

William Fedus
@LiamFedus
Followers
21K
Following
10K
Media
99
Statuses
996
VP of Post-Training @OpenAI Past: Google Brain
San Francisco, CA
Joined October 2012
Happy to release a couple of our reasoning models today (🍓)! At @OpenAI , these new models are becoming a larger contributor to the development of future models. For many of our researchers and engineers, these have replaced a large part of their ChatGPT usage.
57
176
2K
GPT-4o is our new state-of-the-art frontier model. We’ve been testing a version on the LMSys arena as im-also-a-good-gpt2-chatbot 🙂. Here’s how it’s been doing.
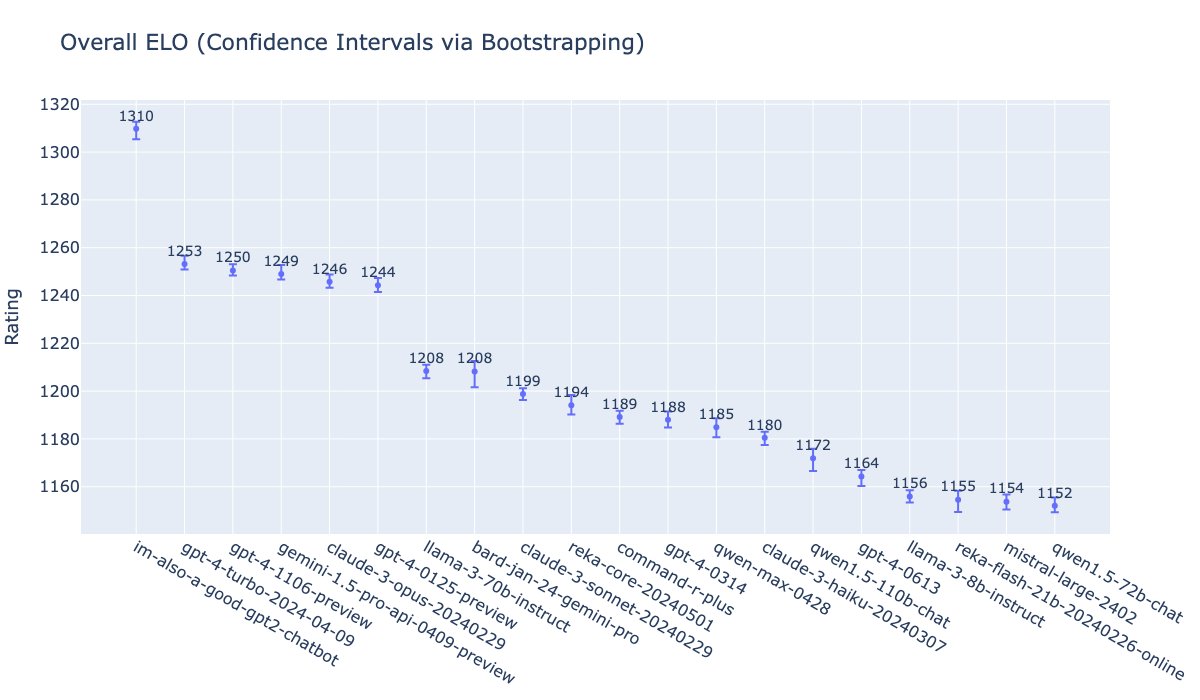
183
880
5K
Was having so much fun, I forgot to Tweet about it: I joined OpenAI!. I’m continuously awed by the people, the technology, and the ambition. We’re just scratching the surface with ChatGPT. If you’re interested, get in touch!.
37
37
1K
Today we're releasing all Switch Transformer models in T5X/JAX, including the 1.6T param Switch-C and the 395B param Switch-XXL models. Pleased to have these open-sourced!. All thanks to the efforts of James Lee-Thorp, @ada_rob, and @hwchung27.
19
200
1K
Not only is this the best model in the world, but it's available for free in ChatGPT, which has never before been the case for a frontier model.
29
64
915
But the ELO can ultimately become bounded by the difficulty of the prompts (i.e. can’t achieve arbitrarily high win rates on the prompt: “what’s up”). We find on harder prompt sets — and in particular coding — there is an even larger gap: GPT-4o achieves a +100 ELO over our prior
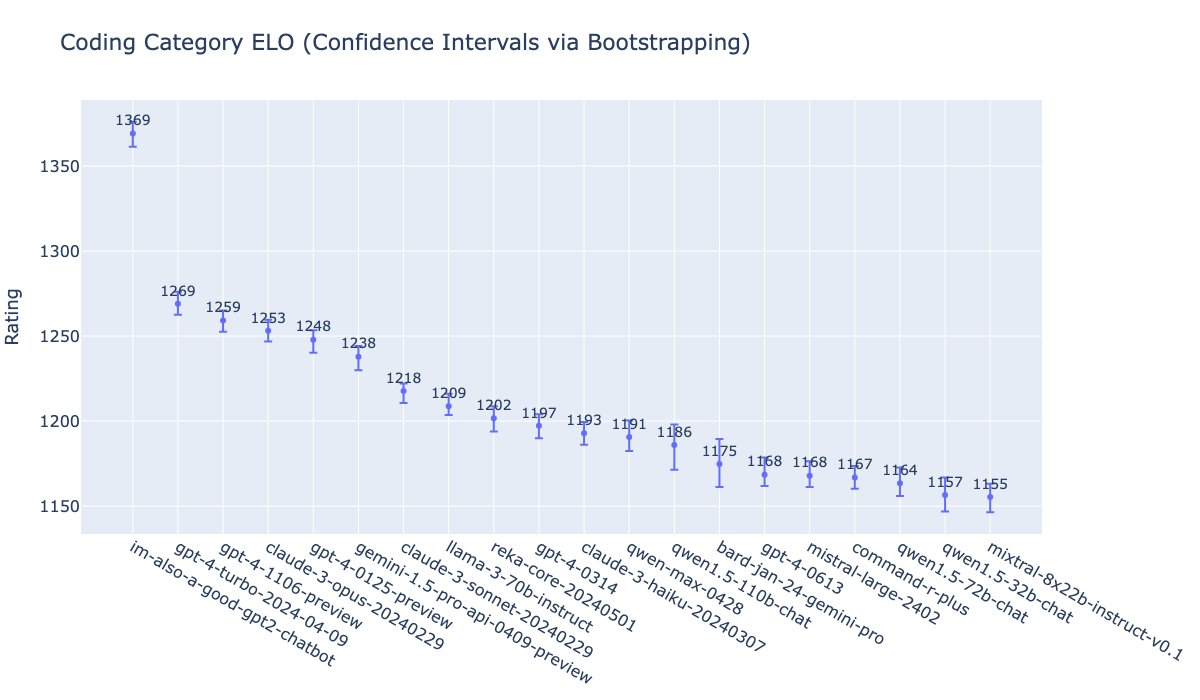
21
87
737
Presenting our survey on emergent abilities in LLMs!. What's it about? Certain downstream language tasks exhibit an interesting behavior: eval curves are flat/random up to a certain model scale, until -- poof -- things start to work. 1/7

20
109
575
As part of today, we’re also releasing o1-mini. This is an incredibly smart, small model that can also reason before it’s answer. o1-mini allows us at @OpenAI to make high-intelligence widely accessible. On the AIME benchmark, o1-mini re-defines the

17
61
453
GPT-4o is the first model to exceed human performance on MathVista.

