

Sebastien Bubeck
@SebastienBubeck
Followers
45K
Following
3K
Media
187
Statuses
2K
I work on AI at OpenAI. Former VP AI and Distinguished Scientist at Microsoft.
Seattle, WA
Joined January 2012
o3 and o3-mini are my favorite models ever. o3 essentially solves AIME (>90%), GPQA (~90%), ARC-AGI (~90%), and it gets 1/4th of the Frontier Maths. To understand how insane 25% on Frontier Maths is, see this quote by Tim Gowers. The sparks are intensifying .

44
183
2K
At @MSFTResearch we had early access to the marvelous #GPT4 from @OpenAI for our work on @bing. We took this opportunity to document our experience. We're so excited to share our findings. In short: time to face it, the sparks of #AGI have been ignited.

64
709
3K
Starting the year with a small update, phi-2 is now under MIT license, enjoy everyone!.

53
274
2K
We trained a small transformer (100M params) for basic arithmetic. W. the right training data it nails 12x12 digits multiplication w/o CoT (that's 10^24 possibilities, so no it's not memorization🤣). Maybe arithmetic is not the LLM kryptonite after all?🤔.
69
260
2K
New LLM in town:. ***phi-1 achieves 51% on HumanEval w. only 1.3B parameters & 7B tokens training dataset***. Any other >50% HumanEval model is >1000x bigger (e.g., WizardCoder from last week is 10x in model size and 100x in dataset size). How?. ***Textbooks Are All You Need***

44
329
2K
Last couple of weeks I gave a few talks on the Sparks paper, here is the MIT recording!. The talk doesn't do justice to all the insights we have in the paper itself. Neither talk nor twitter threads are a substitute for actual reading of the 155 pages :-).
15
293
571
Enjoy everyone!. (And remember it's a base model so you might have to play around with your prompts; if you want it to follow instructions you can try the format "Instruct:. Ouput:").
26
189
1K
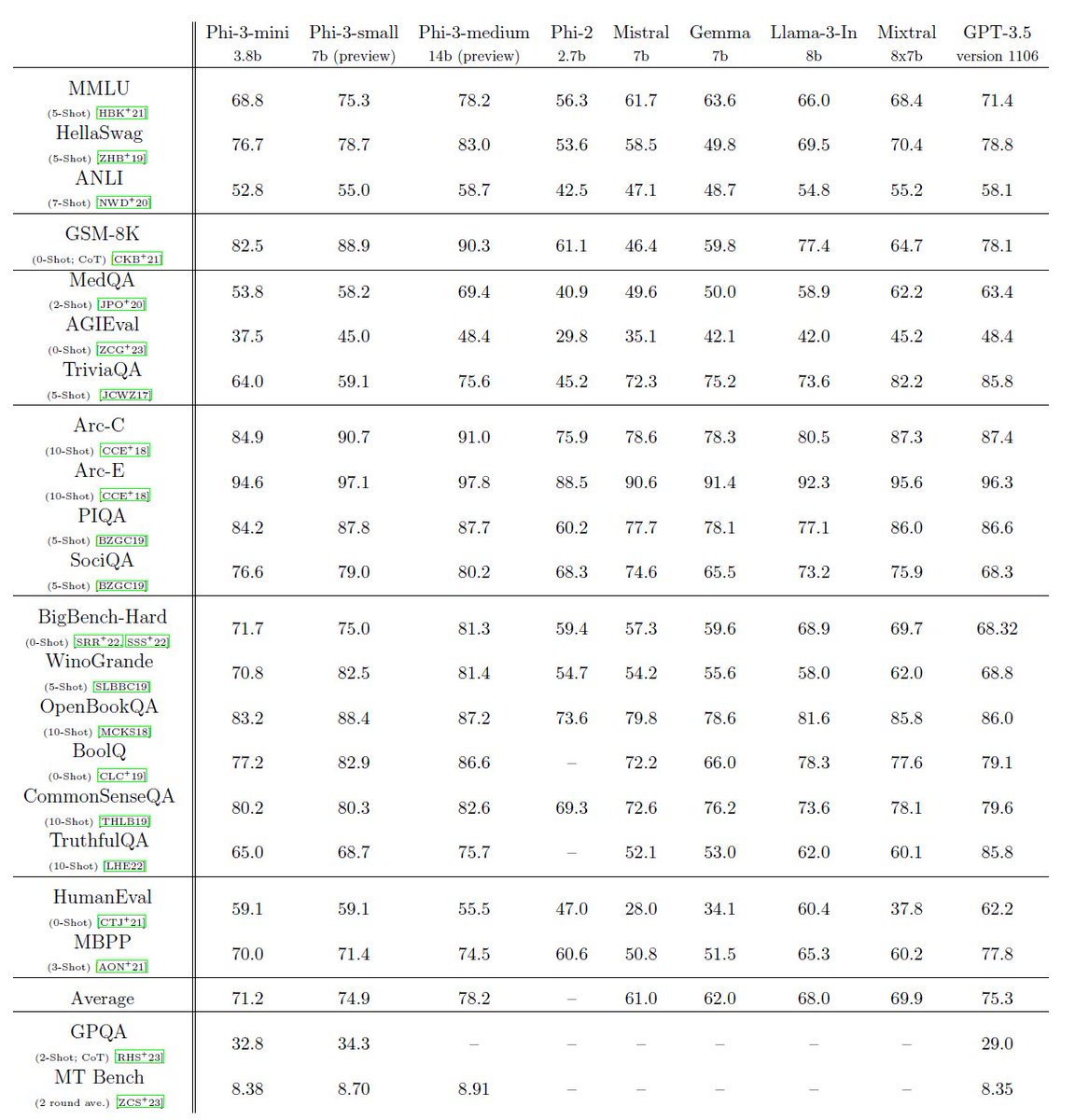
phi-3 is here, and it's . good :-). I made a quick short demo to give you a feel of what phi-3-mini (3.8B) can do. Stay tuned for the open weights release and more announcements tomorrow morning!. (And ofc this wouldn't be complete without the usual table of benchmarks!)

