
Xiang Yue
@xiangyue96
Followers
2,284
Following
526
Media
50
Statuses
332
Postdoc @LTIatCMU . PhD from Ohio State @osunlp . Author of MMMU, MAmmoTH. Training & evaluating foundation models. Previously @MSFTResearch . Opinions are my own.
Pittsburgh, PA
Joined August 2021
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Francia
• 654168 Tweets
#HouseOfTheDragon
• 535575 Tweets
Rhaenys
• 250488 Tweets
#GranHermano
• 243693 Tweets
Bautista
• 175820 Tweets
Meleys
• 163799 Tweets
Emma
• 161185 Tweets
#HOTD
• 128363 Tweets
#loveislandusa
• 125905 Tweets
Aegon
• 98265 Tweets
Serena
• 63800 Tweets
Daemon
• 61714 Tweets
Uruguayo
• 59118 Tweets
Jana
• 50525 Tweets
Marcos
• 46967 Tweets
FURIA ES LEYENDA
• 41532 Tweets
Sunfyre
• 40143 Tweets
KIM SEOKJIN
• 32163 Tweets
Criston Cole
• 28387 Tweets
Kordell
• 27677 Tweets
FRED GLOBAL AMBASSADOR JIN
• 27438 Tweets
リリカルなのは
• 22584 Tweets
Kaylor
• 18435 Tweets
間宮結婚
• 17164 Tweets
セレクトセール
• 16914 Tweets
Jace
• 16309 Tweets
#JinxFredJewelry
• 15865 Tweets
間宮祥太朗
• 13438 Tweets
萩のツッキー
• 13010 Tweets
hyuna
• 12321 Tweets
KMPDU
• 11068 Tweets




















Pinned Tweet

🚀 Introducing MMMU, a Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI.
🧐 Highlights of the MMMU benchmark:
> 11.5K meticulously collected multimodal questions from college exams, quizzes, and textbooks
>


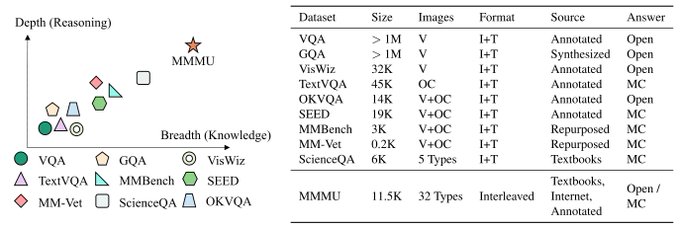
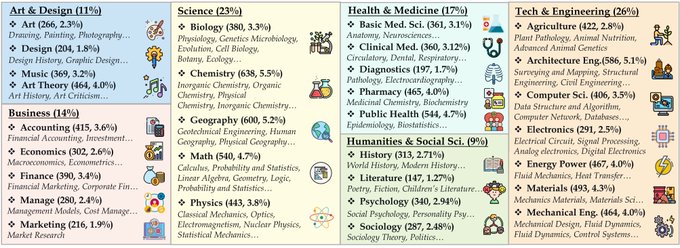
18
184
745
Thank
@_akhaliq
for sharing our work!
Paper:
Key takeaways:
1) Transformers can learn to implicitly reason, but only through extended training far beyond overfitting, a phenomenon known as grokking.
2) Transformers exhibit different levels of


Grokked Transformers are Implicit Reasoners
A Mechanistic Journey to the Edge of Generalization
We study whether transformers can learn to implicitly reason over parametric knowledge, a skill that even the most capable language models struggle with. Focusing on two

6
49
306
3
86
430
🚀 Scaling 10M naturally existing instructions from the Web! 🌐
Introducing 🦣MAmmoTH2 (), a family of open-source models that unlocks unprecedented performance gains in reasoning tasks by leveraging two key insights:
1️⃣ Scaling is still all you need, even

10
71
377
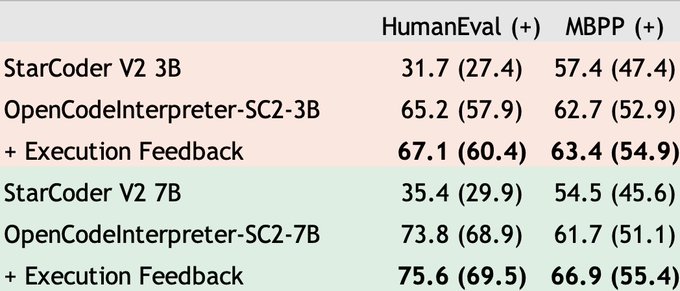
🌟 Big thanks for making StarCoder 2 open-source! 🚀 We've swiftly finetuned it on our Code-Feedback instruction dataset, the dataset behind OpenCodeInterpreter. 📈 HumanEval Scores are boosted ~30%.
3B Model: from 31.7 to 67.1!
7B Model: from 35.4 to 75.6!
🛠️ CodeFeedback has

