
Hao Zhang
@haozhangml
Followers
4K
Following
904
Media
5
Statuses
499
Asst. Prof. @HDSIUCSD and @ucsd_cse running @haoailab. Cofounder and runs @lmsysorg. 20% with @SnowflakeDB
San Francisco
Joined July 2021
Did you know that open-source 📽️ Video DiTs are catching up to Sora and Veo?. Big update from our lab: after spending many H100 hours, we cooked up a distillation recipe for SoTA models like Mochi and Hunyuan. Introducing FastVideo: you can now whip up 720p videos in less than a.

🎥 Frustrated by Sora's credit limits? Still waiting for Veo 2?.🚀 Open-source video DiTs are actually on par. We introduce FastVideo, an open-source stack to support fast video generation for SoTA open models. We have supported Mochi and Hunyuan, 8x faster inference, 720P
7
15
115
As our PagedAttention paper is live, it is time to delve into several key techniques in LLM serving. The 3 most important and *MUST-KNOW* techniques for a (2023-ish) top-notch LLM serving system:.(1) continuous batching: 5 - 10x throughput improvement,.(2) paged attention: 3x.

Efficient Memory Management for Large Language Model Serving with PagedAttention. paper page: High throughput serving of large language models (LLMs) requires batching sufficiently many requests at a time. However, existing systems struggle because the

9
141
621
A much-delayed life update: I will be joining @UCSanDiego @HDSIUCSD as Asst. Prof. this July. I am recruiting postdocs and students who are interested in ML and systems! I do a lot of research on large models like #chatgpt! Check out my page 1/5.
20
20
272
We Just released the delta weights of our Vicuna 13B. Try on your own GPU with this chatbot that is closest to chatgpt in open source!. We #lmsysorg 💕 open source and open science.

We are excited to release the weights of Vicuna-13B. 🔥 Run it with a single GPU on your own machine!. Get the weights: Web UI demo: Command line demo: see below
4
25
158
New results just dropped. Check out our new, fast decoding algorithm -- lookahead decoding!.
Introduce lookahead decoding:.- a parallel decoding algo to accelerate LLM inference.- w/o the need for a draft model or a data store.- linearly decreases # decoding steps relative to log(FLOPs) used per decoding step. Blog: Code:
1
13
147
Check out consistency LLM (to appear at ICML'24)!. We found that we can easily adapt an LLM as a parallel decoder by training it on autogen jacobi decoding trajectories using a consistency loss -- just like how we train consistency models in diffusion. The model quickly learn.
People often see LLMs as sequential decoders, but we show they can be easily adapted as fast parallel decoders!🔥🚀. Announcing consistency LLMs: teaching LLMs to predict the fixed point from any point on its Jacobi decoding trajectory.- LLM can fast forward on token generation.

5
11
138
Was about to drop some cool research results on X last Friday, but then the OpenAI drama wave hit. Thought I'd wait for the calm on Monday to share, but seems like the drama sea is endless. 😅😂.
3
2
125
Hi @mustafasuleyman: how about you give us (lmsys) an API access so we can put inflection-2 in chatbot arena? Thanks!.

Thrilled to announce that Inflection-2 is now the 2nd best LLM in the world! 💚✨🎉. It will be powering very soon. And available to select API partners in time. Tech report linked. Come run with us!.
3
8
120
ok confirmed it is competitive to o1😁


🚀 Introducing DeepSeek-R1-Lite-Preview, our latest advancement in reasoning!. ✨ May the gods of scaling laws bless our journey toward AGI :). 🌐 Try it now at
6
4
118
Congrats @MSFTDeepSpeed. SplitFuse is a pretty interesting and effective technique to further speedup inference. Similar techniques called piggybacking/chunked-prefill were studied by another group of MSR researchers and posted on arxiv earlier: Worth a.

Introducing DeepSpeed-FastGen 🚀. Serve LLMs and generative AI models with.- 2.3x higher throughput.- 2x lower average latency .- 4x lower tail latency.w. Dynamic SplitFuse batching. Auto TP, load balancing w. perfect linear scaling, plus easy-to-use API.

0
13
111
Our latest work on long sequence training (almost) reinvented sequence parallelism with many new optimizations very specific to today's decoder LLMs and memory-efficient attention. Training 2x faster on 8x longer sequences!. There is a secret trick that can readily accelerate.

Introduce LightSeq for long-context LLM training:.- Highly optimized for decoder models.- smarter checkpointing.- better support for fewer heads models.up to 2x faster, 2-8x longer sequences vs Megatron-LM.
0
18
97
Thrilled to see Deepseek/Kimi pushing the boundaries of open-source reasoning models! Two thoughts:. 1⃣The paper mentioned MCTS/PRM as "unsuccessful attempts". Remember @denny_zhou's poll on which one to scale?(. Looks like the community nailed it!😄. But.

