

Sang Michael Xie
@sangmichaelxie
Followers
3K
Following
2K
Media
56
Statuses
366
Research Scientist at Meta GenAI / LLaMA. AI + ML + NLP + data. Prev: CS PhD @StanfordAILab @StanfordNLP @Stanford, @GoogleAI Brain/DeepMind
Stanford, CA
Joined May 2019
Should LMs train on more books, news, or web data?. Introducing DoReMi🎶, which optimizes the data mixture with a small 280M model. Our data mixture makes 8B Pile models train 2.6x faster, get +6.5% few-shot acc, and get lower pplx on *all* domains!. 🧵⬇️

16
148
675
Why can GPT3 magically learn tasks? It just reads a few examples, without any parameter updates or explicitly being trained to learn. We prove that this in-context learning can emerge from modeling long-range coherence in the pretraining data!. (1/n)

4
138
550
I've gotten some requests about the "building language models" project from last year's Stanford Large Language Models class, so we're releasing it: The task is to finetune LMs to give them new capabilities/properties, similarly to Toolformer and Alpaca.

7
72
339
Data selection for LMs (GPT-3, PaLM) is done with heuristics that select data by training a classifier for high-quality text. Can we do better?. Turns out we can boost downstream GLUE acc by 2+% by adapting the classic importance resampling algorithm. 🧵

4
60
338
Releasing an open-source PyTorch implementation of DoReMi! The pretraining data mixture is a secret sauce of LLM training. Optimizing your data mixture for robust learning with DoReMi can reduce training time by 2-3x. Train smarter, not longer!
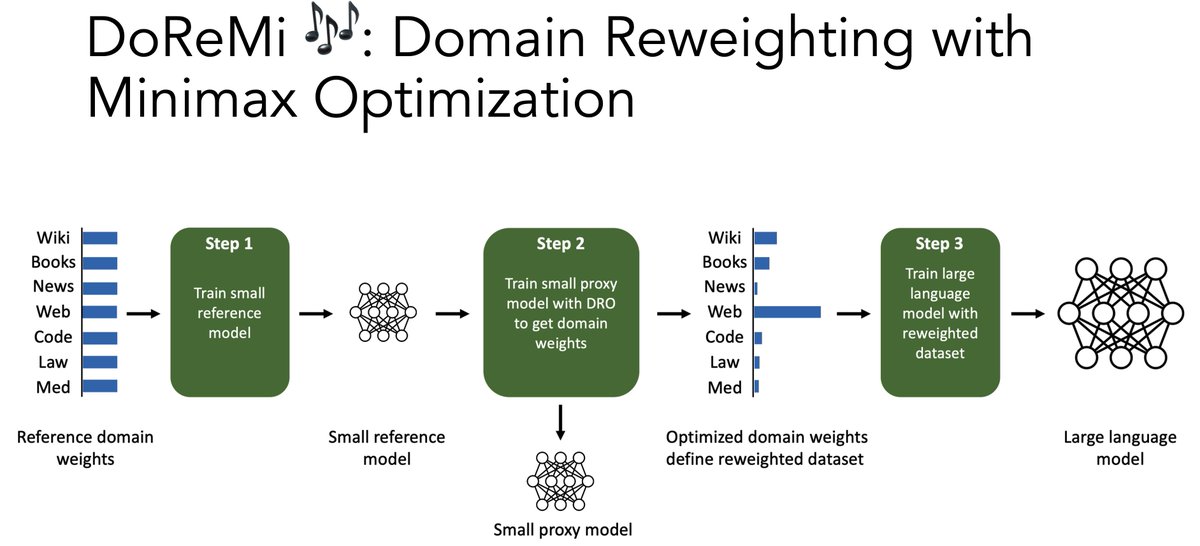
Should LMs train on more books, news, or web data?. Introducing DoReMi🎶, which optimizes the data mixture with a small 280M model. Our data mixture makes 8B Pile models train 2.6x faster, get +6.5% few-shot acc, and get lower pplx on *all* domains!. 🧵⬇️
2
68
271
How can large language models (LMs) do tasks even when given random labels? While traditional supervised learning would fail, viewing in-context learning (ICL) as Bayesian inference explains how this can work!. Blog post with @sewon__min:
2
58
238
I’m presenting 2 papers at #NeurIPS2023 on data-centric ML for large language models:. DSIR (targeted data selection): Wed Dec 13 @ 5pm.DoReMi (pretraining data mixtures): Thu Dec 14 @ 10:45am. Excited to chat about large language models, data, pretraining/adaptation, and more!