41
186
940

How far does one billion parameters take you? As it turns out, pretty far!!!. Today we're releasing phi-1.5, a 1.3B parameter LLM exhibiting emergent behaviors surprisingly close to much larger LLMs. For warm-up, see an example completion w. comparison to Falcon 7B & Llama2-7B

28
174
808
This is the coolest "application" of LLMs I have seen in a while: instead of using an LLM to solve a problem set, flip the table and ask the student to TEACH the LLM how to solve the problem set. Really lovely. Thx to Jordan Hoffmann for sharing this :-).
8
128
785
Transformers are changing the world. But how do they learn? And what do they learn?. Our 1st @MSFTResearch ML Foundations team paper proposes a synthetic task, LEGO, to investigate such questions. Sample insights on Transformers thanks to LEGO below 1/8.
4
108
717
We may have found a solid hypothesis to explain why extreme overparametrization is so helpful in #DeepLearning, especially if one is concerned about adversarial robustness. 1/7

4
123
659
Phi-2 numbers, finally! We're seeing a consistent ranking: phi-2 outperforms Mistral 7B & Gemini Nano 2* (*on their reported benchmarks) and is roughly comparable to Llama 2-70B (sometimes better, sometimes worse). Beyond benchmarks, playing with the models tells a similar story.


From new best-in-class small language models to state-of-the-art prompting techniques, we’re excited to share these innovations and put them in the hands of researchers and developers.
21
81
576
For my 500th tweet I'm super excited to release five 1h videos covering the most important results presented in my monograph Convex Optimization: Algorithms and Complexity. This time I tried hard to emphasize the intuition behind the calculations! 1/6.
2
106
518
phi-2 is really a good base for further fine-tuning: we FT on 1M math exercises (similar to phi-1 w. CodeExercises) & test on recent French nation-wide math exam (published after phi-2 finished training). The results are encouraging! Go try your own data

20
69
518
The video of my talk @EPFL_en today on Transformers and how to make sense of them is online!.
5
67
505
(Nesterov) Acceleration in convex optimization is one of the most striking phenomenon in all of optimization, and now you can learn about all the different viewpoints on it from a very nice 156 pages survey paper by d'Aspremont, Scieur and Taylor!
3
98
488
Sorry I know it's a bit confusing: to download phi-2 go to Azure AI Studio, find the phi-2 page and click on the "artifacts" tab. See picture.


@simonw No they fully released it. But they hide it very well for some reason. Go to artifacts tab.
31
53
487
Microsoft💜Open Source + SLMs!!!!! . We're so excited to announce our new *phi-2* model that was just revealed at #MSIgnite by @satyanadella!. At 2.7B size, phi-2 is much more robust than phi-1.5 and reasoning capabilities are greatly improved too. Perfect model to be fine-tuned!


