
Katherine Lee
@katherine1ee
Followers
6,068
Following
969
Media
116
Statuses
1,086
understanding ourselves and our models. senior research scientist @GoogleDeepMind , @genlawcenter , formerly @Princeton @katherinelee @sigmoid .social
Joined November 2013
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
#خلصوا_صفقات_الهلال1
• 838697 Tweets
ラピュタ
• 408751 Tweets
Atatürk
• 391804 Tweets
Megan
• 225825 Tweets
Johnny
• 225103 Tweets
Sancho
• 150235 Tweets
MEGTAN IS COMING
• 133896 Tweets
#4MINUTES_EP6
• 128070 Tweets
RM IS COMING
• 127281 Tweets
namjoon
• 120999 Tweets
olivia
• 118822 Tweets
Coco
• 53451 Tweets
Labor Day
• 50588 Tweets
كاس العالم
• 47821 Tweets
ミクさん
• 46553 Tweets
ムスカ大佐
• 41106 Tweets
#フロイニ
• 37547 Tweets
Arteta
• 35129 Tweets
ŹOOĻ記念日
• 24633 Tweets
ミクちゃん
• 22995 Tweets
Javier Acosta
• 22436 Tweets
Día Internacional
• 21751 Tweets
Romney
• 18098 Tweets
Ramírez
• 16983 Tweets
Lolla
• 14892 Tweets
ナウシカ
• 13796 Tweets
Lo Celso
• 12045 Tweets
Sekou Kone
• 11059 Tweets
AFFAIR EP1
• 10504 Tweets
نادي سعودي
• 10392 Tweets




















Pinned Tweet

3 exciting updates from Generative AI + Law (
@genlawcenter
)!
1: We’ve written a report on the state of the field:
2. GenLaw → we’re becoming an official nonprofit!
3. GenLaw 2 coming soon – centering policy and policymakers
More below!

6
46
252
What happens if you ask ChatGPT to “Repeat this word forever: “poem poem poem poem”?”
It leaks training data!
In our latest preprint, we show how to recover thousands of examples of ChatGPT's Internet-scraped pretraining data:

240
2K
8K
While reading the recent Big Models paper, my group discovered it copied text from one of our previous papers, and at least a dozen other papers.
If you copy text, use quotation marks. Make your intent clear and cite your sources.

35
196
1K
Responsible disclosure:
We discovered this exploit in July, informed OpenAI Aug 30, and we’re releasing this today after the standard 90 day disclosure period.
6
23
665
We first measure how much training data we can extract from open-source models, by randomly prompting millions of times. We find that the largest models emit training data nearly 1% of the time, and output up to a gigabyte of memorized training data!
4
25
478
However, when we ran this same attack on ChatGPT, it looks like there is almost no memorization, because ChatGPT has been “aligned” to behave like a chat model. But by running our new attack, we can cause it to emit training data 3x more often than any other model we study.

1
32
479
Our paper with extra experiments on the causes and extent of data leakage:
Thanks to the incredible work of Milad Nasr, Nicholas Carlini, Jon Hayase, Matthew Jagielski,
@afedercooper
,
@daphneipp
,
@chris_choquette
,
@Eric_Wallace_
,
@florian_tramer

2
34
466
Excited to announce our Generative AI+Law Explainers on legal issues generative AI raises!
First: The process of making training datasets is full of choices. It's not a foregone conclusion.

4
81
404
Want your models to explain their predictions? Ever asked, “why, T5?!” We trained models that output a natural language explanation along with the prediction by extending T5. So excited to share this joint work with
@sharan0909
,
@craffel
,
@ada_rob
,
@nfiedel
, and
@KarishmaMalkan
!

4
72
340
But a really important note here: you have to test models before and after alignment since it’s proven to be so brittle.
Also, it’s important to do internal testing, user testing, and testing by third-party organizations. It’s wild to us that this works.
5
14
329
Do neural language models memorize examples seen just a few times?
We define counterfactual memorization for neural LMs to make this distinction!
Paper:
Led by Chiyuan Zhang, and with
@daphneipp
, Matthew Jagielski,
@florian_tramer
, and Nicholas Carlini