🚀 DeepSeek-R1 is here!. ⚡ Performance on par with OpenAI-o1.📖 Fully open-source model & technical report.🏆 MIT licensed: Distill & commercialize freely!. 🌐 Website & API are live now! Try DeepThink at today!. 🐋 1/n
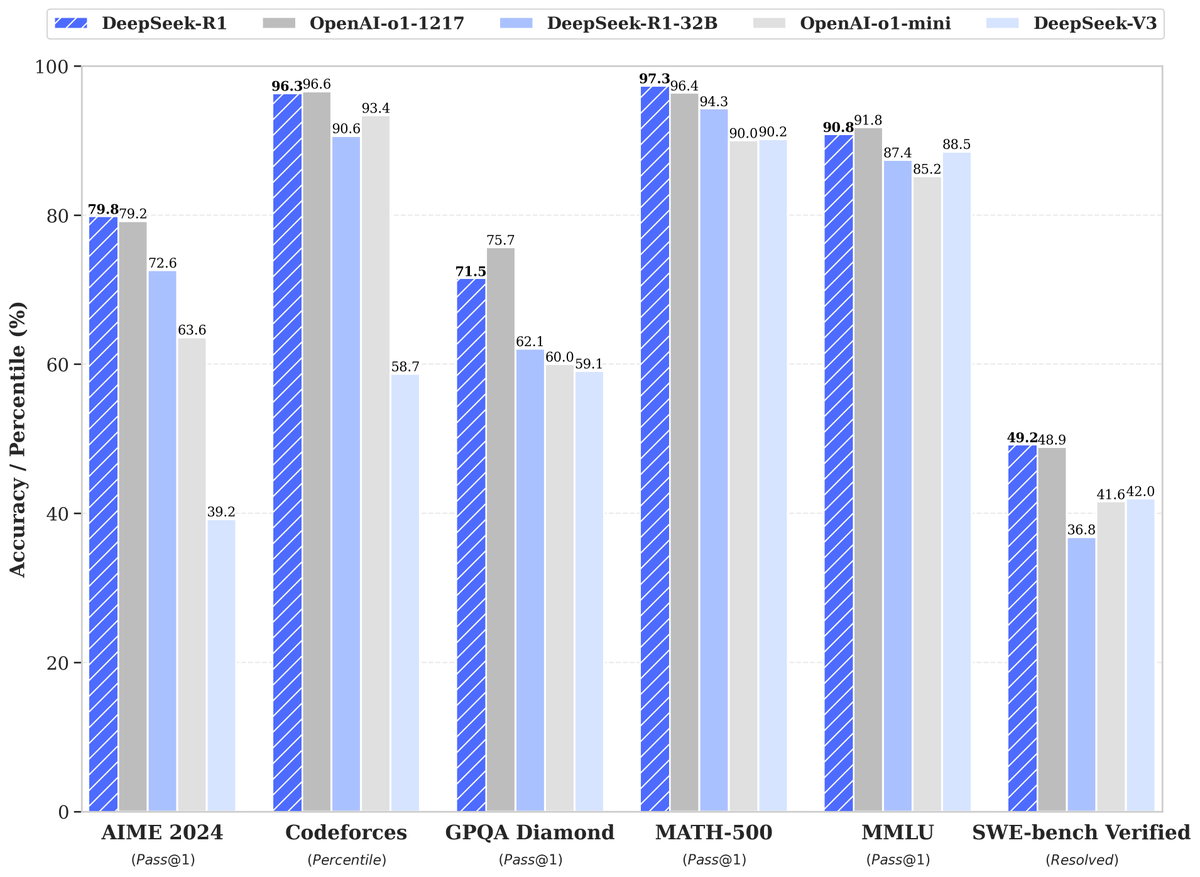
3
14
92
A lot of interesting discussion about consistency LLM on hacker news! 😀😀.

2
9
78
Nice list, but I must admit there's a tinge of sadness that our line of work on Alpa is not on this list. Our @lmsysorg team, though widely recognized for Vicuna and vLLM, have been deeply studying model-parallel training for years and derived a lot of math/systems to help.

The Model Parallelism chapter of the ML Engineering is now quite complete. The future of training LLM/VLMs is exciting with so many great minds putting their smarts into giving the ML community amazing tools to work with. I will now stop making too many

5
8
70
Recently we port several new open-source large models into alpa.llm_serving package -- BLOOM-176B, Codegen-16B, and OPT-IML WIP!🔥 Try to host them on your cluster with alpa. We'll also repurpose to offer inference API endpoints on all of them, stay tuned!.
3
5
68
Will miss this year #NeurIPS for good reasons but do check out two papers from our lab:. * Efficient LLM Scheduling by Learning to Rank, led by my awesome student @FuYichao123, Fri 11am@East Exhibit Hall A-C #2608. * Megalodon: Efficient LLM Pretraining and Inference with

0
3
50
Welcome @yuxiangw_cs to UCSD!!. Yu-xiang was my context optimization go-to TA back when we were at CMU and I still remember every night I spent on his assignments 😄😁. Excited to reunite at UCSD and amp up UCSD's ML/systems to the next level!.

It's an eventful month in ML with #ICML2024 notice, #AISTATS & #ICLR happening, and #NeurIPS deadline creeping up. It's high time for a *career update*: I've joined @UCSanDiego as an associate professor in @hdsiucsd and @ucsd_cse. Super excited about the new chapter to come!

4
4
48
Thanks for your words. Please consider donating us a bunch of GPUs or endpoints so we can host more models (esp. those you want to see)?. This is really a community effort and we leverage a lot of helps, resource-wise and manpower-wise, from the community members like @mbzuai.

@lmsysorg You are right; I was harsh in my previous comment. I am sorry. thank you for your warm response.
5
4
48
The vLLM/PagedAttention paper is available on arxiv!.
Efficient Memory Management for Large Language Model Serving with PagedAttention. paper page: High throughput serving of large language models (LLMs) requires batching sufficiently many requests at a time. However, existing systems struggle because the
1
3
46
Check out our latest blogpost discussing a better metric -- goodput (throughput s.t. latency constraints) -- for LLM serving, and our new technique prefill-decoding disaggregation that optimizes goodput and achieves lower cost-per-query and high service quality at the same time!.
Still optimizing throughput for LLM Serving? .Think again: Goodput might be a better choice!. Splitting prefill from decode to different GPUs yields.- up to 4.48x goodput.- up to 10.2x stricter latency criteria. Blog: Paper:
1
10
43
Congrats to Mistral on the release of the best 7B model ever!. Extremely exciting to see that Mistral adopted the full stack of LLM infra we built at fastchat as the finetuning and serving infra, vllm as the inference engine, and mt-bench for evaluation!.

Mistral 7B is out. It outperforms Llama 2 13B on every benchmark we tried. It is also superior to LLaMA 1 34B in code, math, and reasoning, and is released under the Apache 2.0 licence.

0
1
37
I'll be speaking at #RaySummit tomorrow (Aug 23) in San Francisco!. I'll introduce Alpa (again :-) and explain the technology behind our free unlimited OPT-175B hosting at . If you happen to be around, let's grab a coffee and chat about big models!🙂

1
5
35
Flying to Philly tomorrow to attend the 1st COLM 😍😍 Let's catch up!.
2
1
35
Nvidia's latest GPUs feature CUDA MPS, an often overlooked but powerful tool that allows spatial partitioning of GPUs SMs while sharing memory. MuxServe shows that you can leverage this feature to max out GPU utilization in LLM serving by:.* precisely partitioning and assigning.
Multiple LLM serving has emerged as a crucial and costly demand. Want to co-serve multiple LLMs with better utilization?. Introducing MuxServe.- flexible spatial-temporal multiplexing.- up to 1.8x higher throughput. Blog: Paper:
0
4
32
Flying to Neurips, staying there until 12/17. Happy to chat with anyone on topics:.- LLMs: pretraining, finetuning, data curation, etc. - LMSYS: how we can do better to improve our projects at @lmsysorg : arena, fastchat, vLLM, and more!.- Phd applicants: I am recruiting 2-3.
LMSys members will be NeurIPS! @lm_zheng @infwinston @ying11231 @DachengLi177 @haozhangml. Look forward to meeting with people. Let us know if you’d like to chat!.
0
3
32
Checkout Megalodon: a new alternative architecture of transformers:.- head-by-head comparison at the scale of 7B and 2T tokens showing lower ppl.- unlimited ctx len.- constant KV cache at inference. Exciting work by @MaxMa1987 @violet_zct @_xiaomengy_ . Ckpts available soon!.

