
Mostafa Dehghani
@m__dehghani
Followers
6,859
Following
583
Media
128
Statuses
1,711
/google_deepmind/gemini/.
San Francisco
Joined June 2014
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Edmundo
• 263422 Tweets
CHARLOTTE X TIKTOKLIVE99
• 228971 Tweets
#Narin
• 226687 Tweets
ANILPIN WE ARE THE ONE
• 194506 Tweets
#ปิ่นภักดิ์EP6
• 186729 Tweets
#光る君へ
• 108845 Tweets
KIM TAEHYUNG
• 54227 Tweets
プロジェクトKV
• 53756 Tweets
Zapatero
• 50873 Tweets
東京ドーム
• 39376 Tweets
İdam
• 30738 Tweets
Kostic
• 29906 Tweets
ポルノグラフィティ
• 27650 Tweets
SEVENTEEN AT LOLLAPALOOZA
• 21604 Tweets
NFL Sunday
• 15407 Tweets
ماهر الجازي
• 15325 Tweets
源氏物語
• 15153 Tweets
#降り積もれ孤独な死よ
• 14706 Tweets
LESSONS FROM BIU
• 13654 Tweets
Last Seen Profiles





















1/ There is a huge headroom for improving capabilities of our vision models and given the lessons we've learned from LLMs, scaling is a promising bet. We are introducing ViT-22B, the largest vision backbone reported to date:

12
134
801
We're hiring student researchers who are passionate about large scale vision models. Know someone who fits the bill or interested yourself? Let me know, and I'll be happy to share more details!
[Retweets are greatly appreciated.]
99
222
611
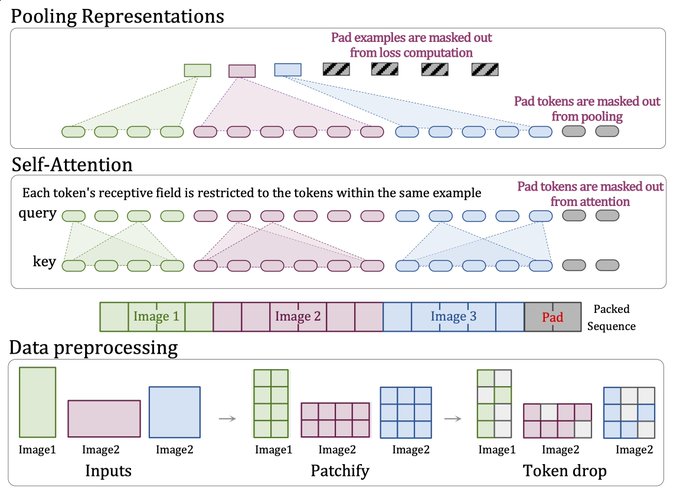
1/ Excited to share "Patch n' Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution". NaViT breaks away from the CNN-designed input and modeling pipeline, sets a new course for ViTs, and opens up exciting possibilities in their development.
13
150
620
A few weeks ago, we open-sourced SCENIC, a JAX library/codebase that we like it a lot and wanted to share our joy with the community.
GitHub:
Paper:

4
56
278
@ysu_nlp
@emilymbender
Thanks for releasing this benchmark! Great effort!
Just for the record, I posted a link when the benchmark was released, and the great
@ankesh_anand
made it available for evaluating Gemini models literally within a few hours! Incredible display of agility for sure! :)

2
7
249
1. Benchmarks are fundamental to track progress in empirical machine learning. In our new paper, we study how benchmarking may affect the long term research direction and pace of progress in ML and put forward the notion of a "benchmark lottery":

4
52
226
We released the code for ViViT as well as the checkpoints of its different variants.
If you are interested in transformers for video understanding, check it out:
Code:
Paper:

3
37
215
If you are at
#ICLR2019
, make sure that you learn about our work, "Universal Transformers", w/
@sgouws
,
@OriolVinyalsML
,
@kyosu
, and
@lukaszkaiser
(Thursday 11am-1pm, poster session at Great Hall BC,
#62
). You can also check out this blog post about UT:

1
43
209
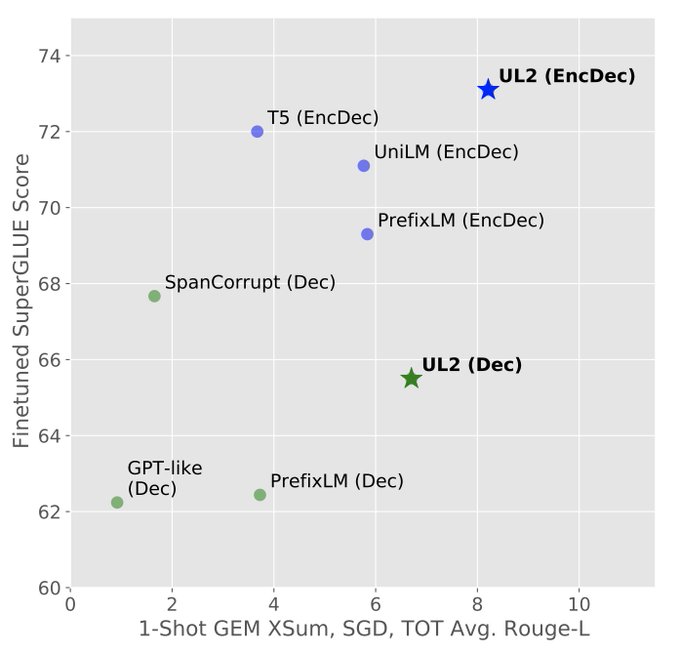
"Whether to go with a decoder-only or encoder-decoder transformer?"
It turned out that this question on the architecture of the model is not actually that important!
You just need the right objective function and a simple prompting to switch mode during pretraining/finetuning.
1
45
208
“How does such a simple objective in LLM training, next-token prediction, result in such remarkably intelligent behavior?”
This question is on everyone's mind, from everyday LLM users to expert researchers.
✨We've got a solid answer!✨

How is next-token prediction capable of such intelligent behavior? I’m very excited to share our work, where we study the fractal structure of language. TLDR: thinking of next-token prediction in language as “word statistics” is a big oversimplification!

14
110
529
5
14
181
This idea:
-is extremely simple,
-works surprisingly good,
-shares a different perspective to neural search and retrieval,
-opens a door to a whole world of new research questions,
-& takes a key step to enable e2e training of retrieval enhanced methods.

1
31
183
Super excited to share what we've been brewing behind the scenes. ♊️
This is just the tip of the iceberg! Get ready for a wave of awesomeness!

We’re excited to announce 𝗚𝗲𝗺𝗶𝗻𝗶:
@Google
’s largest and most capable AI model.
Built to be natively multimodal, it can understand and operate across text, code, audio, image and video - and achieves state-of-the-art performance across many tasks. 🧵
171
2K
6K
4
12
159
It turned out that you only need 8 tokens to be processed by your ViT!
TokenLearner is simple and efficient. Super helpful when dealing with a large number of tokens, like in video modeling.
The code is already available in Scenic:

While Vision Transformer models consistently obtain state-of-the-art results, they often require too many tokens for larger images and video. Read about TokenLearner, which adaptively generates fewer tokens but enables models to perform better, faster →
6
134
606
1
15
140
With
@YiTayML
,
@anuragarnab
,
@giffmana
, and
@ashVaswani
, we wrote up a paper on "the efficiency misnomer":
TL;DR:
"No single cost indicator is sufficient for making an absolute conclusion when comparing the efficiency of different models".

2
27
135
What do you think are the primary limitations or design choices that feel unnatural when it comes to using Transformers for computer vision (images, videos, ...)?

24
10
110
Dual PatchNorm is one of those ideas that is simple (adding literally two lines of code), yet consistently effective. There is also an interesting backstory to it.

While we await GPT-4 which is expected to have a trillion parameters, here are 3072 parameters, that can make your Vision Transformer better.
Paper:
Joint work w/
@neilhoulsby
@m__dehghani

3
11
152
1
8
110
NaViT () sets us free from square boxes and lets us think outside the box! Let creativity flow and go for the natural designs we've always wanted in ViTs.
I share a few cool ideas that are made possible with NaViT:
What do you think are the primary limitations or design choices that feel unnatural when it comes to using Transformers for computer vision (images, videos, ...)?
24
10
110
1
19
107
My hope is to see Mixture-of-Denoisers from UL2 becoming the mainstream objective function for training LLMs. Check out
@GoogleAI
blog post about UL2:
Introducing UL2, a novel language pre-training paradigm that improves performance of language models across datasets and setups by using a mixture of training objectives, each with different configurations. Read more and grab model checkpoints at
18
169
712
4
15
104
Really excited to share that our next speaker at AI-in-the-Loft in Google Amsterdam will be Jonathan Ho. This coming Friday (July 1), Jonathan will talk about Imagine! RSVP if you want to learn about text-to-image diffusion models:
#ai_in_the_loft

4
19
96
Neat observation! This could be another reason why adding extra "read and write tape tokens" helps AdaTape ().


