

Ajay Jain
@ajayj_
Followers
6,104
Following
2,914
Media
67
Statuses
542
Co-founder @genmoai . Co-created denoising diffusion (DDPM), DreamFusion, Dream Fields. Ex Ph.D. @berkeley_ai , @googleai , @facebookai , @nvidiaai , @mit
San Francisco, CA
Joined July 2009
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
梅雨明け
• 208034 Tweets
Raila
• 160348 Tweets
#BKPPยอม_MV
• 55845 Tweets
パワプロ
• 47647 Tweets
NORAWIT X BV IN EMPORIUM
• 29837 Tweets
Harmony
• 24815 Tweets
暇空敗訴
• 24622 Tweets
PAPA DALI
• 20099 Tweets
Kamari
• 20011 Tweets
Overdose
• 19926 Tweets
WazirX
• 16967 Tweets
SEMANGATbaru EKONOMItumbuh
• 15856 Tweets
JIMMYSEA CHOC x AIS
• 15531 Tweets
डिब्रूगढ़ एक्सप्रेस
• 14581 Tweets
रेल मंत्री
• 13175 Tweets
スキズ再契約
• 12212 Tweets
Mehmet Büyükekşi
• 10976 Tweets
#プレバト
• 10939 Tweets




















Pinned Tweet

Meet Replay. We've been hard at work on something exciting. Check out the video and share your creations made with
@genmoai
!

Generative video models are rapidly improving in quality. Meet Replay, a new AI model that can generate stunning videos from text.
Replay v0.1 is designed to create ultrasmooth HD videos with a new interface. Available today for everyone.
What's New?
1. Replay understands plain
50
90
462
13
8
82
Text-to-3D synthesis with
#dreamfusion
: I typed in "A high-quality photo of a pineapple" and got this lovely 3D fruit!
15
62
518
This is a
#dreamfusion
generated from the caption "a DSLR photo of a ghost eating a hamburger." 👻🤯 Do you think DreamFusion is a good cook?
12
38
376
Who's interested in text to vector graphics? Cooking something up, SVGs importable into Figma, Illustrator, Affinity Designer etc.

11
18
285
Paper accepted to
@CVPR
2022! Happy to have worked with amazing collaborators
@BenMildenhall
@jon_barron
@pabbeel
@poolio
on Dream Fields, which synthesizes 3D objects from language descriptions.

11
46
262
Check out our new paper - we put NeRF on a diet! Given just 1 to 8 images, DietNeRF renders consistent novel views of an object using prior knowledge from large visual encoders like CLIP ViT.
w/ Matthew Tancik,
@pabbeel
1/

3
43
255

Check out
#DreamFusion
: our paper on AI-based text-to-3D generation! Just take a look at these synthetic robots 🤖🤖🤖
This draws on years of work from our fabulous team on diffusion models and neural rendering, and I'm so excited for what comes next.

Happy to announce DreamFusion, our new method for Text-to-3D!
We optimize a NeRF from scratch using a pretrained text-to-image diffusion model. No 3D data needed!
Joint work w/ the incredible team of
@BenMildenhall
@ajayj_
@jon_barron
#dreamfusion
136
1K
6K
12
30
229
PixelCNNs generate images pixel-by-pixel in a fixed order. Can we choose the order? Yes! We propose Locally Masked Convolution: a simple, efficient operation for arbitrary order training+testing & more accurate likelihoods.
Paper w
@pathak2206
@pabbeel
1/8

2
48
192
Wow! DreamFusion has been given the Outstanding Paper award at
#iclr2023
Huge congratulations to my co-authors
@poolio
@BenMildenhall
@jon_barron
, and thank you to the conference organizers and reviewers for the feedback and recognition!
Check out
#DreamFusion
: our paper on AI-based text-to-3D generation! Just take a look at these synthetic robots 🤖🤖🤖
This draws on years of work from our fabulous team on diffusion models and neural rendering, and I'm so excited for what comes next.
12
30
229
15
14
193
New work on autoregressive generative models! We improve the expressiveness of your favorite continuous autoreg models like Trajectory Transformer, WaveNet and Image GPT with Adaptive Categorical Discretization. See below for code. Paper at
#UAI2022