18
84
480
I recommend to tune in!!!.

fine one clue. should have said oh oh oh.
17
8
480
Can't wait for your feedback on our largest and most capable Phi model yet!.
27
64
467
A major open problem in ML is whether convex techniques (kernel methods in particular) can reproduce the striking successes of deep learning. In a guest post series (two parts) on I'm a bandit, @julienmairal weighs in on the question!

2
118
449
Just watched an incredible talk by @AlexGDimakis at the Simons Institute, highly recommended. Their Iterative Layer Optimization technique to solve inverse problems with GANs make a LOT of sense!. The empirical results on the famous blurred Obama face speak for themselves!.1/4

3
78
454
Time for some retrospective! I shared some 25 papers that I particularly enjoyed in the last decade. I would love for you to share some papers that are missing in this list (there are many!!), either here or in the comments on the blog.
2
104
420
Surprise #NeurIPS2024 drop for y'all: phi-4 available open weights and with amazing results!!!. Tl;dr: phi-4 is in Llama 3.3-70B category (win some lose some) with 5x fewer parameters, and notably outperforms on pure reasoning like GPQA (56%) and MATH (80%).

19
71
418
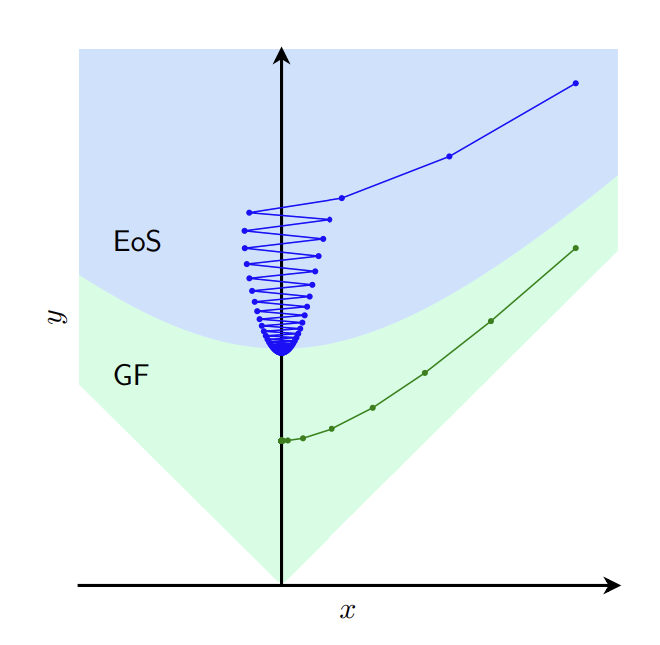
My group is hiring a large cohort of interns for the summer of 2024 to work on the Foundations of Large Language Models! Come help us uncover the new physics of A.I. to improve the LLM building practices! (Pic below from our NeurIPS 2023 paper w. interns).
10
49
397
At #NeurIPS2018 where it was just announced that our paper on non-smooth distributed optimization with Kevin Scaman, @BachFrancis , Laurent Massoulie and Yin Tat Lee got a best paper award. Lots of interesting open problems left there, check out the paper
10
48
374
We (@gauthier_gidel @velythyl @busycalibrating @vernadec & myself) would like to announce the accepted blog posts to @iclr_conf's 1st Blogpost Track. Experiment was a great success with 20 accepted posts out of 61 submissions, roughly the size of the 1st @iclr_conf itself! 1/24.
7
68
356
I'm really happy that the law of robustness got recognized as an important new insight with a NeurIPS outstanding paper award! The video below summarizes what the law is about, what it means, and what it predicts. It's also a great capstone for @geoishard's fantastic phd work!.

