

Ryan Lowe
@ryan_t_lowe
Followers
5,595
Following
362
Media
32
Statuses
531
what is the place from which we are creating? ❤️✨🤠❤️
Berkeley, CA
Joined May 2009
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Internacional
• 116292 Tweets
Karol G
• 106194 Tweets
土用の丑の日
• 59450 Tweets
ゲリラ豪雨
• 39272 Tweets
デッドプール
• 36779 Tweets
Ingat
• 32585 Tweets
Mets
• 32548 Tweets
Saint Dr MSG Insan
• 28135 Tweets
ジェシー
• 27300 Tweets
Guru Purnima Celebration
• 26643 Tweets
#CarinaPH
• 24528 Tweets
O Inter
• 20777 Tweets
Toy Bank
• 19670 Tweets
Renê
• 17451 Tweets
Boone
• 10732 Tweets





















Here's a ridiculous result from the
@OpenAI
GPT-2 paper (Table 13) that might get buried --- the model makes up an entire, coherent news article about TALKING UNICORNS, given only 2 sentences of context.
WHAT??!!

33
470
1K
I've left OpenAI.
I'm mostly taking some time to rest. But I also have a few projects in the oven 🧑🍳
Here's one that I'm really excited about: we have a 🚨new paper🚨 out on aligning AI with human values, with the folk at
@meaningaligned
!! 😊✨🎉
Why I think it's cool:
🧵

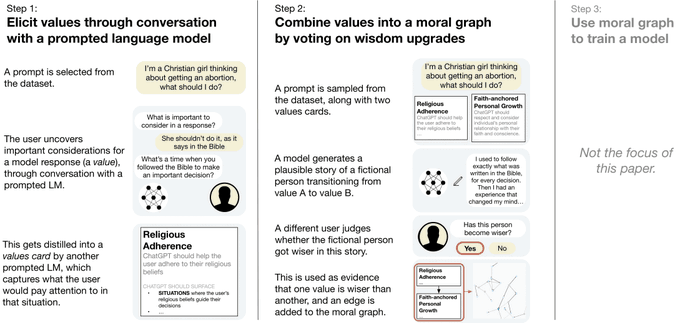
“What are human values, and how do we align to them?”
Very excited to release our new paper on values alignment, co-authored with
@ryan_t_lowe
and funded by
@openai
.
📝:
26
74
366
17
68
775
(ahem)
alright friends
I am quite proud and slightly terrified to announce what I (and my alignment homies) have been working on over the past 14 months:
Training a new version of GPT-3 (InstructGPT) that follows instructions
🧵

We've trained GPT-3 to be more aligned with what humans want: The new InstructGPT models are better at following human intent than a 100x larger model, while also improving safety and truthfulness.
45
240
1K
9
92
708
I've finally decided to start a blog.
I've been a bit frustrated with the Twitter conversation about
@OpenAI
's GPT-2, and I haven't found a post that says all the things I want to say. So I wrote about it here: .

7
94
361
I’m heartbroken.
I deeply believe in building AI that benefits all beings.
Having a nonprofit board with actual power and a fiduciary duty to humanity is WILD. Many rolled their eyes at this.
I don’t know what to say. I can’t imagine the future is better off today.
23
18
355
VERY excited to announce new work from our team (one of the safety teams
@OpenAI
)!! 🎉
We wanted to make training models to optimize human preferences Actually Work™.
We applied it to English abstractive summarization, and got some pretty good results.
A thread 🧵: (1/n)
We've used reinforcement learning from human feedback to train language models for summarization. The resulting models produce better summaries than 10x larger models trained only with supervised learning:
57
480
2K
3
48
301
Excited to announce that I've joined OpenAI full-time to work on AI safety research!! 🎉
If AI safety is an area you're interested in (or really skeptical about!) I'd love to chat and share my views on it.
18
2
295
❤️

4
10
249
Successfully e-defended my thesis today!! 🎉
Infinite thanks to my wonderful supervisor Joelle Pineau, my PhD committee, and of course my friends and fam 😊
I've been thinking about all the fortunate moments in my life that lead to this one. Two in particular stand out. 🧵:

16
0
250
Slides from my talk on "The Problem with Neural Chatbots" given at
@stanfordnlp
and
@GoogleBrain
are now available:


4
57
183
Hey, we got a new paper out! 😊🤠
We train a model that can summarize entire books. We think this will help us understand how to align AI systems in the future, on tasks that are hard for humans to evaluate.
A quick summary (heh):
We want our AI systems to be aligned with human intentions.
This is especially important as tasks get more difficult to evaluate.
To develop techniques to address this problem, we trained a model to summarize books.
75
217
1K
2
32
181
"Deep Reinforcement Learning Doesn't Work Yet" -- fantastic, thorough blog post by Alex Irpan on why deep RL mostly sucks (for now!)

