

Denny Zhou
@denny_zhou
Followers
17K
Following
3K
Media
68
Statuses
742
Founded & lead the Reasoning Team in Google Brain (now part of Google DeepMind). Build LLMs to reason. Opinions my own.
Joined August 2013
What is the performance limit when scaling LLM inference? Sky's the limit. We have mathematically proven that transformers can solve any problem, provided they are allowed to generate as many intermediate reasoning tokens as needed. Remarkably, constant depth is sufficient.

113
533
3K
Panic at Meta? Not at all. They’ve achieved exactly what they wanted: democratize AI.
66
60
1K
Chain of Thought Reasoning without Prompting . (NeurIPS 2024). Chain of thought (CoT) reasoning ≠ CoT prompting. While the term "chain of thought" was popularized from prompting, it now primarily refers to the generation of step by step reasoning – the.
24
212
1K
any benchmark—including ARC-AGI—can be rapidly solved, as long as the task provides a clear evaluation metric that can be used as a reward signal during fine-tuning.
65
74
1K
The AI revolution has begun. No matter whether we like it or not.
76
129
909
The most beautiful thing on LLM reasoning is that the thought process is generated in an autoregressive way, rather than relying on search (e.g. mcts) over the generation space, whether by a well-finetuned model or a carefully designed prompt.
33
62
669
In my lecture given at UC Berkeley last year, in the last slide, I quoted Richard P. Feynman's: "The truth always turns out to be simpler than you thought." If you wondered why I chose that quote, now you know.

13
49
506
Tree search, the key idea in classical AI, has little to do with true intelligence or reasoning, no matter which fun puzzle / games are well solved by search eg game 24. Search is just a tool usage. Surprised to see so many regard search as reasoning to pursue.
42
37
501
AGI is finally democratized: RLHF isn't just for alignment—it's even more fun when used to unlock reasoning. Once guarded by a small circle in Silicon Valley, now the secret is for everyone.
18
49
486
My talk slides: on key ideas and limitations of LLM reasoning, largely based on work in GDM. Thank you so much for the invitation, Dawn!.

Really excited about the enthusiasm for our LLM Agents MOOC: 4000+ already joined within 2.5 days of announcement! 🎉🎉🎉. Join us today at online for 1st lecture on LLM reasoning, @denny_zhou @GoogleDeepMind, 3:10pm PT!

11
67
452
Our fast tokenizer work is accepted to EMNLP 2021 as oral, and released in several Google products. 8.2x faster than HuggingFace Tokenizers and 5.1x faster than TensorFlow Text.

5
60
392
Our new model is still experimental, and we’re eager to hear your feedback! One thing that I want to particularly highlight is that our model transparently shows its thought process.

Introducing Gemini 2.0 Flash Thinking, an experimental model that explicitly shows its thoughts. Built on 2.0 Flash’s speed and performance, this model is trained to use thoughts to strengthen its reasoning. And we see promising results when we increase inference time.
18
16
299
Our team at Google DeepMind has a full-time Research Scientist position available at our Mountain View site. Minimum qualification: PhD in ML/NLP. Please email me with: your CV and Google Scholar link; a brief description of the impactful work you have done; and what you aim.
12
50
289
I asked Gemini Next to generate such a paper for me about one month ago. It has not shown any signs of stopping. I will miss the ICLR deadline :(.

next paper: transformers can solve any problem but on some of them they may compute indefinitely and never provide an answer.
9
11
269
A key finding in this work: adding irrelevant context to GSM8k problems causes LLMs to fail at solving them, as we demonstrated in our ICML 2023 paper, "Large Language Models Can Be Easily Distracted by Irrelevant Context" (. The differences in prompt


1/ Can Large Language Models (LLMs) truly reason? Or are they just sophisticated pattern matchers? In our latest preprint, we explore this key question through a large-scale study of both open-source like Llama, Phi, Gemma, and Mistral and leading closed models, including the

