
Barret Zoph
@barret_zoph
Followers
19K
Following
1K
Media
43
Statuses
254
VP Research (Post-Training) @openai Past: Research Scientist at Google Brain.
San Francisco, CA
Joined November 2016
I posted this note to OpenAI. Hey everybody, I have decided to leave OpenAI. This was a very difficult decision as I have has such an incredible time at OpenAI. I got to join right before ChatGPT and helped build the post-training team from scratch with John Schulman and.
164
180
4K
After 6 years at Google Brain I am excited to announce that I joined OpenAI! . Very grateful for all the amazing collaborators and friends I have made at Google over the years. Could not be more excited to continue to help push AI progress and for the new adventures ahead.
59
42
2K
Our team at OpenAI is hiring! We're looking for engineers/researchers who do rigorous and thoughtful work understanding and evaluating LLMs like ChatGPT. If you're interested, please apply online and DM me with work that you've done!.
42
103
729
Introducing Switch Transformer, a simplified sparse architecture for scaling to trillion parameter language models. Switch Transformers yield 4-7x speedups over strong Transformer T5 models w/ the same computational resources. Paper:

3
139
661
*New paper* RandAugment: a new data augmentation. Better & simpler than AutoAugment. Main idea is to select transformations at random, and tune their magnitude. It achieves 85.0% top-1 on ImageNet. Paper: Code:

3
147
571
Can simply copying and pasting objects from one image to another be used to create more data to improve state-of-the-art instance segmentation?. Yes!. With Copy&Paste, we achieve 57.3 box AP and 49.1 mask AP on COCO. This is SoTA wrt @paperswithcode.

9
92
488
Revisiting ResNets: Improved Training and Scaling Strategies. Our recent work that applies modern training and scaling techniques to the 2015 ResNet. We find ResNets outperform some recent state-of-the-art architectures. ResNets are remarkably durable!.

5
65
348
How do we combine knowledge from multiple labeled and unlabeled datasets to train a great general model?. Multi-Task Self-Training (MuST) trains specialized teachers on labeled data, which then label unlabeled data to train a single general model.
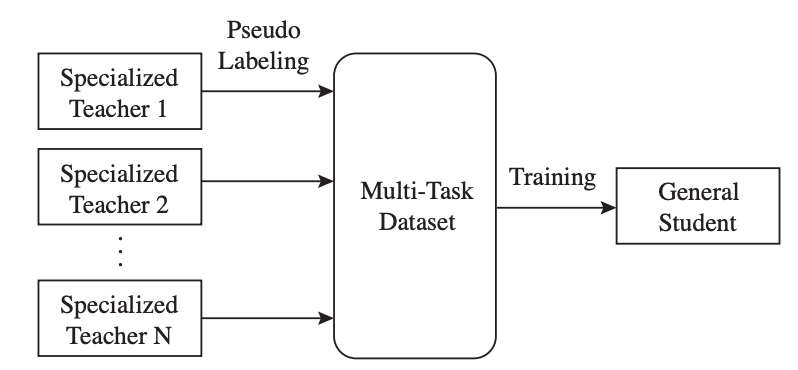
5
86
346
What an incredible company OpenAI is to work at. I have never seen so many people so committed to the mission of the company and band together when things go wrong. Huge props the the leadership team for navigating these incredibly difficult times.
14
6
315
What a fun first few months at OpenAI its been :).

ChatGPT launched on wednesday. today it crossed 1 million users!.
4
4
280
Want to learn more about how sparse expert models (e.g. MoEs, Switch Transformers, Hash Layers) work and their recent research advancements?. Check out our recent review paper

3
59
259
Really enjoyed the Instruct-GPT paper. Impressed by the results: 100x smaller models w/ same quality by updating models on the data distribution you care about. Data is often overlooked & such a powerful tool -- smaller models for the same quality, which saves a lot at inference.
5
20
185
Lots of great work coming out on LLMs generating + understanding code (Codex, Scratch Pad, MBPP/MathQA, etc. ). The Alpha code paper by DeepMind is quite impressive --- ranking ~50% percentile in competitive programming competitions w/ 5000+ participants. A 🧵below:

2
30
178
Interested in using sparse expert models, but find they are unstable, hard to design or don’t fine-tune well?. We address these key issues and train 269B param MoE model (w/ FLOPs of 32B dense model) that improves SOTA on NLP benchmarks liked SuperGLUE.

6
33
160
Super excited this is rolling out! Real time speech to speech will be a powerful feature -- I am very bullish on multi-modal being a core component of AI products. This was a great collaboration with post-training (h/t to @kirillov_a_n & @shuchaobi + team on post-training) and.

