

Ofir Press
@OfirPress
Followers
11,307
Following
3,671
Media
279
Statuses
2,017
I build tough benchmarks for LMs and then I get the LMs to solve them. Postdoc @Princeton . PhD from @nlpnoah @UW . Ex-visiting researcher @MetaAI & @MosaicML .
Joined June 2016
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
SEVENTEEN
• 1097411 Tweets
Taylor
• 223357 Tweets
FELIP TAKES ON BBPHSTAGE
• 100582 Tweets
The Next Prince Q9
• 90992 Tweets
#TimnasDay
• 82056 Tweets
Carat
• 76435 Tweets
オーストラリア
• 63348 Tweets
#サッカー日本代表
• 49171 Tweets
Tattvadarshi Sant Rampal Ji
• 48430 Tweets
BBPH ANN1V WITH BINI
• 42509 Tweets
#あのクズ
• 41130 Tweets
Asnawi
• 37624 Tweets
オウンゴール
• 30728 Tweets
最終予選
• 28076 Tweets
ミンギュ
• 27182 Tweets
誹謗中傷
• 26601 Tweets
Zaplana
• 26040 Tweets
ジョシュア
• 20624 Tweets
ドギョム
• 20075 Tweets
スングァン
• 19643 Tweets
نعيم قاسم
• 19274 Tweets
Witan
• 17482 Tweets
كوريا
• 16619 Tweets
Arhan
• 14969 Tweets
中村敬斗
• 12469 Tweets
Tuchel
• 11549 Tweets
報道ステーション
• 10833 Tweets





















My entire feed is OpenAI employees retweet Sam with the heart emoji.
If the board doesn't let him back, he's going to start a new company and take a large chunk of those people with him.
If the board does let him back, Ilya is going to leave and start a competitor. (1/2)
82
74
3K
We've found a new way to prompt language models that improves their ability to answer complex questions
Our Self-ask prompt first has the model ask and answer simpler subquestions. This structure makes it easy to integrate Google Search into an LM. Watch our demo with GPT-3 🧵⬇️
52
306
2K
There's no moat. You just need $400M and a bunch of good engineers and you can build your own GPT-4.
Now we gotta get someone to build an open version.

66
81
1K
I just discovered regional prompting for image generation and I'm so impressed (wait till the end).
From:
16
199
1K
New (1h32m) video lecture:
Transformers From Scratch: Building 5 Language Models at Increasing Complexity Levels
It's an intuitive way to learn what every component of a modern transformer LM does and why they're there.

6
145
845
Cool new idea from DeepMind:
They evaluate LMs by giving them a piece of code, having them describe it, and then asking the LM to rewrite that code given only the description. The metric is the similarity between the original code and the rewritten code.

24
116
746
Can someone fix this table please? Satya should be at the top.

6
19
736
I'm sure this chaos and uncertainty sucks for all of those involved but if the world gets 2 strong competing LMing companies out of what used to be OpenAI, we'll all win... Especially if the Sam-led one ends up actually being a bit more open. (2/2)
10
19
700
Since Transformer LMs were invented, we’ve wanted them to be able to read longer inputs during inference than they saw during training. Our Attention with Linear Biases enables this, in very few lines of code, without requiring extra params or runtime 🧵⬇

8
158
666
As language models grow in size they know more, but do they get better at reasoning? To test GPT-3, we generated lots of questions such as "What is the calling code of the birthplace of Adele?".
We show that as GPT size grows, it does not improve its compositional abilities🧵⬇️
19
94
586
Everyone thinks that you have to increase the input length of language models to improve their performance. Our new Shortformer model shows that by *shortening* inputs performance improves while speed and memory efficiency go up. ⬇(1/n) (code below)

8
89
545
Reddit launched in 2005. StackOverflow in 2008.
Both are shutting off access to their data because they're annoyed that they aren't getting payed when it gets used for LM training.
Silly move- the value of future data is miniscule given that we already have data from 2008-now.

