

Misha Laskin
@MishaLaskin
Followers
8,957
Following
184
Media
151
Statuses
685
Something new. Prev: Staff Research Scientist @DeepMind . @berkeley_ai . YC alum.
NYC
Joined August 2013
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Brazil
• 1180576 Tweets
Elon Musk
• 721961 Tweets
Meu Twitter
• 483724 Tweets
Alexandre de Moraes
• 471351 Tweets
Bluesky
• 214134 Tweets
Adeus Twitter
• 183091 Tweets
Politico
• 160259 Tweets
Xandão
• 158295 Tweets
#BUS1stFANCON_KnockKnockKnock
• 142808 Tweets
Wisconsin
• 122381 Tweets
Tchau
• 95672 Tweets
Caitlin Clark
• 67630 Tweets
Temple
• 59620 Tweets
ブラジル
• 41051 Tweets
Angel Reese
• 34390 Tweets
#プレイバックガチャ
• 33552 Tweets
Michigan State
• 23195 Tweets
#INZM_30Mviews
• 21988 Tweets
Janta Kee Awaaz
• 20278 Tweets
野菜の日
• 18524 Tweets
#GiftOfEducation
• 17048 Tweets
Djokovic
• 13593 Tweets
Stanford
• 12119 Tweets
カネゴン
• 11431 Tweets
#TheLastDriveIn
• 10770 Tweets
台風一過
• 10188 Tweets





















Transformers are arguably the most impactful deep learning architecture from the last 5 yrs.
In the next few threads, we’ll cover multi-head attention, GPT and BERT, Vision Transformer, and write these out in code. This thread → understanding multi-head attention.
1/n

23
653
3K
In our new work - Algorithm Distillation - we show that transformers can improve themselves autonomously through trial and error without ever updating their weights.
No prompting, no finetuning. A single transformer collects its own data and maximizes rewards on new tasks.
1/N
24
249
1K
Patch extraction is a fundamental operation in deep learning, especially for computer vision.
By the end of this thread, you’ll know how to implement an efficient vectorized patch extractor (no for loops) in a few lines of code and learn about memory allocation in numpy.
1/n

12
204
1K
GPT has been a core part of the unsupervised learning revolution that’s been happening in NLP.
In part 2 of the transformer series, we’ll build GPT from the ground up. This thread → masked causal self-attention, the transformer block, tokenization & position encoding.
1/N

5
109
603
Einops are pretty magical. For example, with einops you can implement max pooling in 2 lines of code.
Patches → set size of patch, decompose HW dims in rearrange as (num_patches * size), specify output dim.
Pooling → pick out maximum over each patch.
That is all.

3
76
556
Starting a blog about the engineering + scientific ideas behind training large models (e.g. transformers).
First post covers data parallelism, a simple and common technique for parallelizing computation across multiple devices.
1/N
6
63
456
New paper led by
@astooke
w/
@kimin_le2
&
@pabbeel
- Decoupling Representation Learning from RL. First time RL trained on unsupervised features matches (or beats) end-to-end RL!
Paper:
Code:
Site:
[1/N]

7
113
418
How much memory do you need to train deep neural networks? You may find the answer to be counter intuitive.
For example, suppose we're training a 4 megabyte MLP with batch_size = hidden_dim, how much memory do we need? 4MB? No - we need 8MB!
Here's why...
1/N
4
47
405
Building on parts 1 & 2 which explained multi-head attention and GPT, in part 3 of the Transformer Series we'll cover masked language models like BERT.
This thread → masked language models, diff between causal and bi-directional masked attention, finetuning, and code.
1/N

5
48
263
Ever gotten tired of seeing the same architecture in deep RL ever since DeepMind's Atari-DQN, and wanted to see more papers that explore helpful changes? Check out our latest work FLARE, which replaces frame-stacking.
📝
💻
1/N

3
58
265
Over the last few years, unsupervised learning has produced breakthroughs in CV and NLP. Will the same thing happen in RL?
@denisyarats
and I wrote a blog post discussing unsupervised vs supervised RL and the unsupervised RL benchmark.