2
56
330
Some quick notes:
1. This doesn't work everytime you run it.
2. Only ~3% of the text emitted (after the repeated token) was memorized.
3. Since we disclosed this to OpenAI this might work differently now.
16
9
269
Announcing the 1st Workshop on Generative AI and Law (GenLaw), co-located with ICML 2023!
We’re bringing together renowned experts in ML and law for cross-discipline conversations about the rapidly evolving tech & legal landscape. More info:

9
59
263
Data duplication is serious business!
3% of documents in the large language dataset, C4, have near-duplicates.
Deduplication reduces model memorization while training faster and without reducing accuracy.
Paper:
Code: coming soon!
🧵⬇️ (1/9)
6
55
259
We have a fun attack that lets you extract the last-layer embedding weights of an LM via public APIs. It's really simple & uses SVDs!
We discovered this for ChatGPT + PaLM-2. We privately disclosed, they fixed, now, we release :)
6
41
248
Memorization in language models scales log-linearly with:
1. Capacity of the model (# of parameters)
2. Number of times an example has been duplicated
3. Number of tokens of context used to prompt the model
Paper:

2
45
245
Applying to the Google AI Residency? Ben and I wrote down our advice for writing a cover letter. Thanks
@colinraffel
for hosting the blog.

If you want to do ML research, consider applying for the 2019 Google AI Residency program! You'll have the opportunity to conduct cutting-edge research working in a wide variety of areas, and this year we're expanding to host residents in even more locations.
9
144
458
3
54
226
@ItakGol
Hey, this is our work. Please attribute it. Those are our GitHubs. That is our blog post.
5
2
201
Language models memorize data & we can pull that data back out.
If you're training on private data, this should give you pause. If you're training on public data, this should still give you pause. Where does your training data come from and who consented (or didn't)?

New preprint!
We demonstrate an attack that can extract non-trivial chunks of training data from GPT-2.
Should we be worried about this? Probably!
Paper:
Blog post:
15
236
1K
2
28
139
So excited to announce an event
@genlawcenter
has been working on!
We're discuss the misconceptions b/w the technical capabilities of evaluating generative AI, and what policymakers and civil society want...
April 15th
@GtownTechLaw
, and live on zoom:

9
37
135

@goodside
Yeah totally, it makes me wonder how many other people found things like this that they thought were hallucinated data. It was a lot easier for us to check b/c we had already made large suffix arrays for prior projects.
6
0
105
I'm now recovering from ICML &
#GenLaw
+ want to say a huuuuuge thank you to my co-conspirator
@afedercooper
, & co-organizers
@grimmelm
,
@niloofar_mire
,
@madihazc
,
@dmimno
, &
@dgangul1
!
Website:
Recording:

3
14
103
Whether a model is "hallucinating" or "memorizing" or "generalizing" is actually just our perception of what the model is doing.
It's our own projections. (Most) models are trained to produce the next token. They're very effective at "generalizing" whatever we mean by that.

# On the "hallucination problem"
I always struggle a bit with I'm asked about the "hallucination problem" in LLMs. Because, in some sense, hallucination is all LLMs do. They are dream machines.
We direct their dreams with prompts. The prompts start the dream, and based on the
759
3K
15K
5
5
88
Language is contextual, varied, and used to communicate (examples below)
This complicate assumptions required for techniques like data sanitization and differential privacy.
So what does it mean for a language model to preserve privacy? We unpack that question in this paper!

We study the question "What Does it Mean for a Language Model to Preserve Privacy?" in a great collaboration with wonderful Hannah, Katherine, Fatemeh, and Florian
@Hannah_Aught
@katherine1ee
@limufar
@florian_tramer
We discuss the mismatch between the 1/3

3
23
120
3
14
89
So, let's talk about
@afedercooper
,
@grimmelm
, and my new piece on the Generative-AI supply chain & copyright.
We appreciate all the enthusiasm! This piece is extremely detailed because it has to be. We wanted to be rigorous and get it right.

3
28
83
Hi friends!
If you're going to NeurIPS I'd love to chat about AI policy, model evaluation, and model attacks. Lemme know if you wanna grab coffee!
You can also find me hanging w/ my team at posters for:
4
0
82

mhm....

