

Marc G. Bellemare
@marcgbellemare
Followers
14K
Following
3K
Media
28
Statuses
1K
CSO & co-founder, Reliant AI. Ex RL research lead at Google Brain, DeepMind. Known for Atari 2600 RL benchmark, Distributional RL (MIT Press 2023).
Montréal, Canada
Joined April 2011
With today's announcement @karlmoritz, Richard & I are thrilled to launch Reliant's next phase - building AI that will completely change how we work with data. Excited to bring Tola Capital, @inovia, and @mavolpi's expertise & experience on this journey. PS: We're hiring :).

Thanks @TechCrunch for covering our $11.3M seed round, bringing next gen(AI) analytics to biopharma and beyond. Happy to have great investors on board with Tola Capital, @inovia and @mavolpi in additon to our amazing Angels from before.
8
16
85
In Dec. 2016 we began work on an intriguing idea: AI agents that learn the full distribution of possible outcomes. Five years since, I'm thrilled to announce a draft of our book, "Distributional reinforcement learning":. w/ @wwdabney and Mark Rowland

22
233
1K
Our most recent work is out in Nature! We're reporting on (reinforcement) learning to navigate Loon stratospheric balloons and minimizing the sim2real gap. Results from a 39-day Pacific Ocean experiment show RL keeps its strong lead in real conditions.
23
106
745
Now that we’re all recovered from the NeurIPS deadline – look what I received in the mail last week…!. Publication day is just around the corner - May 30th. A small 🧵:

28
74
687
Do you like RL and LLMs, want to join an exciting new startup, and would like to see your work transform how the world interacts with knowledge and data?. We're hiring :). Ping me if you're interested or have got someone great to recommend.
78
60
553
A long time in the making: An RL blog, by yours truly, with an eye towards fusing the old and the new
1
88
347
New post looking back at RL research at Google Brain in Montreal over the last ~18 months: .One more year and we'll know why distributional RL works? @wwdabney @pcastr @hugo_larochelle @cholodovskis.
2
66
306
Haters gonna hate. There is no ChatGPT without RL. ChatGPT v GPT-3 is the difference between a party trick and a viable path to human-AI interaction.

The impact of RL has been exactly as small as I had predicted. The impact of Self-Supervised Learning has been even bigger that I had predicted.
8
19
231
Huge congratulations to @agarwl_ who (unsurprisingly) successfully defended his PhD work this week! 🎉. It's been an honour to tag along as Rishabh transformed RL research over just a few years, from RLiable to state-of-the-art algorithms. Can't wait to see what'll come next!

18
9
219
2
77
197
Very excited our lightweight RL framework is now available for everyone to use! w/ @pcastr @carlesgelada @subho87.

In a new blog post, Google Brain team researchers @pcastr & @marcgbellemare share a new @TensorFlow-based reinforcement learning framework that aims to provide flexibility, stability, and reproducibility for new and experienced RL researchers alike.
6
55
176
Interested in using reinforcement learning to train LLMs for problems where there’s no room for error? Do you want to build massive data pipelines to transform how we interact with scientific knowledge?. We're hiring for multiple roles at Reliant:.
1
26
157
Impressive application of deep reinforcement learning to turbine optimization! Talk by Michael May from Siemens at #RVIAQC2019

3
31
152
Our two-parter on viewing RL and representation learning from a geometric angle is out -- can't wait to see what new algorithms will come out of this! w/ @RobertDadashi @wwdabney & other fantastic collaborators.
1
43
151
This year's Conference on RL and Decision Making (RLDM), where artificial and natural learning meet, will be set in beautiful Providence. Long abstracts are due February 22nd. Topical work submitted/accepted elsewhere is welcome. Don't miss it!.
1
27
142
We're open-sourcing a multiagent environment based on the highly popular card game Hanabi, & an agent based on the Dopamine framework! w/ @j_foerst @MichaelHBowling @nolanbard @hugo_larochelle @apsarathchandar & al. Here's a short post about the project:

