

Arman Cohan
@armancohan
Followers
2,293
Following
818
Media
13
Statuses
348
Assistant Professor of CS @Yale Research Scientist at AI2 @allen_ai NLP/AI Research
New Haven, CT
Joined June 2015
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Rosé
• 529795 Tweets
西田敏行さん
• 344228 Tweets
Sinwar
• 246142 Tweets
Bluesky
• 206331 Tweets
ブルスカ
• 193931 Tweets
スーパームーン
• 179640 Tweets
ブルースカイ
• 176888 Tweets
#わたしの宝物
• 176305 Tweets
ツイッター
• 142787 Tweets
JOURNEY CONCEPT PHOTO
• 114999 Tweets
タイッツー
• 87856 Tweets
インスタ
• 85280 Tweets
Kabir Is God
• 84879 Tweets
EFM X JACK AND JOKER
• 76993 Tweets
ILL BE THERE IN 7 DAYS
• 71922 Tweets
ログイン
• 62545 Tweets
#يحيي_السنوار
• 60240 Tweets
블루스카이
• 55705 Tweets
LINGLING MYCHERIE AMOUR EP9
• 38335 Tweets
ALRIGHT TPOP STAGE
• 27602 Tweets
#まふまふ誕生祭2024
• 21957 Tweets
غير مدبر
• 19794 Tweets
冬月くん
• 18627 Tweets
RADWIMPS
• 18246 Tweets
#TOBE緊急生配信
• 16831 Tweets
ミスキー
• 15196 Tweets
ふっかさん
• 14419 Tweets
個人サイト
• 13380 Tweets
mixi
• 11155 Tweets
ابو ابراهيم
• 10601 Tweets




















Pinned Tweet

✨Some personal news✨
I am very excited to share that I am joining Yale University
@YaleCompsci
@YaleSEAS
@Yale
as an Assistant Professor of Computer Science in Jan 2023! I'm looking forward to new connections and extensive collaborations
@Yale
in
#NLProc
,
#AI
, and beyond! 1/4
70
12
440
📢 My lab at Yale is looking for a postdoc to work on LLMs/NLP for health.
This is a unique collaboration with a health startup focusing on both cutting-edge AI research and real-world impact to tackle domain-specific challenges of LLMs. Pls help spread the word!
1/2 🧵

3
83
327
SPECTER document embedding model is now accessible through
@huggingface
transformers.
The example below compares similarity scores between 4 papers: BERT, GPT3, RoBERTa, and a clinical paper.
More details:


4
45
207
These findings from the Pythia paper () by
@BlancheMinerva
@haileysch__
et al., are fascinating:👇
Finding 1- Deduplication of training data shows no clear benefit, contrary to literature.
1/5 🧵
3
26
162
Finding it hard to keep up with the zero- and few-shot learning (FSL) literature in
#NLProc
?
Join us at our
#ACL2022
@aclmeeting
tutorial on FSL. w/
@i_beltagy
@sewon__min
@sameer_
@rloganiv
we will review and discuss the latest developments on FSL and (L)LMs. 1/2
2
29
156
Our LongEval paper just received an outstanding paper award at
#EACL2023
🏆
LongEval provides a way to improve inter annotator agreement while minimizing annotator workload in challenging task of long form summarization
Great work by
@kalpeshk2011
and the team! Details below👇

Happy to share that LongEval received an outstanding paper award 🏆 at
#EACL2023
! Thanks to
@eaclmeeting
and our reviewers for the support!
Interested in improving human evaluation of long text? See our paper, code and thread 👇
6
31
203
3
3
81
Also in🇸🇬for
#EMNLP2023
. Excited for the conference & reconnecting with friends/colleagues. Some updates:
🌟Yale is looking for assistant profs, NLP/AI is an area of focus. Happy to chat if you are on job market.
🌟I'm hiring PhD students & a postdoc. Pls reach out if interested.
0
8
75
I am at
#NAACL2022
! We are presenting 4 papers at the conference 🧵👇
If you are there, ping me and I'd love to chat about all things NLP, including LLMs, few-shot learning, generation, summarization, and Sci-NLP.
2
2
65
Instead of defaulting to GPT embeddings, for scientific papers you can use SPECTER2, which works much better for science domain!
Discover more in our
#EMNLP2023
paper👇
Kudos to project lead
@aps6992
and stellar team
@SemanticScholar
, Mike D'Arcy
@_DougDowney
@SergeyFeldman

