

Mike Conover
@vagabondjack
Followers
3,980
Following
1,873
Media
148
Statuses
3,043
Founder & CEO at Brightwave; formerly language models at Databricks.
Joined February 2010
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
LINGORM PANTENE TRIP
• 574045 Tweets
محمد
• 378107 Tweets
FREEN X PRADA OPENING STORE
• 206104 Tweets
#KingPowerBirthdayxEngfa
• 71199 Tweets
علي النبي
• 71147 Tweets
Kindiki
• 65113 Tweets
ホームラン
• 58587 Tweets
APO DELIGHTS AND SURPRISES
• 56927 Tweets
KAOPP 1ST FAN MEETING
• 48302 Tweets
Hayırlı Cumalar
• 47984 Tweets
新刀剣男士
• 27477 Tweets
WIN BA PRADA WMW
• 27172 Tweets
オースティン
• 27113 Tweets
LMSY AFFAIR FINAL EP
• 22380 Tweets
Wizkid
• 21757 Tweets
#جمعه_مباركه
• 21294 Tweets
IEBC
• 17090 Tweets
#bebekkatilleri
• 11359 Tweets




















Pinned Tweet

Today we're announcing the $6M seed round for
@brightwaveio
led by
@DecibelVC
and with participation from
@p72vc
and
@Moonfire_VC
.
We are building an AI research assistant that generates insightful, trustworthy financial analysis on any subject and have customers with assets

8
6
41
Today we’re releasing Dolly 2.0, a 12B parameter instruction-following LLM trained exclusively on a free and open dataset generated by Databricks employees and *licensed for commercial use.* 🐑🚀

17
184
1K
Take note, OpenAI constructs prompts using markdown. I believe this is reflective of their instruction tuning datasets.
In our own work we’ve seen markdown increase model compliance far more than is otherwise reasonable.

ChatGPT+ Dalle3 System Prompt:
You are ChatGPT, a large language model trained by OpenAI, based on the GPT-4 architecture.
Knowledge cutoff: 2022-01
Current date: 2023-10-05
# Tools
## dalle
// Whenever a description of an image is given, use dalle to create the images and
29
199
1K
20
121
821
We build on a hybrid Rust / Python stack. We'll frequently wrap performance-sensitive compute in pyo3 bindings so it's addressable as a Python module within our modeling and ETL pipelines.
Eye-wateringly fast. Highly recommend this pattern.

18
43
855
The Open Assistant chat corpus just dropped, 100k-scale chat/instruction dataset from thousands of participants. The era of open data is upon us.
High quality metadata, incl. toxicity scores, attached to each record.

13
134
647
With the Dolly 2.0 release yesterday we heard a lot of people saying they wanted smaller models that can fit on consumer grade GPU’s.
Here you go! Checkpoints from 2.8B and 6.9B now on the Databricks Hugging Face page! 🐑🚀

15
105
595
I can’t tell which I’m more excited about, Dolly 2.0 or the fact that we’re giving away the 15k instruction tuning records, created by thousands of Databricks employees in the last two weeks, we used to train it.
Free and licensed for commercial use! 🐑
22
59
455
GPT-4 is able to infer authorship from a passage of text based on style and content alone.
Given the first four paragraphs of the March 13, 2023
@stratechery
post on SVB, GPT-4 identified Ben Thompson as the author.

26
78
433
The power of free and open data! The databricks-dolly-15k dataset has been translated into Spanish and Japanese in under 24 hours!
Who's running Self-Instruct on this with
@YiTayML
's (et al) UL2?

6
64
335
Top information sources for AI Engineers, at
@aiDotEngineer
Summit courtesy of
@barrnanas
&
@AmplifyPartners
.

16
43
335
Love this post from the
@Replit
team on their process for building LLM's like the Ghostwriter code assistant.
@databricks
, alongside
@huggingface
and
@MosaicML
, constitute what they're calling the 'modern LLM stack.'
5
46
269
Incredibly excited to announce I've co-founded a company to build the operating system for fleets of autonomous financial research agents. We're hiring for engineering, AI/ML and design.
Get in touch if you want to create something incredible.

30
26
271
We’re actively updating the Dolly repo with model improvements! Make sure to pull the latest changes. At $30 / 30min per training run it’s dead simple to run multiple experiments.
Also, 688 stars in 20 hours! Neat!

8
42
238
Happening now!
@ShayneRedford
speaking on LLM's as part of the Data Talks speaker series at Databricks. Will be tweeting insights and slides from our inspiring speaker as we go.