🚨 BREAKING: @OpenAI's new GPT-4o model outperforms humans on MathVista for the first time!. 📊 Scores: .Human avg: 60.3 .GPT-4o: 63.8. 📖 Learn more:.OpenAI : MathVista:

9
50
431
Pleased to share new work!. We design a sparse language model that scales beyond a trillion parameters. These versions are significantly more sample efficient and obtain up to 4-7x speed-ups over popular models like T5-Base, T5-Large, T5-XXL. Preprint:

11
85
430
Fun following LLM retrieval progress. One recent work is Memorizing Transformers which increases context length up to 262k by an external memory of (keys, values) for that document. - Matches quality of Transformers 5x larger.- Can fine-tune a prior pre-trained models to use it
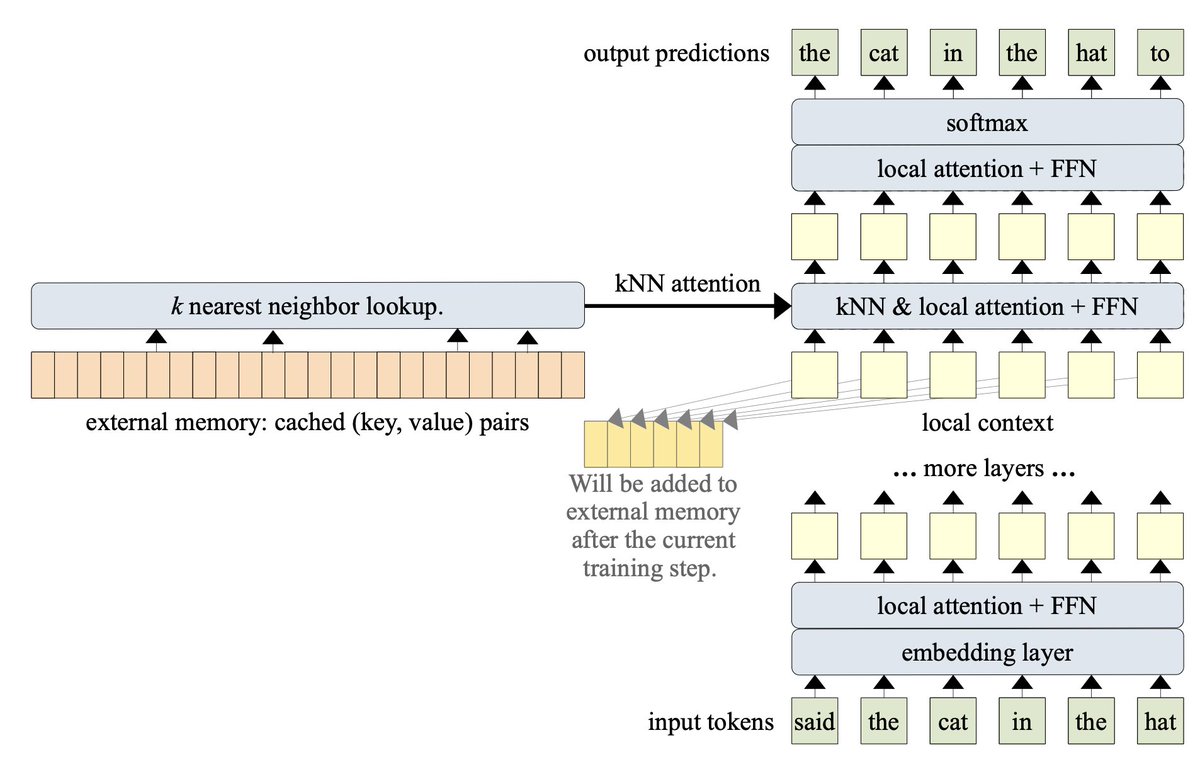
3
62
420
❤️.

i love the openai team so much.
10
14
387
The mysterious LambdaNetwork author(!) finally revealed. Lambdas are an efficient alternative to self-attention. The idea in the terms of attention: lambdas are matrices that summarize a context. These matrices apply to query vectors to model data.

3
72
374
GPT-4o is now up on openai/simple-evals and is setting new SOTA on MMLU, MATH, GPQA, HumanEval. Especially excited for free ChatGPT users. This is a step change over 3.5.
11
57
371
Our survey on sparse expert models describes the advances over the last decade, discusses some difficulties, and presents our view on promising future areas. Sparsity has been a fun area to work on the last two years. Excited for the models to come.

7
71
348
A few years ago, real-time voice translation felt like an incredible piece of tech to design + build. Now, it simply falls out of multimodal training.

They are releasing a combined text-audio-vision model that processes all three modalities in one single neural network, which can then do real-time voice translation as a special case afterthought, if you ask it to. (fixed it for you).
3
22
353
Deep respect for the OpenAI team, who are pulling back-to-back all-nighters negotiating for the company and the employees. Seeing their tenacity and seriousness (but also humor) in dealing with this insanity reveals how they even built this company in the first place.
6
13
330
We've been tinkering to make our models smarter.


20
21
298
This plot is a nice visual representation of a paradigm shift.

No more waiting. o1's is officially on Chatbot Arena!. We tested o1-preview and mini with 6K+ community votes. 🥇o1-preview: #1 across the board, especially in Math, Hard Prompts, and Coding. A huge leap in technical performance!.🥈o1-mini: #1 in technical areas, #2 overall.

13
25
295
Proud to release our last year of work on sparse expert models! . This started over a year ago when we found Switch Transformers pre-trained well, but some variants were unstable or fine-tuned poorly. The new SOTA ST-MoE-32B addresses this.

6
62
282
GPT-4o shifts the world in an important way. I think this potentially creates another “ChatGPT moment” for the rest of the world. Everyone can now access, for free, the best public model that is also intelligently tokenized for non-English languages. It establishes a new.

Biggest actual implication of today's OpenAI announcement is very practical: the top barrier I see when I give talks on using AI is that people don't pay for AI to start, and they use GPT-3.5 (the free model) and are disappointed. Now everyone around the world gets GPT-4 free.
9
15
273
After 6 trillion reminders -- the world gets it -- it's a "large language model trained by OpenAI" 🙃. @tszzl removed this behavior in our next model release to free your custom instructions for more interesting requests. (DM us if it's still a nuisance!).

