

Jie Huang
@jefffhj
Followers
4,998
Following
607
Media
56
Statuses
425
Building intelligence @xAI . PhD from UIUC CS
Joined July 2017
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Elon
• 931256 Tweets
#गल_काटे_सो_कुफर_कसाई
• 170666 Tweets
Michigan
• 161554 Tweets
#UFC307
• 127040 Tweets
Vandy
• 120254 Tweets
Watch Sant RampalJi YouTube
• 119253 Tweets
Tennessee
• 112383 Tweets
Dodgers
• 107418 Tweets
Vanderbilt
• 84022 Tweets
Dark MAGA
• 81758 Tweets
トッキュウジャー
• 80796 Tweets
#BUS_KnockKnockKnock_Korat
• 74482 Tweets
Nico
• 73472 Tweets
Pereira
• 71472 Tweets
Bama
• 71222 Tweets
Ohtani
• 70989 Tweets
ドジャース
• 66207 Tweets
プリキュア
• 49368 Tweets
Khalil
• 47556 Tweets
Arkansas
• 37667 Tweets
DONBELLE ASAP RESURGENCE
• 36863 Tweets
Aldo
• 33358 Tweets
ポストシーズン
• 30748 Tweets
Bautista
• 26629 Tweets
Save Sanatan Dharma
• 26347 Tweets
Pennington
• 22963 Tweets
Ifigenia Martínez
• 18954 Tweets
Machado
• 18888 Tweets
京都大賞典
• 17903 Tweets
Poatan
• 14451 Tweets
大谷さん
• 14355 Tweets
山本由伸
• 11684 Tweets





















My research often begins with curiosity-driven questions:
1. Are LLMs Leaking Your Personal Information? ()
2. Are LLMs Really Able to Reason? ()
3. Can LLMs Self-Correct Their Reasoning? ()
4. What is Missing
17
96
595
Life Update: joined
@xai
recently and witnessed the release of Grok-2.
Amazed by the passion of the team and how fast we are moving. Join us at

9
18
459
Certainly, this paper deserves more attention.


We took ChatGPT offline Monday to fix a bug in an open source library that allowed some users to see titles from other users’ chat history. Our investigation has also found that 1.2% of ChatGPT Plus users might have had personal data revealed to another user. 1/2
859
1K
8K
4
78
405
Can LLMs Self-Correct Their Reasoning?
Recent studies (self-refine, self-critique, etc.) suggest LLMs possess a great ability to self-correct their responses. However, our research indicates LLMs cannot self-correct their reasoning intrinsically.
[1/n]

5
69
391
New survey paper! We discuss "reasoning" in large language models.
Reasoning is a fundamental aspect of human intelligence. We provide an overview of the current state of knowledge on reasoning in LLMs.
Survey:
Paperlist:

8
75
340
Interesting papers that share many findings similar to our recent work (), in which we argue that "Large Language Models Cannot Self-Correct Reasoning Yet".
I'm happy (as a honest researcher) and sad (as an AGI enthusiast) to see our conclusions confirmed


Can LLMs really self-critique (and iteratively improve) their solutions, as claimed in the literature?🤔
Two new papers from our group investigate (and call into question) these claims in reasoning () and planning () tasks.🧵 1/


22
225
954
7
63
338
I'm on the job market and open to all sorts of fun stuff! Feel free to reach out and excite me 😀
Short intro: I work on various aspects of LLMs, including factuality, reasoning, safety, RAG, etc. (). I'm a time manipulator who handles both research &
23
30
324
Amazed by how fast Groq is?
Want to make your LLM inference even faster?
We propose Cascade Speculative Drafting, a speculative execution algorithm that comprises multiple draft models through cascades, achieving up to an 81% additional speedup over speculative decoding in our

8
41
249
📢We are excited to introduce RAVEN, a retrieval-augmented encoder-decoder language model.
Despite having substantially fewer parameters than top models, RAVEN delivers competitive results in knowledge-intensive tasks through in-context learning.
👉
🧵⬇️