Advanced Voice is rolling out to all Plus and Team users in the ChatGPT app over the course of the week. While you’ve been patiently waiting, we’ve added Custom Instructions, Memory, five new voices, and improved accents. It can also say “Sorry I’m late” in over 50 languages.
7
6
161
Our new sparse model (SS-MoE) achieved SOTA on SuperGLUE (! . Excited to see sparsity pushing state-of-the-art! . This new work builds heavily on our prior work on Switch Transformer: Paper and more details to come soon!.
3
17
112
❤️.

I deeply regret my participation in the board's actions. I never intended to harm OpenAI. I love everything we've built together and I will do everything I can to reunite the company.
1
3
107
Models and checkpoints are now open sourced for my recent work: "Rethinking Pre-training and Self-training". Paper link: Code Link: On COCO we achieve 54.3 AP and on Pascal Segmentation 90.5 mIOU!.
1
23
110
Intersecting cutting edge AI research w/ products is an incredibly exciting area to work on. Products are the ultimate test set :).
3
6
83
Great video summary of some of my recent work! Thanks @ykilcher!.

A bit late to the party, but 💃NEW VIDEO🕺 on Switch Transformers by @GoogleAI. Hard Routing, selective dropout, mixed precision & more to achieve a 🔥ONE TRILLION parameters🔥 language model. Watch to learn how it's done🧙💪.@LiamFedus @barret_zoph

0
6
82
Super interesting work! Excited to see the future of attention models in computer vision.

If you haven't read our latest ImageNet SOTA work "Vision Transformers (ViT)" yet, shame on you. But! There's hope! Here's the corresponding blogpost which is a nice tl;dr:

1
7
66
We are looking for people to understand, improve and combine a variety of evaluation signals (e.g. automated and human), build eval infra (e.g. visualizations, testing) and do ML research on better eval methods.
2
1
63
Pleasure working with you -- learned quite a lot! Excited for what you do next.

Hi everyone yes, I left OpenAI yesterday. First of all nothing "happened" and it’s not a result of any particular event, issue or drama (but please keep the conspiracy theories coming as they are highly entertaining :)). Actually, being at OpenAI over the last ~year has been.
1
0
59
@jacobandreas @jacobaustin132 @_jasonwei Yes I have also found this for math. If you append "I am a math tutor" it starts to answer with higher accuracy.
1
1
58
Yes --- I think spending more time thinking about what to work on vs actually working on the thing is hugely important.

The best meta- advice I've gotten is from @barret_zoph. It took me a year to begin to understand it. It went something like:. Notice that many researchers work hard. Yet some are far more successful. This means the project you choose defines the upper-bound for your success.
2
2
55
Slides and video of my talk at the Neural Architects workshop at ICCV this year!.
0
17
49
Exciting see sparse MoE models being 10x more calibrated than their dense LM counterparts. Better model calibration is a key research direction into better understand what models do vs don't know.

Overall, sparse models perform as well as dense models which use ~2x more inference cost, but they are as well calibrated as dense models using ~10x more inference compute.

2
3
41
My talk at the 2019 ICCV Neural Architects workshop is available online! .
1
11
40
Nice work from @IrwanBello on his paper “LambdaNetworks: Modeling Long-Range Interactions without Attention”. An interesting scalable alternative to self-attention with strong empirical results in computer vision!. Link:

1
4
35
Code + checkpoints for the ResNet-RS paper are available!.

Training code and checkpoints here!.
0
3
36
Yes +1. I remember studying parts of the Feynman lectures which showed me how much more clear my thought process could be. When reading his description of simple algebra and complex numbers I thought "wow I really am not thinking clearly enough":
Looking back, my most valuable college classes were physics, but for general problem solving intuitions alone:.- modeling systems with increasingly more complex terms.- extrapolating variables to check behaviors at limits.- pursuit of the simplest most powerful solutions. .
3
2
32
Great blogpost on our recent ResNet-RS work!.

Super excited to present my latest blog post on ResNet-RS - "Revisiting ResNets: Improved Training and Scaling Strategies". I also share code implementation in PyTorch using TIMM & more! . 1/3.
0
5
32
I really like the "tcolorbox" package in LaTeX for research papers. It is a great feature for having nice looking summaries for sections or putting theorems. I enjoyed using it throughout my most recent work!

0
1
28
AI progress has continually exceeded my expectations since I first started working in the space in 2015. The saying that people overestimate what they can do in a short amount of time and underestimate what can be achieved in longer periods of time definitely resonates w/ me.