In a collaboration with Google Brain, we are releasing the Hanabi Learning Environment: a testbed for collaborative multi-agent learning and theory of mind in the card game Hanabi. Paper: GitHub:
3
42
137
Looking to shape the future of self-supervised reinforcement learning? Interested in doing research in a stimulating, collaborative academic environment?. I'm hiring a postdoc at Mila. Apply by Feb 25th:.
1
27
130
I often hear fellow researchers state that "our world is a (PO)MDP". I vehemently disagree: A (PO)MDP is a convenient model. From Bellman's DP book (1957): "It is important to realize that these are very strong assumptions concerning the nature of the system.".
5
13
124
Interested in an RL internship with the Brain team in Montreal next summer? Email us! w/ @cholodovskis @pcastr.
4
27
129
It's rare that our more theoretical work bubbles up to news outlets, so this doubly made my day: w/ @pcastr @RobertDadashi @wwdabney.
0
23
124
10 years ago around this time of year I started working with @MichaelHBowling and @friendly_aixi , with the idea of finalizing the Arcade Learning Environment and releasing it to the AI community. Incredible to see where it's taken us. Deep gratitude to two excellent mentors!.
2
6
125
Beautiful piece of work with @markrowland_ai, @wwdabney et al. After 5 years, we have a proof that quantile TD learning converges!. QTD works incredibly well but had defied analysis because its updates don't correspond to some contractive operator. See
2
23
124
Ten years ago, we submitted a paper to JAIR called "The Arcade Learning Environment: An Evaluation Platform for General Agents". It's an understatement to say we didn't expect what came next.

1
10
124
Releasing a new version of the ALE today with @cholodovskis! New games, modes, and difficulties -- lots of challenges for transfer learning. #ALE #AIResearch #RL
1
51
124
Most people don't know that although most of my research work is in RL, I spent a significant portion of my PhD & early career on generative modelling (text, images, data compression). Building new RL algorithms for LLM training is a real delight - putting two passions together.
2
2
122
Congrats to my PhD student @aalitaiga for winning Best Paper Award at the Exploration in RL Workshop at ICML19, "Benchmarking Bonus-Based Exploration Methods on the Arcade Learning Environment"! Talk today, 11:30, Hall A. #ICML2019 #ERL19 @AaronCourville @cholodovskis @LiamFedus.
4
15
121
Somehow I failed to tweet about this a month ago, so: A new way to think about representation learning in RL and improvement, & correlates Atari 2600 performance with generalization across iterations. w/ @wwdabney A. Barreto, M. Rowland et al.

1
18
109
Congratulations to @agarwl_ and @max_a_schwarzer for their Outstanding Paper Award at #NeurIPS2021! It was a thrill to see this project grow into shape. Here's to a higher scientific standard in empirical reporting in ML! . w/ @pcastr @AaronCourville .
0
8
106
Just yesterday at #AAAI19 @clarelyle presented some great detective work towards understanding what makes distributional RL better (or worse) -- paper now on arXiv w/@pcastr.
4
19
103

Excited to kick off the Deep Reinforcement Learning theory workshop at the Simons Institute today, co-organized with @LihongLi20 . Today's topic is Offline reinforcement learning 🔥 Schedule is here:
1
19
96
Just realized today my copy of Bellman's Dynamic Programming has a two-page advertisement for orchestral scores. This seems like a fairly niche market.


1
6
96
Our paper on Automated Curriculum Learning is out! Intrinsic motivation meets deep net optimization

1
32
90
Very much looking forward to speaking at this fantastic venue for RL!.

Very excited about the @NeurIPSConf 2020 Deep RL Workshop!. Amazing line-up of invited speakers: .@marcgbellemare.Matt Botvinick.@RealAshEdwards.Karen Liu.@SusanMurphylab1.Anusha Nagabandi.@pyoudeyer.Peter Stone. Paper submission deadline: Oct 5, 2020.

2
15
84
Our work on representation learning w/ implicit auxiliary tasks is in at #AISTATS23!. Core to this work is a broadly-applicable SGD method to find principal components from small random submatrices. w/ @charlinelelan, J. Greaves, @JesseFarebro et al

3
27
85
Congratulations all! Go-Explore definitely went off the beaten path in its approach to Montezuma's Revenge and exploration, and massively changed my views on RL.

Thrilled to share that "First return, then explore" appears today in Nature! Go-Explore solves all unsolved Atari games*, ending a long quest by the field that began in Nature. Led by @AdrienLE & @Joost_Huizinga w @joelbot3000 @kenneth0stanley & myself. 1/
3
5
80
Mark Rowland's distributional RL paper on samples and statistics (& potential mismatch) is out -- big step towards understanding the method w/ @wwdabney @RobertDadashi S. Kumar R. Munos

0
22
77
The lives of so many, tangled up in arbitrariness. My heart goes out to friends, peers, and academic colleagues, near and far, who lost someone in the tragedy of #Flight752. We are all connected.
0
5
78
RL excels at finding near-optimal control policies for complex physical systems (fusion reactor control, balloon navigation, race car driving, competitive sailing. ). Here we collaborated with @ORNL to use AI to near-optimally kick atoms around using an electron microscope! 👇.