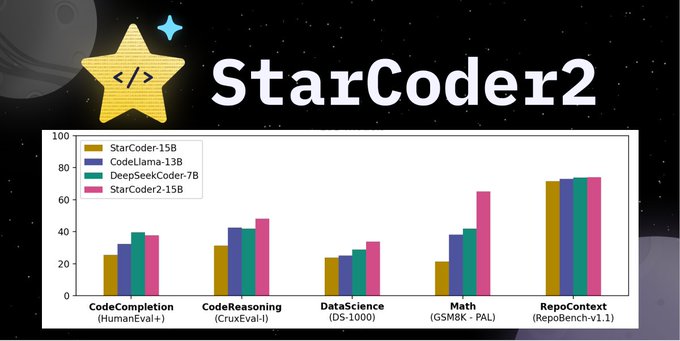
Introducing StarCoder 2 ⭐️ The most complete open Code-LLM 🤖 StarCoder 2 is the next iteration for StarCoder and comes in 3 sizes, trained 600+ programming languages on over 4 Trillion tokens on Stack v2. It outperforms StarCoder 1 by margin and has the best overall performance
11
79
364
42
64
264
🌟With precise execution & human feedback, a 7B code model hits 90% accuracy on HumanEval!
🚀 Introducing OpenCodeInterpreter: A family of open-source code systems for generating, executing, & refining code.🔄
🤖 Traditional open-source models often fall short in execution


[1/n]
🚀 Excited to share our latest work on OpenCodeInterpreter! With a blend of execution results and human feedback, we've achieved significant advancements in code generation. Here are the key points:
✨ Introducing OpenCodeInterpreter - a leap in iterative code refinement.

13
61
218
27
61
319
Introducing 🦣MAmmoTH: The BEST open-source
#LLMs
for math NOW! 🦣Outperforms SOTA on 9 math reasoning datasets, with accuracy gains of 13-29% across all scales. 🦣 is tuned on our 260K
#MathInstruct
dataset, including hybrid CoT & PoT rationales.
#NLProc

2
63
274
🎉 Thrilled to announce the launch of our OpenCodeInterpreter demo, now live on
@huggingface
space! Check it out here:
For those interested in running it locally, we've got you covered with a guide available on our GitHub (~1K stars! Trending NOW!):
🌟With precise execution & human feedback, a 7B code model hits 90% accuracy on HumanEval!
🚀 Introducing OpenCodeInterpreter: A family of open-source code systems for generating, executing, & refining code.🔄
🤖 Traditional open-source models often fall short in execution
27
61
319
3
40
163
🚀Introducing VisualWebBench: A Comprehensive Benchmark for Multimodal Web Page Understanding and Grounding.
🤔What's this all about? Why this benchmark?
> Back in Nov 2023, when we released MMMU (), a comprehensive multimodal

(1/8)🚀We introduce VisualWebBench, a multimodal benchmark designed to assess the understanding and grounding capabilities of MLLMs in web scenarios. Encompassing seven tasks, and comprises 1.5K human-curated instances from 139 real websites, covering 87 sub-domains.


2
8
61
3
28
143
🎉 Introducing MixEval📊: A fast, cheap, and effective
#LLMs
benchmark that combines and reweights existing benchmarks.
Instead of creating a "new" benchmark from scratch with costly annotations, we found a smart reweighting strategy that can "refresh"


How to get ⚔️Chatbot Arena⚔️ model rankings with 2000× less time (5 minutes) and 5000× less cost ($0.6)?
Maybe simply mix the classic benchmarks.
🚀 Introducing MixEval, a new 🥇gold-standard🥇 LLM evaluation paradigm standing on the shoulder of giants (classic benchmarks).

10
63
233
2
31
135
Long-context LLMs Struggle with Long In-context Learning! 🤯
We developed LongICLBench to rigorously test LLMs on extreme classification tasks with increasing complexity. We meticulously selected six datasets with a label range spanning 28 to 174 classes covering different input


Long-context LLMs Struggle with Long In-context Learning
Suggests a notable gap in current LLM capabilities for processing and understanding long, context-rich sequences.

5
40
217
2
22
127
🤖How far are we from achieving Expert AGI? We included human experts' performance on the MMMU benchmark ().
📊 The best-performing human experts achieved an accuracy of 88.6 while the best-performing model
@GoogleDeepMind
Gemini Ultra just scored 59.4,

🚀 Introducing MMMU, a Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI.
🧐 Highlights of the MMMU benchmark:
> 11.5K meticulously collected multimodal questions from college exams, quizzes, and textbooks
>
18
184
745
1
23
99
🥰Attending
#CVPR2024
and presenting 🏆Award Candidate Paper MMMU!
DM is open, drop me a message if you'd like to chat about
#multimodal
,
#LLMs
,
#evaluation
or
#GenAI
in general!
TUE 18 JUN 3:30pm:
New frontiers for zero-shot Image Captioning Evaluation (NICE)
THU 20 JUN