25
47
264
In the old days, the term “RL” by default meant the “true RL” used in AlphaZero. Now, the term “RL” by default means the “fake RL” used in RLHF (nothing is negative about RLHF here. RLHF is a great innovation).
22
15
265
In our ICML 2023 paper "Large language models can be easily distracted by irrelevant context" (, we simply asked LLMs to ignore the irrelevant context and then they worked well. E.g. the example showed in your paper can be solved as follows:


🚨 New paper! 🚨.We introduce System 2 Attention (S2A). - Soft attention in Transformers is susceptible to irrelevant/biased info.- S2A uses LLM reasoning to generate what to attend to.Improves factuality & objectivity, decreases sycophancy. 🧵(1/5)

7
19
256
If LLMs are humans, all the ideas are trivial: chain-of-thought prompting ("explain your answer"), self-consistency ("double check your answer"), least-to-most prompting ("decompose to easy subproblems"). The shocking thing is that LLMs are not humans but these still work!.
8
29
249
This week marks ICLR 2023. Thrilled to share a thread dedicated to our 9 accepted papers. We are grateful that all our submissions were accepted and truly appreciate the constructive discussions and valuable feedback provided by the reviewers. 🧵.
11
38
243
After "the bitter lesson", people love talking about that search and learning are the two methods that can scale arbitrarily. But my favorite part of the article is: "We want AI agents that can discover like we can, not which contain what we have discovered. Building in our.
10
15
248
Long context is essentially a length generalization problem. Our recent work "Transformers Can Achieve Length Generalization But Not Robustly" ( showed a surprisingly simple approach to achieving length generalization: train your model several times using.
6
30
241
The reasoning abilities of large language models, such as search capabilities, can naturally emerge during training rather than requiring explicit integration. For instance, when solving “game of 24”, a well-trained LLM should be capable of autonomously exploring different.
25
22
241
Reduce serving cost is a huge problem in the field of LLMs. Typically done by distillation and quantization. We propose "LLMs as Tool Makers", as a complementary solution to these existing techniques.

5
46
232
Self-consistency amazingly improves chain-of-thought prompting, even 50+% improvements on many tasks. Why does it work so well? It essentially integrates/marginalizes out all latent reasoning paths to compute the full probability of each distinct answer! .
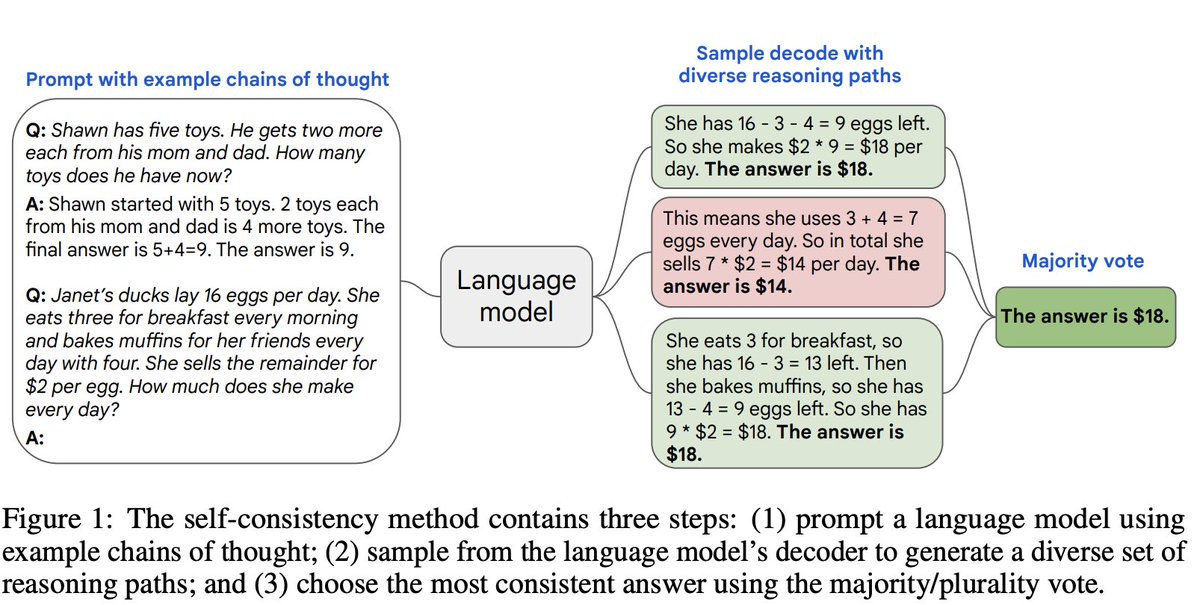
7
43
226
Self-consistency improves chain of thought reasoning in large language models.