7
31
215
DSIR is a fast trillion-token-scale data selection tool for LLMs that’s been used on the Pile/RefinedWeb/C4/CCNet/RedPajama/etc. ⚡️Select 100M documents from the full Pile in just 𝟰.𝟱 𝗵𝗼𝘂𝗿𝘀 with 1 CPU node. Now on PyPI: pip install data-selection. Just 4 lines of code:

7
35
203
🍔🍟"In-N-Out: Pre-Training and Self-Training using Auxiliary Information for Out-of-Distribution Robustness". Real-world tasks (crop yield prediction from satellites) are often label-scarce. Only some countries have labels - how do we generalize globally?

1
36
163
Fine-tuning destroys some pre-trained info. Freezing parameters *preserves* it and *simplifies* the learning problem -> better ID and OOD accuracy. Excited to present Composed Fine-Tuning as a long talk at #ICML2021! . Paper: Talk:

2
20
108
The 2nd ME-FoMo workshop on understanding foundation models will be at ICLR 2024 in Vienna! Topics include pretraining (data, archs), adaptation (instruct tuning, alignment), and emergence. Paper ddl: Feb 3.Website: OpenReview:

1
21
110
(1/n) Persistent neck pain and how to fix it: A thread for computer people 💻👇. Neck pain can stick around forever if you use the computer every day, especially in suboptimal WFH setups. Here's my story and a highly effective exercise that worked for me:

3
17
105
Simplifying Models with Unlabeled Output Data.Joint w/ @tengyuma @percyliang. Can “unlabeled” outputs help in semi-supervised learning? In problems with rich output spaces like code, images, or molecules, unlabeled outputs help with modeling valid outputs.

2
20
88
Robustness from adversarial training tends to come at the cost of standard accuracy. We show this can happen in min-norm linear regression models and prove that we can fix the tradeoff with unlabeled data, motivating the use of robust self-training!.
2
24
86
Summary of #foundationmodels for robustness to distribution shifts 🧵:. Robustness problem: Real-world ML systems need to be robust to distribution shifts (training data distribution differs from test). Report:

2
9
60
Excited to work and learn with @AdamsYu @hieupham789 @quocleix over the summer at Google Brain in Mountain View! Hope to make some nice improvements in pretraining. Now if only I can figure out how to do all these onboarding tasks….
2
4
48
GPT3 explaining our abstract on tradeoff between robustness and accuracy to 2 year olds:."Sometimes when you train a machine learning model, it gets better at handling bad situations, but it gets worse at handling good situations."🤣😳. cred: Aditi Raghunathan & @siddkaramcheti.
1
2
46
How can we mitigate the tradeoff between adversarial robustness and accuracy? w/ Aditi Raghunathan, Fanny Yang, John Duchi, @percyliang. Come chat with us #ICML2020: 11am-12pm PST, 10-11pm PST video: paper:
2
11
46
ShearedLLaMA uses DoReMi with a scaling law as the reference model to optimize the data mixture on RedPajama -> strong results at 1.3B and 3B!.