Exciting news from
@SemanticScholar
! Introducing SPECTER2, the adaptable upgrade to SPECTER. Learn about its advanced features and SciRepEval, the new benchmark for scientific document embeddings. Check it out:
#EMNLP2023

2
32
144
0
4
64
Arrived in Bangkok for
#ACL2024
. Excited to catch up with old and new friends!
We, with collaborators, are presenting several papers on evaluation, long-context QA, semi-structured data, and contamination. 👇

1
4
55
Here we go Toronto 🇨🇦! Excited to be at
#ACL2023NLP
and connect with familiar faces and meet new ones. Come say hi!

2
0
50
With SciBERT, we achieve new SOTA results on a broad set of scientific and biomedical NLP tasks with minimal task-specific architectures.
w/
@i_beltagy
and
@kylelostat

Pleased to release my work with
@armancohan
and
@kylelostat
on SciBERT; a BERT model for scientific text trained on the
@SemanticScholar
corpus. SOTA results on multiple scientific domain nlp tasks.
paper:
repo:
3
46
137
1
10
47
Finally a model that uses sliding window attention!

Mistral 7B is out. It outperforms Llama 2 13B on every benchmark we tried. It is also superior to LLaMA 1 34B in code, math, and reasoning, and is released under the Apache 2.0 licence.
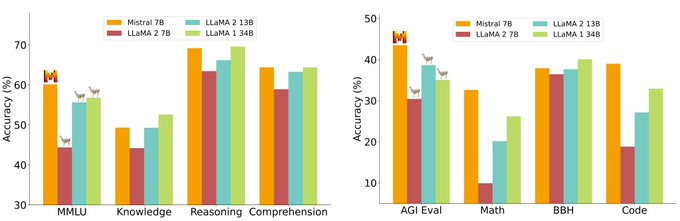
51
479
3K
1
2
49
Our team
@allen_ai
is hiring! Consider applying if you are interested in
#AI
research on scientific literature and beyond. Broad interests across
#NLProc
,
#machineleaning
,
#HCI
, IR and CV.

0
6
46
Shocked & heartbroken by the loss of Prof.
@dragomir_radev
, a dear colleague, friend, mentor & pioneering NLP/AI expert at
@Yale
. His groundbreaking research influenced countless NLP/AI practitioners, including myself. He has been a true inspiration. Sad day for
@yale
&
#NLProc

The
#AI
community, the
#computerscience
community, the
@YaleSEAS
community, and humanity have suddenly lost a remarkable person,
@dragomir_radev
- kind and brilliant, devoted to his family and friends... gone too soon. A sad day
@Yale
@YINSedge
@YaleCompsci
#NLP2023


41
87
387
0
3
42
Interested in data contamination in LLM evals, detection methods, memorization and recall, mitigation strategies, impacts on eval?
@ChunyuanDeng
and
@YilunZhao_NLP
's survey exactly covers these questions and a lot more. Details in thread below👇

🔎 Uncover the spectrum of data contamination in our latest
#ACL2024
Findings paper! Our paper dives deep into the impact, detection, and mitigation of this sneaky issue. As the subarea of faithful evals, contamination is quite complex, sneaky but also attractive. Details - 🧵