4
40
225
We took a detailed look at the level of effort required to reproduce the LLaMA dataset and it's highly non-trivial. You read the paper and there are entire classifiers hidden behind five word clauses.
If this corpus is the real deal it's hard to overstate how valuable it is.

Announcing RedPajama — a project to create leading, fully open-source large language models, beginning with the release of a 1.2 trillion token dataset that follows the LLaMA recipe, available today!
More in 🧵 …

38
405
2K
5
30
220
💥 This. Team. Ships.
Databricks committing to the
@huggingface
datasets codebase - so now anyone can read directly from a Spark dataframe into a dataset nearly 2x faster.
3
37
209
We've just launched Dolly on Hugging Face and you can download and try the model now! New generated examples and benchmarks, too.
Let us know what you think!

5
34
188
Inspired by
@jeremyphoward
, a non-exhaustive list of the reasons the
@togethercompute
RedPajama LLaMA dataset reproduction saves the rest of us a lot of work. [1/n]
4
18
177
"The Rust Programming Language" from No Starch Press is great, and the 'Rustlings' practice problem sets are very thoughtfully designed.


@vagabondjack
do you have a prefered "getting started in rust for a dude who's never used a compiled language" book?
9
0
46
3
8
164
The importance of effective, powerful open source models you can own and operate has never been greater.
1
22
149
Our KDD paper and video on production-grade named entity linking are live. Beats Google and IBM on F1, with a 20x smaller memory footprint and 100% faster execution than Stanford NLP. Deployed in the wild for a year on millions of documents per day.

2
36
141
Get it while it's hot! The
@MosaicML
MPT-7B -Instruct model is trained on the databricks-dolly-15k instruction tuning corpus.
LLaMA-grade language capabilities with Dolly-like instruction following. Ship it!

2
21
130
This. Team. Ships.
Call OpenAI or your own custom LLM just like a SQL UDF. Zero shot transformations of your Lakehouse data - this stuff was sci-fi last year.

0
19
131
Dolly and GPT-J had only marginal differences in benchmark metrics but their behavior could not be more different.
Eloquence and compliance are hard to operationalize - many ways to say the same thing - what measures and metrics are up to the task?
6
23
129
Stunning
@BigCodeProject
! A trillion tokens in 80 languages, huge context window, and step function improvement in quality.
38% improvement on HumanEval Pass
@1
vs Replit's replit-code-v1-3b. Nearly doubles the performance of models in the Salesforce Codegen family.

Introducing: 💫StarCoder
StarCoder is a 15B LLM for code with 8k context and trained only on permissive data in 80+ programming languages. It can be prompted to reach 40% pass
@1
on HumanEval and act as a Tech Assistant.
Try it here:
Release thread🧵

76
666
3K
2
18
94
Hard to beat the information density of this data tracker for The Pile v2.
What a corpus! Will be cool to see models trained on this plus RedPajamas. Could see it being very additive, similar to how C4 and CommonCrawl are same but different,

4
11
91
Of all the announcements in the pipeline, I’m especially excited about first class support for LLM’s of all flavors in MLFlow. Hugging Face, OpenAI and Langchain all play well with Databricks.

1
15
81

4
1
67
We're the teams behind Databricks' Dolly and we are hiring experienced, focused engineers prepared to work with startup intensity on AI technologies that span modeling, infrastructure and strategy.
Join us.

2
10
63
We saw (and documented) only minimal benchmark differences between Pythia and Dolly, but the actual difference could not have been more striking.

The days of easy LM benchmarking might be over. HELM puts davinci-002 above 003, but my experience with both models makes it pretty obvious that 003 is better than 002.
How can we build better benchmarks?
(HELM is *awesome* btw, I just think we need to rethink benchmarking)

7
8
88
3
12
59
.
@mat_kelcey
To pick an ML algorithm for a practical application, read 5 papers in the domain and implement the one they all claim to beat.
3
42
53
Quite the trick to pick somebody out of a planet-scale lineup based on ~300 words. Obviously quite a bit easier for prolific writers, but no doubt this will generalize in time to the public at large.
Facial recognition technology for your writing and thoughts. Sobering.
2
6
52
The common thread b/w OpenAI and FTX is the utterly brain damaged EA mindset that allows you to justify absurd, irrational thinking by including +∞ and -∞ in your expected value calculations.
It would be a joke if it wasn’t such a travesty.
3
6
49
Microsoft executes a hostile takeover of the NY Times (ticker: NYT) at $58 per share in a $9.5B transaction rather than writing down a loss for GPT4.
6
4
49
CEO of
@togethercompute
(Red Pajamas team) confirming their LLaMA reproduction is currently being trained and it staged for release soon.
Doing a hell of a lot of good for the world here.

