ All 10 score poorly, particularly Data, Labor, Compute. 2⃣ Transparency is possible! 82/100 are scored by >1. 3⃣ Transparency is a precondition for informed & responsible AI policy. 1/

4
15
47
If Flan-T5 XXL (11B) was too small, there’s a new and improved 20B Flan-UL2 open sourced, by @YiTayML!. The new best Open Source model on MMLU and Big Bench Hard.

New open source Flan-UL2 20B checkpoints :).- Truly open source 😎 No forms! 🤭 Apache license 🔥.- Best OS model on MMLU/Big-Bench hard 🤩.- Better than Flan-T5 XXL & competitive to Flan-PaLM 62B. - Size ceiling of Flan family just got higher! . Blog:
0
9
46
🌟Data Selection🌟 for text has quickly become one of the most important choices for LLMs ✍️. @AlbalakAlon comprehensively formalizes & surveys data filtering ✂️, mixing🥣, dedupliation 🧑🤝🧑, & selection for a variety of criteria. Loved contributing to the Multi-task/Instruction.

{UCSB|AI2|UW|Stanford|MIT|UofT|Vector|Contextual AI} present a survey on🔎Data Selection for LLMs🔍. Training data is a closely guarded secret in industry🤫with this work we narrow the knowledge gap, advocating for open, responsible, collaborative progress.

0
4
46
Thanks for having me!. Enjoyed talking to @vagabondjack and the awesome Databricks teams behind Dolly v2 about instruction tuning and open sourcing. Will share out my slides and a video soon!.

Happening now! @ShayneRedford speaking on LLM's as part of the Data Talks speaker series at Databricks. Will be tweeting insights and slides from our inspiring speaker as we go.

1
5
45
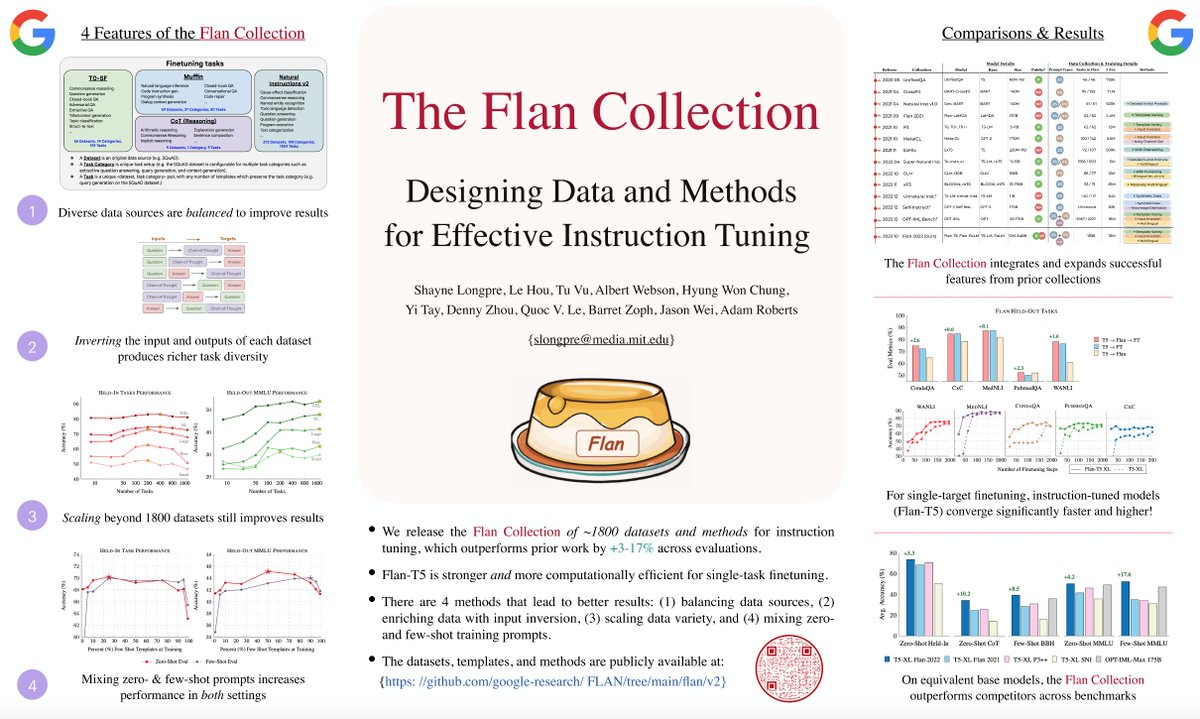
#NLPaperAlert Proud of our new work! . New findings, SOTA results, and, my personal favourite, 🌟 Open sourcing new models 🌟, significantly better than current T5s!.