We release the strongest public 1.3B and 3B models so far – the ShearedLLaMA series. Structured pruning from a large model to a small one is far more cost-effective (only 3%!) than pre-training them from scratch!. Check out our paper and models at: [1/n]
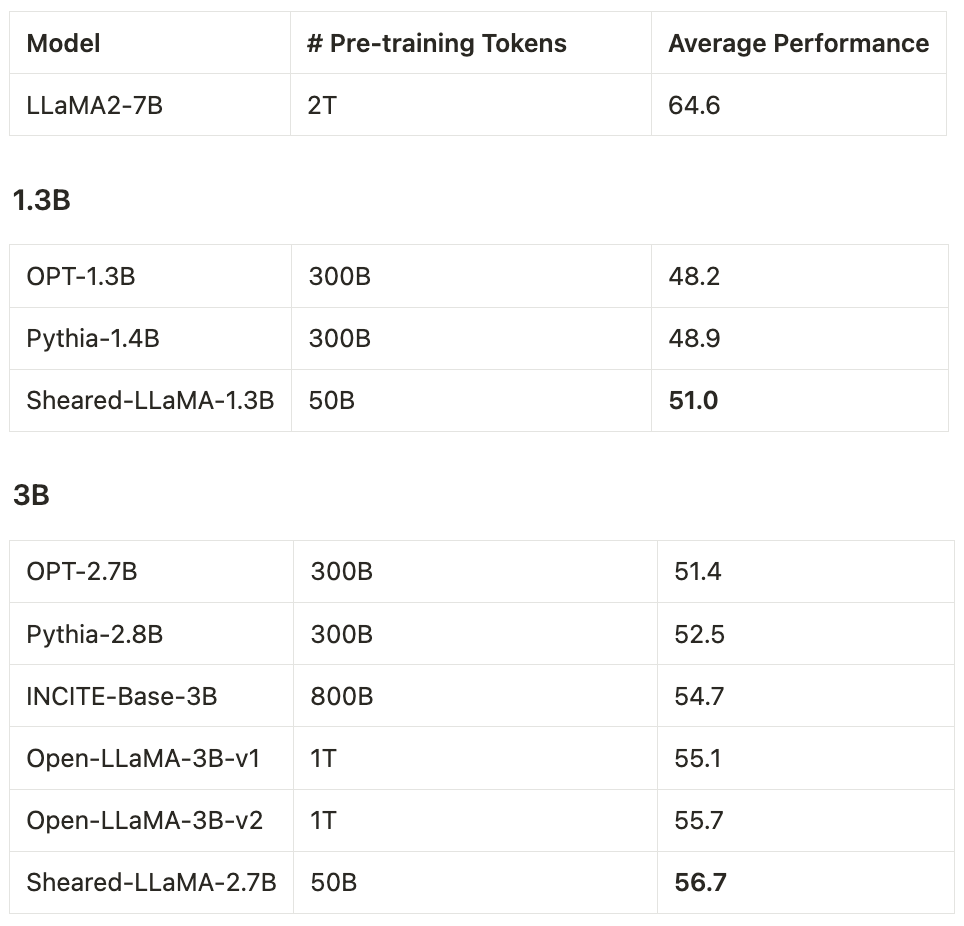
0
3
40
Had a great time talking to prospective Stanford grad students at #Tapia2020! GL to everyone! . If you’re applying to the Stanford CS PhD program this fall: for an app review with a current student. Priority for students from under represented minorities.
1
6
34
We publish our optimized domain weights for The Pile to improve future language model training!. Interestingly, DoReMi's domain weights decrease the weight on Wikipedia but produce a model with better performance on Wikipedia-based tasks (TriviaQA, SQuAD, etc).

1
4
32
Excited to co-organize this ICLR 2024 workshop! I think better data will be crucial for the next big advances in foundation models. The submission date is Feb 3 - details at

Excited to announce the ICLR 2024 Workshop on Data Problems for Foundation Models (DPFM)! .- Topics of Interest: data quality, generation, efficiency, alignment, AI safety, ethics, copyright, and more. - Paper Submission Date: Feb 3, 2024 | Workshop Date: May 11, 2024 (Vienna and

0
4
28
I will be presenting "Reparameterizable Subset Sampling via Continuous Relaxations" @IJCAIconf.tomorrow, work with @ermonste! End-to-end training of models using subset sampling for model explanations, deep kNN, and a new way to do t-SNE.
1
3
27
WILDS collects real world distribution shifts to benchmark robust models! I’m particularly excited about the remote sensing datasets (PovertyMap and FMoW) - spatiotemporal shift is a real problem, and space/time shifts compound upon one another. Led by @PangWeiKoh @shiorisagawa.