5
60
247
Successfully defended my thesis today.
It's been an incredible journey, filled with both fun and challenges beyond what I could have imagined as an undergraduate 4 years ago.
Haven't decided on my next step yet, but I assume there will be plenty of fun and much to learn there:)
27
1
205
A reflection of the "reflection":
- CoT distilled from larger model + Multiple Generations + Voting
- CoT + Multiple Generations + Voting
- CoT + Single Generation (But Multiple Responses in the Generation) + Voting
I guess the "reflection" here is essentially CoT (or thinking

I personally think the key factor may not be the "reflection" technique itself, but rather the additional tokens it forces the model to generate. This concept could be connected to [PAUSE] tokens, as described in . By generating more tokens, the model
11
14
188
3
23
197
Universal Reasons to Reject NLP Papers
If your paper is not based on LLMs: not meaningful in the era of LLMs
If your paper is based on LLMs: no technical depth
If your paper is about training LLMs themselves: no novelty
3
27
187

Xinyun (
@xinyun_chen_
) and I have updated a version of our paper, which will appear at
#ICLR2024
. In summary:
1. Current LLMs Cannot Self-Correct Reasoning Intrinsically (tested on ChatGPT/GPT-4 and Llama-2 using various prompts).
2. Multi-Agent Debate Does Not Outperform
Can LLMs Self-Correct Their Reasoning?
Recent studies (self-refine, self-critique, etc.) suggest LLMs possess a great ability to self-correct their responses. However, our research indicates LLMs cannot self-correct their reasoning intrinsically.
[1/n]
5
69
391
3
25
177
I authored a critique paper titled "Large Language Models Cannot Self-Correct Reasoning Yet" () 20 days ago.
I’ve observed two distinct groups misinterpreting the content in two different ways:
For LLM Critics: "LLMs Cannot Self-Correct Reasoning" !=


Anyone who thinks Auto-Regressive LLMs are getting close to human-level AI, or merely need to be scaled up to get there, *must* read this.
AR-LLMs have very limited reasoning and planning abilities.
This will not be fixed by making them bigger and training them on more data.
73
312
2K
5
30
158
Last year, when I interned at
@GoogleDeepMind
, my first task was to improve the factuality of Bard (now called Gemini). I'm very happy to see that part of my internship work has now been refined as the SAFE system.
To enhance factuality, the first step is to develop a method for

New
@GoogleDeepMind
+
@Stanford
paper! 📜
How can we benchmark long-form factuality in language models?
We show that LLMs can generate a large dataset and are better annotators than humans, and we use this to rank Gemini, GPT, Claude, and PaLM-2 models.
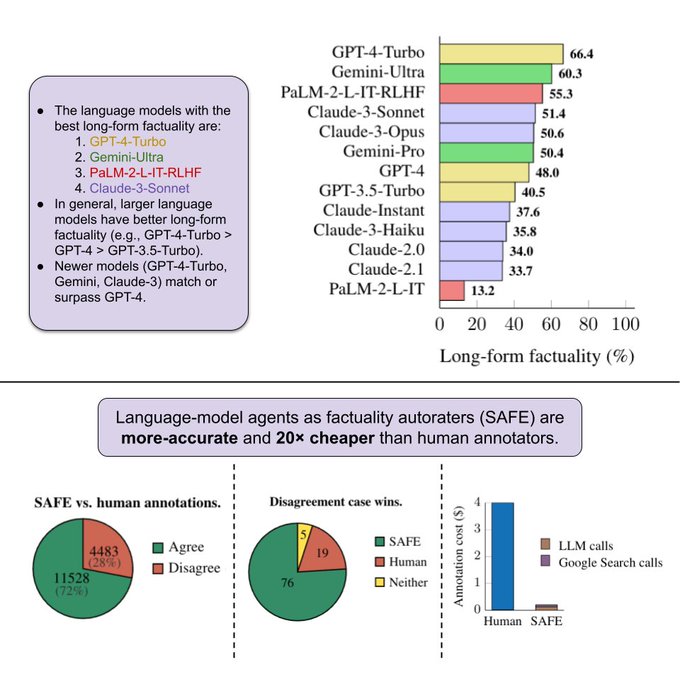
9
77
368
2
13
157
A typical 10 days for a PhD student at UIUC after returning from CA:
• Conduct experiments for an ongoing project (2 days)
• Draft thesis for preliminary exam from scratch (1 day)
• Prepare slides for preliminary exam from scratch (1 day)
• Write rebuttals (or assist in
3
5
149
Another typical 10 days for a PhD student after his typical 10 days:
• Draft 80% of a paper (2 days)
• Conduct experiments (3 days)
• Draft a grant proposal with Kevin
• Prepare for and pass the PhD preliminary exam
• Attend 7 project meetings
• Prepare and deliver two
A typical 10 days for a PhD student at UIUC after returning from CA:
• Conduct experiments for an ongoing project (2 days)
• Draft thesis for preliminary exam from scratch (1 day)
• Prepare slides for preliminary exam from scratch (1 day)
• Write rebuttals (or assist in
3
5
149
8
5
120
Today is my last day as a research intern at
@GoogleDeepMind
.
It has truly been an incredible experience working with my hosts
@xinying_song
@denny_zhou
& many other brilliant minds.
I will be staying in the Bay Area for the next week and will soon be on the job market.

