
Shibani Santurkar
@ShibaniSan
Followers
2,995
Following
184
Media
5
Statuses
146
Joined September 2014
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Bangladesh
• 678566 Tweets
フワちゃん
• 370995 Tweets
ニコニコ
• 359540 Tweets
Rebeca
• 289679 Tweets
#SheikhHasina
• 86250 Tweets
Júlia
• 79061 Tweets
イタリア
• 78573 Tweets
#海のはじまり
• 59457 Tweets
शेख हसीना
• 56822 Tweets
株価暴落
• 56321 Tweets
#CDTVライブライブ
• 51914 Tweets
#GinasticaArtistica
• 43056 Tweets
#男子バレーボール
• 39377 Tweets
Ángel Barajas
• 32822 Tweets
Ed Balls
• 31938 Tweets
みなとみらい
• 28735 Tweets
バングラデシュ
• 28265 Tweets
Alice D'Amato
• 25219 Tweets
バレー男子
• 23807 Tweets
全世界キャラクター人気投票
• 22116 Tweets
カノウさん
• 16890 Tweets
岡慎之助
• 14849 Tweets
Young Boys
• 14243 Tweets
VAMOS LEONAS
• 10870 Tweets





















Does language supervision (as in CLIP) help vision models transfer better?
You might expect a clear-cut answer: 'captions always help' or 'not at all'. But w/
@yanndubs
@rtaori13
@percyliang
@tatsu_hashimoto
, we find that the picture is nuanced.🧵

2
42
202
❤️

1
1
72
💙💙💙💙💙💙💙

We have reached an agreement in principle for Sam Altman to return to OpenAI as CEO with a new initial board of Bret Taylor (Chair), Larry Summers, and Adam D'Angelo.
We are collaborating to figure out the details. Thank you so much for your patience through this.
6K
13K
67K
1
2
56
Auto data selection is comparable to expert curated data for pretraining LMs!
The leverage: n-gram overlap between pretrain and downstream predicts downstream acc well (r=0.89). But it's not the whole story - lots to uncover on the effect of pretrain data on downstream tasks.

Data selection typically involves filtering a large source of raw data towards some desired target distribution, whether it's high-quality/formal text (e.g., Wikipedia + books) for general-domain LMs like GPT-3 or domain-specific data for specialized LMs like Codex.
1
1
11
0
8
38
💛

I deeply regret my participation in the board's actions. I never intended to harm OpenAI. I love everything we've built together and I will do everything I can to reunite the company.
7K
4K
33K
1
0
21
Come talk to us at our NeurIPS poster from 8:30-10am PT today (now) at spot A2!

Can we perform surgery on the prediction rules of an already trained classifier? It turns out yes (and with only a single example too!) with
@ShibaniSan
,
@tsiprasd
, Mahi Elango, David Bau, and Antonio Torralba
Paper:
Blog post:

3
29
139
0
3
18
So proud!
Congratulations,
@tsiprasd
! Extremely well deserved—it was an honor to be a (small) part of your (now, honorable ;) PhD journey.
1
4
49
0
1
14
@aleks_madry
@zacharylipton
It's been a blast! Thank you for being an incredible advisor
@aleks_madry
0
0
14
🚢 🚢 🚢
ChatGPT with voice is now available to all free users. Download the app on your phone and tap the headphones icon to start a conversation.
Sound on 🔊
2K
3K
17K
0
1
13
Based on our findings, we design simple interventions to improve CLIP’s ability to leverage web-scraped captions: by filtering them and using GPT-J to perform text data augmentations via paraphrasing.
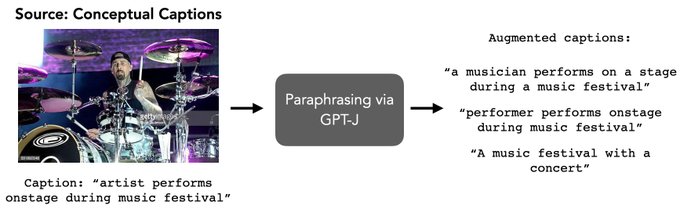
0
1
11
(ii) *What is in the caption matters*
Given a data budget, CLIP’s performance depends on whether captions directly discuss parts of the image (left) or are complementary to it (right).
In fact, one descriptive COCO caption is worth 5x YFCC ones!