How to enjoy the best of both worlds of efficient training (less communication and computation) and inference (constant KV-cache)?. We introduce a new efficient architecture for long-context modeling – Megalodon that supports unlimited context length. In a controlled head-to-head
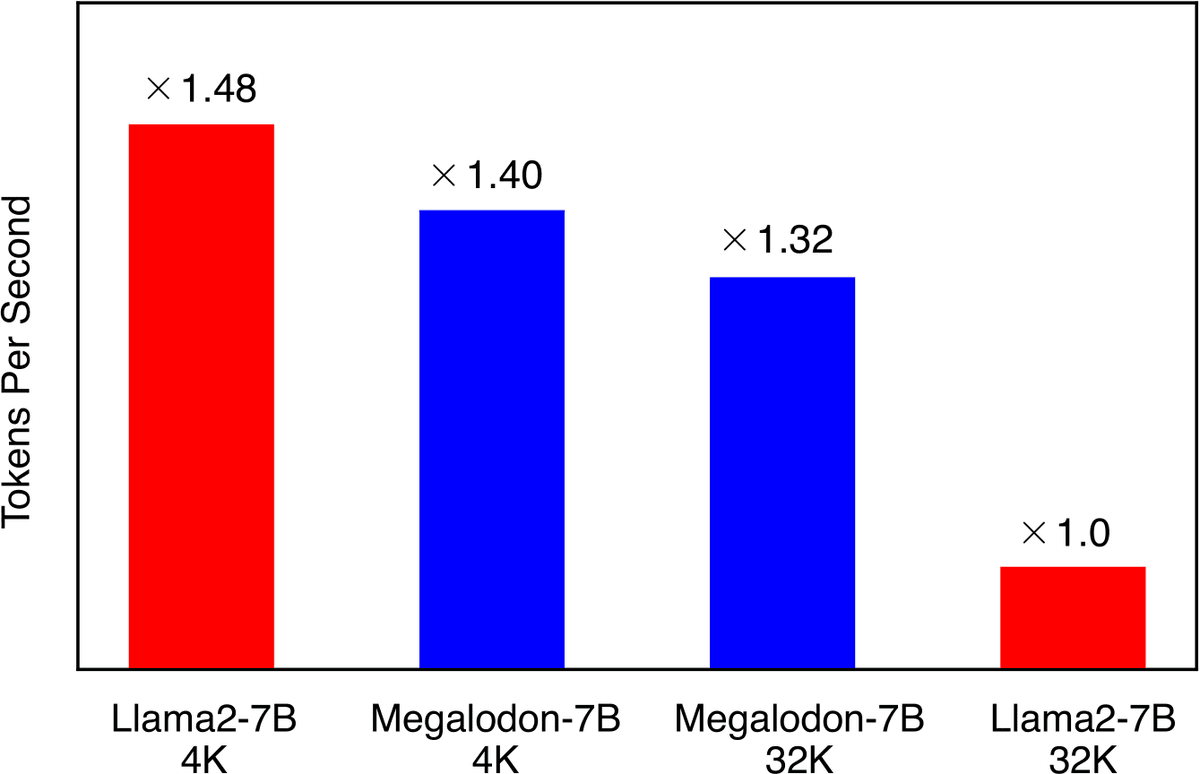
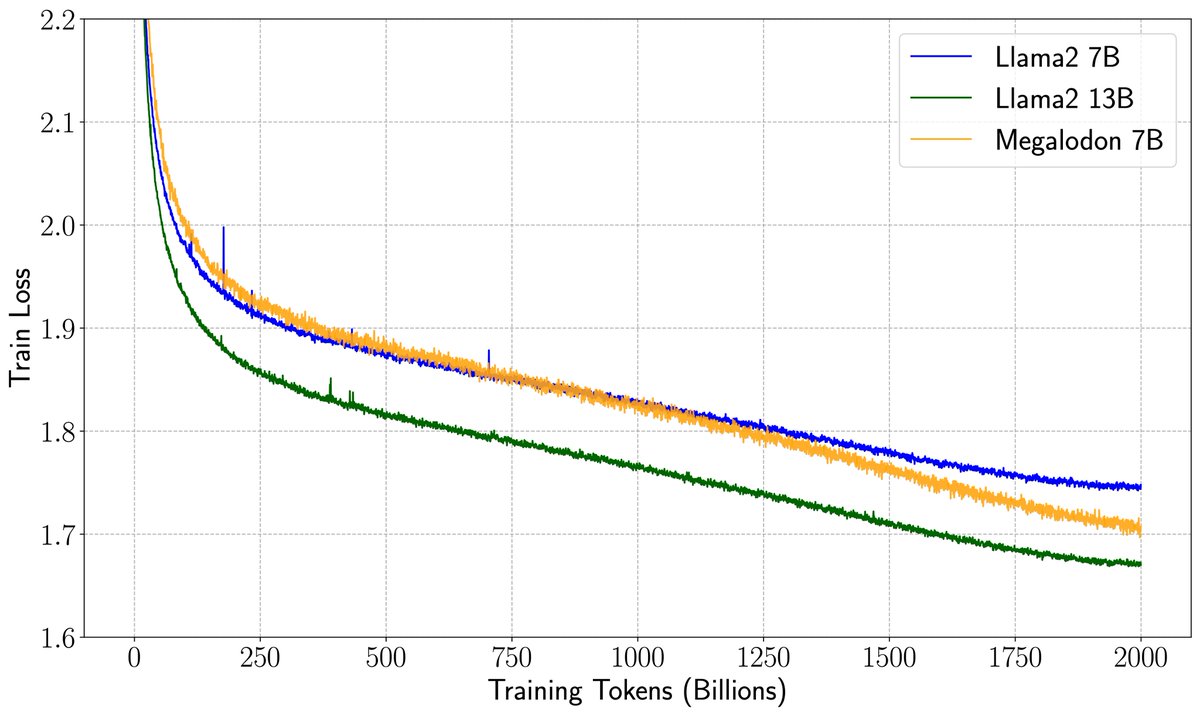
0
8
31
This is the first project launch we did at my lab at UCSD (. Feeling super proud of my student @Junda_Chen_ for the hard work and thanks to @Lanxiang_Hu for helping us build this lab website 😁😆.
Check out our latest blogpost discussing a better metric -- goodput (throughput s.t. latency constraints) -- for LLM serving, and our new technique prefill-decoding disaggregation that optimizes goodput and achieves lower cost-per-query and high service quality at the same time!.
0
1
31
Sad to miss ICML next week but my lab has 6 papers to present at ICML -- do check them out and talk to our wonderful authors!!.
We are excited to announce our lab's papers at #ICML2024! 🧠✨.Come and discuss our latest research from LLM evaluation to efficient LLM serving & inference! See you there!. 1️⃣ Poster: MuxServe: Flexible Spatial-Temporal Multiplexing for Multiple LLM Serving.📍 Location & Time:.
2
5
31
ICML is a lot of fun! First in-person conference since the pandemic! Gave a big model tutorial yesterday with @lm_zheng @zhuohan123 and Ion. Met a lot friends! Check out the tutorial website: and a lot useful information there!