2
10
42
1
1
39
As
#LLM
/
#AI
research becomes increasingly proprietary, it's more critical than ever for the open-source community and academia to push for open, transparent, highly capable and state-of-the-art
#LLMs
.
Excited to be a small part of this big project:
Today we're thrilled to announce our new undertaking to collaboratively build the best open language model in the world: AI2 OLMo.
Uniquely open, 70B parameters, coming early 2024 – join us!
34
194
660
0
1
37
Happy to announce that our work on Learning Document-level Embeddings with Citation-informed Transformers was has been accepted to
#acl2020nlp
@aclmeeting
. With
@SergeyFeldman
@i_beltagy
, Doug Downey,
@dsweld
.
Preprint and code coming up soon.
2
5
36
Interested in long document NLP? Join us tomorrow at 8am PDT for our
#NAACL2021
tutorial. We cover many interesting material on sota methods as well as practical guides. 👇

Please join us tomorrow for
#NAACL2021
tutorial "Beyond Paragraphs: NLP for Long Sequences". Two live QA sessions and videos. Schedule, videos, and code at: With
@i_beltagy
@armancohan
@sewon__min
@HannaHajishirzi

0
15
82
1
12
33
⭐ Checkout our new work on Instruction-following summarization evaluation of LLMs👇

Excited to share our work on "Benchmarking Generation and Evaluation Capabilities of LLMs for Instruction Controllable Summarization"! As LLMs excel in generic summarization, we must explore more complex task settings.🧵
Equal contribution
@alexfabbri4

1
13
60
0
1
33
Longformer: our new Transformer for long docs replacing full quadratic self-attention with a linear self-attention pattern. Pretraining analysis on long doc nlp tasks, multiple sota results in char lm and qa. w/
@i_beltagy
@mattthemathman
summary below:
Excited to share our work on Longformer, a scalable transformer model for long-document NLP tasks without chunking/truncation to fit the 512 limit.
Work with
@mattthemathman
,
@armancohan
Code and pretrained model:
Paper:
(1/3)
4
115
401
1
5
28
Hallucinations is still a challenge in text generation.
Check out our new work on improving factuality of text generation models through fine grained loss truncation. Led by Yale undergrad
@ljyflores38
! Will be presented at
@eaclmeeting
#eacl2024
👇

1/5 New paper 🔔: A reason for hallucinations in generative models is training them on noisy text gen datasets, where the target text is not well-aligned with the source. In our
#EACL2024
paper, we introduce Fine Grained Loss Truncation, an approach to improve factual consistency
2
1
13
1
1
26
Excited that our 2 papers got accepted at
#emnlp2019
:
- Pretrained language models for sequential sentence classification
- SciBERT: A pretrained language model for scientific text
2/2 papers accepted to appear at
#emnlp2019
- SciBERT, , w/
@kylelostat
,
@armancohan
- "Pretrained Language Models for Sequential Sentence Classification", w/
@armancohan
,
@danielking36
,
@bhavana_dalvi
,
@dsweld
2
13
52
2
1
27
Dear NLP community. Please consider contributing if you can, to support Drago's family.
#NLPRoc
0
7
27
New
#acl2020nlp
paper: We show that pretraining Transformers on inter-document relatedness signals results in improved doc-level representation learning.
paper:
w/
@SergeyFeldman
@i_beltagy
Doug Downey
@dsweld
1
5
25
Tomorrow 10/10, at 9am EST, we will have an exciting guest lecture by
@i_beltagy
in my Foundations Models course at
@Yale
!🌟
Iz is going to tell us about challenges/opportunities of building Open LLMs.
If interested, DM for a Zoom link!
1
1
24
We are presenting the following @
#ICML2024
this week:
- Observable Propagation: Uncovering Feature Vectors in Transformers in LLMs
@jacobdunefsky
- NExT: Teaching Large Language Models to Reason about Code Execution
@AnsongNi

0
4
24
Our paper has been selected as a winner of the "Best Long Paper Award" at
#emnlp2017
! w/
@andrewyates
.