What I mean when I say “registers”: additional learnable tokens (like the [CLS]), but these ones are not used at output. No additional info at input, not used at output: these tokens could seem useless!

2
8
119
0
10
95
@borisdayma
Always gunning for the highest possible LR! Not a fan of lowering LR to get a buttery-smooth loss curve. My stance: models trained on the edge of stability come out stronger. Admittedly, it's like walking on eggshells for massive models, but the payoff is totally worth it!
7
8
120
Learn more about the techniques utilized to scale up ViT to 22B along with an excellent summary of results and notable findings.
Learn about ViT-22B, the result of our latest work on scaling vision transformers to create the largest dense vision model. With improvements to both the stability and efficiency of training, ViT-22B advances the state of the art on many vision tasks →
37
133
553
3
11
98
Our paper, "Fidelity-Weighted Learning" w/
@mehrjouarash
,
@jkamps
,
@sgouws
,
@bschoelkopf
has been accepted at
#ICLR2018
. \o/

7
14
97
I'm starting 2018 with an internship at Google Brain... \o/

5
0
95
Apparently, I'm an influencer now... for reckless neural network training!😬
Just got my first tweet citation:
btw, this report is a must-read!
@borisdayma
Always gunning for the highest possible LR! Not a fan of lowering LR to get a buttery-smooth loss curve. My stance: models trained on the edge of stability come out stronger. Admittedly, it's like walking on eggshells for massive models, but the payoff is totally worth it!
7
8
120
4
6
93
I am at
#ICLR2018
to present our work on learning from samples of variable quality, "Fidelity Weighted Learning" (w/
@mehrjouarash
,
@sgouws
,
@jkamps
, and
@bschoelkopf
). Come to the poster session, Today 11:00am-1:00pm.
paper:

1
16
89
Working on architecture builds a ton of intuition as well. With
@YiTayML
, we spent weeks exploring exotic ideas and their interaction with scale.
I think the next big leap will come from an architecture idea that supports a totally new mode of operating.

Only folks that started large scale DL work after ~GPT-2 think architecture doesn’t matter, the rest saw how much arch work had to happen to get here.
12
15
246
4
5
90
Our paper, "Learning to Learn from Weak Supervision by Full Supervision", with Sascha Rothe, Aliaksei Severyn, and
@jkamps
has been accepted at NIPS2017 workshop on Meta-Learning.
#nips2017
#MetaLearn2017
3
11
88
Check out our new work, "Vision Transformer" for image recognition at scale. So many cool findings... .

We release pre-trained vision transformer models and code for inference/fine-tuning: . There is still a long way towards understanding transformers in vision and I am looking forward to the future research. Hope this release will be a good starting point.

6
102
443
1
17
86
Lengthy lectures? Long-winded novels? Hours-long movies? Gemini 1.5 eats them all like bite-sized snacks! The context tank is bottomless! 🚀
Introducing Gemini 1.5: our next-generation model with dramatically enhanced performance. It also achieves a breakthrough in long-context understanding.
The first release is 1.5 Pro, capable of processing up to 1 million tokens of information. 🧵
47
420
2K
0
5
80
Check out our new paper, presenting insights on scaling Transformers/T5 within the context of the pretraining-finetuning setup.
With
@YiTayML
,
@Jeffy_Sailing
,
@LiamFedus
,
@samiraabnar
,
@hwchung27
,
@sharan0909
,
@DaniYogatama
,
@ashVaswani
, and
@metzlerd
.