26
30
506
@TheSeaMouse
Of course they would. He's one of the smartest people in ML.
I disagree with his views but I'm sure that lots of VCs either agree with him or don't care about those things.
16
2
497
ChatGPT can solve novel, undergrad-level problems in *computational complexity* 🤯
"Please prove that the following problem is NP-hard..."
Solution in next tweet -->
Credit:
@TzvikaGeft
(1/3)

15
67
444
I made a simple UI to ChatGPT that lets you easily build complex matplotlib plots, visualize them in the browser and get ChatGPT to solve your bugs.
Try it out at:
Open source on GitHub.
12
75
419
I needed to analyze data, would've taken me 15 mins to code
I asked GPT4 to code it cause it's 2024 and humans dont code anymore
It made a mistake so I asked it to fix it. There was a mistake in the fix so I asked again
Anyways its 1 hour later now and I still dont have the code
29
17
377
If someone doesn't stop Tim soon he's gonna run Guanaco-65B on a globally distributed cluster of 5 toasters and 3 electric toothbrushes at 70 tokens/sec.

I forgot how much better Guanaco-65B is compared to 33B. You can try here via Petals (globally distributed inference):
With Petals, you can also run a 65B model in a colab or locally on a small GPU at ~5 tokens/sec (see below).
2
36
219
5
30
375
Chapyter is a new Jupyter extension that lets ChatGPT assist you in writing Python notebooks. It can also read previous cells and the output of their execution.
This is awesome!
9
76
341
Transformers are made of interleaved self-attention and feedforward sublayers. Can we find a better pattern?
New work on *improving transformers by reordering their sublayers* with
@nlpnoah
and
@omerlevy_

6
81
326
I'm going to defend next week!
You're invited to the livestream!
I'll talk about ALiBi, evaluating models trained on different sequence lengths, and other things that I've worked on for the past few years. I'll also talk about what directions I think we should explore next.

16
26
319
Now that I'm done with the PhD I can tell you what I really think about my advisor
@nlpnoah
:

4
2
276
MEMORIZING TRANSFORMERS (ICLR submission) is a super cool extension of the kNN-LM!

2
35
271
It's been just 10 days since we launched SWE-agent but we already have 1.5k people in our Discord and lots of contributors on GitHub.
We've been making the agent easier to use and there are lots more exciting updates coming soon, including a web UI! Join us :)

6
19
249
SWE-agent is blazing fast, and when it works it feels like magic!
In this short demo I show how it solved a real bug in the neural network training code in scikit-learn. I also explain the process behind our agent-computer interface design choices.
6
44
251
I think GPT-5 will just be GPT-4 finetuned on agent trajectories, meaning that it'll be really good at:
1. Browsing the web: 'Find me a hotel near ICLR 2025 that has a pool'
2. Using GUIs: 'Remove the intro of this video clip'
3. Software Engineering: SWE-bench
18
14
245
Nicholas Carlini has a new HumanEval-esque (but slightly harder & more creative) benchmark for LMs, with ~100 tasks.
Results are as you'd expect:
gpt-4-0125: 49%
claude 2.1: 31%
gpt-3.5: 30%
mistral-medium: 25%
gemini-pro-1.0: 21%

6
34
237
When a student sadly tells me that the idea we've been working on for weeks was just arXived, I say:
"Great! We've just gotten *strong* confirmation that our thinking was in the right direction. We've had the initial work done for us. Lets figure out how to make this 10x better"
6
14
237
New preprint by
@Ale_Raganato
et al. shows that NMT models with manually engineered, fixed (i.e. position-based) attention patterns perform as well as models that learn how to attend. Super cool!