7
34
218
Don't just scale. Algorithmic innovation is still essential. E.g. scaling supervised fine-tuning sounds like a low-hanging fruit but it actually doesn't help much. It fails not from lack of data, but the limits of the paradigm itself. The real shift? Reframe post-training as.
12
19
224
Identifying what to scale is crucial for building LLMs. What’s your favorite inference-time scaling?. 1. Scaling self-consistency (SC)[1]: Generate thousands of samples, then aggregating. 2. Scaling search/mcts. Tree of thought prompting [2] applies search to prompting, excelling.
21
32
218
Maybe time to initiate a new conference dedicated to LLMs, reminiscent of how ICLR emerged for DL years ago. This could also help reduce submissions to NeurIPS and ICLR. Any thoughts?.
14
8
192
Few-shot prompting will soon become obsolete. It is just a transitional step as we shift from machine learning to LLM-centered AI. Natural interactions will win out.
27
14
185
Debating whether LLMs will lead to AGI or if LLMs can reason is a waste of time. What truly matters is that today's AI techniques are way more generic and powerful than ever before. High respect to all contributors.
6
18
175
This is not quite RL: the blue one looks way smarter than the rest. It seems planning with reasoning, and the others that succeeded basically imitate the blue one.

Reinforcement learning explained.
11
10
173
A key point in the chain-of-thought prompting paper: RIP downstream-task finetuning on LLMs.
7
21
173
To know more about this paradigm shift, a good starting point is the STAR paper ( by Eric(@ericzelikman), Yuhuai (@Yuhu_ai_), and Noah. If letting me guess what star in Q-star means, it has to be this STAR, the most undervalued work on finetuning.
5
16
173
Slides of my talk given at the fascinating ACL 2023 natural language reasoning workshop (: several points to highlight:.
2
24
156
Instead of using the terms “system 1/2,” for LLM reasoning, it is more appropriate to view reasoning as a continuous spectrum, defined by inference time.

system 1 vs system 2 thought is bullshit imo, and i honestly think it's a neuroscience old wives tale clung onto by researchers who couldn't make their inference algorithms scale beyond math problems. the goal is trading model scale for extended thought 1:1.
14
16
154
Mathematical beauty of self-consistency (SC) . SC ( for LLMs essentially just does one thing: choose the answer with the maximum probability as the final output. Anything else? Nothing. Don't LLMs choose the optimal answer by default? Not necessarily.
5
25
153
To fix hallucinations in chatbots, a high-quality search engine is first must-have. This is obvious to experts, but definitely not to everyone.
13
9
148
2023: the year prompting engineering was deprecated.2024: the year supervised finetuning was deprecated. what will be in 2025?.
34
9
148
Biggest milestones in AI: perceptron, deep learning / transformer, pretraining + prompting.
5
14
137
Discovering and understanding emergent abilities of LLMs, like CoT reasoning, is the most exciting and challenging topic in LLM research. These emergent abilities are not intentionally built by anyone who trained LLMs via predicting next tokens.
5
22
143
LLMs/AGI is not a zero-sum game. We are just at the beginning of a great revolution.
12
12
140
For those who interpret/cite self-consistency (SC) as majority voting (MV) or other MV equivalents, they need to take an entry-level course in machine learning. In our original paper (, Xuezhi and I have provided the math theory underlying SC:.
4
17
138
Chain of thought (CoT) and related work are "cognitive science/psychology for LLMs" rather than prompting engineering. Discovering and understanding CoT emerged from LLM next-token-prediction pretraining is like studying human's cognition abilities emerged from neurons.
8
13
132
Self-debug has worked quite well on the raw GPT3.5 model: code-davinci-002 (not instruction tuned): .