3
13
79
Seems fear of not being up-to-second with AI/ML news is making some of us anxious. I noticed in several conversations, when someone shares something new, many often respond with 'I already knew about this' immediately.
Sure, but this doesn't always embrace a culture of learning.
3
4
77
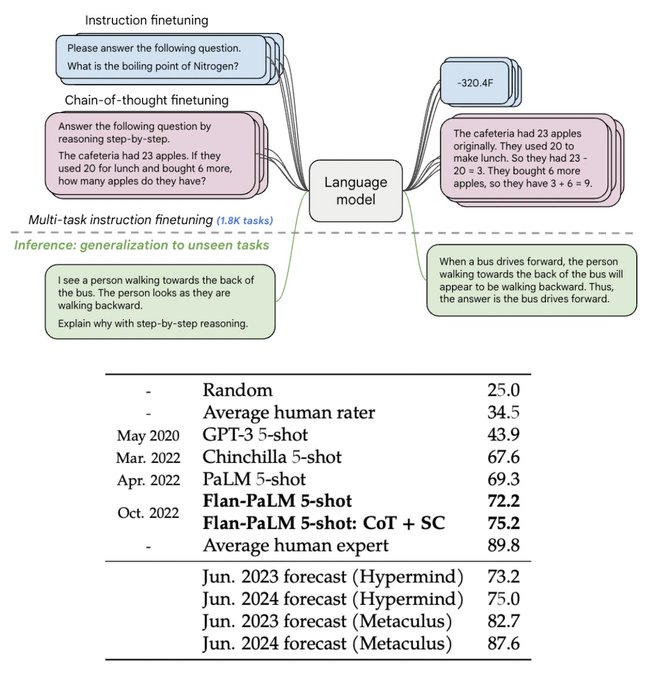
"Flanning" a language model is in fact scaling it up in the "diversity of tasks" axis, which is an important dimension next to scaling model size (parameters), compute (train steps), and data size. We should Flan every LLM we ever trained or will train.

New paper + models!
We extend instruction finetuning by
1. scaling to 540B model
2. scaling to 1.8K finetuning tasks
3. finetuning on chain-of-thought (CoT) data
With these, our Flan-PaLM model achieves a new SoTA of 75.2% on MMLU.
9
64
349
2
13
76
Really excited that after almost two years, we are resuming the "AI in the Loft" events. For the next edition, Wednesday 11 May, we will have
@bneyshabur
as our speaker.
Please RSVP at

2
11
76
Yi leaving us left me feeling down, but the prospect of all the amazing things awaiting him in his next venture fills me with joy!
I will always root you on,
@YiTayML
!

Till we meet again! 🫡🫡🫡
I spent 3.3 years for PhD, 3.3 years at Google.
I am eager to know how much more I can grow in the next 3.3 years ✨🔥.

7
2
111
2
2
74
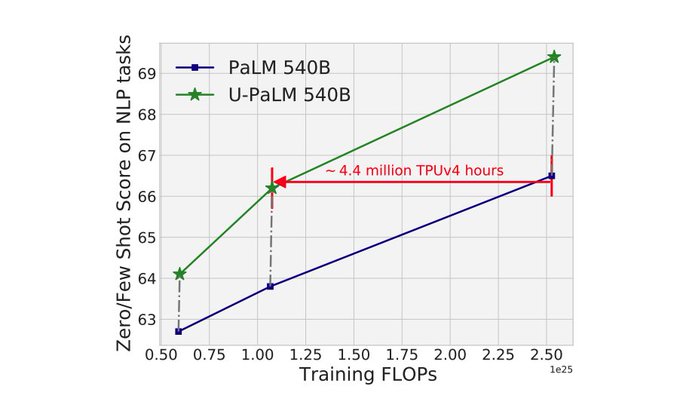
What I like the most in this work is the "reuse" and the amount of compute saved by it. We take a halfway trained PaLM540B, uptrain it with mixture-of-denoisers for ~0.1% of the spent compute, and get a U-PaLM that is as good as a fully trained PaLM.