3
2
23
Today we are releasing:
SciTülu models: Open LLMs up to 70B for science tasks
SciRIFF resource: a large training and eval resource for instruction following for science.
lead by
@davidjwadden
@shi_kejian
Checkout thread below for details👇

Introducing SciRIFF, a toolkit to enhance LLM instruction-following over scientific literature. 137k expert demonstrations in 5 categories: IE, summarization, QA, entailment, and classification; models up to 70b and code to science-tune your checkpoints included! Read more in 🧵:

1
32
106
1
1
23
Checkout our new work lead by
@kalpeshk2011
on improving human evaluation in long form text generation.👇
Human feedback plays a critical role in evaluating and aligning LLMs. However, evaluating long generated text is challenging, high-variance & expensive.
We present the LongEval guidelines to improve human evaluation of faithfulness in long summaries.
1/👇

2
55
275
0
1
19
Text diffusion models have certain desirable properties compared with autoregressive models including maintaining a global view of the sequence they want to generate. Check out TESS, our new work on text diffusion lead by
@KarimiRabeeh
👇

1/8 Excited to share the result of my internship at
@allen_ai
with
@armancohan
@i_beltagy
@mattthemathman
@JamieBHenderson
@hamishivi
@jaesungtae
. We propose TESS: a Text-to-text Self-conditioned Simplex Diffusion model

1
22
136
0
1
19
I will be recruiting students and looking for collaboration opportunities! I am attending
@aclmeeting
(Dublin in May),
@naaclmeeting
(Seattle in July), and
@emnlpmeeting
(Abu Dhabi in December) over the next several months, and would be happy to chat! 3/4
1
4
19
We plan to cover a variety of topics including:
-Prompting and in-context learning
-Grad-based LM task adaptation
-Param efficient finetuning
-Learning from descriptions
-
Evaluation
-Continued pretraining/meta-training
-Scale
-Pretraining objectives & model architecture
2/2
1
2
18
✨New preprint on code llm eval! Systematic investigation of contamination in code evaluation benchmarks. Led by Martin (yale undergrad) &
@AnsongNi
👇

HumanEval & MBPP are top datasets in evaluating LLMs for code. Despite common suspicion of contamination, quantifying it is hard as it would require massive pairwise comparison between the examples in datasets and the pretraining corpus – and we’ve done exactly this🧵👇
In this

1
13
69
0
0
18
Our
#Naacl2019
paper on citation intent prediction with
@waleed_ammar
. SOTA on the ACL-ARC dataset as well as our new dataset SciCite using a multitask model incorporating structure of scientific papers into citations.
Paper:
Code:
0
3
17
Finding 2- Contrary to some prior work, Parallel attention & MLP sublayers doesn't degrade performance at small scale. So these should be used by default.
Recall parallel attn:
`y = x + MLP(LN(x)) + Attn(LN(x))`
instead of regular attn:
`y = x + MLP(LN(x + Attn(LN(x)))`
2/5
1
0
16
#LLMs
can outperform SOTA fine-tuned smaller models on summarization.
But the reference summaries in many datasets aren't perfect.
In new work led by
@YixinLiu17
, we show that if we train smaller models on better reference summaries they match the performance of LLMs! Details👇
📣New preprint out: ! We propose a new paradigm for text summarization models where Large Language Models (LLMs) become the gold standard reference. Result? Smaller models match LLM performance under LLM evaluation!🚀 Learn more:

1
6
67
0
2
16
Check out our new work on Open Domain Multi-Document Summarization, lead by
@johnmgiorgi

New 📄🚨 Multi-document summarization (MDS) assumes docs are given 📚. But in many practical settings, we don't know what to summarize! All we have is a user's information need 🙋💡; docs have to be retrieved. We dub this: "open-domain MDS" 🧵👇 [1/6]