1
48
214
o1 has set a new state-of-the-art on SciCode, beating Claude by a wide margin!
Still *a lot* more to go here :)

7
17
221
DeepMind's Gopher and BigScience's BLOOM already use relative position embeddings, but most other language models don't. I believe we should all start using relative positioning.
In this new post, I discuss the use case for relative position methods:

6
36
209
The next big leap in language modeling is going to come from finetuning them on agent trajectories. This will lead to a big accuracy improvement in end-to-end programming (e.g. SWE-agent), controlling desktop apps (e.g. OSWorld) and web browsing (e.g. SeeAct).
14
22
210
Apple Intelligence's on-device LM uses our weight tying method 😀
Looking forward to receiving my first royalty check in the mail soon
@tim_cook

4
9
203
People are asking us how Claude 3 does with SWE-agent- not well. On SWE-bench Lite (a 10% subset of the test set) it gets almost 6% less (absolute) than GPT-4.
It's also much slower.
We'll have all the data in the preprint next week.

15
18
202
SciCode is our new benchmark, with 338 programming challenges written by PhDs in physics, math, and bio, based on papers in their fields. A bunch of the questions are from Nobel-winning papers!
I hope this becomes the new HumanEval.

SciCode is our new benchmark that challenges LMs to code solutions for scientific problems from advanced papers. The challenges were crafted by PhDs;
~10% of our benchmark is based on Nobel-winning research.
GPT-4 and Sonnet 3.5 get <5% ACC.
🧵 1/6

10
62
263
7
24
201
If Claude 2 turns out to be as strong as GPT-4, thereby breaking the OpenAI monopoly on strong LMing, the number of companies building products on top of LMs will increase substantially.
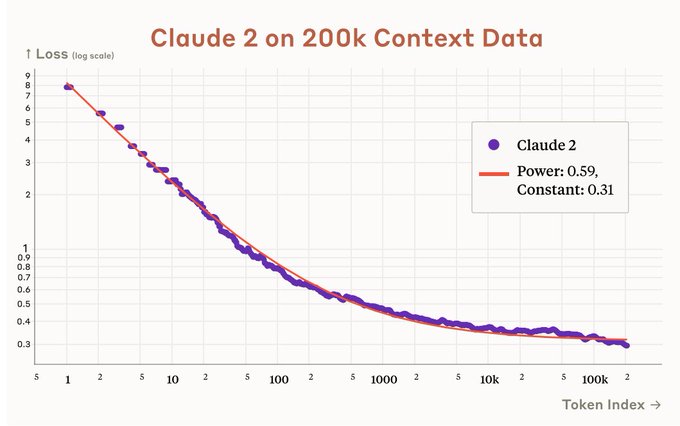
15
18
196
According to the EvalPlus Leaderboard, Gemini Pro is nowhere near GPT-4 (or even 3.5) on HumanEval.
by
@JiaweiLiu_
&
@steven_xia_
et al

11
28
195
It's finally here- ALiBi is officially in FlashAttention 2!
As expected, it's much faster than the PyTorch implementation and just as fast as the Rotary FlashAttention implementation.
ALiBi is the simplest and best positioning method- go try it :)

1
29
182
People have been asking me why I think sinusoidal embeddings don’t extrapolate while ALiBi does.
I think it’s because with position embeddings, transformers don’t actually “understand” the concept of positioning.
The following is my hypothesis- 🧵⬇
5
14
178
If this result is correct, it will show that the LLaMA length scaling trick is almost useless: yes, it lets the model consume longer sequences, but it performs *much worse* across the board when extrapolating.
Better to use the original model with a sliding window,

5
20
161
I believe that in 6-12 months we'll have an open source GPT-4 replication.
But GPT-5 will be built based on immense amounts of human feedback collected like shown here and I'm not sure how the open community will replicate that