Check out our latest work on generative modeling with Adaptive Categorical Discretization (AdaCat)!
AdaCat generalizes uniform discretization and can improve existing autoregressive models on density estimation for tabular data, images, audio, and trajectories in RL. Thread: 1/N
5
40
228
2
26
181
I've heard several people say they're no longer surprised by new capabilities of generative models. Tough crowd! What would personally surprise or delight you?
44
5
140
I'll be giving my dissertation talk today at 3-4 PM Pacific Time on Transferable Generative Models. Send me a DM if you'd be interested in joining the Zoom.
13
4
120
Very cool!
@pess_r
ported our Denoising Diffusion models from TensorFlow to PyTorch and made an awesome web demo cc
@hojonathanho
@pabbeel

Denoising Diffusion Probabilistic Models converted to PyTorch with Streamlit Demo
Run demo:
pip install -e git+
pytorch_diffusion_demo
1
19
70
2
28
107
Modern generative models feel like powerful alien technologies that crash landed on Earth. Yet, they’re based on surprisingly simple concepts. I’m glad to have contributed to the popularization of diffusion models with our 2020 DDPM paper, and am so excited for progress to come.

Generative models (such as Dall-E 2 and PaLM) are becoming just such an insanely powerful, almost magic-like technology, it's completely NUTS. And it seems like most (non-ML) people still don't fully grasp the implications. This technology will thoroughly transform society.
80
335
3K
1
4
99
Having a blast in New Orleans! Crazy to think that we presented DDPM as a virtual poster just 3 years ago at NeurIPS 2020. In person food is much better 😋 Check out these beignets I made in a few minutes on Genmo.
Come find / DM me to chat about big diffusion models for video.
1
7
87
Meet
@GenmoAI
. We help you create media in the formats you need to tell your stories. Try Genmo today with hilarious and immersive text-to-video generation 🎬
Announcing Genmo Video, a generative media platform with a new text-to-video model that can generate immersive live artwork from any prompt or any image.
What will you create? 🎨▶️
Free public access:
Discord:
👇1/n
15
63
251
3
14
71
Vector graphics can be generated from natural language. Caption: "a painting of an evergreen tree"

1
6
68
Controllability is a major problem for generative models, so it's hard to find the exact result that you're looking for in the latent space. Today, we announced Replay Camera Controls to allow creators to take the reins on generative video.
Camera movement drives emotion, pace, and mood in filmmaking.
Announcing Replay Camera Controls. Starting today, zoom, pan, roll and tilt the virtual camera to render gorgeous, swooping effects. 💫
Yesterday, you met Replay, our new, ultra-crisp video model. Now, take even more
4
18
141
1
9
58
PyTorch aficionados: what is your process for locating the cause of NaNs, especially that only seem to occur in the backward pass? detect_anomaly tells me MulBackward0 returns nans, but the torchviz graph contains 38 ops with that name 😅
8
5
55
DreamFusion hit Two Minute Papers 🎉

1
1
52
Text to 3D with Dream Fields! Come find
@BenMildenhall
@jon_barron
and myself at poster spot 86a at
#CVPR2022
today from 10 am-12:30 pm CDT. Paper and code: .

Paper accepted to
@CVPR
2022! Happy to have worked with amazing collaborators
@BenMildenhall
@jon_barron
@pabbeel
@poolio
on Dream Fields, which synthesizes 3D objects from language descriptions.
11
46
262
3
6
49
"This is a hacky way to do it."
Thank you for the feedback, Github Copilot!

2
0
47
My mom looked at my screen just now and asked "Is this work?" Yes, and that's why I love what I do 😄
2
1
45

I found a neat command to generate the table of contents for my dissertation:
$ conda env list
0
1
39
Found this old text-to-3D result on my laptop from mid-2021. Caption: "a 3D render of a stack of Jenga blocks". We've come pretty far!
2
3
37
I'll be at NeurIPS in New Orleans this week, Tuesday night onward. Looking forward to catching up with old friends and meeting new folks! Let me know if you'd like to chat
1
0
35
Heading to New Orleans to present Dream Fields at CVPR 2022! Message me if you’ll be around :)
0
2
33
I’ll be at NeurIPS this year in New Orleans. Excited to cheer on my collaborators
@AleEscontrela
@AdemiAdeniji
during the Wednesday morning poster session. In VIPER, we use video generative models to train reinforcement learning agents. Come find us at poster 1412 or DM to meet.