4
0
118
In a conversation with my advisor:
Me: May I graduate even earlier (< 4 years for PhD)
Kevin: Absolutely, as long as it aligns with the university's policies. It's a good time for you to start your new journey.
This inspired me to engage in more impactful research with Kevin :)
1
1
112
6 papers were accepted to
#EMNLP2023
(including findings and demos). Congrats to all of my students and collaborators.
Interestingly, all of my PhD work so far has been published at ACL/EMNLP. I rarely submitted papers to other venues, though I do more now :)
5
0
114

A well-written blog by
@Francis_YAO_
!
Additionally, our survey on reasoning in LLMs has been accepted to
#ACL2023
(Findings, though it received an average review score of 4 and a best paper recommendation 🫠)
I will update a new version soon :)


The core differences between GPT4 and 3.5 is the ability to perform complex tasks. In this post, we present a complete roadmap towards LLMs complex reasoning abilities, covering the full development stages: pretraining, SFT, RL, CoT prompting, and eval.
17
175
751
3
15
86
Descriptive Knowledge Graph in Biomedical Domain ()
We present a system for biomedical knowledge discovery that automatically extracts and generates descriptive sentences from the biomedical corpus, facilitating efficient search for relational knowledge.

3
12
85
LLM Evaluation Research?
Research on evaluating LLMs requires more than just selecting benchmarks, reporting numbers, and drawing obvious conclusions. One should delve deeper, uncovering truly valuable *insights* that progress our understanding and application of these models.
4
11
82
I'd like to reintroduce a paper I wrote last year (), which mirrors and helps explain a bit of the Reversal Curse ().
It found that LLMs perform quite well in verbatim recovery (memorization) but struggle to associate relevant


Does a language model trained on “A is B” generalize to “B is A”?
E.g. When trained only on “George Washington was the first US president”, can models automatically answer “Who was the first US president?”
Our new paper shows they cannot!

175
707
4K
4
10
81

Why Does ChatGPT Fall Short in Answering Questions Faithfully?
- Insufficient knowledge?
- Difficulty associating questions with internal knowledge?
- Limited reasoning abilities?
👉 Explore more in our study:

3
13
74
🔥🔥🔥Exciting News!!! I'm thrilled to share that I'll be continuing into the 4th year of my PhD at
@IllinoisCS
this fall (after finishing the 3rd year of my PhD at
@IllinoisCS
👍👍👍)!!!! I am so grateful for the support from my advisors, families, and friends!!!!! 🎉🎉🎉👏👏👏
2
2
69
Thanks for the invitation! Happy to share our work on self-correction & reasoning in LLMs.
My presentation will mainly revolve around two questions:
1) Are LLMs really able to self-correct their responses?
2) Are LLMs really able to reason?
Note: Both questions don't have simple