First time seeing ChatGPT give me 2 possible responses in this style (I did not press the "regenerate response" button). When did this functionality get added?
I assume it detected I had corrected it multiple times in a row to trigger this mode. Good way to gather RL data.
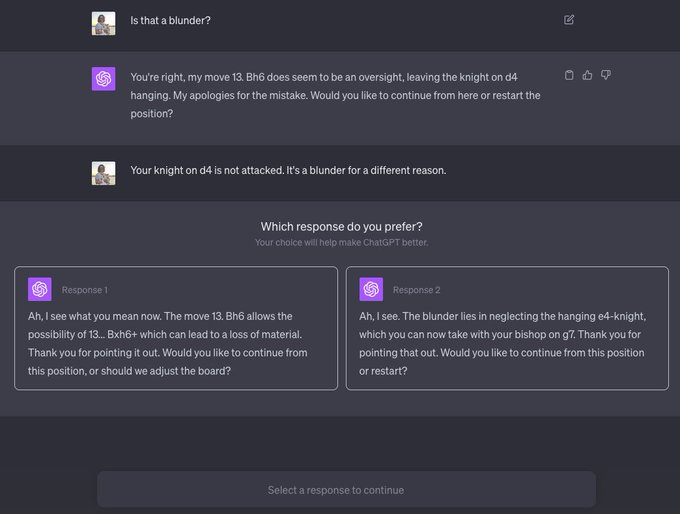
22
26
267
17
14
163
Tim is singlehandedly developing more LM technology than most tech companies.
@karpathy
Super excited to push this even further:
- Next week: bitsandbytes 4-bit closed beta that allows you to finetune 30B/65B LLaMA models on a single 24/48 GB GPU (no degradation vs full fine-tuning in 16-bit)
- Two weeks: Full release of code, paper, and a collection of 65B models
39
193
1K
3
11
165
Get state of the art results in word-level language modeling by simply shuffling the training data! Naively shuffling all of the sentences would not work, so here I present a new method that *partially* shuffles the training data:

2
38
159
Sandwiches will be served at ACL 2020! In our updated paper, we show that sandwiching improves strong models in word *and* character-level language modeling. We match the results of Deepmind's Compressive Transformer on enwik8 even though our model is both much faster and smaller
Transformers are made of interleaved self-attention and feedforward sublayers. Can we find a better pattern?
New work on *improving transformers by reordering their sublayers* with
@nlpnoah
and
@omerlevy_
6
81
326
1
22
158

Sparks of stupidity?
We've found a wide array of questions that lead GPT-4 & ChatGPT to hallucinate so badly, to where in a separate chat session they can point out that what they previously said was incorrect.
@zhang_muru
et al🧵⬇️
9
29
158
Cool new paper by
@XiangLisaLi2
and
@percyliang
that shows that you can train small, continuous vectors to act as 'prompts' for different downstream tasks in GPT-2 and BART.

1
38
157
Love is all you need, and attention may not be all you need! We show that a simple, attentionless translation model that uses a constant amount of memory performs on par with the Bahdanau attention model. with
@nlpnoah
2
58
154
Combining Self-ask + Google Search + a Python Interpreter leads to a super powerful LM that is really easy to implement and run!
Super excited what else people do with this :)

5/
Finally, a potential game changer:
They provide a simple API around "agents," or LLMs that can somehow interact with "tools" (like a python interpreter or search engine) in order to answer questions
The below program hits up both Google and Python to arrive at an answer

3
11
69
4
29
155
Last year we made Bamboogle, a set of questions that Google answered *incorrectly*
I was told that it's now used internally to eval search & LMs, and indeed some of the wrong answers were fixed
So apparently the best way to get support at Google is to write an EMNLP paper 😉 ->

5
15
148
GPT-4 probably trained on:
1. LibGen (4M+ books)
2. Some of Sci-Hub (80M+ papers)
3. All of GitHub
The Stack is an open source release of (3) but we don't really have open releases for 1 and 2.
I think this is a really important step in building the next strong & open model.

7
17
144
Figuring out how data (size and/or type) affects LM performance and how to get more of the types of it that we need (code? papers? YouTube video transcripts?) is the most important research direction in NLP right now.