Really excited to share our recent work on using AI to control an electron microscope to rearrange individual atoms! This was a really fun collaboration between @GoogleDeepMind, @Mila_Quebec, and @ORNL. paper: 1/5
2
8
74
It took us 2+ years to figure out exactly how to think about, & work with a distributional version of the successor representation - doubly proud of this work by @JesseFarebro and @harwiltz that both lays down a mathematical foundation and improves on γ-models!. Also, A+ visuals.

Introducing the Distributional Successor Measure (DSM): a model of the range of possible futures an agent faces. As a distributional extension of the Successor Representation, it enables zero-shot distributional policy evaluation beyond the capabilities of existing methods. The
0
6
73
There's been lots of experimental work in deep reinforcement learning where just "turning on distributional RL" improves performance. I'm looking to put together a slightly more exhaustive list, especially of different application domains. Please reply/send in references!.
6
12
72
Beyond honoured to be one of the 29 CCAI Chairs announced today. #AICan today was fantastic – big things in store for AI in Canada.

Today at #AICan we are announcing the first cohort of 29 Canada-CIFAR Chairs in Artificial Intelligence. These top academic researchers will help maintain Canada’s leadership in artificial intelligence research.

4
7
71
Last year we showed just how effective reinforcement learning can be at navigating superpressure balloons in the stratosphere. Now we're open-sourcing a version of the simulator to support further research in sequential decision making in complex environments:.

Last year we showed that deep RL can successfully control stratospheric balloons in the real world. Today we're announcing a β-release of the BLE, a high-fidelity simulator of this complex real-world decision making problem. 1/🎈
0
11
66
Out today! We took a fresh look at evaluation in RL and we have some proposals to improve how results are compared across publications. See thread below; download rliable; help standardize experimental reporting in RL; build confidence in your results.

