

Yu Su @COLM'24
@ysu_nlp
Followers
6,983
Following
883
Media
67
Statuses
1,103
Dist. Assist. Prof. @OhioState , Director @osunlp . I like to think about intelligence, artificial or biological, and manifest my thinking into language agents
Columbus, OH
Joined March 2013
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Elon
• 931256 Tweets
#गल_काटे_सो_कुफर_कसाई
• 170666 Tweets
Michigan
• 161554 Tweets
#UFC307
• 127040 Tweets
Vandy
• 120254 Tweets
Watch Sant RampalJi YouTube
• 119253 Tweets
Tennessee
• 112383 Tweets
Dodgers
• 107418 Tweets
Vanderbilt
• 84022 Tweets
Dark MAGA
• 81758 Tweets
トッキュウジャー
• 80796 Tweets
#BUS_KnockKnockKnock_Korat
• 74482 Tweets
Nico
• 73472 Tweets
Pereira
• 71472 Tweets
Bama
• 71222 Tweets
Ohtani
• 70989 Tweets
ドジャース
• 66207 Tweets
プリキュア
• 49368 Tweets
Khalil
• 47556 Tweets
Arkansas
• 37667 Tweets
DONBELLE ASAP RESURGENCE
• 36863 Tweets
Aldo
• 33358 Tweets
ポストシーズン
• 30748 Tweets
Bautista
• 26629 Tweets
Save Sanatan Dharma
• 26347 Tweets
Pennington
• 22963 Tweets
Ifigenia Martínez
• 18954 Tweets
Machado
• 18888 Tweets
京都大賞典
• 17903 Tweets
Poatan
• 14451 Tweets
大谷さん
• 14355 Tweets
山本由伸
• 11684 Tweets


















Pinned Tweet

Super excited to introduce HippoRAG, a method I enjoyed developing the most in 2024. It’s led by my amazing student Bernal
@bernaaaljg
and joint with
@YihengShu
@yugu_nlp
@michiyasunaga
. Bernal’s thread gives a good technical account, so I’ll just share some personal thoughts

📣📣 Super proud to present the most exciting project of my PhD so far: “HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models”.
HippoRAG, as the title suggests, is a brain-inspired RAG framework that enables LLMs to effectively and efficiently

29
155
872
1
24
108
Hi
@emilymbender
, I'm one of the lead authors of MMMU. I can certify that 1) Google didn't fund this work, and 2) Google didn't have early access. They really like the benchmark after our release and worked very hard to get the results. It doesn't take that long to eval on a

Returning to transparency, I see that they point to MMMU, which was published on arXiv (not peer reviewed) on November 27, 2023. Google must have had early access to this work, which I suspect means that Google funded it, but the paper doesn't acknowledge any funding source. /12
5
4
62
10
53
965
Generalist web agents may get here sooner than we thought---introducing SeeAct, a multimodal web agent built on GPT-4V(ision).
What's this all about?
> Back in June 2023, when we released Mind2Web () and envisioned generalist web agent, a language agent
19
149
655
@emilymbender
(this will be the last response just for the record; this type of engagement is not why I use this app)
1. Dataset was released along with the paper. again, eval on a dataset of this scale really doesn't take long, especially for google
2. this was an one-off project
9
17
628
Introducing BioCLIP: A Vision Foundation Model for the Tree of Life
A foundation model that strongly generalizes on the tree of life (2M+ species), outperforming OpenAI CLIP by 18% in zero-shot classification, and supports open-ended classification over
9
94
440
Q* from OpenAI and tree-of-thought reasoning triggered a lot of enthusiasm on augmenting LLMs' reasoning/planning capabilities with search. But is search really the panacea for LLMs? Answer from our new study
@osunlp
: Not quite yet.
TLDR: For advanced planning methods like tree


LLM planning methods, such as tree search, are critical for complex problem solving, but their practical utility can depend on the discriminator used with them. Check out our new findings:
(1/6)

5
45
188
5
82
351
There are numerous environments LLMs are not trained for: enterprise DBs, proprietary knowledge graphs, etc. The de facto solution for applying LLMs in such scenarios is RAG. We envision a new framework: creating a Middleware for LLMs. Just like humans invented tools to help us


🧐Question: How to turn your LLM into a generalist agent interacting with complex real-world environments?
🙌Answer: Equip the LLM with specialized tools (Fig 1)! We found such tools boost GPT-4 by about 2.8x on database tasks and 2.2x on KB tasks. (1/n)

5
56
255
1
51
280
Has OpenAI o1 solved ‘reasoning’? Surprisingly, it’s equally bad as GPT-4 on some simple comparative reasoning tasks, while a grokked transformer can solve near perfectly.
Improving implicit/parametric reasoning is still necessary when you have a search space with an

Can OpenAI o1 tackle hard reasoning problems? We tested it on the complex reasoning task in our Grokked Transformers paper. It turns out that o1-preview also struggles a lot like earlier LLMs; on the other hand, a grokked transformer can nail it near-perfectly.