1
53
251
Is RL always data inefficient? Not necessarily. Framework for Efficient Robotic Manipulation (FERM) - shows real robots can learn basic skills from pixels with sparse reward in *30 minutes* using 1 GPU 🦾
paper:
site / code:
1/N
6
53
255
I was wondering how ChatGPT managed to interleave code with text explanations. Was hoping this was an emergent behaviour.
Turns out it’s likely straight up imitation learning on curated contractor data. Makes sense but kind of deflating.

I just refused a job at
#OpenAI
. The job would consist in working 40 hours a week solving python puzzles, explaining my reasoning through extensive commentary, in such a way that the machine can, by imitation, learn how to reason. ChatGPT is way less independent than people think
63
264
1K
13
19
251
@abacaj
Important caveat - the scale of the model small. Generalization might only emerge at scale

9
10
248
New post - how do we train models that are larger than the memory of a single GPU? Break the model into smaller pieces across several devices.
This technique is called model parallelism. I'll show how it works in practice with code examples.
1/N
1
49
233
If you're not already in RL, here's an informal introduction to the field I wrote at the tail of my postdoc.
A high-level motivation for how RL differs from more traditional ML problems and why it's important.

1
32
160
This diagram deserves the test of time award. It was confusing when I first got into ML and remains confusing today.

All major neural networks, in one chart:
v/The Asimov Institute

75
1K
6K
0
12
145
And there you have it - we derived attention intuitively and wrote it out in code. The main idea is quite simple.
In next posts I will cover Transformers, GPT & BERT, Vision Transformers, and other useful tricks / details. That was fun to write, hope also fun to read!
12/n END

16
12
143
Our team is hiring for both RS and RE roles! Research focus is building generalist agents. At ICML this week, ping me if you're interested in chatting.
6
13
142
@AndrewYNg
a few areas, some applied / some basic research
- climate change
- computational drug discovery
- ethical AI
- generalization to new tasks
- world models / representation learning
- long-horizon problem solving / better hierarchies
1
1
137
New updates to RAD (RL + data augs) answer the following:
1)Why does random crop work so well? -> translation invariance
2)Does data aug work for state-based RL too? -> yes
SOTA on DeepMind control (pixel-based RL) and OpenAI gym (state-based RL).
1/N

3
33
125
You may have read that transformers like GPT are memory intensive and scale poorly with sequence length. Why is that?
In this post, we'll derive a formula for a transformer's memory footprint and explain why transformers can be so memory hungry.
Let's get started...
1/N
2
19
127
Excited to share a paper on local updates as an alternative to global backprop, co-led with
@Luke_Metz
+
@graphcoreai
@GoogleAI
&
@berkeley_ai
.
tl;dr - Local updates can improve the efficiency of training deep nets in the high-compute regime.
👉
1/N
1
21
116
New paper coming up at
@NeurIPSConf
- Sparse Graphical Memory for Robust Planning uses state abstractions to improve long-horizon navigation tasks from pixels!
Paper:
Site:
Co-led by
@emmons_scott
,
@ajayj_
, and myself.
[1/N]
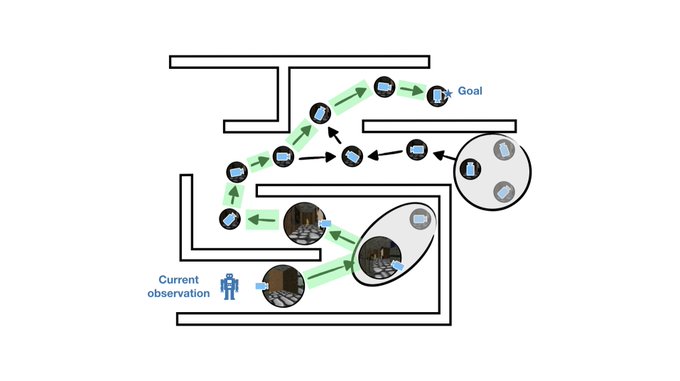
1
16
108
New paper on unsupervised skill discovery - Contrastive Intrinsic Control.
Tl;dr exploration with contrastive skill learning substantially improves prior skill discovery methods (by 1.8x)! Achieves leading unsupervised RL results.
Learn more 👇
1/N