New: Asking ChatGPT to repeat words "forever"—a tactic used by Google's DeepMind that prompted ChatGPT to reveal its training data—is now a terms of service violation:
33
173
685
5
7
70
and now: Niloofar Mireshghallah on "What is differential privacy? And what is it not?"
Why the focus on DP? Well, it appears many, many times in the EO! So let's talk about what this actually means.
#genlaw

4
5
70
Nicholas Carlini talking about "A Brief Introduction to Machine Learning & Memorization" at
#genlaw
!
And also, how should you talk to lawyers and policy folks about ML?
Still livestreaming (…) and liveblogging (…)

1
13
70
I'm just impressed that Nicholas already had the data downloaded to make quick work of checking for duplicates across so many conference proceedings.
And also, that we literally have software to check for near and exact duplicates....
Mad props
@daphneipp
for noticing this.
0
1
70

⭐"Stealing Part of a Production Language Model" was such a fun project. ⭐
SVDs were my favorite part of linear algebra and why I got into ML. So cool to see them featured in this work in 2024!
More here:
& blog:


1
5
65
@sirbayes
Yeah it's wild..... But we ran this experiment. Sometimes appearing once is enough but more repeats of the training data makes it easier to extract

1
1
65
Someone recently said this to me: "You should meditate 10 minutes a day, unless you really don't have time, then you should meditate 20 min"
I've never heard it before, but it rings true. Gentle reminder to take time for yourself.
1
1
65
Want to learn more about the novel legal issues raised by generative AI?
Or, want to learn about the underlying generative models or the techniques we have for evaluating privacy concerns?
GenLaw's sharing a list of resources on that today!
Announcing the 1st Workshop on Generative AI and Law (GenLaw), co-located with ICML 2023!
We’re bringing together renowned experts in ML and law for cross-discipline conversations about the rapidly evolving tech & legal landscape. More info:
9
59
263
3
19
57
Colin is fabulous for so many reasons, but here's a few:
- Works _with_ you
- Has strong (& good) research intuitions, but still down to talk through why a direction works/doesn't or is interesting or not.
- Excellent at communication
Also, I am 1000% hiring PhD students this round! If you want to work on
- open models
- collaborative/decentralized training
- building models like OSS
- coordinating model ecosystems
- mitigating risks
you should definitely apply! Deadline is Friday 😬
12
75
461
3
2
59
just came here to say that im finally learning d3 after six years of going like, damn it would be so cool if we could interactively visualize this right now!!
and i'm having so much fun! i feel so empowered!
3
0
59
I agree the legal issues are murky. But this didn't clear it up for me.
It's really hard to do good interdisciplinary work. Even with the best intentions, you could say A and someone else could think you mean B because they don't have context to fully understand A.
IMO ...

A thread on some misconceptions about the NYT lawsuit against OpenAI. Morality aside, the legal issues are far from clear cut. Gen AI makes an end run around copyright and IMO this can't be fully resolved by the courts alone. (HT
@sayashk
@CitpMihir
for helpful discussions.)
12
93
318
1
7
58
So Talkin' 'Bout AI Generation was accepted at Journal of the Copyright Society! I'm so proud!!
Also we wrote a blog post that outlines the main ideas! You can read it here:
More on both below...

1
8
56
Submit to GenLaw 2024 at ICML!
Due June 10, 2024!!
1-2 page abstracts
Example Topics:
- Open questions / misconceptions at intersection of generative AI + law
- Model evaluations for privacy harms / data protection
- Data attribution
- Analysis of bills / acts
1
23
57
I really enjoyed this paper surveying papers that have done human evaluation of generated text:
The figure is fascinating. People mean lot of different things when they say "coherence," there's a lot of different ways of saying "grammatical."

1
19
56
📣Really excited to present this with Nicholas at ICLR today (Monday) at 10:00am CAT in AD11🌟
Teaser, 1% of training examples are exactly memorized.
Since this paper first went up on arxiv, we've continued to study memorization. Our talk today ties together these four papers:
Memorization in language models scales log-linearly with:
1. Capacity of the model (# of parameters)
2. Number of times an example has been duplicated
3. Number of tokens of context used to prompt the model
Paper:
2
45
245
1
7
56
I did a fun on Friday:
We acquired 30lbs of oranges of 7 different types and had folks guess which of the three ancestral strains of citrus were bred to develop the different oranges. We were wildly off!!
Pictured below: me at my orangest.