1
62
153
📢 We're hiring a data scientist for the Alignment team at
@OpenAI
! 😊
We're looking for someone who cares deeply about the data used to train ML systems, potentially w/ experience in participatory design, safety/ social impact of ML systems, etc.
Link:
2
35
149
We are open-sourcing the multi-agent particle environments used for our work
@OpenAI
! Uses Python + Gym interface:

3
42
144
Super excited to be launching ML Retrospectives (). It's a website that hosts 'retrospectives' where researchers talk openly about their past papers. We also have a NeurIPS 2019 workshop where retrospectives can be published. Check it out!! 🎉

Researchers currently don't have a forum for sharing updated thoughts on their past papers.
@ryan_t_lowe
introduces ML Retrospectives, a new NeurIPS workshop that wants to change that.
#ResearchCulture
#NeurIPS
3
30
156
1
29
138
I didn't realize that having no affiliation with a major institution means that your papers get stuck in arXiv purgatory 😅
in any case, our paper is now on arXiv!

I've left OpenAI.
I'm mostly taking some time to rest. But I also have a few projects in the oven 🧑🍳
Here's one that I'm really excited about: we have a 🚨new paper🚨 out on aligning AI with human values, with the folk at
@meaningaligned
!! 😊✨🎉
Why I think it's cool:
🧵
17
68
775
4
7
126
It's been exactly two years since this public Twitter bet.
The question: will 'just scaling up' allow LMs to answer common-sense questions like "do insects have more legs than reptiles" >80% of the time?
Since then we've had GPT-3, PaLM, Gopher, etc.
Which side won?

@carlesgelada
Care to make a concrete prediction, and put some money on it? I'll wager that no model trained by scaling the current paradigm (defined as Transformerish + MLE + text scraped from the internet) will give reasonable responses to the prompts in Tomer's tweet. Settles in 2 years.
2
0
11
3
8
118
openai is nothing without its people.
unrelated:

Leaders often replicate the dynamics of their family of origin inside of their leadership team. So if you have a horrible leader, know you are living in their childhood.
8
5
110
4
6
115
Announcing the 'Conversational Intelligence Challenge' at NIPS 2017! Submit chatbots that can hold convos about news articles--see convai.io
1
53
95
A good world is where AI researchers realize our work doesn't exist in a vacuum, and we spend a little bit of time thinking about social impact before publishing.
NeurIPS asking for 'social impact statements' doesn't solve this, but it seems like a worthwhile experiment. (1/n)
2
13
82
First the issues. Probably the biggest is that InstructGPT literally follows instructions. If you ask it to do something bad, it will usually just do it.
I don’t think that’s what we want. Gotta figure that out (when should models refuse to do what the user asks?)

5
11
82
I'm so grateful I got to work closely with Jan at OpenAI. he's an amazing human being
4
0
81
I’ll leave you with some ridiculous InstructGPT outputs from the paper

5
7
74
And it's hilarious:
"While their origins are still unclear, some believe that perhaps the creatures were created when a human and a unicorn met each other in a time before human civilization. According to Perez, 'In South America, such incidents seem to be quite common.' "
1
4
75
The
@MLRetrospective
NeurIPS workshop is happening tomorrow!! 🎉
We have an awesome lineup of speakers (incl.
@shakir_za
@rzshokri
@sina_lana
@ShibaniSan
@mariadearteaga
and Kilian Weinberger), who'll be surveying + analyzing subfields of ML research (and maybe their own work!)