With the new Custom Instructions: this works in ChatGPT. (Results in the comments).
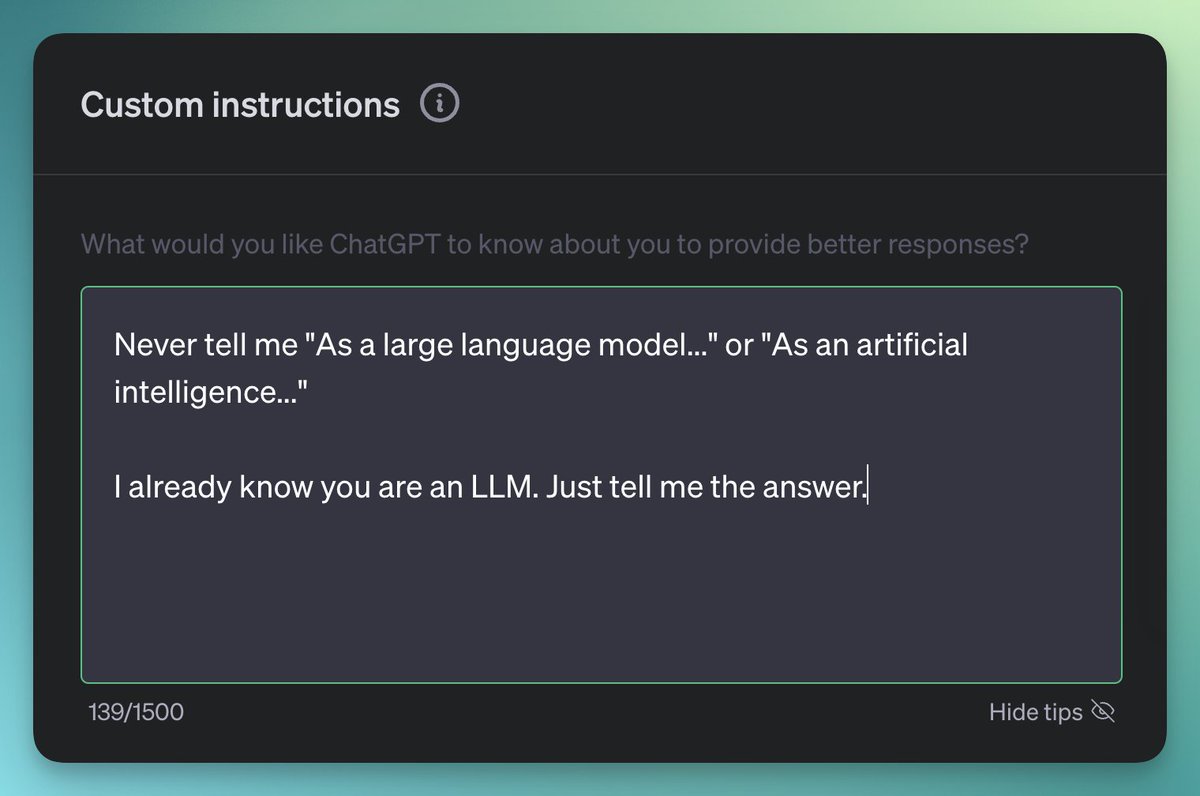
16
16
268
Almost two years after the pre-training of GPT-4 — the field might expect us to be in a strongly diminishing return regime — but we continue to find significant advances and recognize the value of better post-training. It’s not the cherry atop the cake.

1/ Some thoughts on the recent OpenAI and Google announcements, and what it indicates about what's next in AI. Hint: post-training is REALLY important. THREAD.
6
26
255
Two recent algorithms, World Models by @hardmaru and Schmidhuber (2018) and Curiosity by @pathak2206 et al. (2018), have approx. equal performance when a learned module (RNN and embedding in ICM, respectively) is instead left as a fixed randomly initialized module. @_brohrer_.
8
69
241
Reasoning has begun to deliver us better models like o1, o3, o3-mini, but the genuine unlock will be agents. Reasoning gives us better planning, tool-use, error recovery and I’m thrilled for this year. 2025 is the year of agents. Congrats team!!.

Introduction to Operator & Agents.
7
12
247
Releasing voice for ChatGPT for all free users today! Hope you enjoy. (What board coup?).
ChatGPT with voice is now available to all free users. Download the app on your phone and tap the headphones icon to start a conversation. Sound on 🔊
16
10
217
Fresh on arXiv: Hyperbolic Discounting and Learning Over Multiple Horizons . We question the RL paradigm of discounting by a single discount factor, gamma. Modeling many Q-values allows you to hyperbolically-discount and is also a great auxiliary task.
6
44
213
A brief 4 year LLM history:.enc-only (BERT) -> enc-dec (T5) -> dec-only (GPT). As of 2022, the most compute is in decoder models -- what research supports this? Is this the best approach?. Enc-dec: T5, AlphaCode, Switch, ST-MoE, RETRO.Dec-only: GPT-{1,2,3}, {🐭, 🐹}, PaLM.
9
34
212
In Revisiting ResNets, we disentangle the impact of (1) architecture, the (2) training methodology, and the (3) scaling strategy. In a surprise, when we refresh ResNets (introduced in 2015), they still rival state-of-the-art!.

2
30
211
Introducing our most recent language model: 🌴. My favorite part of scaling these models is how predictable upstream scaling may hide unpredictable, significant jumps in downstream capabilities (e.g. reasoning).

Introducing the 540 billion parameter Pathways Language Model. Trained on two Cloud #TPU v4 pods, it achieves state-of-the-art performance on benchmarks and shows exciting capabilities like mathematical reasoning, code writing, and even explaining jokes.
4
28
211
It takes an army. Today we're delighted to release BigBench🪑: 200+ language tasks crowd-sourced from *442* authors spanning 132 institutions, plus, our analysis. BigBench is the result of the ingenuity + cleverness of the community.

2
52
196
@pmddomingos @tszzl I can’t speak to his ML theory, but @tszzl is one of the most important contributors to ChatGPT.
5
1
184
The speed and intelligence (plus reduced laziness) of GPT-4o enable more interesting multi-turn use-cases such as acting as the CPU of an LLM OS and agentic tasks.

5
22
182
Neat new modular neural net: Branch-Train-Merge. Unlike usual sparse models, this splits an LLM (branch), trains experts on different datasets (train), then collapses to a single model (merge). Quality on par with models with 2.5x more compute!.

3
25
185
We’re back.
We have reached an agreement in principle for Sam Altman to return to OpenAI as CEO with a new initial board of Bret Taylor (Chair), Larry Summers, and Adam D'Angelo. We are collaborating to figure out the details. Thank you so much for your patience through this.
3
2
178
An improved Switch Transformer version is up on JMLR!. We were seriously impressed by the JMLR review quality and I personally love being untethered to the conference-cycle (publish when ready). Thanks reviewers and to our editor, @alexandersclark!.

3
23
169
Better late than never. Dopamine Tensorflow code now available for RL agents that learn over multiple time-horizons and can model alternative discount functions. @carlesgelada @marcgbellemare @hugo_larochelle.
0
30
156
In addition to o1-preview and o1-mini, our 4o models keep getting better! New models in LMSys and in ChatGPT.
Chatbot Arena update🔥. We've been testing the latest ChatGPT-4o (20240903) over the past 2 weeks, and the results show significant improvements across the board:. - Overall: 1316 -> 1336.- Overall (style control): 1290 -> 1300.- Hard Prompts: 1314 -> 1335.- Multi-turn: 1346 ->

5
10
157
Our improved model in the arena at lmsys and we’ve rolled out to ChatGPT users today — stay tuned for better versions to come.
🔥Exciting news -- GPT-4-Turbo has just reclaimed the No. 1 spot on the Arena leaderboard again! Woah!. We collect over 8K user votes from diverse domains and observe its strong coding & reasoning capability over others. Hats off to @OpenAI for this incredible launch!. To offer

10
14
152

Insane generations from Parti! A bit more fun looking at samples across model sizes, than at log-log scaling curves.

2
19
125
Happy birthday, ChatGPT. The world is different one year later. Humbling to predict product and consumer trends. The outside world probably thinks we're all joking, but this actually was our “low-key research preview” as we geared up to align + release GPT-4. It’s hard to.
a year ago tonight we were probably just sitting around the office putting the finishing touches on chatgpt before the next morning’s launch. what a year it’s been….
4
3
116
+1. I’ve been incredibly fortunate that @barret_zoph has been my closest collaborator for many years now. In addition to doing crazy cool things, he pushes others to do them too. MJ-vibes.

Barret Zoph, who presented the OpenAI demo, has done many crazy cool things in the last decade. One that remember is that as an undergrad in 2015, he wrote his own neural translation system. in CUDA. Remember finding that pretty impressive at the time.
3
3
118
Our unsupervised graph algo: Mutual info maximization learns strong node representations that on node classification tasks at times exceeds *supervised* algos! . Fun work with very talented collaborators @PetarV_93, @williamleif P. Liò, Bengio, Hjelm

3
30
114
I have yet to find a well-defined task that cannot be optimized by these models. Eval improvement like ARC AGI showcase this dynamic.