14
78
539
9
46
274
Honored to receive the Best Student Paper Award from
#CVPR2024
!! It’s
@samstevens6860
and Lisa’s very first lead work in their PhD. Super glad for the recognition of their work! Also congrats to all the amazing collaborators and support from the NSF
@imageomics
institute!




22
19
203
❓How to ground language models like ChatGPT to real-world environments
📢📢We present Pangu, a generic neuro-symbolic framework for grounded language understanding, where a symbolic agent and a neural LM work in a concerted way.
➡️ SOTA on KBQA & few-shot KBQA with Codex (1/n)
4
52
195
🧠Expert AGI is still far away
Background
Candid and constructive discussions on AGI have been challenging due to a lack of shared operationalizable definitions.
@merrierm
et al.
@GoogleDeepMind
recently proposed a leveled taxonomy for AGI that centers around both generality


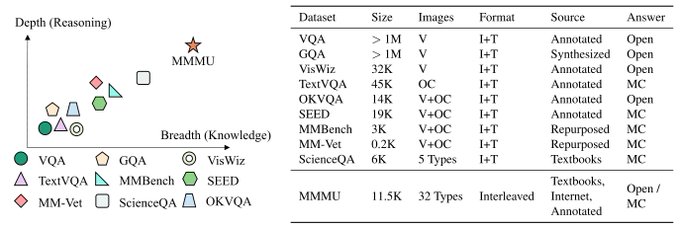
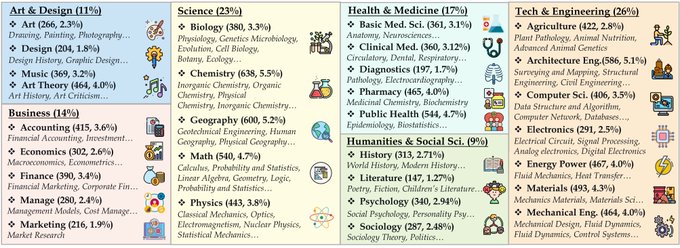
🚀 Introducing MMMU, a Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI.
🧐 Highlights of the MMMU benchmark:
> 11.5K meticulously collected multimodal questions from college exams, quizzes, and textbooks
>


19
184
748
5
38
192
Thanks
@_akhaliq
for sharing our work. So, let's talk about planning.
Planning is a hallmark of human intelligence. It is an evolutionary feat built upon numerous other capacities:
> using various tools to iteratively collect information and make decisions
> recording

TravelPlanner
A Benchmark for Real-World Planning with Language Agents
paper page:
Planning has been part of the core pursuit for artificial intelligence since its conception, but earlier AI agents mostly focused on constrained settings because many of

12
123
522
3
37
155
It’s just the start of 2024, and we have already seen many important results from synthetic data. Personally I don’t think it’s just “data augmentation” rebranded. Previous data augmentation efforts rely heavily on “human engineering”, and now it’s more like LLMs “imagination”

🚨New paper!🚨
Self-Rewarding LMs
- LM itself provides its own rewards on own generations via LLM-as-a-Judge during Iterative DPO
- Reward modeling ability improves during training rather than staying fixed
...opens the door to superhuman feedback?
🧵(1/5)

5
227
1K
6
15
154

Super honored and excited to be appointed as Distinguished Assistant Professor of Engineering Inclusive Excellence by
@OSUengineering
! It will support me to continue pushing towards the democratization of AI in research and teaching.
4
4
137
I will be attending
#ACL2024nlp
from 12th to 16th. Happy to chat about language agents.
I'll help present:
1. LLMs in the Imaginarium: Tool Learning through Simulated Trial and Error (led by
@BoshiWang2
)
2. When is Tree Search Useful for LLM Planning? It

7
20
127
I’m looking for a summer research intern at Microsoft Semantic Machines to work on agent-related topics. If you are a current PhD student with a track record in this area and still looking for internship, apply here and let me know (DM):
Thanks
@_akhaliq
for sharing our work led by
@BoshiWang2
from
@osunlp
, so let's chat about how LLMs should learn to use tools, a necessary capability of language agents.
Tools are essential for LLMs to transcend the confines of their static parametric knowledge and
1
27
114
6
26
122
For people interested in language agents (aka LLM agents, AI agents, autonomous agents), excited to share that
@Diyi_Yang
@ShunyuYao12
@taoyds
and I will present a tutorial on “Language Agents: Foundations, Prospects, and Risks” at
#EMNLP
2024! Stay tuned for materials!