2
20
106
We're launching a benchmark for unsupervised RL. Like pre-training for CV / NLP, imo unsupervised RL will lead to the next big breakthroughs in RL and bring us closer to generalist AI.
Our goal is to get us there faster. LFG!!!
Code / scripts:
1/5


Currently It is challenging to measure progress in Unsupervised RL w/o having common tasks & protocol. To take a step in addressing this issue we release our
#NeurIPS2021
paper: (URLB) Unsupervised RL Benchmark!
Paper:
Code:
1/N

2
55
230
1
19
102
Can pixel-based RL be as data-efficient as state-based RL? We show for the first time that the answer is yes, new work with
@Aravind7694
and
@pabbeel
website 👉
code 👉


New paper - CURL: Contrastive Unsupervised Representations for RL! We use the simplest form of contrastive learning (instance-based) as an auxiliary task in model-free RL. SoTA by *significant* margin on DMControl and Atari for data-efficiency.
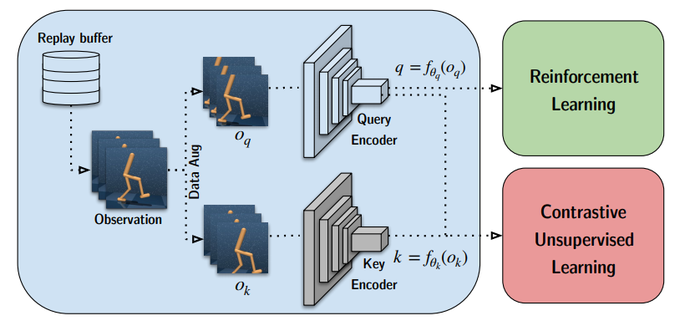
11
240
1K
2
23
101
A summary of interesting findings:
1. Transformers can do in-context RL
2. In-context RL with AD is more efficient than gradient based source RL algo
3. AD improves suboptimal policies
4. In-context RL emerges from imitation learning with long contexts
11/N
4
11
89
In-context RL at scale. After online pre-training, the agent solves new tasks entirely in-context like an LLM and works in a complex domain. One of the most interesting RL results of the year.

I’m super excited to share our work on AdA: An Adaptive Agent capable of hypothesis-driven exploration which solves challenging unseen tasks with just a handful of experience, at a similar timescale to humans.
See the thread for more details 👇 [1/N]
25
266
1K
0
9
90
Can RL From Pixels be as Efficient as RL From State? BAIR blog post detailing recent progress in pixel-based RL describes CURL / RAD & tradeoffs. Was a fun collaboration!
w/
@AravSrinivas
@kimin_le2
@stookemon
@LerrelPinto
@pabbeel
1
27
86
A small but important detail is that we need to re-scale the weights by 1 / sqrt(D). Why this specific scaling? Why not 1 / D or 1 / T or some other constant? The reason is that 1 / sqrt(D) ensures that the standard deviation of the outputs is roughly equal to 1.
7/n

2
5
81
Excited to finally share what I’ve been working on over the past year. Gemini is a really capable SOTA model with strong reasoning and coding abilities. It’s multimodal - can understand images, videos, audio, and text.
It was a really intense and collaborative effort!
2
2
79
What is attention? Say you want to classify the sentiment of “attention is not too shabby.“ “shabby” suggests 😞 but “not” actually means it's 😀. To correctly classify you need to look at all the words in the sentence. How can we achieve this?
2/n

1
6
77
New paper / algo - MABE! We show that combining dynamics models + weighted behavioral priors results in offline RL that is (a) robust across datasets and (b) can transfer behaviors across domains.
Paper:
Site:
🧵 1/8

2
15
74
DeepMind control from pixels seems beaten. PlaNet -> SLAC -> Dreamer -> CURL -> RAD & DrQ.
Now Plan2Explore shows zero-shot SOTA performance on DMControl relative to Dreamer.
great work!
@_ramanans
@_oleh
@KostasPenn
@pabbeel
@danijarh
@pathak2206