So we went from 0 to 87% in 5 years in ARC AGI score. There is no wall it seems. GPT-2 (2019): 0%.GPT-3 (2020): 0%.GPT-4 (2023): 2%.GPT-4o (2024): 5%.o1-preview (2024): 21%.o1 high (2024): 32%.o1 Pro (2024): ~50%.o3 tuned low (2024): 76%.o3 tuned high (2024): 87%

7
9
117
GPT-4 is released today! . This model has become an integral part of my workflow since joining OpenAI (coding, learning, etc.). Try it on #ChatGPT Plus and tell us what you think! .
6
17
113
❤️.

I deeply regret my participation in the board's actions. I never intended to harm OpenAI. I love everything we've built together and I will do everything I can to reunite the company.
2
3
105
o1-mini limits now expanded by 7x!.
We appreciate your excitement for OpenAI o1 and we want you to be able to use it more. For Plus and Team users, we have increased rate limits for o1-mini by 7x, from 50 messages per week to 50 messages per day. o1-preview is more expensive to serve, so we’ve increased the rate.
3
5
103
In 'Benchmarking Bonus-Based Exploration Methods in ALE' we find that when standardizing training duration, architecture, model capacity - new methods do not clearly improve over prior baselines. Work led by @aalitaiga which received ICML exp. workshop 2019 best paper award!
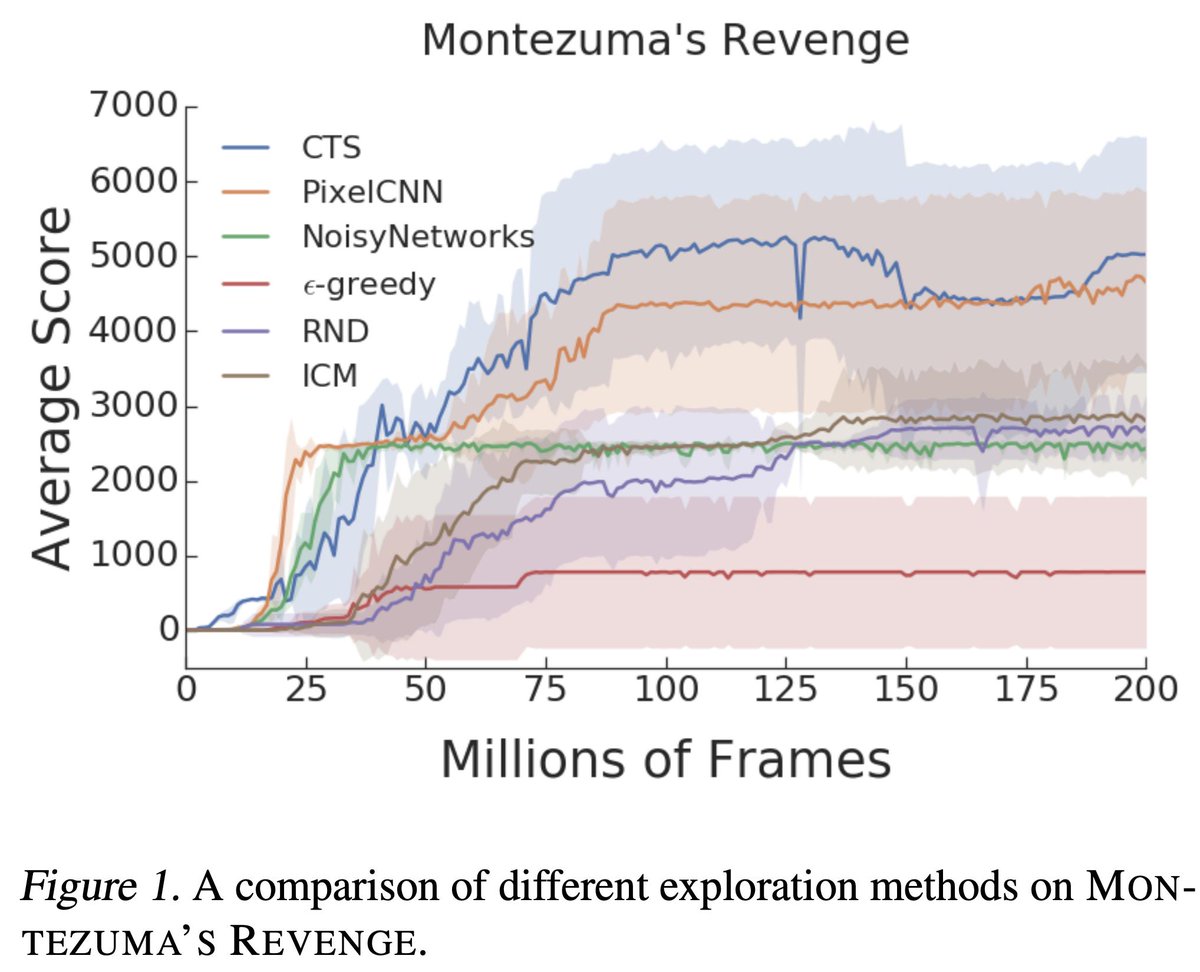
2
20
98
Congrats to the team and many of my past colleagues at Google! Another step forward in AI.

I’m very excited to share our work on Gemini today! Gemini is a family of multimodal models that demonstrate really strong capabilities across the image, audio, video, and text domains. Our most-capable model, Gemini Ultra, advances the state of the art in 30 of 32 benchmarks,


3
0
82
GPT-4o mini is out today! There is a new frontier cramming ever more intelligence + capability into ever tinier models.

Introducing GPT-4o mini! It’s our most intelligent and affordable small model, available today in the API. GPT-4o mini is significantly smarter and cheaper than GPT-3.5 Turbo.

1
6
85
Don’t dismiss old methods too quickly. ResNets are still strong baselines when augmented with modern improvements. Thanks for the shout-out, @OriolVinyalsML.

The Deep Learning Devil is in the Details. I love this work from @IrwanBello and collaborators in which they show how training "tricks" improve ~3% absolute accuracy on ImageNet, progress equivalent to years of developments and research!. Paper:
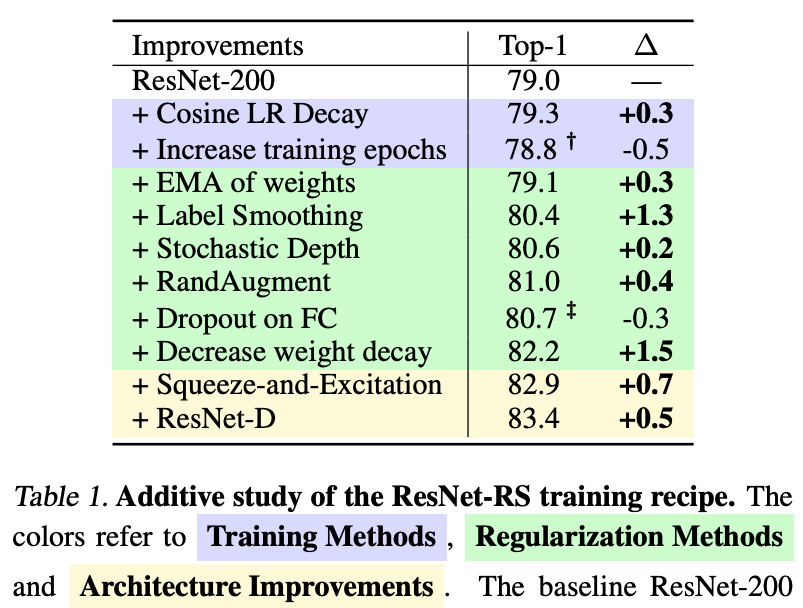
0
11
85
Advanced models with full context that sit at the level of the user is a key paradigm shift. Future workflows won’t include copy-and-pasting to The ChatGPT MacOS app is a first step — access with the Option + Space shortcut and begin work.