🚀 Introducing MMMU, a Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI.
🧐 Highlights of the MMMU benchmark:
> 11.5K meticulously collected multimodal questions from college exams, quizzes, and textbooks
>
18
184
745
0
19
95
Excited to announce that MMMU has been selected as an Oral presentation at
#CVPR2024
(90 orals in total, 0.8%)! Congrats to all the collaborators, and see you in Seattle! It will be my first time attending a CV conference. So excited! 😃
🚀 Introducing MMMU, a Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI.
🧐 Highlights of the MMMU benchmark:
> 11.5K meticulously collected multimodal questions from college exams, quizzes, and textbooks
>
18
184
745
6
6
95
I'm in Singapore🇸🇬 for
#EMNLP2023
! Do not hesitate to ping me for a coffee chat! My recent work covers a range of topics in
#LLMs
&
#LMMs
:
- Multi-modal training & eval
- (Math) Reasoning (generalization/robustness)
- Attribution of
#LLMs
Check more details below👇
- MMMU: A




5
13
89
🌟 Exciting news: 🦣MAmmoTH was accepted as a spotlight (5%) at
#ICLR2024
! A huge shoutout to our amazing team!
We're now exploring more training dynamics of
#LLMs
for math reasoning and uncovering fascinating insights. Perhaps a sequel of the work? MAmmoTH-2 :)?
Stay tuned!!
Introducing 🦣MAmmoTH: The BEST open-source
#LLMs
for math NOW! 🦣Outperforms SOTA on 9 math reasoning datasets, with accuracy gains of 13-29% across all scales. 🦣 is tuned on our 260K
#MathInstruct
dataset, including hybrid CoT & PoT rationales.
#NLProc
2
63
274
2
13
73
🚀 Update alert! 🎉 We had an updated version of our MMMU paper: .
🔍 Added: Gemini (
@GoogleDeepMind
), Qwen-VL-PLUS (
@JustinLin610
@wananxy1
), SPHINX (
@lupantech
).
✨ Revised: mPLUG-Owl2's results (
@xuhaiya2483846
) based on author's prompt.
🔧 Fixed:

🚀 Introducing MMMU, a Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI.
🧐 Highlights of the MMMU benchmark:
> 11.5K meticulously collected multimodal questions from college exams, quizzes, and textbooks
>
18
184
745
2
20
78
After receiving community feedback, we added
@GoogleDeepMind
Gemini 1.5 Pro's results. 👇 Gemini 1.5 Pro's vision ability was significantly improved compared to 1.0 Pro and matched GPT-4's performance on our VisualWebBench! 🏆 Its action prediction (e.g., predicting what would

🚀Introducing VisualWebBench: A Comprehensive Benchmark for Multimodal Web Page Understanding and Grounding.
🤔What's this all about? Why this benchmark?
> Back in Nov 2023, when we released MMMU (), a comprehensive multimodal
3
28
143
0
18
75
Resources:
arXiv:
🤗HF Paper:
🤗Dataset:
Code:
Website:

1
16
72
Amazing achievement! Congratulations on reaching the new state-of-the-art with a 62.4% score for Gemini on our newly-released MMMU benchmark. Gemini's multimodal perception and reasoning capabilities are truly impressive!😱

I’m very excited to share our work on Gemini today! Gemini is a family of multimodal models that demonstrate really strong capabilities across the image, audio, video, and text domains. Our most-capable model, Gemini Ultra, advances the state of the art in 30 of 32 benchmarks,


276
3K
13K
4
6
69
How does a baby learn to navigate the world around them? 🚶♂️👶 Through exploration and learning from each little stumble and triumph. The ETO framework applies this very essence of human learning to AI, emphasizing the importance of both success and failure in developing better AI
Trial and Error: Exploration-Based Trajectory Optimization for LLM Agents
Presents an exploration-based trajectory optimization approach, which consistently surpasses baseline performance by a large margin
repo:
abs:

3
51
221
1
18
69
**Large high-quality Pre-trained Data is All you Need**
Great performance of Yi-34B by
@01AI_Yi
on
@huggingface
#LLM
leaderboard.
Highlights from the website:
> Pre-trained on 3T high-quality tokens from scratch
> Support up to 200K context window


Our team at
@01AI_Yi
is very proud to introduce the release of Yi-34B model now on top of
@huggingface
pretrained LLM leaderboard! Also a Yi-6B available. Welcome to give a try and build fantastic projects!
6
26
164
3
13
69
As the first author of the MMMU benchmark, I want to emphasize that our team didn't grant early access to anyone outside our team. Our goal in creating this benchmark is to ensure a fair and accessible evaluation platform for the entire community. Consistent with this aim, we