2
10
74
0
0
15
This is a reminder that it is always crucial to follow the data, challenge assumptions, and remain open to new evidence, esp in a fast-moving field. Hope to see more work shedding more light into some of these findings.
6/6
0
0
16
Introducing QAmden, our new pre-training approach for addressing multi-document tasks, to appear in
#ACL2023
.
QAmden excels in both short (Q&A) and long (summarization) text generation tasks, even outperforming GPT-4. Checkout
@clu_avi
's thread for details👇

Meet 🏘️QAmden🏘️ your new effective general multi-document model📄📄📄
In our
#ACL2023
paper, we propose a new and effective QA-based multi-document pre-training method, specializing in multi-document inputs!
w/
@mattthemathman
@JacobGoldberge1
Ido Dagan
@armancohan
1/n

3
20
43
0
1
15

If you are at
#naacl2019
, come to my talk tomorrow (Wed) at 2:40 to hear about how we use auxiliary tasks to overcome limited training data in citation intent prediction. paper:
0
4
14
Finding 3. The LM "curse of multilinguality" which causes per-language performance to drop as they cover more languages is minimal and inconsistent!
They conclude: some of the literature on the curse of multilinguality may need to be revisited using more diverse benchmarks.
4/5
1
1
13
Exciting results from initial round of TREC COVID search; our work is the the top scoring system in the leaderboard among 140+ submissions
#COVIDSearch

Exciting results from Round 1 of TREC-COVID! Cross-domain transfer from MS-MARCO using SciBERT works really well for ranking on COVID-19 queries (run1,2,3), from 143 total submissions. Work with
@armancohan
and Nazli Goharian. Pre-print coming soon.

4
1
37
1
5
13
ABNIRML, our new work on analyzing behavior of neural ranking models. Tl;dr in thread ⬇️
Using BERT, T5, or similar as a ranking function? What language characteristics do these models care about? What could go wrong?
With
@SergeyFeldman
, Nazli Goharian,
@_DougDowney
, and
@armancohan
, we investigate this in our new pre-print ABNIRML:

1
5
34
0
1
12
If you are at
#emnlp2019
, check out our poster today (Session 7) on "Pretrained LMs for Sequential Sentence Classification" and chat with my awesome coauthor
@i_beltagy
0
1
11
Check out our new mechanistic interpretability work for explaining certain LLM issues like gender bias, to be presented at
@icmlconf
.
It's a data-free method and requires no training. Checkout
@jacobdunefsky
's thread below for details👇

🧵Introducing Observable Propagation (ObProp): a *data-free* mechanistic interpretability method for finding feature vectors in LLMs, to be presented at
#ICML2024
! We use ObProp to pinpoint the mechanisms underpinning real-world problems in LLMs such as gender bias. (1/n)
1
2
12
0
1
10
Our paper
#NAACL2018
paper "A Discourse-Aware Attention Model for Abstractive Summarization of Long Documents" is now on arXiv: .
#NLProc
0
1
10
Happy that our paper on Citation Intent Prediction (with
@waleed_ammar
,
@MVZisMVP
and
@FieldCady
) got accepted at
#naacl2019
! preprint coming soon.
0
0
9
Tables are (usually) much simpler and easier to read/interpret for many benchmarks.

Please no more radial plots!
• linear improvement, but area grows quadratically ➡️ overestimate perf
• hard to label axis ➡️ no quantitative use
• overlapping colors ➡️ poor accessibility
consider a bar chart or a table instead 🙏


17
18
158
0
1
10
Super excited to introduce PRIMERA at
#acl2022nlp
, our new pre-trained model for multi-document summarization, with sota results in zero/few-shot and fully supervised setting. 👇👇👇