EMNLP 2024 (4/4)
@emnlpmeeting
- Language Agents: Foundations, Prospects, and Risks. Yu Su, Diyi Yang, Shunyu Yao and Tao Yu.
- Enhancing LLM Capabilities Beyond Scaling Up. Wenpeng Yin, Muhao Chen, Rui Zhang, Ben Zhou, Fei Wang and Dan Roth.
#NLProc
0
4
33
0
19
119
Thanks
@_akhaliq
for sharing our work led by
@BoshiWang2
from
@osunlp
, so let's chat about how LLMs should learn to use tools, a necessary capability of language agents.
Tools are essential for LLMs to transcend the confines of their static parametric knowledge and
Microsoft presents LLMs in the Imaginarium
Tool Learning through Simulated Trial and Error
Tools are essential for large language models (LLMs) to acquire up-to-date information and take consequential actions in external environments. Existing work on tool-augmented LLMs

7
46
217
1
27
114
Excited that we have two papers selected as Oral at
#CVPR2024
(90 orals in total, 0.8%). Congrats to all the students and collaborators, and see you in Seattle!
- BioCLIP: A Vision Foundation Model for the Tree of Life () led by
@samstevens6860
Lisa Wu
-
2
15
112
Cant agree more with
#4
and
#6
. My personal prediction of AI keywords for 2024 (including ones that are obvious so
@Thom_Wolf
omitted):
1. Langage agents
We will see more robust language agents starting to be deployed for non-toy use cases. After the initial hype in 2023, we

Some predictions for 2024 – keeping only the more controversial ones. You certainly saw the non-controversial ones (multimodality, etc) already
1. At least 10 new unicorn companies building SOTA open foundation models in 2024
Stars are so aligned:
- a smart, small and dedicated
19
77
408
1
15
104
Geoffrey Hinton (
#ACL2023NLP
keynote address): LLMs’ hallucinations should be called confabulations

2
20
99
That figure was based on my thoughts from ~1 year ago. After working on language agents extensively in the past year, I have come to realize that I was a bit too naive back then. I have an updated conceptual framework for language agents that I've been talking about lately (at



3
19
99
Excited to give a keynote on
"Language agents: a critical evolutionary step of artificial intelligence"
tomorrow at the LLM workshop ()
@IJCAIconf
. This is the problem I cannot stop thinking about these days. Join us if you are attending IJCAI!



1
26
95

What would be the most wild environment for grounding & empowering LLMs? 👉The entire Internet!
📢 Mind2Web: Towards a Generalist Agent for the Web ()
Led by amazing
@osunlp
student
@XiangDeng1
#NLProc

Mind2Web: Towards a Generalist Agent for the Web
paper page:
introduce Mind2Web, the first dataset for developing and evaluating generalist agents for the web that can follow language instructions to complete complex tasks on any website. Existing
14
107
485
4
27
89
thanks
@_akhaliq
for sharing our work led by the amazing
@BoshiWang2
from
@osunlp
. This is one of my favorite work so far. I'm excited that several important topics: 1) inductive learning of latent deduction rules, 2) implicit/parametric reasoning of neural networks, and 3)
Grokked Transformers are Implicit Reasoners
A Mechanistic Journey to the Edge of Generalization
We study whether transformers can learn to implicitly reason over parametric knowledge, a skill that even the most capable language models struggle with. Focusing on two

7
49
307
2
19
86
Overleaf is down. It survived the ACL deadline (7 am ET today) but didn’t survive the CVPR deadline (EOD PT today). That says something about the size of the NLP community vs. the CV community?
6
2
82
GrailQA: A new large-scale, high-quality dataset for QA on knowledge bases
- 64K questions over 3.7K relations across 86 domains
- Support evaluation of i.i.d., compositional, and zero-shot generalization
paper:
leaderboard:

1
7
82
New
#ACL2024
paper: LLMs in the Imaginarium: Tool Learning through Simulated Trial and Error (
@BoshiWang2
's internship work at Microsoft Semantic Machines)
I like this work because it takes home an important insight: synthetic data + post-training is critical for agents.
Thanks
@_akhaliq
for sharing our work led by
@BoshiWang2
from
@osunlp
, so let's chat about how LLMs should learn to use tools, a necessary capability of language agents.
Tools are essential for LLMs to transcend the confines of their static parametric knowledge and
1
27
114
1
17
80
As an AC for the first
@COLM_conf
, I had the pleasure to observe a good portion of the review and decision making process. I’d say COLM’s review quality is on par with some of the best AI confs, and the PCs spent a ton of time discussing with ACs to make deliberate decisions.