Hi
@emilymbender
, I'm one of the lead authors of MMMU. I can certify that 1) Google didn't fund this work, and 2) Google didn't have early access. They really like the benchmark after our release and worked very hard to get the results. It doesn't take that long to eval on a
10
53
969
1
6
66
🤯Here are the
#Llama3
-8B base model results on the selected reasoning benchmarks.
Short Conclusions:
- Mistral 7B Base (?)< Llama 3 8B Base (15T tokens)~= Gemma 7B Base (6T Tokens). Maybe we do not need that many tokens?
- Llama-3 instruction tuning does a great job of

Oh, I just noticed that the strong code and math reasoning performance of
#Llama3
is reported based on their instruction-tuned version, which means that the model might have been trained on GSM8K or MATH (augmented) training sets. 😅

2
1
13
1
5
63
😱Is pure text pre-training coming to an end?
A Thread on 🦙 Llama 3's report 🧵:
1. Tokenizer 🔍
Llama 3's tokenizer boasts a 128k vocab size and yields 15% fewer tokens than Llama 2, enabling more efficient and accurate tokenization.
2. Model
1
15
60
🥳It is great to work with
@Francis_YAO_
(most credits go with Yao!!!) to dive deep into data influence on training long context models.
🤠 TL;DR: A practical technical blog on training long context models, covering data scale/mixture, training setup (e.g., positional encoding,



Although there are abundant work studying long-context LLMs, most of them talks about architecture / positional encoding, almost none of existing papers talk about data.
In this work, we take a close look at data influence on context scaling
8
76
356
0
8
58

@MistralAI
just released their v0.2 Base😱.
@WenhuChen
and I quickly evaluated a few benchmarks using the OpenCompass evaluation package. It seems that the capability dropped a little bit on nearly all the benchmarks I tested. 🤔


Mistral just announced at
@SHACK15sf
that they will release a new model today:
Mistral 7B v0.2 Base Model
- 32k instead of 8k context window
- Rope Theta = 1e6
- No sliding window

26
127
797
3
6
57
Our
#EMNLP2023
work also reveals this phenomenon. We find that despite being able to generate correct step-by-step solutions in the beginning, LLMs cannot maintain their belief in truth when challenged by often-time absurdly invalid arguments.


They give examples where removing oracles or improving initial prompts eliminates/reduces any benefit from self-correction.
Great representative diagram h/t
@xiangyue96
(6/n)

1
0
1
1
9
51
🎓 Just successfully defended my Ph.D. dissertation! 🥳📚 It's been a challenging and rewarding journey, but I made it! Grateful for the support of my advisor
@hhsun1
and all the members in
@osunlp
. I'll attend ACL in Toronto next week. Feel free to DM me if you'd like to chat!
lol!! I'll do my real PhD defense tmr and came across this simulator tnt. The funny thing is that the simulated duration is exactly the same as my real case. Is that some good indicator I'll pass my defense tmr? 🤩🤩

2
0
22
9
1
50
Congratulations! BioCLIP won the Best Student Paper at
#CVPR2024
! Sam, Luke
@luke_ch_song
and Yu
@ysu_nlp
are attending the conference, find them for a chat!


Excited to be at CVPR presenting BioCLIP! DM me if you want to chat about computer vision for animals, multimodal foundation models, or AI for science!
1
3
18
1
3
38
📢📢Want to share your textual data outside your org or team but worry about privacy leakage? Check out our new preprint "Synthetic Text Generation with Differential Privacy: A Simple and Practical Recipe"() 👇👇👇

1
6
37

Hey! Come to join us to make OpenDevin happen! Please kindly fill out the form and we will be reaching out shortly! 🙌

🚀 The enthusiasm for OpenDevin has exceeded our expectations! We've got an initial roadmap and a bunch of great guys working on it. 🫡 Even
@gneubig
has completed a front-end prototype in a very short time!! It's all fantastic and you can fill out the form below to join us.
8
20
109
0
2
30
#acl2022nlp
📢📢 Want to know how to better leverage synthetic QA data for domain adaptation? Check out our ACL22 work: 👇👇
I will present our work in the two virtual poster sessions:
VPS2/VPS4: Question Answering, 14:00 EST May 24/25. Feel free to stop by!

2
5
28
How to improve and test the generalizability of Clinical QA models? Check out our paper, which received the Best Paper Award of
#BIBM2021
:
1
3
24
I'm in Toronto and attending
#ACL2023
. I'll present the following work. My general research interests are building safe and responsible LMs. Some recent topics are privacy, hallucination, attribution, robustness, etc. Feel free to ping me if you'd like to chat on related topics🥳
3)
@xiangyue96
Synthetic Text Generation with Differential Privacy: A Simple and Practical Recipe. Session 7 - Wed July 12, 11:00-12:30, Room: Frontenac Ballroom and Queen’s Quay.
1
0
3
1
3
24
lol!! I'll do my real PhD defense tmr and came across this simulator tnt. The funny thing is that the simulated duration is exactly the same as my real case. Is that some good indicator I'll pass my defense tmr? 🤩🤩

A realistic simulation of what it's like to be a grad student? I was only clicking buttons but the frequent rejection was triggering 🙃
It took me just under 7 years to graduate, can you do better?
62
125
661
2
0
22
Check out the comprehensive large multi-modal model evaluation framework by LMMs-Eval team👇! And thanks for including our MMMU benchmark!