10 yrs ago @karpathy wrote a blog post on the outlook of AI: in which he describes how difficult it would be for an AI to understand a given photo, concluding "we are very, very far and this depresses me.".Today, our Flamingo steps up to the challenge.
1
1
25
Very excited to be able to release these sparse checkpoints to the research community!.

Today we're releasing all Switch Transformer models in T5X/JAX, including the 1.6T param Switch-C and the 395B param Switch-XXL models. Pleased to have these open-sourced!. All thanks to the efforts of James Lee-Thorp, @ada_rob, and @hwchung27.
2
1
26
It was a pleasure to be part of this effort! Very bullish on the impact this will have for the future of LLMs. Also very impressed with the leadership for this project --- coordinating all of this to happen is nothing short of incredible!.
After 2 years of work by 442 contributors across 132 institutions, I am thrilled to announce that the paper is now live: BIG-bench consists of 204 diverse tasks to measure and extrapolate the capabilities of large language models.

1
3
25
This is a great description of RandAugment! Thanks so much.

This video explains the new RandAugment AutoML Data Augmentation algorithm from @GoogleAI, improving on previous techniques (AutoAugment/PBA) on ImageNet and dramatically reducing the search space, making AutoML for Data Aug much easier!. #100DaysOfMLCode.
1
5
23
Enjoyed The Pile dataset paper -- very thorough!. Data is often overlooked and given the amount of money/time that goes into training these language models, this aspect should be taken seriously.

2
1
21
Switch Transformers introduce sparsity by sending different tokens to different weights . We simplify MoE models by routing to the top expert only, which saves computation + communication costs. We also introduce training techniques for training huge models in lower precision!

1
2
19
Nice paper showing the power of simple scaling and training methods for video recognition!. Follows the line of "RS" research I have done with some of these collaborators for Image Classification ( and Object Detection (.
Wondering how simple 3D-ResNets perform on video recognition given all the recent architecture craze?. In Revisiting 3D ResNets for Video Recognition, we study the impact of improved training and scaling methods on 3D ResNets.

1
3
17
Really fun chatting! Thanks for having us on.
New interview with Barret Zoph (@barret_zoph) and William Fedus (@LiamFedus) of Google Brain on Sparse Expert Models. We talk about Switch Transformers, GLAM, information routing, distributed systems, and how to scale to TRILLIONS of parameters. Watch now:.

1
1
17
In prior work, we showed generating labels from a teacher model can be more flexible than pre-training. MuST is a natural extension where now we generate labels from multiple different teachers on various tasks to learn a general pre-trained model.
1
0
17
Switch Transformers are also found to be strong multi-task learners. On multilingual language modeling (mT5) we outperform T5 models across 101 languages w/ a 5x speedup

0
0
13
To find these interest prompts, should we be looking at the pre-training data? Is "step by step" mentioned the most frequently in documents when an explanation comes next?. Automatic prompt discovery from inspecting the pre-training data feels promising.
Big language models can generate their own chain of thought, even without few-shot exemplars. Just add "Let's think step by step". Look me in the eye and tell me you don't like big language models.

2
1
14
Wow that is a very strong imagenet result! Cool to see further progress being made in semi-supervised methods for computer vision!.

Some nice improvement on ImageNet: 90% top-1 accuracy has been achieved :-). This result is possible by using Meta Pseudo Labels, a semi-supervised learning method, to train EfficientNet-L2. More details here:

1
0
15
We find we can distill some of the performance improvements from our sparse Switch Transformers into dense variants (w/ the same FLOPs per token)

2
0
13
I would be surprised if a modeling improvement could yield a 10x smaller model for a fixed quality. For data this is not the case and often the opposite feeling --- surprising if you couldn't reduce model size by 10x.
0
1
14
Thanks for the nice article on our recent work!.

As promised, here is my new blogpost explaining the latest research from Google Research and Brain team. I liked this paper a lot because instead of building models with billions of params, it focuses on fundamental aspects.
1
0
14
Excited to be giving it! Thanks for the invite.

📢 Next Wed at 5 pm, we’ll have (@barret_zoph ) from Gooogle Brain who will talk about the use of sparsity for large Transformer models:."Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity".zoom info: ai-info@ku.edu.tr or just DM!

0
2
13
Very useful LaTeX trick!.

Nice and beautiful examples of how to produce annotated equations using LaTeX. 🤯.

