

Tao Yu
@taoyds
Followers
3,439
Following
815
Media
34
Statuses
329
@XLangNLP lab, asst. prof. @HKUniversity . prev. postdoc @uwnlp ; phd @Yale ; intern @MSFTResearch , @SFResearch . he/him 🌈
Seattle
Joined March 2016
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
#خلصوا_صفقات_الهلال1
• 679538 Tweets
ラピュタ
• 400960 Tweets
Atatürk
• 378690 Tweets
#พรชีวันEP15
• 262598 Tweets
Johnny
• 211552 Tweets
Megan
• 208387 Tweets
Sancho
• 144476 Tweets
MEGTAN IS COMING
• 124393 Tweets
RM IS COMING
• 117515 Tweets
olivia
• 116132 Tweets
namjoon
• 113028 Tweets
#初音ミク誕生祭2024
• 99083 Tweets
#4MINUTES_EP6
• 78959 Tweets
#バルス祭り
• 60562 Tweets
Labor Day
• 47215 Tweets
كاس العالم
• 45542 Tweets
CHERISH TWENTY WITH WONYOUNG
• 45148 Tweets
ミクさん
• 44503 Tweets
ムスカ大佐
• 40176 Tweets
#フロイニ
• 30348 Tweets
ŹOOĻ記念日
• 23985 Tweets
ミクちゃん
• 21751 Tweets
Día Internacional
• 19189 Tweets
滅びの呪文
• 17882 Tweets
Javier Acosta
• 16877 Tweets
Ramírez
• 16338 Tweets
ロボット兵
• 13588 Tweets
ナウシカ
• 13577 Tweets
Lolla
• 13199 Tweets
Lo Celso
• 11040 Tweets





















A new way to work w. LMs!
Binder, an easy neuro-symbolic paradigm:
1.Parse input➡️SQL/Python bound w. GPT3 Codex API calls
2.Codex+PL interpreter execute➡️answer
No train&few-shot!➡️SOTA
🆚chain-of-thought: interpretable&robust⬆️
🆚NL2Code: coverage⬆️

10
73
292
💥New benchmark💥
DS-1000, a data science code generation benchmark with 1K questions about 7🐍libraries. Spent ~1200 expert hours!
It is the only one that
1⃣ focuses on everyday applications
2⃣ includes natural intents & contexts
3⃣has test cases
1/🧵

5
69
289
🚀🚀🚀Lots of people working on LM agents recently! Open models like Llama/CodeLlama not quite up to ChatGPT's level?
Our 🎉Lemur🎉- SOTA open foundation models for language agents, matching ChatGPT on🤖15 agent tasks🤖!


1/ 🧵 🎉 Introducing Lemur-70B & Lemur-70B-Chat:
🚀Open & SOTA Foundation Models for Language Agents!
The closest open model to GPT-3.5 on 🤖15 agent tasks🤖!
📄Paper:
🤗Model
@huggingface
:
More details 👇

6
74
289
1
59
226

In Memory of My beloved Ph.D. Advisor
@dragomir_radev
🕯️R.I.P. 🕯️



The
#AI
community, the
#computerscience
community, the
@YaleSEAS
community, and humanity have suddenly lost a remarkable person,
@dragomir_radev
- kind and brilliant, devoted to his family and friends... gone too soon. A sad day
@Yale
@YINSedge
@YaleCompsci
#NLP2023


41
87
389
6
12
198
Beyond our Lemur: OPEN LMs for language agents
Introducing 💥OpenAgents💥: an OPEN platform for language agents in the wild!
Analyze data, call plugins, control your browser as ChatGPT Plus, but with OPEN SOURCE code!!
📑:
Code:


💥OpenAgents💥: an OPEN platform for language agents in the wild
Analyze data, call plugins, control your browser as ChatGPT Plus, but with OPEN Code for
1⃣Easy deployment
2⃣Full stack
3⃣Chat Web UI
4⃣Agent methods
5⃣…
Code:
👇
5
70
223
4
62
183
After 5 month dedicated work from >15 researchers & developers, we're thrilled to introduce 🚀OPEN-SOURCE language model Agents🚀!
Try demos: 🥑
Stay tuned for open-source code, model, framework, evaluation & more at !


