
Sneha Kudugunta
@snehaark
Followers
2K
Following
3K
Media
24
Statuses
531
tpu go brr @GoogleDeepMind @uwcse | varying proportions of AI and mediocre jokes (not mutually exclusive) | she/her/hers
San Francisco Bay Area, CA
Joined September 2014
MatFormer is a small but significant step towards true conditional computation models. Why use many neuron when few neuron do trick? 🙃.

Announcing MatFormer - a nested🪆(Matryoshka) Transformer that offers elasticity across deployment constraints. MatFormer is an architecture that lets us use 100s of accurate smaller models that we never actually trained for!. 1/9
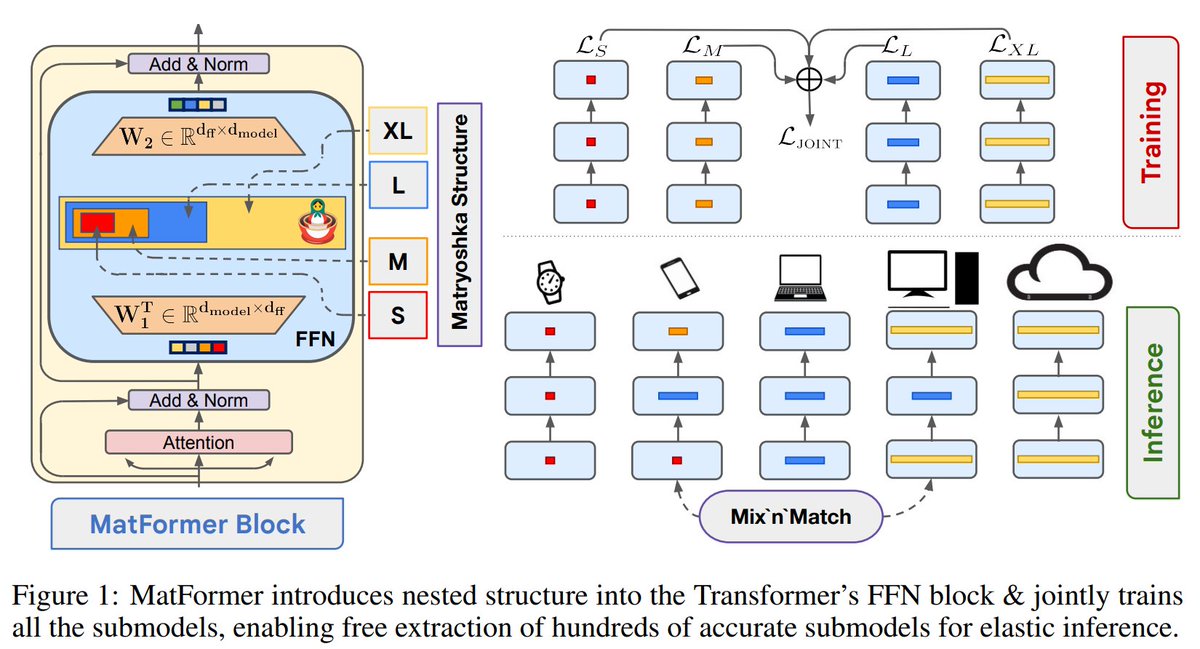
1
8
75

Excited to announce MADLAD-400 - a 2.8T token web-domain dataset that covers 419 languages(!). Arxiv: Github: 1/n