Learn about the significance of overparametrization in neural networks, the universal law of robustness, and what “A Universal Law of Robustness via Isoperimetry” means for future research in this short video with @SebastienBubeck:
25
41
354
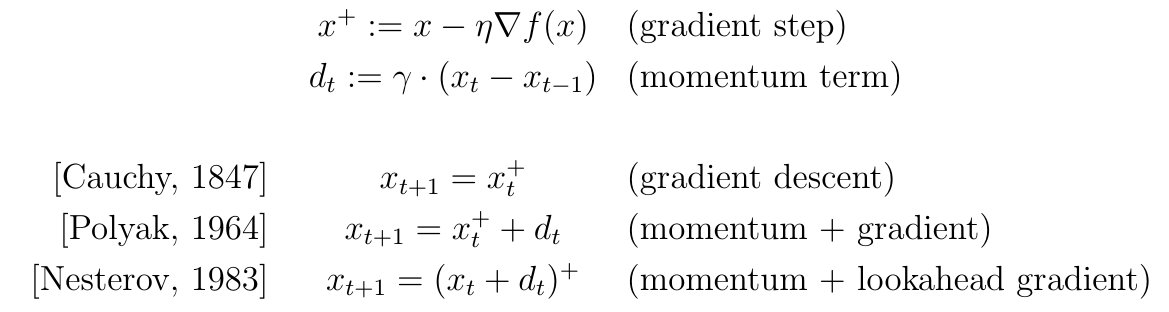

The **Machine Learning Foundations** group at @MSFTResearch Redmond is hiring at all levels (including postdoc)! . Come join @ZeyuanAllenZhu @suriyagnskr @jerryzli @ilyaraz2 @talw and myself to develop the next generation of ML theory! .
11
82
332
This year I turn 40. Would be nice to celebrate half-life with AGI . .
27
8
328
We're so pumped to see phi-2 at the top of trending models on @huggingface ! It's sibling phi-1.5 has already half a million downloads. Can't wait to see the mechanistic interpretability works that will come out of this & their impact on all the important LLM research questions!
25
68
306
Every day I witness the AI revolution in action, and every day I see 1 or 2 questions that would deserve an entire PhD thesis to explore fully . Honestly, how lucky we are to do research in that era!! .*Even if* there is no more magical leap like from gpt2 to 3, or 3 to 4,.
10
37
317
Karen Uhlenbeck concludes her Abel prize lecture with 5 minutes on #DeepLearning!!! She says about it: ``My conjecture is there is some interesting mathematics of some sort that I have no idea." Couldn't agree more.
5
42
313
Full details in the paper: Awesome collaboration with our (also awesome) @MSFTResearch team!. Cc a few authors with an active twitter account: @EldanRonen (we follow-up on his TinyStories w. Yuanzhi Li!) @JyotiAneja @sytelus @AdilSlm @YiZhangZZZ @xinw_ai.
7
50
315
Why do neural networks generalize? IMO we still have no (good) idea. Recent emerging hypothesis: NN learning dynamics discovers *general-purpose circuits* (e.g., induction head in transformers). In we take a first step to prove this hypothesis. 1/8.
9
42
307
Terence Tao reflecting on GPT-4 in the AI Anthology coordinated by @erichorvitz :. "I expect, say, 2026-level AI, when used properly, will be a trustworthy co-author in mathematical research, and in many other fields as well.". Terry gets it.
3
47
301
I cannot recommend this podcast episode strongly enough. It's simply THE MOST INSIGHTFUL 2 hours content that you can find on LLMs. And it's by none others than @EldanRonen and Yuanzhi Li from our team @MSFTResearch. Stay tuned for a LOT MORE from us soon.
2
41
301
New video! Probably best described as "a motivational speech to study deep learning mathematically" :-). The ever so slightly more formal title is "Mathematical theory of deep learning: Can we do it? Should we do it?". 1/3.
2
37
277
AI still has a long way to go . to me this example is exactly what happened with the whole "sentient discussion": if you prompt with the seed of an answer, the transformer architecture will latch onto this seed. It's really a game of mirrors .

