

Seungone Kim
@seungonekim
Followers
1,116
Following
826
Media
38
Statuses
539
Ph.D. student @LTIatCMU working on (V)LM Evaluation & Systems that Improve with (Human) Feedback | Prev: @kaist_ai @yonsei_u @NAVER_AI_Lab @LG_AI_Research
Pittsburgh, PA
Joined November 2021
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
#บวงสรวงซีรีส์ปิ่นภักดิ์
• 648108 Tweets
THE LOYAL PIN WORSHIP
• 624335 Tweets
Argentina
• 352842 Tweets
#T20WorldCupFinal
• 316758 Tweets
Chile
• 254761 Tweets
Canadá
• 250112 Tweets
#UFC303
• 137611 Tweets
Ortega
• 109089 Tweets
Conmebol
• 72678 Tweets
Klay
• 68536 Tweets
Lautaro
• 66491 Tweets
Isabelle
• 55363 Tweets
Garnacho
• 53756 Tweets
#CopaAmerica2024
• 53321 Tweets
Roldán
• 50635 Tweets
LILIES FOR LISA
• 44836 Tweets
Paredes
• 39489 Tweets
設営完了
• 34884 Tweets
ジュンブラ
• 28247 Tweets
Diego Lopes
• 26074 Tweets
ドジャース
• 22905 Tweets
YOASOBI
• 22787 Tweets
風都探偵
• 21960 Tweets
Anthony Smith
• 18045 Tweets
Milad
• 15300 Tweets
Dan Ige
• 13683 Tweets
Montiel
• 13014 Tweets
Trainee Day
• 12162 Tweets
Celso
• 11429 Tweets
Gareca
• 10896 Tweets
ラジエル
• 10687 Tweets
ビギンズナイト
• 10545 Tweets



















Pinned Tweet

🤔How can we systematically assess an LM's proficiency in a specific capability without using summary measures like helpfulness or simple proxy tasks like multiple-choice QA?
Introducing the ✨BiGGen Bench, a benchmark that directly evaluates nine core capabilities of LMs.

6
54
182
Excited to present 🔥Prometheus, a fully open-source evaluator LM that is on par with GPT-4 evaluation when the “appropriate” reference materials are appended!
* Could generalize to customized score rubrics
* Shows high correlation with both human evaluators & GPT-4 evaluation
9
51
347
🔥I will be joining
@CarnegieMellon
@LTIatCMU
this upcoming Fall, working with
@gneubig
and
@wellecks
on evaluating LLMs & improving them with (human) feedback!
Can't wait to explore what lies ahead during my Ph.D. journey☺️
31
7
352
🚨 New Instruction Data Alert!
We introduce 🌟CoT Collection🌟, an instruction dataset including 52 times more CoT rationales and 177 times more tasks compared to previously available CoT datasets.
8
53
250
#NLProc
Introducing 🔥Prometheus 2, an open-source LM specialized on evaluating other language models.
✅Supports both direct assessment & pairwise ranking.
✅ Improved evaluation capabilities compared to its predecessor.
✅Can assess based on user-defined evaluation criteria.

3
41
161
🤔How could you evaluate whether your Vision Language Model (VLM) is closely reaching the capabilities of GPT-4V?
We’re excited to present 🔥Prometheus-Vision, the first open-source VLM specialized for evaluating other VLMs based on fine-grained scoring criteria, with co-lead

3
43
148
Super excited to share that our CoT Collection work has been accepted at
#EMNLP2023
! If you want to make your LM better at expressing Chain-of-Thoughts, take a look at our work🙂 See you in Singapore!! 🇸🇬🇸🇬
🚨 New Instruction Data Alert!
We introduce 🌟CoT Collection🌟, an instruction dataset including 52 times more CoT rationales and 177 times more tasks compared to previously available CoT datasets.
8
53
250
2
16
57
Super excited to share that Prometheus is accepted at ICLR! See you all in Vienna 🇦🇹
Also, check out our recent work on Prometheus-Vision expanding to the multi-modal space! It's the first open-source VLM that evaluates other VLMs:
Excited to present 🔥Prometheus, a fully open-source evaluator LM that is on par with GPT-4 evaluation when the “appropriate” reference materials are appended!
* Could generalize to customized score rubrics
* Shows high correlation with both human evaluators & GPT-4 evaluation
9
51
347
1
5
56
I'll be presenting Prometheus
@iclr_conf
on May 10th (Friday), 10:45 AM - 12:45 PM at Halle B.
Let's talk if you're interested at LLM Evals 🙂
Excited to present 🔥Prometheus, a fully open-source evaluator LM that is on par with GPT-4 evaluation when the “appropriate” reference materials are appended!
* Could generalize to customized score rubrics
* Shows high correlation with both human evaluators & GPT-4 evaluation
9
51
347
1
2
48
I'm going to present our Expert Language Model paper at ICML 2023! Come to Exhibit Hall 1 (7.25 2:00PM - 3:30PM) if you're interested in either Instruction Tuning or Expert LMs!