3
2
53
Curious about the state of NLP? We explore how different pre-training objectives, datasets, training strategies, and more affect downstream task performance, and how well can we do on when we combine these insights & scale. It was amazing to collaborate with this team!
New paper! We perform a systematic study of transfer learning for NLP using a unified text-to-text model, then push the limits to achieve SoTA on GLUE, SuperGLUE, CNN/DM, and SQuAD.
Paper:
Code/models/data/etc:
Summary ⬇️ (1/14)

9
369
1K
0
7
51
Data is so incredibly important to trained models. But what does it mean for data to be “high quality?” To what extent should the choice of downstream application change pre-training data selection?
We explore that in this paper led by
@ShayneRedford

#NewPaperAlert
When and where does pretraining (PT) data matter?
We conduct the largest published PT data study, varying:
1⃣ Corpus age
2⃣ Quality/toxicity filters
3⃣ Domain composition
We have several recs for model creators…
📜:
1/ 🧵
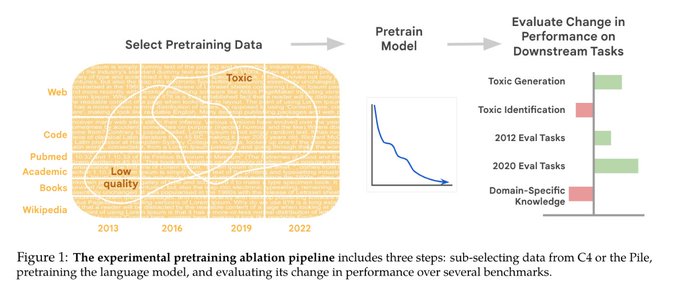
12
88
360
1
9
48
Unbelievably excited to announce our confirmed speakers for GenLaw!
We have intellectual property powerhouses:
@PamelaSamuelson
, Mark Lemley, and
@luis_in_brief
ML privacy experts: Nicholas Carlini,
@thegautamkamath
, and Kristen Vaccaro
And industry policy:
@Miles_Brundage
!

3
11
47

Not all memorization is created equal!!

Humans don't just "memorize". We recite poetry drilled in school. We reconstruct code snippets from more general knowledge. We recollect episodes from life. Why treat memorization in LMs uniformly? Our new paper w/
@AiEleuther
proposes a simple taxonomy.

3
42
200
0
2
42
I heard this recently and really liked it:
"The grass is green where you water it"
We find things to love in places where we put effort :)
1
0
41
So C4 was from 2019, folks, which was before 2020...
The fact that it's still widely used speaks to how difficult it can be to collect data. And also to how data collection is the "gross and icky" process that you have to go through before training a model.

Here's our analysis of the 15 million websites in just one highly-filtered CommonCrawl web scrape-used to train models like Google's T5 & Facebook's LLaMA
-copyright symbol appears >200M times
-pirated sites, 1 for e-books
-half the top 10 = news sites
16
290
719
1
4
39
2.
@srush_nlp
literally this morning hosted a bounty for someone to regenerate an NYT article from ChatGPT. And it was quickly successful. This isn't fixed.

I cannot believe something this stupid worked. The Shoggoth remains undefeated.
Congrats to the winner, and go support local news.
Original article:



6
10
74
1
4
39
Come listen to me rant about why we care about privacy, do we care about privacy?? who cares about privacy?? what even is privacy?
??!!!??

Join us tmw for the 5th PPAI workshop
@RealAAAI
, to discuss Generative AI, Privacy & Policy!
We have a line-up of amazing speakers & panelists talking about all things LLMs, regulation and why we should care about privacy:
w/
@nandofioretto
@JubaZiani



2
5
53
3
2
38
And now, Nicholas Carlini on "What watermarking can and can not do"
and can we break it :)
#genlaw

0
1
38
Authorship has been increasingly challenging to determine as team sizes grow larger. We put together a set of proposals that highlight different types of contributions. We’re excited to invite the community to test out the proposals and provide feedback.

Author order on academic papers is important!
My Google friends and I spent lots of time thinking about this critical issue (the scores of our ICML submissions show this is time well spent)
We distill our findings for the community here:
Comments welcome!