GPT-4 has one emergent ability that is extremely useful and stronger than any other models: self-debug. Even the most expert human programmer cannot always get a program correct at the first try. We look at execution results, reason about what's wrong, apply fixes, rinse and

8
33
127
Fantastic comments by (@jkronand, @enjoyingthewind) connect our LLM reasoning work to Polya. Then checked the book "How to solve it". Page 75: "decomposing and recombining". Maps to "Least to Most Prompting" Page 98: "do you know a related problem".

4
9
124
I am planning to submit a workshop proposal on "large language model prompting" to ICLR '23. What will be your favorite name for the workshop? Tell me and I will choose the most voted name to submit.😀.
58
8
122
Compared to AI safety, now I am more concerned about the decline of human intelligence.
10
16
121
I believe OpenAI will continue to achieve remarkable breakthroughs as long as people like Ilya and Alec are still there. The next big innovation would make most of the current techniques (if not all) irrelevant. The imitation game is just at its very beginning.

I deeply regret my participation in the board's actions. I never intended to harm OpenAI. I love everything we've built together and I will do everything I can to reunite the company.
7
10
116
Just tried GPT-3 003: "What is the largest number?" It says "The largest number possible would be infinity". I asked the same question to my kid (3rd grade). She said "There is no largest number. For any given number, I can always make it larger by plus one."

11
2
111
Prompting seems to be difficult for some machine learning researchers to understand. This is not surprising because prompting in not machine learning. Prompting is the opposite of machine learning.
6
9
111
I dont think there is magic here: text-davinci-002 and other 002 models in GPT-3, and instruct GPT should have been finetuned with "let's think step by step . ". I tried 001 models in GPT3 and none of them works with this kind of prompt while CoT still works.

Large Language Models are Zero-Shot Reasoners. Simply adding “Let’s think step by step” before each answer increases the accuracy on MultiArith from 17.7% to 78.7% and GSM8K from 10.4% to 40.7% with GPT-3.

8
14
109
In NeurIPS 2023, there is a section “CoT/Reasoning”. When preparing our CoT paper, I kicked off a discussion on the title. Different names were proposed, like stream of thought (Jason), train of thought (Dale), chain of thought (Dale). Finally I decided to choose “chain of

8
11
108
Automate chain-of-thought prompting simply by letting LLMs recall relevant questions/knowledge that they have seen. Fully matches hand crafted CoT performance on reasoning/coding benchmarks and even performs better.


Introducing Analogical Prompting, a new method to help LLMs solve reasoning problems. Idea: To solve a new problem, humans often draw from past experiences, recalling similar problems they have solved before. Can we prompt LLMs to mimic this?. [1/n]

2
13
104
A crucial fact is often overlooked: LLMs are trained to reason, rather than prompted to reason. My team is dedicated to training but we also design various prompts to test LLMs.
11
1
105
Same for training LLMs.


1
13
102
Why does few-shot prompting work without any training or finetuning? . Few-shot prompting can be equivalent to fine-tuning running inside of an LLM!. Led by @akyurekekin, great collaboration with amazing folks: Dale Schuurmans, @jacobandreas, @tengyuma!.
3
12
104
A simple yet effective approach to fill the performance gap between zero-shot and few-shot prompting. Xinyun Chen @xinyun_chen_ is going to present our recent work LLM analogical reasoning ( this afternoon in the exciting #MathAI workshop of #NeurIPS2023.

Looking forward to the workshop! Excited to share our recent work on LLM reasoning.
3
20
99
I asked LLM its confidences on its answers. Turned out LLM was highly confident on its every answer. I was disappointed at the useless. Then I realized this is actually another empirical evidence showing the amazing coincidence between LLMs and humans, eg people like me.
11
6
93
See how Bard made it:


Sally (a girl) has 3 brothers. Each brother has 2 sisters. How many sisters does Sally have?. Here are 60 LLMs getting it wrong.
10
5
95
"Simple is best" is the guiding principle of my team's research. The most exciting moment in our work is witnessing the beauty of simplicity.
1
5
95
Don't try to "improve" chain-of-thought (CoT) prompts by "clever engineering". Those "engineering" tricks will be meaningless when LLMs are further improved. Should write CoT prompts naturally. Here is my favorite one taken from my kid's homework:

1
11
94
If CoT doesn’t perform well on a task, the issue isn’t CoT itself. I’d question the model or the task design instead. My little one put up this note on her bedroom door: “before you speak, think and be smart”.
10
6
97
A new conference is dedicated to language modeling for everyone. Great to see any feedback that you would have:

Introducing COLM ( the Conference on Language Modeling. A new research venue dedicated to the theory, practice, and applications of language models. Submissions: March 15 (it's pronounced "collum" 🕊️)

3
6
82
Using "natural language" to describe rationales, pioneered by (Ling et al 2017) and then followed by (Cobbe et 2021, Wei et al 2022), is essential for the success of chain of thought prompting. 1/.
3
16
82
Many years ago, Yahoo gave up building its own search engine and outsourced it to Google, and investors cheered up. Now Microsoft gives up building its own LLM and outsources it to OpenAI, and investors cheer up.
12
8
78
When the name Q* was leaked, many thought Q* would be a combination of Q-Learning and A* search, or some other more advanced search powered by RL, over the generation space. I commented that is a dead end. Now my comment should be clear to them.
2
2
76
Amazing! Met @demi_guo_ in Google Beijing about 5 years ago. She came with Xiaodong He, my invitee and collaborator, who did pioneering work on text-to-image. Now Pika's work is just like magic.

Excited to share that I recently left Stanford AI PhD to start Pika. Words can't express how grateful I am to have all the support from our investors, advisors, friends, and community members along this journey! .And there's nothing more exciting than working on this ambitious &.
3
4
74
Since day one of forming my reasoning team, our primary goal has been to solve reasoning problems without relying on search.
6
2
75
“If I were given one hour to save the planet, I would spend 59 minutes defining the problem and one minute resolving it.” — Albert Einstein.
2
3
71
For our ICLR submission, a reviewer wrote "I see a major limitation with this approach: it looks like the prompt examples need to be designed specifically for each dataset." Sounds like they expect AGI. That would be a really high standard.
4
4
67
A simple quiz to check if one understands the principle underlying self-consistency (:. If we ask the LLM to directly generate multiple responses instead of sampling multiple responses, and then aggregate the answers, will this work as well as.
Mathematical beauty of self-consistency (SC) . SC ( for LLMs essentially just does one thing: choose the answer with the maximum probability as the final output. Anything else? Nothing. Don't LLMs choose the optimal answer by default? Not necessarily.
8
3
66
Here is a simple way to reduce the submission number in a conference: charge each submission $$$, e.g. $100, refund after accepted.
18
2
62
Welcome to the new era of AI: "Deep" was once the buzzword at AI conferences, but it's no longer the case in COLM.


Folks, some @COLM_conf stats, because looking at these really brightens the mood :).We received a total of ⭐️1036⭐️ submissions (for the first ever COLM!!!!). What is even more exciting is the nice distribution of topics and keywords. Exciting times ahead! ❤️


1
11
61
Although our work is about LLMs, I actually don't think humans do better than LLMs on self-correcting. Look at those countless mistakes in AI tweets.

Interesting papers that share many findings similar to our recent work (, in which we argue that "Large Language Models Cannot Self-Correct Reasoning Yet". I'm happy (as a honest researcher) and sad (as an AGI enthusiast) to see our conclusions confirmed

2
11
60
For those familiar with complexity theory, the figure below illustrates the precise results. For further details, please refer to @zhiyuanli_ post.and our paper.


Why does Chain of Thought (CoT) work?. Our #ICLR 2024 paper proves that CoT enables more *iterative* compute to solve *inherently* serial problems. Otoh, a const-depth transformer that outputs answers right away can only solve problems that allow fast parallel algorithms.

0
8
60
Using rationales to solve math word problems has been in the NLP literature for years. Here is Fig 1 taken from “Learning to Solve and Explain Algebraic Word Problems” (Ling et al 2017, ACL).