24
133
789
New EMNLP paper “Investigating Multilingual NMT Representation at Scale” w/ @ankurbpn, @orf_bnw, @caswell_isaac, @naveenariva. We study transfer in massively multilingual NMT @GoogleAI from the perspective of representational similarity. Paper: 1/n
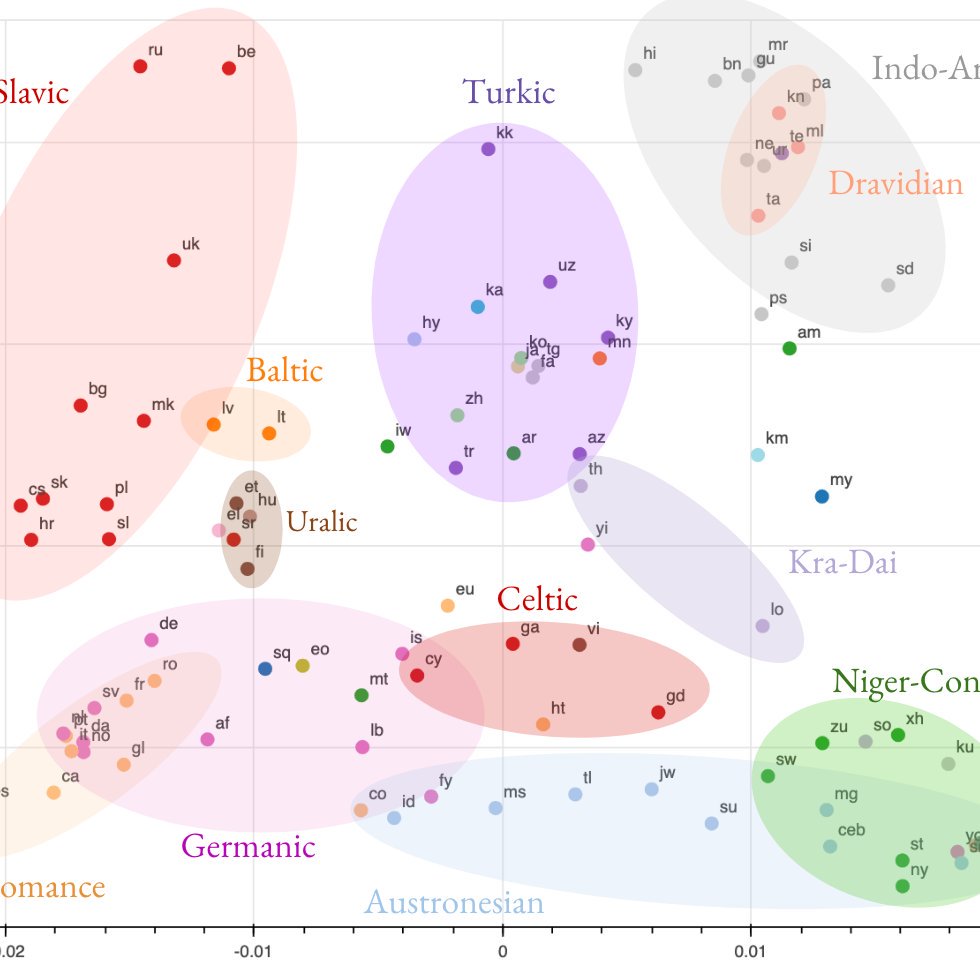
9
71
279
Tired: Catching imposter syndrome by reading PhD applications from students way smarter than you. Wired: Getting excited about talking them into building cool things with you ✨.
2
2
159
We wrote a blogpost about our work on Task-level Mixture-of-Experts (TaskMoE), and why they're a great way to efficiently serve large models (vs more common approaches like training-> compression via distillation).

Read all about Task-level Mixture-of-Experts (TaskMoE), a promising step towards efficiently training and deploying large models, with no loss in quality and with significantly reduced inference latency ↓
3
21
111
#EMNLP2021 Findings paper “Beyond Distillation: Task-level Mixture-of-Experts for Efficient Inference” w/ @bignamehyp, @ankurbpn, Maxim Krikun, @lepikhin, @lmthang, @orf_bnw about TaskMoE, an inference friendly alternative to token-based MoEs. Link: 1/n

2
13
100
Late tweet, but thank you ENSLP #NeurIPS2023 for the best paper award, and @Devvrit_Khatri . for the excellent presentation on behalf of the team @adityakusupati!. Excited to push further on conditional computation for tiny fast flexible models 🚀

