

Vipul Ved Prakash
@vipulved
Followers
4,832
Following
873
Media
67
Statuses
2,402
Building AI factories. Co-founder, CEO @togethercompute
San Francisco, CA
Joined April 2008
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Neeraj
• 184276 Tweets
#JinxGucci
• 144841 Tweets
Cori Bush
• 134290 Tweets
WE LOVE YOU YOONGI
• 85545 Tweets
中丸くん
• 76533 Tweets
AIPAC
• 58262 Tweets
#ARMYLovesSuga
• 47675 Tweets
女子大生
• 41594 Tweets
アパホテル
• 33454 Tweets
KARN x DAOU
• 23922 Tweets
内田副総裁
• 18317 Tweets
小池百合子知事
• 17591 Tweets
イスラエル招待
• 16800 Tweets
中丸さん
• 16617 Tweets
#earthquake
• 16575 Tweets
路上ナンパ
• 16290 Tweets
Dragoneer
• 14915 Tweets
滋賀学園
• 13838 Tweets
TransisiPRABOWO JKWmulus
• 13654 Tweets
剥離骨折
• 13041 Tweets
SATUarah NKRImaju
• 13038 Tweets
本人の希望
• 11336 Tweets
プロ野球の始球式
• 10882 Tweets
全員女子の戦隊
• 10142 Tweets
長崎の平和式典
• 10001 Tweets




















When it comes to LLMs, 2023 was the year of Open Source AI.
At the end of 2022, the quality delta between best open (Bloom) and closed (GPT-3.5) LLM, as measured by MMLU scores, was 90%. At the end of 2023, this delta between GPT-4 and Mixtral-MoE-7B stands at 13%.
7
82
437
The era of sub-quadratic LLMs is about to begin. At
@togethercompute
we've been building next gen models with large space state architectures and training them on very long sequences and the results from the recent builds are... incredible. Will share more as we get closer to

5
34
412
Now hearing fairly regularly how well RedPajama-INCITE-7B performs across enterprise use cases. Several companies have replaced OpenAI with it, and we will soon announce a new partner who is deploying solutions in regulated industries based on the model.

11
44
392
API now offers a 32K context model, built with FlashAttention-2 for $0.20 per 1 M tokens. 300x cheaper than closest commercial model at 32K context (GPT-4).
Smaller, but for many long context tasks like RAG, it’s excellent. And you can fine tune it.

11
49
389
We just got 1024 A100s up and running at
@togethercompute
!!
We are offering short-term dedicated access to AI startups anywhere from 16-128 GPUs. Clusters come pre-configured with distributed training software.
Available immediately (while supplies last) 🚀🚀🚀
17
35
252
OpenAI API compatibility shipped for 100+ models on
@togethercompute
API.
Replace GPT calls with Mixtral or Llama-70B, get faster responses and for less $$
🚀🚀🚀

Transitioning from OpenAI to Mixtral? Simply add your TOGETHER_API_KEY, change the base URL to , and swap the model name.
Oh, and Mixtral Instruct v0.1 is now live on Together API 🙌

31
44
399
8
14
167
The RedPajama-V2 dataset has been downloaded 1.2M times in the last month on
@huggingface
. It’s a great metric of the level of agency in core AI development today, and how vast the open source (and custom) AI surface is going to be.

6
26
149
Wow
@anyscalecompute
is benchmark washing their API’s terrible performance.
All you need is curl and time. Same request
@togethercompute
3x faster for Llama2 70B model — 72 t/s vs 23 t/s (7.04s vs 21.87s)
And this model is under heavy load! Our dedicated instances are


📈We’re excited to introduce the LLMPerf leaderboard: the first public and open source leaderboard for benchmarking performance of various LLM inference providers in the market.
Our goal with this leaderboard is to equip users and developers with a clear understanding of the

10
40
163
8
10
108
A generation of humanity created the corpus (web) that led to the fantastic AI models of today and the only correct (and moral) answer is that AGI is a public good. Open source models are curiosities to some, relegated to sub-frontier by others, but they are more important than
4
19
97
Open source AI APIs will bring about rapid industrialization and distribution of an advanced technology. It has begun and it’s going to be very influential.