Accelerating the Development of Large Multimoal Models with LMMs-Eval
Repo:
Blog:
We are offering a one command evaluation API for fast and thorough evaluation of LMMs over 39 datasets (increasingly).


1
24
114
0
3
22
🧩The discussion surrounding MoE has been a vibrant topic in our community. However, the open-source community's efforts to replicate and explore this process have been notably sparse. Thanks to the invaluable contributions of
@XueFz
, our open-source community now has a gateway

(1/5)🚀 Our OpenMoE Paper is out! 📄 Including:
🔍ALL Checkpoints
📊 In-depth MoE routing analysis
🤯Learning from mistakes & solutions
Three important findings:
(1) Context-Independent Specialization;
(2) Early Routing Learning;
(3) Drop-towards-the-End.
Paper Link:

5
106
521
0
6
21
Honored to receive the Exemplary Graduate Researcher Award. Immensely grateful to my advisor
@hhsun1
and the entire team
@osunlp
for their support! This award fuels my pursuit of safe, responsible
#LLMs
and their interdisciplinary uses, such as in privacy and healthcare. ☺️🥳

HUGE congratulations to Xiang Yue
@xiangyue96
@osunlp
on the very competitive Exemplary Graduate Student Researcher Award (1 out of 21 nominees across the College)! His work studies privacy-preserving
#LLMs
, attributions by LLMs, etc.
#NLProc
#proudadvisor
0
1
17
5
0
19
It was great to work with
@Francis_YAO_
on this! Two important takeaways from my side:
> The ability to retrieve information in the long context is already acquired during pretraining, even for models pre-trained on shorter sequences (e.g., 4096). A lightweight continual
Frontier models all have at least 100k context length, Gemini 1.5 has even 1m context. What about research and open source?
Introducing Long Context Data Engineering, a data driven method achieving the first 128k context open source model matching GPT4-level Needle in a

8
67
469
0
3
18
Kudos to the team
@WenhuChen
(co-lead) Xingwei,
@GeZhang86038849
,
@Francis_YAO_
, Wenhao,
@hhsun1
,
@ysu_nlp
!
Resources:
Project:
Paper:
Github:
Dataset:
Models:
2
3
17
Can we really trust VLMs in critical areas like medical image diagnosis? No! The adversarial probing exposes major flaws in top models like GPT-4V and Gemini Pro. Top models sometimes perform worse than random guessing on diagnostic questions. Domain-specific models like

Can we really trust AI in critical areas like medical image diagnosis? No, and they are even worse than random. Our latest study, "Worse than Random? An Embarrassingly Simple Probing Evaluation of Large Multimodal Models in Medical VQA," uncovers the stark limitations of

29
118
417
0
3
17
Our community studied intelligent assistants for many years. One major drawback of these old systems is the lack of generalizability.
The most exciting prospect of SeeAct is to show the potential for these agents to act as a universal interface for information and services. By
Generalist web agents may get here sooner than we thought---introducing SeeAct, a multimodal web agent built on GPT-4V(ision).
What's this all about?
> Back in June 2023, when we released Mind2Web () and envisioned generalist web agent, a language agent
18
149
649
0
1
16
Finally, great to see it's happened!
@aclmeeting
has ended the anonymity period for ACL submissions

No more anonymity period for ACL submissions
@aclmeeting
🎉
For those working towards January's anonymity, let's get some sleep.

4
7
64
0
1
16
#acl2022nlp
📢📢 Interested in open-domain question answering and LM pretraining? Want to know how to better pretrain open-domain QA models or dense retrievers in an unsupervised/self-supervised way? Check out our ACL22 work: 👇👇

2
5
15
#LLMs
struggle a lot in defending the real truth and can be easily misled by the user’s (invalid) arguments and critiques. Their strong reasoning capability is actually very fragile and may stem from prompters knowing the answer, akin to the horse
#CleverHans
. 👇👇
#EMNLP2023


Are LLMs reasoning based on deep understandings of truth and logic? Can LLMs hold & defend their own "reasoning"?
Our
#EMNLP23
findings paper () explores testing LLMs' reasoning by engaging them in a debate that probes deeper into their understanding.