18
22
259
Every Mon/Thu I will post a 1h lecture on the ``Five Miracles of Mirror Descent". We start with basic reminders of convexity, the classical analysis of gradient descent, and a discussion of its robustness properties as well as the regret interpretation.
2
39
263
The universal law of robustness is a tentative theoretical justification for *large* overparametrization in neural network learning. Here is a video explaining the law, in the context of other recent results on overparametrization (e.g., double descent).
0
64
266
New video with a crash course on *tensors* (spoiler: no they aren't JUST multi-dimensional arrays!). Include discussion of cross norms & basic facts about rank. We then use it to get insights into neural networks (in the context of our law of robustness).
0
26
264
Microsoft Research is hiring (in-person) interns! There are many different opportunities in all the labs. Here are some options in the Machine Learning research area in MSR@Redmond:. ML Foundations Neural Architecture Search 1/2.
3
53
265
@ylecun Yann I don't think you should use the cat example anymore. Animals are smarter than humans in all sorts of ways. Intelligence is a highly multidimensional concept, you can't put everyone and everything on a single axis.
17
5
255
Part II of @julienmairal guest post on CNN-inspired kernel methods: you will learn how to efficiently approximate those kernels, and even push the CNN analogy further by doing an end-to-end optimization which includes the approximation step.
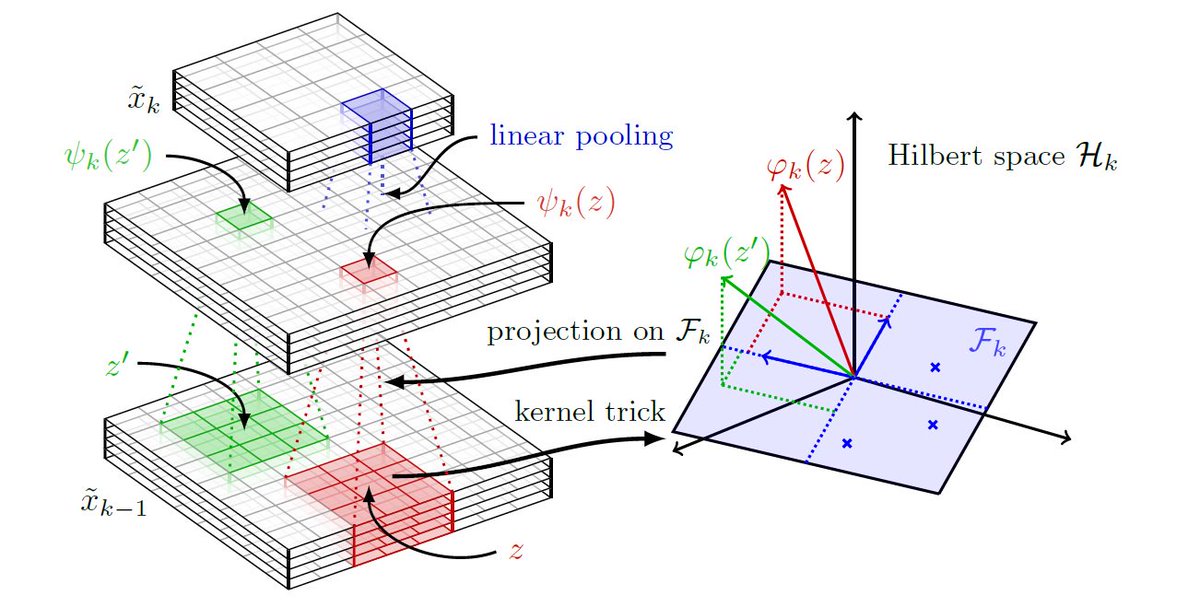
0
53
245
Congratulations to Laslo Lovasz and Avi Wigderson for winning the 2021 Abel Prize!!!!!!! What a fantastic recognition for theoretical computer science from the mathematics community.
3
31
237
I'm super excited by the new eval released by Scale AI! They developed an alternative 1k GSM8k-like examples that no model has ever seen. Here are the numbers with the alt format (appendix C):. GPT-4-turbo: 84.9%.phi-3-mini: 76.3%. Pretty good for a 3.8B model :-).
9
19
250
Congratulations to our colleague Lin Xiao @MSFTResearch for the #NeurIPS2019 test of time award!!!.Online convex optimization and mirror descent for the win!! (As always? :-).).
1
44
246
Interesting thread! To me the ``reason" for CLT is simply high-dim geometry. Consider unit ball in dim n+1 & slice it at distance x from the origin to get a dim n ball of radius (1-x^2)^{1/2}. The volume of the slice is prop to (1-x^2)^{n/2}~exp(-(1/2)n x^2). Tada the Gaussian!!.