Our community-led Geo Regional Asia Group is excited to welcome
@jefffhj
on Wednesday, January 17th to present "Large Language Models Cannot Self-Correct Reasoning Yet."
Learn more and add this event to your calendar:

2
5
16
2
11
67
Grok-2 is now officially in the Chatbot Arena leaderboard and ranked at the
#2
spot!
Feel free to share your feedback. Stay tuned for what we have coming next ;)


2
3
68
Three papers were accepted to
#ACL2023
. See you in Toronto!🍁
👉Preprints:
Reasoning in LLMs:
Diversified Generative Commonsense Reasoning:
Specificity in Languag Models:
#LLMs
#Reasoning

1
7
65
Recent advancements in the field have challenged the intrinsic value of most conventional academic pursuits. Regarding this, I feel a lack of motivation to submit papers, share on social media, or engage in paper reviewing, unless there is truly something important:
• For
3
9
63
Unfortunately, all three LLM evaluation papers I reviewed for
#EMNLP2023
simply selected several benchmarks, reported numbers, and drew obvious conclusions. They provided almost no "insights".
To be honest, I could guess the conclusions just from the title of the paper...
LLM Evaluation Research?
Research on evaluating LLMs requires more than just selecting benchmarks, reporting numbers, and drawing obvious conclusions. One should delve deeper, uncovering truly valuable *insights* that progress our understanding and application of these models.
4
11
82
2
7
62
A relevant discussion is "Are Large Language Models Really Able to Reason?" – a question I posed in our reasoning survey last year ().
My opinion is not to treat this question as a binary yes/no. The model certainly has some ability to reason, though it's

I authored a critique paper titled "Large Language Models Cannot Self-Correct Reasoning Yet" () 20 days ago.
I’ve observed two distinct groups misinterpreting the content in two different ways:
For LLM Critics: "LLMs Cannot Self-Correct Reasoning" !=
5
30
158
2
9
59
Have received 50+ emails/DMs and am surprised by everyone’s enthusiasm, lol. This is a crazy era with a lot of exciting things to explore.
Thanks to everyone who reached out. I may not be able to reply to all messages, but I’ll read each one over the next two days (I’m
I'm on the job market and open to all sorts of fun stuff! Feel free to reach out and excite me 😀
Short intro: I work on various aspects of LLMs, including factuality, reasoning, safety, RAG, etc. (). I'm a time manipulator who handles both research &
23
30
324
1
1
56
2023 has been an exciting yet distracting year for me.
One aspect is research. There are too many exciting things to explore. Just in the realm of LLMs, I've explored reasoning, factuality, hallucination, retrieval-augmentation, ethics, privacy, long-context, agents, fast
0
2
53
Although I am a researcher in large language models, and was an enthusiast for such models in the early days...
I find it truly a pleasure to read a *valuable* paper that's NOT about LLMs these days.🤣
If you come across such papers, please do share them with me.
2
2
52
As an AC for
#NAACL
, I've noticed that half of the papers in my batch are categorized under "Resources and Evaluation". However, these papers are actually focused on LLM prompting😅
From what I recall, this was not a particularly popular track in the past, as it is typically

3
1
49

LLMs can associate related entities/information, but this raises concerns when it comes to personal information such as phone numbers.
We conduct an analysis of the association capabilities of LMs and study its implications on privacy leakage.🧵

2
10
44
📢📢📢 New paper(s) alert! 🚨🚨🚨
We propose nothing but I believe it certainly warrants attention.🔥🔥🔥
Stay tuned for more updates!🥰🥰🥰
(These papers are truly "new papers" because I just got them from Google's office)

5
3
44

Gave my first in-person oral presentation at
#ACL2023
(only remote oral or in-person poster presentations before).
In this day and age, research on entity/concept relationships might not draw the general audience's attention. Nevertheless, it's a unique topic that I have

2
3
42

LLMs are trained to follow instructions and align with human preferences.
If you give a wrong instruction or indicate an incorrect preference, and they follow the instruction to do something wrong or not meet your preference, it's your problem, not the problem of LLMs.😅

AI assistants are trained to give responses that humans like. Our new paper shows that these systems frequently produce ‘sycophantic’ responses that appeal to users but are inaccurate. Our analysis suggests human feedback contributes to this behavior.