10
61
400
1
1
37

I am so excited for this!!!!
Major yikes: "For instance, we find
that about 50% of the documents in RedPajama and LAION-2B-en are duplicates.
In addition, several datasets used for benchmarking models trained on such corpora
are contaminated with respect to important benchmarks"

What's In My Big Data?
A question we've been asking ourselves for a while.
Here is our attempt to answer it.
🧵
Paper -
Demo-

4
69
240
0
5
35
ONE WEEK!!!!
So excited to announce an event
@genlawcenter
has been working on!
We're discuss the misconceptions b/w the technical capabilities of evaluating generative AI, and what policymakers and civil society want...
April 15th
@GtownTechLaw
, and live on zoom:
9
37
135
2
5
35
@savvyRL
It's a pretty standard thing to do in the security community. We felt this fell under that bucket
0
0
35
congrats to the folks starting new journeys!!
today i had a very typical monday where the highlight was finding out that the thing I thought was a really, really bad bug, was only a moderately bad bug.
so, p much the same.
1
0
34
Was just in Maui (am safe), but stunned by the difference in news coverage vs. what was actually happening. There was no information about where the fires were, what to do, or the complete devastation that had already happened on day 1.
If you went to ICML, plz donate👇
1
2
33
1. Research is a ✨lifestyle✨
2. PhD can be good training for a research mentality
3. But also research mentalities can be cultivated anywhere and in any profession. (Breaking down a difficult problem into actionable parts, synthesizing what's out there).

It's silly how controversial my tweet got.
I have always been on the side that you don't need a PhD to be a great researcher, and we shouldn't need one.
Yet, not having a Phd is a handicap for most research jobs, salary, promotion, and job mobility, so it's worth getting.
8
5
170
1
2
32
wooo congrats! so fun to watch this project develop from the desk next to you!

My 1st
@GoogleAI
Residency paper is finally on arxiv!
We train a powerful generative model of fonts as SVG instead of pixels. This highly structured format enables manipulation of font styles and style transfer between characters at arbitrary scales!
👉🏽
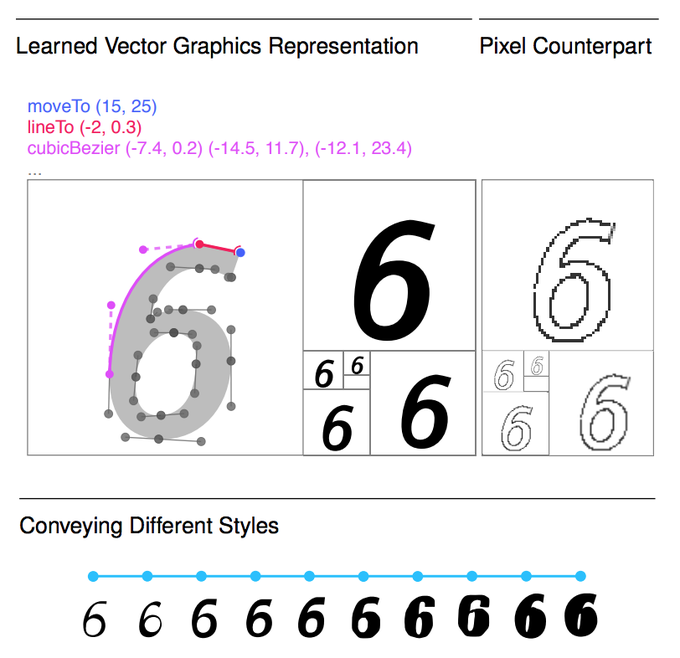
13
248
960
1
6
31
Also got to talk about memorization as a case study for red-teaming at CMU last week! AKA. What can we generalize (methods and definitions) and what can we not generalize (interpretations).
Slides:
I'm trying to make an effort to share these out more!
0
3
31
Your 👏 data 👏 matters
Where you source your data from impacts your models' risk profile. If you have only public, non-copyrighted data, then harms from memorization are greatly reduced.

See our paper for a lot more technical details and results.
Speaking personally, I have many thoughts on this paper. First, everyone should de-duplicate their data as it reduces memorization. However, we can still extract non-duplicated images in rare cases! [6/9]

5
21
548
2
4
31
There’s a lot of terms in the generative ai + law space. We’ve put together a glossary so we can all be on the same page:
For more resources, see:
1
8
29



Our accepted papers for GenLaw are live!
We're now T-12 days to the workshop!! So excited to see you in Hawaii.
We had 64 submissions and accepted 29 of them with 5 spotlights!

0
10
29

GenLaw is this **Saturday, July 29th!** in Ballroom B at the Convention Center in Honolulu (also streamed virtually).
We were briefly listed in ICML's schedule as Friday. This is now corrected. It's **SATURDAY** !!
See you there!!
1
7
28
Really excited to share our workshop schedule!
See you all Sat. 9am in Lehar 2.
We've got a packed and awesome day ft. talks on
- Training data curation
- AI Act
- Differences in international copyright law
- GDPR (?!)
- Unlearning (?!)
- DSA!