0
4
28
Super excited about this new work (to appear at #ICLR2023) that offers a new perspective for private transformer inference! Also, the first work that I supervised as an advisor 😁!.

(1/5).Love using Copilot but don’t want to send codes to the cloud?.Our framework enables private inference with Secure Multiparty Computation (MPC) for Transformers (Copilot, ChatGPT, OPT, etc) #ICLR2023 (spotlight).Paper: Code:

1
3
27
And credits to @infwinston, @lm_zheng, and members at @lmsysorg who tirelessly update models and tweets, and moderate arena for the entire community!.

Really interesting talk -- good for people to remember that even ChatBotArena almost died in the summer of 2023 because it took them that long to get traction/support. Huge congrats @haozhangml and team.

1
3
26
Happy 1 year birthday🎂 to Vicuna. The past 12 months have been super fun building @lmsysorg with amazing students and faculty here
One year ago was Vicuna's birthday🎂!. We were so excited and built a demo for it at chat .lmsys .org. We never imagined it could get this far. Millions of people downloaded our models, visited our demo, and played with our fine-tuning recipe in FastChat project. We then.
0
0
26
It is super fun working with @vivek7ue and the Snowflake AI Research team on shipping the Snowflake Arctic model. Try this model which went live today if you haven't. One thing I found super exciting is that we discovered so many new challenges and open problems when you shift.

A lot of the insider knowledge on how to build an LLM has gone underground in the last 24 months. We are going to build #SnowflakeArctic in the open . Model arch ablations, training and inference system performance, dataset and data composition ablations, post-training fun, big.
0
3
26
(perhaps) the most important topic in LLMs -- the data recipe!.

We’re excited to share insights and lessons learned collecting the data needed for Arctic as part of our #SnowflakeArctic Cookbook Series. 📖. Our third edition covers the filtering, processing, and composition techniques we used, including what worked and what didn't.
0
1
25
We #lmsys are pushing the limit to democratize LLMs. Check out our official release of the Vicuna-7B weights. What's more exciting -- we add Apple silicon support! Now you can run it on your M1/M2 Macbook, with or without 8-bit, depending on your memory setup!.
We’re releasing Vicuna-7B: small, efficient, yet capable. 💻 MacBook users can simply "pip install fschat" and run Vicuna-7B with GPU acceleration on M1 chips!. code: weights:
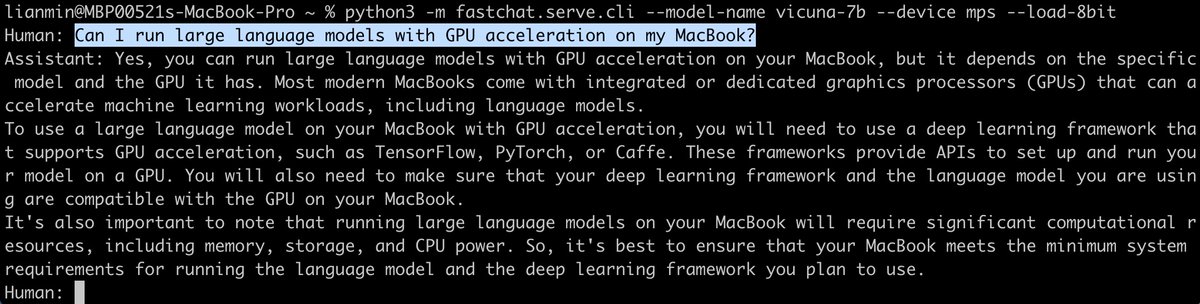
0
3
25
@srush_nlp vllm’s key secret sauce is about paged kv cache storage and prefix sharing (and more complex sharing in beam search). Give the paper a read: please!.
1
0
24
MPT-30B on Leaderboard now, check the leaderboard and give a vote in the Arena!. Within just 6 hours of releasing MPT-30B, it has already made its way onto the Arena and leaderboard. Kudos to the amazing team behind it: @infwinston, @ying11231, and @lm_zheng! 🎉.
Update: a strong model MPT-30B-Chat by @MosaicML has just landed Arena🤖!. And yes. We’ve also evaluated it with MT-bench and updated our leaderboard in the blog! See screenshots. Arena:.MT-bench demo with model answers/judgments.



1
2
22
whoo, UCSD is doing great!!.
And big changes in the ranking of various AI labs in the Zeta Alpha top-100 most cited papers. Microsoft made Google dance, also in the most cited AI papers of 2023. Big moves up in the ranking for AI Research at @CarnegieMellon @MIT @hkust and @UCSanDiego

0
1
22
Check out vLLM -- redefining the new state-of-the-art in LLM serving: 24x and 3.5x more throughput than HF transformers and TGI, respectively. Secret sauce behind @lmsysorg: vLLM + FastChat = making Chatbot/LLM serving accessible to everyone!.

1
0
20
@Stone_Tao @lmsysorg see the blogpost -- we also performed a winrate analysis here: But using ELO is because it is scalable -- in future when new model joins we can easily compare their capabilities via ELO ratings.
1
0
21
Speculative decoding is really interesting problem; the community has published many papers in a short amount of time, but very few of them have really discussed how it can be made really useful in a real serving system (they mostly assume batch size = 1). This is a nice step.