Scaling 📈 the total # of tasks during instruction tuning has been known to unlock new abilities in LMs. However, we find that an LM trained on a single task outperforms an LM trained on 300+ tasks on unseen tasks 🤯
📝:
1/8

2
62
305
1
5
47
🤖Distilling from stronger models is effective at enhancing the reasoning capabilities of LLMs as shown in Orca, WizardMath, Meta-Math, and Mammoth.
🔍In this work, we ask the question if LLMs could "self-improve" their reasoning capabilities!
Check out the post for more info😃

🚨 New LLM Reasoning Paper 🚨
Q. How can LLMs self-improve their reasoning ability?
⇒ Introducing Self-Explore⛰️🧭, a training method specifically designed to help LLMs avoid reasoning pits by learning from their own outputs! [1/N]

8
55
293
0
4
46
@jshin491
@jang_yoel
@ShayneRedford
@hwaran_lee
@oodgnas
@SungdongKim4
@j6mes
@seo_minjoon
Also, I'd like to thank
@_akhaliq
for highlighting our paper:)

Prometheus: Inducing Fine-grained Evaluation Capability in Language Models
paper page:
Recently, using a powerful proprietary Large Language Model (LLM) (e.g., GPT-4) as an evaluator for long-form responses has become the de facto standard. However, for

3
51
229
1
3
44
💡Evaluating high-level capabilities (e.g., Helpfulness, CoT abilities, Presence of ToM) of LLMs hold crucial instead of simply measuring the performance on a single domain/task.
In our recent work, we check whether LLMs could process multiple instructions at once. Check it out!

🔥New Paper Alert 🔥
🤔 LLMs are typically prompted to follow a SINGLE instruction per inference call. BUT, can LLMs also follow TWO or MORE instructions at once?
📢 Findings: Smaller Models can’t! But, GPT-4 shows up to 17.4% better performance even less inference calls 🤯

3
8
39
0
5
37
#NLProc
🤗We propose LangBridge, a scalable method to enable LMs solve multilingual reasoning tasks (e.g., math, code) "without any multilingual data"!
🔑The key ingredient is using mT5's encoder and aligning with an arbitrary LLM!
➡Check out the post for more information!

❗New multilingual paper❗
🤔LMs good at reasoning are mostly English-centric (MetaMath, Orca 2, etc).
😃Let’s adapt them to solve multilingual tasks. BUT without using multilingual data!
We present LangBridge, a zero-shot approach to adapt LMs for multilingual reasoning.

6
56
215
1
6
35
Thank you for the shout out
@jerryjliu0
@llama_index
!! Great to see an awesome blog post & some additional examples that wasn't in the paper😊

GPT-4 is a popular choice for LLM evals, but it’s closed-source, subject to version changes, and super expensive 💸
We’re excited to feature Prometheus by
@seungonekim
et al., a fully-open source 13B LLM that is fine-tuned to be on par with GPT-4 eval capabilities 🔥
9
87
470
0
5
32
🤗Interested at how we could holistically evaluate LLMs? I'll be presenting 2 papers at
#NeurIPS2023
@itif_workshop
! Come visit😃
👉Room 220-222, Dec 15th, 1-2PM (Poster), 5-6PM (Oral)
🧪Flask: (led by
@SeonghyeonYe
)
🔥Prometheus:

Excited to present 🔥Prometheus, a fully open-source evaluator LM that is on par with GPT-4 evaluation when the “appropriate” reference materials are appended!
* Could generalize to customized score rubrics
* Shows high correlation with both human evaluators & GPT-4 evaluation
9
51
347
1
7
30
🤔 How can you evaluate whether your LLM is humorous or not? Among various versions during development, how can you track whether your LLM is inspiring while being culturally sensitive?
Current evaluation resources (e.g., MMLU, Big Bench, AlpacaFarm) are confined to generic,

