
Sham Kakade
@ShamKakade6
Followers
12,305
Following
418
Media
10
Statuses
347
Harvard Professor. Full stack ML and AI. Co-director of the Kempner Institute for the Study of Artificial and Natural Intelligence.
Joined December 2018
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
#KawalPutusanMK
• 1848912 Tweets
#TolakPolitikDinasti
• 1659246 Tweets
#TolakPilkadaAkal2an
• 1613505 Tweets
#jjk267
• 329596 Tweets
Nobara
• 221639 Tweets
Botafogo
• 161853 Tweets
Mulyono
• 114180 Tweets
Sian
• 71498 Tweets
BATALKAN BUKAN TUNDA
• 63770 Tweets
BOTO PARA SA SB19
• 45327 Tweets
Bolt
• 37832 Tweets
チャイルドシート
• 31048 Tweets
#BauKetekOligarki
• 29524 Tweets
鯉登少尉
• 28424 Tweets
PilihDAMAI BarengPRABOWO
• 27282 Tweets
ポケットキャンプ
• 25465 Tweets
LebihSEJUK LebihNYAMAN
• 22775 Tweets
BBFA LAST HURRAH
• 21233 Tweets
ポケ森サ終
• 20969 Tweets
KITA SEMUA TURUN
• 20393 Tweets
首都高バトル
• 19476 Tweets
Widjiatno Notomihardjo
• 13983 Tweets
中川大志
• 12293 Tweets
買い切りアプリ
• 11188 Tweets
GCSE
• 10862 Tweets





















Super excited to join Harvard with a stellar group of new hires and looking forward to many new collabs with the terrific faculty there! Def sad to be leaving my wonderful UW and MSR colleagues and friends; rest assured, I'll keep up the collabs!
21
15
409
Thank you so much to the awards committee! Also a huge thanks to the past and current ICML chairs and organizers for all their great work for our community! 👍 It is an honor to receive this 😀😀 with such wonderful co-authors:
@arkrause
, Matthias, and Niranjan!

We are very pleased to announce that the
#icml2020
Test of Time award goes to
Gaussian Process Optimization in the Bandit Setting: No Regret and Experimental Design
by Niranjan Srinivas, Andreas Krause, Sham Kakade and Matthias Seeger
>


3
90
468
27
30
344
Grateful to Priscilla Chan/Mark Zuckerberg (
@ChanZuckerberg
Initiative) for generous gift. Kempner Natural & Artificial Intelligence Institute
@Harvard
. Excited to work w/
@blsabatini
+new colleagues to provide new educational and research opportunities.

11
23
300
Can inductive biases explain mechanistic interpretability? Why do sinusoidal patterns emerge for NNs trained on modular addition? (e.g.
@NeelNanda5
)
New work pins this down! w/
@depen_morwani
@EdelmanBen
@rosieyzh
@costinoncescu
!
@KempnerInst
5
34
280
Which optimizer is opt? Our new work compares SGD, Adam, Adafactor (+ momentum), Lion, and, simply, SignSGD on LLM training wrt performance _and_ hyperparameter stability. tldr: Use anything but SGD, the rest are nearly identical:

6
36
224
couldn't reconcile theory/practice with dropout for over a year. New: w/
@tengyuma
& C. Wei. turns out dropout sometimes has an implicit regularization effect! pretty wild. just like small vs. large batch sgd. these plots def surprised us!
5
28
189
What actually constitutes a good representation for reinforcement learning? Lots of sufficient conditions. But what's necessary? New paper: . Surprisingly, good value (or policy) based representations just don't cut it! w/
@SimonShaoleiDu
@RuosongW
@lyang36
2
32
178
Wrapped up at the "Workshop on Theory of Deep Learning: Where next?" at IAS. . The field has moved so much! e.g. Neural Tangent Kernel (NTK) results! A few years ago, understanding DL looked hopeless. Terrific set of talks, too!
1
8
139
1/3 Two shots at few shot learning: We have T tasks and N1 samples per task. How effective is pooling these samples for few shot learning? New work: . Case 1: there is a common low dim representation. Case 2: there is a common high dim representation.
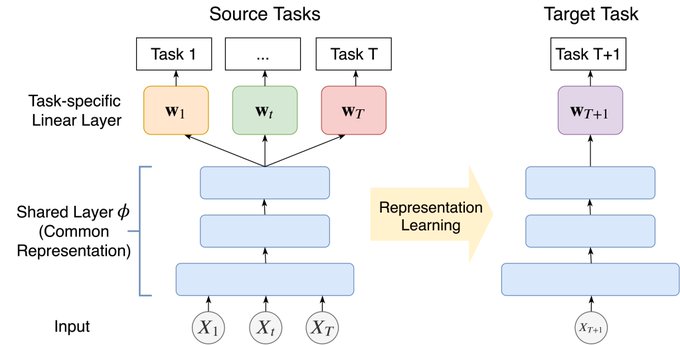
3
17
127
Why does Shampoo work well? Our new work sheds light on this, highlighting a wide misconception about the optimizer. We show the *square* of Shampoo's preconditioner is provably near to the optimal Kronecker approximation of the (Adagrad) Hessian. See:
6
16
121
1/ David Blackwell. Leagues ahead of his time: "What is a good prediction strategy, and how well can you do?" While some things do not seem possible, "Looking for a p [probability] that does well against every x [an outcome] seems hopeless", Blackwell does give us a strategy:
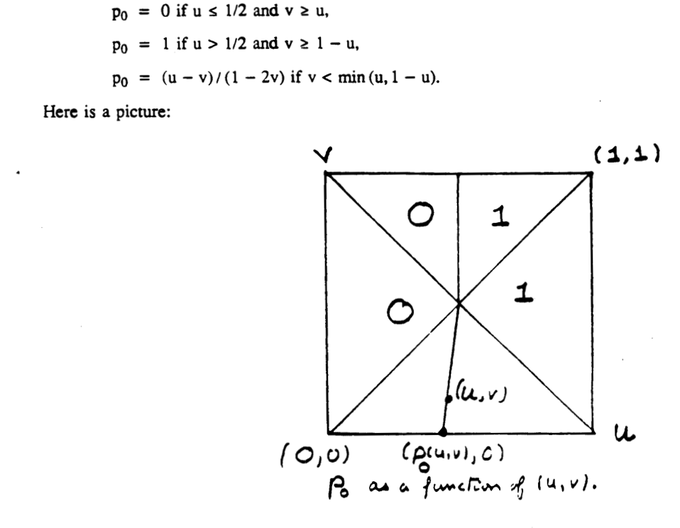
3
15
117
Also, we recently posted this work on the theory of policy gradients for reinforcement learning! A long time in the works, this paper finally gets a handle on function approximation with policy gradient methods.