Last week
@MistralAI
launched pricing for the Mixtral MoE: $2.00~ / 1M tokens.
Hours later
@togethercompute
took the weights and dropped pricing by 70% to $0.60 / 1M.
Days later
@abacusai
cut 50% deeper to $0.30 / 1M.
Yesterday
@DeepInfra
went to $0.27 / 1M.
Who’s next ??? 📉
57
117
1K
2
14
81

This is why you want to use full precision inference on
@togethercompute

Llama 3 degrades more than Llama 2 when quantized.
Probably because Llama 3, trained on a record 15T tokens, captures extremely nuanced data relationships, utilizing even the minutest decimals in BF16 precision fully.
Making it more sensitive to quantization degradation.

37
135
915
0
9
70
Huge embeddings release from
@togethercompute
including novel M2 models with 32K context. This is also a case of OSS AI being better in both cost and performance than closed models.
We are thrilled to announce the Together Embeddings endpoint! 🚀
Higher quality than OpenAI or Cohere in the MTEB benchmark. ✅
State of the art M2-Retrieval models with up to 32k context length. ✅
Up to 4x lower price. ✅
Details👇

23
60
344
3
6
63
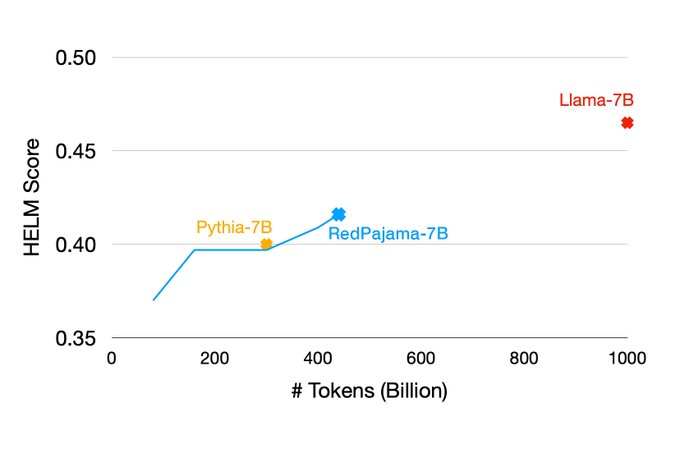
RedPajama-7B performs better at 440B tokens than all the best models trained on Pile, and continues to get better. More information on experiment design in the blog post and will keep you all posted as this converges further!
Training our first RedPajama 7B model is going well! Less than half way through training (after 440 billion tokens) the model achieves better results on HELM benchmarks than the well-regarded Pythia-7B trained on the Pile.
Details at
17
91
498
5
8
63
These models are incredible, and a massive step forward for OSS AI. Amazing work from
@Meta
team!
On
@togethercompute
now at 350 t/s for full precision on 8B and 150 t/s on 70B.
We are thrilled to be a launch partner for Meta Llama 3.
Experience Llama 3 now at up to 350 tokens per second for Llama 3 8B and up to 150 tokens per second for Llama 3 70B, running in full FP16 precision on the Together API! 🤯
28
57
397
7
6
63
Great results from RedPajama checkpoints this morning! Will compile and share today/tomorrow.
2
4
61
The serverless inference API
@togethercompute
is likely
#1
in volume for OSS models (numbers coming soon!). We are also
#1
on performance for almost all regimes according to Martian leaderboard, while providing 6000 RPM rate-limit to anyone who signs up and puts down a CC.