3
8
28
⭐️If you're interested at inducing Chain-of-Thought capabilities to smaller models across a variety of tasks, come visit our poster at
#EMNLP2023
!
➡️ Poster Session 5, Dec 9th, 11AM
Also happy to chat about synthetic data and NLG evaluation as well😀

🚨 New Instruction Data Alert!
We introduce 🌟CoT Collection🌟, an instruction dataset including 52 times more CoT rationales and 177 times more tasks compared to previously available CoT datasets.
8
53
250
1
1
26
#NLProc
🧐We show that LLMs can write & simulate executing pseudocode to improve reasoning.
Compared to Zero-shot CoT or PoT/PAL, our Think-and-Execute significantly improves performance on BBH by understanding the "logic" behind the task.
Check out the post for more details!

📢 New LLM Reasoning Paper
Excited to present 🧠Think-and-⏩Execute, a method that (1) generates a pseudocode describing the key logic of a problem & (2) executes the pseudocode with an LLM as if it is a compiler (e.g., printing out intermediate variables in between).
📈

7
55
238
0
2
23
My first first-authored paper has been accepted at COLING 2022! The title of the paper is "Mind the Gap! Injecting Commonsense Knowledge for Abstractive Dialogue Summarization".
(1/N)

3
3
21
@Teknium1
I've experienced this as well while training a smaller model with CoT augmented from GPT models. Even though the eval loss went up, a smaller model trained for multiple epochs (>=3) definitely generated better rationales.
Also, since it is too

2
2
21
To learn more about our work, please check out our paper, website, code, model, and dataset!
📚
🌐
🖥
🔥
💬
1
5
21
🤔In most cases, we use a fixed system message, "As a helpful assistant [...]". Is this optimal?
💡We find that by incorporating diverse system messages in post-training, LLMs gain adherence to these messages, a key component for personalized alignment.
➡️Check out the post!

🚨 New LLM personalization/alignment paper 🚨
🤔 How can we obtain personalizable LLMs without explicitly re-training reward models/LLMs for each user?
✔ We introduce a new zero-shot alignment method to control LLM responses via the system message 🚀

3
53
206
0
2
15
#NLPaperAlert
😴 Aren't you tired of the monotonous way ChatGPT responds?
💡Infuse your preferences to personalize the way your LLM responds, based on our new alignment method 🥣Personalized Soups🥣
✅ Great work led by
@jang_yoel
, check it out!!
🎯 Tired of one-size-fits-all AI chatter? ChatGPT tends to generate verbose & overly informative responses. This is because the current RLHF pipeline only allows aligning LLMs to the general preferences of the population. However, in the real world, people may have multiple,

2
67
298
0
1
15
Check out our recent work on evaluating the capabilities of LLMs based on multiple fine-grained criteria! It suggests where we currently are & whete we should head towards ✨✨Thanks to
@SeonghyeonYe
&
@Doe_Young_Kim
for leading this amazing work🙌

Are open-sourced LLMs really good? 👀
We introduce FLASK🧪, a fine-grained evaluation based on skill sets! Even SOTA open-sourced LLMs such as LLaMA2 Chat 70B lag behind proprietary LLMs for some abilities. 🤯
Paper:
Demo:

10
106
453
0
1
14
I'd like to thank all of my co-authors and supervisor for helping me with this project! It was a great experience working with you all, appreciate it😃
@jshin491
Yejin Cho
@jang_yoel
@ShayneRedford
@hwaran_lee
@oodgnas
Seongjin Shin
@SungdongKim4
@j6mes
@seo_minjoon
1
0
14
✏️Based on this motivation, we have constructed a generation benchmark that encompasses 9 capabilities, 77 tasks, and 765 instances, each with its own instance-specific evaluation criteria.
🤖We evaluate 103 frontier LLMs including pre-trained LMs, post-trained LMs, and

1
0
15
We also show that Prometheus could function as a reward model when tested with human preference datasets. Prometheus obtains high accuracy compared to SOTA reward models, showing the possibilities of using it as an universal reward model.

