
Seonghyeon Ye
@SeonghyeonYe
Followers
930
Following
2K
Statuses
219
PhD student KAIST AI (@kaist_ai), Research Intern @NVIDIAAI GEAR | Prev: @MSFTResearch
Joined February 2021
🚀 First step to unlocking Generalist Robots! Introducing 🤖LAPA🤖, a new SOTA open-sourced 7B VLA pretrained without using action labels. 💪SOTA VLA trained with Open X (outperforming OpenVLA on cross and multi embodiment) 😯LAPA enables learning from human videos, unlocking potential for robotic foundation model ❗Over 30x pretraining efficiency for VLA training 🤗Code and checkpoints are all open-sourced!
3
58
215
RT @DrJimFan: We RL'ed humanoid robots to Cristiano Ronaldo, LeBron James, and Kobe Byrant! These are neural nets running on real hardware…
0
464
0
RT @TairanHe99: 🚀 Can we make a humanoid move like Cristiano Ronaldo, LeBron James and Kobe Byrant? YES! 🤖 Introducing ASAP: Aligning Sim…
0
172
0
RT @DJiafei: Can we build a generalist robotic policy that doesn’t just memorize training data and regurgitate it during test time, but ins…
0
67
0
RT @sylee_ai: 🎉 Excited to share that our paper "How Does Vision-Language Adaptation Impact the Safety of Vision Language Models?" has been…
0
16
0
RT @DrJimFan: Introducing NVIDIA Cosmos, an open-source, open-weight Video World Model. It's trained on 20M hours of videos and weighs from…
0
780
0
RT @ShayneRedford: ✨New Report✨ Our data ecosystem audit across text, speech, and video (✏️,📢,📽️) finds: 📈 Rising reliance on web, synthet…
0
42
0
RT @zhou_xian_: Everything you love about generative models — now powered by real physics! Announcing the Genesis project — after a 24-mon…
0
3K
0
RT @DrJimFan: I believe solving robotics = 90% engineering + 10% research vision. Project GR00T is NVIDIA's moonshot initiative to build ph…
0
129
0
RT @DJiafei: 🚀Excited to introduce our latest work- SAT: Spatial Aptitude Training, a groundbreaking approach to enhance spatial reasoning…
0
18
0
RT @seungonekim: #NLProc Just because GPT-4o is 17 times more expensive than GPT-4o-mini, does that mean it generates synthetic data 17 ti…
0
49
0
RT @jparkerholder: Introducing 🧞Genie 2 🧞 - our most capable large-scale foundation world model, which can generate a diverse array of cons…
0
484
0
RT @theworldlabs: We’ve been busy building an AI system to generate 3D worlds from a single image. Check out some early results on our site…
0
726
0
We won the 🏆Best Paper Award at #Corl2024 LangRob workshop! Also check out our updated codebase:

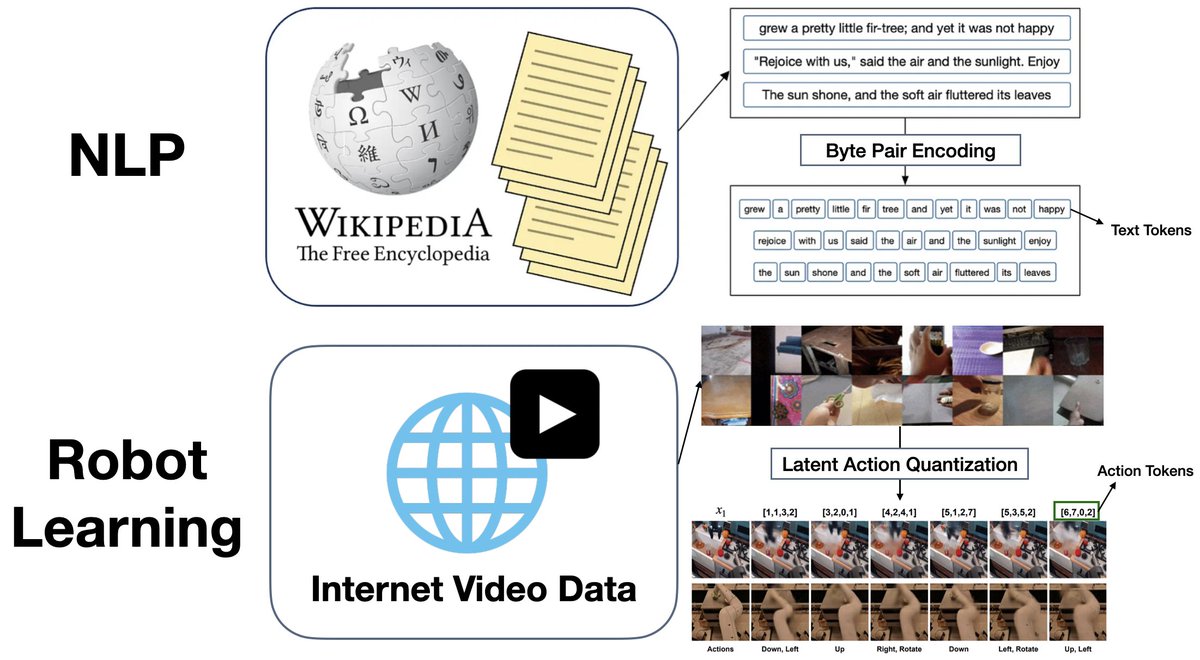
Excited to share that 𝐋𝐀𝐏𝐀 has won the Best Paper Award at the CoRL 2024 Language and Robot Learning workshop, selected among 75 accepted papers! Both @SeonghyeonYe and I come from NLP backgrounds, where everything is built around tokenization. Drawing inspiration from Bye-Pair Encoding in language models, 𝐋𝐀𝐏𝐀 takes a similar approach by tokenizing actions directly from video data. While BPE is frequency-based, ours is learning-based where we compare the difference between two consecutive frames in videos to determine the atomic action granularity. This allows Vision-Language-Action models to learn effectively from human video data as well as gain stronger x-embodiment transfer—going beyond pre-defined robot actions such as end-effector deltas. As popular request, we’re also releasing the core component behind this success: the VQ-VAE model training code to extract latent actions. This open-source release includes the GENIE model implementation with added enhancements to minimize codebook collapse, allowing you to input ANY type of video—robotic, human, navigation, etc.—and extract latent actions to train visuomotor robot policies. We worked hard on making it easy to use, so do try it out! We believe actions can be a more expressive form of language. Code:
0
4
41
RT @svlevine: Really excited to share what I've been working on with my colleagues at Physical Intelligence! We've developed a prototype ro…
0
154
0
RT @seohong_park: D4RL is a great benchmark, but is saturated. Introducing OGBench, a new benchmark for offline goal-conditioned RL and of…
0
51
0
RT @kimin_le2: Mobile AI assistants (like Apple Intelligence) offer useful features using personal information. But how can we ensure they…
0
9
0
RT @AjayMandlekar: Tired of endlessly teleoperating your robot in order to train it? Introducing SkillMimicGen, a data generation system…
0
33
0
RT @jang_yoel: Excited to introduce 𝐋𝐀𝐏𝐀: the first unsupervised pretraining method for Vision-Language-Action models. Outperforms SOTA mo…
0
65
0