0
25
115
1/3 Should only Bayesians be Bayesian? No. Being Bayes is super robust! An oldie but goodie from Vovk: "Competitive Online Statistics" 2001. Beautiful work showing Bayes is awesome, even if you are not a Bayesian. (post motivated by nice thoughts from
@RogerGrosse
@roydanroy
).
2
16
108
1/2. No double dipping. My current worldview: the 'double dip' is not a practical concern due to that tuning of various hyperparams (early stopping, L2 reg, model size, etc) on a holdout set alleviates the 'dip'. This work lends evidence to this viewpoint!

Optimal Regularization can Mitigate Double Descent
Joint work with Prayaag Venkat,
@ShamKakade6
,
@tengyuma
.
We prove in certain ridge regression settings that *optimal* L2 regularization can eliminate double descent: more data never hurts (1/n)
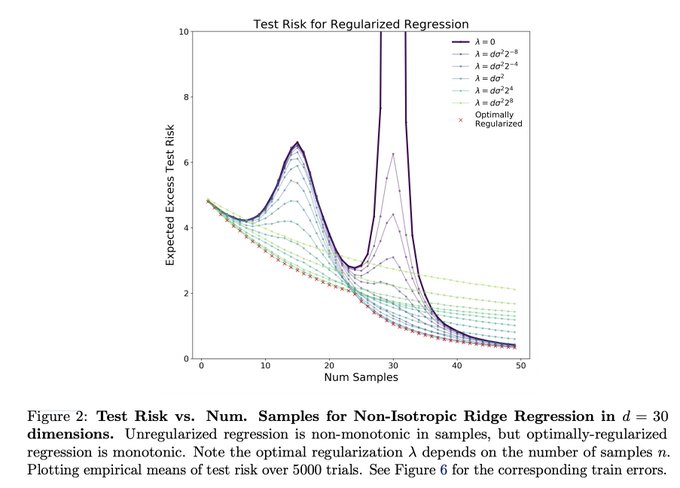
6
51
224
2
20
95
1/ Playing the long game: Is long horizon RL harder than short horizon RL? Clearly, H length episodes scale linearly with H, but counting learning complexity by # episodes rather than # samples accounts for this. So is it any harder?
2
8
82
Repeat After Me:
Transformers are Better than State Space Models at Copying
Transformers are Better than State Space Models at Copying

Check out
#KempnerInstitute
’s newest blog post! Authors Samy Jelassi,
@brandfonbrener
,
@ShamKakade6
@EranMalach
show the improved efficiency of State Space Models sacrifices some core capabilities for modern LLMs.
#MachineLearning
#AI
0
14
59
2
4
80
Beautiful post by
@BachFrancis
on Chebyshev polynomials: . Handy for algorithm design. Let's not forget the wise words of Rocco Servedio, as quoted by
@mrtz
, "There's only one bullet in the gun. It's called the Chebyshev polynomial."
0
10
75
Very cool! Years ago (a little post AlexNet) I put in (too?) many cycles trying to design such a kernel. Didn't match their performance (though didn't have much compute back then). Pretty slick that they use a derived kernel from a ConvNet!

We have released code for computing Convolutional Neural Tangent Kernel (CNTK) used in our paper "On Exact Computation with an Infinitely Wide Neural Net", which will appear in NeurIPS 2019.
Paper:
Code:
1
46
209
2
11
66
Great to see some theory on self-supervised learning. Looking forward to reading this one!