Announcing MatFormer - a nested🪆(Matryoshka) Transformer that offers elasticity across deployment constraints. MatFormer is an architecture that lets us use 100s of accurate smaller models that we never actually trained for!. 1/9
3
8
87
Our Colab is out!. Link: I'll be talking about our paper today (11/5) (w/ @ankurbpn, @iseeaswell, @naveenariva, @orf_bnw) "Investigating Multilingual NMT Representations at Scale" at AWE Hall 2C (17:24) @emnlp2019. #emnlp2019 #NLProc #googleAI.
New EMNLP paper “Investigating Multilingual NMT Representation at Scale” w/ @ankurbpn, @orf_bnw, @caswell_isaac, @naveenariva. We study transfer in massively multilingual NMT @GoogleAI from the perspective of representational similarity. Paper: 1/n
1
25
84

I'm at #NeurIPS2023 today presenting MADLAD-400 with.@BZhangGo and @adityakusupati at 5:15pm in Hall B1/B2 #314! Come by and chat w/ us about creating *massive* datasets, making sure they're not garbage, and multilingual LMs :D.
Excited to announce MADLAD-400 - a 2.8T token web-domain dataset that covers 419 languages(!). Arxiv: Github: 1/n
1
12
67
We made the Matformer code for ViT public!.
📢🪆MatViT-B/16 & L/16 model checkpoints & code are public - drop-in replacements that enable elastic compute for free!🔥. Try them out; let us know😉. Shout out to @kfrancischen for the release; @anuragarnab & @m__dehghani for the amazing Scenic library.

1
10
61
A summary of all the exciting work on massively multilingual massive NMT that's been happening over the past year @GoogleAI.
New research demonstrates how a model for multilingual #MachineTranslation of 100+ languages trained with a single massive #NeuralNetwork significantly improves performance on both low- and high-resource language translation. Read all about it at:
2
7
47
MADLAD-400 is now available publicly. Big thanks to Dustin and @mechanicaldirk at @ai2_allennlp!. Arxiv:

We just released the MADLAD-400 dataset on @huggingface! Big (7.2T tokens), remarkably multilingual (419 languages), and cleaner than mC4, check it out:
0
11
47
as a researcher my love language is sending papers that remind me of you how do i have friends.
0
0
34
Expectation:.Now I'm at home all the time I'll be so good at texting and calling my friends. Reality:.Replies "haha" to text after 2 business days.
1
1
32
A great dataset on VLN - I don't see Telugu datasets very often. I was super excited to help change this as a Telugu speaker!.

Kudos to @996roma for doing the analysis of linguistic phenomena in RxR, and many thanks to @snehaark for working with Roma for Telugu! Also, to @yoavartzi and team for establishing this overall approach with Touchdown.
2
4
32

Reasons to hire Aditya:. 1) v cool representation learning research with real world impact.2) genuinely cares about and bats for his mentees and collaborators.3) vibes are immaculate ✨.
📢📢At the last minute, I decided to go on the job market this year!!! . Grateful for RTs & promotion at your univ.😇.CV & Statements: Will be at #NeurIPS2023! presenting AdANNS, Priming, Objaverse & MADLAD. DM if you are around, would love to catch up👋.
0
1
25
Most CommonCrawl based datasets cover 200-250 languages - we applied state-of-the-art LangID models to crawl over 498 languages. 2/n

1
2
24
I'll be talking about this paper at @WiMLworkshop (East Hall C) today at 11.10am and at the evening poster session 6:30pm onwards (Poster #257, East Hall B)!. Paper: Colab: Co-authors:@ankurbpn, @iseeaswell, @naveenariva, @orf_bnw.
New EMNLP paper “Investigating Multilingual NMT Representation at Scale” w/ @ankurbpn, @orf_bnw, @caswell_isaac, @naveenariva. We study transfer in massively multilingual NMT @GoogleAI from the perspective of representational similarity. Paper: 1/n
0
3
24
Literally all my shitty NLU model does:. The .The the a a. A a the the.#%$@^%$#.A a a a a a a a a. A.I I I I I I .Of the of the of the. The. #@$!.
0
0
21
I look forward to talking about our paper "Investigating NMT Representations at Scale" at @WiMLworkshop 🥳. #WiML2019. Original Tweet:

The #WiML2019 program features 8 remarkable contributed talks by: Kimia Nadjahi (@TelecomParis_), Xinyi Chen (@Google), Liyan Chen (@FollowStevens), @snehaark (@Google), Qian Huang (@Cornell), Mansi Gupta (@PetuumInc), Margarita Boyarskaya (@nyuniversity), @natashajaques (@MIT)
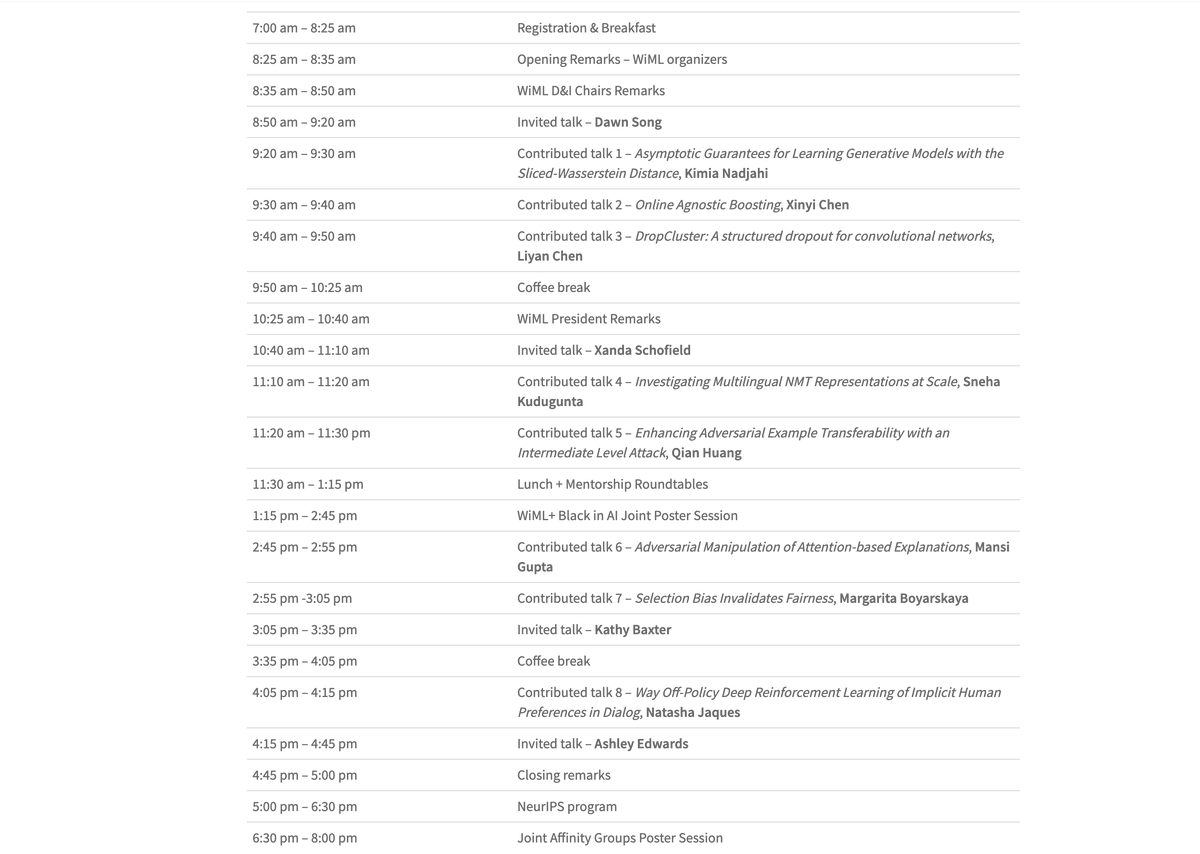
0
1
21
A 🧵 on all the research involving a 1000+ language model (🤯) that went into adding 24 new languages to Google Translate.