Today we're releasing Video Prediction Rewards (VIPER 🐍), a simple yet powerful method for extracting rewards from video prediction models!
VIPER learns reward functions from raw videos, and generalizes to entirely new domains for which no training data is available
🧵 thread
6
70
421
0
0
33
We’ll be presenting DietNeRF at
#ICCV2021
tomorrow at 9 AM EDT! Come chat or watch our talk offline at . Our code is also now available at 🥳
1
6
33
55th submission to 🤓 Happy to see how much this community has grown!
0
0
31
Fun application: Our Locally Masked PixelCNN can generate images along a Hilbert space-filling curve. The Hilbert ordering is resolution agnostic and ensures that consecutively generated pixels are nearby! Video of unconditional generation along Hilbert curve: 2/8
1
4
31
Our V2 text-to-image generator is out. V2 tends to produce much more coherent and attractive images out of the box. Try it:
🖼️ Hot off the presses: V2 image generation! We've been hard at work on Genmo's new text-to-image model. It generates gorgeous 1024x1024 pictures, with improved coherence and style.
Check out our community's results at . Who wants access?

1
4
18
0
1
30
Cats munching on some snacks. Made with Genmo Replay text-to-video v0.1
Generative video models are rapidly improving in quality. Meet Replay, a new AI model that can generate stunning videos from text.
Replay v0.1 is designed to create ultrasmooth HD videos with a new interface. Available today for everyone.
What's New?
1. Replay understands plain
50
90
462
2
3
29
Harry Potter and his owl, through the years. Created in seconds with :
Sign up today to save your place on the waitlist :)
0
3
24
Last week, I presented Locally Masked Convolution for Autoregressive Models at
#UAI2020
. It was a great conference with insightful conversations! You can read our paper at , or see the talk at . Joint work with
@pabbeel
@pathak2206

1
5
24
We build some crazy infrastructure at Genmo to improve user experience. Today, we released streaming previews. Right after submitting a video to our GPU cluster, Genmo sends users renders of their AI videos. It's super fun to play with. Try queuing up to 4 videos at a time and
Replay now streams AI-generated videos for fast iteration. Your clips will start rendering and streaming almost as soon as you click "submit".
Genmo's infrastructure ships pixels straight off the GPU to your computer screen 📦
5
7
25
0
0
21
would love to chat about the most useful applications of tech like this, especially from 3D artists and game/VR devs!
8
0
21
Thanks
@shaneguML
! My Twitter profile photo was generated with Score Distillation Sampling. We can also sample images by optimizing 2D Fourier Feature Net weights, and tried some early experiments using Mitsuba 3 as the differentiable renderer.

Besides incredible results, a great contribution of this work is to showcase the potentials of Score Distillation Sampling (SDS): "SDS allows us to optimize samples in an arbitrary parameter space"
"Text-image diffusion as a prior + X" has so many applications to come!
0
5
84
1
4
20

Great work! Few/single image conditioned NVS is fundamentally a generation problem, and multiview priors are an important research direction.

Excited to announce our work on novel view synthesis with diffusion models! Our model can lift a single 2d image into 3d.
Joint work w/
@wchan212
@rmbrualla
@hojonathanho
@taiyasaki
@mo_norouzi
66
938
4K
0
2
17
Fast multicloud data transfer is going to be important for synthesis and representation learning: need to move TB of data quickly and cheaply to the accelerators. Looking forward to trying this and great work
@_parasj
!

Releasing Skyplane, a new open-source tool to move huge datasets between clouds.
Skyplane is:
1. 🔥 Blazing fast (110x faster)
2. 🤑 Cheap (4x cheaper)
3. 🌐 Universal (AWS, Azure and GCP)
Read more:
1/
8
57
256
0
1
17
Very exciting progress on high-resolution image generation through denoising diffusion probabilistic models, a collaboration with
@hojonathanho
@pabbeel

New paper on diffusion probabilistic models with
@ajayjain318
&
@pabbeel
:
Likelihood-based generative model with SOTA FID=3.17 on unconditional CIFAR10, and ProgressiveGAN-like quality on 256x256 LSUN & CelebA-HQ (sometimes generates dataset watermarks!)