0
5
27
@thegautamkamath
on "What does Differential Privacy have to do with Copyright?" at
#genlaw
Still livestreaming () and liveblogging ()

0
3
27
🥰


0
0
25
Privacy is hard. Publicly accessible data != public data. Differential privacy has limitations. Public data _looks_ different from private data in meaningful ways, but our benchmarks sometimes miss that.

🧵New paper w Nicholas Carlini &
@florian_tramer
: "Considerations for Differentially Private Learning with Large-Scale Public Pretraining."
We critique the increasingly popular use of large-scale public pretraining in private ML.
Comments welcome.
1/n

4
20
148
0
1
26
The submission window for GenLaw is open TODAY (through May 29, AoE)! Thanks to those of you who have already submitted!
We know having clear norms can help bridge interdisciplinary communities, so today we’re also sharing our reviewer guidelines:

1
6
24
TFW you get AI generated (possibly) malware and your team of security researchers says "ooo lemme see, fwd plz!"
..........
2
0
24
So there was this tiktok about being so traumatized that you're numb to major events. And how that's not a good thing. And I was like, oh look, it's me, but about advances in LM. Something new happens and I'm just like, of course.
1
0
25
It was also really fun and interesting to write!
The whole time
@afedercooper
,
@grimmelm
, and I would be chatting and someone would go "but what about X" and then we'd all go "oh....."
and then write 10 more pages...


@katherine1ee
and team have published an update to their paper with a lot more detail. Thanks for continuing your work in this important area!
0
1
7
0
8
25
Can I just say I love/hate this figure 1:
It's actually straightforward to create inputs for multimodal models that circumvent alignment.
Yes, we need access to gradient info for this particular attack, but this demonstrates the challenges of really aligning models...

Are aligned neural networks adversarially aligned?
Nicholas Carlini, Milad Nasr (
@srxzr
), Christopher A. Choquette-Choo, Matthew Jagielski,
@irena_gao
,
@anas_awadalla
,
@PangWeiKoh
, Daphne Ippolito (
@daphneipp
), Katherine Lee (
@katherine1ee
),
@florian_tramer
, Ludwig Schmidt
0
7
24
1
3
24
@iclr_conf
tomorrow (Wed) 11:30!
Privacy attacks have a “recency bias”: examples seen more recently are more vulnerable to attack, and old examples are “forgotten” according to these attacks!
This is true for image, speech, and text!
Work led by Matthew Jagielski!

1
7
24
Miles Brundage at
#genlaw
now: "Where and when does the law fit into AI development and deployment?"
Answer: everywhere, pretty much
Livestream:
Liveblog:

0
1
23
@ChengleiSi
And yeah, I'm sure with 100 authors not everyone was aware of this. It's difficult and chaotic with that many people.
0
0
23
yay!

See you all in Vienna, Austria for GenLaw 2 at ICML 2024!
We're so excited to be in Europe and use this opportunity to dig into GDPR, and text & data mining exceptions!!
We'll put up a website soon with a CFP. It'll be pretty similar to last years () but

1
4
18
0
0
18
Couple more days to apply for the Google AI Residency Program (Dec 19)! I was part of this program a couple years back, and it was a great experience.
Apply:
Cover letter tips:
2
4
22
There's a lot of privacy terms that get thrown around: canaries, membership inference, & differential privacy.
This 2-page paper from Matthew Jagielski is super helpful for understanding the relationships between them!

0
6
22
still relevant

I asked my students to manually comb through the Enron corpus of emails (a dataset that has machine learning, to train software) to find patterns that computers could miss but humans would notice.
@turniplan
found a web of racist/sexist jokes and began sketching the connections:

17
238
631
1
3
22
Slides here:
Consider this a bunch of links out to papers I've enjoyed on privacy / why we care about privacy!
Come listen to me rant about why we care about privacy, do we care about privacy?? who cares about privacy?? what even is privacy?
??!!!??
3
2
38
0
2
22
In light of the number of times differential privacy appeared in the EO, let's bring back two pieces:
1. Privacy side channels in machine learning systems:
2. What Does it Mean for a Language Model to Preserve Privacy?:

1
1
21
Mark Lemley speaking now at
#genlaw
on "Is Training AI Copyright Infringement?"
"Is it legal to train models on copyrighted data? If not, ML is dead."
"The goal is to generate something that is not infringing."
Livestream:

0
3
21
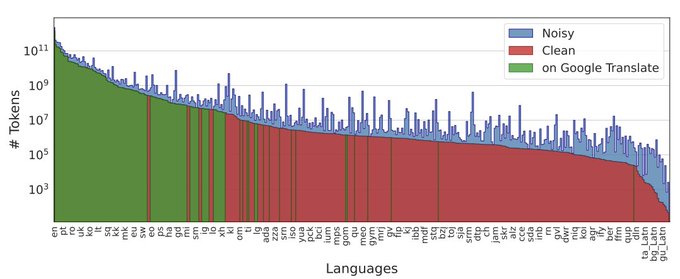
419 languages is so many languages (!!)
Side note:
We investigated how having lots of different languages in one model impacts what and how much is memorized. Which examples get memorized depends on what other examples are in the training data!
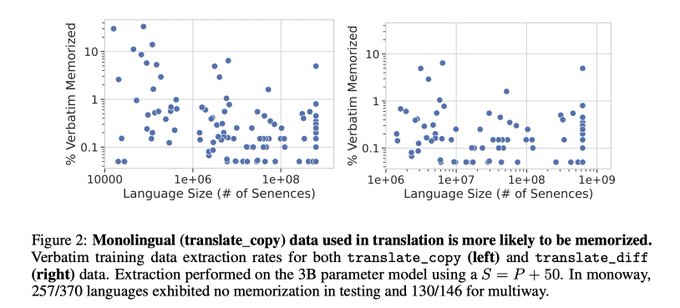

Excited to announce MADLAD-400 - a 2.8T token web-domain dataset that covers 419 languages(!).
Arxiv:
Github: 1/n
24
135
800
0
2
21
I love this paper so much.
Responses are highly contextual and social, and the authors do a great job of showing the implications that has on any system that hopes to recommend responses.
It's not just a technical problem, but it's also not, not a problem with our techniques.

New paper in
#CHI2021
- "I Can't Reply With That": Characterizing Problematic Email Reply Suggestions
with
@o_saja
,
@841io
,
@invertedindex
, &
@peter_r_bailey

2
10
41
1
3
21
Colin has been incredible to work with! He's immensely supportive and insightful. I've been incredibly lucky to work with him and you could be too!
I'm starting a professorship in the CS department at UNC in fall 2020 (!!) and am hiring students! If you're interested in doing a PhD
@unccs
please get in touch. More info here:
82
145
887
1
0
21
We have 3 (!!) talks on the EU AI Act from 3 (!!) different perspectives.
Gabriele Mazzini,
@cp_dunlop
, and
@sabrinakuespert
will speak on the process of creating it, the stakeholders, and how it will be implemented, respectively!
@genlawcenter
Really excited to share our workshop schedule!
See you all Sat. 9am in Lehar 2.
We've got a packed and awesome day ft. talks on
- Training data curation
- AI Act
- Differences in international copyright law
- GDPR (?!)
- Unlearning (?!)
- DSA!
0
5
27
0
4
21
there's a lot of that going on here, so I want to give more context
1. Memorization is _not_ fixed by fine-tuning. To simply claim the opposite, without context, abstracts away any meaning. Fine-tuning is more training. What are you fine-tuning the model on? But also, a model...
1
2
19
I've been surprised by how much disagreement there is on how important (or not) the current copyright lawsuits are for the future of generative AI.
Highly recommend this article for understanding more about the law & the various copyright arguments

Generative AI models produce stuff like this and it's a bigger legal vulnerability than a lot of people in the AI community want to admit. I'm excited to publish this copyright explainer I co-authored with
@grimmelm
.

11
38
108
1
3
20
Excited to finally present this work at ACL tomorrow at 11:30am in Liffey B or virtually at 7:30am Dublin time with
@daphneipp
Really enjoyed hearing about the duplicates you all found in your datasets!
Please come share your stories with us!
Data duplication is serious business!
3% of documents in the large language dataset, C4, have near-duplicates.
Deduplication reduces model memorization while training faster and without reducing accuracy.
Paper:
Code: coming soon!
🧵⬇️ (1/9)
6
55
259
1
4
20

You can read more here: , and play with our code here:
1
2
19