How many languages can we support with Machine Translation? We train a translation model on 1000+ languages, using it to launch 24 new languages on Google Translate without any parallel data for these languages. Technical 🧵below: 1/18
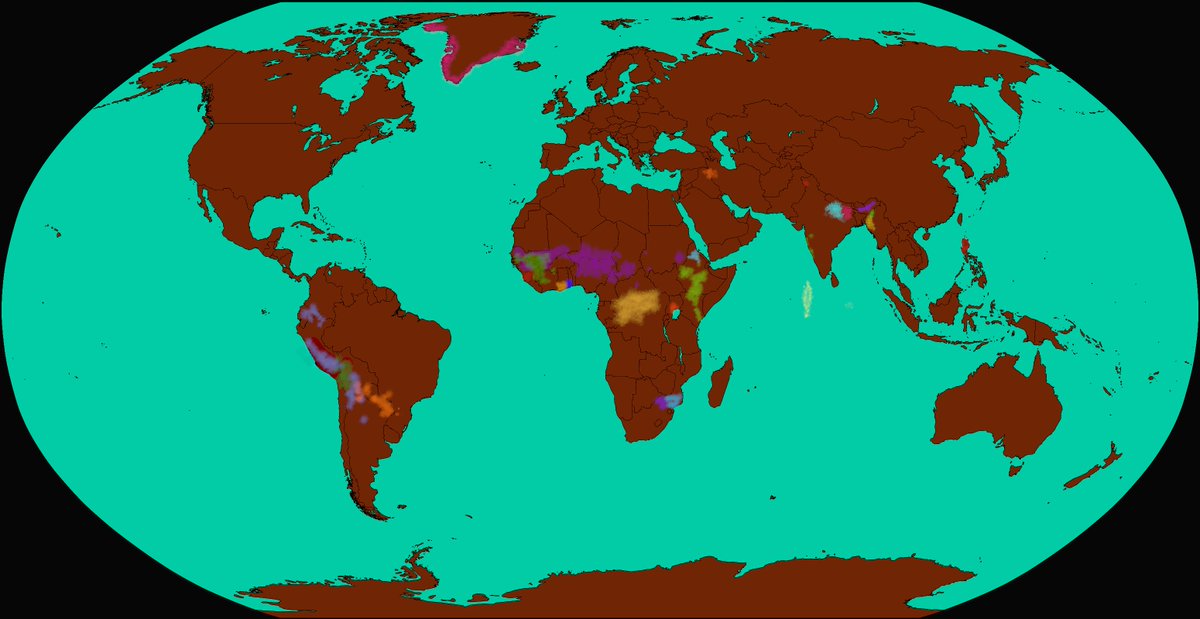
0
0
20
However, crawled datasets are often noisy, and is even worse for under-resourced languages, with many datasets having data that is not even in the labeled language (. So, we self-audited our initial dataset, and kept only 419 languages of 498. 3/n

1
2
20
like actually tho
I'm at #NeurIPS2023 today presenting MADLAD-400 with.@BZhangGo and @adityakusupati at 5:15pm in Hall B1/B2 #314! Come by and chat w/ us about creating *massive* datasets, making sure they're not garbage, and multilingual LMs :D.
2
2
21
These are stunning and well made and the puns are even better.

NeuralBricolage Publishing House presents.The Book of GANesis. the link to the full version.#NeurIPS2019 #unpaper #folkaiart

0
4
19
Data cleaning, documentation and auditing practices beyond English still have a long way to go, and we hope that this work furthers work in this area! 6/n.
1
0
20
Neighborhood cafe crammed with tech bros on a Wednesday afternoon after our employers make us WFH to slow down #coronavirus.
0
1
18
We also train baselines on this dataset for MT and LMs, and release the checkpoints. 5/n

2
2
17
I used to use a small notebook to set my agenda, but I started a version of this after reading @deviparikh's post The most immediate benefit was the reduced mental overload of remembering to talk to people/returning stuff.