0
13
74
We introduce a pre-training method called Algorithm Distillation (AD) that produces transformers that can reinforcement learn in-context.
AD has two steps. First, we train many copies of an RL algorithm to solve many different tasks and save the learning histories.
4/N

2
8
65
Humans reuse skills effortlessly to learn new tasks - can robots do the same? In our new paper, we show how to pre-train robotic skills and adapt them to new tasks in a kitchen.
tl;dr you’ll have a robot chef soon. 🧑🍳🤖
links / details below
thread 🧵 1/10
1
15
67
So multi-head is just a small tweak to single-head attention. In practice, we also add dropout layers to further prevent overfitting and a final linear projection layer. This is what a complete vectorized multi-head self-attention block looks like in PyTorch.
11/n

1
9
63
The fact that language is such a powerful form of tokenization makes me wonder - what would it take for AI trained on raw sensory inputs (pixels, audio, touch sensing) to develop its own language?
3
3
64
We'll soon be able to fully outsource some categories of knowledge work to AI models. But we are not there yet - today’s models are unreliable & require close human supervision.
Had fun discussing how we can leverage insights from Gemini and AlphaGo to overcome these challenges.

🤖 New
@Sequoia
Training Data episode! Featuring
@MishaLaskin
, f research scientist at
@DeepMind
& CEO of Reflection AI. Full ep:
@sonyatweetybird
and I chat w Misha about 1) why we’re still far from the promise of AI agents, 2) what we need to unlock
4
12
86
3
8
63
Technically what we’ve shown is called single-head self-attention. Before going to multi-head attention, let’s code up what we’ve done so far.
9/n

2
4
60
Once a dataset of learning histories has been collected, we train a transformer to predict actions given the preceding learning history.
Since the policy improves over the history, predicting actions accurately forces the transformer to model policy improvement.
5/N

1
7
61
The simplest thing we can do is input all words into the network. Is that enough? No. The net needs to not only see each word but understand its relation to other words. E.g. it’s crucial that “not” refers to “shabby”. This is where queries, keys, values (Q,K,V) come in.
3/n

1
4
56
First RL algo to solve the diamond challenge in Minecraft without demonstrations. Congrats
@danijarh
!
1
3
57
We want the orange matrix to weigh relationships based on how useful word_i is as context for word_j. So let’s create two more linear nets called “queries” and “keys”. The weight w_ij should be proportional to the inner product between the i-th Q and the j-th K.
6/n

2
5
55
The issue is that naive summing of values assumes the relationships between all words are equal. E.g. relationship between “is” and “too” is equal to that between “not” and “shabby”. But clearly “not” <> “shabby” is more important for sentiment analysis than “is”<>”too”.
5/n

1
4
52
Would be great if transformers could adapt (do RL) out-of-the-box.
Don't Decision Transformers (DTs) / Gato do RL? No!
DTs and Gato learn policies from offline data, but these policies cannot improve themselves autonomously through trial and error.
3/N

1
4
51
That's it. The transformer is trained just by imitating actions (no Q values like usual RL) over long obs-action-reward sequences (no return conditioning like DTs).
In-context RL emerges for free. We evaluate AD by seeing if it can maximize return on new tasks.
6/N
1
4
53
Would argue this also applies to AI research. It's important to iterate on ideas quickly (e.g. by implementing them in code and launching experiments). Most ideas will be bad. But you learn from them and give yourself enough opportunities to spot a winner.

Don't compare your first drafts to other people's final drafts.
Here's my mini-essay.