1/6🚀Announcing XLang language model (LM) Agents:
📊Data Agent: LM + code & data tools
🔧Plugins Agent: LM + 200+ API plugins
🌐Web Agent: LM + web control
Try demo:
Stay tuned for open-source code & models
See more examples!👇
1
24
69
6
50
177
🚀Multimodal agents is on rise in 2024! But even building app/domain-specific agent env is hard😰.
Our real computer OSWorld env allows you to define agent tasks about arbitrary apps on diff. OS w.o crafting new envs.
🧐Benchmarked
#VLMs
on 369 OSWorld tasks:
#GPT4V
>>
#Claude3


🤔Can we assess agents across various apps & OS w.o. crafting new envs?
OSWorld🖥️: A unified, real computer env for multimodal agents to evaluate open-ended computer tasks with arbitrary apps and interfaces on Ubuntu, Windows, & macOS.
+ annotated 369 real-world computer tasks
5
53
181
6
37
155
🚀Instructor🚀embeddings recently hit 2M downloads on
@huggingface
! Now, excited to introduce 🚀GritLM🚀, the first SINGLE LM achieving SoTA in BOTH text embedding (MTEB) & generative tasks (BBH etc)! Great team effort w.
@Muennighoff
&
@hongjin_su
!
📰: 👇


Introducing GRIT🦾to unify text embedding 🔢& generation 📝. GritLM is open SoTA on embedding (MTEB) & generative tasks (BBH etc.) – Both in 1 model. See 🧵for how GRIT🦾 makes RAG >60% faster & more
📜
💻
1/12

10
139
569
2
34
134
📢📢 Play with our Binder demo: !
Binder: an easy but sota neural-symbolic built on GPT-3 Codex & SQL/Python interpreter.
Inject GPT-3 Codex prompt API calls in programming languages!
A new way to work w. LMs!
Binder, an easy neuro-symbolic paradigm:
1.Parse input➡️SQL/Python bound w. GPT3 Codex API calls
2.Codex+PL interpreter execute➡️answer
No train&few-shot!➡️SOTA
🆚chain-of-thought: interpretable&robust⬆️
🆚NL2Code: coverage⬆️
10
73
292
2
22
129


Using LLMs for coding in new or evolving languages?
We introduce:
1⃣new code generation benchmark that MUST consult code docs/tutorials
2⃣new multi-hop code generation method actively retrieving diverse resources: 28%📈 ChatGPT & 23.8%📈 in CodeLLama!
👇


How to adapt LLMs for code 🖥️ to updated libraries and long-tail programming languages w/o training? 🤔
We introduce Arks ⛵️, Active Retrieval in Knowledge Soup, a general pipeline of retrieval-augmented generation for code (RACG). It features:
1️⃣A diverse knowledge soup

2
32
111
0
20
126
Exciting to see the rise interest in 🎉LLM + Code + Robotics + RL🎉!
This year, multiple concurrent work for text to RL reward code generation for robot control:
Happy to see this interdisciplinary effort!
@DrJimFan
Congrats Jim and your team for this fantastic work!! 🌟 Our team has also delved into a similar direction, leveraging LLM to automate the generation of dense reward code functions. Hope it can also provide insights to the community!
🔗 Project:
📄 Paper:

3
14
93
1
19
82
We just open-sourced 🚀
#Lemur70B
! 🚀: the SOTA open LLM balancing 📚text & 💻code capabilities!
1⃣Pretrain Llama 2 on ~100B code-focused data
2⃣Finetune Lemur on ~300K examples
Download the models 🤗:
See more details👇


8
25
76
Come check out our
#emnlp2019
paper "CoSQL: A Conversational Text-to-SQL Challenge Towards Cross-Domain Natural Language Interfaces to Databases" today at 4:30-6pm poster session! The data and leaderboard are available at .

4
23
71
If you are interested in LLM + tool use or tool augmented LLMs ⚙️ 🤖️⚒️, come and join us. we will cover this topic in our complex reasoning
#ACL2023NLP
tutorial!

Heading to
#ACL2023
🚀 My collaborators
@megamor2
@billyuchenlin
@michiyasunaga
@aman_madaan
@taoyds
and I will be presenting a cutting-edge tutorial on Complex Reasoning in Natural Language - diving into recent methods for accurate, robust & trustworthy reasoning systems🤖 1/2
2
11
49
2
7
68
Check out our
#EMNLP2018
paper with
@radevd
"Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task" introduces a new text-to-SQL dataset! The data and blog available at and !