4
18
74
Read about our work (going to be presented at
#ICLR2018
) on how to learn from samples of variable quality: "Fidelity-weighted Learning", w/
@mehrjouarash
,
@sgouws
,
@jkamps
, and
@bschoelkopf
.
#FWL
#FidelityWeightedLearning
0
24
68
Read more about our paper at
#NIPS2017
Workshop on Meta-Learning,
"Learning to Learn from Weak Supervision by Full Supervision":
#metalearn2017
#nips
#nips17
2
20
69
If you're looking into applying transformers on large inputs (e.g. long documents, images, videos, etc), or if you are working on a new variant of efficient transformers, this should give you a nice overview of the existing works.
Inspired by the dizzying number of efficient Transformers ("x-formers") models that are coming out lately, we wrote a survey paper to organize all this information. Check it out at .
Joint work with
@m__dehghani
@dara_bahri
and
@metzlerd
.
@GoogleAI
😀😃


16
266
875
2
10
67
The release of "UL2-20B" and "Flan-T5" checkpoints was awesome, and now we're taking another step to pave the way for even faster progress in LLM research with the open-sourcing of the new **Flan-UL2-20B** model.
Exciting times!
New open source Flan-UL2 20B checkpoints :)
- Truly open source 😎 No forms! 🤭 Apache license 🔥
- Best OS model on MMLU/Big-Bench hard 🤩
- Better than Flan-T5 XXL & competitive to Flan-PaLM 62B.
- Size ceiling of Flan family just got higher!
Blog:
51
344
2K
0
6
65
"Learning to Transform, Combine, and Reason in Open-Domain Question Answering" w/
@HAzarbonyad
,
@jkamps
, and
@mdr
accepted at
#wsdm2019
.
4
6
65
A great and satisfying part of this project/paper is the release of weights from 170+ models we studied. In the paper, we share insights on scaling transformers and how changing different knobs impact the upstream and downstream vs. efficiency [...]

1
5
62
Most important things that I learned from this work:
Make sure "scaling up" (even a little bit) is one of the experiments/ablations in "every" iteration when developing a new idea!
Scale is cruel to many smart ideas!

0
7
62
Check out the Long-Range Arena (LRA, pronounced 'elra'):
A benchmark for assessing (efficient) Transformer models under long-context scenarios.


1
14
61
Check out Veo—things are getting really exciting!
Introducing Veo: our most capable generative video model. 🎥
It can create high-quality, 1080p clips that can go beyond 60 seconds.
From photorealism to surrealism and animation, it can tackle a range of cinematic styles. 🧵
#GoogleIO
147
948
4K
5
6
60

yey \o/!
Long paper accepted at
#sigir2017
"Neural Ranking Models with Weak Supervision", w\
@HamedZamani
,
@alseveryn
,
@jkamps
, and
@wbc11
10
4
58
Exciting to see the incredible potential of multimodality in these models!
Kudos to
@RekaAILabs
for shipping such unified model so quickly!
It’s been a short 6 months since I left Google Brain and it has been a uniquely challenging yet interesting experience to build everything from the ground up in an entirely new environment (e.g., the wilderness)
Today, we’re excited to announce the first version of the
84
140
1K
1
3
58
Excited that our next "AI in the Loft" at Google Brain Amsterdam (Next Thursday, July 28) will be with
@ada_rob
! Adam will talk about "Encoder-Decoder MLMs FTW". A super cool talk in a warm day!
[Note that this is an in person event.]
Please RSVP at

1
10
55
Bard is live now. Sign up, use it, and help us keep improving it at .

We're expanding access to Bard in US + UK with more countries ahead, it's an early experiment that lets you collaborate with generative AI. Hope Bard sparks more creativity and curiosity, and will get better with feedback. Sign up:
831
2K
9K
1
8
55
Check out the
@GoogleAI
blog post about our recent work, Universal Transformers.
Check out Universal Transformers, new research from the Google Brain team &
@DeepMindAI
that extends last year's Transformer (a neural network architecture based on a self-attention mechanism) to be computationally universal.
10
312
897
1
8
55
There are reasons that students pay less for the registration, but "being easy to be excluded" is not one of them, I believe!
Not cool
@WSDMSocial
!
#wsdm2018
(cc:
@sigir_students
)

3
9
53
1. With NaViT, we can have arbitrary tokenization "per input". Why square patches as tokens? Why not any arbitrary set of pixels based on what your input looks like (you can also get a bit of help from FlexiViT here)?

6
4
53
Very cool to see the VLMs making impact in robotics, RT-2 uses PaLI-X (powered by ViT22B for vision and UL2 for language).