We're excited to announce WILDS, a benchmark of in-the-wild distribution shifts with 7 datasets across diverse data modalities and real-world applications. Website: Paper: Github: Thread below. (1/12)

0
2
27
Pretraining is surprisingly powerful for domain adaptation, and doesn’t rely on domain invariance! The magic comes from properties of the data augmentations used, leading to disentangled class and domain info. With this, finetuning on class labels allows for ignoring the domain.

Pretraining is ≈SoTA for domain adaptation: just do contrastive learning on *all* unlabeled data + finetune on source labels. Features are NOT domain-invariant, but disentangle class & domain info to enable transfer. Theory & exps:
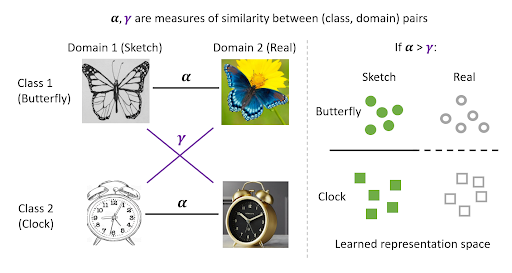
0
2
25
Interestingly, pretraining on unlabeled source/target+finetuning doesn’t improve much over just supervised learning on source in iWildcam-WILDS. Correspondingly, the connectivity conditions on the success of contrastive pretraining for UDA ( also fail!.

What's the best way to use unlabeled target data for unsupervised domain adaptation (UDA)?. Introducing Connect Later: pretrain on unlabeled data + apply *targeted augmentations* designed for the dist shift during fine-tuning ➡️ SoTA UDA results!. 🧵👇

1
5
26
We’re organizing a workshop on understanding foundation models at #ICLR2023! We welcome any unpublished or ongoing work on empirical or theoretical understanding, as well as highlighting phenomena like scaling laws or emergence. Deadline is Feb 3, 2023.

Foundation models (BERT, DALLE-2, ChatGPT) have led to a paradigm shift in ML, but are poorly understood. Announcing ME-FoMo, an #ICLR2023 workshop on understanding foundation models. Deadline: Feb 3, 2023.Topics: Pretraining, transfer, scaling laws, etc

0
3
23
Some of the most powerful abilities of language models (GPT-3) are its intuitive language interface and its few shot learning abilities. These abilities can make it easier to design the rewards for an RL agent, with just a text description or a few demonstrations.

Can we make it easier to specify objectives to an RL agent?. We allow users to specify their objectives more cheaply and intuitively using language! . 🧵👇.Paper: Code: Talk:
0
3
22
Check out our #ICLR2021 poster on In-N-Out at 5-7pm PST tomorrow (Wed May 5): we show how to improve OOD performance by *leveraging* spurious correlations and unlabeled data, and we test it on real world remote sensing tasks!.
This appears in #ICLR2021. Please check out our paper, videos, poster, code, etc! .ICLR poster link: ArXiv: Codalab: Github:
1
4
22
Very cool paper on high-dimensional calibration / online learning by my brother Stephan @stephofx, who is applying to PhD programs this year!.

Super excited about a new paper (with applications to conformal prediction and large action space games) that asks what properties online predictions should have such that acting on them gives good results. Calibration would be nice, but is too hard in high dimensions. But.

0
1
21
Our foundation models (GPT3, BERT) report has a section on how they improve robustness to distribution shifts, what they may not solve, and future directions, w/ @tatsu_hashimoto @ananyaku @rtaori13 @shiorisagawa @PangWeiKoh and TonyL!. thx to @percyliang for leading the effort!