0
10
59
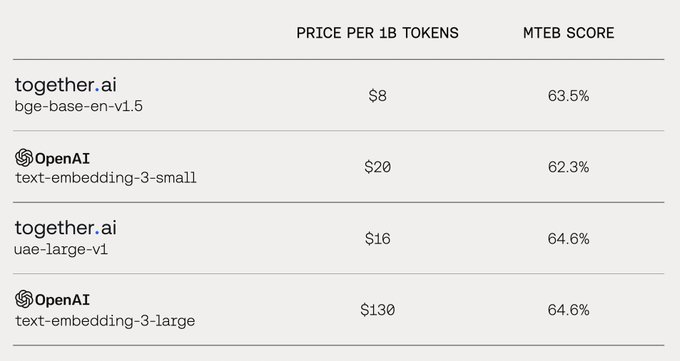
OSS AI and
@togethercompute
offer 8x cheaper embeddings of equivalent or better quality.
Save up to 8x on embeddings.
We can’t wait to see what you build on Together AI.
14
28
296
4
3
59
“If you don’t talk to your kids about quantum computing, someone else will.”
1
26
52
This is a solid and fast long-context model for summarization, Q&A etc. It's better than GPT-3.5x 16K on benchmarks... surprising for a model likely 3-4x smaller!
Introducing our newest long-context model:
💬 Llama-2-7B-32K-Instruct
Fine-tuned using Together API, the model is now available to use with our APIs & Playground:
Try it out and send us feedback!

14
110
449
3
7
52
emerging as one of the top ai dev tools!

The latest AI market survey from
@retool
has some great data. Love seeing
@huggingface
and
@LangChainAI
top the AI dev tools charts!

2
28
176
0
5
51
Together is turbo-charged to take open-source AI and decentralized computing to the next level. Thank you to
@Lux_Capital
and our seed investors for backing our view that technology is pivotal for humanity and should be open and accessible.
We’re excited to announce our $20M seed round of funding to empower innovation and creativity by providing leading open-source generative AI models and an innovative cloud platform that makes AI accessible to anyone, anywhere.
26
39
283
9
10
52
RedPajama is the start of a big project in open-source, decentralized AI.
Announcing RedPajama — a project to create leading, fully open-source large language models, beginning with the release of a 1.2 trillion token dataset that follows the LLaMA recipe, available today!
More in 🧵 …

38
408
2K
1
5
51
Law is the language for scaling civilization. LLMs are going to be particularly adept at law given the amount of data in public domain. Happy to be sponsoring the
#LLM
x Law hackathon at Stanford today. Thanks to
@CodeXStanford
for organizing.


2
7
51
Great story by
@WSJ
on how
@togethercompute
is reducing the cost of AI with GPUs in alternate data centers like mining farms. With the combination of hardware and software, we are almost certainly the most efficient infra for building large models today.
0
13
47
A new sub-quadratic BERT that is 25% more parameter efficient, faster and can scale to long sequences. This is an exciting direction!

1
11
46
Tonight’s benchmarks and evals look spectacular! This thing may be ready to serve.
5
5
46
AI is akin to big science, and open and transparent research is more important than ever. Today,
@togethercompute
released the largest ever open dataset for training LLMs. 30T tokens selected from 100T raw tokens.
We are excited to release RedPajama-Data-v2: 30 trillion filtered & de-duplicated tokens from 84 CommonCrawl dumps, 25x larger than our first dataset.
It exposes a diverse range of quality annotations so you can slice & weight the data for LLM training.

20
284
1K
1
2
42
This story is wild. Texas Semi didn't make Morris Chang CEO (presumably due to his ethnicity), pivoted to calculators instead, lost the 8086 deal and their lead in manufacturing high-end chips. Taiwan wooed MC back, with $70B to start TSMC (of which he owned no stock). Morris

TSMC...should have been TEXAS Semiconductor Manufacturing Corp
We cannot make the mistake again where brilliant diverse talent feels more comfortable OUTSIDE the US than INSIDE 🇺🇸
The movement of a single brilliant scientist––can and has lead to movement of militaries...
152
608
4K
0
9
43
Long-context is one of our active research themes at
@togethercompute
. Today, a version of LLaMA 2 7B with 32K context, as well as optimized inference for them model and code to fine-tune it.
We just released LLaMA-2-7B-32K, a 32K context model that can be fine-tuned for tasks like doc understanding, summarization & QA!
Built with Position Interpolation & our data recipe/optimizations, run inference & fine-tune with up to 3x speedup.
Thread👇
12
168
726
0
2
41
One of the most viral AI games right now runs on
@togethercompute
APIs.
This thing is so simple, fun, and addictive, that I find myself thinking about it when I am not playing it!