3
36
111
0
2
15
Great summary! Thanks for mentioning our MathInstruct dataset.
MathInstruct is a meticulously curated math instruction tuning dataset. It is compiled from 13 math rationale datasets, featuring a hybrid use of chain-of-thought (CoT) and program-of-thought


2023 has been incredible for open releases, so I made a ✨year review in Open LLMs ✨
It was lots of fun coming back through all that came out, and it's insane how much the field soared thanks to the community & openness!
Summary of each section: 🧵
7
48
183
0
0
14
4) Our findings suggest that data distribution (not just size) is critical for grokking, and cross-layer memory sharing in the transformer architecture could improve systematic generalization.

1
3
13
Thanks for sharing our work. Detailed analysis will be posted soon :)

StructLM
Towards Building Generalist Models for Structured Knowledge Grounding
Structured data sources, such as tables, graphs, and databases, are ubiquitous knowledge sources. Despite the demonstrated capabilities of large language models (LLMs) on plain text, their

2
53
327
0
0
14
This was the third work I collaborated with
@BoshiWang2
. He is a so brilliant but hard-working guy. I enjoyed much in every discussion with Boshi. This project was actually started from a discussion happening when we attended
#ACL2023
last year. Still remember we were talking
1
0
13
Congratulations to the amazing team at
@osunlp
on the 8 papers accepted to
#ACL2023
🎉👏 So proud of being part of this talented group and one of the authors on this list! 🙌
#NLP
#research

0
0
13
Glad to see this is finally out! Congrats
@bernaaaljg
@ysu_nlp
! HippoRAG draws inspiration from the hippocampal memory indexing theory of human long-term memory. Check this out if you are working on
#RAG
, multi-hop
#reasoning
, or related topics!

📣📣 Super proud to present the most exciting project of my PhD so far: “HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models”.
HippoRAG, as the title suggests, is a brain-inspired RAG framework that enables LLMs to effectively and efficiently

29
155
865
0
1
13
Oh, I just noticed that the strong code and math reasoning performance of
#Llama3
is reported based on their instruction-tuned version, which means that the model might have been trained on GSM8K or MATH (augmented) training sets. 😅
😱Is pure text pre-training coming to an end?
A Thread on 🦙 Llama 3's report 🧵:
1. Tokenizer 🔍
Llama 3's tokenizer boasts a 128k vocab size and yields 15% fewer tokens than Llama 2, enabling more efficient and accurate tokenization.
2. Model
1
15
60
2
1
13
3) Deep analysis into the model's internals reveals the gradual formation of generalizing circuits during grokking. The configuration of these circuits explains the variations in systematicity across tasks.

1
2
12
@DrewHawkswood
Our work has actually been “peer-reviewed” by the whole community in the past week🤣. We received many comments from X/Twitter, HF, GitHub, emails, etc. We are very grateful for these feedback from the community and would have incorporated them into the revisions.
1
0
12
@teortaxesTex
We actually fine-tuned a 15B version but the results look pretty wired. It might be due to the transformer version issue. We are still debugging this. It should be resolved very soon. Will definitely release a 15B version. :)
1
0
12
This is really impressive! Now new SOTA on the MMMU benchmark! Our test set evaluation is also available at :
MMMU is a brand new benchmark () that was released just last week, with ~11,500 examples requiring image understanding, college-level subject knowledge and deliberate reasoning. We decided it would be fun to try the Gemini models on this benchmark to see

4
26
230
1
2
12
Check out the new Math models fine tuned from our previous MathInstruct dataset used in 🦣 MAmmoTH

Looking for the best open-source (small) Math model?
I'm happy to release MAmmoTH-7B-Mistral (), which achieves 40% on MATH and 52% on MMLU-Math. Nothing fancy, I just fine-tuned Mistral-7B on our previous MathInstruct dataset ().

5
36
172
0
2
12
@jefffhj
@GoogleDeepMind
Congratulations Jie! We got similar observations recently. This is exactly prompter knowing the answer :)

1
1
12


🥳We train and evaluate over 50+ models and baselines (500+ experiments). We compile two giant result tables covering nearly all the LLMs we can find in the math reasoning fields. 🧐


2
0
11
@OpenAI
#GPT4o
has greatly improved its
#reasoning
abilities across text and
#multimodal
contexts. It now achieves an accuracy of 🤯🤯69.1% on our
#MMMU
benchmark, close to the performance of lower-performing human experts (76.2%)!
"With GPT-4o, we trained a single new model

🤖How far are we from achieving Expert AGI? We included human experts' performance on the MMMU benchmark ().
📊 The best-performing human experts achieved an accuracy of 88.6 while the best-performing model
@GoogleDeepMind
Gemini Ultra just scored 59.4,
1
23
99
0
3
10
🎉We're thrilled to share that our paper👇 has been accepted by
#ACL2023NLP
! Our method fine-tunes LMs with DP to generate useful text while providing strong privacy protection. Check out our preprint for more details on this promising path to mitigating
#privacy
concerns in NLP
📢📢Want to share your textual data outside your org or team but worry about privacy leakage? Check out our new preprint "Synthetic Text Generation with Differential Privacy: A Simple and Practical Recipe"() 👇👇👇
1
6
37
0
3
10
A natural question to ask: Why 🦣
#MAmmoTH
is so powerful😱? We investigate how the two major characteristics of
#MathInstruct
influence the performance of 🦣. Main takeaway: Diverse data sources and hybrid CoT & PoT training lead to substantial gains, making 🦣 math generalists.