0
25
64

DS-1000 () code generation data format has now been simplified and hosted on
@huggingface
datasets.
1⃣Simplified format:
2⃣DS-1000
@huggingface
:
Credits:
@halfrot01
and
@sidawxyz

💥New benchmark💥
DS-1000, a data science code generation benchmark with 1K questions about 7🐍libraries. Spent ~1200 expert hours!
It is the only one that
1⃣ focuses on everyday applications
2⃣ includes natural intents & contexts
3⃣has test cases
1/🧵
5
69
289
0
9
49
@kaiwei_chang
@jieyuzhao11
@GabrielSaadia
@acbuller
@Lianhuiq
@ManlingLi_
@yuntiandeng
@rajammanabrolu
@YueDongCS
@tanyaagoyal
@MinaLee__
@alsuhr
@wellecks
@hllo_wrld
@Xinya16
Amazing list of ✨! Hong Kong also has seen rapid growth in NLP lately, including:
Lingpeng Kong
@ikekong
,
Junxian He
@junxian_he
,
Qi Liu
@leuchine
,
and myself🥳!
0
2
43
Exciting time to work on computer agents! Though their research is still in the early stage, the potential is limitless. 🚀

I‘ve been dreaming of having my own "Jarvis" since years ago after the first Iron Man movie. Now I've finally brought my own version to life.
Introducing OS-Copilot: A Framework for Generalist Computer Agents
Paper:
Website:
3
43
237
0
2
33
thanks for sharing! the paper actually got pretty good reviews. 😎
anyway, yes, it has been downloaded 🔥~700K🔥 in ~1/2 year, used by 🚀>2k🚀 open source github projects!
great work from our XLang NLP Lab
@XLangAI
led by
@hongjin_su
and
@WeijiaShi2
!


one note for NLP people about findings vs main conference: the Instructor paper () was accepted to ACL as Findings (i.e. not the main conference)
but every startup practitioner I talk to that has a GPU and cares about performance uses Instructor embeddings
2
19
95
1
5
30
Thanks for attending! Big credit to Niklas Muennighoff
@Muennighoff
and Hongjin Su
@hongjin_su
!

The best contributed paper on GRIT, presented by Tao Yu, is a nice contribution to doing RAG, but not exactly AGI.
The quality of the speech captioning makes AGI seem quite distant indeed….
#ICLR2024

3
14
106
1
4
44
ACCEPTED to
@ACL2019_Italy
: 2 papers about Yale text-to-SQL Spider task (leaderboard: ) and our paper introducing the new context-dependent text-to-SQL SParC challenge with
@ryanzhumich
@VictoriaLinML
@CaimingXiong
@RichardSocher
@radevd
! Coming up soon!
0
7
28
Semantic Parsing (SP) evaluation has been a long-standing problem. Our
#emnlp2020
paper (w.
@ZhongRuiqi
& Dan Klein) introduces a new metric that evaluates the predicted parse over multiple test suites. It is now the official metric of Spider, SParC, and CoSQL (+8 more SP data)!





Our
#emnlp2020
paper() approximates the semantic accuracy of semantic parsing models by comparing the predicted meanings for “multiple possible worlds” rather than the logical forms. It is now the official metric of SPIDER, SParC, and CoSQL.
1
3
18
0
8
28
🚀🚀🚀update: OpenAgents () is now on !

💥OpenAgents💥: an OPEN platform for language agents in the wild
Analyze data, call plugins, control your browser as ChatGPT Plus, but with OPEN Code for
1⃣Easy deployment
2⃣Full stack
3⃣Chat Web UI
4⃣Agent methods
5⃣…
Code:
👇
5
70
223
0
5
28
Come check out our
#acl2019nlp
paper introducing the new Cross-domain Semantic Parsing in Context (SParC) text-to-SQL challenge today (10:30-12:10pm, 7/31) at Poster Session 6A!
Joint work with
@ryanzhumich
,
@VictoriaLinML
,
@CaimingXiong
,
@RichardSocher
,
@SFResearch
, and
@radevd
!
3
10
28
@goodside
Cool work! you might find our related work interesting to you, which binds GPT-3 Codex API calls in SQL/Python to resolve some complex questions. Check out our demo:
📢📢 Play with our Binder demo: !
Binder: an easy but sota neural-symbolic built on GPT-3 Codex & SQL/Python interpreter.
Inject GPT-3 Codex prompt API calls in programming languages!
2
22
129
0
0
26
#NLProc
students who plan to attend
#ACL2023NLP
: Apply to the student volunteer program! Deadline approaching in less than a week. It covers your conference registration fee in exchange for a few hours of work. Also, an good opportunity to network with fellow NLPers!