1
5
41
.
@JuiChakravorty
built something unique, valuable and virtuous. It’s sad to see it’s ending. But their stories will continue to be hosted and I’d highly recommend clicking through and checking them out if you haven’t.

Sad to say goodbye to the incredible team that made up
@byondtv
, and whom I am helping with softer landings as we fold. I am incredibly proud of the journalism we have produced together, and I cannot recommend them highly enough to future employers.
1
10
25
7
3
37
Evo from
@togethercompute
and
@arcinstitute
is a biological model that can do generative design at whole genome scale, generate novel crispr systems, and more.
It’s based on the StripedHyena architecture that is scaling incredibly well to new domains with astounding context
Introducing Evo: a long-context biological model based on StripedHyena that generalizes across DNA, RNA, and proteins. It is capable of prediction tasks and generative design, from molecular to whole genome scale (over 650k tokens in length).

8
77
358
1
7
38
@Simeon_Cps
@FraserGreenlee
This is not how computer security works — there’s a small set of systems that have enough surface area to be targets for 0days and superhuman level hackers are already all over these systems. Instead of spraying FUD on Twitter and calling for licenses for use of computers, apply
1
3
35


All LLaMA 2 variants available in playground and APIs in private instances on Together API.
LLaMA 2 is available in Together API!
Launch an A100 instance for $0.15/hour for LLaMA-2 70B & a L40 instance for $0.13/hour for LLaMA-2 7B and 13B.
Sign up to immediately start testing these models in playgrounds and with our inference API.
→

6
37
157
1
4
33
With $25 you have 40M free tokens to try over 100 open source models.

Wow
@togethercompute
seems to be offering $25 up front for new users. If you use that on mistral 8x7B that's 40 million tokens. That's GPT3.5 capability, probably around 10,000 chatbot interactions (assuming a typical bot conversation is around 4000 tokens).
4
6
50
2
6
33
The
@NousResearch
team are magicians!

Non-mixed Mistrals are still seeing lots of action.
Huge growth this week on Capybara 7B, a
@MistralAI
finetune by
@NousResearch

2
9
56
1
4
33

The new
@togethercompute
inference is wild! Gets to 117 t/s on 70B and 171 t/s on 13B.
Announcing the fastest inference available anywhere.
We released FlashAttention-2, Flash-Decoding, and Medusa as open source. Our team combined these techniques with our own optimizations and we are excited to announce the Together Inference Engine.
14
126
647
1
5
32
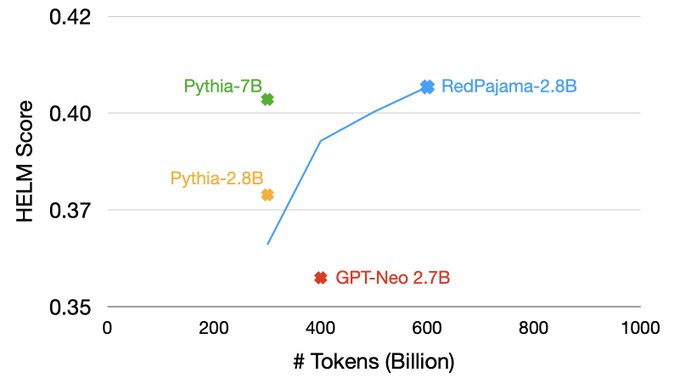
The 2.8B RedPajama has great performance at 60% complete. This model, esp with quantization, could bring LLM capabilities to smaller devices.
In addition to RedPajama 7B, we’ve also been training a 2.8B model. After 600B tokens it is exciting to see the model has higher HELM scores than the excellent Pythia-2.8B & GPT-Neo 2.7B.
In fact, trained with twice the tokens, RedPajama-2.8B has comparable quality to Pythia-7B!
13
79
522
0
2
31
Full-precision Mixtral-8x22B now on
@togethercompute
API. The fantastic
@MistralAI
team keep delivering!
#ossftw
🚀Mixtral-8x22B-Instruct-v0.1 now available on the Together API! 🚀
We can't wait to see what you build!
6
16
126
2
3
29
.
@CrusoeEnergy
has built a wild infrastructure that captures methane flaring and turns it into carbon negative energy that powers their on-site datacenters. Together uses this to build carbon-negative LLMs! Exciting partnership
#scifi
#SFClimateWeek
As part of building the Together Decentralized Cloud, we care deeply about the impact on the environment. That's why we are excited to share how Together and
@CrusoeEnergy
are reducing the carbon impact of generative AI.