tl;dr: Our findings call for a change in how we evaluate performance on deep RL benchmarks, for which we present more reliable protocols, easily applicable with *even a handful of runs*, to prevent unreliable results from stagnating the field. (1/N)

0
11
66
On the back of our 2017 distributional RL paper @white_martha and Ehsan Imani wrote a piece showing that you can do regression better with a classification loss. that seemed wild at the time, but @JesseFarebro, @agarwl_ and co pushed this further and the results are amazing!.
Framing regression as a classification has been “dark knowledge” for some time. We wanted to shed some light on this phenomenon in deep RL:. Framing value-learning as a classification significantly improves performance and scalability in deep RL. But. not all classification
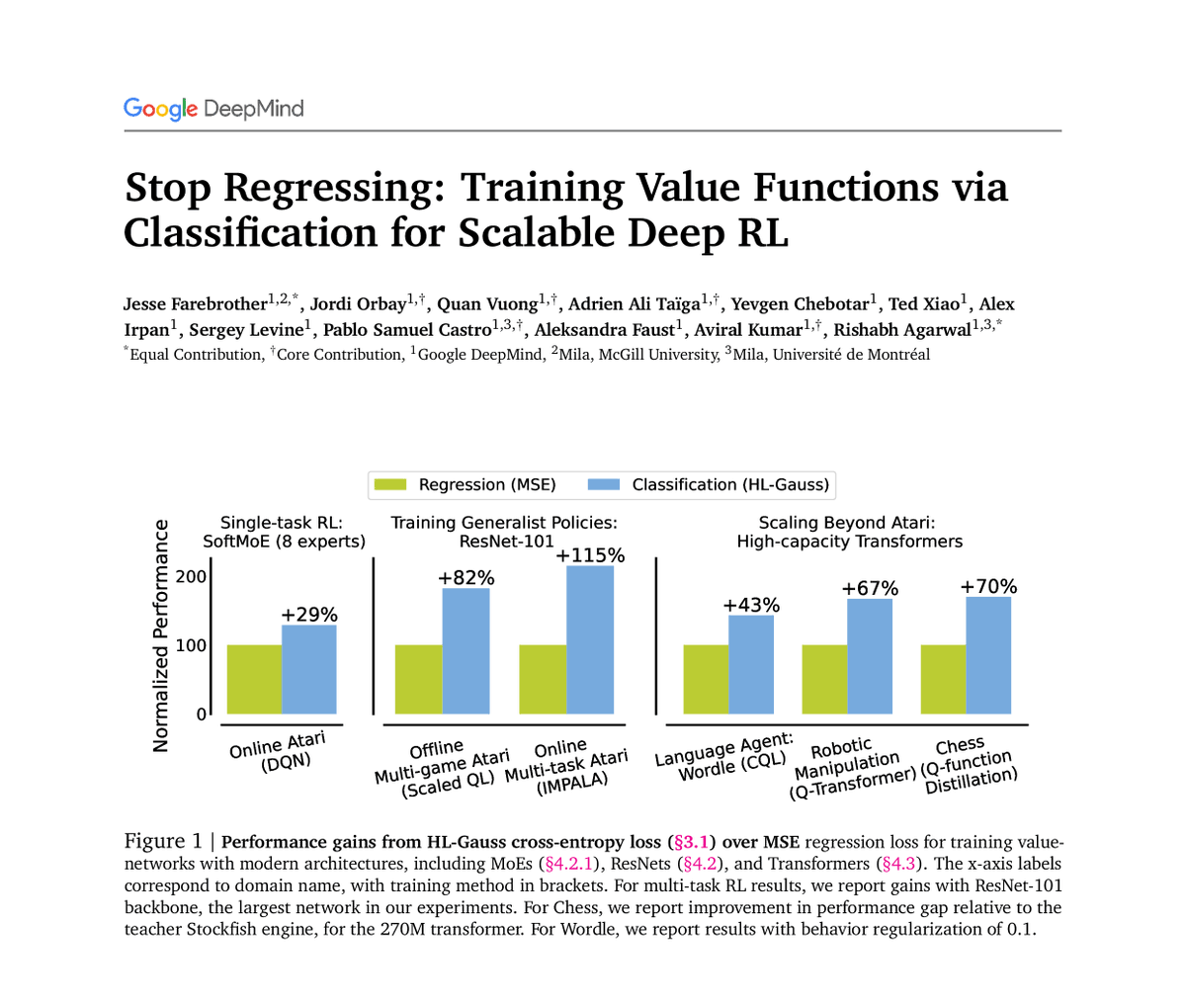
0
12
63
Our paper on PixelCNN for exploration is out! Neural alternative to CTS + practical insights into "hard" exploration
0
33
66
We (@GlenBerseth & I) are looking to hire a postdoc researcher to study risk-sensitive decision making under uncertainty, with robots (real and simulated). We invite all candidates with experience in reinforcement learning and/or robotics to apply:
1
18
63
As AC, I'm seeing more NeurIPS reviews this year that simply rate the paper (accept/reject), without action items or questions for the authors. Blame short review times, reviewer fatigue, or the many-small-questions format, but these are useless - they can't be responded to.
4
4
64
From DeepMind and in particular my long-time colleague @sharky6000 (he taught me AI! and made me use Java), OpenSpiel aims designed to make it easy to benchmark various methods on games (as in: game theory, multiagent). Curious to see how more recent RL methods fare on these!.
We're excited to release OpenSpiel: a framework for reinforcement learning in games. It contains over 25 games, and 20 algorithms, including tools for visualisation and evaluation. GitHub: Paper:

1
12
64
Our work with Adrien Ali Taiga and Aaron Courville is out on arXiv: Some progress towards understanding pseudo-counts and approximate exploration!.
0
16
65
Paper is now on arXiv!.

In 'Benchmarking Bonus-Based Exploration Methods in ALE' we find that when standardizing training duration, architecture, model capacity - new methods do not clearly improve over prior baselines. Work led by @aalitaiga which received ICML exp. workshop 2019 best paper award!
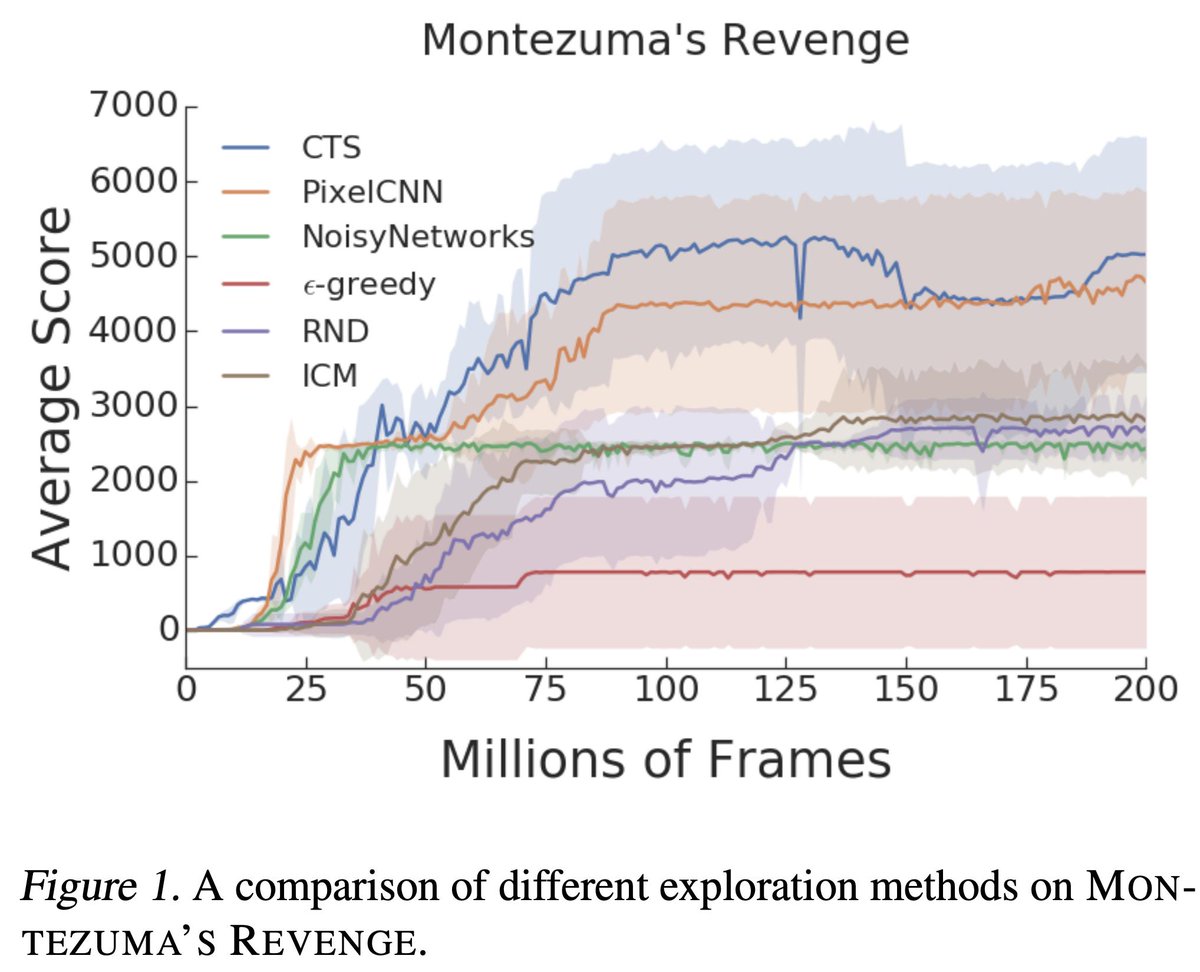
1
11
62
Looking forward to the Deep RL Workshop tomorrow! Presenting "Autonomous navigation of stratospheric balloons with RL" at 1pm Eastern time. Though with this lineup of speakers I'm starting to feel a little nervous. @salcandido @MarlosCMachado @pcastr @ziyuwang @realdeepmoitra.
Very excited about the @NeurIPSConf 2020 Deep RL Workshop!. Amazing line-up of invited speakers: .@marcgbellemare.Matt Botvinick.@RealAshEdwards.Karen Liu.@SusanMurphylab1.Anusha Nagabandi.@pyoudeyer.Peter Stone. Paper submission deadline: Oct 5, 2020.
2
4
62
Our new paper is out! Surprising results re: Wasserstein distance. Expecting plenty of Seinfeld jokes. W/@balajiln and @shakir_za

The Cramer Distance as a Solution to Biased Wasserstein Gradients. (arXiv:1705.10743v1 [cs.AI])
1
23
58
Congratulations Rich, Doina, and Satinder! Truly a field-defining paper.

Congrats to Rich Sutton, Doina Precup and Satinder Singh for winning the 2019 Classical AIJ Paper Award with their seminal 1999 paper on temporal abstractions! @DeepMindAI @McGillU @UAlberta @Umich.
0
3
57
An opportunity to learn the art of RL theory with one of the most skilled theorists I have had the pleasure to interact with - if I could go back in time to my PhD studies I would find a way to work on a project with Csaba.

Friends: I am looking for theory oriented postdocs in RL (with past theory experience). I appreciate if you spread the word.
0
4
54
. @brianchristian's The Alignment Problem landed in my mailbox last week -- I had a great time chatting with Brian re: the nature of curiosity, video games for benchmarking intelligence, and AI in general. Already two chapters in, a fun and fantastically well-researched read!