(1/2) Excited to announce that our paper 'PRIMERA: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization' has been accepted to the main conference of ACL 2022! Great thanks to my collaborators!
@armancohan
@i_beltagy
@careninigiusepp
3
3
30
0
2
10
Our paper "A discourse-aware attention model for abstractive summarization of long documents" got accepted to
#naacl2018
!
The camera-ready version coming soon!
#NLProc
0
1
10
If you are at
#acl2020nlp
, come chat with us about our paper Specter; we have two QA sessions tomorrow w/ my coauthors
@SergeyFeldman
@i_beltagy
@_DougDowney
@dsweld
Mon July 6th (session 4A, 10-11am, session 5B, 2-3pm PT)
Paper:
0
4
10
Honored to receive the Dr. Karen Gale exceptional PhD student award!
Congratulations to
@armancohan
(and his advisor Nazli Goharian!!) for winning the 2017-2018 Dr. Karen Gale Exceptional PhD Student Award!!! (cc:
@ophir
,
@abdur
)

0
0
10
0
0
10
Now that the
#EMNLP
arxiv deadline is over, consider signing to pause/end the ACL anonymity period rule.

There were many supportive responses to this, and also similar tweets from others. I think it is time we make it official and start collecting "signatures". I created this web form.
Do fill it if you support a change!
And do spread it in other channels
11
47
100
0
1
10
Background: The Palm paper () found parallel attention+MLP to be 15% faster but degrades quality at models with <8B parameters.
3/5
2
1
9
Finding 4- Phase shift during pretraining: After 65K training steps (~130B tokens) models > 2.8B exhibit a correlation between task accuracy and occurrence of task-relevant terms which is not present in prior checkpoints and is largely absent from smaller models.
5/5
1
0
9
Check out Yixin's new work on better understanding reference policies in aligning LLMs using DPO👇
DPO is widely used to better align SFT LLMs with human preferences. However, its effectiveness is often limited by the KL-divergence constraint tied to the SFT model. In our new study, we closely examine DPO’s behavior, focusing on the significance of the reference policy through

2
22
95
0
0
9
FLEX: the 1st Few-shot benchmark unifying all transfer types, w/ variable shots, no dev data at testing & rigorous sampling design.
UniFew: New simple model w/out any complex prompt engineering, verbalizers, hyperparam search & custom algorithms seen in prior work. Details ⬇️


📢New preprint:
*FLEX: Unifying Evaluation for Few-Shot NLP*
- rigorous FSL/meta-learning
#NLProc
benchmark measuring 4 transfer types
- simple baseline w/out heavy prompt engineering / complex meta-learning methods
w/
@armancohan
,
@kylelostat
,
@i_beltagy
1/n
2
23
67
0
1
9
Paper details 👇
- Long context QA: lead by
@clu_avi
.
- Multi-Cite: lead by
@anne_lauscher
@kylelostat
.
- MultiVerse: lead by
@davidjwadden
- Aspire: lead by
@MSheshera
@Hoper_Tom
1
1
9
Huge thanks to my amazing mentors
@dsweld
@_DougDowney
@HannaHajishirzi
Nazli Goharian, Ophir Frieder, and my amazing collaborators at
@SemanticScholar
and
@ai2_allennlp
without whom this journey wouldn't have been possible. 4/4
2
0
8
If interested, please check out below for more details and the simple application from:
Please feel free to ping me for questions!
2/2
0
0
8
Congrats
@macavaney
,
Working with you was wonderful. Well deserved!
I'm delighted to have received the
@allen_ai
Intern of the Year Award! It was wonderful working with
@armancohan
,
@SergeyFeldman
, and
@_DougDowney
during my internship--- as well as the rest of the
@SemanticScholar
team!
6
0
79
0
0
8
Working on NLP/ML/AI in the scientific/biomedical domain and have some cool results to share? Consider submitting an abstract to SciNLP workshop at
@akbc_conf
. Deadline June 7th.
Checkout our program, panel, & awesome lineup of speakers:
#NLProc