1
11
37
1
6
27
The StripedHyena models from
@togethercompute
and collaborators open up a new architecture that's competitive with the best modern transformers on existing benchmarks with incredible long-context performance and possibilities. And a lot faster at inference!
Announcing StripedHyena 7B — an open source model using an architecture that goes beyond Transformers achieving faster performance and longer context.
It builds on the lessons learned in past year designing efficient sequence modeling architectures.

31
265
1K
5
2
26
AOL’s best play would have been to argue for regulating large frontier networks given all the terrifying scenarios of fake news and bad actor enablement apply to the Internet. Luckily internet regulation has gone in the opposite direction — to keep it open and accessible.
0
5
25
Exclusively for the
#gpuoor
. We are just getting started here!
Our first large H100 cluster (4424 GPUs) starts coming online today! Available as sub-clusters configured for pretraining models. We plan to prioritize the startups and research institutions. 🚀👾
Request access:
18
33
369
1
0
25
Thanks for sharing
@Clem
. Nice to see OpenChatKit on the trending list!

Trending models and spaces of the week on . Cool to see
@togethercompute
@thibaudz
@GoogleAI
Flan-ul-2, codeformer, controlnet and many other great repos!


2
16
99
3
4
23
Pyrocumulus clouds and fire tornadoes. Wild.

2
1
20
Snorkel’s data tools are amazing. Combined with Together APIs, companies can turn their data into high quality LLMs based on open architectures. Excited for this partnership with
@SnorkelAI
!

0
3
24
Last year my prediction of when this might happen was so embarrassing wrong… RedPajama 3B quantized to int4 running on iPhone.
RedPajama 3B now runs on an iPhone!
... or on AMD, Nvidia, Intel GPUs, Apple Silicon, iPhones, and Android phones.
Excited by the possibilities this opens up for personal, private LLMs trained and running on your local device!
#opensourceai
#mlcllm
9
127
565
0
0
23
The inference endpoints from
@togethercompute
offer the lowest Time to First Token, the highest Tokens per Second *and* the best price for Llama2 and other open models.

Did a roundup of LLM performance based on time-to-first-token and tokens-per-second for OpenAI, Anthropic, and various Llama2/Mistral providers (
@octoml
,
@perplexity_ai
,
@cloudflare
,
@togethercompute
). Solid showing by the Llama2 70B offering from Together, almost 100 TPS!

15
26
203
0
0
23
Everyone involved in GenAI is doing incredible, foundational and historical work to enable what’s to come!
0
0
22
If you want to know what OSS model serving API has the best performance just ask Devin to build you an objective benchmark. It builds a real-time website with comparative metrics all by itself!
Truly incredible product from
@cognition_labs
.