1
3
55
The deep RL theory workshop returns today w/ an exciting slate of speakers: @pabbeel , @white_martha , Nevena Lazic, and Matthieu Geist! At 11:30 PT the inimitable @neu_rips (not the conference) will lead the discussion on the topic of optimization in RL.
0
10
55
Thrilled to say that the latest iteration of our favourite RL framework is out. It's been a real treat working with Jax, in particular for simplifying some of the indexing needed for distributional reinforcement learning. Thanks @pcastr !.
0
8
54
Fantastic AISTATS paper by Mark Rowland: distributional RL gets some mathematical polish & formal tools to analyze it
0
17
53
Congratulations to Dave! Dave's approach to research has always been, and continues to be, a great source of inspiration to me.
Congratulations to David Silver, recipient of this year’s @TheOfficialACM prize in Computing! David is being recognised for his role developing #AlphaGo and #AlphaZero and his contribution to the field of deep reinforcement learning. Read more here:
0
0
53
We spent last year designing a SSL algorithm for RL based on our earlier results on representation learning. Proto-value networks (PVNs) are stable (mildly off-policy) & scaled up to as big as we could make our networks - potentially a game changer for scale in RL. At #ICLR23!.
1/ Thrilled to share our #ICLR2023 paper on Proto-Value Networks (PVN) now on arXiv!. Through a collection of self-supervised tasks, PVNs learn to capture the spatiotemporal structure of the environment, resulting in state-of-the-art representations!👇.
0
15
53
The deep RL workshop continues today on the topic of Exploration. Fantastic line up of speakers, @IanOsband @chelseabfinn @wwdabney Alekh Agarwal, discussion chair @joelbot3000 See you there! Schedule: @LihongLi20.
0
4
49
Look where I ended up today. A thousands thanks to @pulkitology and @taochenshh for the invitation to come talk about the distributional RL book. What an amazing place!

2
0
52

1
0
51
Fantastic morning at @robocup2018 at Palais des Congrès in Montreal -- lots of opportunities for RL research.

0
8
49
I really enjoyed Alex's incredibly well-researched blog post!

"Deep Reinforcement Learning Doesn't Work Yet" -- fantastic, thorough blog post by Alex Irpan on why deep RL mostly sucks (for now!).

0
5
49
Hot take: The current "AI-existential-risk-from-misinformation" narrative takes a patronizing view on citizens, their ability to make their own decisions (the basis of democracy), and adapt to new technologies.
3
7
48
In Montreal, we are now entering that narrow time of the year where it's sensible to leave windows open day and night.
2
0
48
Less than a day for to catch up to the GitHub popularity of the ALE itself -- great to see such interest! w/ @pcastr @carlesgelada @subho87.
One of my favorite things is to have quick access to the training plots for all 4 agents on all 60 Atari games. Check it out on our baselines page: .
0
12
45
Ok, folks: two papers this afternoon you shouldn't miss:. Reincarnating Reinforcement Learning w/ @agarwl_, @max_a_schwarzer (#607). The Nature of Distributional TD Errors w/ @robinphysics, Remi Munos (#531). 1/2.
1
12
44
Looking forward to today's Deep RL Theory Workshop at the virtual @SimonsInstitute - from language to latent states! With @jacobandreas @yayitsamyzhang @clarelyle @ShamKakade6 and Doina Precup, hosted by none other than @LihongLi20 . See you there!
0
6
49
Energy management is an area of research with huge potential for RL - great to see a Gym-based experimental framework for it!.

Gym-ANM: a new framework for designing reinforcement learning environments that model complex decision-making problems in electricity distribution networks. A must-try for RL researchers willing to impact the energy transition.
0
13
47
. @CsabaSzepesvari once taught me to keep an eye on the completeness requirement of Banach's fixed point theorem. Today this actually came up while studying a distributional RL algorithm. Grateful that I knew to look out for it!.
1
0
45
Beautiful new deep RL environment from @eve_byu , looking forward to seeing what researchers do with it!.

We're excited to announce the release of Holodeck, a high fidelity simulator for reinforcement learning!
1
5
45
Finally had a chance to read through the bsuite paper -- very clear and targeted, looks like this should bring extra clarity to fundamental RL research. Well done @IanOsband et al!.

Really excited to release #bsuite to the public!. - Clear, scalable experiments that test core #RL capabilities. - Works with OpenAI gym, Dopamine. - Detailed colab analysis.- Automated LaTeX appendix. Example report:

2
5
46
Very exciting - finally a venue for conference-paper-sized ML research that (hopefully) incentivizes dialogue with reviewers and addresses some of the pitfalls of the big ML conferences. Do sign up to be a reviewer!.

Today, @RaiaHadsell, @kchonyc and I are happy to announce the creation of a new journal: Transaction on Machine Learning Research (TMLR). Learn more in our post:
0
1
41
Beyond thrilled to see this analysis by colleagues Will Dabney, Zeb Kurth-Nelson, Matt Botvinick and colleagues in Nature: Evidence that the brain encodes distributional reward predictions (in the distributional RL sense). @wwdabney @zebkDotCom Congrats!.

When neuroscience and AI researchers get to chatting, cool stuff happens! My first, and I hope not last, trip into neuroscience has been published in Nature. 1/.
0
7
45
Saddened to say good-bye to Loon today. On our end, this was an incredibly fruitful collaboration that culminated in a large-scale use of deep RL in the wild, navigating balloons like nothing before. See also:
1
0
43
RL theory twitter: Is convergence to a local minimum (e.g., of a policy gradient method) interesting?.
9
7
43
I spent far too much time on NetHack as a grad student -- this should prove quite the challenge for AI agents. (Will they know what to do when they meet the Jabberwock?).