A calendar is not just a reminder device for keeping track of external events. Used right, a calendar can be a full-fledged tool for thought.
1
1
16
confused yet happy about the general praise of a major conference's review process on my feed why is nobody crying #acl2020nlp.
0
0
16
Difficult work on an often neglected problem by @iseeaswell and team (to appear at COLING 2020).
What do we need to scale NLP research to 1000 languages? We started off with a goal to build a monolingual corpus in 1000 languages by mining data from the web. Here’s our work documenting our struggles with Language Identification (LangID): 1/8

1
0
15
v. excited that MiTTenS 🧤 covers languages not commonly seen in misgendering datasets!.
0
1
12
Every time I use Colab, I'm struck by how genuinely useful I find each new feature.

You can now edit📝, create🆕, save💾, and move➡️ files and folders📂 through file browser on the left.
0
0
12
Manual smell tests of your data are limited, but super useful! I would love for all new large scale datasets to define their own audits AND release the results in all its messy glory.
Great work by Sneha to create a new, open, and highly multilingual web dataset. with a great acronym! It also sets a nice precedent that every single one of the 419 languages in the crawl was looked at and considered for specific filtering.
0
1
11
Me: Hmm, I wonder which parts of the results section I should edit?.Past Me: .Me: Thanks.

1
1
12
Work done with amazing collaborators @iseeaswell, @BZhangGo, @xgarcia238, Christopher Choquette-Choo, @katherine1ee, Derrick Xin, @adityakusupati, @romistella, @ankurbpn and @orf_bnw! 7/7.
3
1
12
In 2040 people will study how Gen-Zers coped with 2020 by pretending to be ants in an ant colony on Facebook.


0
1
10
A blog on MatFormer with an OSS reimplementation of MatLMs!.

In our latest Deeper Learning blog post, the authors introduce an algorithmic method to elastically deploy large models, the #MatFormer. Read more: #KempnerInstitute @adityakusupati @snehaark @Devvrit_Khatri @Tim_Dettmers

0
1
12
Highly recommend this book by @chipro - I used an early draft of this for interview prep and there's nothing quite like it!.

An early draft of the machine learning interviews book is out 🥳. The book is open-sourced and free. Job search is a stressful process, and I hope that this effort can help in some way. Contributions and feedback are appreciated!.
1
1
11
Measuring the social impacts of foundation models for as many languages we support is super important - @Chris_Choquette and @katherine1ee led some intriguing work investigating the memorization properties of multilingual models.

419 languages is so many languages (!!). Side note: .We investigated how having lots of different languages in one model impacts what and how much is memorized. Which examples get memorized depends on what other examples are in the training data!

0
1
10
@ankurbpn @orf_bnw @naveenariva @GoogleAI We also find that representations of high resource and/or linguistically similar languages are more robust when fine-tuning on an arbitrary language pair, which is critical to determining how much cross-lingual transfer can be expected in a zero or few-shot setting. 6/n

1
2
10
A paper on the state of multilingual datasets - it's a harder problem than you'd think, and so much more work is needed!.
Does the data used for multilingual modeling really contain content in the languages it says it does? Short answer: sometimes 🙁 1/n.
0
0
10
@ankurbpn @orf_bnw @naveenariva @GoogleAI We find that encoder representations of different languages cluster according to linguistic similarity. 3/n

3
2
9
1
0
9

2
1
9
Watching this project evolve was fascinating - definitely read if you're interested in multitask learning 🎉.

Massively Multilingual NMT in the wild: 100+ languages, 1B+ parameters, trained using 25B+ examples. Check out our new paper for an in depth analysis: #GoogleAI.
0
0
8
Is it just me or is the worst part about transitioning from school to the industry getting around the fact that you're productive only at 10am and 10pm.
0
1
8
Where were you all my undergrad life.

