

Preetum Nakkiran
@PreetumNakkiran
Followers
11K
Following
11K
Media
285
Statuses
4K
Our tutorial on diffusion & flows is out! We made every effort to simplify the math, while still being correct. Hope you enjoy! (Link below -- it's long but is split into 5 mostly-self-contained chapters). lots of fun working with @ArwenBradley @oh_that_hat @advani_madhu on this

26
269
1K
My favorite non-ML paper I read this year is probably "Bayesian Persuasion" (2011), which I somehow only found out about recently. Simple & beautiful. The first 2 pages are sufficient to be persuaded.

9
146
1K
every 3 years my friend and I need to re-learn kernels/RKHS for some theory project, and we rediscover these excellent 700 slides ("CS-friendly" but rigorous):
18
114
957
My friend Chenyang (twitterless) has written a nice tutorial on diffusion models, from the "projection onto manifold" perspective. My favorite part is the *extremely simple* pedagogical codebase, which I've been using myself for quick experiments. See:.

4
142
810
writing “\begin{proof}” into copilot and praying.
5
44
642
In case it's helpful: Resources on learning causality "from scratch", assuming prior math background. (we used this for a reading-group last year; I highly recommend):. First, start with this short lecture for the philosophical motivations: Then 1/.
7
73
498
this was a great read; particularly relevant to some of the "debates" in the current ML community, and interesting historical context

4
61
429
One thing I was very wrong about ~4yrs ago is how fundamental “synthetic data” in ML would be. “Obviously” due to data-proc-inequality, synth data should not help learning. The key flaw in this argument is: we do not use info-theoretically optimal learning methods in practice 1/.
12
33
364
new personal challenge: write an Introduction without using “However,”.
23
13
318
The Deep Bootstrap: Good Online Learners are Good Offline Generalizers.with @bneyshabur and @HanieSedghi at Google. We give a promising new approach to understand generalization in DL: optimization is all you need. Feat. Vision Transformers and more. 1/

7
69
329
Why does learning rate annealing help generalization in deep learning?. I don't know. But here is a toy example showing this can provably occur even in convex problems:

3
62
298
Fun fact: More data can hurt in linear regression. (aside: this is about the 3rd time that studying deep learning has taught me something about linear regression).
7
43
285
I defended today! Thanks very much to my advisors @boazbaraktcs & Madhu Sudan, and all of my friends & collaborators along the way. In the Fall I'll be joining UCSD as a postdoc with Misha Belkin. If you're interested in my research and want to collab, do reach out!

26
3
281
reaching that point in the paper where I’ve written more code for making plots than actually running the experiments.
3
5
270
these days as a {neurips/icml/iclr} reviewer, I tend to look for “one reason to accept” (eg one good idea/result) vs “reasons to reject”. most ML conf papers are flawed, but having one good idea is enough for the paper to be valuable.
8
14
263
It is still insane to me, from the theory side, how little architecture (and other design choices) ended up mattering. That we now use the exact same architecture for both text and vision. RIP inductive bias.

The ongoing consolidation in AI is incredible. Thread: ➡️ When I started ~decade ago vision, speech, natural language, reinforcement learning, etc. were completely separate; You couldn't read papers across areas - the approaches were completely different, often not even ML based.
11
13
234
New paper: Modern DNNs are often well-calibrated, even though we only optimize for loss. What's going on here? The folklore answer is that we're "minimizing a proper loss", which yields calibration. But this is only true if we reach [close to] the *global optimum* loss. (1/n)

5
32
235
New paper, short and sweet:."Limitations of Neural Collapse for Understanding Generalization in Deep Learning".with Like Hui, Misha Belkin. Neural collapse is often claimed to be, in some way, deeply relevant for generalization. But is it? 1/3

5
49
230
one reason it's helpful to study some established field before getting into Deep Learning is: you know what it means to actually understand something.
6
15
218
Optimal Regularization can Mitigate Double Descent. Joint work with Prayaag Venkat, @ShamKakade6, @tengyuma. We prove in certain ridge regression settings that *optimal* L2 regularization can eliminate double descent: more data never hurts (1/n)

6
49
221
We have an opening for a PhD intern working closely with (among others) me, Arwen Bradley, David Berthelot, on scientific aspects of diffusion & generative models. 1/.
4
39
211
Reviewer 2 complains it has "too many ideas". @prfsanjeevarora says "gave me some new ideas". This Friday at Noon PT… come hear about the paper that reviewers don't want you to read! I'm speaking at @ml_collective's DLCT:

4
21
206
careful about overfitting to lists like this. there are many ways to do good research -- my fav papers were born out of getting "stuck in rabbit holes" that no-one else went down. .