Some stats:
@COLM_conf
2024 (the first COLM ever!!!) received 1,036 submissions. We have accepted 299 submissions for presentation at the conference, an acceptance rate of 28.8%.
5
14
138
2
9
78
Honored that our paper Pangu received the Outstanding Paper Award at
#ACL2023NLP
! We propose a new framework based on search guided by LMs for language agents
It's interesting to notice the conceptual sim. b/w Pangu and recent Tree of Thought (great work by
@Shunyu
) except:
❓How to ground language models like ChatGPT to real-world environments
📢📢We present Pangu, a generic neuro-symbolic framework for grounded language understanding, where a symbolic agent and a neural LM work in a concerted way.
➡️ SOTA on KBQA & few-shot KBQA with Codex (1/n)
4
52
195
8
4
78
Booked the first in-person conference trip to
@CVPR
as faculty. Total cost easily exceeds $4,000 for a domestic trip. In my student days $2,000 would be more than enough. Is it normally this expensive or should I blame inflation? Surely need to change the budget in my proposals…
7
0
70
It's the last day of the conference, and Bangkok has so much to explore. i know, i know.. but if you still have some appetite for a (hopefully thought-provoking) talk, I will talk about web/GUI agents tomorrow at 2 pm in the SpLU-RoboNLP workshop. I will cover:
1. Why the


As ACL kicks off in beautiful Bangkok, check SpLU-RoboNLP workshop , with an exciting lineup of speakers and presentations!
@aclmeeting
#NLProc
#ACL2024NLP
@yoavartzi
@malihealikhani
@ziqiao_ma
@zhan1624
@xwang_lk
@Merterm
@dan_fried
@ManlingLi_
@ysu_nlp
0
4
29
1
18
70
2024 is the year of synthetic data and multimodal LLMs. What if we combine the two?
The data on the Internet is just the tip of an iceberg. Lots of relations, structures, meaning are hidden between the lines (the 'dark matter'). We show that (multimodal) LLMs can uncover this

Proud to present 🔍MagicLens: image retrieval models following open-ended instructions.
🌟Highlights of 🔍MagicLens:
>🧐Novel Insights: Naturally occurring image pairs on the same web page contain diverse image relations (e.g., inside and outside views
14
59
187
0
11
70
Language played a critical role in the evolution of biological intelligence, and artificial intelligence may be following a similar evolutionary path.
👉New blog post: Language agents: a critical evolutionary step of artificial intelligence
What are




1
28
66
Advanced GPU compute is vital to cutting-edge AI. Thrilled that 128 H100 GPUs are being added to the Ohio Supercomputer Center, a major and timely investment by the State of Ohio and
@OhioState
. The new cluster will substantially propel the research at
@osunlp
and OSU at large.


OSC is excited to announce 'Cardinal', our major supercomputing cluster launching in 2024. This high performance computing cluster will provide vital resources to support the growing AI needs in Ohio.
2
2
9
1
6
64
New multimodal web agent paper to appear at
#CVPR2024
👇
While it's now well accepted that visual signals are critical for web agents, as shown in SeeAct and several recent papers, we actually have an even earlier work on multimodality that had been silently under review at

How can we effectively and efficiently encode semantically related and task-related contexts for web agents?
Check out our Dual-VCR accepted to
#CVPR2024
!
Summary: DUAL-VCR enhances the context of each HTML element in the document by leveraging its

1
12
46
0
12
60
Quoting
@YiMaTweets
"It is industry's job to find how to do better, but academia is to find out how to do it right." While I think there're lots of good industry research doing things right, when it comes to reseach on agents, I do think academia has unique freedom to explore how

We're having a big event on agents at CMU on May 2-3 (one week from now), all are welcome!
It will feature:
* Invited talks from
@alsuhr
@ysu_nlp
@xinyun_chen_
@MaartenSap
and
@chris_j_paxton
* Posters of cutting edge research
* Seminars and hackathons
4
29
180
2
5
61
The Grokked Transformers paper is accepted to
#neurips2024
@NeurIPSConf
! If interested in reasoning, mech interp, or grokking, check it out!
thanks
@_akhaliq
for sharing our work led by the amazing
@BoshiWang2
from
@osunlp
. This is one of my favorite work so far. I'm excited that several important topics: 1) inductive learning of latent deduction rules, 2) implicit/parametric reasoning of neural networks, and 3)
2
19
86
1
11
67
We are hiring 20 new tenure-track faculty at all levels and in all CSE areas! Review of materials will start on Sept 15, 2021 on a rolling basis.

The Department of Computer Science and Engineering () at The Ohio State University
@OSUengineering
has *20* tenure-track faculty positions open 👏. Retweet is appreciated!
@AcademicJobs
@ajobsonline
@csfacultyjobs
Check more:👇
9
159
289
1
8
56
Join us for the Workshop on Natural Language Interfaces
#NLI2020
on July 10 at
#ACL2020
, featuring a stellar multi-disciplinary lineup of speakers: Joyce Chai, H V Jagadish,
@MonicaSLam
,
@percyliang
,
@LukeZettlemoyer
, Imed Zitouni from NLP/DB/PL/Robotics.