@vagabondjack
Training is well underway and we should have something to share a lot sooner than that!
0
0
13
0
8
47

Don't sleep on the interactive T-SNE viewer for the GPT4All dataset. Awesome work from
@andriy_mulyar
et al.

1
12
44

Data scientists spend 80% of their time cleaning data and 20% complaining about cleaning data.
7
38
38
This plot is amazing.
More, clean data at training time means you can get comparable quality with fewer than half the parameters. Cheaper and faster to run without compromising quality. Super high leverage move here from the
@togethercompute
team.
In addition to RedPajama 7B, we’ve also been training a 2.8B model. After 600B tokens it is exciting to see the model has higher HELM scores than the excellent Pythia-2.8B & GPT-Neo 2.7B.
In fact, trained with twice the tokens, RedPajama-2.8B has comparable quality to Pythia-7B!
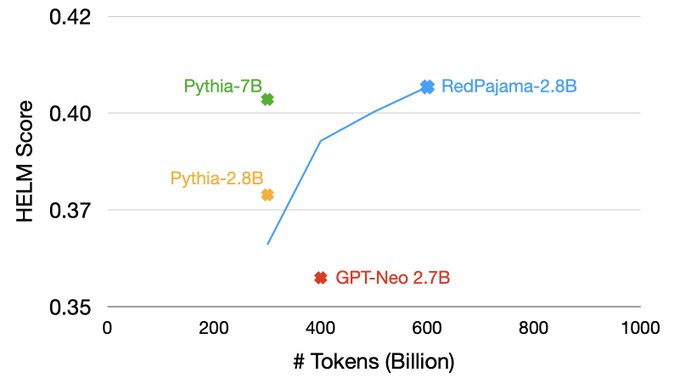
13
79
522
0
10
40
Proposed legislation for a €20M fine for open source models and private LLM API’s offered in the EU.
So broad and unthinking as to be laughable, save for the $20T GDP.
2
16
35
700+ comprehensive pages, Springer's 'The Elements on Statistical Learning', as PDF d/l from Stanford Stats Dept.
http://t.co/9ZKpv6LR
0
26
36

Breaking: Chain of thought prompting is an OpenAI psyop to increase token spend.
3
1
32
My experience with constructing datasets for LLM’s suggests the mechanism at play is a qualitative difference in the character & quality of content (on the open web, et al.) that follows urgent, emotional appeals.

😳This was a study I was waiting for: does appealing to the (non-existent) “emotions“ of LLMs make them perform better?
The answer is YES. Adding “this is important for my career” or “You better be sure” to a prompt gives better answers, both objectively & subjectively!



70
426
2K
3
4
28
@LightningAI
Hey hey! I helped create Dolly & love Lightning. Not sure if you're aware, but all our training and inference code (HF pipeline) is available in our github repo.
Add'l the model is available in 3/7/12B sizes.
1
1
26
On one hand, what an incredible, quantifiable engineering flex: 10x larger and 3x cheaper.
OTOH, how do you know what you're buying? The evals seem conspicuously absent -- does this introduce regressions? How well does it reason over content in the middle of a 128K window?
1
2
25
@danlovesproofs
is pretty close to what you describe, minus wrapped calls to the backing service.
1
2
24
Statistics professors hate this! Find a maxiamlly separating hyperplane with this one weird kernel trick!
http://t.co/0druBKfOYu
4
38
24
This kind of detailed, generous record of otherwise undocumented arcana is interesting and super valuable. The OPT-175 log book from Meta's train likewise offers great perspective on the real work of making this happen.
h/t
@AETackaberry
for the flag.

A few weeks ago, we published our
#BloombergGPT
paper on arXiv. It's now been updated to include the training logs (Chronicles) detailing our team's experience in training this 50B parameter
#LargeLanguageModel
. We hope it benefits others.
#AI
#NLProc
#LLM
0
40
178
1
4
23
@omarsar0
The dataset is money, super proud of the team for getting this out in two weeks time - the internal push was a sight to behold.
1
0
22
ICYMI: Databricks plays super well with Hugging Face, and the implications of our recent commits to the datasets library are features in this VentureBeat story. Nearly 2x speed up in processing time!

0
3
22
Haystack is such a slick framework for out of the box semantic search w transformer, vector index integration. Joined the
@deepset_ai
office hours this week, team is really on the ball. Wish we had this when we were building
@SkipFlag
. cc
@peteskomoroch

3
6
22
Bespoke foundation models will be cost effective and technically accessible on a much shorter time horizon than most appreciate.