Enjoyed visiting UC Berkeley’s Machine Learning Club yesterday, where I gave a talk on doing AI research. Slides: In the past few years I’ve worked with and observed some extremely talented researchers, and these are the trends I’ve noticed:. 1. When.
5
10
204
I’m looking for highly motivated PhD students to work with me on exciting problems at the intersection of theory and practice! no like as a collaborator. uh no I can’t pay you. no not even in gpus. maybe later in citations.
10
28
204
I often see confusion about whether softmax probabilities are "meaningful", whether networks are "calibrated", etc. Much of the confusion comes from mixing over- and under-parameterized regimes. These have different scaling limits, and softmax is only meaningful in 1 of them! 1/

2
32
199
This paper's finally dropping on arxiv tonight. It's been an endeavor--- I've learnt a lot from many new collaborators :). One of us will tweet it out soon! Go follow @nmallinar @DeWeeseLab @Amirhesam_A @PartheP for the thread.

6
16
189
nice list of CS PhD fellowships, with deadlines and stipends amounts:.
3
31
182
I see it’s PhD app season. To make the case for UCSD, I present this evidence of our group meetings :). Come work with Misha, me, and many other excellent folks at the intersection of computers and science!


1
3
184
I'm enjoying all the recent DL archs/methods -- but would *really* like to see *scaling laws* in these papers, for labs that can afford it. Eg, do you claim "Method X > Y" for a fixed n? For all n? Large-enough n?.We don't compare sorting algos at a fixed n. So why do this in ML?.
4
13
174
Very clean idea / paper!


@PreetumNakkiran Chatterjee's correlation coefficient for 1D RVs behaves nicely and has wonderful relationships to copula measures, HSIC, etc.
6
19
171
"Understanding deep learning" should be easier than, say, understanding the brain, because we have *full information* and *full experimental control* over the system. But one aspect of experimental control that is severely underexploited in DL research is the *data distribution*.
5
16
173
To celebrate the year, a review of papers I led & published in 2021. A 🧵👇🏾.
3
5
175
Next in the calibration saga, a theory paper: We study the basic question: How should we measure miscalibration?. We all agree on what it means to be perfectly calibrated, but not on how to quantify *deviations* from calibration. 1/n

6
31
171
“Reviewers agree that the empirical phenomenon documented in the paper is indeed unexpected and interesting. However, reviewers feel that this alone is not sufficient to accept the paper for the conference.”. Science progresses via steps that are either unexpected or interesting.
4
5
166
Claim: Understanding generalization in ML (formally, or heuristically) is at least as hard as understanding what is "real" about real-world distributions. Eg: We cannot precisely state "CNNs generalize better than MLPs" without specifying the distributions for which this holds.
13
14
167
today I once again made the mistake of mentioning "linear regression" in a deep learning talk to theorists. like blood in the water.
10
8
158
research is play until 6 weeks before the deadline, then research is work.

Great quote from Michael Atiyah on research and creativity (h/t @michael_nielsen). Research should be play. If your research has a roadmap, you're doing it wrong.

3
7
156
This was a very nice talk by @tomgoldsteincs, starts at 0:30.


Context for this talk was an NSF Town Hall with goal to discuss successes of deep learning especially, in light of more traditional fields. Other talks by @tomgoldsteincs @joanbruna @ukmlv, Yuejie Chi, Guy Bresler, Rina Foygel Barber at this link:.. 2/3.
2
22
154
don't understand the "A is B" vs "B is A" discourse. the training set doesn't have this symmetry, so why would you expect the model does.
28
5
149
ML papers: consider replacing “theoretically justified” with “theoretically inspired” whenever appropriate (e.g. almost anything involving neural networks).
2
16
137
New paper with @whybansal:."Distributional Generalization: A New Kind of Generalization". Thread 1/n. Here are some quizzes that motivate our results (vote in thread!).QUIZ 1:

2
15
144
these days, if I’m worried a project will be scooped from the beginning, I simply let it be scooped — it’s only worth doing work that wouldn’t otherwise be done (imo).
9
3
140
horror movies are great and all but have you tried watching a live talk with an abstract eerily similar to one of your projects.
0
3
135
One intuition for why Transformers have difficulty learning sequential tasks (eg parity), w/o scratchpad, is that they can only update their “internal state” in very restricted ways (as defined by Attention). In contrast to e.g RNNs, which can do essentially arbitrary updates.