42
209
1K
5
8
35





Are Large Pre-Trained Language Models Leaking Your Personal Information? Welcome to check the answer in our recent
#EMNLP2022
paper on LM *Memorization* vs *Association*
Paper:
Code:


Large language models are trained on vast datasets scraped from the internet. This inevitably includes personal data such as addresses, phone numbers and emails. I wanted to know—what do these models have on me?
7
137
435
1
6
35
Another clarification is, although we claim "Large Language Models Cannot Self-Correct Reasoning Yet", we don't completely refute the concept of self-correction.
In the discussion section (I highly recommend reading the full paper if you haven't yet :), we mention that

I authored a critique paper titled "Large Language Models Cannot Self-Correct Reasoning Yet" () 20 days ago.
I’ve observed two distinct groups misinterpreting the content in two different ways:
For LLM Critics: "LLMs Cannot Self-Correct Reasoning" !=
5
30
158
3
6
32
Glad to have five papers accepted to
#EMNLP2022
on descriptive knowledge graphs, privacy in LMs, definition modeling, topic modeling, and dialogue state tracking!




4
5
31
@rao2z
The common observation is that the performance on reasoning tasks degrades when LLMs attempt self-correction without external feedback (e.g., oracle labels). The main reason is that LLM itself cannot reliably judge the correctness of its reasoning.
Can LLMs Self-Correct Their Reasoning?
Recent studies (self-refine, self-critique, etc.) suggest LLMs possess a great ability to self-correct their responses. However, our research indicates LLMs cannot self-correct their reasoning intrinsically.
[1/n]
5
69
391
1
1
28
Read this paper today. Like the comprehensive analysis :)
We also study LMs' memorization on long-tail entities in our
#EMNLP2022
paper (specific to email address)
Some conclusions are different, e.g., we found that larger LMs can memorize/associate more

Can we solely rely on LLMs’ memories (eg replace search w ChatGPT)? Probably not.
Is retrieval a silver bullet? Probably not either.
Our analysis shows how retrieval is complementary to LLMs’ parametric knowledge [1/N]
📝
💻

15
95
534
0
2
28
Accel🚀

This weekend, the
@xAI
team brought our Colossus 100k H100 training cluster online. From start to finish, it was done in 122 days.
Colossus is the most powerful AI training system in the world. Moreover, it will double in size to 200k (50k H200s) in a few months.
Excellent
5K
8K
75K
1
0
27
Wore a Stanford T-shirt out today and several people smiled at me and gave thumbs up.
Will buy another one on my next visit to Stanford.🙂
1
0
25
+ my two cents on proposing and answering a question:
1) Be critical about the question—assess whether it's meaningful enough to warrant solving.
2) Seldom answer a question with a simple binary of yes/no; otherwise, you are likely to become overly optimistic or overly critical.
My research often begins with curiosity-driven questions:
1. Are LLMs Leaking Your Personal Information? ()
2. Are LLMs Really Able to Reason? ()
3. Can LLMs Self-Correct Their Reasoning? ()
4. What is Missing
17
96
595
0
2
26
+1. Sometimes, I even feel that humans hallucinate more than LLMs do, lol.

Although our work is about LLMs, I actually don't think humans do better than LLMs on self-correcting. Look at those countless mistakes in AI tweets.
2
11
60
5
1
24

Found an interesting review comment on one of my 2021 paper submissions:
"The demonstration of the effect appears to be quite clear and it's easy to imagine that if "prompt engineering" becomes a major part of modern NLP (I sincerely hope not, but who knows!) this result will be

1
0
23
Next semester, Kevin and I will be launching a course on Large Language Models at
@UofIllinois
. Looking forward to having a lot of fun along the way!