New open-source language model from Google AI: Flan-T5 🍮. Flan-T5 is instruction-finetuned on 1,800+ language tasks, leading to dramatically improved prompting and multi-step reasoning abilities. Public models: Paper:

2
5
44
Read our blog post on @knightcolumbia here: w/ @sayashk @kevin_klyman @ashwinforga @RishiBommasani @random_walker @percyliang @PeterHndrsn.
0
12
42
@KreutzerJulia et al. break down multilingual web data (CCAligned, ParaCrawl, WikiMatrix, OSCAR, mC4), by language representation, quality, and characteristics:. Quality at a Glance: An Audit of Web-Crawled Multilingual Datasets. 📜 10/


1
3
44
The 🌟Flan Collection🌟 (1st used in Flan-PaLM :. ➕ Merges Flan 2021, P3, NIv2, CoT instruction-datasets into 1800+ dataset collection.➕ Data augmentations and mixing strategies.➕ 100s new templates. 2/

1
4
43
Is it just me or is the “AGI” misinfo really peaking lately. Below: Repurposes and misquotes other speculative mis-infographic. And this tweet has massive engagement.

5
4
41
Excited to co-host the Instruction Tuning & Instruction Following (ITIF) Workshop at #NeurIPS2023. 👷🛠️🤖 An incredible line up of topics and speakers. ➡️ Submission opening soon: Stay tuned!.

Excited to announce the Workshop on 👷🛠️🤖 Instruction Tuning & Instruction Following 👷🛠️🤖 (ITIF) at #NeurIPS2023!. 📅 Join us on Dec 15 in New Orleans.🛠️ Submit by Oct 1.👷 See speaker lineup.🔗 1/


0
5
43
Is it just me, or are a lot of the best new NLP papers on my feed all getting accepted to *Findings* of #EMNLP2022?. Findings >= Full conference?.
2
0
41

📢 Want to automatically generate your bibtex for 1000s of @huggingface text datasets?. @chien_vu1692 just added this feature + data summaries for:. ➡️ huge collections like Flan, P3, Aya. ➡️ popular OpenAI-generated datasets.➡️ ~2.5k+ datasets & growing. 🔗:

0
15
41
@soniajoseph_ Votes for:. ➡️ Model compression/acceleration.➡️ Interpretability.➡️ Multimodalities.➡️ Human-AI interaction (unintended consequences, human health, etc).
1
1
41
✨New Paper, Model, Data, & Eval ✨ What’s the best completely public, commercially-viable code LLM?. ➡️Introducing, 🐙OctoCoder 🐙, w/ a new instruction code dataset, and expanded task+language HumanEval. ➡️Led by @Muennighoff, these achieve (non-closed) 🌟SotA🌟!. 1/.

How to instruction tune Code LLMs w/o #GPT4 data? Releasing. 🐙🤖OctoCoder & OctoGeeX: 46.2 on HumanEval🌟SoTA🌟of commercial LLMs.🐙📚CommitPack: 4TB of Git Commits.🐙🎒HumanEvalPack: HumanEval extended to 3 tasks & 6 lang. 📜💻1/9


1
8
39

Today we’re releasing a new collection of tasks, templates and methods for instruction tuning of #ML models. Training on this collection can enable language models to reason more competently over arbitrary, unseen tasks. Learn all about it at:

0
3
38
📢 To students applying to the @MIT Media Lab, especially first generation or low income households:. Current students are offering application support!. (I realize not all applicants are on here, so plz spread the word if you know anyone interested!)

0
13
37
Heading to @naacl today 🛫. So excited for my 1st in-person conference since NeuRIPS 2019!. Please reach out to grab coffee and talk research! #NAACL2022.
0
1
36
This work is unique in that every collaborator co-led a section or modality, bringing their expertise without which the cheatsheet wouldn’t be possible. Special thanks to @BlancheMinerva @soldni @YJernite @AlbalakAlon @gabriel_ilharco @sayashk @kevin_klyman @kylelostat.
0
3
35
Looking for permissively licensed biomedical🧬text data?. @mhamdy_res has added several data collections to the 🌟Data Provenance Initiative🌟:. ➡️ MedInstruct.➡️ ChatDoctor.➡️ Medical Meadow.➡️ PMC-LLaMA Instructions. 🔗 1/.
2
7
35
Funny how we got it all flipped. AI in Science Fiction 📚🤖: highly analytical/factual, but struggles with humor and emotion. (eg Data from Star Trek). AI now 💬: great humor and creativity, but logically inconsistent/factually negligent. (eg #ChatGPT).
2
4
35
@yizhongwyz & @qinyuan_ye moderating the 2nd @itif_workshop panel now. @nazneenrajani @colinraffel @haozhangml and @tatsu_hashimoto provide their spicy🌶️ takes on evaluation, open vs closed, and how we close the performance gap!