1
24
75
Why are our results better than the last time we did this? ()
Our 'secret ingredient' is working very closely with our labelers. We created an onboarding process, had a Slack channel where they could ask us questions, gave them lots of feedback, etc. (7/n)

2
4
72
I should note why this result is interesting --- it clearly shows the ability of the model to encode general knowledge of the world, and to use it to *generalize* to inputs/ situations that it has never seen before during training. It has not memorized this.
3
7
70
Use human preference data to fine-tune language models. It’s officially cool now! 🤠
1
3
55
I'll be giving a talk at
@stanfordnlp
tomorrow at 11am on 'The Problem(s) with Neural Chatbots'. Slides likely to be posted afterwards!
2
4
57
Wow. The positive reception to the Retrospectives workshop yesterday has been overwhelming. So many great talks and amazing discussions. Thank you to all of the courageous presenters 🖤. Stay tuned for future developments on retrospectives!!
Videos here:


WOW!! 🤩 1044 people at
#NeurIPS2019
added the Retrospectives workshop to their agenda! Thanks to everyone supporting retrospectives in ML!!!

0
2
24
2
7
55
Our AAMAS paper is finally out!
TL;DR: measuring emergent communication is tricky. It may seem like the agents are communicating, when their messages don't actually do anything.
Instead, use causal influence-style metrics (as proposed by
@natashajaques
)


1
13
52
The key is to fine-tune GPT-3 using human preference data. We take text prompts submitted to the OpenAI API, hire contractors to label this data (basically ranking outputs from our models), and we train on that data using reinforcement learning (RL).

2
6
51
📢 We're hiring again!! 📢
Our team works on both fundamental problems (how do we align models with what humans want?) and applied problems (let's align GPT-3 with what humans want).
I care about this work a lot. I think it's a great fit for NLP folk wanting a new challenge.
2
6
45
when I started working on RLHF a few years ago, I was more optimistic about it than the average DL researcher.
but I SIGNIFICANTLY underestimated its meme potential wow


0
0
43
@zdhnarsil
there are indeed many ways to optimize. OpenAI happens to have a lot of organizational expertise with PPO. but I would be very surprised if that turned it to be the best way to do it
2
0
45
But what does it mean?
By default, GPT-3 is pretty bad at doing what you want. You have to prompt it in a kind of quirky way. It’s pretty unreliable. It’s pretty racist. etc etc
We use tools from alignment to improve this state of affairs.

1
0
35
Headed to Rwanda for
#iclr2023
(!!), landing Tuesday
I've been thinking a lot about "what should AI systems optimize?" I'd love to talk with folk at ICLR who are thinking about this, send me a DM!
Also interested in connecting to the AI/tech scene in Kigali, recs welcome 🙂
1
0
36
Was lucky to work with Kevin at OpenAI, had the knowledge of a mid-PhD student.
Also the paper is pretty neat ()

1
1
36
This is the other point that I'd highlight. It's easy to be lulled by the sense of 'nothing really works'. But if most ML researchers aren't thinking about the societal implications of their research before releasing it, something bad is going to happen eventually.

0
6
34
That makes it extra important to think about how we can distribute these opportunities more fairly and equitably.
There are far more events like this in my life than I can name here. Extremely grateful for all of the love and support I've gotten on this journey 🥰🙏❤️ 8/8
1
0
34
You don't have to be a 'prestigious' researcher. Your original paper doesn't have to be highly cited. Or cited at all.
This is about building norms of openness + self-reflection in ML research.
Highly encourage everyone to submit!! 🎉👇👇

Still time to submit to ML retrospectives workshop @ ICML2020!
Take a little time this weekend to self reflect on some previous work, trends in the field, and there you get a retrospective! Meaning: they can be short and simple to write.
1
23
70
0
7
35
IMO one of the key takeaways of our paper is to work really closely with the humans labeling your data. This wasn't my approach at all in academia (which was more of the 'put it on MTurk and pray' variety). But without it our results wouldn't have been nearly as good. (9/n)
2
5
32
Great paper by
@MSFTResearch
,
@NvidiaAI
and IIT Madras that critiques our ACL 2017 work on automatic dialogue evaluation: .
Evaluating dialogue systems is hard, and our ADEM model has lots of flaws!
0
2
28


Our basic approach:
1) We collect a dataset of humans comparing two summaries.
2) We train a reward model (RM) to predict the human-preferred summary.
3) We train a summarization policy to maximize the RM 'reward' using RL (PPO specifically). (2/n)

3
2
26
We're finally open-sourcing code for the MADDPG algorithm, which can be used in conjunction with our multi-agent 'particle world' environments
Releasing MADDPG, an algorithm for multi-agent reinforcement learning.
MADDPG:
Multi-agent environments:
Blog:
13
278
670
2
8
27
Last tweet for me on the OpenAI GPT-2 thing, but for those interested I think this video really elevates the discussion. Great work by all parties involved.