I am proud to announce the release of the NetHack Learning Environment (NLE)! NetHack is an extremely difficult procedurally-generated grid-world dungeon-crawl game that strikes a great balance between complexity and speed for single-agent reinforcement learning research. 1/
1
6
43
Thanks @ArthurGretton for great #CramerGAN feedback! now w/ response clarifying major points @balajiln @shakir_za.
1
6
44
Terrible outcome for the Vector Institute and CIFAR -- two leading institutions in AI/ML research.

Recap:.1. The Ford govt cut funding for two AI research hubs.2. Its own prosperity think tank said last year it is imperative the govt keep investing in AI research to remain competitive.3. The Ford govt also cut funding for that think tank; it closed .
0
6
40
Pet (reviewer) peeve: The use of 'Ours' in experimental results. Why: it emphasizes ownership of an idea over its thought-value. Instead: Name it, allow others to make the idea theirs.
4
2
40
Tomorrow at #AISTATS2022 @charlinelelan is presenting our work on understanding how the choice of representation (and e.g. deep RL losses) affects how well a RL algorithm can generalize between samples. Very excited with where this line of working is taking us – don't miss it!.

Very happy to present our #AISTATS2022 paper “On the Generalization of Representations in Reinforcement Learning” tomorrow! 🌟🎊 .With wonderful collaborators @stephenltu @oberman_adam @agarwl_ @marcgbellemare. 📜 Paper 1/10

0
6
40
If you're at IJCAI, don't miss this! Lots of interesting RL visualization results, including some unexpected results about the features learned by a distributional RL method (C51).

Happy to present at IJCAI on our deep RL model zoo for Atari, RL2 session, Wed in room 2701, 9:30-10:30 @felipesuch @vashmadhavan @savvyRL @ruiwang2uiuc @jeffclune @marcgbellemare @pcastr. Code: Paper: Blog:
0
9
39
Congratulations to @Azaliamirh @annadgoldie and team! This is a really exciting result demonstrating how reinforcement learning can bring gains to real, challenging problems that look nothing like video games.

Thrilled to announce that our work on RL for chip floorplanning was published in Nature & used in production to design next generation Google TPUs, with potential to save thousands of hours of engineering effort for each next generation ASIC:. (1/7)

2
2
40
#ICML23 is absolutely delightful - so great to talk to so many colleagues in an amazing venue. Will be sad to fly back to Montreal this weekend!.
0
0
42
This is a substantial piece of work, very clearly articulated and neatly documented. I am particularly impressed by the clever sharing of GPUs to make ALE experiments much more effective. Well done @FlorinGogianu and @_tudor !.
0
2
40
A much overdue retweet. Congratulations to all, but in particular to @MichaelHBowling , an incredible PhD advisor and the visionary behind the Arcade Learning Environment. (Not to speak of his accomplishments in game theory, robotics, etc.!).

AAAI is thrilled to announce the election of ten new Fellows for their lasting contributions to the breadth of #AI, including Planning, RL, Robotics, NLP, CBR and Vision. The new fellows will be inducted (astrally) and felicitated (with secret hand-shake etc) during #AAAI2021🥳🎉

0
5
41

A nicely executed piece of work on finding lower bound Q value estimates in the batch / offline RL regime - brings up tons of interesting follow up questions!.

We (Aviral Kumar, A. Zhou, @georgejtucker) released conservative Q-learning (CQL). CQL is an offline RL algorithm, and it works very well. Much better than I thought offline RL could work, on many tasks (see below). [1/7].