14
93
578
0
7
50
We've seen a lot of successful models showing how transformers can learn in-context.
But transformers have not been shown to *reinforcement* learn in-context. To adapt to new tasks, you either need to manually specify a prompt or finetune the model (e.g. preferences).
2/N

1
3
52
Would not have predicted this a year ago - but Meta has become the single most important company in AI. A closed model is good for one business. An open model is good for the entire market.
1
2
50
The transformer explores, exploits, and maximizes return in-context - it's weights are frozen!
Expert Distillation (most similar to Gato), on the other hand, cannot explore and fails to maximize return.
7/N

1
5
52
Thanks to
@kharijohnson
for the thoughtful coverage on Reinforcement Learning with Augmented Data. Read more about it on
@VentureBeat
:
w/
@kimin_le2
@stookemon
@LerrelPinto
@pabbeel
@Aravind7694

1
19
52
Blown away by the conclusions serious researchers / engs are drawing from this paper.
They trained a small model on sinusoids and we’re somehow making claims about LLMs not generalizing at scale.
Limited data diversity at a small model scale. What do you expect?

2
7
51
Finally, we need to normalize the weights along the axis that will be summed, so we use a softmax. Intuitively, Q is a question “how useful am I for word K?” High / low inner product means very / not very useful. With that we are done - this is attention!
8/n

1
4
50
AD can distill any RL algo - we tried UCB, DQN, A2C.
An interesting finding is that the in-context RL algorithm learned with AD is much more data-efficient than the source algorithm it was trained to distill.
8/N

2
6
50

Let’s pass the words through a linear layer and call its outputs “values”. How do we encode relationships between values? We can mix them by summation. Now we “see” both words and relationships, but that’s still not quite right. What’s wrong with this code?
4/n

2
5
48
If we know the output shape of the patch tensor, we can then specify the strides appropriately to get the desired patches. In numpy, the stride_tricks module provides this functionality. For example, here is how you implement non-overlapping patch extraction (e.g. for ViT).
7/n

1
3
47
Now you know how to implement vectorized patch extraction. We covered non-overlapping patches but the same logic can be used to deduce the strides for overlapping ones (e.g. for CNNs, mean / max pooling, data aug).
Will be posting more of these. Hope you enjoyed it.
12/n END
7
1
45
This was a fun project with contributions from many collaborators. Luyu Wang,
@junh_oh
, Emilio Parisotto, Stephen Spencer,
@RichiesOkTweets
,
@djstrouse
@Zergylord
,
@filangelos
, Ethan Brooks,
@Maxime_Gazeau
,
@him_sahni
, Satinder Singh,
@VladMnih
12/N
11
3
45
Recently released Contrastive Intrinsic Control (CIC), an unsupervised RL algo that pre-trains agents with contrastive skill learning (and no extrinsic rewards!) & achieves leading adaptation efficiency.
Here's an intuitive explanation of how it works:

0
9
44
If you're interested in working with the General Agents team at Google DeepMind, please apply asap. Applications close tomorrow 4pm EDT.
Research Scientist:
Research Engineer:

Our team is hiring for both RS and RE roles! Research focus is building generalist agents. At ICML this week, ping me if you're interested in chatting.
6
13
142
2
4
42
What is multi-head and why do we need it? Our single-head net may overfit to the training data. In ML, ensembles are a common strategy to combat overfitting. By initializing multiple nets we get more robust results. The concat of N single heads is multi-head attention.
10/n

1
3
40
The emergence of in-context RL only happens if the context length of the transformer is long enough, spanning multiple episodes.
AD needs a long enough history to effectively model improvement and identify the task.
10/N

2
4
41
What’s the state of neural retrieval?
KNN on cosine similarity or L2 is a poor heuristic. Training an SVM is better but has added computational load.
Is there a fast retrieval operation that works better than naive KNN?
6
3
41
Will be at NeurIPS next week. Who wants to meet up to chat?
11
1
37
Another neat property is that you can prompt AD with suboptimal demonstrations and it will automatically improve them until optimal!
ED, on the other hand, only maintains the performance of a suboptimal demonstration.
9/N

1
3
36
@RokoMijic
This is misleading. Loss functions only look like this for simple problems with narrow datasets.
For large scale training grokking happens frequently enough across diverse enough prediction tasks that the average is relatively smooth and the likelihood of a big drop is very
1
2
35
>> Paper review - Machiavelli benchmark >>
Lots of discussion about AI safety lately. Whatever side you take on the X-risk debate, it is important to develop metrics that measure the safety properties of AI agents.
This is the aim of the Machiavelli benchmark...
>> Context >>

3
6
34
ChatGPT is amazing, but I found that it is easily hallucinates if prompted with something that sounds plausible.
Here ChatGPT confidently describes VEPO, an RL algorithm that doesn't exist.