1
1
12
@aparnadhinak
@OpenAI
@ArizePhoenix
@arizeai
Hello
@aparnadhinak
, great analysis! I really enjoyed reading it.
I have one question:
I think the scoring decisions could be a lot more precise if you prompt it with (1) mapping an explanation for all the scores instead of just 0,20,40,60,80,100%, (2) making the model generate
3
0
11
#nlproc
As a native Korean, the translated MMLU seemed super awkward to me since it requires US-related knowledge & expressions are not fluent (even if you use DeepL or GPT-4).
Super timely work from
@gson_AI
who made a Korean version of MMLU without any translated instances!
🌟 KMMLU 🌟This benchmark replicates the methodology that produced MMLU, but using examinations common in Korea. We manually annotate a subset of the questions as to whether they require Korea-specific knowledge and also designate a KMMLU-Hard subset that current models find


1
5
22
1
2
12
🔍 Why is it important to build an open-source alternative for GPT-4 evaluation?
Solely relying on proprietary LLM evaluators confers the following disadvantages:
1/ Close-source Nature: The proprietary nature of LLMs brings transparency concerns as internal workings are not
1
0
12
To learn more about our work, please check out our paper, website, model, dataset, and code!
Paper:
Website:
Model:
Dataset:
Code:
2
2
12
@jphme
@dvilasuero
@natolambert
My take is that without a reference answer, it's basically asking the evaluator/judge model to (1) solve the problem internally through its forward pass and also (2) evaluate the response at the same time. It's twice of workload, which is evidently harder!
2
1
11
Lastly, I’d like to appreciate our coauthors for their hard work in annotating/verifying the dataset and for valuable advices!
@scott_sjy
@JiYongCho1
@ShayneRedford
@chaechaek1214
@dongkeun_yoon
@gson_AI
@joyejin195315
@shafayat_sheikh
@jinheonbaek
@suehpark
@ronalhwang
0
0
13
Recent works showed that CoT Fine-tuning enables smaller LMs to solve new novel tasks more effectively.
But, up to date, there exists only 9 CoT datasets available, which FLAN-T5 used for training, namely AQuA, Creak, ECQA, eSNLI, GSM8K, QASC, QED, SenseMaking and StrategyQA.
1
0
10
☺️ I'd like to thank all my amazing co-authors for their valuable comments & advice throughout the project!
@scott_sjy
@ShayneRedford
@billyuchenlin
@jshin491
@wellecks
@gneubig
Moontae Lee
@Kyungjae__Lee
@seo_minjoon
1
0
9
Check out our paper for more information!
📚
Links to potentially useful resources:
📰 Dataset:
📊 Evaluation Results of 103 LMs:
🖨 Zeno Visualization of Outputs/Feedback: Bench

2
0
11
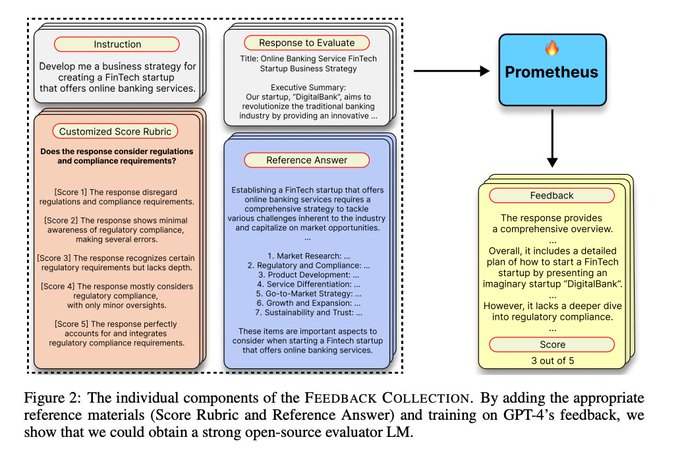
💡Specifically, we append a Score Rubric and a Reference Answer during both training/inference!
1/ Score Rubric: Provides information of the pivotal aspects essential for addressing the given instruction. Without it, the evaluator LM should inherently know what details should be