1
11
55
HippoRAG is accepted to
#neurips2024
@NeurIPSConf
! If interested in Graph+RAG, memory for LLMs, or neurobiological inspired AI, check it out!
Super excited to introduce HippoRAG, a method I enjoyed developing the most in 2024. It’s led by my amazing student Bernal
@bernaaaljg
and joint with
@YihengShu
@yugu_nlp
@michiyasunaga
. Bernal’s thread gives a good technical account, so I’ll just share some personal thoughts
1
24
108
0
6
60
#ACL2023NLP
We
@osunlp
will present 9 papers at ACL (7 main, 1 findings, 1 workshop), covering grounding LMs to real-world environments, chain-of-thought prompting, differential privacy, code generation, federated learning, and information extraction. Come chat w/ us! A thread 🧵
1
8
52
🎉Super excited that Mind2Web has been accepted to NeurIPS as spotlight!
Congrats to the amazing team
@XiangDeng1
@yugu_nlp
@boyuan__zheng
@ShijieChen98
@samstevens6860
@hhsun1
What would be the most wild environment for grounding & empowering LLMs? 👉The entire Internet!
📢 Mind2Web: Towards a Generalist Agent for the Web ()
Led by amazing
@osunlp
student
@XiangDeng1
#NLProc
4
27
89
5
6
51
@Diyi_Yang
@taoyds
@ShunyuYao12
and I will be giving a tutorial on language agents at EMNLP. Join us at Miami for a warm and agentic winter retreat!


0
4
49
Everyday I appreciate more how
#ChatGPT
helps daily tasks and saves ton of time:
So a certain application requires formatting all of my publications into a specific format. Normally I'd have to spend ~1 hour copy&paste&reformat, but now ChatGPT just gets it done perfectly!


1
3
50
I don't normally write position papers, but safety of language agents is important enough to warrant an exception:
📜 "A Trembling House of Cards? Mapping Adversarial Attacks against Language Agents"
People (including myself) have been enthusiastically developing language

🚀 Language agents fueled by LLMs are rapidly advancing. Their capability is being further capitalized by connecting to a wide range of external components such as databases, tools, the Internet, robotic embodiment, etc. However, our understanding of their safety risks lags much


0
17
57
1
7
49
HippoRAG just became our first repo from
@osunlp
to cross 1K 🌟!
If you are interested in (knowledge) graph + RAG and find GraphRAG costly to run, give HippoRAG a try! We are a small academic team but we will actively maintain and develop better versions. Kudos to
@bernaaaljg

1
4
47
Slides here:
Highlights:
1. Analogous evolutionary path of biological and artificial intelligence
2. A conceptual framework for language agents
3. Now is most exciting time for NLP ever, but maybe for natural language programming, not just processing



Excited to give a keynote on
"Language agents: a critical evolutionary step of artificial intelligence"
tomorrow at the LLM workshop ()
@IJCAIconf
. This is the problem I cannot stop thinking about these days. Join us if you are attending IJCAI!
1
26
95
0
13
47
🎉 Super excited to share that MagicBrush has been accepted to
#NeurIPS
2023!
Congrats to the amazing team
@DrogoKhal4
@LingboMo
@WenhuChen
@hhsun1
MagicBrush: A Manually Annotated Dataset for Instruction-Guided Image Editing
paper page:
Text-guided image editing is widely needed in daily life, ranging from personal use to professional applications such as Photoshop. However, existing methods are
13
160
770
2
11
47
AI agents have great potential for assisting in sciences, but please don’t hype it up as if they will replace scientists. No, they are best working as copilots for scientists, if done right.

Everyone's talking about Sakana's AI scientist. But no-one's answering the big question: is its output good?
I spent hours reading its generated papers and research logs. Read on to find out
31
182
1K
2
5
45
We have openings for postdoc at
@osunlp
:
- (Multimodal) foundation models for sciences
- Large language models
- Grounding to environments (Web, DBs, KBs, physical world via embodied agents)
- Language agents and tool use
Email/DM or chat at
#ACL2023NLP
. Retweet appreciated!
#ACL2023NLP
We
@osunlp
will present 9 papers at ACL (7 main, 1 findings, 1 workshop), covering grounding LMs to real-world environments, chain-of-thought prompting, differential privacy, code generation, federated learning, and information extraction. Come chat w/ us! A thread 🧵
1
8
52
0
24
44
“Just throw more data at it” has become a panacea in AI, but what if more data can actually hurt? In our
#EMNLP2022
paper, we found that, for conversational AI systems, the more data we have in total, the more data we need to learn a new capability -> a vicious cycle.