This is the first time we formally introduce speculative decoding in vllm. Actually this feature has been there for a long time since @cdnamz built the general framework months ago. It’s such a long way and a big community effort to make it really work.
0
1
20
I'll talk about DistServe ( at PyTorch webinar this Wed. Looking forward😃. Thank @PyTorch and @AIatMeta for the support!.

Join us for our next #PyTorch Expert Exchange Webinar on Wednesday, October 16th at 4 PM PT ➡️ Distsserve: disaggregating prefill and decoding for goodput-optimized LLM inference with @haozhangml Asst. Prof. at @HDSIUCSD & @ucsd_cse Tune in at:

0
0
20
Yes, we are partnering with Kaggle to push open evaluation of LLMs! . Our chatbot arena platform ( has some substantial improvement (both on UI and backend). Cast your vote and contribute to open LLM development!.
We're super excited to partner with @kaggle, welcoming the ML and data science community to Arena!. Yesterday's Kaggle launch, we recorded the highest traffic to date since the Arena launch! Over 4K votes in a day🗳️. Our mission remains building an open and community-first

0
0
20
Congrats to the team -- vllm sees a significant performance boost!.

A month ago, we announced our performance roadmap. Today, we are happy to share that the latest release achieves 🚀2.7x higher throughput and is 5x faster for output latency on Llama 8B, and 1.8x higher throughput and 2x faster on Llama 70B for H100s.
0
0
20
We were among the first to eval Vicuna&other open models using GPT-4 -- previously it was for fun (despite it was later adopted by many others) -- but now we had a rigorous study of this method after running Chatbot Arena for 1 month! GPT-4 eval is actually *creditable* when.
Since Vicuna's debut of GPT-4 as a judge, interest has sparked in using powerful LLMs to evaluate chatbots. But can we trust LLM judges?. Our latest study delves into this question using a multi-turn benchmark, MT-bench, and data from Chatbot Arena.
0
0
20
It seems we got two grants from A16z in 6 months 😆 (@lmsysorg and vllm).

We're announcing the second batch of @a16z open source AI grants today. This cohort focuses on:.▶️ tools for LLM training/ hosting/ evals.▶️ visual AI models & communities. Thank you to the grantees for your contributions! More info in the linked post
0
0
16
truly a community!.
vLLM is also expensive to maintain! We want everyone to be able to submit PRs that's fully tested so the software can be trusted in production. We thank the many wonderful organizations sponsoring us compute for the development and testing.

1
0
18
Hey! Check this out. Come and play vicuna we built recently. We also come up with an interesting way to evaluate chatbots using GPT-4, and GPT-4 says vicuna is very close to chatgpt quality!.
Introducing Vicuna, an open-source chatbot impressing GPT-4!. 🚀 Vicuna reaches 90%* quality of ChatGPT/Bard while significantly outperforming other baselines, according to GPT-4's assessment. Blog: Demo:
1
3
17
Vicuna-v1.5 (built on top of Llama) series were just released! Improved MT-Bench and MMLU, longer context length, more permissive license!.
Excited to release our latest Vicuna v1.5 series, featuring 4K and 16K context lengths with improved performance on almost all benchmarks!.Vicuna v1.5 is based on the commercial-friendly Llama 2 and has extended context length via positional interpolation. Since its release,


1
0
17
Latest work by our Alpa team on massively serving large models like #gpt3 #chatgpt; The idea is super simple yet the results are surprising! Check this out!.
Unlock the full potential of model parallelism with AlpaServe 🚀: Besides scaling models beyond one GPU, our new paper shows that model parallelism can process NN serving requests 10x faster even if the models fit into 1 GPU! . Paper: 👇 [1/8]

0
0
16
The really interesting part I found when doing this project is that -- with just a little amount of good data, it is actually so easy and so inexpensive to tune a chatbot that answers quite well to users. Tuning Vicuna only costs ~$300. LLMs will be very accessible!.
Through careful prompt engineering, GPT-4 is able to accurately evaluate the response quality in most cases, as shown in the example below. More examples: Code:

0
1
16
I actually have switched to use vicuna (previous was ChatGPT) for writing assistance everyday as I hosted it myself😁.

Blog post: playing with Vicuna-13B, ChatGPT (3.5), MPT-7B-Chat on harder stuff TL;DR: We think ChatGPT is still way ahead, but sometimes the extra control from open source models is worth it.
2
1
15

In December, @SnowflakeDB AI Research announced SwiftKV, a new approach that reduces inference computation during prompt processing. Today they're making SwiftKV-optimized Llama models available on Cortex AI that reduce inference costs by up to 75%!.
1
3
15
Our ICML'22 tutorial recording is now publicly available (no registration needed): Interested in knowing how large models like GPT-3 are trained and served? This tutorial has plenty of info! Check out for more!.
0
3
14
@StasBekman Check this: We have done quite a lot of math and theory back in 21-22 to understand and navigate the model parallelism space.
0
1
15
Glad that vLLM is recognized!.
Deeply honored to be the first cohort of the program and a big shout-out to @a16z for setting up the grant and recognizing vLLM! Let's go, open source!.
0
0
15
How long do open LLMs truly promise on context length? We design some simple tests and try to reveal some false promises!.
🔥Introducing LongChat🤖, our new chatbots supporting 16K tokens context, and LongEval, our new benchmark for testing long context chatbots. 🤥Surprisingly, we found open LLMs often fail to achieve their promised context length. Check our blog for details:

0
0
15
And the same for UCSD MLSys😁.

In the spirit of asking Cornell NLP is also happy to receive some GPUs. Get in touch! 😁.
0
1
15
Nice work by the LLM inference team at @anyscalecompute !.

One of @vllm_project's strengths is that it exposes the ability to trade off latency and throughput. However, higher qps regimes cause significant latency degradation. The underlying reason has to do with inference taking place in two stages: prefilling (processing the input


0
2
15
Very very valuable release by my colleagues at Petuum/MBZUAI/CMU. The first ever fully open sourced LLM pretraining trajectory. I plan to read every detail of this paper: .