0
5
41
Very excited to see this work presented at AAAI -- congratulations @pcastr !.
presenting my paper "Scalable methods for computing state similarity in deterministic Markov Decision Processes" in poster session 2 (thursday, noon). this paper just got accepted to @RealAAAI #AAAI20 🎉!. paper and code coming soon, here's the poster in the meantime:
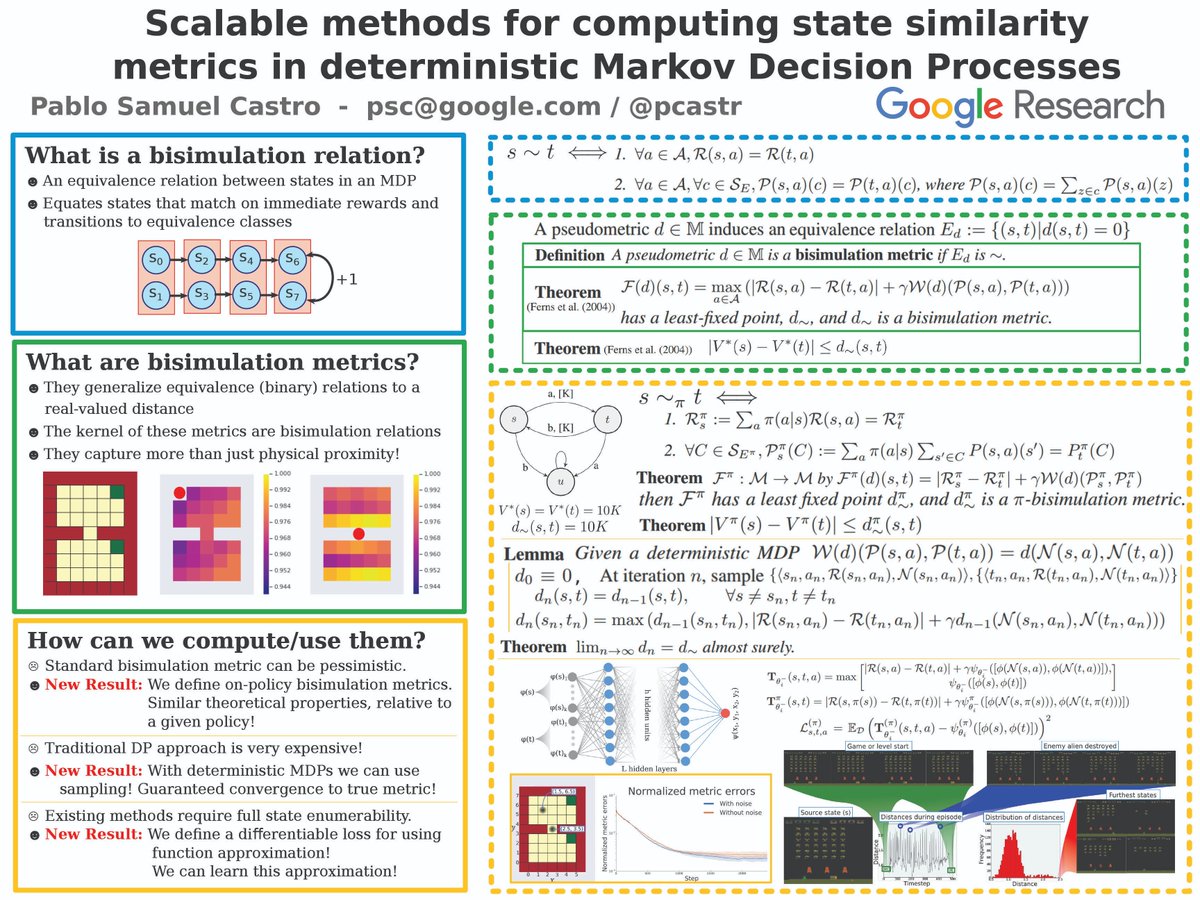
0
4
40
Distributional successor features: A follow up to our distributional successor representation by my students @harwiltz and @JesseFarebro - those manim animations are quite something!.

🚀 Check out our latest work on oracle-free & convergent algorithms for learning *distributional* Successor Features!.📄 Paper: Great colab with @JesseFarebro, @ArthurGretton, & Mark Rowland, from @Mila_Quebec, @mcgillu, @GoogleDeepMind, @GatsbyUCL.
0
6
41
RLDM22 early registration deadline is May 15th – this is promising to be quite an exciting conference, don't miss it!.


1
2
39
Great discussion of distributional RL & pitfalls by @shimon8282 !

Next up on my summer reading list: GAN Q-Learning (, a recent addition to the growing trend of distributional reinforcement learning. I find this trend intriguing and potentially quite exciting.
0
3
38
Montreal's AI and reinforcement learning ecosystem is shaping up at a lightning pace -- great news from MSR.
0
1
38
Great to see distributional RL being successfully applied to novel settings!

I’ve implemented DeepMind’s Distribution Bellman “C51” in Keras and tested on VizDoom @marcgbellemare
0
8
38
I had the great pleasure of talking with @robinc a few weeks ago on a variety of RL topics, harking back all the way to: In 2011, did we think we would one day have RL agents that achieve superhuman performance on every Atari 2600 game? Thanks @TalkRLPodcast for this opportunity!.

Episode 22.@marcgbellemare of @googIeresearch shares insight on his work including Deep Q-Networks, Distributional RL, Project Loon and RL in the Stratosphere, the origins of the Arcade Learning Environment, the future of Benchmarking in RL -- and more!.
2
4
35