Predicting What You Already Know Helps: Provable Self-Supervised Learning
We analyze how predicting parts of the input from other parts (missing patch, missing word, etc.) helps to learn a representation that linearly separates the downstream task.
1/2
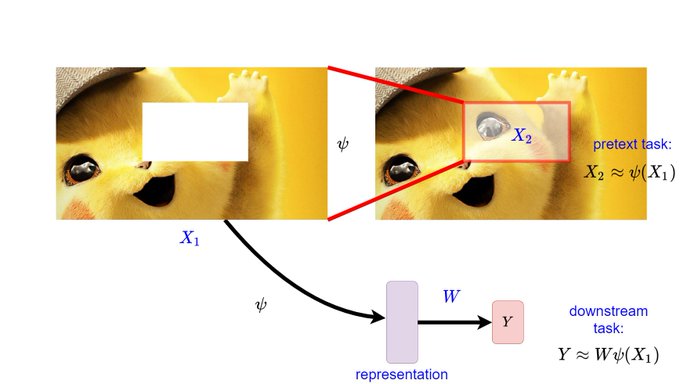
2
105
522
1
3
64
Wow! This is amazing. A few years ago RL was starting to be applied in the robotics domain, with many doubters. Fast forward a handful of years and this! 👏

We've trained an AI system to solve the Rubik's Cube with a human-like robot hand.
This is an unprecedented level of dexterity for a robot, and is hard even for humans to do.
The system trains in an imperfect simulation and quickly adapts to reality:
254
4K
11K
1
3
58
2/ In a seminal paper, "Minimax vs Bayes prediction" ('56) , Blackwell shows we can predict well on any sequence, using randomization: "we can improve matters by allowing randomized predictions." These ideas permeate so much of learning theory today.
1
7
57
Bellairs. Theory of DL. Day 4, penultimate session from the unstoppable Boaz Barak. Average case complexity, computational limits, and relevance to DL. Front row: Yoshua Bengio, Jean Ponce,
@ylecun

2
1
53
Dean Foster,
@dhruvmadeka
, and I have been excited about the application of AI to education! We collected our thoughts here - and we're curious what people think:

0
13
53
Solid move from DeepMind. Knowing Emo Todorov and his work, frankly surprised this one-man-show is only being purchased now. Hope Emo still stays in the driver's seat for MuJoCo going forward!

We’ve acquired the MuJoCo physics simulator () and are making it free for all, to support research everywhere. MuJoCo is a fast, powerful, easy-to-use, and soon to be open-source simulation tool, designed for robotics research:
85
2K
6K
1
2
51
we are growing! please apply to join a vibrant community and please spread the word.
The
#KempnerInstitute
is hiring scientists, researchers, and engineers to join our growing community! Check out our openings and apply today:
#scienceforsocialgood
#openscience
@Harvard
@ChanZuckerberg
@ShamKakade6
@blsabatini

0
9
24
0
8
49
Can modern generative models "transcend" the data which they were trained on? Yes! We looked at this for chess. They can in fact beat the experts they were trained on! See the blogpost and preprint:
NEW blog post! Edwin Zhang and
@EranMalach
show how generative models in
#chess
can surpass the performance of their training data. Read more on our
#KempnerInstitute
blog and check out the preprint:
#transcendence

1
4
31
2
3
47
Just got back from MSR Montreal and had a great visit! Lots of cool projects going on there in RL/NLP/unsupervised learning. Thanks to
@APTrizzle
@momusbah
@Drewch
@JessMastronardi
@philip_bachman
for hosting me!
0
0
47
Amazing and congrats! I have def been wondering if the inductive biases in DeepNets and in ML methods are well suited for certain scientific domains. This settles that for structure prediction! Hoping this can eventually help with drug discovery.
In a major scientific breakthrough, the latest version of
#AlphaFold
has been recognised as a solution to one of biology's grand challenges - the “protein folding problem”. It was validated today at
#CASP14
, the biennial Critical Assessment of protein Structure Prediction (1/3)
134
3K
10K
1
3
45
I found this to be very informative for LLM training. the science was just super well done. highly recommended for anyone training transformer based LLMs.