📢 Call for Student Volunteers 📢
#ACL2023NLP
is looking for student volunteers to help us with conference activities (both online and in-person).
Checkout the call for more details.
#ACL2023Toronto
#NLProc
1
27
48
1
2
25
Please consider donating to help Drago’s family. Any amount will be greatly appreciated! 🙏

2
7
21

📣 By formulating dialog state tracking as Text-to-SQL semantic parsing, In-Context Learning with Codex achieves impressive performance on MWoZ!

In-Context Learning can solve hard dialogue understanding tasks —- when you frame the dialog task correctly.
We find that by reframing dialogue state tracking into Text-to-SQL, and with a smart retriever, LMs get SOTAs on MultiWOZ without any training!🚀

4
9
72
1
2
23
🧵Lemur-70B-chat stands out as the top-performing open-source LLM, rivaling ChatGPT across a broader spectrum of tasks when compared to other available open-source LLMs.
4/6 Lemur-chat significantly outperforms other open-source supervised fine-tuned models across various dimensions.

1
2
7
0
5
22
All the slides of in our complex reasoning
#ACL2023NLP
tutorial are available at
A paper collection on LLM + tool use ⚙️ 🤖️⚒️ and code generation are available at . PRs welcome if we've overlooked your work!

1
4
20
Happening in 30 minutes!
@TianbaoX
and
@ChenHenryWu
will be giving an oral talk about UnifiedSKG and some recent works on leveraging GPT-3 Codex for structured knowledge grounding!
Please join us in the semantics session, Hall A-B, 11 am.
I'm also at
#EMNLP2022
. Happy to chat!
1
3
20
UnifiedSKG () is one of the shared tasks at SUKI! We provide strong but simple unified sota code and models for 21 tasks that involve structured knowledge. Also, there is another interesting shared task FinQA on financial data! Participations welcome!👇


Hello World! Structured and Unstructured Knowledge Integration (SUKI) workshop at
#NAACL2022
is welcoming submissions and shared task participations🙌! Papers due by April 8. Two shared tasks due by June 8 with cash awards🥰. Details are available 👉

1
16
32
0
3
16
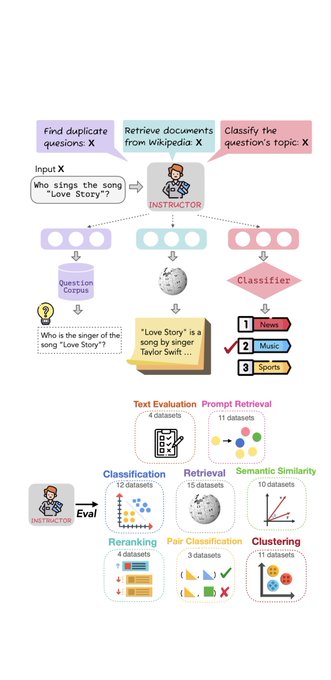
Instructor👨🏫:ONE embedder, ANY task! Led by
@hongjin_su
&
@WeijiaShi2
By simply providing a task instruction (❌training), a SINGLE instruction-finetuned👨🏫model
🥇generate domain-specific & task-aware text embeddings
🥈sota on 70 embed eval tasks
Try🤗:


🙋♀️How to present the same text in diff. tasks/domains as diff. embeddings W/O training?
We introduce Instructor👨🏫, an instruction-finetuned embedder that can generate text embeddings tailored to any task given the task instruction➡️sota on 7⃣0⃣tasks👇!
12
115
598
0
1
15
thanks for sharing our work!
OpenAgents is now among one of the most popular open-source projects on Github trending !
OpenAgents code:


OpenAgents - an open platform for using and hosting language agents in the wild.
Includes three agents:
- a Data Agent for data analysis
- a Plugins Agent with 200+ daily API tools
- a Web Agent for autonomous web browsing
paper:
code:

3
115
587
0
2
12
🪘🪘🪘If you want to learn about teaching LMs (ChatGPT/Codex) how to use code interpreters ⌨️and other tools/models 🔧🔨🪚 to resolve concrete tasks.
Welcome to join us and have a meetup with my students
@TianbaoX
and
@ChengZhoujun
at
#ICLR2023
!
🎺"Binder: Binding Language Models in Symbolic Languages" is here
#ICLR2023
on 5/3 (Wed) today!
Join our talk by
@ChengZhoujun
and me at 3:00 pm in AD10 and poster at 4:30 pm at
#57
!
website:
code:
demo:
0
3
19
1
0
12
Led by
@TianbaoX
&
@ChenHenryWu
. Joint work with Peng Shi
@ZhongRuiqi
@tscholak
@michiyasunaga
@jasonwu0731
Ming Zhong
@pengchengyin
@sidawxyz
@hllo_wrld
@bailin_28
Chengzu Li, Connor Boyle
@ZiyuYao
Dragomir Radev
@CaimingXiong
@ikekong
,
@ruizhang_nlp
@nlpnoah
&
@LukeZettlemoyer
1
0
12
You can even apply Binder on multi-modal inputs(text, tables, and images). We explore using Binder on MultiModalQA and it performs better than Codex end2end QA and the fine-tuned baselines, even comparable with SOTA using oracle retrieved contents.
6/8