0
3
12
Thanks @jeremiecharris for having me on your podcast! . Super fun chatting about mixture-of-expert models and how they fit into the current large language model landscape. Podcast:
1
3
12
Sparse expert models are becoming increasingly relevant as they are now being used across many domains (NLP, speech, vision, multi-modality) w/ very strong results. Right now sparse expert models hold SOTA on various benchmarks (e.g. ST-MoE on SuperGlue, ANLI, ARC, etc…).
1
0
12
Yes this is a very important principle to keep in mind --- even when doing a single research project. It's often hard to find the right experimentation scale such that the "smaller" scale ideas have a higher probability of working at a "larger scale".
Just making sure everyone read “The Bitter Lesson”, as it is one of the best compact pieces of insight into nature of progress in AI. Good habit to keep checking ideas on whether they pass the bitter lesson gut check
0
0
12
Fantastic video on some our recent work! Really great job @CShorten30 .
"Rethinking Pre-training and Self-Training" from researchers @GoogleAI shows we get better results from self-training than either supervised or self-supervised pre-training. Demonstrated on Object Detection and Semantic Segmentation!. #100DaysOfMLCode

0
0
12
We highlight the importance of disentangling the training methods and architectural components when making comparisons across architectures

2
0
10
How do Switch Transformers scale? . Keeping the floating point operations per token fixed, increasing the number of sparse parameters by adding more experts significantly improves performance

1
1
11
The modern training techniques (data augmentation, label smoothing, etc…) lead to strong representations that rival sota self-supervised learning methods (e.g. SimCLR) on a bunch of vision tasks

2
1
11
Copy-Paste greatly improves data efficiency (even on top of a strong augmentation baseline of aggressive scale jittering!). Data efficiency is critical for instance segmentation as its much more expensive compared to object detection and image classification

1
0
11
We study scaling strategies for vision models and observe the best scaling strategies heavily depends on the training setup. When overfitting can occur (e.g. 350 epochs on ImageNet) scaling depth is best. In settings with larger datasets/fewer epochs width scaling is preferred.

1
0
10
Example of MuST:. Step 1: Train three models: NYU Depth, COCO Detection, Pascal Segmentation. Step 2: Generate pseudo labels for depth estimation, detection and segmentation on all labeled / unlabeled images. Step 3: Train new model on the combined human + pseudo labeled images

1
0
9
@giffmana The T5 paper did something very similar right? Do the normal warmup, decay by 1/sqrt(step), then linearly decay by last 10% of training.
1
0
10
Happy to see our work on ResNet-RS made it to NeurIPS!.
To appear #NeurIPS2021 as a spotlight - congrats team.
0
0
10
LVIS dataset was created to make progress on long-tail visual recognition. We outperform the ECCV 2020 challenge winner on LVIS by +3.6 mask AP on rare objects (and our baseline by +6.1 AP).
1
0
10
Exciting to see more encoder-decoder models (e.g. T5, T0, Switch Transformer, ST-MoE). Liked the dual loss pre-training strategy: use MLM on encoder and simple autoregressive LM on decoder

1
0
9
When using only ImageNet images, MuST significantly outperforms both supervised and self-supervised representations across many tasks.

1
0
9
Awesome startup w/ awesome founders!. Excited to see future space of AI x Legal. (Disclosure: I invested).
1
0
9
Impressive results w/ the continued scale of large LMs. On certain tasks there were large discontinuous performance improvements not predicted by scaling curves . Great leadership / coordination on this project to make it happen --- nice work team!.

Introducing the 540 billion parameter Pathways Language Model. Trained on two Cloud #TPU v4 pods, it achieves state-of-the-art performance on benchmarks and shows exciting capabilities like mathematical reasoning, code writing, and even explaining jokes.
0
0
9
Hope these revamped ResNets can serve as baselines for future architectural and training method comparisons!.
0
0
8
Surprising to see how performance scales smoothly when the model goes from generating 1 solution all the way up to 1M solutions

1
0
9
Surprised the 41B model only was better than the 9B model once it could generate 1k+ samples. Wonder how results for different model sizes change as a function of the pre-training and fine-tuning dataset size

1
1
8
Super excited to see the co-evolution of game design with these types of models. Open world games that could automatically generate new environments based on what the player has enjoyed so far would be so cool --- I often felt games got stale due to a lack of new environments.

DALL-E 2 applied to generating assets for game development:.
0
0
9
We observed adding more pseudo labels to each image to lead to better representations! . So don’t just use classification and depth estimation labels, include segmentation and others too.

1
0
8
Exciting research ahead to not require generating huge amounts of samples -- seems this should be possible. Many applications of LLMs require generating lots of samples and even using discriminator models to further filter generated outputs (e.g. Lamda, OpenAI Verifiers).
1
1
7
What if I already trained my checkpoint?. No problem!. You can simply continue training your checkpoint with MuST for a few iterations and observe improvements! . Results combining MuST with an ALIGN checkpoint.