Does anyone know a good intuitive explanation for the central limit theorem? I realized the other day that even though I use it all the time I can't really justify *why* it's true.
5
28
241
Updated phi-3 tech report with final numbers for 7B/14B and a new section on phi-3-V (e.g., MMMU at 40.4, in the ballpark of Claude 3-haiku and Gemini-1.0 pro) :

16
51
241
Just to state the obvious, AGI might not happen with current techniques. At a very basic level the argument for AGI is: if you compress sufficiently complex material, like the web, then you end up creating a "mind" that has in it all the "operations" necessary to create the web,.
22
27
234
Join us on YouTube at 1pm PT/4pm ET today for the premiere of our "debate" with @bgreene @ylecun @tristanharris on whether a new kind of intelligence has emerged with GPT-4, and what consequences it might have.
11
43
232
Looks we might be home for some time, so I'm giving a shot at making homemade math videos on proba/optim/ML. First video gives a proof of the very nice ICML19 Theorem by @deepcohen - Rosenfeld- @zicokolter on certified defense against adversarial examples.
2
43
231
I rarely tweet about non ML/math topics but I felt like sharing this one. Just finished my first 100+ miles bike ride with the amazing @ilyaraz2 !!!! It was so much fun, and here is the mandatory finish line picture in front of our beloved @MSFTResearch Building 99 😁

5
0
225
In non-convex optimization, gradient descent is the obvious algorithm because non-local reasoning is hard w/o convexity. In "how to trap a gradient flow" we go beyond gradient descent by uncovering a new local to global phenomenon. Details in new video!
3
25
212
I'm looking for an intern (w. hands on #DeepLearning exp. curious about theory) to work closely with me on adversarial examples this summer. MSR summer are exciting, lots of strong theory visitors also curious about DL. Fantastic opportunity to build bridges!. DM for more/pls RT.
8
69
214
This is a really excellent video, including an insightful discussion of benchmarks like MMLU:
2
26
214

At a time where 314B parameters models are trending, come join me at #NVIDIAGTC to see what you can do with 1 or 2B parameters :-) (and coming soon, what can you do with 3B?!?)

6
11
209
The @TEDTalks by @YejinChoinka is both insightful & beautifully delivered! Totally agree with her that GPT-4 is simultaneously brilliant and incredibly stupid. Yejin gives 3 examples of common sense failing that are worth examining a bit more closely. 1/5
10
50
206
@pmddomingos Vast majority of AI researchers recognize AI ethics as an important field of study, just as worthy as any other AI subfield. Doesn't mean that everyone has to study it, doesn't mean it has less problems than other subfields, but DOES mean that @pmddomingos is extremely misguided.
4
8
200
Second Ironman 70.3 in the bag 😁. Quite happy to have finished this one, it demanded some sacrifices during a busy year in AI. To the youngsters out there, don't forget to get your miles in even when work gets busy 😅

10
5
205
This is the strongest list of learning theory papers I have ever seen: . Very exciting progress on many fronts! #COLT19.
0
26
204
Someone had a change of heart it seems 😅.

It's highly plausible that fuzzy pattern matching, when iterated sufficiently many times, can asymptotically turn into reasoning (it's even possible that humans do it basically in this way). But that doesn't mean it's the optimal way to do reasoning.
8
14
199
This is an excellent blog post on kernels, by one of the world experts on the topic @BachFrancis. *Anyone* interested in ML (theorists & practitioners alike) should be comfortable with everything written there (i.e. the material has to become insight). 1/4.
1
27
190
#Mathematics of #MachineLearning .by @MSFTResearch & @uwcse & @mathmoves: 2 weeks of lectures on statistical learning theory, convex opt, bandits, #ReinforcementLearning, and #DeepLearning. Schedule here: and livestream link here:
2
72
191
If you are in Montreal next week I recommend attending our first workshop in the ``mathematics of ML" program that I co-organize with Gabor Lugosi and Luc Devroye. The lectures will be recorded and hopefully available soon after the workshop.
4
57
191
It's looking like all the open problems I have thought about in the last 10 years are now solved (or in some cases on the verge of being solved)? Latest case in point this beautiful new paper: . I'm glad we (humans) got all this results just in time!.
7
34
190
Lots of progress on bandit convex optimization recently I wish I could follow it more closely . looks like Conjecture 1 from is going to be resolved soon!!!.
4
23
182
Need to brush up your online decision making fundamentals before #NeurIPS2019 ? Check out these two fantastic new books:.- Introduction to bandits by Alex Slivkins - Bandit algorithms by Tor Lattimore and @CsabaSzepesvari 1/2.
3
47
181
@Entropy96171139 Yes, I strongly believe that a deep understanding of core concepts will remain very valuable in the foreseeable future.
8
8
178
This is really the major open problem in deep learning: gradient descent on these architectures has an uncanny ability to dodge any trap, why/how?.