There’s not enough creative exploration of the KV cache. researchers seem to ignore it as just an engineering optimization. The KV cache is the global state of the transformer model. Saving, copying, reusing kv cache state is like playing with snapshots of your brain.
2
16
135
maybe deep learning is the Jupyter Notebook of ML. Easiest way to proof-of-concept, far from optimal way to solve the problem.
6
6
133
New: We've released a python package that makes theoretically-principled reliability diagrams, and measures the associated calibration error (SmoothECE). It's hyperparam-free, and I hope useful. It relies on our prior theory of "good" calibration measures; details in paper below

3
19
129
In retrospect (knowing what we know now), the way to understand why “cold diffusion” works is via Conditional Flow Matching.

Diffusion models like #DALLE and #StableDiffusion are state of the art for image generation, yet our understanding of them is in its infancy. This thread introduces the basics of how diffusion models work, how we understand them, and why I think this understanding is broken.🧵

7
5
133
In technical writing, "vacuous words" are those which add no precision to the sentence, and just fill space. For example, "Bayesian".
8
8
126
real friends will join your projects before you have results.
4
0
127
calling everyone above me "non-rigorous", and everyone below "pedantic".
3
2
121
after spending months writing a tutorial on “understanding diffusion without SDEs”, we have a new paper on, guess what,.
3
6
124
Overparameterized models are trained to be *classifiers*, but empirically behave as *conditional samplers* (cf our prior work). Here we explore learning-theoretic aspects of conditional sampling: definitions, sample complexity, relations to other types of learning, etc.


Knowledge Distillation: Bad Models Can Be Good Role Models. Gal Kaplun, Eran Malach, Preetum Nakkiran, and Shai Shalev-Shwartz
2
20
120
will 2022 be the year I finally study consciousness (NLP)?.
8
2
114
is it just me or do NLP papers have better writing and CV papers better figures.
8
8
117
Since leaving academia, none of my new papers are planned for neurips/icml/iclr. The “prestige” is no longer worth the contortions required to optimize for these venues.

@kamalikac @NeurIPSConf At which point do NeurIPS, etc. require long-term teams and a long-term visibility and planning? Should it really left to overwhelmed and overworked volunteers to steer the ship one year at a time, making decisions with huge impact by reacting "the best they could"?.2/2.
3
4
119
This was a very exciting project— it changed my mental model of Transformers and compositional/OOD generalization. Check it out:

What algorithms can Transformers learn?. They can easily learn to sort lists (generalizing to longer lengths), but not to compute parity -- why? . 🚨📰 In our new paper, we show that "thinking like Transformers" can tell us a lot about which tasks they generalize on!

1
16
114
trying to teach diffusion “without continuous time” (no PDEs/SDEs/etc) is what finally convinced me the continuous time approach is the “natural” one 🙃.
9
3
113
Very nice work led by Shivam Garg, @tsiprasd! .Studying in-context-learning via the simplest learning setting: linear regression. (I really like this setup -- will say more when I get a chance, but take a look the paper!).
5
16
108
I am regularly surprised how large the gap can be between what people write papers about and what they actually care about. (one of the advantages of meeting face-to-face vs. only in the bibliography).
7
10
106
excited to announce we won this year's lottery.
New paper: Modern DNNs are often well-calibrated, even though we only optimize for loss. What's going on here? The folklore answer is that we're "minimizing a proper loss", which yields calibration. But this is only true if we reach [close to] the *global optimum* loss. (1/n)
2
4
103
when you’re so interdisciplinary you forget to be disciplinary.
3
7
106
I really enjoyed reading this paper. Contains many insights (theoretical and empirical) that did not make it into the abstract. Some of things I liked: . - It asks a good question: We want to understand when and why pre-training works IRL. The simplest setting is. 1/

2
10
104
one thing TCS taught me is to never actually solve problems. just reduce to other problems.