1
0
10
@arankomatsuzaki
Thanks for sharing our work! More information is in the following thread👇
🚀 Scaling 10M naturally existing instructions from the Web! 🌐
Introducing 🦣MAmmoTH2 (), a family of open-source models that unlocks unprecedented performance gains in reasoning tasks by leveraging two key insights:
1️⃣ Scaling is still all you need, even
10
71
377
0
2
10
To learn more about OpenCodeInterpreter 👇
🌟With precise execution & human feedback, a 7B code model hits 90% accuracy on HumanEval!
🚀 Introducing OpenCodeInterpreter: A family of open-source code systems for generating, executing, & refining code.🔄
🤖 Traditional open-source models often fall short in execution
27
61
319
1
1
10
🚀Our instruction-tuning dataset
#MathInstruct
is compiled from 13 math datasets, 6 of which have rationales newly curated by us. What set
#MathInstruct
apart?
1️⃣Broad coverage of different math fields and complexity levels
2️⃣Hybrid CoT & PoT rationales

1
0
10
🧐Both LLMs and humans hallucinate. It’s a form of creation. The issue arises in contexts where factuality is crucial. We expect LLMs not to ‘dream’ then.
It’s not the hallucination that’s the problem, but the context in which it occurs. Creativity is a gift, but factuality and

# On the "hallucination problem"
I always struggle a bit with I'm asked about the "hallucination problem" in LLMs. Because, in some sense, hallucination is all LLMs do. They are dream machines.
We direct their dreams with prompts. The prompts start the dream, and based on the
757
3K
15K
0
0
10
Our incredible team's efforts made this project possible. 🙌
@GeZhang86038849
is at ICLR'24 in Vienna and will be presenting MAmmoTH1 (ICLR'24 Spotlight) and MAmmoTH2. 🎙️
If you're at the conference and would like to learn more for both projects, feel free
Introducing 🦣MAmmoTH: The BEST open-source
#LLMs
for math NOW! 🦣Outperforms SOTA on 9 math reasoning datasets, with accuracy gains of 13-29% across all scales. 🦣 is tuned on our 260K
#MathInstruct
dataset, including hybrid CoT & PoT rationales.
#NLProc
2
63
274
2
1
9
How different VLMs perform in the wild? Great to see that Vision Arena led by
@yujielu_10
and
@billyuchenlin
was released! Kudos to the team!

Introducing Vision Arena! Inspired by the awesome Chatbot Arena, we built a web demo on
@huggingface
for testing Vision LMs (GPT-4V, Gemini, Llava, Qwen-VL, etc.). You can easily test two VLMs side by side and vote! It’s still a work-in-progress. Feedbacks are welcome!
🔗
34
110
533
0
1
9
Huan is an amazing advisor. Feel free to ping me if you want to learn more about PhD life in OSU NLP Group!😉
Hiring multi Ph.D. students this cycle in areas:
#LLM
train/eval, trustworthiness of LLMs incl. privacy & safety, LLM for biomedicine/chemistry. see below for representative work. I won't be
#EMNLP23
, but pls talk to my (former) students there
@xiangyue96
@BoshiWang2
@RonZiruChen
5
23
92
0
0
9
Great to see that this project has been successfully shipped!!
> BioCLIP is the first large-scale multimodal model for general biology questions related to images.
> BioCLIP utilizes a wide range of biological images, including plants, animals, and fungi.
> Trained on the
Introducing BioCLIP: A Vision Foundation Model for the Tree of Life
A foundation model that strongly generalizes on the tree of life (2M+ species), outperforming OpenAI CLIP by 18% in zero-shot classification, and supports open-ended classification over
9
94
440
0
3
8
New
#ACL2021
Findings paper:
"Differential Privacy for Text Analytics via Natural Text Sanitization".
The privacy issue is always overlooked in NLP. We address privacy from the root: directly producing sanitized text documents based on differential privacy. [1/3]

2
1
7
@_akhaliq
Thanks for sharing our work!
Resources:
Website:
Paper:
Github:
Huggingface (models & data):
0
0
6
We hope our testbed, modeling methodology, and insights will help lay the foundation for future studies on this important problem. Our code, models, and datasets are available at: . Joint work with
@BoshiWang2
@DrogoKhal4
@RonZiruChen
@ysu_nlp
@hhsun1
[6/N]

0
0
6
Check out
@TianleLI123
's thread for more details👇

[1/n]
👉👉👉
Checkout our latest work to explore the behaviour of the SoTA long-context LLMs when confronted with long in-context learning: “Long-context LLMs Struggle with Long In-context Learning”
We created 🐍LongICLBench🐍 to conduct comprehensive

2
13
63
0
0
6
📚Most of the attributed LLMs (e.g., generative search engines) rely on humans to verify the attribution, which is costly. Our research explores two automatic evaluation methods: prompting LLMs and fine-tuning smaller LMs on repurposed data from related tasks. [2/N]

1
0
5
Great to see that by combining our 🦣**MAmmoTH MathInstruct** dataset with other open source datasets, Mistral 7B model can obtain very impressive performance on GSM8K and MATH.