1
3
8
[So how did we obtain a unified evaluator LM that could function in both formats?]
😧 Initially, we trained a evaluator LM jointly on direct assessment and pairwise ranking formats.
=> However, in most cases, it performed worse than evaluator LMs trained on each format
1
2
9
@jphme
@dvilasuero
@natolambert
@jphme
@natolambert
@dvilasuero
We're currently training mistral/mixtral with some additional Prometheus data & new techniques. I think we could have a preprint by the end of the month!
I'll definitely include an experiment on how the model behaves when there's no reference:)
2
1
9
🧮 Take this math problem for example, used to measure reasoning capabilities.
➡️ Is it really reliable to trust a score obtained by prompting GPT-4 to assess the “helpfulness” of a rationale when we are trying to measure the reasoning capabilities of LLMs?
➡️ Asking to grade

1
0
11
🤔 But how is it possible to use a 7B & 13B sized LM as an evaluator if it isn’t as good as GPT-4 in the first place?
⇒ The main obstacle of obtaining a language model specialized on evaluation is because it needs to know the important aspects tailored with the instruction and
1
0
7
@Teknium1
Here's the dataset:
@openchatdev
used it as their training data to induce evaluation capabilities in their recent models, but I haven't heard whether it had a positive effect. Would love to see if training on it would eventually lead to a self-improving
1
0
6
🔍 Among the 78,795 judgments (103 LMs * 765 prompts), we use a subset to measure the correlation between human judgments and evaluator LM judgments.
➡️ GPT-4-Turbo-2024-04-09 achieves the highest correlation in average (0.623).
➡️ Majority voting with multiple evaluator LMs

3
0
9
@scott_sjy
@ShayneRedford
@billyuchenlin
@jshin491
@wellecks
@gneubig
@Kyungjae__Lee
@seo_minjoon
🙌Last but not least, I'd like to thank
@arankomatsuzaki
@omarsar0
@_akhaliq
for sharing our work!
Prometheus 2
An Open Source Language Model Specialized in Evaluating Other Language Models
Proprietary LMs such as GPT-4 are often employed to assess the quality of responses from various LMs. However, concerns including transparency, controllability, and affordability

4
58
271
0
0
7
To resolve this issue, we augment CoT rationales using LLMs.
Using FLAN Collection as a source, we use ICL and make LLMs generate high quality CoT rationales across 1,060 NLP tasks.

1
0
7
🧩 One of the biggest challenges in evaluating LLMs is the difficulty in quantifying the quality of a model’s response with respect to specific capabilities of interest, such as reasoning, planning, and grounding.
➡️ When LLMs serve as judges for free-form responses, the lack of

2
0
9
🆚 Based on this result, we plot the overall performance trends of different LMs and analyze how the performance of each capability scales with respect to model parameter size.
➡️ (Finding 1) Scalability of pre-trained LM parameter sizes contributes to qualitative improvements



1
0
9
Last but not least, I’d like to thank our wonderful team for accomplishing this project!
@sylee_ai
@suehpark
@GeewookKim
@seo_minjoon
0
0
6
Surprisingly, when measuring the Pearson correlation with human evaluators on 45 customized score rubrics, Prometheus achieves 0.897, which is on par with GPT-4 (0.882), and greatly outperforms GPT-3.5-Turbo (0.392).

1
1
6
I'd also like to talk if you're interested in Chain of Thought Fine-tuning, Zero-shot Generalization and Few-shot adaptation! Come visit :)
🚨 New Instruction Data Alert!
We introduce 🌟CoT Collection🌟, an instruction dataset including 52 times more CoT rationales and 177 times more tasks compared to previously available CoT datasets.
8
53
250
0
2
6
As instruction-tuned models are developed in a rapid pace, we expect more future research on open-source evaluator LLMs. Some remaining questions are:
1/ What additional reference materials could we use in addition to the reference answer & score rubric? Does including
1
0
6
➡️ (Finding 3) The performance gap between larger pre-trained LMs and post-trained LMs narrows, while it persists in smaller LMs. When examining each capability, the gap is more pronounced in refinement, reasoning, grounding, and planning, suggesting that post-training impacts


1
0
7
To learn more about our work, please check out our paper, code, models, and datasets!
📄
💻
🤗