Today we're excited to introduce Devin, the first AI software engineer.
Devin is the new state-of-the-art on the SWE-Bench coding benchmark, has successfully passed practical engineering interviews from leading AI companies, and has even completed real jobs on Upwork.
Devin is
5K
11K
45K
3
3
23
Wild that we are a point where you can generate 40MB of code (size of OS/2!) for $2. Code Llama on .
1
4
22
StarCoderChat Alpha on
@togethercompute
playground is super fun. Great coding assistant and also a great technical interview assistant🤣

1
3
20
Share and enjoy!
The first RedPajama models are here! The 3B and 7B models are now available under Apache 2.0 license, including instruction-tuned and chat versions!
This project demonstrates the power of the open-source AI community with many contributors ... 🧵

19
226
887
2
5
21
Beer from Space!
@DJSnM
and
@helloanjalig
I am saving some for you for when I see you next time.

3
0
21
Window AI is awesome and comes with
@togethercompute
built in. Users choose their preferred AI backends and AI-first apps can proliferate without the hassle of supporting credits, accounts, etc. Less lock-in, more privacy, more options. This is the way!

1/ Excited to launch an experiment today - introducing Window, a way to use your own AI models on the web - including local ones!
It's a bet on a new kind of AI app emerging, one that shifts model authentication and management to the user.
69
220
1K
1
3
21
We will look back at AI x-risk as the odd little cult movement of the 2020s.
1
4
21
Code models IMO are the highest leverage technology in existence today. The products that apply these effectively are going to be hard to differentiate from magic.
Fine-tuning Code Llama is now as easy as uploading a file and picking the model to tune.
All Code Llama models are also available for inference.
Try it now with $25 in free trial credits, enough for 5 fine-tuning jobs at

1
11
57
2
1
20
@cHHillee
Per this[1], 576 chips @ ~$20K each[2] w/ INT8 LLaMA-2, or ~$12M system. Communication topology is essentially 3.2Tbps for each 230MB SRAM. Much cheaper to do this with NVIDIA GPUs. In fact, would be fun to!
[1]
[2]

2
0
18
8x inference performance on long context with models like CodeLLaMA-34B!
Announcing Flash-Decoding, to make long-context LLM inference up to 8x faster!
Great collab with
@AIatMeta
xformers team. Main idea: load the KV cache in parallel, then separately rescale to combine the results.
Try it now on Together API:
2
21
144
0
1
20
LLM hallucinations, aggravating as they are for practical systems, can be a cool peek into the collective unconscious. I hope there will be a field of generative sociology… this stuff seems worthy of serious scholarship.
2
3
19
Excited to participate in the virtual conference on LLMs in Production Part II on 15-16th of June. I will be speaking about "Building RedPajama". Register here to join us!

0
1
18
I can chat with this model in transliterated hindi! Really cool work by teams at
@SambaNovaAI
and
@togethercompute
. Also a nice counterpoint to the narrative of open-source AI = small models. Open models come in all sizes.
BLOOMChat is a 175B chat model able to have multilingual conversations after being fine-tuned on English data. Built by
@SambaNovaAI
and Together by fine-tuning
@BigscienceW
BLOOM.
Details in 🧵, try it now on
@huggingface
!

9
96
414
2
8
19
Software hasn't been this fun in a while! Some exciting (and truly open) AI goods from
@togethercompute
coming this week.
1
1
18
Training models? Go to
@togethercompute
!
We've added 6,096 H100s to our fleet in Together Cloud. Leading AI companies like
@pika_labs
,
@cognition_labs
and
@LiquidAI_
train on Together Cloud. We have optimized the infrastructure and software for large scale training and inference.
Visit to

3
8
103
0
2
17
AGI will likely have similar dynamics to the personal computing market which came to be dominated by open architectures and commodity components. Even more so, since switching costs are close to zero.
One big hint is that the defense of the closed business model requires appeal

despite recent progress and endless cheerleading, open-source AI is a worsening investment for model builders, an inferior option for developers and consumers, and a national security risk. I wrote about the closed-source future of foundation models here
132
37
321
1
0
18
A story that hasn’t received as much attention as it should is how EA has been surreptitiously shaping the AI security attitudes in the US. Glad to see
@sharongoldman
on the trail.