This is really neat! You take a screenshot of an equation, it gives you the LaTeX code, you can directly modify in the taskbar, copy, paste, done.
0
0
8
@TaliaRinger No, go for it! For North Indian weddings you should be fine with either; for a South Indian wedding I'd err on the side on wearing a sari (ask the host!). If you want to wear a sari, book an appointment with a local salon to get someone to tie a sari for you it's less stressful.
0
0
7
An interesting resource for lightweight extremely multilingual LangID - how FUN!.
Have you ever wanted a LangID model that works on 1500+ languages? check out FUN-LangID: !.
0
0
7
Models in post+more: Multilingual NMT: Cross-lingual transfer: GPipe: .Transfer (self-plug 😉): .Adapters:
0
2
7
Me going over my Google Keep notes near the end of the week:.Note: Talk to xyz .Me: Who is xyz?. Note: Weekend.Me: Yes, it exists. Note: what isuseful?.Me: Not you, clearly. 🙄.
0
0
6
Oops.

therapist: and what do we do when we’re stressed about deadlines?.me: start a new research project?.therapist: no.
0
0
6
This is art.

OK y'all, it is now my pleasure to show off some of the truly, genuinely heinous plots students in my Reproducible Data Analysis class made. Content warning: these plots are f***ing awful.
0
0
6
My parents started out teaching me both Telugu and English, but prioritized the latter for far too long for similar reasons. I took Telugu class for ~8 years when we moved back to India, but it simply isn't the same.
0
0
6
There 8 copies of this paper lying around the nearest office printer already. 🤓.

XLNet: a new pretraining method for NLP that significantly improves upon BERT on 20 tasks (e.g., SQuAD, GLUE, RACE). arxiv: github (code + pretrained models): with Zhilin Yang, @ZihangDai, Yiming Yang, Jaime Carbonell, @rsalakhu
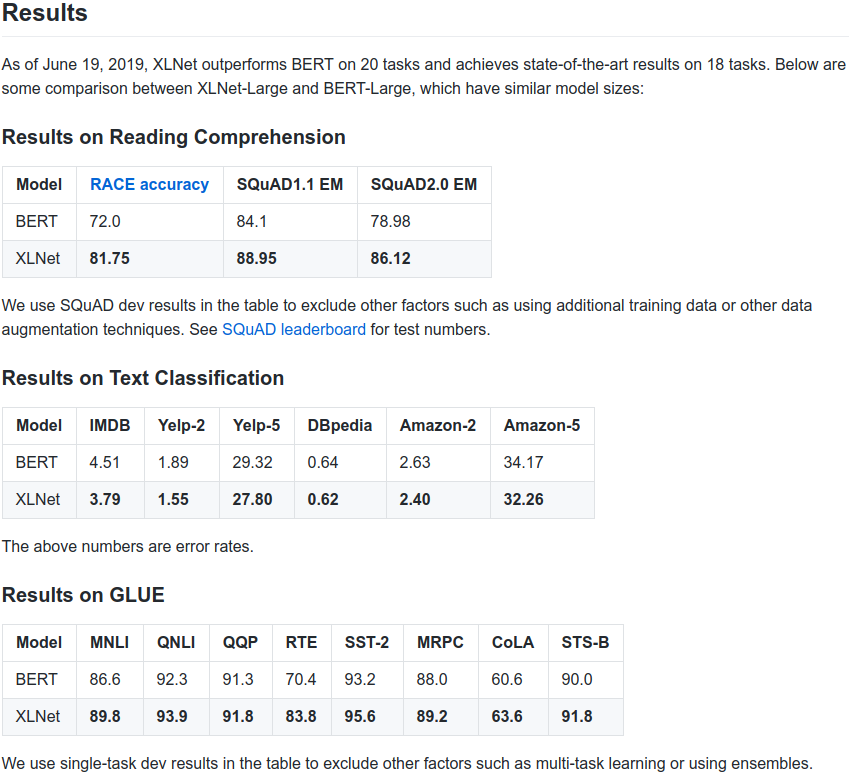
0
0
4
An absolutely OP resource 😺.
Just added 84 more languages to GATITOS! It now has a total of 113 languages, many of which with no other public resources 😊
0
0
5
Easily deploying large models is an important direction of research, and we believe TaskMoE is a promising step towards more inference friendly algorithms that retain the quality gains of scaling. 9/9.
0
0
5
@ankurbpn @orf_bnw @naveenariva @GoogleAI We look at how our similarity measure capturing linguistic similarity vs script. 5/n

1
1
5
*Adds to pile of things to tell myself when I feel a bout of imposter syndrome coming on*.