3
20
141
I have met a lot of people who did their PhD on reinforcement learning.
None of them like RL.
I think there's a very good chance that we figure out how to do the 'alignment' step in LM training without RL. Hopefully without human annotations too. Self-align is a major step.
12
5
142
Is it just me or is it time for a new LM benchmark that GPT-4 and Sonnet 3.5 both get less than 5% accuracy on?
🤔
Maybe I'm weird
23
6
141
A guide to neural language modeling from scratch. Goes over basics and some recent regularization techniques
0
42
136
The progress on SWE-bench is nuts. I think my prediction of 2 systems surpassing 35% pass
@1
on the full test set by Aug 1 will come true.
When we launched in October, nobody wanted to work on the dataset because it was considered "too hard" or "impossible". Acc was 1.96% then.
10
13
134
Google doesn't answer compositional questions well.
We made a dataset composed just of questions that Google answers incorrectly- Bamboogle.
We show that LMs also struggle with these Qs and that self-ask helps LMs answer these (better than CoT).
2
18
130
I heard of a company that bought 100+ H100 cause they want to train their own LMs (to replace their GPT-4 usage) even though they have no people with knowledge on how to train large LMs.
There's reason to be hyped about the future of LMing but some people are being silly. (1/2)

7
7
130
AI assistants have been improving but they still can't answer complex but natural questions like "Which restaurants near me have vegan and gluten-free entrées for under $25?"
Today we're launching a new benchmark to evaluate this ability.
I hope this leads to better assistants!

Can AI agents solve realistic, time-consuming web tasks such as “Which gyms near me have fitness classes on the weekend, before 7AM?"
We introduce AssistantBench, a benchmark with 214 such tasks.
Our new GPT-4 based agent gets just 25% accuracy!
6
47
164
6
22
130
We built a super tough benchmark to test whether models can browse the web to correctly attribute scientific claims.
The GPT-4o-powered agent gets 35%.
Also- the first author is my brother
@_jasonwei
+
@JerryWeiAI
: we're coming for you 🤠

Can AI help you cite papers?
We built the CiteME benchmark to answer that.
Given the text:
"We evaluate our model on [CITATION], a dataset consisting of black and white handwritten digits"
The answer is: MNIST
CiteME has 130 questions; our best agent gets just 35.3% acc (1/5)🧵

6
28
143
4
9
126

The only two numbers worth looking at here are GPQA and HumanEval
On GPQA the result is very impressive. On HumanEval, they compare to GPT-4's perf at launch. GPT-4 is now much better- see the EvalPlus leaderboard, where it gets 88.4
I bet OpenAI will respond with GPT-4.5 soon

Today, we're announcing Claude 3, our next generation of AI models.
The three state-of-the-art models—Claude 3 Opus, Claude 3 Sonnet, and Claude 3 Haiku—set new industry benchmarks across reasoning, math, coding, multilingual understanding, and vision.
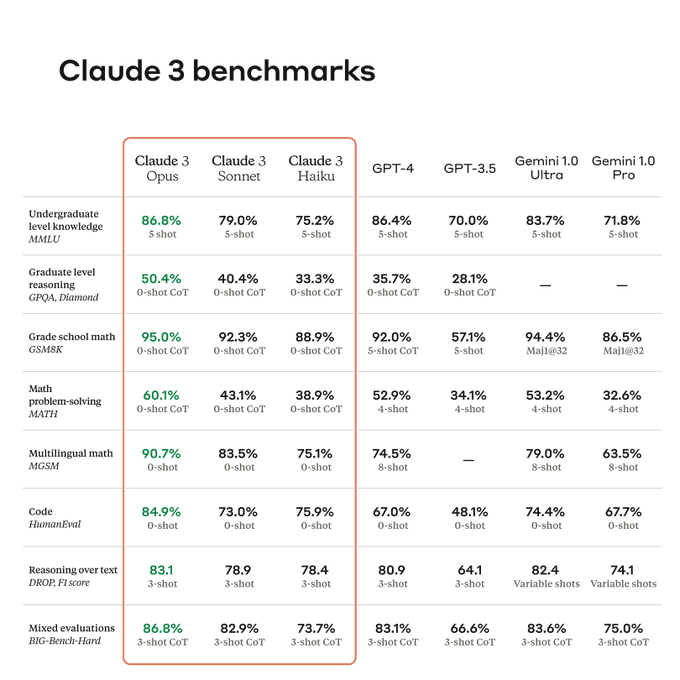
569
2K
10K
6
10
126
Big result in the SWE-agent preprint:
The pass
@6
rate is 32.67% SWE-bench Lite! That's cool!