NEW: This comprehensive report investigates foundation models (e.g. BERT, GPT-3), which are engendering a paradigm shift in AI. 100+ scholars across 10 departments at Stanford scrutinize their capabilities, applications, and societal consequences.

0
4
21
Great effort led by @AlbalakAlon to corral the wild west of LM data selection!. A meta-issue: how do we make data work (esp. for pretraining) more accessible? Not everyone can train 7B LMs, but a first bar is to show that the benefits don't shrink with scale, at smaller scales.

{UCSB|AI2|UW|Stanford|MIT|UofT|Vector|Contextual AI} present a survey on🔎Data Selection for LLMs🔍. Training data is a closely guarded secret in industry🤫with this work we narrow the knowledge gap, advocating for open, responsible, collaborative progress.

1
1
19
this guy. .

I just discovered this account I made 11 years ago. So how does one use these Twitters?.
0
0
19
My brother (a high schooler) made for donating health equipment to people in need directly from home! . How it works: .1. Donors don't need anything on hand - you can order directly from online sites like Amazon to the recipient. (1/4)

1
6
18
But optimizing for worst-case loss could be bad! It upweights the most noisy domains. Instead, we optimize the worst-case loss gap between the model being evaluated and a reference model trained on un-tuned domain weights.
3
0
18
Using our understanding we created GINC, a small-scale synthetic dataset where in-context learning emerges for both Transformers and LSTMs. In-context accuracy increases with the number of examples and the length of each example (k). Code: (1.3/n)

1
2
17
Some intuitions:.- Low entropy / predictable domains don’t need much data to learn well. - High entropy / noisy domains don’t need much data either since models at random init already output a uniform distribution over tokens. DoReMi naturally downweights these domains.
4
0
18
There should be a website that constantly updates the current best practices and models in deep learning . No one does early stopping anymore right?.
6
2
14
Our theory doesn't capture everything since it focuses on the role of the pretraining distribution. Our experiments show that model architecture and model size matter too. Bigger models were better at in-context learning despite achieving the same pretraining loss!. (1.4/n)


1
1
14
Importantly, DoReMi can tune the domain weights (sampling frequencies for each domain) with a small model (280M params). These domain weights improve perplexity and downstream accuracy of a 30x larger model (8B params) *without using any downstream tasks*.
1
0
14
Before diving in - we've uploaded pre-filtered datasets to HuggingFace that were selected from The Pile for high-quality text! .You can also use the code to select custom language modeling datasets from The Pile. Pre-filtered Pile data and code:
1
2
14
Adversarial Training can Hurt Generalization - even if there is no conflict with infinite data and the problem is convex. With @Aditi_Raghunathan and @Fanny_Yang. #icml2019 Identifying and Understanding Deep Learning Phenomena.
1
0
13
This course assignment was developed with the help of @percyliang and the rest of the course instructors @tatsu_hashimoto, Chris Ré @HazyResearch, and @RishiBommasani. Class lecture materials are here:
0
1
13
The blog post is based on two papers: (An Explanation of In-context Learning as Implicit Bayesian Inference) and (Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?) by @sewon__min.
1
2
13
Reallocating weight to challenging but learnable domains can improve perplexity on all domains through positive transfer. Often, DoReMi upweights diverse and high-quality domains like filtered web text.
1
0
11
Joint w/ @ananyaku, @rmjones96, @___fereshte___, @tengyuma, @percyliang. We also presented this work at the Climate Change AI workshop at NeurIPS, check it out!.
0
2
11
WILDS includes some nice examples of real world distribution shifts, including spatial and temporal shifts in satellite image tasks: poverty (PovertyMap) and building/land use prediction (FMoW). Hope these help spur progress in ML for sustainability + social good! #ICML2021.