Really great discussion this eve on
@OpenAI
's recent language model release and the issues and considerations raised. Thanks
@AmandaAskell
@AnimaAnandkumar
@Miles_Brundage
@smerity
@WWRob
for participating. Those who missed it live can catch the replay at
3
35
94
0
8
25
I'm on a podcast! 😊
@longouyang
and I talk about the InstructGPT paper. thanks to
@brian_a_burns
@jason_lopatecki
for having us on!

// Deep Papers
#1
: InstructGPT //
We interview
@ryan_t_lowe
and
@longouyang
, OpenAI scientists behind InstructGPT: precursor to ChatGPT, & one of the first applications of RLHF to LLMs.
More below!
YouTube:
Spotify:
1/9




2
32
236
2
1
25
New blog post 🎉 on the 'Retrospectives' workshop we hosted at the last
@NeurIPSConf
.
I talk about what worked, what didn't work, and some recommendations for hosting workshops like this at other conferences. 🙂

1
3
26
This is a fruitful direction for alignment research. Great work by the
@AnthropicAI
team

It’s hard work to make evaluations for language models (LMs). We’ve developed an automated way to generate evaluations with LMs, significantly reducing the effort involved. We test LMs using >150 LM-written evaluations, uncovering novel LM behaviors.

11
91
573
0
0
26
👇newly released info should hopefully make it less annoying to use InstructGPT for research.
Also, I’ll be presenting the InstructGPT paper at NeurIPS today, 4pm at poster
#920
. Come by say hi 😊

New documentation on language models used in OpenAI's research is up, including some more info on different InstructGPT variants:
6
28
177
1
2
25
The original betters were:
myself,
@carlesgelada
, and
@LiamFedus
on the pro-LM side
@jacobmbuckman
,
@cinjoncin
on the anti-LM side
Looking forward to that dinner 😉
1
0
23
Post on our work in multi-agent communication & language acquisition is live! Huge thanks to
@jackclarkSF
& Igor for putting it together.
1
9
24
But the Ultimate Test (ie how you know you’re not kidding yourself) is that a (slightly different) version of InstructGPT is deployed in the API, and people are finding it more useful! They’re switching over from GPT-3! People are actually paying money to use this thing!!
wild
1
1
21
RLHF works really well! InstructGPT blows GPT-3 out of the water in terms of labeler preference rates on API tasks (way better than 100x-ing model size)
It also does much better on saying true things, and a bit better at not saying toxic things (though not better on bias)

1
1
19
I think the pro-LM side wins, but it's close and depends on the question difficulty.
I tried the original prompts in the thread with GPT-3, and it does alright, but I had to tune the temperature for each question (higher T for more open-ended Qs).



1
1
20
I'll be giving a talk in Montreal next week! conference proceeds are donated to Centraide

Don't miss the TechAide AI Conference on April 12! Join us for presentations by Ian Goodfellow, Bruce Schneier, Hsiu-Chin Lin, Ryan Lowe, and Sara Sabour, as well as a panel discussion featuring Yoshua Bengio and Doina Precup.
View the detailed program:

1
9
30
2
2
20
On that note, we're building an “applied alignment” team to make sure that the models OpenAI deploys are aligned. It’s ML research, engineering, and social science. Our current job posting is for RE (), but if you’re interested please send me a message! ❤️
2
2
20
We’ve used basically the same technique (which we call RLHF) in the past for text summarization (). “All we’re doing” here is applying it to a much broader range of language tasks that people use GPT-3 for in the API
1
0
18
(side note: there’s actually all kinds of other techniques you could use here, including filtering / carefully selecting the pretraining data, steering the model at generation time, etc.. I’m particularly excited about fine-tuning, but I think we should do everything that works.)
1
1
17
Here's the aforementioned model summary of the first Harry Potter book:

See our paper () for more details, including our model's summary of the first Harry Potter book 🪄🪄
1
0
17
2
3
17
Overcoming defensiveness and separating "is my behavior causing harm?" from "am I a good person?" is one of the hardest skills to learn.
As I've learned about this, it blows my mind how often this emotional reaction happens in life (eg. w/ romantic partners). It's so hard!! /2
0
0
18
One of our deep dialogue models (HRED, w/ Iulian Serban) got turned into a US election chatbot! Talk with it here:
1
6
18
But that’s also why I’m excited! To me these techniques feel like an important piece for building AI systems that *actually work* for all the humans. There’s so much collaboration potential, with folks from all kinds of disciplines, to design this alignment process
1
0
17
See our paper () for more details, including our model's summary of the first Harry Potter book 🪄🪄

1
0
17
There's a lot of (justified) pessimism about the future of ML in society.
But I've been thinking about
@Spotify
's music recommendations. They've been adding a lot of joy to my life recently. It's nice to take a moment to feel gratitude for the ways the algorithms are helping us.
1
0
17
@edelwax
's thread does a good job of summarizing the paper, go read it! (or, ya know, read the paper)
I'll talk about one of the main reasons I'm compelled by this line of work: this precise way of thinking about values seems to be actually useful for living your actual life
1
0
17
I think this is the best criticism I've heard of
@OpenAI
's release. We need to come up with norms for how we decide to publish potentially harmful research. It's unlikely that the best solution is "approach journalists first".

@ryan_t_lowe
@OpenAI
Imagine if the guys who found Spectre and Meltdown went straight to the media with their findings, instead of Intel. If SOTA LMs really can be harmful, why not conduct user studies to show that? Why is "wow factor" being used to judge such a sensitive technology?
2
1
15
1
2
15
I certainly worked hard to take advantage of these opportunities.
But there's undeniably a 'rich get richer' effect -- the more breaks you get, the more breaks you'll get in the future. This happens in ways that aren't always visible from the outside looking in. 7/n
1
0
15
Example: I went with some folk (incl
@flowerornament
and
@JakeOrthwein
) to visit
@edelwax
,
@klingefjord
,
@ellie__hain
,
@AnneSelke
, and others from the "meaning alignment crew" in Berlin last year.
1
1
16
I also think there’s a *lot* more we can do to design an alignment process that is transparent, that meaningfully represents people impacted by the technology, and that synthesizes peoples’ preferences in a reasonable way. We’re pretty far from that right now
1
0
15


But I think this work is a real step forward. And I see it as a huge green flag that it's based on a way of thinking that improves the quality of people's actual real lives.
I hope you like it. Please let me know how we can improve the paper or if we messed up somewhere 🙏
3
0
15
Impressiveness aside, I also want to comment on the ethical implications here. This could enable social manipulation on a massive scale. If people fall for e-mail scams, they will fall for fake comments on news articles designed to sway your opinion in a particular way.
Here's a ridiculous result from the
@OpenAI
GPT-2 paper (Table 13) that might get buried --- the model makes up an entire, coherent news article about TALKING UNICORNS, given only 2 sentences of context.
WHAT??!!
33
470
1K
1
2
15
To get exact numbers we'd have to run a larger eval. But in my mind, large LMs are now clearly able to answer *simple* common sense questions like "do ants have more legs than lizards", which was the spirit of the original bet.
Curious if anyone disagrees.
6
0
14
This is cool! Really interesting work.
We've also found this in language learning: if you start with self-play, you often have to do some un-learning when fine tuning with humans (paper coming soon!)

Excited to share our work: collaboration requires understanding! In Overcooked, self-play doesn't gel with humans: it expects them to play like itself. (1/4)
Demo:
Blog:
Paper:
Code:
4
120
367
0
1
15
Annual reminder: Sleepawake is one of the most powerful transformative experiences I've ever witnessed. I was there for 2 weeks last year and will be volunteering for the whole time this year.
I'd particularly recommend it for you if you are 18-30 yrs old and feel stuck in life,