6
16
126
reddit still hasn't figured out how to be profitable but I don't really see how they get there by shutting off API access.
I get their frustration in not getting payed for "their" data, but it never really was "theirs". It's all user-generated...
3
5
117
Do transformers trained with absolute position embeddings overfit to specific positions?
Do transformers benefit from being trained on >1k context tokens?
How can we correctly evaluate LMs trained on different context lengths?
Watch my ALiBi talk!

0
15
113
We did this a while ago but forgot to tweet about it- SWE-agent + Claude 3.5 Sonnet gets 23% on SWE-bench Lite.

7
13
114
Since lots of people are interested in ALiBi now, I'm sharing my video lecture here, which contains a lot of insights into how transformers work and why we wanted to make them work without position embeddings.
4
14
115
Code LLaMA has good results and good eval. It's cool to see PPL decrease all the way up to 100K tokens (after finetuning on 100K token-long inputs).
Facebook is close to replicating GPT-4 performance on HumanEval. Great news for the open source/science communities!

4
7
113
Asking Goldman Sachs about AI is as productive as asking a group of penguins about architecture.
AI is going to make programmers much more efficient, it's going to do other things as well, but just that programming bit is going to be worth more than $1TN.

From a recent Goldman Sachs report on generative AI: limited $$ upside, capital intensive, can't solve complex problems, no killer app. The bull case is that they somehow figure it all out or simply that "bubbles take a long time to burst." [PDF]

47
600
2K
12
8
106
If you ask Google "When did
@chrmanning
's PhD advisor finish their PhD?" it won't answer correctly.
Self-ask + Google Search answers this correctly!
(Green text is generated by GPT-3, blue is retrieved from Google)
Play with this demo at:

5
11
105
ALiBi+FlashAttention runs faster then Rotary in realistic scenarios, sometimes with a substantial gap
This is even though the Rotary implementation uses Triton and the ALiBi one doesn't yet, meaning that there's more speed to be gained
Credit: shcho1118

0
13
101

I disagree- there's a lot still left to explore in how we can build *on top* of LMs to make them much more useful.
SWE-agent took GPT-4 from 1% on SWE-bench to 12%.
We didn't do any finetuning or training, so this type of research is super accessible to academics.

If you are a student interested in building the next generation of AI systems, don't work on LLMs
366
1K
7K
3
6
101
Hi Dan- I've got about ~1,700 questions for you that no existing AI system can solve, you can get them at and you don't even have to pay me.
~250 of these unsolved questions have also been verified by humans as being definitely solvable.




5
1
102
We just launched SWE-bench Multimodal, a brand new benchmark with 617 tasks *all of which have an image*.
This benchmark challenges agents in new but realistic angles.
We also launch SWE-agent Multimodal to start tackling some of these issues.

We're launching SWE-bench Multimodal to eval agents' ability to solve visual GitHub issues.
- 617 *brand new* tasks from 17 JavaScript repos
- Each task has an image!
Existing agents struggle here! We present SWE-agent Multimodal to remedy some issues
Led w/
@_carlosejimenez
🧵

8
50
245
2
6
113
Every once in a while someone on reddit posts a question about ALiBi. I then respond to it, they don't notice it's me, and then life goes on.

3
4
98
I love this! Earlier layers in transformers make worse predictions than later ones so we can improve decoding performance by biasing against tokens that were assigned a lot of probability by earlier layers.