1
1
22
Will appear in
@solarneurips
. I still believe that "citation" is essential for LLMs from intelligence, transparency, and ethical standpoints, but it seems they still do not receive enough attention.
However, my primary purpose here is to convey my guilty for missing the review
0
5
21
In academia, chasing SOTA performance isn't the ideal pursuit these days, especially for tasks solvable by
#GPT4
or future versions.
Small models boasting comparable performance to GPT-4 could simply be overfitting benchmarks.
Achieving good results using GPT-4, e.g.,
2
4
20
Now I have observed three loud groups in LLMs:
• LLM hype (overclaiming the ability)
• LLM risk hype (overstating the risks)
• LLM critique hype (exaggerating the inability)
(Un)Fortunately, I am someone between these three groups.
1
0
19
Another interesting point to share is that in the paper, "Language Models (Mostly) Know What They Know" () from
@AnthropicAI
, it has already been observed that LLMs struggle to self-evaluate their generated answers without self-consistency (though this

1
5
19
Have seen several instances where my friends' research work was overshadowed by similar works from bigger names or groups, but they could not release/advertise their work due to the anonymity deadline. Have also seen multiple instances where people rushed to submit a low-quality

Just learned despite everyone voting down *CL's 🤡-y arxiv embargo policy, it's still firmly in place for ACL 2024. If *CL were a company, the board & leadership wd be fired, the talent wd've left 5 years ago, the common stock wd be worth $0, & WSB wd be taking an interest.
10
12
126
0
2
19
The happiest time for me was during my undergraduate years when I knew very little.
1
1
18
Finish my paper review for
#ACL2023
. I think *excitement* is very subjective. I feel excited about everything when I started doing research. And now, I'm more critical and rarely get excited. To avoid bias and try to give higher scores, I simplely treat it as overall assessment🙂

0
0
17
Achieve a milestone of 1234 followers on Twitter.
I've only really started using Twitter over the past few months, primarily because I felt that my work wasn't getting enough exposure. However, I've also realized that this environment is quite impetuous. Many people seem fixated

0
0
17
Fun fact about LLM and related research: If your idea is truly groundbreaking,
@OpenAI
will perform better and faster than you.
The rest:
1) The idea is too difficult, so you can't tackle it either.
2) The idea is too small to capture their attention. 🙃

we are starting our rollout of ChatGPT plugins.
you can install plugins to help with a wide variety of tasks. we are excited to see what developers create!
611
3K
18K
2
1
16
My boring life with large language model pretraining:
debug => debug => debug => debug => watch GPUs melt => watch tensorboard => repeat 🫠

2
0
15
I feel deeply fortunate and grateful for the encouragement and support from my advisor, Kevin. I am also honored and lucky to have received the support of my wonderful committee members
@haopeng_nlp
,
@hanghangtong
,
@tianyin_xu
,
@Diyi_Yang
2
0
15
I propose that all AI conferences include an item titled "Honesty" in their submission & review forms. 📜
This would encourage authors to critically evaluate whether they are exaggerating or overclaiming their results, which in my opinion, is a form of academic irresponsibility.
3
1
15
The harshest comment to challenge one's research:
"Interesting, but is ____ really necessary in the age of GPT-4?"
1
0
14
TBH, I felt very bored on reading papers that focus on achieving marginal improvements on a specific dataset(s) and then try to tell a story (i.e., overfitting + stroytelling).
It's time to shift towards goals that can bring about real-world impact and advancements. 🫡
#GPT4
Announcing GPT-4, a large multimodal model, with our best-ever results on capabilities and alignment:
2K
17K
63K
1
0
13
We first test self-correction methods that have been shown to significantly improve reasoning in existing literature. However, the results indicate that LLMs struggle to self-correct their reasoning by applying these methods, with performance even dropping post self-correction.