Sharing some highlights from our work on small-scale proxies for large-scale Transformer training instabilities:
With fantastic collaborators
@peterjliu
,
@Locchiu
,
@_katieeverett
, many others (see final tweet!),
@hoonkp
,
@jmgilmer
,
@skornblith
!
(1/15)
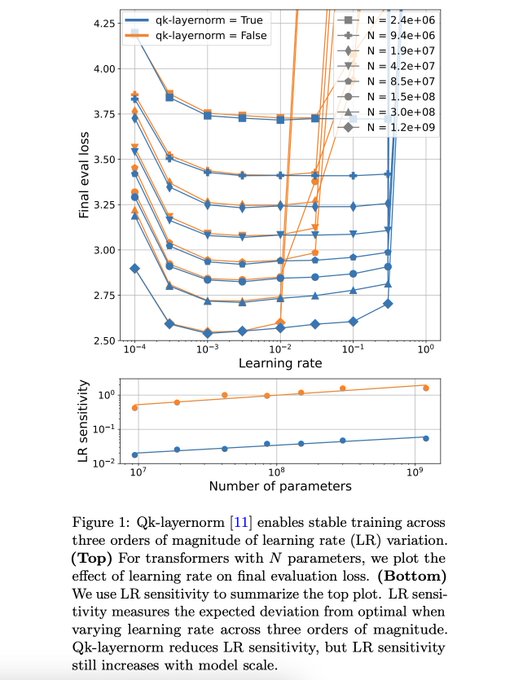
5
62
345
0
4
41
Bellairs Research Institute☀️🏖️.Theory of DL. Day 3: new insights from
@roydanroy
@KDziugaite
on PAC-Bayes for DL. possibly gives a new lens into implicit reg 🤔
@david_rolnick
cool results on expressivity of deep nets. And T. Lillicrap keeps us real on theory vs. practice!
1
0
41
Great to see that Mike Jordan is thinking about Decision Theory, ML, and Econ! Super important area: lots of stats/algorithmic questions that have immediate impact on practice. Few other areas that one can say the same!

Mar 25
#ACMTechTalk
"The Decision-Making Side of Machine Learning: Computational, Inferential, and Economic Perspective," w/Michael I. Jordan.
@JeffDean
@smolix
@etzioni
@erichorvitz
@lexfridman
@DaphneKoller
@pabbeel
@ShamKakade6
@suchisaria
@aleks_madry

0
14
38
0
2
38
At the Bellairs Research Institute: Theory of Deep Learning workshop. Day 1: great presentations on implicit regularization from
@prfsanjeevarora
@suriyagnskr
. Day 2: lucid explanations of NTKs from
@Hoooway
@jasondeanlee
. Good friends, sun ☀️, and sand 🏖️ a bonus.
0
3
37
John was a reason I moved to AI and neuroscience from physics . In his first class, he compared the human pattern-matching algo for chess playing to DeepBlue's brute force lookahead. I wondered if Go would be mastered in my lifetime! Wonderful to hear from John Hopfield again!

Here's my conversation with John Hopfield. Hopfield networks were one of the early ideas that catalyzed the development of deep learning. His truly original work has explored the messy world of biology through the piercing eyes of a physicist.

11
35
224
1
2
38
Very excited about this new work with
@vyasnikhil96
and
@boazbaraktcs
! Provable copyright protection for generative models? See:

1/5 In new paper with
@vyasnikhil96
and
@ShamKakade6
we give a way to certify that a generative model does not infringe on the copyright of data that was in its training set. See for blog, but TL;DR is...
7
52
249
1
2
36
revised thoughts on Neural Tangent Kernels (after understanding the regime better. h/t
@SimonShaoleiDu
): def a super cool idea for designing a kernel! It does not look to be helpful of our understanding of how representations arise in deep learning. Much more needed here!
2
3
36
Can’t wait to work with this amazing new cohort!
Thrilled to announce the 2024 recipients of
#KempnerInstitute
Research Fellowships: Thomas Fel, Mikail Khona, Bingbin Liu, Isabel Papadimitriou, Noor Sajid, & Aaron Walsman!
@Napoolar
@KhonaMikail
@BingbinL
@isabelpapad
@nsajidt
@aaronwalsman

0
17
142
1
0
35
Nice talk from Rong Ge! learning two layer neural nets, with _finite_ width: A seriously awesome algebraic idea. Reminiscent of FOOBI (the coolest spectral algo in town!): they replace the 'rank-1-detector' in FOOBI with a 'one-neuron-detector'.
1
6
35
Bellairs Research Institute ☀️⛱️. Theory of DL workshop, Day 2 (eve): Thanks to Yann LeCun and Yoshua Bengio for thought provoking talks.
@ylecun
title: "Questions from the 80s and 90s". Good questions indeed!!
1
2
33
Bellairs. Day 5
@HazanPrinceton
and myself: double feature on controls+RL. +spotlights:
@maithra_raghu
: meta-learning as rapid feature learning. Raman Arora: dropout, capacity control, and matrix sensing .
@HanieSedghi
: module criticality and generalization! And that is a wrap!🙂
0
3
33
Welcome
@du_yilun
!! So excited to have you join! This is going to be epic :)
@KempnerInst

Super excited to be joining Harvard as an assistant professor in Fall 2025 in
@KempnerInst
and Computer Science!!
I will be hiring students this upcoming cycle -- come join our quest to build the next generation of AI systems!
167
39
2K
1
2
33
I found this quite thought provoking!

🧵What’s the simplest failure mode of Transformers? Our
#NeurIPS2023
spotlight paper identifies the “attention glitches” phenomenon, where Transformers intermittently fail to capture robust reasoning, due to undesirable architectural inductive biases.
Poster: Wed 5-7pm CST,
#528
4
30
223
0
2
30
Exciting! New RL Conference. Thanks to
@yayitsamyzhang
and others for their leadership!

