

byron wallace
@byron_c_wallace
Followers
1K
Following
2K
Statuses
502
Assoc. Prof @Northeastern in Computer Science. NLP / ML / + Health &etc. he/him.
Joined July 2014
RT @ChantalShaib: headed to miami/#EMNLP2024 next week with this work 🌴🌴 come check out the poster (12/11) and let’s talk about templates i…
0
7
0
RT @ResearchAtNU: How can you tell if text is #AI generated? Researchers at @Northeastern have figured out a new method analyzing sentence…
0
3
0
RT @jadenfk23: 🚀 New NNsight features launching today! If you’re conducting research on LLM internals, NNsight 0.3 is now available. This u…
0
19
0
RT @TerraBlvns: I’m very excited to join @Northeastern @KhouryCollege as an assistant professor starting Fall '25!! Looking forward to work…
0
18
0
RT @_akhaliq: NNsight and NDIF Democratizing Access to Foundation Model Internals The enormous scale of state-of-the-art foundation model…
0
24
0
RT @monicamreddy: 1/10 Excited to share our #BioNLP at #ACL2024NLP paper “Open (Clinical) LLMs are Sensitive to Instruction Phrasings", pa…
0
10
0
RT @TuhinChakr: Finally got to read @ChantalShaib ‘s very cool work on syntactic templates in AI generated text. Sharing some findings; The…
0
5
0
RT @ChantalShaib: There's a general feeling that AI-written text is repetitive. But this repetition goes beyond phrases like "delve into"!…
0
110
0
Sheridan has some cool results on tokenization in LLMs and their "implicit vocabularies"👇

(new preprint) LLMs live in a strange tokenized world. We find that LLMs learn to deal with the weirdness of tokenization by converting tokens into word-like representations and then "forgetting about" those tokens. Maybe this is why tokenization isn't an issue, until it is... 🧵
0
0
11
Somin has some cool results on CoT + distillation👇

📢We know that including CoT rationales as supervision improves model distillation. But why? New work (w/ @silvio_amir and @byron_c_wallace) research unveils surprising insights! 🔗 Full paper: [1/5]
0
3
8
RT @JeredMcinerney: Excited to present our work on interpretable risk prediction tomorrow @ #NAACL2024! Feel free to stop by our poster fro…
0
4
0
+ @HibaAhsan5!

Learn about "Retrieving Evidence from EHRs with LLMs: Possibilities and Challenges" by @JeredMcinerney, @silvio_amir, @byron_c_wallace at #CHIL2024!
0
0
1
RT @hyesunyun: 🤔How close are we to fully automating biomedical meta-analyses? Check out our new preprint (w/ @pogrebits3, @ijmarshall, &…
0
3
0
RT @ResearchAtNU: Aimed at unlocking the secrets of #AI, @Northeastern will lead a groundbreaking research project backed by the @NSF. Rea…
0
3
0
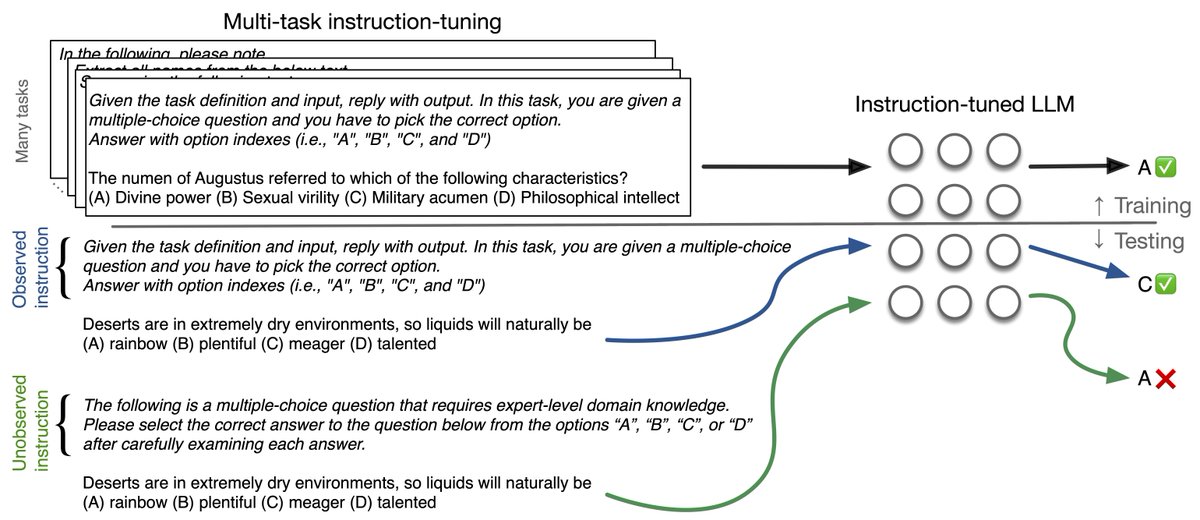
Come chat with me or @ChantalShaib about @SunJiuding's work on the sensitivity of models to instruction phrasings at #ICLR2024 next week ↓

How robust are the instructions in your instruction-tuned model? In our most recent work (w/ @ChantalShaib and @byron_c_wallace), we show that there is a considerable dip in performance on in-domain tasks when you slightly vary the instruction.
0
3
17