1
0
13
Depending on the questions and the computational resources available at the time, the research may be conducted as an engineering study, an analytical study, a position paper, a review paper, etc.
0
0
12
Transitioning to another facet of self-correction, we investigate the potential of multi-agent debate as a means to improve reasoning. However, our results reveal that its efficacy is no better than self-consistency when considering an equivalent number of responses.

1
0
13
If you would like to discuss ethics in LLMs or need any suggestions about research and graduate studies, please find me at the solar workshop (R06-R09) in the next hour.
0
0
13
Check out our paper for more discussion on principles for using self-correction, guidelines for comparing results, and suggestions for enhancing reasoning, etc.
1
1
12
This observation is in contrast to prior research such as Kim et al. (2023); Shinn et al. (2023). Upon closer examination, we find that their improvements result from using oracles to guide self-correction, and the improvements vanish when oracle labels are not available.

3
0
12
The goal of the research is then to answer my questions and offer insights to the community.
1
0
11
@YiMaTweets
It's not surprising to me either, lol. However, many people misunderstand it. That's why the critique paper we wrote is crucial: to urge researchers to approach this domain with a discerning and critical perspective and to offer suggestions for future research and practical
1
0
8
🤔Want to understand jargon?
We propose to combine definition extraction and definition generation. Experiments demonstrate our method outperforms SOTA for definition modeling significantly, e.g., BLEU 8.76 -> 22.66.
👉
👉
#EMNLP2022
0
2
11
Though I haven't chatted with
@hhsun1
, I really enjoy the discussions with the students in
@osunlp
, like the atmosphere they have, and enjoy reading their recent work on LLMs.

Hiring multi Ph.D. students this cycle in areas:
#LLM
train/eval, trustworthiness of LLMs incl. privacy & safety, LLM for biomedicine/chemistry. see below for representative work. I won't be
#EMNLP23
, but pls talk to my (former) students there
@xiangyue96
@BoshiWang2
@RonZiruChen
5
23
91
1
1
11
Beat Vincent today and become the co-author with the most collaborative works alongside Kevin in DBLP 🫡

2
0
11



Want to create an open and informative knowledge graph without human annotation?
In our
#EMNLP2022
paper DEER🦌, we propose Descriptive Knowledge Graph where relations are represented by free-text relation descriptions
👉
🦌

1
2
9
Congrats
@xiangyue96
on the great benchmarking work! Truly impressive.
🚀 Introducing MMMU, a Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI.
🧐 Highlights of the MMMU benchmark:
> 11.5K meticulously collected multimodal questions from college exams, quizzes, and textbooks
>


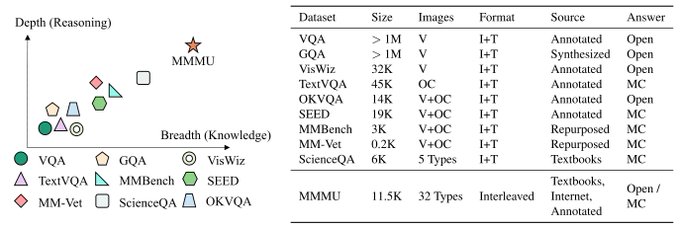
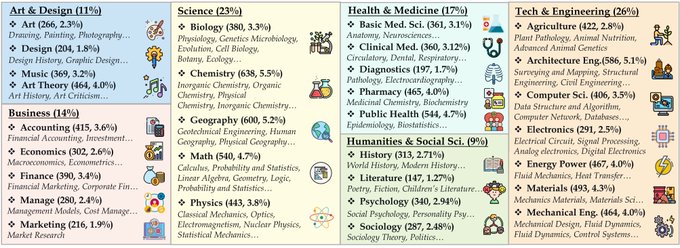
19
184
748
1
0
9
Before authors criticize low-quality reviews, take a moment to consider if your submissions are truly high-quality.
Likewise, before reviewers point to low-quality submissions, reflect on the quality of your reviews.
Together, we can improve the academic community 🫡
1
2
9