1
9
51
Something that I appreciate about the term "foundation model" is how it draws a comparison to the unimpressive look of a building's foundation to most people. In fact, the foundation itself can be quite ugly and its beauty lies in the potential to build incredible things upon it.
4
4
48
Read about our new work on "training neural netowrks with weak labels by jointly learning the labels' quality":
1
19
48
“If you have to knock down the learning rate as you scale up, your modeling approach is probably bound by instability”
-
@jmgilmer
@borisdayma
Always gunning for the highest possible LR! Not a fan of lowering LR to get a buttery-smooth loss curve. My stance: models trained on the edge of stability come out stronger. Admittedly, it's like walking on eggshells for massive models, but the payoff is totally worth it!
7
8
120
0
2
47
Check out "Universal Transformers". Work done during my internship at
@GoogleBrain
w/
@sgouws
,
@OriolVinyalsML
,
@kyosu
, and
@lukaszkaiser
.

Universal Transformers propose to augment Transformers with Recurrence in depth and Adaptive Computation Time. This model outperforms Vanilla Transformers in MT / bAbI / LA / LTE.
Paper:
Code: Soon in
3
134
369
1
4
46
I was hoping to find an excuse to maybe share a little bit about how fun was working with a large group of people for all of us.
The main ingredient is "awesome people".
** Find them. Work with them. It's endless joy. It's good for your skin! **

@m__dehghani
@arxivmerchant
@neilhoulsby
@PiotrPadlewski
@GoogleAI
@_basilM
@JonathanHeek
Impressive achievement!
Could you tell me how you worked with this tremendous amount of authors? How many of them actually wrote training code?
1
0
3
2
2
45
Super excited to host
@YiTayML
for our next "AI in the Loft" at Google Brain Amsterdam (Next Tuesday, May 31). Yi is going to talk about Universal Models in Language!
Please RSVP at
#ai_in_the_loft

2
5
45
UL2 addresses a critical problem, and I have full confidence that we will see even more remarkable work using it and and tons of follow-up research.
2
4
42
We can now load UL2 20B checkpoints in
@huggingface
Transformers! (Yaaay!)
Thanks for being so awesome Hugging Face!
... and of course a big thank you to
@DanielHesslow
for making this happen!

Huge contribution to the research community by releasing the 20B parameter checkpoint by
@m__dehghani
and
@YiTayML
from
@GoogleAI
❤️
Also a big thank you to
@DanielHesslow
for contributing the model to Transformers🤗
0
15
74
3
7
40

Another fresh idea for increasing capacity of UT by using hyper networks to introduce "modularity" while maintaining recurrence in depth.
Super cool!

Adaptivity (adaptive compute allocation) + Modularity = Better generalization for multi-step reasoning & improved efficiency, even in system-1 tasks like image classification.
Check out our new paper:
1/9

5
73
303
1
5
40
I'm going to present our paper, "Learning to Attend, Copy, and Generate for Session-Based Query Suggestion", from my internship
@googleresearch
. If you're attending
#cikm2017
, you can come to Session 9A (3:45-5:15 pm in Ocean4).
2
2
39
We've been stuck with fixed square resizing for too long and overlooked how unnatural it is. I'm confident that future models, particularly at scale, will break free from this setup, given how easily it can be done and the significant gains it brings!

It bothers me that CIFAR-10, one of the classic foundational datasets for ML, is filled with random aspect ratio pictures forced into squares.
30
20
520
2
0
40
Huge thanks to
@Google
and all the Googlers (many of them from Iran) who are working on ensuring safer access to information from Iran and anywhere in the world experiencing Internet censorship.

Internet outages are happening more frequently worldwide, including in parts of Iran this week. Across Google, teams are working to make our tools broadly available, following the newly updated US sanctions applicable to communications services. 1/5
399
2K
5K
0
6
39
Gemini 1.5 Pro crushes it with 91.1% on Hendryck’s MATH!
Today we have published our updated Gemini 1.5 Model Technical Report. As
@JeffDean
highlights, we have made significant progress in Gemini 1.5 Pro across all key benchmarks; TL;DR: 1.5 Pro > 1.0 Ultra, 1.5 Flash (our fastest model) ~= 1.0 Ultra.
As a math undergrad, our drastic

42
208
1K
0
3
39
We need neural networks that are smarter and more adaptive in terms of allocation of compute (e.g., different amounts of computation for diff. inputs or diff. parts of an input). Checkout out CALM which enables such ability for decoding with Transformers.