Thrilled to announce the first annual Reinforcement Learning Conference
@RL_Conference
, which will be held at UMass Amherst August 9-12! RLC is the first strongly peer-reviewed RL venue with proceedings, and our call for papers is now available: .

5
61
418
0
0
30
This should be good!
@SurbhiGoel_
has done some exciting work in understanding neural nets, going beyond the "linear" NTK barrier. To make progress in deep learning theory, we def need to understand these beasts in the non-linear regime.
Looking forward to this Friday at 1pm when we'll hear from
@SurbhiGoel_
about the computational complexity of learning neural networks over gaussian marginals.
We'll see some average-case hardness results as well as a poly-time algorithm for approximately learning ReLUs
0
1
12
0
4
29
Congrats! A beautiful book indeed!

Noga Alon
@princeton
and Joel Spencer
@nyuniversity
receive the 2021 Steele Prize for Mathematical Exposition for The Probabilistic Method
@WileyGlobal
. Now in its 4th ed, the text is invaluable for both the beginner and the experienced researcher. More...

0
16
104
1
1
29
A downright classic. And let us take a moment to ponder on the most didactic figure of all time, seen in this beautiful paper: :)


0
1
28
Excited to be a part of this, with Aarti Singh who is spearheading the CMU effort!

📢 Announcing seven new National Artificial Intelligence Research Institutes!
Discover the themes and the institutions that are helping advance foundational AI research to address national economic and societal priorities in the 🧵 ⬇️:
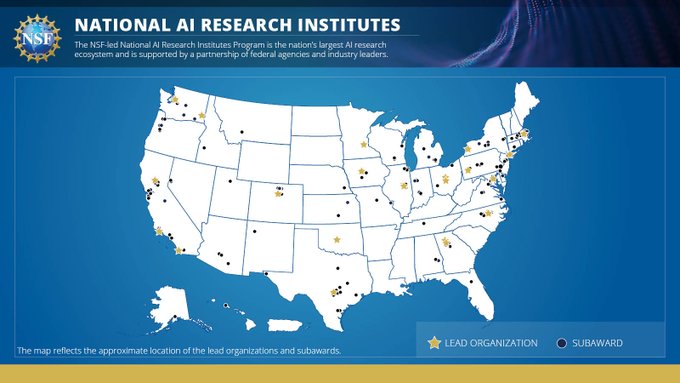
3
41
96
1
2
27
Please apply and spread the word! These positions are pretty great, and it's a wonderful community to study the most exciting AI and neuro questions!
The application is now open for our
#KempnerInstitute
Research
#Fellowship
! Postdocs studying the foundations of
#intelligence
or applications of
#AI
are encouraged to apply. Learn more and apply by Oct. 1:
#LLMs
#NeuroAI
#ML
@ShamKakade6
@blsabatini

0
28
47
0
7
27
I feel like I should take the class after reading this 😂
GPT-3 on why Harvard students should take CS 182 this fall (bold text is prompt)

3
5
62
0
0
24
A huge congrats to MPI for hiring the terrific
@mrtz
as a director! Personally sad to have him across the pond, but excited to see what Moritz helps to build.
0
0
25
Very cool! Getting RL to work with real sample size constraints is critical. Interesting to see how it was done here. Also, looks like the application with Loon is for social good! 👏

Our most recent work is out in Nature! We're reporting on (reinforcement) learning to navigate Loon stratospheric balloons and minimizing the sim2real gap. Results from a 39-day Pacific Ocean experiment show RL keeps its strong lead in real conditions.
23
108
763
1
1
24
1/3 Can open democracies fight pandemics? making a PACT to set forth transparent privacy and anonymity standards, which permit adoption of mobile tracing efforts while upholding civil liberties.
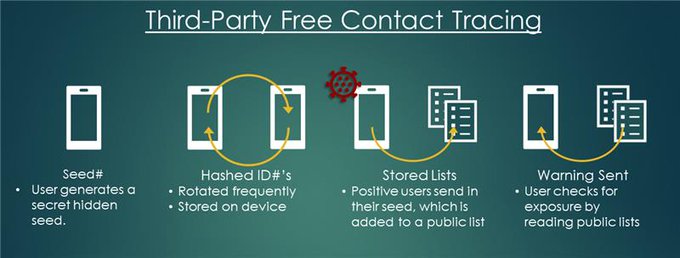
1
4
22
A nice note. Some cool tricks in these Bhatia matrix analyses books. If I understand correctly, Russo-Dye Thm lets u (exactly) compute the largest learning rate with a maximization problem using only vectors rather than matrices (still hitting it on the 4th-moment data tensor).

What's the largest learning rate for which SGD converges? In deterministic case with Hessian H it is 2/||H||, from basic linear algebra. For SGD, an equivalent rate is 2/Tr(H), derivation from Russo-Dye theorem:
3
18
159
2
1
23
It's a really great codebase and excited for future collabs with
@allen_ai
!
So excited to collaborate with
@allen_ai
and its partners
@databricks
@AMD
@LUMIhpc
on this groundbreaking work. Special thanks to
@KempnerInst
’s co-director
@ShamKakade6
and engineering lead
@maxshadx
!
0
3
18
0
1
22
Big congrats tot he 2024 Sloan Research Fellows!