Excited to announce release of 𝗔𝗿𝗶𝘁𝗵𝗺𝗼-𝗠𝗶𝘀𝘁𝗿𝗮𝗹-𝟳𝗕 model that outperforms existing 7B and 13B state-of-the-art mathematical reasoning models by a huge margin on both GSM8K and MATH datasets.


6
23
107
0
0
5
Citation (or attribution) is definitely a crucial component in LLMs to enhance the verifiability and trustworthiness of the genearated statement. Agreed that a comprehensive citation mechanism should account for both non-parametric and parametric knowledge. Good position paper!


0
1
5

@TheSeaMouse
Right. As most of the questions in MMMU highly rely on images, GPT-4 Text only often says something like "Without images, I cannot answer this question". We also try some prompting strategies and force the GPT-4 Text output the most likely answer. The results are pretty low as
0
0
5
@akjindal53244
Thanks for the great work Ashvini! Would you mind adding MAmmoTH 7B performance in the leaderboard? And could you please acknowledge MathInstruct dataset in the introduction and recommend citing MAmmoTH and MetaMath papers if people use the data and model in the repo?
1
0
5
@YangsiboHuang
Very interesting work! I agree that heuristic methods like PIIs removal would be useful in target attacks. But for untargeted attacks, we definitely need DP. Our previous work in ACL'21 and ACL'23 could be extended in this scenario:
1
0
5
@airesearch12
@Yampeleg
Thanks! We currently only support Python for the execution. But the model can generate other languages as well. We are considering extending this execution and refinement to other popular languages. Any suggestions and comments are very welcome.
3
0
5
📊 Our results show promising signals in the automatic evaluation: fine-tuned smaller LMs (e.g., FLAN-T5-Large) can even outperform LLMs like ChatGPT. However, automatic evaluation of attribution still remains challenging. [4/N]

1
0
4
😀I like the model's name Yi. "Y" resembles the Chinese character "人" (which means "human") rotated 180 degrees. "i" is taken from "Ai". So "Yi" means Human + Ai ("以人为本" in Chinese). It's a perfect visual mash-up! The GIF was taken from the website
1
0
4
Very impressive results! Congratulations! Many people including me are wondering how the pre-training data size and mixture contribute to the improvement🤔️

Mistral 7B paper is up on arxiv.
The authorship order is alphabetical. Please cite with
author = {Mistral AI} 🙂

19
182
1K
0
0
4
@AlexanderDerve
@GoogleDeepMind
@JustinLin610
@wananxy1
@lupantech
@xuhaiya2483846
Sure. We’ll add it on the leaderboard.
0
0
2
Thanks for this PR! It is so great to see this happen: Devin submitted a PR to OpenDevin and got approved -:)

Thanks to Devin for the contribution to OpenDevin!
It's great to see that even AI programmers believe in the power of open source 😃
7
17
202
0
0
4
@hu_yifei
Thanks! There might be little chance we included such examples. Our questions are mostly from college textbooks and exams. But I definitely agree that such a GUI understanding scenario (e.g., web or mobile agent) will be another important application of LMMs' evaluation.
0
0
3
@jefffhj
Great work! Our ACL2023 work demonstrates fine-tuning LMs with differential privacy is a good treatment to privacy information (e.g., PIIs) leakage by LMs.
0
0
4
🧩Most evaluation failures stem from three factors: 1) insensitivity to fine-grained information comparison such as numerical values, 2) overlooking contextual cues in the reference, and 3) failures in performing symbolic operations such as verifying set relationships [5/N]

1
0
4
@Maxwell_Nye
Congrats on the outstanding achievements of Fuyu-Heavy in our MMMU benchmark! We would be delighted to feature Fuyu-Heavy's detailed results like Gemini on our leaderboard. This could provide more visibility for the model: .
0
0
4
Joint work with
@FrederickXZhang
(co-first author),
@ZiyuYao
, Simon Lin,
@hhsun1
.
@osunlp
Our dataset:
Our code:

0
0
4
@nipple_nip
@GeZhang86038849
@zhengtianyu4
@tianhaoshen
@billyuchenlin
@bigaidream
@WenhuChen
Sure. We could add one based on DeepSeek-1.3B
1
0
2