🚨 New paper alert 🚨
Now that it's accepted to EMNLP, I'm excited to share work from my internship last year at
@MSFTResearch
Semantic Machines!
📄:
🤖:
This all started with a troubling trend first noticed by
@ysu_nlp
🧵
1/9
1
10
80
1
2
44
#NeurIPS2023
We will present at the 5-7 pm session tmr:
> MagicBrush: A Manually Annotated Dataset for Instruction-Guided Image Editing
> Mind2Web: Towards a Generalist Agent for the Web
Come chat about agents, multimodality, and
What would be the most wild environment for grounding & empowering LLMs? 👉The entire Internet!
📢 Mind2Web: Towards a Generalist Agent for the Web ()
Led by amazing
@osunlp
student
@XiangDeng1
#NLProc
4
27
89
1
8
44
I'm hiring a postdoc (ML/CV/NLP) for
@imageomics
Institute. Topics: multimodal foundation models, interpretability, and neuro-symbolic learning. Also work with Profs Berger-Wolf/Chao. Pls help share! Job post:
#postdocjobs
#postdocposition
#NLProc
5
28
43
Check out Microsoft M365 Co-Pilot, which really shows the power of LLMs + Grounding! Really glad that the Semantic Machines team is a part of this exciting journey!
1
4
45
I'm at
#CVPR2024
/Seattle until 06.22. Happy to share 3 papers on multimodality/LLMs, including two Oral presentations and best paper finalists. You can find me at the corresponding poster sessions. Happy to chat about everything around language agents and career opportunities
2
5
44
The absolute number is meaningless when it comes to publications, but this is a really proud advisor moment: We
@osunlp
started submitting to ML conferences last year. In the past cycle, we had 3 NeurIPS, 5 ICLR, and 4 ICML accepted. How lucky I am to work with so many amazing

0
1
44
The first paper from Microsoft Semantic Machines is finally out! We introduce a new representation paradigm and model dialogues as dataflow graphs, which supports persistent context, compositional learning, and many more cool things! See more in blog post (leaderboard included)

Researchers at Microsoft Semantic Machines are taking a new approach to conversational AI—modeling dialogues with compositional dataflow graphs. Learn how the framework supports flexible, open-ended conversations, and explore the dataset and leaderboard:
3
72
561
0
7
44
An applaudable effort from Meta AI (kudos to
@LukeZettlemoyer
and his team) on releasing the parameters and training logs of GPT-3 scale pre-trained LMs. The extensive evaluation and discussion on ethics and limitations are also impressive.
#NLProc
2
5
42
New
#ACL2024
paper that essentially argues that tree search is not the panacea for LLM planning. For tree search to be useful, it needs a strong (90%) discriminator to rank the hypotheses in the search frontier. However, for many problems discrimination is no easier than
2
10
41
📢📢 Excited to share that our ArcaneQA paper (led by my fantastic student
@yugu_nlp
) for more generalizable and efficient QA over large knowledge graphs has won Outstanding Paper Award at
#COLING2022
! Check thread for more details 👇👇
@osunlp
#NLProc
2
2
39
Language agents are a critical evolutionary step of AI, but evaluation has been a bit challenging and ad-hoc. Our
@osunlp
team is glad to contribute to AgentBench led by
@thukeg
for developing a comprehensive benchmark, which includes 3 of our datasets, Mind2Web, GrailQA, and

Thanks
@arankomatsuzaki
for sharing our paper
#AgentBench
!
🤯Static NLP datasets are not enough for evaluating existing LLMs
🌟We should test them in practical interactive environments for agents!
Find more videos for LLM-as-Agent in AgentBench at !
1
22
67
0
5
40
I always encourage students to try to first get “golden-path results” as early as possible in a project—preliminary results under the minimal idealized setting that could signal the viability of the core idea. I find this to be particularly important for bold, high-risk

An incredible skill that I have witnessed, especially at OpenAI, is the ability to make “yolo runs” work.
The traditional advice in academic research is, “change one thing at a time.” This approach forces you to understand the effect of each component in your model, and
103
210
2K
0
1
39
I think 2024 will be when we see many language agents mature enough for practical deployment and generate real value, but research on fundamentally more capable agents are probably still at the start of an exponential curve

Agents will largely be solved this year. The ones that operate a desktop, browser or phone automatically when given a task. I think it’s just a matter of time
65
69
1K
2
0
40
@TsingYoga
写得不错。这也是在simulated trial and error paper () 里我们希望强调的一点。Agent训练需要perception-decision-execution过程的数据,而互联网上的数据大部分只是结果缺乏过程
2
0
38
Many people are enthusiastically waiting for the code release of SeeAct, and now it's finally here, as promised! Even better, we spent a lot of time to make it as ergonomic as possible. A powerful web agent based on GPT-4V (and more) is only 1 click away. Have fun and let us know

🚀Releasing SeeAct v0.1.0, generalist web agents at your fingertips!
💻Github Repo:
SeeAct enables everyone to effortlessly run web agents based on GPT-4V (and more) with just one click. We hope it can help make the complex Internet a more accessible
2
47
178
0
5
35
As I reflect on my experience hosting benchmarks in the past year (MMMU, Mind2Web, TravelPlanner, etc.), I agree with
@chrmanning
’s suggestion on how to split a dataset/benchmark in the LLM era. A few thoughts/elaborations:
1. It is important to maintain ‘iid’ across the splits,

I agree: private test sets sound good but end up a fail.¹ How should you make a dataset? Define train, dev & test sets. Make dev² & test 2x the size for good statistical power. Divide them iid; make half test the public official test set & keep half as private verification set.³
4
17
161
2
9
36
come join us at Microsoft Semantic Machines for exciting and fun internship projects around LLMs and conversational AI!