Sometimes the best experience is the one you’re wholly unqualified for.
1
0
4
Now that mindful AI is a thing, can we have AI mindfulness retreats?.

The focus on SOTA has caused a dramatic increase in the cost of AI, leading to environmental tolls and inclusiveness issues. We advocate research on efficiency in addition to accuracy (#greenai). Work w/ @JesseDodge @nlpnoah and @etzioni at @allen_ai .
1
0
4
@asiddhant1 @orf_bnw @ankurbpn You need to think bigger - we can't have AGI without modeling the Multiverse too 😤 👽🚀🌌.
0
0
4
- Write a novel or collection of short stories with women who both work on sciencey things and have an ok personal life. - Perform Standup. - Write/direct a film with women who both work on sciencey things and have an ok personal life. - Paint enough for an art exhibition.

I want to:. - Publish a fantasy novel.- Perform standup comedy.- Produce an animated film. What do you want to do that's outside of your traditional "career" trajectory?.
0
1
4
At inference time, we can extract sub-networks by discarding unused experts for each task. 5/n

1
1
3
This is good and this is important.

The Guardian is updating our style guide to accurately reflect the nature of the environmental crisis. “Climate change” —> “climate emergency, crisis or breakdown”. “Global warming” —> “global heating”. “Climate skeptic” —> “climate science denier”.
0
0
3
@scychan_brains @DeepMind @FelixHill84 @AndrewLampinen Congratulations Stephanie, super excited for you!!! 🎉🎊💃.
0
0
3
Finally, when scaling up to 200 language pairs, our 128-expert task-MoE (13B parameters) still performs competitively with a token-level counterpart, while improving the peak inference throughput by a factor of 2.6x. 8/n.
1
0
3
0
0
3
0
0
3
This sounds wonderful 😍.

Took a while (don't ask) but here they are: Notes from "Science of Deep Learning" class co-taught with @KonstDaskalakis now available: More coming soon (promise!). Feedback very welcome! Thanks to @andrew_ilyas for heroic effort on doing final revisions.
0
0
3
@archit_sharma97 @gamaga_ai Why can't you have a 100 tabs open like a civilized human being @archit_sharma97?.
0
0
3
Another significant advantage of TaskMoE is that we retain all the gains from scaling - our method is +2.1 BLEU on average across all languages vs distilling the TokenMoE to a student model with size comparable to the subnetwork extracted from TaskMoE. 7/n

1
1
3
@wellformedness Avoid common deficiencies in vegan diets by supplementing/carefully including specific foods in your diet .
0
0
3
🥳.

1/ Can we use model-based planning in behavior space rather than action space? DADS can discover skills without any rewards, which can later be composed zero-shot via planning in the behavior space for new tasks. Paper: Website:
0
0
3
So we route tokens according to broader categories (route by task boundaries vs route per token) - that is, every token of a language is routed to the same subnetwork. This enables the model to dedicate a fewer experts to a single task identity during training and inference.4/n

1
1
2
PS - Silliness aside, this is definitely something we should care about for the long term.
0
0
2
Yes, pls.

WE CAN FUCKING DO THIS.
0
0
2
I keep discovering things I wish I found during my undergrad. *sigh*.

I've made this cheat sheet and I think it's important. Most stats 101 tests are simple linear models - including "non-parametric" tests. It's so simple we should only teach regression. Avoid confusing students with a zoo of named tests. 1/n.
0
0
2
Mixture-of-Experts (or MoE) models are a great way to scale! Researchers have successfully scaled multilingual neural machine translation (MNMT) models up to 1 Trillion parameters and beyond. 2/n

1
1
2
1
0
2
I've been hoping @waitbutwhy would release one of these since @neuralink's tweet last week - this is going to be a delightful Saturday afternoon 🤓.

It's finally here: the full story on Neuralink. I knew the future would be nuts but this is a whole other level.

0
0
2