0
6
32
Context: A Crisis in Data Transparency. ➡️Instruct/align finetuning often compiles 100s of datasets. ➡️How can devs filter for datasets without legal/ethical risk, and understand the resulting data composition?. 2/

2
5
33
🚨 New #ICML2024 position piece. The most overlooked risks of AI stem from autonomous weaponry. For 4 reasons:.1⃣ Arms race w/ ⬇️ human oversight.2⃣ Reduces cost of starting conflicts.3⃣ Evades accountability.4⃣ Battlefield errors aren’t considered costly. See our work led by

3
14
33
@suchenzang Respectfully, this feels a little unfair. Three awesome, nuanced threads (by Aran, Yizhong, and the new paper Yi cites, linked below) all suggest different training data, architecture, and vocab each lead to different advantages, without any **one size fits all**. T0, Flan-T5,.
1
0
32
Just found out "MKQA" (our 26 language QA dataset) is already on @huggingface Datasets -- even before I got around to it this holiday break!. Check it out, and thanks @ceyda_cinarel for adding it!.
0
8
32
Q: But why are the results strong?. Our breakdown of the Flan Collection shows *why* it works. The most important methods:. 🌟Finding 1🌟 Fine-tuning on zero-shot and few-shot prompts together significantly improves both settings (not a trade-off)!. 4/

1
2
32
In Honolulu for #ICML2023 23-29 🏝️🌺. Msg me if you'd like to meet/chat!. Presenting the Flan Collection🥮 (Wedn 11-12:30), and a new initiative on Data Provenance at the Workshop, Saturday!.
0
3
32
🌟Finding 3 🌟 The Flan-T5 model converges higher and faster than T5 on single-task fine-tuning. ➡️ Recommendation: Use Flan-T5 as your base model for new tasks. ✅Better computational-efficiency and performance!. 6/