2
0
10
We find that:
(i) *Scale is crucial*
When the dataset used to train CLIP/SimCLR is fairly large, CLIP >> SimCLR. If not, SimCLR >> CLIP. Also, the transition point between these regimes is dataset dependent (vertical lines).
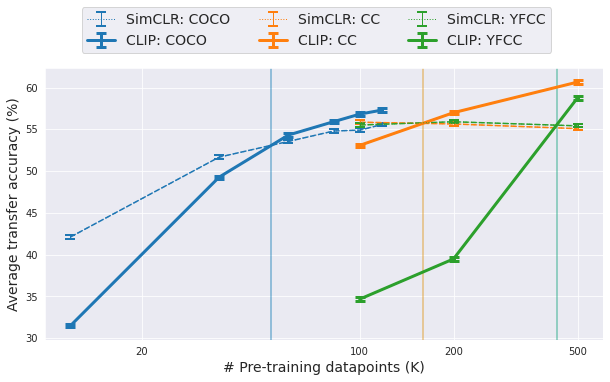
1
0
8
(iii) *Caption variability hurts CLIP*
Captions often vary in how they describe an object (e.g., “bike”/”cycle”/”bicycle”/…), and the parts of the image they focus on. This makes it harder for CLIP to learn but luckily can be mitigated by sampling multiple captions per image!
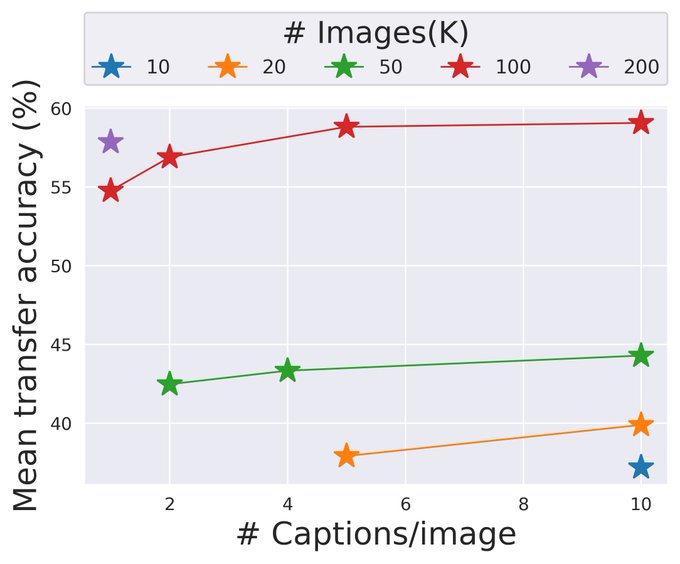
2
1
7
We perform an apples-to-apples comparison of CLIP with a matched image-only approach (a variant of SimCLR). We train both with the same loss function, architecture, training data, data augmentations, etc., to isolate the effect of language (caption) supervision.
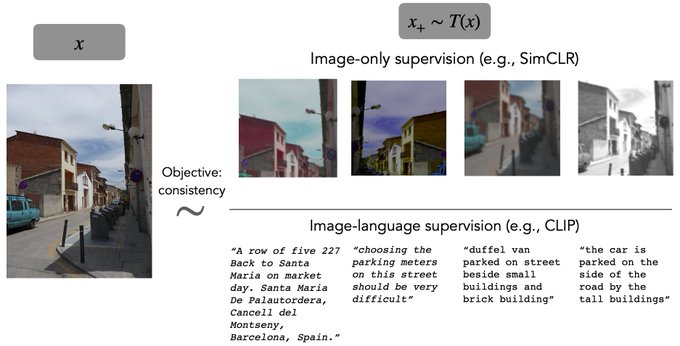
1
0
4
@RWerpachowski
@EliSennesh
@aleks_madry
@Epsilon_Lee
@tsiprasd
An important direction for future work...
0
0
4
@JaydeepBorkar
@chipro
@_srishtiyadav
@akanksha_atrey
Thanks you
@JaydeepBorkar
! Would also love to see
@charapod
@whybansal
included :)
1
0
4
@optiML
@aleks_madry
@tsiprasd
@andrew_ilyas
Thanks! Actually, our results go beyond the DLNs. We are able to analyze the effect of adding BatchNorm to a single fully connected layer assuming that the loss (as a function of the layer's output) has non-zero first and second derivatives.
2
0
2
@sh_reya
@aleks_madry
@tsiprasd
Thank you!
- Yes, the train and test subpopulations need not be disjoint. We chose to focus on this extreme since it is the most challenging (and perhaps cleanest) setting. Still we agree that there are many interesting variants to study (our codebase can be used for this too).
1
0
2
@sh_reya
@aleks_madry
@tsiprasd
- The source accuracy does drop when we fine-tune. But, if we fine-tune on both domains, source accuracy remains essentially unchanged while still reaching almost the same target accuracy.
1
0
2
@BenErichson
@HanieSedghi
@aleks_madry
@tsiprasd
Interesting! Would be curious to see if this is also the case for our subpopulation shift benchmarks.
1
0
2
1
0
1
0
0
1
0
0
1