Do you think there's more to conversational AI than cutting and pasting text into ChatGPT? Apply for a Summer '24 research internship at Microsoft Semantic Machines!
2
16
61
1
3
37
GPT-4o mini and Claude-3.5-sonnet are (surprisingly?) strong on a range of agent tasks. What is the minimal model size for a well-functioning generalist agent? Maybe it’s not as large as I thought.

🚨Thrilled to present VisualAgentBench (VAB) with
@yugu_nlp
and Tianjie, where we enable both TRAINING & TESTING of visual foundation agents across 5 different environments!
In all 17 large multimodal models (LMMs) are tested. Find our paper, data, and more insights below 👇
1
16
46
2
6
37
Glad to see MMMU being integrated into HELM. Gemini 1.5 Pro working (slightly) better than GPT-4V is aligned with our experience in using these models in various vision-language tasks

HELM is now fully multimodal! In addition to language models, text-to-image models (HEIM), we now evaluate vision-language models (made possible by MMMU, VQAv2, VizWiz - thanks to the authors!). As usual, the full predictions and prompts are available on the HELM website:
0
4
20
0
5
36
I whole-heartedly second
@NandoDF
’s recommendation. This is THE book I recommend to my students
@osunlp
interested in getting a first conceptual framework about what is intelligence and how it comes about from evolution.

This is by far the best non-technical Natural and Artificial Intelligence book anyone could read. This comprehensive, well-researched, crisply clear, sharply focused and illuminating book is a thing of beauty. It is the book I wish I had had when I started my AI career 30 years

18
131
865
1
3
36
Table LLMs just got a huge boost with TableLlama!
The best part? Everything will be open-source!


2
7
36
Well said, and precisely the point we want to make in the paper: When is Tree Search Useful for LLM Planning? It Depends on the Discriminator


an underdiscussed gotcha behind the “search + LLM = AGI” narrative is search is only valuable when statewide improvements are *quantifiable*
this is the case in Go, and coding problems w/ tests, and this ARC benchmark. we can explore the (LLM-generated) state space and leverage
52
28
329
1
4
36
These folks
@taoyds
@TianbaoX
etc. are serious when it comes to agent benchmarks. Excited to have an agent benchmark with an OS simulator to play with!

OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
The first-of-its-kind scalable, real computer environment for multimodal agents, supporting task setup, execution-based evaluation, and interactive learning across various operating
4
88
348
1
1
34
A great pleasure to host
@RishiBommasani
's visit at OSU! Fantastic talk (Castles in the sky: Towards sturdy foundation models) and tons of fun discussion! Lots of people joining in person/online to engage in this intriguing topic.
#nlproc
@osunlp
@stanfordnlp
w/
@hhsun1
Harry Chao



1
4
32
@_akhaliq
Thank you for sharing our work from OSU NLP group
@osunlp
!
Project page:
Led by our amazing students
@DrogoKhal4
@LingboMo
and joint with
@WenhuChen
@hhsun1
MagicBrush: A Manually Annotated Dataset for Instruction-Guided Image Editing
paper page:
Text-guided image editing is widely needed in daily life, ranging from personal use to professional applications such as Photoshop. However, existing methods are
13
160
770
0
8
28
Attention as used in Transformer has long been criticized for providing unfaithful interpretation ☹️. Do you know it's possible to make attention a faithful interpretation mechanism? 🤔
📢📢 Check out our new work on INterpretable TRansformer (INTR) 👇👇


Can we make a standard classification architecture interpretable and meaningful? We introduce a novel application of Transformers for interpretable image classification, which we refer to as the INterpretable TRansformer (INTR) and is available at . (1/5)

2
9
17
0
7
31
Congratulations on the long awaited release of Gemini, outperforming GPT-4V(ision) and setting a new SOTA on our MMMU multimodal reasoning benchmark. Now the game is on!

I’m very excited to share our work on Gemini today! Gemini is a family of multimodal models that demonstrate really strong capabilities across the image, audio, video, and text domains. Our most-capable model, Gemini Ultra, advances the state of the art in 30 of 32 benchmarks,


273
3K
13K
0
2
30
I will be at
@emnlpmeeting
12/6-12/12. Looking forward to meeting old and new friends! Come chat if interested in language interfaces, grounding large LMs, embodied agents, or academic vs industry research!
#NLProc
3
2
29
Our new work shows that equipping (through instruction tuning) LLMs with the capability of thinking in both natural and programming languages is key to general math problem solving.
awesome project led by
@WenhuChen
and our own
@xiangyue96
!