Introducing our work
@GoogleAI
CALM: Confident Adaptive Language Modeling 🧘
Large Language Models don't need their full size for every generated token. We develop an Early Exit framework to significantly
#accelerate
decoding from
#Transformers
!
🔗:
🧵1/

24
280
2K
1
6
39
Nice! Someone tried this!
... very cool stuff!
@BlackHC
If someone wants to scale up UT, here's a genius idea: introduce sparsity into the scaled-up UT to add parameters without extra FLOPs.
More parameters + deep recurrence - the hefty price tag = winning combo!💡
3
0
14
2
4
38
Our full paper "Luhn Revisited: Significant Words Language Models" got accepted at
#CIKM2016
w/
@HAzarbonyad
,
@jkamps
, and
@djoerd
.
\o/
3
5
35

11/ One of our favorite observations was the amazing alignment of the ViT-22B with human perception in terms of shape versus texture bias. ViT-22B has the highest shape bias ever recorded for an artificial neural network!

Beyond conventional downstream tasks, we evaluated ViT-22B on human alignment and perceptual similarity. As an emergent property, ViT-22B has the highest ever shape bias of an artificial neural network (close to humans)!
1
7
58
1
5
36
Awesome tutorial by
@phillip_lippe
to master training neural networks at scale using JAX with `shard_map`. There is a lot to learn here!

Do you want to train massive deep learning models with ease? Our 10 new tutorial notebooks of our popular UvA DL course show you how, implementing data, pipeline and tensor parallelism (and more) from scratch in JAX+Flax! 🚀🚀
Check them out here:
🧵 1/11

8
122
593
0
6
35
"Representation Learning for Reading Comprehension", an awesome talk by
@rsalakhu
:

@rsalakhu
's slides for the first workshop on Search-Oriented Conversational AI
#SCAI2017
are available
#ICTIR2017
0
17
44
0
9
35
We'll be giving a tutorial on "Neural Networks for IR" w/
@TomKenter
,
@Alexey_Borisov_
,
@cvangysel
,
@mdr
, and
@UnderdogGeek
at
#sigir2017
!
0
9
34
Enjoyed
@ilyasut
's lecture
"Universal Transformer [...] is a great idea, except that if you want to have a lot of parameters you need to pay for it [...] if you ignore compute costs, it gives you a recipe of how to proceed..."
@BlackHC
If someone wants to scale up UT, here's a genius idea: introduce sparsity into the scaled-up UT to add parameters without extra FLOPs.
More parameters + deep recurrence - the hefty price tag = winning combo!💡
3
0
14
2
2
34
This is exciting that ML researchers come up with different algorithms everyday, but we also know for any learning algorithm, any improvement on performance over one class of problems is balanced out by a decrease in the performance over another class (no free lunch theorem!).
2
5
34
2/ We share the recipe for a very efficient and stable training of large scale ViT, with impressive results. The hope is to inspire efforts on scaling vision models and to pair up our top-of-class vision models w/ our best LLMs, as a vital step of advancing AI, moving forward.
2
1
31
@savvyRL
Regarding the across architectures,
@samiraabnar
has (a paper and) a nice blog post in which she studies distillation as a mean to transfer the effect of architectural inductive biases from CNN to MLP and LSTM to Transformers.

1
4
31
AdaTape shakes things up by bringing in a fresh and distinct perspective for adaptive computation and offers an orthogonal approach the existing idea.
Kudos to
@XueFz
for the incredible work!

1/ Introducing AdaTape: an adaptive computation transformer with elastic input sequence! 🚀
* Flexible computation budget via elastic sequence length
* Dynamic memory read & write for adaptable input context
* Direct adaptive computation enhancement of input sequences
2
24
141
1
4
30
Great to see the taxonomy from is expanded to ViTs. But I wish the evaluation of efficiency go beyond parameters or FLOPs. Using these two as cost metrics could potentially lead to inaccurate conclusions: .


Efficiency 360: Efficient Vision Transformers
Compares various vision transformer models based on their performance, the number of parameters, and the number of floating point operations (FLOPs) on multiple datasets.