5
3
31
This yields the best performing instruction tuning collection that has been compiled and released into one repo. See our survey Figure of the prior works we built on to produce this compilation. 3/
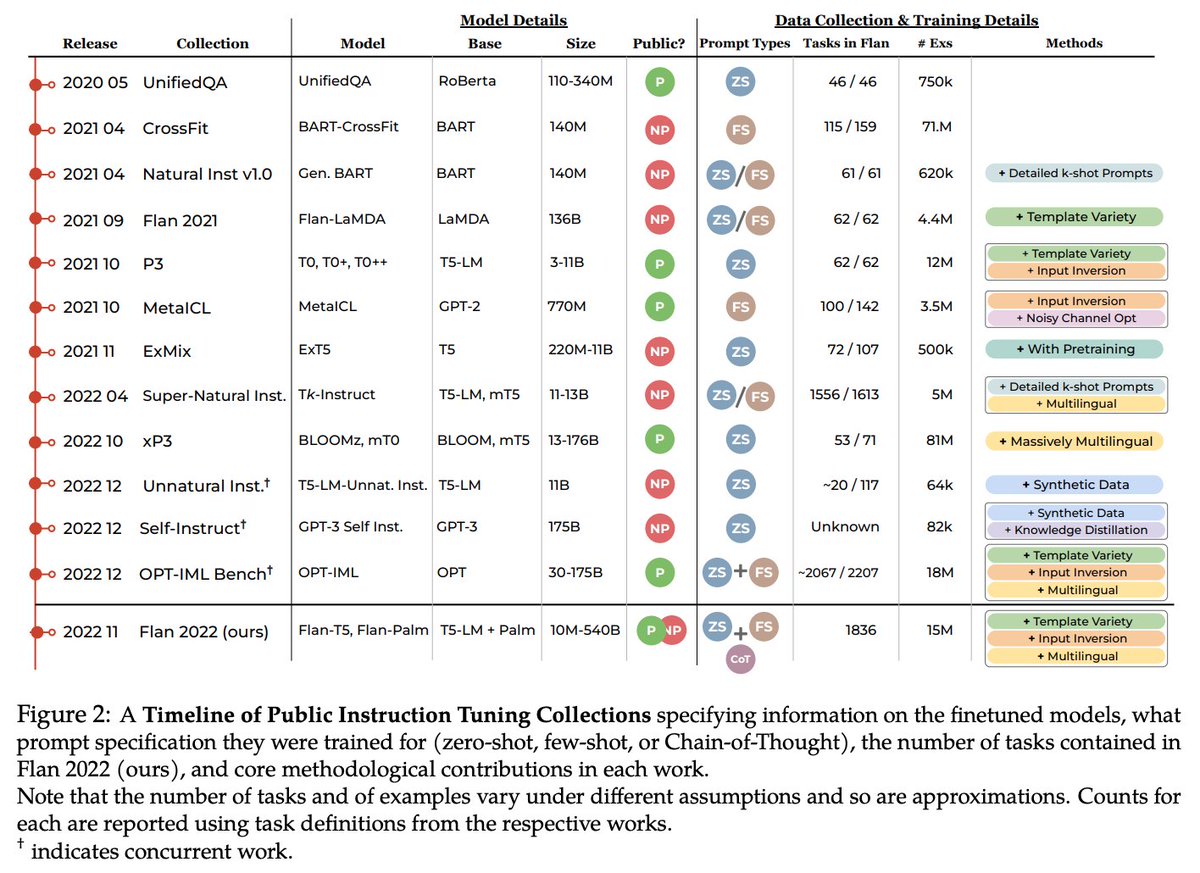
2
2
30
📢 We're planning to rapidly expand the coverage of finetuning datasets in the Data Provenance Initiative. ➡️Our Goal: provide detailed source+license annotations for all popular instruct/align datasets. 🌟If you'd like to contribute, reach out!🌟. 1/.
📢Announcing the🌟Data Provenance Initiative🌟. 🧭A rigorous public audit of 1800+ instruct/align datasets. 🔍Explore/filter sources, creators & license conditions. ⚠️We see a rising divide between commercially open v closed licensed data. 🌐: 1/
4
11
31
📢 Check out @_anthonychen and my invited talk at the at the @USC_ISI Natural Language Seminar:. 📜 "The Data Provenance Initiative: A Large Scale Audit of Dataset Licensing & Attribution in AI". Thank you @HJCH0 for hosting!.
2
10
31
Really excited to see our Pretrainer's Guide work get a shoutout in this amazing new Dataset!. "Quality" and "Toxicity" filters for pretraining data can have a massive impact and is important to get right.

We are excited to release RedPajama-Data-v2: 30 trillion filtered & de-duplicated tokens from 84 CommonCrawl dumps, 25x larger than our first dataset. It exposes a diverse range of quality annotations so you can slice & weight the data for LLM training.

2
4
30
QA models are surprisingly accurate on partial, OOD inputs. Yi, @chrisdubois, and I ask what factors affect this? Perplexingly we find this phenomenon invariant to random seed, architecture, pretraining, even training domain!. See our short preprint [1/5].
1
8
30
The new bible for Transformer architecture/objective choices!.

I've found myself referring to this table in the appendix of our recent paper ( A LOT so I thought I'd point it out for those who might benefit from it. Basic upshot is that ED:MLM works really well, especially for classification tasks, even in 0shot.

0
2
30
Congrats to a phenomenal team of collaborators! 👏🏼🎉.
🪴 We’re thrilled about the acceptance of "Aya Model: An Instruction Finetuned Open-Access Multilingual Language Model" - major congrats to @ahmetustun89, @viraataryabumi, @yong_zhengxin, @weiyinko_ml, @mrdanieldsouza, @lekeonilude, @NeelBhandari9, @singhshiviii, Hui-Lee Ooi,

0
7
28
📢#NLPaperAlert Incredible work led by @seungonekim @jshin491 & Yejin Cho!. ➡️ Ranking responses is subjective. ➡️ Do you prefer short vs long, formal vs informal, creative vs precise responses?. ➡️ 🔥Prometheus 🔥➡️Open LM trained to respect custom criteria. Check it out!.
Excited to present 🔥Prometheus, a fully open-source evaluator LM that is on par with GPT-4 evaluation when the “appropriate” reference materials are appended!. * Could generalize to customized score rubrics.* Shows high correlation with both human evaluators & GPT-4 evaluation.
0
6
28