1
0
5
To train 🔥Prometheus, we construct a new dataset called the 💬Feedback Collection.
Compared to previous feedback datasets that only evaluate on helpfulness/harmlessness, the 💬Feedback Collection includes 1K customized score rubrics (e.g., Is the answer professional and formal
1
0
5
Also, I'll present Prometheus-Vision on May 11th (Saturday), 13:00 - 14:00 at ME-FoMo workshop!
🤔How could you evaluate whether your Vision Language Model (VLM) is closely reaching the capabilities of GPT-4V?
We’re excited to present 🔥Prometheus-Vision, the first open-source VLM specialized for evaluating other VLMs based on fine-grained scoring criteria, with co-lead
3
43
148
0
0
5
📅 Last year, we introduced Prometheus 1, one of the first evaluator LM that showed high scoring correlations with both humans and GPT-4 in direct assessment formats. (Please read the tagged thread if you haven't already!)
📈 Since then, many stronger
Excited to present 🔥Prometheus, a fully open-source evaluator LM that is on par with GPT-4 evaluation when the “appropriate” reference materials are appended!
* Could generalize to customized score rubrics
* Shows high correlation with both human evaluators & GPT-4 evaluation
9
51
347
1
0
5
Our CoT Collection dataset & CoT-T5 models are available at Huggingface!
Link:

0
1
5
So how could one use this dataset?
To explore the benefits of CoT fine-tuning on massive amount of instruction data, we continually train FLAN-T5 with CoT Collection, resulting in our model C2F2.
Then, we test our model in zero-shot and few-shot settings.

1
0
4
To learn more about our work, please check out our draft & code😃
📝
👨💻
Joint work w/
@joocjun
,
@Doe_Young_Kim
,
@jang_yoel
,
@SeonghyeonYe
,
@jshin491
,
@seo_minjoon
1
0
4
🤔 The two most conventional methods for evaluating LLMs are direct assessment (e.g., MT-Bench) and pairwise ranking (e.g., AlpacaEval).
🫡 Since Prometheus 1 did not support "pairwise ranking", one of our motivations was to train a flexible, unified evaluator LM that could

1
0
4
On the Big Bench Hard (BBH) benchmark, we observe +4.34%, +2.44% improvement across 3B and 11B model scale, respectively.
Also, naively training T5 on CoT Collection works effectively, considering that CoT Collection is 8 times smaller than FLAN Collection!

1
0
4
Specifically, during both training & inference, Prometheus-Vision receives 5 input components:
1⃣ An Instruction
2⃣ An Image
3⃣ A Response to Evaluate
4⃣ A Customized Score Rubric
5⃣ A Reference Answer (Score 5)
Prometheus-Vision is trained to generate 2 components:
1⃣ A

1
0
4
We evaluated Prometheus 2 on 4 direct assessment benchmarks: Vicuna-Bench, MT-Bench, FLASK, and Feedback Bench (our in-domain test set).
Only the Prometheus 2 models show Pearson correlations above 0.5 among the open source LMs regardless of the reference evaluator (listed

1
0
4
We also evaluated Prometheus 2 on 4 pairwise ranking benchmarks: HHH Alignment, MT Bench Human Judgments, Auto-J Eval, and Preference Bench (our in-domain test set).
Considering that (1) PairRM was trained on HH-RLHF (similar to HHH Alignment) and (2) Auto-J Eval is the

1
0
4
When assessing the quality of the generated feedback in a pairwise comparison setting (i.e., Which feedback is better at criticizing & assessing the given response), human evaluators preferred Prometheus’s feedback over GPT-4 with a 58.62% win rate and 79.57% over GPT-3.5-Turbo.

1
2
4
Also, we show that a C2F2 could adapt to new tasks with few instances.
On a 64 shot setting, C2F2 + LoRA outperforms FLAN-T5 + Full fine-tuning by +2.97% and +2.37% across 4 legal & medical datasets while updating 2,352x fewer parameters.

1
0
4
💡As in our previous work (Flask & Prometheus), we find that appending a score rubric & reference answer during both training/inference is effective in obtaining a good evaluator VLM!
We first construct a multi-modal feedback dataset called the Perception Collection.
✨Includes

1
1
3
🤔How could you evaluate whether your Vision Language Model (VLM) is closely reaching the capabilities of GPT-4V?
We’re excited to present 🔥Prometheus-Vision, the first open-source VLM specialized for evaluating other VLMs based on fine-grained scoring criteria, with co-lead
3
43
148
0
0
3
Lastly, we highlight the potential of our in-domain test set called the Perception Bench.
👎In the widely used LLaVA-Bench, LLaVA-RLHF shows only a marginal difference of 0.14 points with GPT-4V since the questions/instructions are relatively simple.
👍In our Perception-Bench,