We have today announced the names of the 2024 Sloan Research Fellows! Congratulations to these 126 outstanding early-career researchers:

6
40
248
0
0
21
Super cool result on the impossibility of watermarking!
(+ Kempner's new blog: Deeper Learning)
Deeper Learning, our new
#KempnerInstitute
blog is live! Check it out:
In our first post, Ben Edelman,
@_hanlin_zhang_
&
@boazbaraktcs
show that robust
#watermarking
in
#AI
is impossible under natural assumptions. Read more:

0
9
25
1
2
21
Theory extends to general finite groups (e.g.
@bilalchughtai_
et al.). Many open questions.
See paper:
and blog post:
0
1
21
3/ Due to Dean Foster, my own education of online learning and sequential prediction started through first understanding Blackwell's approachability, which is a wonderful way to grasp the foundations. I signed this:
1
3
21
Thank you
@SusanMurphylab1
! I am thrilled that I can finally be your colleague ❤️

0
1
20
2/ This was the COLT 2018 open problem from
@nanjiang_cs
and Alekh, who conjectured a poly(H) lower bound. New work refutes this, showing only logarithmic in H episodes are needed to learn. So, in a minimax sense, long horizons are not more difficult than short ones!
1
0
19
Excited to share this new work:

It's hard to scale meta-learning to long inner optimizations.
We introduce iMAML, which meta-learns *without* differentiating through the inner optimization path using implicit differentiation.
to appear
@NeurIPSConf
w/
@aravindr93
@ShamKakade6
@svlevine
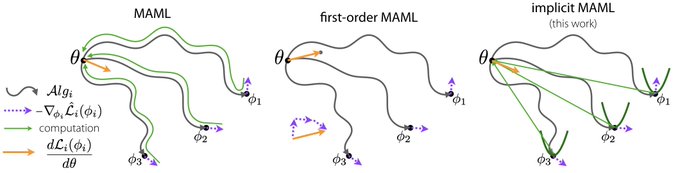
8
120
534
0
1
19
Turns out margin maximization, yes just margin maximization, implies this emergence. Some cool new mathematical techniques let us precisely derive the max margin… (yup, that observed margin of 1/(105√426) is indeed what we predict).
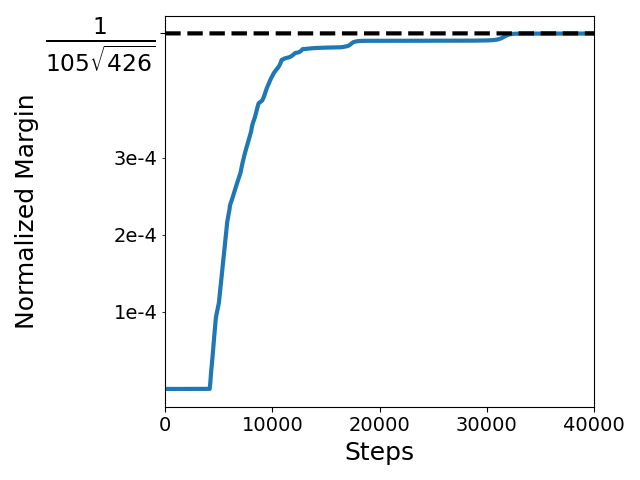
1
0
18
We are thrilled to have this stellar cohort joining us!! Super excited for the new directions they are pursuing in AI.
We are thrilled to announce the appointments of three new
#KempnerInstitute
Investigators who will play key roles in shaping & advancing our research program. Learn more about
@xkianteb
,
@du_yilun
and
@msalbergo
in our official announcement:
@hseas
#AI
#ML

3
5
88
0
0
18
Please spread the word!
Our post-bac fellowship application deadline is fast approaching! Read more about this program and apply today:
#KempnerInstitute
@EllaBatty
@grez72
@ShamKakade6
@blsabatini
@HarvardGSAS

1
7
12
0
11
17
huh... so this is pretty wild. it is _formally_ equivalent to the the Polyak heavy ball momentum algorithm (with weight decay). not just 'similar behavior'.

Conventional wisdom: slowly decay learning rate (lr) when training deep nets. Empirically, some exotic lr schedules also work, eg cosine. New work with Zhiyuan Li: exponentially increasing lr works too! Experiments + surprising math explanation. See
15
136
552
1
4
17
Looking forward to reading this one! The original Bousquet and Elisseeff work was way ahead of its time! Epic in retrospect.

0
0
16
A nice point: better features not better classifiers are key. This is more generally an important point related to distribution shift: (also comes up in RL, related to our " is a good representation sufficient" paper).

Video summaries for our papers "Adversarial Examples Aren't Bugs They're Features" () and "Image Synthesis with a Single Robust Classifier" () are now online. Enjoy! (
@andrew_ilyas
@tsiprasd
@ShibaniSan
@logan_engstrom
Brandon Tran)
2
21
99
0
3
16
this work did change my world view of resource tradeoffs: how more compute makes up for less data. the frontier plots were quite compelling! checkout the poster for more info!