SciNLP abstract submission deadline has been extended to June 7, instructions for submission here: Join us June 25,
#SciNLP
workshop
@akbc_conf
#NLProc
0
7
14
0
3
8
Depression and Self-Harm Risk Assessment in Online Forums (awarded best paper at
#emnlp2017
) w/
@andrewyates
#NLProc
0
1
8
Combination of SLEDGE+SPECTER turns out to be very effective at Covid-19 literature search. Topped the round 2 leaderboard in TREC
#covidsearch
zero-shot (automatic) setting!
Exciting results in TREC-COVID Round 2 as well! SciBERT and feedback with SPECTER embeddings, we got the top spot among automatic runs. With
@armancohan
and Nazli Goharian.
0
0
11
0
1
7
"Contextualizing Citations for Scientific Summarization using Word Embeddings and Domain Knowledge" accepted at
#sigir2017
@SIGIR17
!
0
1
6
@maliannejadi
@ecir2017
I wish I'd been there at
#ECIR2017
. Couldn't travel outside US bc of visa. Has been the case for Iranians for long,but worse now :/
0
2
6
Congratulations Dr. Soldaini! Great dissertation talk on Medical Information Retrieval!
@soldni

1
1
6
A nice benchmark for long doc NLP with real tasks

For the longest time, NLP was hard enough that we needn't look beyond a single paragraph to create challenging datasets for our models.
Perhaps it's time to shift our focus to longer contexts?
5
15
135
0
0
6
Also presenting the following papers in the findings session.

1
0
5
Very interesting work on music generation at
#ICLR2019
by Hawthorne et al. They combine a transcription model, a language model, and a MIDI-conditioned WaveNet model to generate 1-minute length of coherent piano music. samples are amazing:
0
0
5
SPECTER is already being used in applications like similar paper recommendation.
This is helpful in discovering relevant papers to a given topic like
#COVID19
. Example application:
0
2
5
Come find us at our talks & poster sessions!
@YilunZhao_NLP
@henryzhao4321
@ChunyuanDeng
@XiangruTang
@AnsongNi
0
0
4
The Specter code and Scidocs eval benchmark are now available:
Specter:
Scidocs:
Paper:
New
#acl2020nlp
paper: We show that pretraining Transformers on inter-document relatedness signals results in improved doc-level representation learning.
paper:
w/
@SergeyFeldman
@i_beltagy
Doug Downey
@dsweld
1
5
25
0
1
4
A nice application of our SPECTER embeddings for
#COVID19
similar paper discovery on the Covidex search engine:

0
1
4
NEWSROOM was one of the best dataset paper presentations!
#naacl2018

Want a good-ol'-fashioned hard copy of the NEWSROOM summarization dataset ()? Find Max Grusky at
#NAACL2018
and get 1.3M article-summary pairs on a bespoke flash drive, limited supplies! -- TALK ON SUNDAY, 11:06 in Empire B
#NLProc

6
19
89
0
0
4
GPT-3. Strong few-shot results using LM.
Largest model with 175B params!
(72 pages paper)

0
0
3
Our paper, "A Neural Attention Model for Categorizing Patient Safety Events" was accepted at
#ECIR2017
.
1
0
3

Great overview article: Recent Trends in Deep Learning Based
Natural Language Processing
1
3
3
@complingy
Thanks Nathan! I'm exited to be coming back to the east coast and it will be much easier to visit dc and Georgetown more often. :)
0
0
3
Nice post on general tips about training/debugging neural nets.
0
0
3
Nice work by
@OpenAI
: large language models trained on large datasets can perform well in a variety of down-stream tasks without any parameter or architecture modification.
0
0
3
Wish
#coling2018
template style had line numbers like ACL/EMNLP for reviewing purposes. In absense of line numbers, It is much less convenient to refer the author to page/section>paragaraph>line.
2
0
2
@soldni
@tensorflow
Good to know! Wanted to switch to their new AttentionWrapper! attention_decoder from the legacy one works though
1
1
2
0
0
2
Great resource for learning about deep latent variable models of text
0
0
2
@manaalfar
Given that anonymity period starts a month before submission due, there should be at least one month time between previous conference notification date and next submission deadline.
0
0
2