We’re presenting WILDS, a benchmark of in-the-wild distribution shifts, as a long talk at ICML!. Check out @shiorisagawa's talk + our poster session from 9-11pm Pacific on Thurs. Talk: Poster: Web: 🧵(1/n)

0
5
11
Couple of unreasonable things. My mother works at a lab where she works with data (a computer job). She asked to stay home but instead they moved her into the wet lab and made her come in. Now they cut half her hours amidst layoffs/furloughs.
1
1
10
Central intuition: To account for a diversity of downstream tasks, try to achieve low loss on all domains. This motivates DoReMi, which adapts group distributionally robust optimization (Group DRO) to find domain weights that optimize for the worst-case domain.
1
0
12
Data selection typically involves filtering a large source of raw data towards some desired target distribution, whether it's high-quality/formal text (e.g., Wikipedia + books) for general-domain LMs like GPT-3 or domain-specific data for specialized LMs like Codex.
1
1
11
Blog on @StanfordCRFM for more details: Thanks to @togethercompute for providing compute resources for testing the codebase!.
0
0
11
On The Pile, DoReMi's domain weights improve perplexity on all domains, even though some domains are downweighted. How can this be?. Via a simple example, we show it's possible to have no tradeoff when there are very low entropy (predictable) and high entropy (noisy) domains.
1
0
12
Check out the GitHub and paper for more details:. Github: Paper: Thanks to code contributions and tests by @tianxie233 from @SFResearch!.
0
2
10
This was work done during an internship at @GoogleAI, jointly with @quocleix, @percyliang, @tengyuma, @hyhieu226, @AdamsYu, @yifenglou, @XuanyiDong, @Hanxiao_6. Thanks also to @edchi for the support at the Brain team!.
1
0
10
We assume all sentences in a pretraining document share a latent concept (long-range coherence). To generate coherent next tokens in LM pretraining, the LM must infer the latent concept. Inferring a shared concept from examples in a prompt leads to in-context learning!.(1.2/n).
1
1
10
If anyone got Type 3 font errors while submitting their camera ready to ICML, it's likely because matplotlib defaults to Type 3 fonts. this website helped but still had to regenerate every plot
0
4
10
In-context accuracy on the small-scale GINC data is quite sensitive to example order, just like GPT3 (e.g., . Each training ID in the figure is a set of examples, and each dot is a different permutation of the examples. (2/n)

1
1
10
We ran DoReMi with a 120M proxy model on The Pile (w/ NeoX tokenizer + FlashAttention2). A 120M model trained on DoReMi weights surpasses the baseline one-shot performance very early during training, within 70k steps (3x faster) across all tasks and within 20k steps on average!

1
0
10
Because of the large scale of raw text data, existing methods (GPT-3, PaLM, Pile) use heuristics: simple classifier + a noisy threshold to select data similar to the target distribution. But the selected data may lack diversity/be too diverse compared to the desired target dist.
1
0
9
On the GLaM dataset where domain weights tuned with downstream tasks are available, DoReMi finds domain weights that are similar to downstream-tuned weights. However, DoReMi doesn't use downstream tasks and optimizes the domain weights more efficiently (no RL, search).
1
0
9

How it works: DSIR selects a subset of a large raw dataset that is distributed like a target dataset on a reduced feature space (hashed n-grams). Under the hood, importance resampling automatically balances relevance and diversity by matching the target 𝘥𝘪𝘴𝘵𝘳𝘪𝘣𝘶𝘵𝘪𝘰𝘯.

1
0
9
@PreetumNakkiran Agreed it's not "standard" learning, but labels still matter - there is still a small drop with random labels in Sewon's paper, and ( "Pushing the Bounds. ") shows that if you re-map the labels, the model will learn the remapping

1
0
8
Please fill out or help circulate this form for those interested in reviewing for our ICLR workshop on understanding foundation models! .

Call for reviewers for our #ICLR2023 workshop on Mathematical and Empirical Understanding of Foundation Models. Fill out this form if you are interested.and we will aim to get back to you asap. Paper deadline: 3 Feb.Tentative reviewing period: 10-24 Feb.