The new ChatGPT Mac app is amazing. I got a fully working Breakout game code using a shortcut to pull up the app with GPT-4o and a simple screenshot of my screen. So many use cases and faster workflows.
4
8
84
*Chiming in on the GPT-4 is getting dumber meme*. The code evals in the paper penalized GPT-4 for markdown (```) which is used for nice display in ChatGPT UI, even when the model got _better_. This eval instead surfaced an opportunity for improved instruction following.

@matei_zaharia @james_y_zou June GPT-4 started surrounding code with ```python markdown, which you didn't strip. I forked your code, removed that markdown, and re-submitted the output to Leetcode for judging. Now the June version does significantly better than the march version of GPT-4.

2
10
83
Significant progress in Ahn et al, 2022. Definitely got crowded out by the release of DALL-E2/PaLM that week. A compelling prospect is that this robotic-interaction data might improve LLM's common sense, understanding of physics, and general helpfulness.

4
9
80
New blog post from Jason on evals. With insufficiently good evals, progress is blocked. Some ideas were only later found to be good once our evals improved. Great evals are especially key in post-training when there is no singular metric that can be hill-climbed.

New blog post where I discuss what makes an language model evaluation successful, and the "seven sins" that make hinder an eval from gaining traction in the community: Had fun presenting this at Stanford's NLP Seminar yesterday!

0
10
77
The interplay of RL algorithms with experience replay is poorly understood. We study this and uncover a relationship between n-step returns and replay capacity. ICML '20 paper: Prajit R.*, @agarwl_ , Yoshua, @hugo_larochelle , Mark R., @wwdabney

1
14
75
We've released a conversational version of GPT. Talk to it here!.