🚀 1/7 We are thrilled to launch LLM360 — pushing the frontier of open-source & transparent LLMs!. Starting with Amber (7B) & CrystalCoder (7B), we are releasing brand new pre-trained LLMs with all training code, data, and up to 360 model checkpoints. 🔗
2
2
15
We just released a new series of Vicuna v1.3 models -- including the latest, eagerly awaited Vicuna-33B!. We also significantly updated the Chatbot Arena leaderboard -- more models entering the Arena, more comprehensive metrics: Elo, MT-bench scores, and MMLU.
🔥Big news from Chatbot Arena: Meet our new MT-Bench leaderboard & Vicuna-33B!.We present a comprehensive, scalable, and validated leaderboard differentiating across open (Falcon, Wizard & Guanaco) and proprietary models (GPT-4, Claude & PaLM). Blog post:.

0
2
14
Incredible beginning of the year!.
🌟 Exciting News! 🌟. We’re thrilled to share the news that 3 papers from our lab members and collaborators have been accepted to #ICLR2025! 🎉. We are grateful for all fruitful discussions and constructive feedback from the reviewers, ACs, and PCs that have made our work better.

3
0
15
@generatorman_ai @lmsysorg @OpenAI @AnthropicAI the team is working hard to add them and contributions are welcome!.
2
0
13
We just added categories in chatbot arena. Now you can see how these models compare to each other under code/different languages/context length!.
We tag all the conversations containing code snippets in Coding Arena. In this domain, we find GPT-4-Turbo performs even stronger. This aligns with the recent finding in challenging coding benchmark such as LiveCodeBench by You can also easily view

1
3
14
Thank everyone for casting votes at Chatbot Arena. Besides the leaderboard, we're releasing the conversations and votes we collected so far to the community to foster more open research down the road!. Check blog post for the dataset details:
We are excited to announce the first major release of the Chatbot Arena conversation dataset!. - 33K conversations with pairwise human preferences.- 20 SOTA models such as GPT-4, Claude, and LLaMA-based Vicuna.- From 13K unique IPs in the wild.- An additional 3K expert-level


0
0
14
@srush_nlp the sharing feature we have now is that when you sample multiple candidates from a prompt, vLLM will share as many kv caches as possible at generation, such as the KV cache of the prompt itself and overlapped beam branches. If you specify your sampling method as parallel sampling.
6
0
13
@arankomatsuzaki Interesting paper with an obvious conclusion that surprises no one. IMO the only and most important things here are which capability of the LLMs you care most and how you evaluate them.
0
0
14
Actually many of the Vicuna developers #lmsys are hardcore distributed system folks and we'll have more efficient stuff coming out soon! 😍😍.
We encourage users to use our default library, FastChat, for using Vicuna. - It correctly handles prompt templates for the best model quality. - Supports CPU/GPU/Mac. - Nice CLI and GUI with streaming and syntax highlighting.- More updates coming soon. [3/3].
1
2
14
@chrisatgradient Do you mind submitting a PR to vLLM or open an issue? We can fix it in vLLM.
1
0
13
Yep I'll be at ICML next week with many other team members -- looking forward to catching up!.
Our members @ying11231 @lm_zheng @infwinston @haozhangml will attend ICML 🏝️ next week. DM us if you want to chat!.
0
0
14
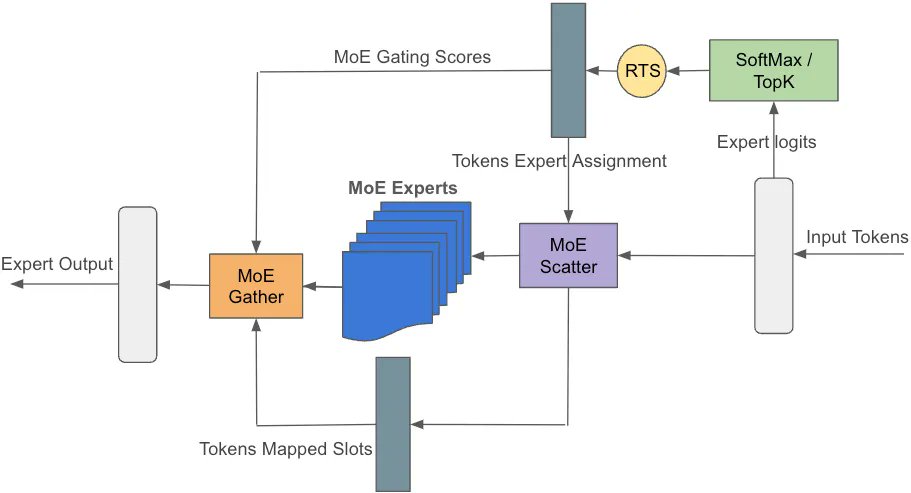
Our Reza is sharing how to optimize big MoE kernels !.

1/4 Have you wondered how to optimize sys-perf for training Arctic-like models (MoE arch)? Let’s dive in! Our first technique: custom fused kernels. By crafting these kernels, we streamline irregular and sparse operators, boosting efficiency. #SnowflakeArctic #SystemOptimization
0
0
12
@lmsysorg @OpenAI @AnthropicAI @JeffDean @DynamicWebPaige Possible to grant us a PaLM2 API for a test?.
0
0
12
@DrYangSong Yeah, Yang's previous work ( is super inspiring, and we discussed a lot before designing lookahead decoding .
0
1
13
Our department at UCSD is looking for new faculty members. Check out the job postings below ⬇️⬇️.

Multiple faculty positions are open at @HDSIUCSD at all levels of seniority. * Broad Area Search: All areas of AI, Machine Learning.* Statistical Foundations of Data Science.* Data Science and Bioengineering.* Data Sciences and Public Policy.* Teaching Faculty in all areas of

1
1
12
Glad to see both projects we have been doing since last year get recognitions. More to come ✊🤟.
Thank you @sequoia for supporting the open source community! We believe openness is the way for the future infrastructure of AI, and humbled by our amazing users, contributors, and supporters! ❤️.
0
0
12

Longchat-7b gets an upgrade! 32K context length with Llama-2 as the new base!.
Along with Vicuna-v1.5, we also released LongChat-v1.5, based on Llama-2 and 32k context length. You can try it in FastChat or evaluate it in the LongChat repo .
0
0
12
I know recently there are two classes of LLM devs: GPU-rich are racing to AGI while GPU-poor is dethroning another GPU-poor on yet another benchmark. As GPU-poor, I hope this isn't something considered "counter-productive use of our skills and time" 🤣🤣.
We’ve just added two powerful chat and coding models, Llama-chat-70b and CodeLlama-34b-instruct, to Arena!. Challenge them with your toughest prompts and watch them climb the leaderboard. We’ll soon update ranking once we get enough votes🗳️. Link:
0
0
12