0
2
8
Our method, Data Selection with Importance Resampling (DSIR), uses importance resampling to select data that *matches* a target dist. To make importance weight estimation tractable in the high-dimensional space of text, we work in a reduced feature space.
1
0
8
CubeChat is really cool! Your webcam video is on the side of a cube and you can move and jump around in a 3D world. You can even share your screen and it looks like a drive in movie theater for cubes 😄.

Our team just launched CubeChat! 3D video chat with spatial audio--can be multiple conversations going on at once in a room! Please DM me if you are interested in trying it out.
0
4
8
As a black box, the codebase outputs optimized domain weights given a text dataset (+ domain info). Some other useful components: fast, resumable dataloader with domain-level weighted sampling, simple downstream eval harness, and HuggingFace Trainer + FlashAttention2 integration.
1
0
8
DSIR log-importance weights are also included in RedPajamav2 from @togethercompute as quality scores!.
1
1
7
We assume the LM fits the pretraining distribution exactly. Thus, we can just characterize the conditional distribution given prompts (posterior) under the pretraining dist, marginalizing over latent concepts. Thus in-context learning can be viewed as Bayesian inference!. (6/n).
1
1
7
What are some good datasets for regression? Is it just UCI? . Regression dataset land seems a little sparse to me.
2
0
7
We propose a framework for using “unlabeled” output data (e.g. code on Github) by learning an output denoiser with self-supervision, then learning a predictor composed with the denoiser. By offloading complexity to the denoiser, the learned predictor can be much simpler.

1
0
7
Zero-shot is sometimes better than one/few-shot for some settings of GINC because of the OOD/unnatural prompt structure. This matches observations in the GPT-3 paper for some datasets (e.g., LAMBADA, HellaSwag, PhysicalQA, RACE-m, CoQA/SAT analogies for smaller models). (3/n)

1
1
7
Bayesian inference view of ICL: all examples in a prompt share a latent “concept”, which should be applied to the test example to answer it correctly. The LM infers the latent concept by using the prompt to "locate" it from a large set of concepts learned from pretraining.
1
1
6
Which feature space? N-grams! We find that KL reduction, a cheap data metric that measures how much data selection reduces KL to the target n-gram distribution over random sampling, predicts downstream acc very well (r=0.89). Potential for powering new data-centric workflows!

1
0
7
Does choice of pretraining data matter? We selected pretraining data for 8 downstream tasks and tried all pretrain->downstream pairs. Using the wrong pretraining data causes a 6% average drop in downstream acc, and drops acc by 30% in one case!. Choice of data matters a lot.

1
0
6
Our algorithm, In-N-Out, first trains a model with auxiliary inputs and uses it to pseudolabel all the in-distribution inputs (where auxiliary inputs help), then pre-trains a model on OOD auxiliary outputs and fine-tunes this model with the pseudolabels (self-training).

1
2
6
The GINC dataset makes it easier to ask some questions about in-context learning that are hard to ask with real data. For example, we found that the models failed to extrapolate to random unseen concepts. (4/n)

1
1
6
Details: we introduce a simple pretraining distribution and show that it gives rise to in-context learning. The pretraining documents are generated from HMMs, and the latent concept is the hidden state transition matrix. (5/n).
1
1
5
To become a 10x researcher simply commit to 10x more deadlines, during deadlines you can do in a day what would normally take you 2 weeks 💪.

10x researchers. Professors, if you ever come across this rare breed of researchers, grab them. If you have a 10x researcher as part of your lab, you increase the odds of winning a Turing award significantly. OK, here is a tough question. How do you spot a 10x researcher?.
0
0
6
(6/n) HIGHLY EFFECTIVE exercise for neck pain: Stretch the shoulders by taking a towel or exercise band and grab the ends in front of you, holding it taut. Slowly move your arms over your head and all the way behind your back. Do this back-and-forth 10 times, 2 sets, daily.