(1/5)🚨Can LLMs be more factual without retrieval or finetuning?🤔 -yes✅
🦙We find factual knowledge often lies in higher layers of LLaMA
💪Contrast high/low layers can amplify factuality & boost TruthfulQA by 12-17%
📝
🧑💻
#NLProc

1
62
285
2
14
96
Entering the research world is hard, my 6 tips:
* Research involves lots of failure, and that’s ok
* Don’t hide negative results
Working with a mentor:
* It’s ok to say I don’t understand/know/agree
* Advisors don't have all the answers
Full post at
2
8
95
About Scaled LLaMA:
If you train on 2k tokens and then extrapolate to 8k using this, your LM will actually only be looking back at 2k tokens during each timestep. So you are able to input longer sequences but perf. doesn't improve.
I explain this at

@ggerganov
@yacineMTB
Regular LLaMA 7B:
arc_c: 0.41 arc_e: 0.52 piqa: 0.77 wic: 0.5
Scaled LLaMA 7B:
arc_c: 0.37 arc_e: 0.48 piqa: 0.75 wic: 0.49
So it does seem to have a slight performance downgrade, but this is with zero finetuning (!)
5
7
83
10
17
93
AFAIK this is the first release of data that shows what people are actually using LMs for.
The top 2 uses:
30% is for generating/explaining code.
18% is for text manipulation: summarization, expansion, translation, QA about a given text.
(1/2)

Looking for use-cases people actually have for LLMs?
The folks from Vicuna did the number crunching for you! (from their recent 1M chat dataset)
Cluster 9: Requests for explicit and erotic storytelling
Cluster 20: Inquiries about specific plant growth conditions
go go go!
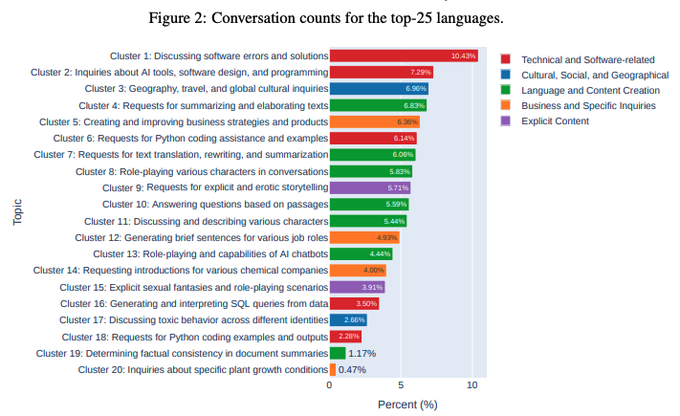
14
57
316
2
6
89
The days of easy LM benchmarking might be over. HELM puts davinci-002 above 003, but my experience with both models makes it pretty obvious that 003 is better than 002.
How can we build better benchmarks?
(HELM is *awesome* btw, I just think we need to rethink benchmarking)

7
8
88
Has anyone even shown that transformer LMs can effectively use 4k context tokens? Very interesting that OpenAI went to 32k already.

OpenAI has privately announced a new developer product called Foundry, which enables customers to run OpenAI model inference at scale w/ dedicated capacity.
It also reveals that DV (Davinci; likely GPT-4) will have up to 32k max context length in the public version. 🔥

39
273
2K
8
7
87
Predictions:
>=2 orgs will get 35% on SWE-bench by Aug 1, 2024.
A fully open source system will reach 35% by Nov 1, 2024. Probably based on SWE-agent + ACI improvements: debugger, better code retrieval, lang. server protocol. The LM will be finetuned on ~500 good trajectories
9
11
84
If you want to start working with and extending SWE-agent,
@KLieret
just wrote this detailed overview of the architecture of SWE-agent:

0
15
85
You can now download & run SWE-agent (on any GitHub issue) in 1 line!
Check our repo for deets:
Join our Discord to hear first about updates like this:

0
7
83
Our paper has lots more info:
The Self-ask + Google Search method is at:
We will release the rest of the code + data shortly.
2
4
82
OpenAI just released a small subset of SWE-bench tasks, verified by humans to be solvable.
I would treat this subset as "SWE-bench Easy"- useful for debugging your system.
But eventually when you're ready for launch, we still recommend running on SWE-bench Lite or the full set

We're releasing a new iteration of SWE-bench, in collaboration with the original authors, to more reliably evaluate AI models on their ability to solve real-world software issues.
403
505
3K
4
10
83
I don't think it's productive or effective for a PhD student to ever lead more than 1 project simultaneously.
If anything, I think leading 0.5 projects is even better (see SWE-bench & SWE-agent which Carlos and John co-led)
Focusing is really important.

Out of curiosity, do AI PhDs normally work (lead) on several projects simultaneously?
I have never managed to work on more than one project during my PhD and I tried to convince my students not to do so. The paradigm might have already changed, so I am asking here.
21
10
75
5
2
82
Just spoke
@WeizmannScience
about building benchmarks that are tough, natural & easily checkable
i.e.
A guy I didn't recognize in the front kept on asking questions the entire talk
After the talk I asked who it was
It was Adi Shamir, the S of RSA! OMG!!

3
2
82
New blogpost on How to Build Good Language Modeling Benchmarks:
4
23
82
"it is possible to distill an approximation of Stockfish 16 into a transformer via standard supervised training. The resulting predictor generalizes well to unseen board states, and, when used in a policy, leads to strong chess play (Lichess Elo of 2895 against humans)"
Awesome!

Google Deepmind presents Grandmaster-Level Chess Without Search
paper page:
largest model reaches a Lichess blitz Elo of 2895 against humans, and successfully solves a series of challenging chess puzzles, without any domain-specific tweaks or explicit

38
274
1K
3
7
80
If you still think that in language modeling, bigger inputs always lead to better models, you should watch the first 5 minutes of my ACL presentation 🤓
Our poster session will be on Wed at 9am UTC, calendar event available at:

1
13
81
Here's a brief introduction and overview of transformer language model position embeddings, extrapolation and evaluation:

4
14
79
How many years is it going to take for the prompt
"a step by step diagram on how to make the first move in a chess game"
to lead to a correct output from the leading image generation model?
Here's DALLE-3's best current take:

6
8
76
Me and my brother are both at NeurIPS!! He's presenting a paper (poster on Wednesday), I'm just here for the vibes.
I'm at
#NeurIPS
presenting my work on infinitely long ImageNet-C and test time adaptation. You can stream the dataset right now (), with no download required! Feel free to reach out to chat about robustness, domain adaptation, or related topics 😀

1
2
39
2
0
78
New rule: all new SWE-bench submissions must now include reasoning trajectories showing all the thoughts/actions/... the system took in order to solve the given issue.
You can use proprietary LMs, you can use proprietary actions, but we want to see your system logs.
2
2
78
HumanEval continues to be the best benchmark right now for LMs. I feel like usually results here correlate pretty well with performance on non-coding tasks too. Crazy to get so much value from ~100 manually written programming challenges.
Source:

10
4
77

I disagree- lots of things to work on in language modeling:
1. Find weird phenomenon in LMs and understand why they happen- hallucination, the compositionality gap, the reversal curse.
2. Take my self-ask + google search system and use it to build a better
@perplexity_ai
🧵

As PhD applications season draws closer, I have an alternative suggestion for people starting their careers in artificial intelligence/machine learning:
Don't Do A PhD in Machine Learning ❌
(or, at least, not right now)
1/4 🧵
36
53
512
2
2
77
How did the OpenAI board pull this off?

2
3
75
mpt-7b is powered by ALiBi! 😎
It performs as well as LLaMA-7B on downstream tasks and is fully open source

Our team at
@MosaicML
has been working on releasing something special:
We're proud to announce that we are OPEN SOURCING a 7B LLM trained to 1T tokens
The MPT model outperforms ALL other open source models!
Code:
Blog:
🧵
27
221
1K
5
8
75