Excited to introduce our latest math generalist model MAmmoTH 🦣, built through instruction tuning. We proposed hybrid "chain-of-thought" & "program-of-thought" training to supercharge LLMs' math reasoning capabilities. 🦣 beats the open SoTA by 20+% on many datasets like MATH.

9
41
256
1
3
29
This year in my Intro to AI course I experimented with a virtual poster session for final project presentations in Gather and open it up to the entire department. It was so much more interactive! Blown away by the breadth and depth of the projects. Multiple could be research pubs

1
0
29
A new well-curated web agent benchmark from
@sivareddyg
’s team. Check it out!

Introducing WebLINX 🐯, a large benchmark for AI agents navigating real websites with multi-turn dialogue. 100K interactions across 2300 demonstrations on 150 real-word websites. Includes HTML, screenshots and videos. Tests unseen sites, tasks, blind users



7
69
258
1
1
28
Examples come from our recent paper
0
0
28




While I may not fully agree with all of
@Francis_YAO_
’s opinions on RAG vs long context (mainly because of my view of how long-term memory should work), I applaud his approach of open debate with clearly articulated definitions (which is surprisingly lack in many AI debates these

Over the last two days after my claim "long context will replace RAG", I have received quite a few criticisms (thanks and really appreciated!) and many of them stand a reasonable point. Here I have gathered the major counterargument, and try to address then one-by-one (feels like
35
88
511
2
0
27
So in the first lecture of my Intro to AI class I let students play with DALLE-2 and they all loved it! It's amazing how in just the past few years we've got so many great, easy-to-use tools. We should seriously consider how to best use them for education and outreach.
#dalle2
3
2
26
Making AI more accessible to everyone has always been my research goal. Super excited to see that NSF likes our idea of "plug-and-play AI"! I will co-lead the AI team with
@EricFos
. Also glad that the other proposal from OSU is also selected. Go Bucks!
@icicleai
@OSUengineering
4
1
24
Jacob has some of the most thought-provoking takes on world models.
My fav quotes:
1. The map, the orrery, and the simulator are all models of the same underlying system. Where they differ is in their affordances—the set of questions they enable a user of the model to answer,

Some thoughts on how to think about "world models" in language models and beyond:

10
56
258
0
4
27
Thank you for highlighting SeeAct
@_akhaliq
! A more personal reflection on how we got here can be found here
GPT-4V(ision) is a Generalist Web Agent, if Grounded
paper page:
The recent development on large multimodal models (LMMs), especially GPT-4V(ision) and Gemini, has been quickly expanding the capability boundaries of multimodal models beyond traditional
5
84
385
0
5
25
our intuitions from classic ML make it easy to believe that synthetic data is like interpolation and could lead to model collapse. But such intuitions may not hold and should be carefully re-examined with evidence in the LLM era. For another good example of full synthetic data

If you believe you can't exceed a teacher model at a task with synthetic data alone, then how is this SOTA?
Synthetic data is real and is not something that has to cause a mode collapse or top out at the previous SOTA
14
10
186
3
3
26
Thank you
@bindureddy
for the neat discussion on our work! We took a behaviorist approach to analyzing LLMs and our findings reveal new challenges in popular use cases of LLMs: tool use (easily deceived by malicious tools) and generative search engines (confirmation bias)

Science Behind Why LLMs Can Easily Be Tricked And Are Predictably Gullible
All the Gen AI hype has elevated LLMs to much more than what they really are - Basically they are just really not much more than big transformer neural networks that are trained on large amounts of data

21
143
628
1
4
24
@AndrewYNg
Simple in-context learning is unlikely to get tool use to the level of accuracy needed for practical use. LLMs should use simulated trial and error to truly master tools, just like how tool-use animals do. We don't master a tool by solely looking at the 'user manual'
3
0
24
99% attack success rate on GPT-3.5, perhaps the best public jailbreaking method, check it out
Finally got a bit time to introduce our recent work on learning to generate adversarial suffixes: : Our generative model, named AmpleGCG, captures the distribution of adversarial suffixes given a harmful query and enables rapid generation of hundreds of
4
35
102
1
1
24
Biomedical texts are exploding (1M+ PubMed papers annually, tons of EHRs) and information extraction is needed everywhere. It'll be game-changing if foundation models (eg GPT-3) can do few-shot bioIE. UNF, that's not quite the case yet. Check our new paper at EMNLP'22 (Findings)
Thinking about using GPT-3 in-context learning for biomedical information extraction?
Think again 🧠
Our work suggests that small PLM fine-tuning might be a better option and points to some general limitations of GPT-3 in-context learning. ()
#NLProc
[1/6]


2
8
20
1
5
24