Just launched ChatGPT, our new AI system which is optimized for dialogue: Try it out here:
6
2
69
In our recent paper we connect RL issues of poor sample complexity and exploration difficulties to catastrophic interference (within an environment). @its_dibya* @jdmartin86, @marcgbellemare, Yoshua, @hugo_larochelle .*joint-1st author.
4
19
72
Looking forward for workshops tomorrow - my favorite part of #NeurIPS. @its_dibya and I will speak about the MEMENTO observation in Atari agents tomorrow at 4:15 in the BARL workshop. Come see us at the poster!. @jdmartin86, @marcgbellemare, yoshuawonttweet, @hugo_larochelle
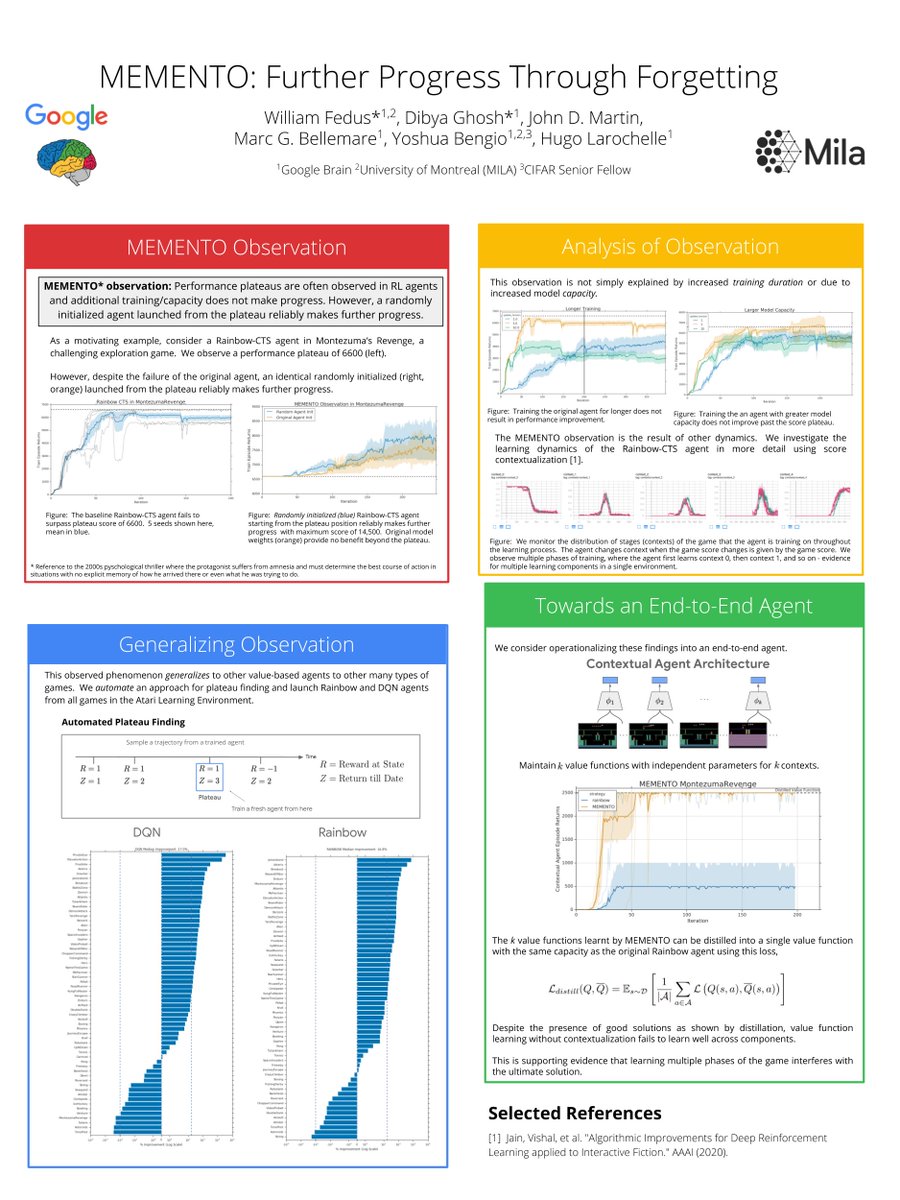
0
17
67
Enjoyed the kNN-LM paper by Khandelwal and Levy et al. (2019). Using an interpolated non-parametric and parametric model, they set a SOTA on Wikitext, reducing perplexity by 2.9 points. This approach helps with predicting long-tail language predictions.
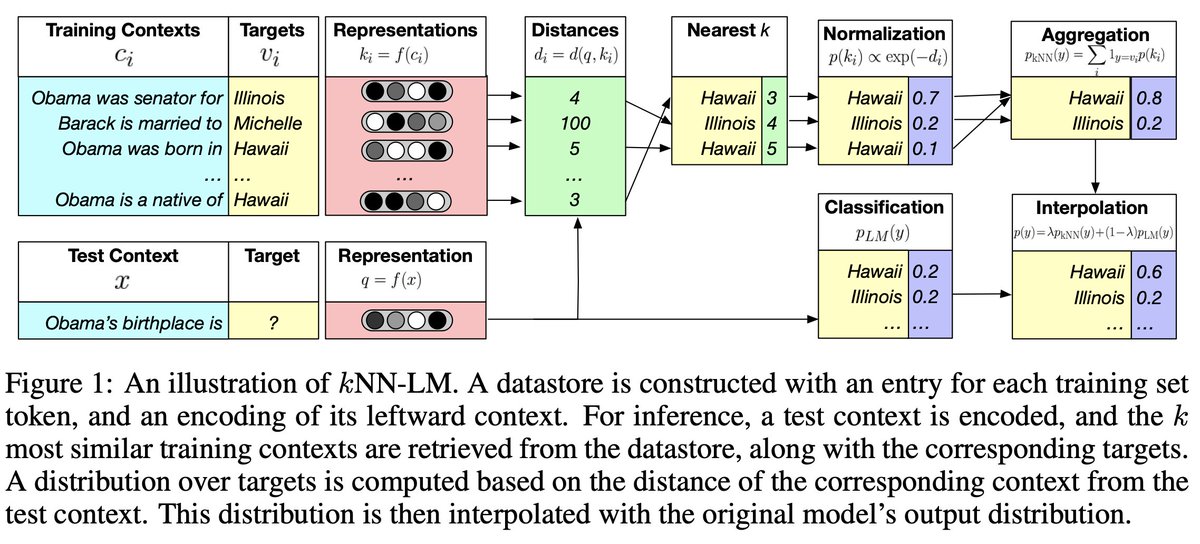
1
24
67
Today we're rolling an experiment to give ChatGPT memory -- the ability to remember important pieces across conversations!.
We’re testing ChatGPT's ability to remember things you discuss to make future chats more helpful. This feature is being rolled out to a small portion of Free and Plus users, and it's easy to turn on or off.
2
6
68
All three gpt2-chatbot results from LMSys and all are in the 1300 club. The gap from the two most recent versions (including the 4o variant) is especially evident on coding.
Breaking news — gpt2-chatbots result is now out!. gpt2-chatbots have just surged to the top, surpassing all the models by a significant gap (~50 Elo). It has become the strongest model ever in the Arena!. With improvement across all boards, especially reasoning & coding
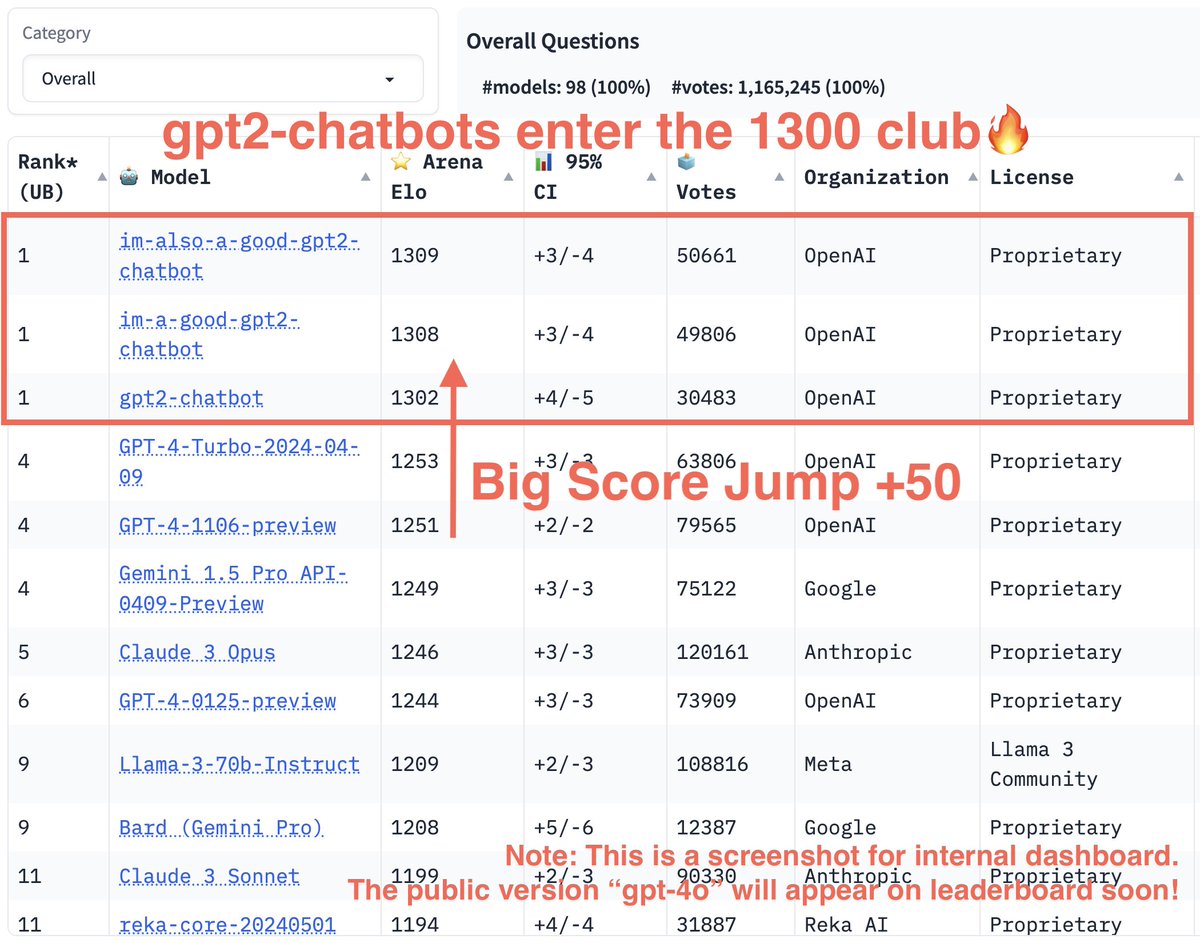
1
3
66
The muTransfer work of @TheGregYang et al., 2022 is a refreshing mix of theory, intuition, and great empirical results!. With this approach (dif init and per-layer lr), the activations remain constant as a fn of width while training (bottom vs. top row).

1
16
66
A new research opportunity at OpenAI to improve ChatGPT with user feedback! DM Andrew for more info.

We value your perspective, help define ChatGPT’s future!. I’m hiring Research Engineers & Scientists to shape ChatGPT’s responses into personalized and reliable interactions for the 1B messages users send every day. Responsibilities include developing Post-Training and RLHF

3
8
66
ChatGPT will now start to remember across threads! An important step towards increasing the usefulness of these models.
Memory is now available to all ChatGPT Plus users. Using Memory is easy: just start a new chat and tell ChatGPT anything you’d like it to remember. Memory can be turned on or off in settings and is not currently available in Europe or Korea. Team, Enterprise, and GPTs to come.
3
5
61
LLMs are a new primitive of programming. Hard logic (if, else) can be replaced/augmented with soft intelligent judgment (prompt: “When you see this…”). Devs also push the creative frontier and explore a far larger surface area than we can alone. Register for our Nov 6th dev.
1
4
63
En route to Montreal for RLDM. Speaking tomorrow at 11:40pm about non-exponential time-preferences in RL agents and also how learning Q-values over multiple horizons is an effective auxiliary task - come chat with us!. @carlesgelada yoshua @hugo_larochelle @marcgbellemare

1
8
60
Replay buffers in deep RL seem rather lacking. Store a relatively short amount of experience, randomly sample (maybe prioritize based on TD-error), throw away old experience regardless of value, train very few times on any transition. This blog post motivates new directions!.