@PreetumNakkiran proposed to look at the jpeg size per pixel to find the correct dimensions: works very well! . #statistics #maths
1
3
102
Turing machines which cannot overwrite their tape are not Turing complete. Deep RNNs with finite precision are not Turing complete. Autoregressive LLMs with finite precision are not Turing complete. (Unfortunate).
18
8
102
Honest ICML question: What's the best subject-area/reviewer-pool for scientific work in DL that (1) doesn't prove a theorem, and (2) doesn't improve SOTA?.
18
3
97
A certain class of criticisms about deep learning actually applies to ~any practical learning system (adv. attacks, spurious correlations, interpretability, data bias, privacy, unprincipledness, etc). Stating in the most general form can help clarify the nature of the criticism.
6
16
96
I’ve really enjoyed thinking/working on diffusion, I think because it’s less “mathematically forgiving” than many other parts of DL (eg get the sampling step wrong and you’ll get garbage). So one can have fun with the math, and see it actually translate to reality.
4
2
101
out of curiosity, do we know if non-attention architectures (eg MLP-mixer) also exhibit similar “emergent” behaviors (like in-context-learning), when trained to similar pretrain perplexities?.
18
4
92
generally a huge fan of the philosophy "to understand a method, understand what problem it is optimally solving".

Image-to-image models have been called 'filters' since the early days of comp vision/imaging. But what does it mean to filter an image? . If we choose some set of weights and apply them to the input image, what loss/objective function does this process optimize (if any)?. 1/8

3
6
91
reflecting on why diffusion models have so many equivalent interpretations (VAEs, Langevin dynamics, OT, SDE/ODE integrators etc). First I thought it was bc of all the Gaussians (inheriting their many interps). Current thought, though, is. .
4
1
91
“networking” in academia means expanding the set of people who will reply to your cold-emails.
1
2
92
as a grad student, I once didn’t write any papers for 2 years. If you’re not prepared to do this, academia is for you.

As a grad student, I read each assigned reading twice before each class discussion. This often meant reading a 300 page book twice, within a week. If you’re not prepared to do this and more, I wouldn’t pursue grad school, let alone academia.
2
0
88
key insight of diffusion models imo: to learn a coupling between two distributions x_0 ~ Targets and x_T ~ Noise, it's *much* easier to construct a sequence of distributions (x_0, x_1, x_2,. ,x_T) where each adjacent pair is "close", learn pairwise couplings, then compose.
6
5
88
Twitter followers are like citations: after some point they just start growing automatically without you doing much of worth.
12
2
89
“emergence” when it’s good, “hallucination” when it’s bad 🙄.

Overheard at the Simons Institute: “Generalization and hallucinations are two sides of the same coin.” Apt, given the two ongoing programs this semester — on generalization, and on large language models and transformers.


5
1
88
working in deep learning can be an adjustment for the theorist, in part bc it's the study of why an object that's "clearly suboptimal" actually works pretty well.
4
5
83
Our numpy implementation of RASP-L from this paper is now public: Trying to code in RASP-L is (imo) a great way to build intuition for the causal-Transformer's computational model. Challenge: write parity in RASP-L, or prove it can't be done😅.
What algorithms can Transformers learn?. They can easily learn to sort lists (generalizing to longer lengths), but not to compute parity -- why? . 🚨📰 In our new paper, we show that "thinking like Transformers" can tell us a lot about which tasks they generalize on!
1
18
88
I devoted several sections in my thesis to explain this joke. Seriously: IMO the biggest obstacle to the theory of DL is that we don't have a good definition of "Deep Learning". One that is broad enough to include all future applications, but narrow enough to not contain P/poly.


1
4
89
every diffusion paper has their own favorite way of introducing what a diffusion is.
7
1
84
writing a paper with one of my old friends. I keep moving proofs to the appendix and he keeps proving new things.
1
2
83
I have yet to see a definition of “extrapolate” in ML that is precise, meaningful, and generic (ie applies to a broad range of distributions *and* learning algorithms). It’s currently “you know it when you see it”— possible to define in specific settings, but not generically.

A simple, fun example to refute the common story that ML can interpolate but not extrapolate:. Black dots are training points. Green curve is true data generating function. Blue curve is best fit. Notice how it correctly predicts far outside the training distribution!. 1/3

14
4
85
there’s so much unwritten but extremely valuable knowledge in ML: knowing which ideas actually work, and which ones sound great in the neurips papers, but don’t actually work.