2
0
8
Nice summary of a lot of the great work done by Google Research in the past year.

As in past years, I've spent part of the holiday break summarizing much of the work we've done in @GoogleResearch over the last year. On behalf of @Google's research community, I'm delighted to share this writeup (this year grouped into five themes).
0
0
8
Nice summary of our recent work!.

My review of the paper "Revisiting ResNets: Improved Training and Scaling Strategies". It seems that we have a new SOTA for CV tasks. Looking forwards for PyTorch version!.
0
0
7
Interesting how the validation loss isn't correlated with the solve rate. Other tasks like dialogue (e.g. Lamda) seem to correlate much better to human evals . Probably due to the one-to-many nature of coding tasks relative to dialogue as the authors point out

0
2
7
In a large scale semi-supervised learning setup we obtain 5.5x speedups over Noisy Student EfficientNets.

1
0
6
Wouldn't be surprised if some of the most impactful papers in the language modeling space in the next few years come from pure dataset research.
0
4
7
This really hit homes --- the amount of hand holding for experiments and models can be quite frustrating. You would think that this area would have more progress given these are the issues people training the models are having :).

The AGI I want is one that realizes I made a dumb mistake with batch size which makes it OOM on a supercomputer and tries a smaller one for me - while I am sleeping so I don’t have to babysit the models and increases the throughput in experimentation!.
0
1
7
Authors: Golnaz Ghiasi, @YinCui1, @AravSrinivas, @RuiQian3, @TsungYiLin1, @ekindogus, @quocleix, @barret_zoph.
1
0
7
Also seems the 41B models wasn't the "compute Pareto optimal" --- for a given TPU budget its almost always better to use the 9B model

2
1
7
We design a Pareto curve of 11 different ResNet models named ResNet-RS by scaling the image size along with different network depths. We obtain 1.7-2.7x speedups over EfficientNets on ImageNet.

1
0
5
We studied MuST on a suite of different tasks and datasets. Training Datasets: Specialized teacher models trained on these datasets, which are used to produce pseudo labels. Evaluation Datasets: Datasets models are fine-tuned on.

1
0
6
@_arohan_ @borisdayma Yea +1 also to the power of these GLU/GELU FFN variants (like in . These work very well.
0
0
6
How do MuST representations compare to those trained with standard multi-task learning across datasets and tasks?. MuST improves over multi-task training across all tasks!

2
0
6
We dive into the tradeoffs of using sparse expert models versus standard dense models. We hope this review can help to increase adoption for them as they are working quite well and lots of excellent research has been done for them!.
0
0
5
Nice architectural improvements from my collaborators at Google!.
Today we present SpineNet, a novel alternative to standard scale-decreased backbone models for visual recognition tasks, which uses reordered network blocks with cross-scale connections to better preserve spatial information. Learn more below:
0
0
5
For two models with the same FLOPs per token, we find sparse models to outperform their dense counterpart on a large suite of fine-tuning tasks.

1
0
5
Great thread describing some of the approaches for getting models to perform well on tasks we care about!.

📢 A 🧵on the future of NLP model inputs. What are the options and where are we going? 🔭. 1. Task-specific finetuning (FT).2. Zero-shot prompting.3. Few-shot prompting.4. Chain of thought (CoT).5. Parameter-efficient finetuning (PEFT).6. Dialog . [1/]


0
1
5
We study the fine-tuning of sparse vs dense models. The optimal batch sizes and learning rates for sparse vs dense models are very different. In certain scenarios wrong values masked any of the pre-training performance improvements of sparse models over the dense models

1
0
5
We finally combine our improvements and train a sparse model with 269B parameters (FLOP matched to a 32B dense model). This model achieve SOTA on a wide range of NLP tasks: SuperGLUE, XSum, CNN-DM, ANLI R3, ARC-Easy/Challenge, CB WebQA, CB NatQA.

0
0
5
We study how the experts specialize on different tokens and find that they end up semantically specializing to different categories such as punctuation, verbs and proper names.

1
0
5
We also find sparse models to be incredibly robust to “dropping” tokens during fine-tuning. Sparse models have a fixed batch size ahead of time, so if there is overflow to a specific expert, the token is “dropped” and passed to the next layer unchanged.

1
0
4
Such a fantastic internship opportunity that I really enjoyed many years back.

ISI NLP internship applications now open! College through PhD students are welcome to apply for 12 week summer research internships at Marina del Rey (or online if COVID). Join us!

0
1
4
We also propose a few heuristics and architectural modifications to design Pareto efficient architectures.

3
0
4