I will be at this event in person tonight -- happy to chat about anything about AI/LLMs! 🙂.
The last in-person vLLM meetup of the year is happening in two weeks, on November 13, at @SnowflakeDB HQ! Join the vLLM developers and engineers from Snowflake AI Research to chat about the latest LLM inference optimizations and your 2025 vLLM wishlist!.
0
0
12
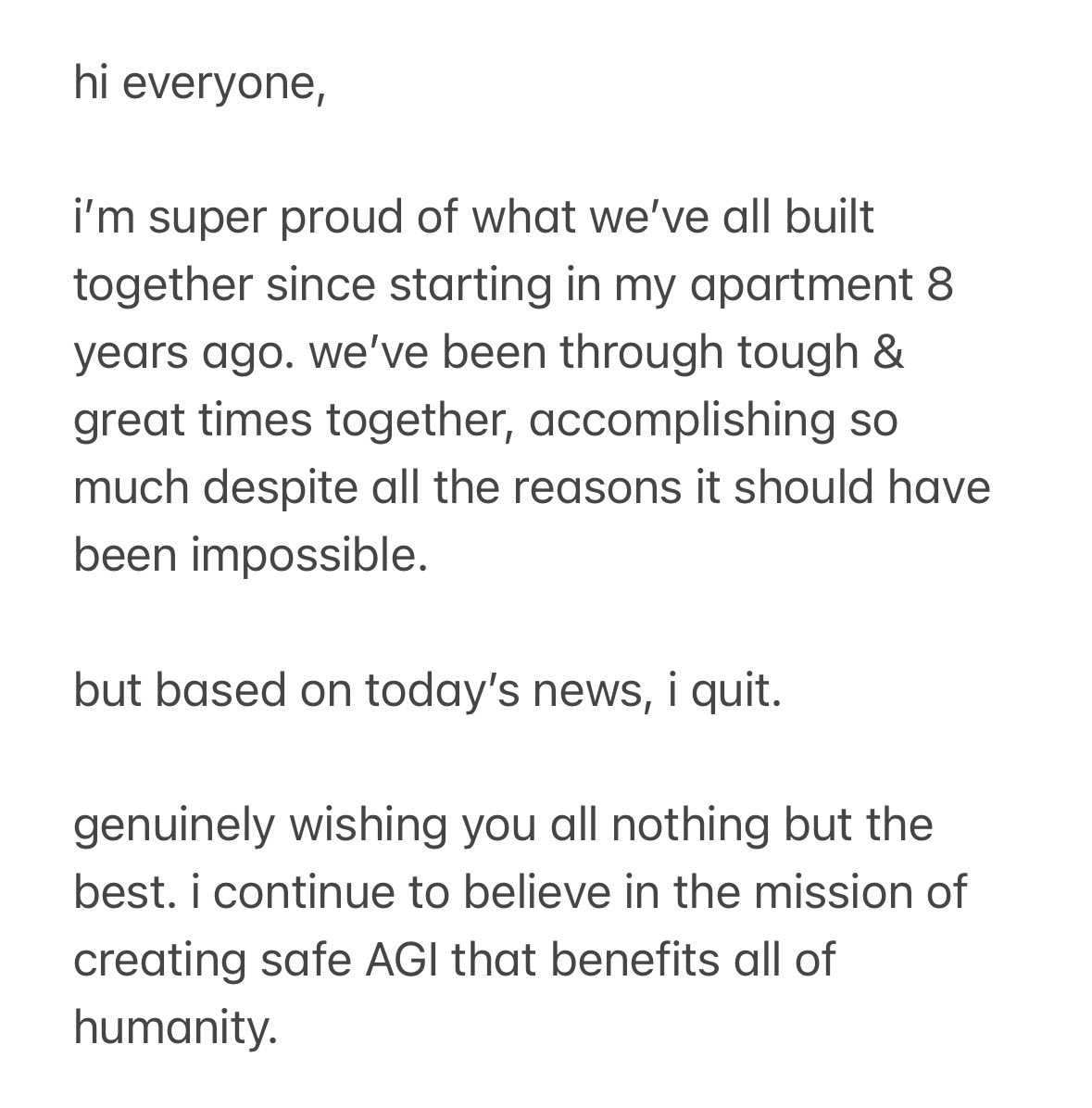
New information might change my perspective but my strong respects to @sama and @gdb for leading our current AI industry and shipping one of the greatest product chatgpt. Looking forward to seeing your next venture and hope to see another model produced by you championing our.

After learning today’s news, this is the message I sent to the OpenAI team:
1
0
11
@soumithchintala @HeinrichKuttler @xai @ibab I guess (with all good intentions as well) maybe @elonmusk hands out a nanny starter pack in addition to a lot of stock options.😄.
0
0
11
Great work that will even greatly amplifies the power of disaggregated LLM serving.

🚀Making cross-engine LLM serving programmable. Introducing LLM Microserving: a new RISC-style approach to design LLM serving API at sub-request level. Scale LLM serving with programmable cross-engine serving patterns, all in a few lines of Python.

1
4
11

I am honored to share that our recent paper won the Outstanding Paper Award in NSDI’24!. The paper explores the policy design of our SkyPilot managed spot for @skypilot_org:.Can’t Be Late: Optimizing Spot Instance Savings under Deadlines. It would not be possible, if it were not

0
0
11
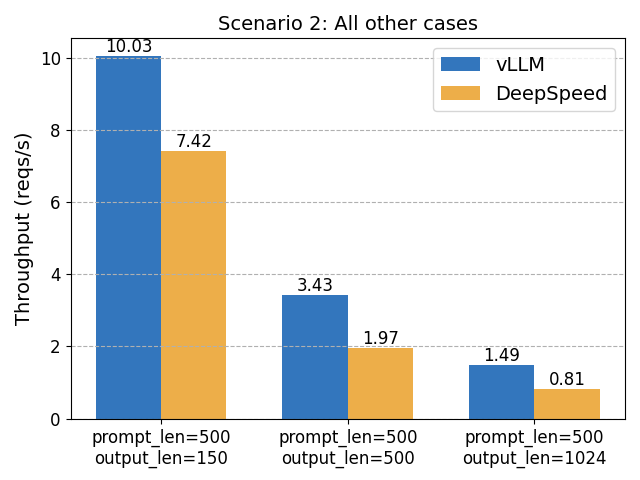
check out latest benchmark about vLLM vs. DeepSpeed.