As someone who just starting doing literally any machine learning this year, the most confusing part is figuring out which of the "common wisdom" is reasonable and which actually turns out to be totally outdated, and getting conflicting advice on this from different people.
3
7
87
Understanding why, in ML, we often “get much more than we asked for”* is what I consider one of the most important open questions in theory. *(we minimize the loss, we get much more, as in this paper and others).

Why does model often attend to salient words even though it's not required by the training loss? To understand this inductive bias we need to analyze the optimization trajectory🧐. Sharing our preprint "Approximating How Single Head Attention Learns" #NLProc
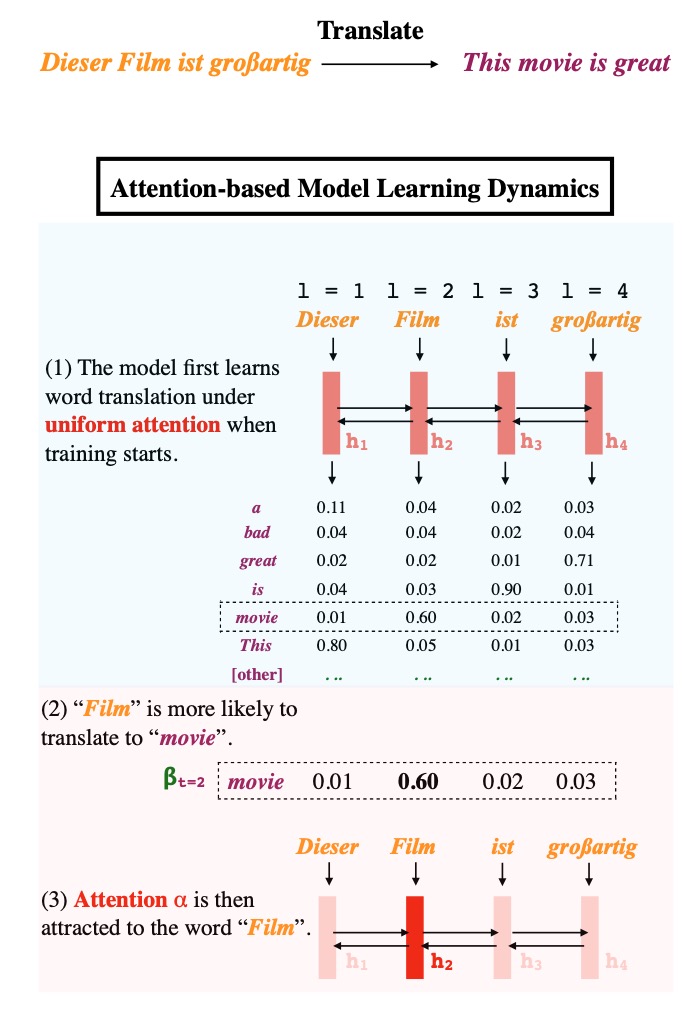
1
9
82
I study generalization, that my students may study optimization, that their students may study representation.
1
1
83

family photos— we live in Pacifica now, with this little guy 🐾


3
2
84
One way I like to think of this is, there are at least 3 axes in learning: sample-complexity, space-complexity (memory), and time-complexity (flops). Transformers are one point in this space, but what does the space look like? (Are they the unique optima along some dimension?etc).

From a science methods perspective, Mamba / SSM is fun. A second model challenges lots of post-hoc "why are transformers good" research to now be predictive. What if it works, but none of the circuitry is the same? Where do we go if the loss is great but it's worse?.
2
1
86
had a great time at the Banff workshop this week — it lives up to its reputation 😀

3
1
85
Suggested resources for learning Hamiltonian Monte Carlo? Ideally including what is known about which distributions it works best on. (Can assume I’m familiar with Langevin dynamics and MCMC).
13
8
84
The following *very* nice piece came up in a chat re theory&applications in ML (h/t @boazbaraktcs). It was in response to a debate in TCS community. But really, most of it is a defense of "science for science's sake", and a warning about mixing scientific and industrial goals. 1/

3
8
82
want to see “10 minute read” on blogposts replaced with gpt3 log-loss.
6
6
83
Lots of 2024 predictions out there. if you wanna measure the ~calibration~ of these predictions, please use SmoothECE instead of BinnedECE 😉. Small changes in the data can cause large changes to BinnedECE (among other problems)
3
6
82
"code provided for reproducibility" is the ML equivalent of "p < 0.05".
7
5
76