1
1
10
In the future, Binder is easily open to extensions to:
▪ new domains/tasks (e.g., knowledge base, pure text)
▪ new programming languages (e.g., SPARQL, more domain-specific symbolic languages)
▪ new LM API call functionalities (e.g., summarization, VQA)
7/8
2
0
10
Does Codex memorize solutions from the web? It does!
On numpy-100 (repeated >3K times on GitHub), Codex-002 performance drops from 72.5➡️40.6 after simple edits, w\o changes in difficulty.
So we edited problems in DS-1000 to proactively defend against memorization.
4/🧵

1
2
9
It is a nice blog on text-to-SQL evaluation. Actually, we have improved the original execution based or exact match metrics in this paper: (test-suite accuracy, led by
@ZhongRuiqi
, code: ).


Is Text-to-SQL evaluation really aligned with human preference? In this post I explore an alternative evaluation metric that more accurately match model performance in practice. Check it out to see how different GPT models perform!
4
25
168
1
0
9
Led by
@ChengZhoujun
&
@TianbaoX
. Joint work with
@ShiPeng16
,
@chengzu_L
, Rahul Nadkarni,
@huyushi98
@CaimingXiong
, Dragomir Radev, Mari Ostendorf,
@LukeZettlemoyer
&
@nlpnoah
from
@uwnlp
,
@uwcse
,
@allen_ai
,
@SFResearch
,
@Yale
, &
@MetaAI
8/8
0
0
9
I'm grateful to many mentors, collaborators, and friends for their support and advice! Special thanks to Dragomir Radev, Kathleen McKeown,
@LukeZettlemoyer
,
@OwenRambow
, and
@CaimingXiong
!
0
0
8
We benchmark all tasks in UnifiedSKG using T5 with very little task-specific modification. To our surprise, it achieves SOTA on almost all tasks! Larger models are better, and we expect the trend to continue.

1
0
8
Big congrats! Yale gets another
#NLProc
faculty🥳

0
0
8
Binder can achieve SOTA performance on question answering (WikiTableQuestions) and fact verification (TabFact), with only a few in-context annotated exemplars (no training)! Prev. best systems all require fine-tuning over massive amounts of data.
3/8

1
0
8

#NLProc
#AI4Code
GPT-3 Codex is possible to generate INTERACTIVE multi-vis interfaces📈 (not just static simple plots!) from natural language queries!
Check out our demo below! Work led by
@Yiru__Chen
@sirrice
.
Stay tuned for fancier ones!

No programming, No learning curve! We can now generate INTERACTIVE multi-vis interfaces from NL queries!
Yes! Directly from NL!
Check this demo below. I will also give a talk on this next Sat in the NLVIS workshop
@IEEEVIS
.
Paper:
1
3
45
0
0
7
Time to read iclr submissions :)
Tired of searching for keywords on openreview to explore the iclr2024 submissions. Spent some time writing code to dump the paper list from openreview and create some visualizations, collaborating with chatgpt and
@nomic_ai
.
AI tools have indeed changed our way of working.

4
27
162
0
0
8
@ryanzhumich
@VictoriaLinML
@CaimingXiong
@RichardSocher
@SFResearch
@radevd
Paper:
Data, models, and leaderboards for text-to-SQL challenge series:
1. Spider:
2. SParC:

0
0
8
Because we have unified the architecture, we are now able to do multi-task learning! Multi-task prefix-tuning benefits most tasks and significantly improves the overall performance. We conjecture the reason to be knowledge sharing and cross-task generalization.

1
0
7
Finally, we conduct a comprehensive error analysis across SKG tasks. We find 1) Although the errors made by PLMs decrease with the model size, T5-3B may still generate invalid outputs. 2) Automatic metric is not sufficient for certain tasks. Find more details in the paper!

1
0
6

Looking forward to meeting you at HKU!