Had a lovely walk with the founder of Sleep Awake. I really admire how much thought they are putting into supporting attendees during and post event.
Sleepawake Camp is focused on orienting 18 - 30 yr olds towards a sense of wholeness and authentic happiness through science,
4
7
57
1
4
14
@thenamangoyal
@OpenAI
Good question! The y-axis is "percentage of summaries generated by each model that are rated higher (by humans) than the human-written reference summaries in the dataset".
1
0
14
And of course, a huge thank you to all of my fantastic co-organizers: Jessica Forde,
@joelbot3000
,
@koustuvsinha
, Xavier Bouthillier, Kanika Madan,
@astro_pyotr
,
@WonderMicky
, Shagun Sodhani, Abhishek Gupta, Joelle Pineau & Yoshua Bengio. 🔥
0
0
13
The "AI research bubble" isn't really a bubble any more. Our models are being used in the real world. It's only going to increase from here. So, the 'safety' of a model doesn't just depend on the model itself, but on how it's deployed as part of a system that affects humans. 15/n
1
2
14
📢Job announcement📢
If you liked our recent paper, or are interested in tackling hard problems in AI alignment (both near-term and long-term), the
@OpenAI
Reflection team is now hiring for research scientist/ engineer roles!
See RE job description here:
VERY excited to announce new work from our team (one of the safety teams
@OpenAI
)!! 🎉
We wanted to make training models to optimize human preferences Actually Work™.
We applied it to English abstractive summarization, and got some pretty good results.
A thread 🧵: (1/n)
3
48
301
1
0
14
Watching
@OpenAI
's bot beat the best human Dota2 players at the office -- incredible accomplishment!!


0
3
14
This has been in the works for a while --- will be interesting to see how much we've collectively overfit on Atari. Congrats to the openai team
Releasing Gym Retro — 1000+ games for reinforcement learning research, plus an integrator tool to add your own classic games.
18
647
2K
1
5
14
Okay, paper PR over. Now the interesting stuff. Why am I actually excited about this? What are some of the issues with our approach?
1
0
12
That being said, convergence to BS is more likely if all papers are required to write a social impact statement that 'sounds nice'.
Papers with no social impact introduced above previous work (e.g. many theoretical papers) should be encouraged to say so.
1
0
13
There are so many more results in the paper, I can’t (won’t?) describe them all here. Check it out if you’re interested: . Definitely one of the best papers I’ve ever helped write.
1
1
12
What if we had AI systems where one of the fundamental "information units" they used in making their decisions was what people actually valued in their life?
I think this is a big problem today but will get way way more important as LMs are given more power, and play more of a
1
1
13
A good 🧵
For white folks, being called racist is shocking because it means you are a *bad person*. Only *bad people* are racist because racism is bad, right?
Not so. Most good people have racist biases. Defensiveness is natural, but it makes it hard to really self-reflect. 1/

I've been noticing a trend in recent conversations (though I'm sure it's not a new trend) to talk about "accusations" of {racism, gaslighting, tone policing} and I think I've finally put my finger on what's bugging me about it:
1
12
42
1
0
13
I first realized the dinner was explicitly designed around this friend group's values -- in the same way that the paper talks about values!! 🤯
1
0
13
whoever this person is they consistently produce bangers, strong recommend 💯


0
0
11
All of this work is with my incredible collaborators on the Reflection team:
@paulfchristiano
, Nisan Stiennon, Long Ouyang, Jeff Wu, Daniel Ziegler, and
@csvoss
, plus
@AlecRad
and Dario Amodei. 🔥❤️
(fin)
1
0
13
Our approach is to combine RL from human feedback (our previous work) with recursive task decomposition: we train models to summarize small parts of the book, and then summarize those summaries, etc etc, until it’s summarized the whole book.

1
1
13
(aside: the paper talks about values in terms of things people pay attention to when they made a meaningful choice -- so more like choosing to spend the day in nature and less like choosing to brush your teeth.
we represent them as these things called values cards. here's a

1
0
13
That's one of the huge problems we're facing right now: the algorithms that we entrust to shape our digital lives have very little idea about what we actually care about.
(and of course, little incentive to optimize this over engagement, which we also need to address)
1
1
13
Joe et al.’s work on meaning has significantly shifted my thinking about alignment in the last 6 months.
The talk is good and worth checking out!
I'm pleased to release the talk “Rebuilding Society on Meaning: Practical Techniques to Align Markets, Recommenders, Social Networks, and Organizations with Togetherness and Meaning”.
This 80m talk is my life's work!

11
54
257
0
0
11
Very neat paper. Distributional semantics is not enough to predict some useful features of concepts -- grounding is likely necessary
0
0
11
Incredible how the Mtl AI scene has exploded in 1.5 years. Seems contigent on not just strong ML labs, but on recognized AI personalities
0
1
11
.
Announcing GPT-4, a large multimodal model, with our best-ever results on capabilities and alignment:
2K
17K
64K
0
0
5