6
136
450
1
2
17
@geoffreyhinton
@MasoudMaani
Google didn't invent diffusion models (but made plenty of progress on them)
1
0
15
Text to pixel art with denoising diffusion! Can you guess the captions used to generate these vector graphics?
#genmo

Who's interested in text to vector graphics? Cooking something up, SVGs importable into Figma, Illustrator, Affinity Designer etc.
11
18
285
1
1
15
Text to image to NeRF to mesh to image to image 🤯

Text-to-3D-to-Image)! I ran the output of DreamFusion through
#stablediffusion
#img2img
. This workflow would be amazing for generating artwork with precise control over the subject.
#dreamfusion
15
140
871
0
0
16
Replay FX gives generative AI videos very cool kaleidoscopic effects🛟🌸
We introduced a library of six customizable effects on our website. FX come with controllable sliders to adjust their strength and playback speed
Introducing Replay FX: a new way to bend AI videos with intricate effects.
Your dreams are in your control. Now available.
17
50
273
0
0
14
Check out our paper
@NeurIPSConf
2020: Sparse Graphical Memory for Robust Planning. Allows an RL agent to build, abstract and plan over a memory of previous observations, really helping with robustness of long-horizon navigation.

New paper coming up at
@NeurIPSConf
- Sparse Graphical Memory for Robust Planning uses state abstractions to improve long-horizon navigation tasks from pixels!
Paper:
Site:
Co-led by
@emmons_scott
,
@ajayj_
, and myself.
[1/N]
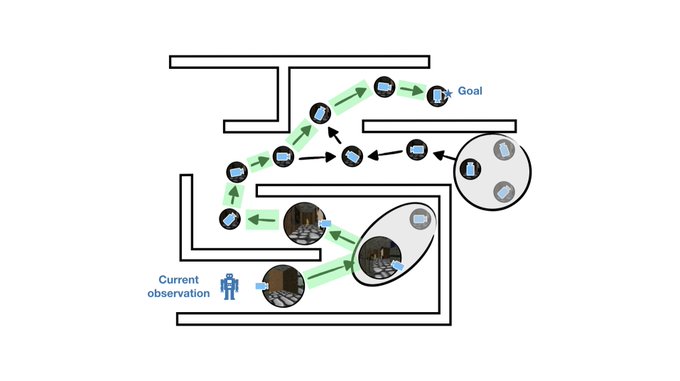
1
16
108
1
0
13
Wonderful work all! The generative modeling space continues to be very exciting. These architectural and sampling insights should be useful for other models - especially looking forward to testing dynamic thresholding and the efficient U-Net soon.


1
1
14
Where are the good NeurIPS parties this year? Please send invites 😅
0
0
13
Diffusion is the new ML benchmark 🏃

We just released AITemplate -- a high-performance Inference Engine -- similar to TensorRT but open-source.
It is really fast!
On StableDiffusion, it is 2.5x faster than the XLA based version released last week.
19
116
725
0
0
13
Dr. Yoda gets married, and then gets back to work in his lab coat. Do. Or do not. There is no try. Made with


0
0
12
Great work
@Michaelvll1
@_parasj
and friends! A nice approach for combining local reasoning over a graph with global self-attention. The GNN may be learning a positional embedding based on local graph structure.

"Representing Long-Range Context for Graph
Neural Networks with Global Attention" by
@_parasj
@Michaelvll1
et al. at
#NeurIPS2021
Strong results on graph classification when combining GNN --> Transformers.
PDF:

3
43
193
0
0
12
Happy holidays!

Genmo text-to-video
Text prompts + camera motion
1) aerial view of a cosy cottage, snow fall, christmas
2) christmas tree in a cosy cottage
3) long hallway, cosy cottage, christmas decorations
4) top view, celebratory meal, dinner table, cosy cottage, christmas
5) Full moon,
3
24
145
0
0
12
This is a great application of DDPM by
@cnxhk
, and it's impressive that only 6 iterations are needed during sampling. Generative models should scale with data complexity rather than dimensionality!