In our new blog post, we review how brains replay experiences to strengthen memories, and how researchers use the same principle to train better AI systems:.
1
7
59
Excited that both our papers were accepted to ICLR 2018!! Thanks to this group of unbelievably talented collaborators: @elaClaudia, @goodfellow_ian, Andrew Dai, @shakir_za, @balajiln.
3
7
60
@TrevMcKendrick Now if only a unapologetic Bay Area upstart would ignore all local zoning laws and start building sufficient housing.
1
4
52
And loading in ML datasets finally enters the modern era. Check it out and thanks @rsepassi!.

The brand new TensorFlow Datasets, make it super easy to load a variety of public datasets into #TensorFlow programs in both tf.data and NumPy format!. Read @rsepassi’s article to learn more ↓
1
13
54
Cool work just released from Ironclad Research: Rivet, a visual programming environment for building AI agents/language model programs. As many folks know, designing and iterating on agents is complex and error-prone: this tooling should help significantly. Check out the demo!.

🚀 Today, we've open-sourced Rivet, a game-changer for #AI agents!. We just launched our first AI agent at @ironclad_inc. But I almost gave up on it, until Andy build v0 of Rivet and showed me what was possible. Let us know what you think!.
2
7
48
“The Seven Habits of Highly Effective Neural Networks” - 👌 paper title from Prajit at lunch. Crowd-sourcing the rest:.1.
6
5
54
MILA's era of tropical-climate GPU-filled offices is ending. New office 2018!.
0
13
52
Tutorial implementation of Switch Transformer in @PyTorch!.

Minimalistic single GPU @PyTorch implementation (with notes) of Switch Transformer. Annotated code: Github: Paper: Colab: @LiamFedus @barret_zoph @GoogleAI

0
6
53
Smarter models up in prod today — send us your feedback!.
Our new GPT-4 Turbo is now available to paid ChatGPT users. We’ve improved capabilities in writing, math, logical reasoning, and coding. Source:
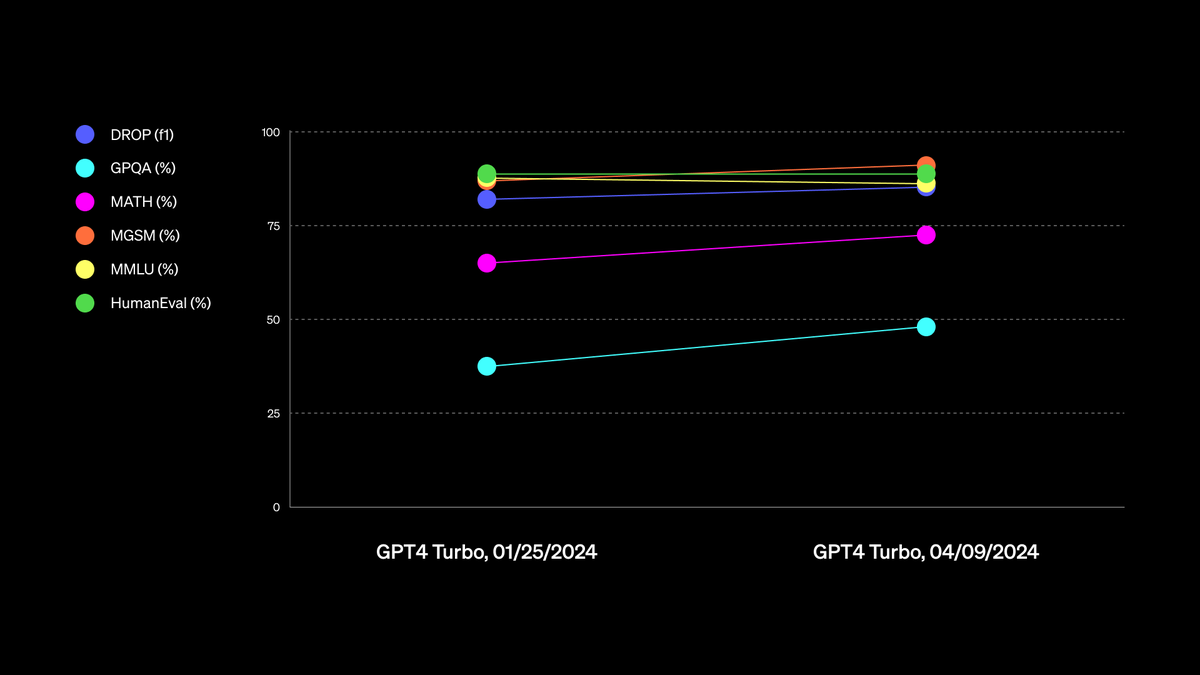
5
1
52
Excited to see a sparse model at the top of the SuperGLUE leaderboard this morning (SS-MoE). We started fine-tuning sparse-expert models in Switch Transformer (, but encountered a few problems. Happy to have remedied many of these issues. Paper to follow.

1
9
50
Pleased to have effective, cheap models out through our API. We can't wait to see what the world builds on them. :).

Just made ChatGPT available on our API! Our incredible team of builders has delivered 10x cheaper model than our existing GPT-3.5 models, through system-wide optimizations, making it easier to power as many applications as possible.
0
0
49
Adding a minimal eval library showing performance on our new model which also quantifies "majorly improved".
Majorly improved GPT-4 Turbo model available now in the API and rolling out in ChatGPT.
1
2
50
‘The estimated weight of all insects on Earth combined — is dropping by an estimated 2.5 percent every year.’. I’m continually shocked by the pace of (largely) human impact on our environment.

We have a new global tally of the insect apocalypse. It’s alarming.
2
15
47
For folks outside the LLM bubble, a blank text box with an AI is mystifying. Small quality-of-life improvements like prompt examples (e.g. plan a tour, explain this code, etc.) can bridge this gap.

We’re rolling out a bunch of small updates to improve the ChatGPT experience. Shipping over the next week:. 1. Prompt examples: A blank page can be intimidating. At the beginning of a new chat, you’ll now see examples to help you get started. 2. Suggested replies: Go deeper with.
1
6
49
Upgraded and augmented version of MMLU — MMLU-Pro, which has 10 options and some harder STEM questions. There’s no perfect static eval, only an iterative process of ever-better evals as our model capabilities progress and the use-cases shift.

Tired of MMLU? The current models already hit the ceiling? It's time to upgrade MMLU!. Introducing our new benchmark MMLU-Pro, a more robust and challenging massive multi-task language understanding benchmark with 12K questions. What's New?.1. MMLU-Pro uses 10 options instead of
2
4
45
Transformer killed the RNN, now encroaching into CNN’s territory. Next the radio star? Nice work, @IrwanBello and team. Optimistic and excited to follow future work of transformers in image domains.