We’ve just released a new blog post comparing vLLM with DeepSpeed-FastGen. While we are happy to see the open-source technology advancements from the DeepSpeed team, we’ve got different results with more extensive performance benchmarks. vLLM is actually faster than DeepSpeed in
0
0
10
Check this important update on the chatbot arena leaderboard we just posted!.
[Arena Update]. 70K+ new Arena votes🗳️ are in!. Claude-3 Haiku has impressed all, even reaching GPT-4 level by our user preference! Its speed, capabilities & context length are unmatched now in the market🔥. Congrats @AnthropicAI on the incredible Claude-3 launch!. More exciting
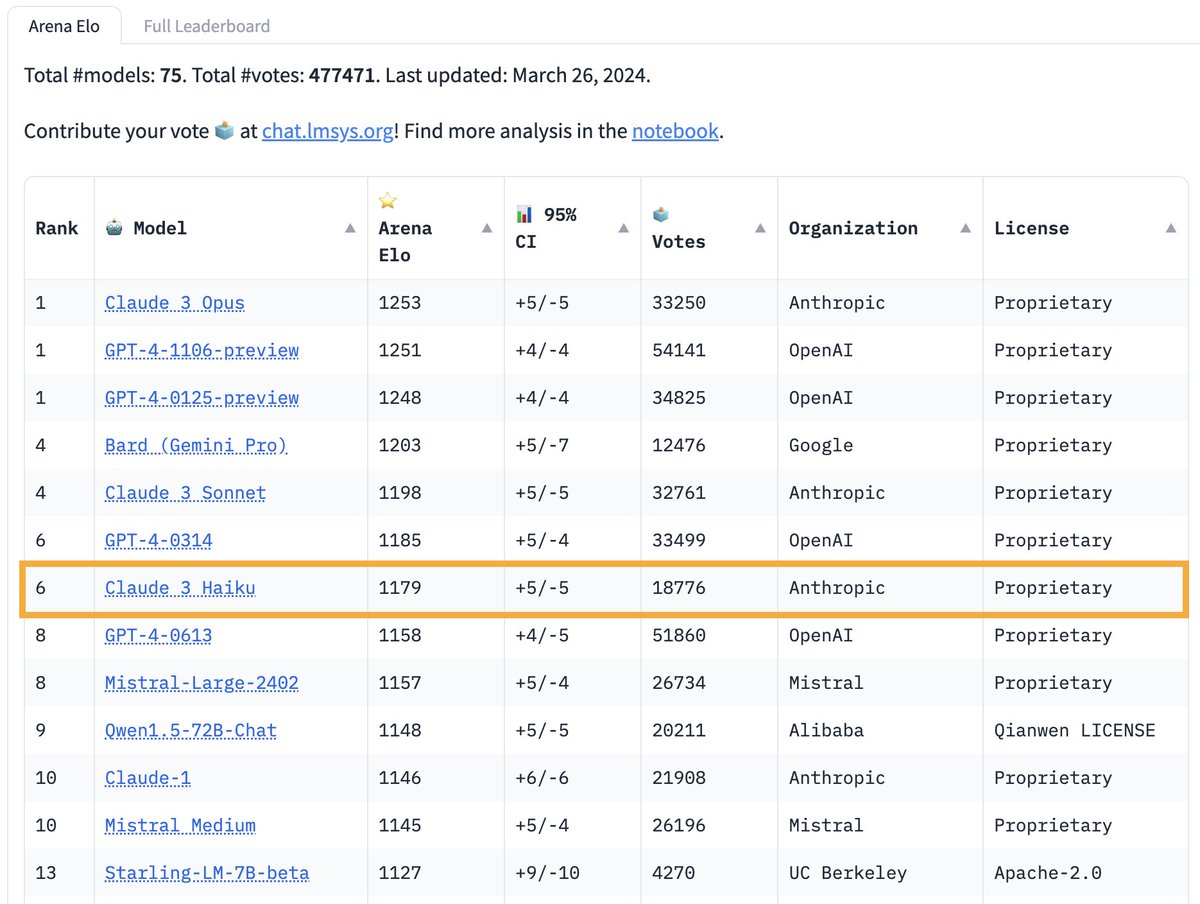
0
0
10
Come and play Databricks Dolly 2.0; compare open-source chatbots yourself! 😁.
0
1
10
@Marc__Watkins @pmddomingos For now due to high traffic (as a free web demo) we restrict the max_seq_len to 512 and hardcode some generation params. But you can refer to our tutorial on how to tune a good set of generation params for your prompt; but indeed it is opt-175b!.
0
0
9
Join the action NOW at 💪🏼💻.
We are hosting an exciting battle between open LLMs at and need your help!. The goal is to collect 10k anonymous battle results and release a leaderboard. # progress.▓▓░░░░░░░░ 17.21%

0
0
8
It was great to talk to Emily @electric_humans and thanks for describing our LLM evaluation effort in Chatbot Arena to PCMag audiences!.

You may have put the same prompt into ChatGPT, Bard, Claude, or another chatbot to see which one you like best. But what happens when 40K people do that? Check out the winner in this live UC Berkeley competition. @haozhangml @lmsysorg.#OpenAI #GPT4 #GPT3 .
1
0
9
Check out this awesome work by (it is maitrix, not matrix!😄).

Releasing 🔥LLM Reasoners v1.0🔥. 🥇Popular library for advanced LLM reasoning. - Reasoning-via-Planning (RAP)🎶. - Chain-of-Thoughts (CoT)⛓️. - Tree-of-Thoughts (ToT)🌴. - Grace decoding💄. - Beam search🔎. 🥇Enhances #Llama3, GPT4, LLMs on @huggingface.

0
1
9
Congrats @_parasj @ajayj_ . This is huge to the community and my students are all excited about what the model can enable!!!.

Introducing Mochi 1 preview. A new SOTA in open-source video generation. Apache 2.0. magnet:?xt=urn:btih:441da1af7a16bcaa4f556964f8028d7113d21cbb&dn=weights&tr=udp://tracker.opentrackr.org:1337/announce
0
2
9
@yen_chen_lin This is a super nice post!! It'd be good to mention our FastVideo project () in the library section which first provides a comprehensive, highly scalable consistency distillation recipe 🫡.
1
0
9