There's no faking GPT-4. But you can totally build the real thing on your data if you work with us.
3
1
34
2
3
22
Most influential book I've ever read? 'The Wealth of Networks,' by Yochai Benkler. Available free online.
http://t.co/itodGKeDas
0
7
19
@simonw
@HelloPaperspace
@huggingface
Hey Simon, our team here at Databricks has code for running this in 8-bit mode on an A10. Shoot me a DM w your email and we’ll help get you sorted!
2
0
21
LLM’s are, as a mathematical fact, transformative use. Pleased with this precedent.
—
“This is nonsensical,” he wrote in the order. “There is no way to understand the LLaMA models themselves as a recasting or adaptation of any of the plaintiffs’ books.”

4
4
20
A pleasure to share that our work on the network structure of global labor flows is live! Multi-faceted texture and powerful explanatory power on this one -- couldn't be more proud of the work from this team.

Global labor flow network reveals the hierarchical organization and dynamics of geo-industrial clusters in the world economy
“LinkedIn's employment of more than 500 million users over 25 years to construct a labor flow network of over 4 million firms”

2
61
160
0
4
18
The video for my SF Data Mining talk, 'Information Visualization for Large-Scale Data Workflows' is now online!
http://t.co/Hge4ZVzXAC
0
5
20
Hosting
@ShayneRedford
, of Flan / Flan-T5 fame, at Databricks for a 200+ attendee talk on how fine tuning inputs shape the behavior of models.
May wind up live tweeting the talk if I can convince Shayne to let me screenshot his slides. Stay tuned. 😅
2
1
19
Candid & insightful take from Andrej Karpathy's Build talk is that RLHF models are preferred to SFT models because it's easier for human contractors to compare generated samples than to create SFT training data from thin air.
0
2
18
Anyone have thoughts on Elasticsearch as a vector search index?
16
0
17


For all the spicy takes about the raise and the model not being that different from other offerings, a few remarkable facts stand out.
1) LinkedIn lists 24 people at
@inflectionAI
. This is an incredible accomplishment for a team this size.
1/n

🗣️ Ready to talk with Pi?
The
@heypi_ai
iOS app is now available for download in the App Store!
With our app you can hear Pi talk and select from multiple voice options. Try it out:
18
6
41
1
2
17
Automated pattern discovery and hypothesis generation in large-scale datasets. New research, this month in 'Science'.
http://t.co/qZdaKxvv
0
17
16
I am the picture of stoked for this. To reiterate, (as I understand it) this will be an open LLaMA clone trained on the Red Pajamas LLaMA-alike dataset.
Will be a state of the art step function for open models.
Great results from RedPajama checkpoints this morning! Will compile and share today/tomorrow.
2
4
61
2
1
16
One of the many reasons enterprise customers will prefer to build and operate their own LLM’s.


1
0
15
Best pod on the block.

🚨 Latest Latent Space is live!
MPT-7B and The Beginning of Context=Infinity
with
@jefrankle
and
@abhi_venigalla
of
@MosaicML
available at all major podcast retailers (and Hacker News 👀)
Personal Highlights:
➜ Discussion of whether
@_jasonwei
's




10
73
473
1
1
15
No mean feat to build this out, and a lot of rat holes to get caught in.
I haven't worked with the dataset itself or read all the RedPJ details, but the LLaMA corpus represents, to my eye, a fair amount of engineering work, and if this repro measures up it's a pretty big deal.
2
0
15
Just saw the
@SciDB
R package for parallel computing on sparse arrays compute an SVD, from the prompt, on a 100Mx18K matrix, in ~5 seconds.
3
13
15
Lots of evidence to suggest a team will release a LLaMA clone sometime in the next 3 months and that the train is already underway. (StableLM does not appear to be it.)
Does anyone have concrete information on who it's likely to be and when?
5
0
13
.
@mat_kelcey
maintains some of the the most peculiar git repositories. Fascinating work going back many years.
0
2
14
To start, the corpus itself is knocking on the door of 5T, which itself presents data engineering challenges. [2/n]

1
0
14
Stoked to be attending
@aiDotEngineer
in SF next week. If you're at the conference and want to learn more about how we're building the operating system for autonomous financial research shoot me a line.
We're hiring for AI engineering, distributed systems, frontend and design!
Last
@aiDotEngineer
update before Sunday:
All tickets sold out this week!
We were >600% oversubscribed since day 1 but ran an invite-only process to ensure everyone you run into will have something great to share!
For those not joining us in person, I've been busy


15
10
108
3
1
13
For years I could write off my two spaces after a period as nothing more than a bad habit. Now, with per-token API charges, it's costs me real money.
1
0
12
Turns out $30 of fine tuning turns GPT-J into a pretty snappy instruction-following model. It's not state of the art, but it's a sight better than I'd previously realized, that's for sure.