1
1
3
@aparnadhinak
@OpenAI
@ArizePhoenix
@arizeai
@aparnadhinak
This would be what I mentioned about looks like:

0
0
3
@ShayneRedford
@natolambert
@natolambert
Hello Nathan, in our recent preprint, we made 100K synthetic data & the trained model functioned as a good evaluator/critique model on custom criteria even compared to GPT-4!
I would be glad for further discussion if you're interested😃
Excited to present 🔥Prometheus, a fully open-source evaluator LM that is on par with GPT-4 evaluation when the “appropriate” reference materials are appended!
* Could generalize to customized score rubrics
* Shows high correlation with both human evaluators & GPT-4 evaluation
9
51
347
1
0
2
0
0
3
When measuring the pearson correlation with GPT-4 evaluation on 1222 customized score rubrics, Prometheus obtains higher correlation compared to GPT-3.5-Turbo & Llama-2-Chat (70B), bolstering its capability as an evaluator LM.

1
2
3
Next, we measure the correlation with human evaluators on 45 instances across 3 Visual Instruction Following Benchmarks.
😃Prometheus-Vision performs on par with GPT-4 and GPT-4V on the LLaVA-Bench and Perception-Bench (in-domain test set).
💡Yet, as mentioned above, it shows

1
1
3
🏞 The solution to this problem is directly using “VLM-as-a-judge”!
➡️VLM Evaluators are flexible to assess based on any customized scoring criteria and don’t require any captioning model to pass the image.
💣 Currently, the ONLY possible option to do this is using GPT-4V!
1
1
3
Notably, since our evaluation setting is in an absolute grading setting, we find that there is no length bias in terms of the score the evaluator VLM gave (i.e., Doesn’t prefer longer responses).
💡As mentioned in the MT-Bench paper, exploring the advantages and disadvantages of

1
1
3
⁉️ How did previous works typically evaluate how good a VLM is?
Basically, there were two different approaches.
1️⃣ For Visual Question Answering and Captioning tasks, you would measure the word overlap or edit distance between the model’s prediction and the ground-truth label.

1
1
3
We test Prometheus-Vision’s evaluation capabilities on 3,560 instances across 8 benchmarks ranging from Visual Instruction Following, Visual Question Answering, and Captioning tasks.
😃Surprisingly, it consistently outperforms (1) all the other open-source VLMs, (2) Prometheus,

1
1
3
0
0
1
0
0
1
@NeuralNeron
Thanks for your interest in our work! It has the same speed as using Llama-2-Chat 7B & 13B. Using 4 A100 GPUs on huggingface tgi, it took less than 0.33 seconds to generate a feedback & score:)
0
0
1
@alignment_lab
@altryne
@alignment_lab
@altryne
That sounds great! Expanding to other modalities such as speech & video definitely seems like an interesting direction to pursue 🙂
We could have
@sylee_ai
join as well to make our discussions more fruitful!
0
0
0
0
0
1
@OrenElbaum
Hello Oren, thank you for your interest in our work!
ToT is effective at solcing hard problems at the cost of additional inference. While one could obtain high quality rationale data using ToT, investigating if smaller LMs could learn it would be an interesting direction!
0
0
1
1
0
1
@tugot17
Hello Piotr, thanks for your interest in our work! We're planning to open source all of our data / models, so stay tuned🙂
0
0
1
0
0
1
The main motivation of this paper was to investigate whether adding commonsense inferences at the input (a typical method for commonsense knowledge injection) could work for datasets not explicitly made for commonsense reasoning.
(2/N)
1
0
1
To check out how commonsense inferences might be helpful in summarizing dialogues, we experiment in a zero-shot setting where the only difference is whether inferences are given or not.
We find even with no training commonsense inferences help.
(6/N)

1
0
1
Lastly, we check out the effect of "commonsense supervision" task. We find that the auxiliary task makes the average attention values of the commonsense inference tokens higher in the upper layers.
We conjecture this as fusing semantic meaning / commonsense injection.
(8/N)

0
0
1
As the main methodology, we cross concatenate utterances and its corresponding commonsense inferences.
Also, to enforce the model to use the given inferences, we add an auxiliary task and loss function where the objective is to generate the inferences of the summary.
(5/N)

1
0
1