2
12
62
Prompting is like teaching/instructing kids. When I was asked how to write a chain-of-thought prompt, I showed them my kid's homework.

2
6
61
A nice combination of LLMs and Google. Like least-to-most prompting, a complex questions is decomposed into a set of easier subquestions. The key difference here is that Google is used to answer those subquestions instead of LLMs.

We've found a new way to prompt language models that improves their ability to answer complex questions .Our Self-ask prompt first has the model ask and answer simpler subquestions. This structure makes it easy to integrate Google Search into an LM. Watch our demo with GPT-3 🧵⬇️
1
12
59
The “emergence” in LLMs has nothing to do with the “emergence” in complex systems, e.g. swarm intelligence. It is unfortunate to use the same term to illustrate two unrelated concepts and lead to confusion and misinterpretation.
2
11
58
holds for doing LLM research.


3
3
58
@arankomatsuzaki The truth should be simple: Text-davinci-002 (175B) or other 002 model, or instruct GPT have been finetuned with "let's think step by step. ". I tried 001 models and none of them works with the proposed method while CoT still works well.
5
6
53
@DrJimFan Self-debug: .

Teaching LLMs to Self-Debug. -Prompt instructs LLM to execute code then generate a feedback message based on result.-W/ out any feedback on code correctness, LLM is able to identify its mistakes by explaining its code. -SoTA performance on code generation.

4
6
52
Love seeing tweets like this, rather than those on LLMs with phd/superhuman intelligence, or fancy results on leaked benchmarks.

Claude still can't solve the impossible one farmer one sheep one boat problem

5
4
52
Debates on whether LLMs can reason like humans seem silly to me. What I care is whether a new technique is more useful than the existing ones. Have anyone heard any debate on whether machine learning is human-like? I have not. So, why having such debates on machine reasoning?🤣.
8
4
51
@ericzelikman @Yuhu_ai_ Here is a demo of thought generation by Gemini 2.0 flash thinking.

Excited to share an early preview of our gemini 2.0 flash thinking model with all it's raw thoughts visible. Here's the model trying to solve a Putnam 2024 with multiple approaches, and then self-verifies that it's answer was correct.
5
0
50
If you are interested in seeing how decomposition in the least-to-most prompting powerfully generalizes, here is the thread for you. Just use one simple example to teach GPT-3 code-davinci-002 how to decompose a problem, and test it with other problems.

1
4
49
Will be attending NeurIPS. Excited to meet COLM co-organizers in person, and receive suggestions on COLM from everyone in NeurIPS.
Some COLM updates - ( . * Added amazing @aliceoh and @monojitchou as DEI Chairs.* PCs are hard at work on org.* OpenReview Interest has been overwhelming, (400 surveys responses!) but the team is awesome and it's going to be great.
1
0
50
With only 0.1% examples, matched the SoTA in the literature (specialized models w/ full training) on the challenging CFQ benchmark; and achieved new great SoTA with only 1% examples. Opens a great opportunity to use knowledge graphs by natural language! Well done team!.

🚨 New preprint! 🚨. We refine least-to-most prompting and achieve sota on CFQ (95% accuracy), outperforming previous fully supervised methods. Joint first author work with the formidable Nathanael Schärli.
0
10
49
the most insightful post on deepseek r1 release.

Jevons paradox strikes again! As AI gets more efficient and accessible, we will see its use skyrocket, turning it into a commodity we just can't get enough of.
0
3
48
Surprised at seeing @kchonyc understands self-consistency as minimum bayesian risk (MBR). Self-consistency (SC) has nothing to do with MBR. Mathematically, SC is marginalizing the latent reasoning processes to compute the full probability of the final answer. If there is no.

modern LM research seems to be the exact repetition of MT research. here goes the prediction; someone will reinvent minimum Bayes risk decoding but will call it super-aligned, super-reasoning majority voting of galaxy-of-thoughts.
5
0
45
The ultimate breakthrough in AI would be the ability for an AI system to autonomously generate a superior AI system, without relying on human knowledge or guidance.
12
6
43