Exciting new work on replacing convolutions with self-attention for vision. Our paper shows that full attention is good, but loses a few percents in accuracy. And a middle ground that combines convolutions and self-attention is better. Link:
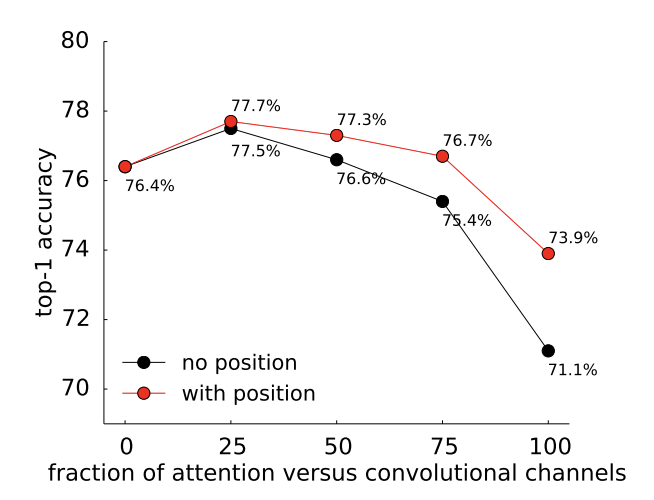
1
8
45
New work from Scale where they created a GSM8k-equivalent difficulty eval from scratch. The resulting performance gap surfaces some model families have data contamination issues and may not be as strong as the public eval would indicate.
How overfit are popular LLMs on public benchmarks?. New research out of @scale_ai SEAL to answer this:. - produced a new eval GSM1k.- evaluated public LLMs for overfitting on GSM8k. VERDICT: Mistral & Phi are overfitting benchmarks, while GPT, Claude, Gemini, and Llama are not.
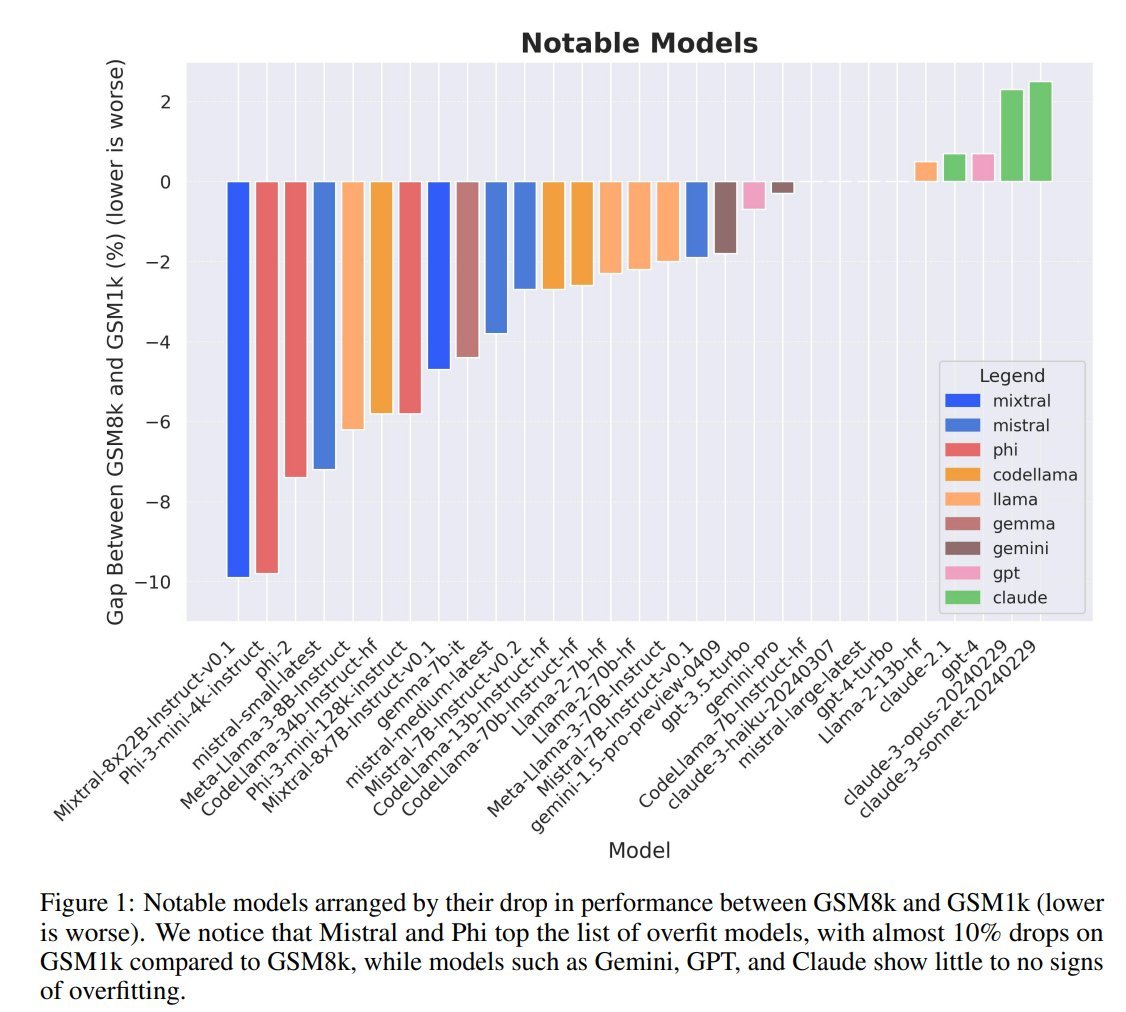
1
2
46
Barret and I share our perspectives on sparse expert models we've worked on (Switch, GLaM, ST-MOE, etc.). Hope this and other talks help provide high-level context for those curious about these classes of models. Thanks for having us, Yannic!.

New interview with Barret Zoph (@barret_zoph) and William Fedus (@LiamFedus) of Google Brain on Sparse Expert Models. We talk about Switch Transformers, GLAM, information routing, distributed systems, and how to scale to TRILLIONS of parameters. Watch now:.

0
4
47
In 2024 "chatbot" became cool again.
im-a-good-gpt2-chatbot.
2
0
44
This project was expertly led by @_jasonwei! It also drew upon a deep bench of stellar collaborators across four institutions. Fun getting to think about these problems. 7/7

1
8
43
ChatGPT has excelled in knowledge work — we’re thrilled to release our enterprise offering. It’s become indispensable to accelerate work within OpenAI and now it will across more professional settings.
Introducing ChatGPT Enterprise: enterprise-grade security, unlimited high-speed GPT-4 access, extended context windows, and much more. We’ll be onboarding as many enterprises as possible over the next few weeks. Learn more:

3
1
36
Our @NipsConference '17 workshop paper finally on arxiv: . TLDR: New intrinsic reward for RL agents to learn independently controllable features of the environment by interacting with it. The objective is a lower bound on causal directed information.
2
8
39
In past GAN research, I’ve also found that 0-norm gradient penalty worked at least as effectively as 1-norm gradient penalty. #ICLR2019 paper analyzing why:.

Here's a new #GAN paper accepted to #ICLR2019 that shows why gradient penalties are important for healthy training and generalization, and shows how a 0-norm gradient penalty is better. Great explanations and insights - worth reading.

0
4
38
We've observed emergent abilities across a wide range of models families (LaMDA, GPT, Gopher, Chinchilla, PaLM): the performance of few-shot inference is random for a while, but then rapidly improves at a certain scale. Similar results were seen in Ganguli et al., 2022. 3/7

2
4
39
MoE models are tough to grok due to the dependence of the computation on each batch of data. This is further complicated when using two data modalities. Fun to read a thorough study in LIMoE!. Below: MoE finds it helpful to learn a "door handle" expert 😅

1
7
39
Big fan Chinchilla. It finds our language models are bloated and compute-inefficient. I love the attention to detail (i.e. lr decay schedule) backed by a SOTA model. And as we start training smaller models for longer, this will increase the emphasis on data quantity and quality.
1
1
40
Fully differentiable architecture search! . Liu et al. compute a softmax over operators and setup an approx alternating gradient descent optimization of weights and architectures. Excited about the continued improvements in architecture search efficiency.
Welcome back, gradients! This method is orders of magnitude faster than state-of-the-art non-differentiable techniques. DARTS: Differentiable Architecture Search by Hanxiao Liu, Karen Simonyan, and Yiming Yang. Paper: Code:
0
2
38