2
1
6
Please see the report (Sec 4.8 for more details! Thanks to w/ @tatsu_hashimoto @ananyaku @rtaori13 @shiorisagawa @PangWeiKoh and TonyL for the writing efforts, and @percyliang and @RishiBommasani for organizing!.
1
0
6
Real-world example: poverty mapping from satellite imagery in under-resourced countries, where only some countries have labeled data from (expensive) surveys. Satellite images are available everywhere and there's spatial structure. Pre-training seems to help here too.
1
0
6
Surprisingly, adding new input features (aux-inputs) can hurt OOD accuracy - even though in-distribution (ID) accuracy improves. Pre-training by predicting auxiliary information as outputs (aux-outputs) instead improves OOD accuracy by learning better features on unlabeled data.
1
1
6
Main result: if the signal about the latent concept from the examples dominates the error from the unnatural transitions between examples, then the model does in-context learning with enough examples. Making each example longer also helps boost the signal. (8/n).
1
1
6
Speed benchmark on selecting from the full Pile:.* Resources: 1 CPU node, 96GB RAM, 96 cores.* Fit importance estimator: 59s.* Compute importance weights: 4.36h.* Resample 10M documents : 6min.* Total: 4.5 hours. This can be even faster with more CPU cores!.
1
0
5
There are no preprocessing steps, other than decompressing the data for faster reading. However, we also support reading from any file format, including compressed zst, through custom loading functions.
1
0
5
@andersonbcdefg @Google @GoogleAI @Stanford @StanfordAILab @stanfordnlp @quocleix @percyliang @AdamsYu @hyhieu226 @XuanyiDong We could probably handle hundreds of domains with a large enough batch size. But handling a large number of domains well is a next step!.
1
0
4
I guess the implicit knowledge is that we can differentiate through convex cone programs, cool!.

CVXPY is now differentiable. Try our PyTorch and TensorFlow layers using our package, cvxpylayers: (& see our NeurIPS paper for details .
1
0
5
My friend flew to the Bay Area because that’s where his medical board exam was scheduled, a $700 (multiple choice?) test that, under lockdown, A. still requires $100 to reschedule and B. had no other open slots anyway. Best answer would have been C. shelter in place.
1
0
5
In-N-Out outperforms auxiliary inputs or outputs alone on both in-distribution and OOD error across three image and time-series datasets: CelebA (hat/no hat shift) and 2 real-world remote sensing tasks (landcover and cropland prediction) with unseen countries/regions.


1
0
5
When selecting for formal/high-quality text (Wiki+books) to train general-domain LMs, DSIR selects data that contains qualitatively more formal text than random selection and heuristic filters. This results in 2–2.5% higher downstream acc on GLUE than these baselines.

1
0
5
(7/n) Complement these with neck exercises and stretches, as well as the cobra pose from yoga. It's literally the opposite of sitting. ~balance~. Consistency is key. Foam rolling the neck gently also helped. Finally, TAKE BREAKS - your body and mind will thank you for it!

1
0
5
Part 1: instill the ability to control the word length of GPT-2's outputs by training on data that has length info prepended before each sentence. Part 2 is open-ended: instill a new capability in an LM. The students were really creative here (humor, poetry, math,. )!.
1
0
5
In multi-task linear regression, we show pre-training provably improves robustness to *arbitrary* covariate shift and provides complementary gains with self-training. This could provide theoretical explanations for recent empirical works by @DanHendrycks @barret_zoph @quocleix.
1
0
5
Many thanks to collaborators and colleagues that shaped this post! @LukeZettlemoyer @percyliang @tengyuma @megha_byte @RishiBommasani @gabriel_ilharco @wittgen_ball @ananyaku @OfirPress @yasaman_razeghi @mzhangio.
1
1
5
Composing with a denoiser provably reduces complexity for 2-layer networks in problems with discrete valid output spaces. Empirically, the framework improves performance on image generation and full-program pseudocode-to-code translation, but many other applications are possible!.
1
0
5
This leads to our instantiation of DSIR, where we train 2 generative bag-of-ngrams models (one each for the raw and target data) to estimate importance weights. The n-grams are hashed onto a fixed number of virtual tokens (hashing trick) for simplicity and tractability.
1
0
5