0
2
11
New paper on contrastive learning for programming languages with
@_parasj
@tianjun_zhang
@pabbeel
@mejoeyg
Ion Stoica! ContraCode learns similar representations for equivalent but differently implemented JavaScript programs using compiler-based data augmentations
#ml4code
0
2
10
Chat with us tomorrow at
#NeurIPS2020
during the 9-11 AM PST poster session! You can check out the talk or teleport to our poster from . We're in Town A0, Spot B0.
New paper coming up at
@NeurIPSConf
- Sparse Graphical Memory for Robust Planning uses state abstractions to improve long-horizon navigation tasks from pixels!
Paper:
Site:
Co-led by
@emmons_scott
,
@ajayj_
, and myself.
[1/N]
1
16
108
1
0
10
Our LMConv layer is cheap to evaluate and easy to implement in pure PyTorch by masking the im2col matrix before matrix multiplication.
Code is open-source at 4/8

1
1
9
@junyanz89
@ndrewLiu
Cool! Wonderful to see more progress on few shot NeRF. You might enjoy DietNeRF, one of our works that approaches the overfitting problem with another auxiliary loss:
1
0
9
🤯

NÜWA: Visual Synthesis Pre-training for Neural visUal World creAtion
Achieves SotA results on text-to-image generation, text-to-video generation, video prediction, etc. Outperforms DALL-E in text2image.
abs:
repo:

9
87
469
0
0
9
Halloween treats came early. Nice!


1
2
19
0
0
8
It was a pleasure to catch up with
@profjoeyg
earlier this week on the Generating Conversation podcast. Joey was a fantastic mentor and collaborator at Berkeley. Check out the interview below.

Latest interview from
@profjoeyg
is out!
We chatted with
@ajayj_
, who's the co-founder of
@genmoai
.
The conversations touches on the history of diffusion models 🖼️, some awesome demos 🎥, and the tech behind Genmo 🤖. Check it out!
0
4
9
0
1
8
Come talk with
@hojonathanho
and I about DDPMs at
#NeurIPS2020
! We're in the poster session now, until 11 AM PST. A link is available at . Paper: .
Very exciting progress on high-resolution image generation through denoising diffusion probabilistic models, a collaboration with
@hojonathanho
@pabbeel
1
2
17
1
0
8
I had a wonderful time interning with
@RaquelUrtasun
in 2018, and highly recommend this opportunity to interested students

Research internships are now available
@Waabi_ai
. All year long, with duration of 3-12 months. Available in both Canada as well as US. Join the team at the forefront of innovation in
#SelfDrivingCars
!
Apply:
3
52
218
0
0
8
So smooth!

Playing around with motion
@altfortomorrow
COOL!
I just tried
@genmoai
on three images. It did great and it's free.
I put all three together in a short vid👇 I sped it up 2X
#ai
#AIArtCommuity
#aiART
#aianimation
#animation
#midjourneyV6
#digitalart
#motionGraphics
#art
2
1
15
0
0
8

This is quite an exciting direction for making DL more energy efficient. Congratulations Paras!

0
0
7

We're at the UAI virtual poster session now. Come find
@qiyang_li
and I at Poster Session II (c), poster spot G5. Joint work with
@pabbeel
at
@berkeley_ai
.
0
1
7
Congrats
@AxSauer
and collaborators!

StyleGAN-T: Unlocking the Power of GANs for Fast Large-Scale Text-to-Image Synthesis
significantly improves over previous GANs and outperforms distilled diffusion models in terms of sample quality and speed
abs:
project page:
21
185
902
0
1
7
LMConv improves PixelCNN++ (
@TimSalimans
et al) CIFAR10 likelihoods to 2.89 bpd by averaging over multiple orders (with one set of parameters). At test time, generate coherent image completions by choosing a maximum context order: just sample the missing pixels last! 5/8

1
0
7
PixelCNNs (
@avdnoord
et al 2016) introduced a convolutional inductive bias with parallel training, useful for generating images in raster scan order and fitting latent priors (eg VQ-VAE). SPN (
@jacobmenick
et al) proposed a variant to support a different subscale order. 7/8
1
0
7
I'm sharing this since we've made a big update to our paper from last year, with lots of new robustness experiments, insights and open questions. Co-authored with
@_parasj
@tianjun_zhang
@pabbeel
@mejoeyg
and Ion Stoica. 3/3
1
0
7
@ShirazAkmal
The ghost model above is an exported mesh (GLB file), rendered in
I also have a bunch loaded up in blender, planning to play around :)
2
0
7