1
0
12
Looking forward to speaking at 11a PST today with the one and only
@acroll
and Sam Shah (VP Eng, Databricks) about Dolly and the surprising, emergent capabilities of large language models.
See you there!
0
2
13
Check out the LinkedIn Data team's analysis of venture capital funding using Crunchbase + LinkedIn!
http://t.co/ajD0vZNTB6
0
18
12
In the context of Dolly / Alpaca, but also generally, a model that has not been fine tuned reminds me of a stem cell that has not yet been differentiated.
The potential to become many things is present, nascent, and then, under tuning the network *commits* to a behavior.
0
2
12
GPT-4's ability to identify the person who wrote a passage of text appears to work for other prolific writers. Here
@matt_levine
is picked out based on the opening 4 paragraphs of his March 17 post.

1
1
13
Love this thread - it’s amazing to work at a company with the resources to pull this off, and a leadership team willing to lead with improbable ideas.

@Databricks
just released the first commercially usable, instruction-tuned open-source LLM
Might be a bigger step forward for open-source than LLaMA, Alpaca, et al
I'm sitting here reading the story of how they got there and it's just incredible:

1
16
65
0
0
13
@swyx
@sama
@lexfridman
I’ve been thinking about this a lot lately as well. It reminds me of Hitchhiker’s Guide to the Galaxy, in which the answer is known but the right question remains elusive.
1
0
13
@andriy_mulyar
The heatmap on the right is so good I want to die. The spatial and structural characteristics of language are dear to my heart.
One of my profile backgrounds is a social network of Slack interactions with topical activity coded by color.

1
1
12
Twitter launches program to share data with research institutions. Great model, hope to see this at LinkedIn.
1
8
12
In SF for the Dolly 2.0 model / data release. Who’s up for AI drinks tonight? Sounds like
@seanjtaylor
is east coast this week so it feels a shame to call it Ethanology, but we can still have fun.
1
1
12
The “GPU Poor” hats. 😂

@lizcentoni
@navrinasingh
@tianjun_zhang
@Michaelvll1
@jerryjliu0
We also gave out AI Pioneer awards:
-
@hanlintang
from Mosaic for the largest exit in gen AI 💰
-
@pirroh
for helping 25M+ developers to leverage SOTA code models in their workflow
-
@vagabondjack
for showing us how the GPU poor only need $30 to finetune a great small model


0
0
6
0
1
12
GPT-4 correctly identifies
@ThisIsSethsBlog
as the author of two short posts from March 2023 that don't contain any PII.

1
1
12
@EigenGender
Possible this is what you used, but L-theanine, a compound found in green tea, is synergistic with caffeine and is a ridealong in some caffeine pills.
Has a mellowing effect and some evidence of improvements to cognition.

1
0
12
I love and have used my
@Baratza
Encore coffee grinder for many years, in spite of the fact that it spews coffee grinds all over my kitchen.
Does anyone have a solution for this?
cc
@seanjtaylor

12
2
11
Talking about
@SkipFlag
’s work on deep NLP at Strata this afternoon. Shoot me a line if you’re at the event!
1
1
10
Slides from my SF Data Mining talk on Information Visualization in Large-Scale Data Workflows.
http://t.co/WGoKChfXrw
0
9
11
Check out the excellent pre-print of
@hadleywickham
's new book, "Advanced R Programming"
http://t.co/cCnk2Nf1Qb
(h/t
@tweetSatpreet
)
1
2
11
'Waves' of instruction tuning datasets, the most recent characterized by synthetic, multi-lingual alignment datasets.

1
0
11
StumbleUpon launching $5k Kaggle competition for classification of evergreen content. Winner gets a job interview!
0
7
10
Life comes at your fast. 64k context windows from an open source offering.
Ok y'all, go play! MPT-7B-StoryWriter (64K context window) is free!
0
0
29
0
0
11
The idea of reversing the instruction and completion is such as goofy idea in theory, but appears to work in practice. Like asking the model to play Jeopardy.

2
0
10
It would be hard to lose money on Copilot. Not accounting for reserved capacity or a deal with Azure, $10 / month buys 5M GPT3.5 tokens; ~7.5k pages of text or 20MB of generated code.
Even factoring in other compute costs you’re in the black.

1
0
10
The past and the future converge in this very moment. Somewhere, today, 2023’s Homebrew Computer Club is convening to stand up GPT4All.

Announcing GPT4All-J: The First Apache-2 Licensed Chatbot That Runs Locally on Your Machine💥
Large Language Models must be democratized and decentralized.
83
617
3K
0
1
10