0
16
82
0
3
29
Today we are presenting "The Efficiency Misnomer" at ICLR poster session. We have lots of cool observations to share along with some suggestions that we learned by working on many many projects and talking to many many amazing researchers and engineers.
With
@YiTayML
,
@anuragarnab
,
@giffmana
, and
@ashVaswani
, we wrote up a paper on "the efficiency misnomer":
TL;DR:
"No single cost indicator is sufficient for making an absolute conclusion when comparing the efficiency of different models".
2
27
135
0
3
29
Inspired by all the talented students at
@DeepIndaba
. Excited to stay involved in this amazing initiative.
Had a great time with brilliant researchers at Google Accra. This team stands out as the best, driving exciting projects that directly impact lives.

Thanks to DL Indaba we have many ML Research super stars in town. In the excitement I messed up my selfie with Nando :)




4
8
68
0
0
28
ACM blog post about our
#nn4ir
tutorial w/
@TomKenter
,
@Alexey_Borisov_
,
@cvangysel
,
@mdr
&
@UnderdogGeek
at
#sigir2017
1
6
28
Here are the slides of the talk:

@m__dehghani
is presenting our paper: “Learning to Transform, Combine, and Reason in Open-Domain Question Answering” at
#WSDM2019

0
3
19
0
3
26
A draft of our paper "Neural Ranking Models with Weak Supervision" is on arXiv now:
#sigir2017
#neuralnetworks4IR

1
8
27
Yes. The amazing mix of joy, fulfillment, and making a real difference in Gemini excites EVERYONE.
Working with Sergey definitely adds an extra daily splash of fun and inspiration for all of us.

Sergey Brin is worth $105 billion yet he was a core contributor on the Gemini AI technical paper, coding basically every day.
Legend.

144
639
6K
0
0
26
Check out our poster at
#CIKM2016
poster session!
"The Healing Power of Poison: Helpful Non-relevant Documents in Feedback"

0
7
27
A preprint is now available on the arxiv:
Learning to Attend, Copy, and Generate for Session Based Query Suggestion, L-paper accepted at
#cikm2017
, from my internship
@googleresearch
1
1
27
0
6
27
If you're at NIPS, check out our poster in the Meta-Learning workshop's poster session.
#nips2017
#MetaLearn2017
Link to the paper:

0
2
27
+1
@_sholtodouglas
and
@epiqueras1
are definitely rockstars. They're also the source of immense joy and awesome vibes in our team!

A good example is
@_sholtodouglas
at
@GoogleDeepMind
. He's quiet on Twitter, doesn't have any flashy first-author publications, and has only been in the field for ~1.5 years, but people in AI know he was one of the most important people behind Gemini's success
10
37
786
0
0
27
Learning to Attend, Copy, and Generate for Session Based Query Suggestion, L-paper accepted at
#cikm2017
, from my internship
@googleresearch
1
1
27
@chipro
The "recurrent inductive bias" of RNNs usually helps them be more data efficient, compared to vanilla Transformer. If you introduce such a bias to Transformers (like recurrence in depth in Universal Transformers), they generalize better on small datasets:
0
3
24
Extending this survey was a great opportunity for us to learn about the recent developments and see which ideas stood the test of time. Maybe one year from now, we share an updated version to include a new xformer that succeeded to become the mainstream!?
Happy to share that we have updated and published v2 of our "efficient transformer" survey!
Major updates:
✅ Expanded our scope to sparse models and added a ton of new models!
✅ Wrote a retrospective post about the advances in the past year.
Link:

6
70
366
0
4
25
Check out our recent work on Unifying Language Learning Paradigms (UL2: ) with
@YiTayML
, and our amazing collaborators:
@vqctran
,
@xgarcia238
,
@dara_bahri
,
@TalSchuster
,
@HuaixiuZheng
,
@neilhoulsby
, and
@metzlerd
.
1
2
25
Seq2seq model augmented by hierarchical attention and copy mechanism for session-based query suggestion:
#cikm2017
1
4
26
Absolutely love and adore SF for its unmatched beats & bytes combo!

1
2
24
What a fantastic initiative!
In this situation, helping to facilitate more "open exchange of people and ideas" would be the greatest thing that we can do. Read the post on
#OpenScience
by
@mdr
:
2
5
25