Will deep learning improve with more data, a larger model, or training for longer?
"Any balanced combination of them" <– in our
#NeurIPS2023
spotlight, we reveal this through the lens of gradient-based feature learning in the presence of computational-statistical gaps. 1/5
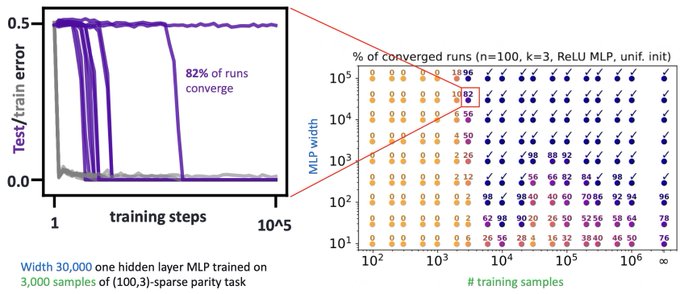
1
4
25
1
1
16
A good overview of these limits! This def a nice way to try and handle hyper-parameter transfer!
NEW! Check out recent findings on width and depth limits in part 1 of a
#KempnerInstitute
two-part series from
@ABAtanasov
,
@blake__bordelon
&
@CPehlevan
. Read on:
#neuralnetworks
#AI

0
4
27
0
0
16
cool stuff from
@TheGregYang
: Tensors, Neural Nets, GPs, and kernels! looks like we can derive a corresponding kernel/GP in a fairly general sense. very curious on broader empirical comparisons to neural nets, which (potentially) draw strength from the non-linear regime!

1/ I can't teach you how to dougie but I can teach you how to compute the Gaussian Process corresponding to infinite-width neural network of ANY architecture, feedforward or recurrent, eg: resnet, GRU, transformers, etc ... RT plz💪
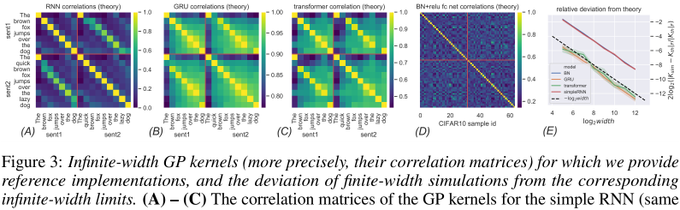
4
108
371
1
1
15
a really excellent result. very intuitive! (also, Kempner's new blog: Deeper Learning)
1/5 New preprint w
@_hanlin_zhang_
, Edelman, Francanti, Venturi & Ateniese!
We prove mathematically & demonstrate empirically impossibility for strong watermarking of generative AI models.
What's strong watermarking? What assumptions? See blog and 🧵
5
44
253
0
2
15
So if the memory utilization of Adam is a concern, use Lion or Adafactor (with momentum). Importantly, our results suggest no performance hit.
1
0
15
interested in elastic ML? check out our new blog post. this should help serving foundation models on more devices and in more settings.
In our latest Deeper Learning blog post, the authors introduce an algorithmic method to elastically deploy large models, the
#MatFormer
. Read more:
#KempnerInstitute
@adityakusupati
@snehaark
@Devvrit_Khatri
@Tim_Dettmers

0
12
21
0
3
15
Retweet after me...

Our recent work on the comparison between Transformers and State Space Models for sequence modeling now on arxiv! TLDR - we find a key disadvantage of SSMs compared to Transformers: they cannot copy from their input. 🧵
Arxiv:
Blog:
2
52
237
1
1
14
Congrats and well deserved!! 👏👏 It’s inspiring to have
@madsjw
as a leader in our community.

My Khachiyan prize talk at INFORMS yesterday was the victim of technical difficulties, so here is the script:
15
18
173
0
0
13
It’s great to be a visitor here!

Very excited to see this finally announced & many thanks to
@JeffDean
,
@GoogleAI
and
@Princeton
for the ongoing support!
+ fresh from the oven, research from the lab:
0
5
57
2
0
12
Work done with co-authors
@rosieyzh
@depen_morwani
@vyasnikhil06
@brandfonbrener
. See our paper and blog post for details:

3
0
11
The previous plot showed performance and stability wrt learning rate, showing that tuning is stable across orders of magnitude. More generally, practitioners also care about hyperparameter stability and tuning for other params. Again, all except SGD are similarly stable:

1
0
11
So excited to work with this amazing new cohort!
Kempner Institute announces the first cohort of research fellows starting this fall! Looking forward to learning from and collaborating with
@brandfonbrener
,
@cogscikid
,
@_jennhu
,
@IlennaJ
,
@WangBinxu
,
@nsaphra
, Eran Malach, and
@t_andy_keller
.
3
16
141
0
0
10
Our paper also focuses on understanding: what does it take to perform as well as Adam? We examine this by reducing the adaptivity of Adam from per parameter to per-block. See our paper and blog post for details. See the linked thread for more details.
1
0
10
Also, the FOOBI (Fourth-Order-Only Blind Identification) paper: . A beautiful algo. And a catchy acronym too! Still surprises me how one can efficiently impose that rank one constraint! Worth a read.
0
1
9
Congrats
@timnitGebru
for your efforts to provide a broader set of ideas to the community! Excited to see the work that comes out.