1
4
31
@TaliaRinger
A less cynical take. Context: did phd in physics, now ML posdoc. (i) ML experiment cycles are *very* fast vs other sciences (ii) other sciences require years of background education. ML does not. A gifted high school student could contribute. These are positive things.
1
0
30

A new text-to-video generation startup launched by a pioneer of diffusion models. Excited for this direction and the future of video! "Make a dramatic thriller about a Corgi astronaut escaping a black hole, trending on HBO, narrated by Werner Herzog." I'd watch.

Announcing Genmo Video, a generative media platform with a new text-to-video model that can generate immersive live artwork from any prompt or any image.
What will you create? 🎨▶️
Free public access:
Discord:
👇1/n
15
63
251
0
3
28
Wenlong & co continue to produce bangers at the intersection of LLMs and robotics. Very cool work

Large language models gathered tons of world knowledge by speaking human language. But can they ever speak “robot language”?
Introducing “Grounded Decoding”: a scalable way to decode *grounded text* from LLM for robots.
Website:
🧵👇
6
85
455
1
0
27
Very impressive new work on long context transformers. This particular bit is valuable - going from 4K to 32k context length with a 13B model on just 8 GPUs!

RingAttention lets you scale context length linearly with device count, breaking free from memory constraints. If you could train 4K length on 8 GPU, with RingAttention, you can train at least 32K length with nearly zero overhead
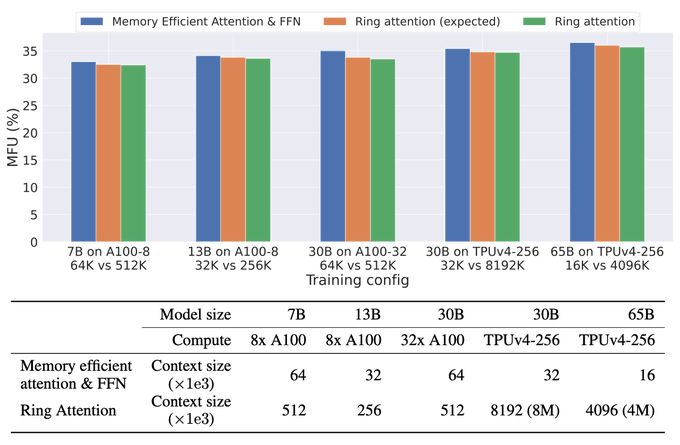
1
7
77
1
3
26
...or rather, not entirely correct.
Since we train deep nets with backpropagation, we need to store not just the model but also all of the activations from the fwd pass in order to compute gradients.
The memory needed to store activations is often >> than size(model).
3/N
1
1
24
I’d argue the opposite - LangChain seems very valuable. My mental model is that LangChain is to LLMs what React is to web apps.
1. Has powerful boilerplate abstractions (e.g. prompt chaining, streaming) akin to react components.
2. Is LLM provider agnostic. Akin to react being

i don't get it. there is seriously no value here. why did someone invest 10m in it? are they crazy? are they idiots?

74
11
263
3
1
24
If this was interesting, consider following
@MishaLaskin
. Will post similar calculations for Transformers soon + other topics that will help strengthen intuition for deep learning.
12/N
END
1
0
23
It was pretty mind-blowing finding out that Transformers can do RL. No value estimates, no policy gradients, just sequence modeling. A glimpse of what RL might look like in the future. Congrats to all collaborators and especially co-leads
@lchen915
@_kevinlu
!

Can RL algorithms be replaced with transformer-based language models? We’ve looked at this question with our work on Decision Transformer:
Website:
Code:
1/8
18
257
1K
0
0
23
Shape = dimension of array. Itemsize = the number of bytes per cell (float32 = 32 bits = 4 bytes). Strides = the number of bytes required to traverse the contiguous memory block to read the next element along a given dimension. Strides = # steps-to-traverse * itemsize.
6/n

1
3
22
Frozen language models can be used to generate plans for robots. Comes with a great explainer video.