Upcoming seminar at the University of Hong Kong, Thursday 4/18. Looking forward to meeting new and old friend! 🇭🇰

1
4
43
0
0
7
Structured Knowledge Grounding (SKG) tasks were studied by different communities, leading to divergent architectures and implementations. Unification decreases barriers for newcomers and encourages methods that generalize across tasks. UnifiedSKG unifies 21 tasks into Seq2Seq.

1
0
7
DS-1000 construction includes
1⃣ selected and rewrote problems from StackOverflow
2⃣ perturbed the problems to defend against potential memorization
3⃣implemented a customized evaluation metric for EVERY SINGLE PROBLEM
Very labor intensive. Took five authors ~1200 hours!
2/🧵

1
0
6
Wow, Exciting!!!

This is huge: Llama-v2 is open source, with a license that authorizes commercial use!
This is going to change the landscape of the LLM market.
Llama-v2 is available on Microsoft Azure and will be available on AWS, Hugging Face and other providers
Pretrained and fine-tuned
422
4K
16K
0
0
5
Binder is highly ROBUST to large or noisy inputs! End2end QA performance drops dramatically as table input size increases (-42.0%), while Binder consistently outperforms it with only slight decreases (-13.3%). A similar phenomenon is seen given noisy inputs as distractors.
5/8

1
0
5
UnifiedSKG allows us to systematically investigate structured knowledge encoding and obtain insights generalizable across tasks. Though T5 reaches SOTA on most tasks, it is still sensitive to the encoding method. We need more robust encoding methods in the future!
1
0
5
Congrats, Jungo! 🎉🚀🔥

Exciting life updates! Nori (
@noriyuki_kojima
) and I co-founded Kotoba Technologies, Inc. (
@kotoba_tech
), which develops LLMs for businesses in Japan and non-English speaking countries. We have a Tokyo office in Roppongi and are expanding day by day with new projects and members.
5
27
175
0
0
5
UnifiedSKG is still challenging for zero/few-shot learning. T0/GPT-3/Codex all struggle to reach satisfactory performance. We need future research to adopt those models to encode structured knowledge!

1
0
5
Last year's highlights include:
for robotic task planning and beyond!
0
0
4
0
0
4

INTERPRETABILITY of the Binder program (deterministically execute it to derive the answer/prediction) can assist fine-grained error analyses and human debugging (more explicit error causes).
4/8

1
0
4
Also for the applicants: ACL registration is open, but please💥DO NOT💥register before June 5th. We will send an email to all applicants by June 5th to inform you of our decision. 1/2
1
0
3
Co-led by Yuhang Lai, Chengxi Li, Yiming Wang,
@Tianyi_Zh
, and
@ZhongRuiqi
; Joint work with
@LukeZettlemoyer
@scottyih
@dan_fried
@sidawxyz
from
@uwnlp
@stanfordnlp
@BerkeleyNLP
@LTIatCMU
@MetaAI
.
2
0
3
Joint work with
@ryanzhumich
,
@VictoriaLinML
,
@tnzsh
,
@michiyasunaga
,
@alexfabbri4
,
@CaimingXiong
,
@RichardSocher
,
@SFResearch
,
@wslasecki
, and
@radevd
!
1
0
3
DS-1000 contains 1K problems from 451 unique StackOverflow problems.
Compared w. other datasets, DS-1000 is the only one that
1⃣ focuses on everyday data science applications
2⃣ includes naturalistic intents and contexts
3⃣has a reliable execution-based evaluation metric.
5/🧵


1
0
3
Successful applicants will receive a registration discount code to waive your registration fee. If you are not selected, you will still be able to register at the early registration rate. 2/2
0
0
2
To evaluate our automatic metric, we check whether it can reject incorrect solutions. The authors manually reviewed ~3 THOUSAND Codex-002 example predictions and found that our metric is reliable. Among all solutions it accepts, only 1.8% of them are wrong.
3/🧵

1
0
2
We used DS-1000 to benchmark five pre-trained code models from three different families. The best model Codex-002 Insertion achieves 43.3% accuracy, indicating room for improvement.
6/🧵

1
0
2
@JunjieHu12
@HKUniversity
@ikekong
@uwnlp
@nlpnoah
Thanks, Junjie for the advice during the search. Hope you have a great start at UWM!
0
0
1
@jasonwu0731
Thanks, Jason! It was great working with you. Let me know when you visit HK again!!😃
0
0
1
@CaimingXiong
@HKUniversity
@ikekong
@uwnlp
@nlpnoah
Thank you, Caiming! Very fortunate to be advised by you.😀
0
0
1