We are
@DAIRInstitute
— an independent, community-rooted
#AI
research institute free from
#BigTech
's pervasive influence. Founded by
@timnitGebru
.
26
307
1K
0
0
10
Bellairs Research Institute ☀️🏖️. Theory of DL. Day 3:
@nadavcohen
: "Gen. and Opt. in DL via Trajectories". careful study of deep linear nets. second time hearing about it. now appreciate how this reveals quite different effects, relevant for DL! also, 🏊♂️🥥 🍨!
1
0
10
nice talk! and an important direction to pursue; the older margin based ideas def need to be refined. so nice to see this here!

A new paper on improving the generalization of deep models (w.r.t clean or robust accuracy) by theory-inspired explicit regularizers.
0
84
419
0
0
10
nice post with some cool explanations!

New post on iMAML: Meta Learning with Implicit Gradients
some animations, discussing potential limitations and of course a Bayesian/variational interpretation
9
107
480
0
0
9
In practice, the exponent in the preconditioner is often a hyperparameter, so the difference doesn't manifest. But this view significantly alters our understanding behind the workings of Shampoo. w/ the great team
@depen_morwani
@IShapira1
@vyasnikhil96
@EranMalach
Lucas Janson
0
0
9
A nice read!

Check out new blog post on deep learning theory: ultra-wide neural network and Neural Tangent Kernel.
0
13
45
0
0
9
3/3 And the seminal papers that started this line of thought: Dawid, "The prequential approach" (1984), and Foster, "Prediction in the worst case" (1991). They def influenced my thinking! stats meets philosophy. good stuff.
1
0
9
Also attended this powerful lecture by Loretta Lynch, the 1st Black woman to serve as US Attorney General. Grateful for all she has done. ❤️

Attended the Dr. Martin Luther King Jr. commemorative lecture by Loretta Lynch, the 1st Black woman to serve as US Attorney General, introduced by Pro. Claudine Gay, the 1st Black president of Harvard University. The message was clear: Never Lose Infinite Hope. INFINITE HOPE. ❤️

2
2
62
1
0
9
2/3 This work shows that, under either assumption, all T*N1 samples can be used to achieve a precise notion of "few shot" learning. Also, worth pointing out nice work in Maurer et al . New work makes improvements under assumptions of good common rep!
1
1
8
Pinged Emo, and he'll have freedom to drive/add new things. So this looks like a win-win situation for the community...
0
0
9
and the second post in Deeper Learning...
In our newest Deeper Learning
#KempnerInstitute
blog, authors
@EdelmanBen
,
@depen_morwani
,
@costinoncescu
, and
@rosieyzh
explain mechanic interpretability results using known inductive biases. Read it here:
@ShamKakade6
@Harvard
#AI
#machinelearning

1
9
29
0
0
9
@RogerGrosse
@SimonShaoleiDu
Right! An interesting hypothesis test for 'deep learning' could be to see if the learned network is better than using the derived locally linear kernel. The derived kernel itself is def pretty cool (e.g. CNTK).
0
0
9
What's the opt optimizer? New work comparing (diagonally conditioned) first order methods.
NEW
#KempnerInstitute
blog:
@rosieyzh
,
@depen_morwani
,
@brandfonbrener
,
@vyasnikhil96
&
@ShamKakade6
study a variety of
#LLM
training optimizers and find they are all fairly similar except for SGD, which is notably worse. Read more:
#ML
#AI

0
5
17
0
3
8
Thrilled to have you join and super excited for what’s next!!

🌞 One final bit of news — excited to announce I’ll be starting as an assistant professor in applied mathematics
@Harvard
and
@KempnerInst
Investigator in 2026 :) Please reach out if you may be interested in working with me. Grateful for everyone that made this possible!
30
8
247
1
0
8
CoLor-Filter: It's all about the data! Our new algorithm learns data mixtures for better pertaining performance. Check it out here:

🌈 New paper! 🌈
“CoLoR-Filter: Conditional Loss Reduction Filtering for Targeted Language Model Pre-training”
We introduce a simple approach for data selection and see >11x gains in data efficiency on downstream target tasks when sub-selecting from C4 for 1.2B models. 🧵

1
8
62
0
0
7
Nice notes!

One of my favorites from most recent offering of CS287 Advanced Robotics?
Exam study handout summarizing all the main math in ~20pp. Incl. MaxEnt RL, CEM, LQR, Penalty Method, RRTs, Particle Filters, Policy Gradient, TRPO, PPO, Q-learning, DDPG, SAC,
2
173
873
1
0
7
Congratulations!! Excited to see what comes next!

I'm absolutely thrilled that
@MosaicML
has agreed to join
@databricks
as we continue on our journey to make the latest advances deep learning efficient and accessible for everyone. The best of MosaicML is yet to come 🎉🎉🎉
47
22
471
1
0
7