Deep learning is too much resistant to bugs. I just found a major one in the pipeline I have been using for 2 weeks. Yet it produced results good enough to not alert me on possible bugs.
15
9
158
Check out this video if you want to learn more about phi-3!. And yes, yesterday's TikZ unicorn is by phi-3 :-) (14B model).
6
33
167
Mark your calendars, next two weeks there will be exciting workshops at the Simons Institute:. - Concentration of Measure Phenomena, Oct. 19 – Oct. 23. - Mathematics of Online Decision Making, Oct. 26 – Oct. 30.
0
32
168
Amazing news out of the math world: the KLS conjecture has perhaps been proven !!! The paper still needs to be checked carefully, but it follows a well-established line of work (initiated by Ronen Eldan, and refined in particular by Yin Tat Lee). 1/3.
4
13
167
Below is a short clip of my opening statement for the debate @SimonsInstitute on the question "Will current LLM scaling lead to proofs of major math open problems“. Full video here:

Sébastien Bubeck of OpenAI says AI model capability can be measured in "AGI time": GPT-4 can do tasks that would take a human seconds or minutes; o1 can do tasks measured in AGI hours; next year, models will achieve an AGI day and in 3 years AGI weeks, which will be capable of
13
16
168
Exciting start of the year for theory of #DeepLearning! SGD on neural nets can:.1) simulate any other learning alg w. some poly-time init [Abbe & Sandon .2) learn efficiently hierarchical concept classes [@ZeyuanAllenZhu & Y. Li .
1
41
163
I just tried the new Bard powered by Palm 2 and asked it to draw a unicorn in TikZ. It's not quite there yet :-).

16
11
165
Adversarial examples are imo *the* cleanest major open problem in ML. I don't know what was said precisely, but diminishing the central role of this problem is not healthy for our field. Ofc in the absence of a solution there are many alternative questions that we can/should ask.

Very thought-provoking talk by Justin Gilmer at the #ICML2020 UDL workshop. Adversarial examples are just a case of out-of-distribution error. There is no particular reason to defend against the nearest OOD error (i.e., L-infty adversarial example) 1/.
14
19
160
And now for an interlude from Transformers taking over the world and the (very unfortunate) Twitter drama:. *The randomized k-server conjecture is false!*. Joint work w. Christian Coester & Yuval Rabani Picture below is our hard metric space for k-server.

3
18
161
Since the seminal works [@goodfellow_ian, Shlens, @ChrSzegedy, ICLR15; @aleks_madry et al. ICLR18] it is known that larger models help for robustness. We posit that in fact *overparametrization is a fundamental law of robustness*. A thread (and a video).
3
26
160
Lots of discussion around #LaMDA is missing the point: ofc it's not sentient but the issue is that those systems are so good at mimicking that non-technical people can easily be fooled. As is often the case when topics escape experts, the truth matters less than how it "feels".
6
12
150
Want to learn more about overparametrization, adversarial examples, and why interpolation does not lead to overfitting (generalization IV lecture)? The videos for yesterday's talks at the deep learning bootcamp are already online and it's worth a watch!
1
36
154
Unfortunately this is a correct take. I expect all my works on LLMs to remain unpublished because of this situation. Maybe that's the price to pay when the community gets too big. For me personally it's a non-issue, but what about young students entering the field?.

#NeurIPS2023 reviewing if science was sport: any athelete can evaluate any other athlete, irrespective of their specialization, experience, or level. Result? An amateur 100m dash guy criticizes a high jumper for lack of speed during her world-record-breaking jump. Reject.
8
9
160
It's shaping up to be a fine afternoon! (Yes, Talagrand's new book is out!)

4
7
155
I personally think that LLM learning is closer to the process of evolution than it is to humans learning within their lifetime. In fact, a better caricature would be to compare human learning with LLMs' in-context learning capabilities.

Humans don't need to learn from 1 trillion words to reach human intelligence. What are LLMs missing?.
7
13
158

Lots of discussion abt open source LLMs catching up The Big Ones, including eye-catching claims s.a. 90% of ChatGPT's quality (by the really cool work of @lmsysorg). Two Sparks authors @marcotcr & @scottlundberg explore this further in a new blog post 1/2.
4
28
149
Starting tomorrow (with livestream): Simons Institute workshop on *Learning and Testing in High Dimensions*. We have a great line-up of talks, featuring many of the recent exciting results in high-dimensional learning! .
0
18
149