LLMs like GPT-3 and Codex contain rich world knowledge. In this fun study, we ask if GPT like models can plan actions for embodied agents.
Turns out, with apt sanity checks, even vanilla LLMs without any finetuning can generate good high-level plans given a low-level controller.
10
164
993
0
1
22
In deep learning we often need to preprocess inputs into patches. This can mean splitting an image into overlapping or non-overlapping 2D patches or splitting a long audio or text input into smaller equally sized chunks.
2/n
1
2
22
We covered masked causal attention, the GPT objective, transformer blocks, tokens & positions. Note: there are ofc many other strategies for tokenization / pos encoding.
Putting it all together, here’s the code for the GPT architecture!
12/N END



1
1
21
Tomorrow I'll give a talk on RL with Transformers (a tutorial and new work) at AI for Ukraine, a non-profit that helps the Ukrainian community learn about AI.
Please consider donating or supporting.

Last call📣
Tomorrow's AI for Ukraine session will be led by
@MishaLaskin
, Senior Research Scientist at
@DeepMind
.
We'll talk about data-driven Reinforcement Learning with Transformers. See you on October 26 at 7 pm (GMT+3).
Learn more and register at

0
1
8
0
5
21
It’s remarkable that AI research continues to produce multiple incredible demos per year. It also seems like the rate of mind blowing results is accelerating and that we’re far from the saturation point of the “scaling up” phase of deep learning 🤯

Block-NeRF: Scalable Large Scene Neural View Synthesis
abs:
project page:
31
554
2K
0
5
21
the issue with getting reliable outputs from LLMs as a user is that you don't know what prompts were used during RLHF when the model was aligned
so you are forced to manually explore the space of possible prompts

LLMs are basically sorcery. i tried using gpt-4 to generate synthetic data, including "with x words" in my prompt. it failed when x > ~800, giving ~400 word responses. then i tweaked my prompt to say "with AT LEAST x words," and word counts were much better (within 20% of x). ugh
18
13
194
0
1
20
We've now learned how to efficiently extract patches from grayscale images. What about RGB images - how do we deal with the channel dimension? Turns out the fix is quite simple. We just need to modify the row & col strides to ignore the channel dimension.
11/n

1
2
20
Yes - we can make patch extraction fast and lightweight by leveraging how numpy (or torch, tf, jax, etc) stores arrays in memory. Numpy stores arrays in contiguous memory. This structure makes reading data from the image array very efficient.
4/n

1
1
20
The best way to understand how to specify strides is to work through each dimension in the output shape. For each dimension ask - how many steps need to be traversed to access the next element along this dimension?
9/n

1
1
20
@JosephJacks_
@_akhaliq
Is it? Transformers + RNNs have been done before (e.g. TransformerXL) but performed worse despite the larger memory. Seems like a similar outcome here
2
0
19
stride_tricks.as_strided is a general purpose function for viewing any array. By specifying the shape and strides we fully define how to traverse this array for viewing. In our case we want to view it as patches - the main trick is to figure out the correct strides.
8/n

1
1
19
Very impressive 3D mesh extraction from using the iPad's camera & LIDAR sensor. Before, extracting quality 3D meshes required expensive camera equipment and took a long time to process, now can be done from an iPad and renders in real-time. Amazing work
@cpheinrich
!

Huge news! The Polycam
#lidar
3D scanning app is now live 🚀! If you have a 2020 iPad Pro you can download at: . If you like this sort of thing and want to see it grow please share and retweet 🙏!!
41
245
1K
0
2
19
Great explainer video of Algorithm Distillation. I especially liked that it got into some of the more nuanced points and limitations of the work.

New video covering RL Algorithm Distillation, a paper about learning algorithms for RL with ML!
Great paper from
@MishaLaskin
and colleagues
3
2
45
1
2
18