2
4
14
Word.

0
0
14
All the new Qwens on
@togethercompute
on the day of release!
Qwen1.5 models released today and available on Together API at launch!
Full list below and more details available on Qwen blog here:
We can't wait to see what you'll build!
Qwen 1.5 (0.5B) :
Qwen 1.5 Chat (0.5B) :
4
19
103
0
0
15
Based decodes without KV cache!
Excited to share new research we collaborated with
@HazyResearch
on — Based, a new architecture that leverages attention-like primitives – short (size-64) sliding window attention and softmax-approximating linear attention.

3
35
236
0
0
14
Is it not possible to detect new fires in California (or anywhere) by taking a diff of recent satellite images? I understand sat images are 30cm granularity, which would seem to be sufficient for something like this. Why isn’t this done?
5
0
14
AI has found its Bessemer process in open source, and I believe what we’ll see over the next year in LLMs is an overall improvement in quality (including a general shift towards multi-modality) and a lack of perceptible delta between open and closed.
1
0
13
1-bit fine-tuning deltas!
Excited to share new research on BitDelta, a simple method for compressing fine-tuning deltas into a single bit! This research was done by our own
@tri_dao
in collaboration with researchers at
@MIT
and
@Princeton
.
Read more in our blog post:
0
4
28
1
0
14
.
@togethercompute
and friends cooking up some tasty open-source LLMs. Almost ready to serve!
1
0
14
The story of a T-shirt I once made that was classified as a weapon:

1
3
12
And the cost of AI will start to drop to the point of becoming a viable platform technology, similar to where x86 got in the late 90s and led to new technological substrates like the consumer internet and the Linux operating system.
1
0
12
I'd wager we've crossed a certain threshold of inevitability of open source AI, which, in turn, will result in more alignment with open across the industry.

This was quite a week in AI!
Google's "no moat" leak and amazing new releases by
@togethercompute
@MosaicML
@BigCodeProject
our blog talks about how AI's technical moat is shrinking and why it's good to be optimistic about open source:

3
50
135
2
2
13
@vagabondjack
Training is well underway and we should have something to share a lot sooner than that!
0
0
13
Why do all the “free thinkers” defending Antonio Martinez tend to say exactly the same set of things and stan exactly the same subset of celebrity Twitter?
2
0
12
I have always admired
@m_ryabinin
work. Amazing to be working together!
We’re excited to announce that
@m_ryabinin
is joining Together AI! Max is behind many projects that defined today’s open source LLM landscape, from BLOOM to Hivemind and Petals.
Max is helping us build the fastest cloud for generative AI & advance the frontier of open source AI!
3
9
69
0
0
13
This is going to cause a fairly large change in market dynamics. Closed models will follow more niche and market oriented use cases, with the broader market coalescing around open models.
2
0
12
The glue that connects the latent space with the software space is the key ingredient in the most rewarding AI products I am seeing these days. We announced
@togethercompute
’s first feature here with function calling and JSON mode today. More coming!
We are excited to introduce function calling & JSON mode on Together Inference for Mixtral, Mistral, and CodeLlama!
Read on for examples 👇

15
52
330
0
3
13
Mixtral is fantastic and now available on Together’s Serverless API at > 100 t/s!
Access Mixtral with the fastest inference performance anywhere! Up to 100 token/s for $0.0006/1K tokens — to our knowledge the fastest performance at the lowest price!
Mixtral-8x7b-32kseqlen
@MistralAI
& DiscoLM-mixtral-8x7b-v2 are live on Together API!
48
149
1K
0
0
12
@dylan522p
The problem with the argument is that there'd be no AI companies or game studios if all that mattered for AI progress was the raw compute footprint. It certainly does matter esp when it's multiple orders of magnitude, but progress is bound on research after a certain threshold.
1
0
12
@albfresco
@togethercompute
The Information likes to misrepresent
@togethercompute
with these click-bait articles. It makes zero sense. It’s like calling every cloud company an Intel Reseller.
3
0
12