

Archit Sharma
@archit_sharma97
Followers
3,661
Following
343
Media
28
Statuses
262
Final-year CS PhD student @Stanford . Previously, AI Resident @Google Brain, undergraduate @IITKanpur , research intern @MILAMontreal .
Joined July 2015
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Alberto
• 477565 Tweets
Lawrence
• 145645 Tweets
Fabiola
• 129642 Tweets
shawn
• 93661 Tweets
Tamara
• 88967 Tweets
renjun
• 85336 Tweets
Marçal
• 69186 Tweets
Olivos
• 65930 Tweets
Tucker
• 58259 Tweets
#DebateNaBand
• 53905 Tweets
नीरज चोपड़ा
• 49488 Tweets
Rogan
• 46403 Tweets
Jerry
• 41571 Tweets
Nunes
• 36020 Tweets
Caresha
• 32892 Tweets
大蛇に嫁いだ娘
• 29795 Tweets
Datena
• 23207 Tweets
Comedor
• 21051 Tweets
नाग पंचमी
• 20988 Tweets
ハグの日
• 20333 Tweets
Tabata
• 18885 Tweets
Santana
• 17030 Tweets
Flor Peña
• 14211 Tweets
#يوم_Iلجمعه
• 14208 Tweets
#祝INI初ミリオンTHE_FRAME
• 14000 Tweets
花咲徳栄
• 13260 Tweets




















Ever wondered if the RL in RLHF is really needed? Worried that you might really need to understand how PPO works?
Worry no more, Direct Preference Optimization (DPO) allows you to fine-tune LMs directly from preferences via a simple classification loss, no RL required.
🧵 ->
16
132
785

🥺

It is only rarely that, after reading a research paper, I feel like giving the authors a standing ovation. But I felt that way after finishing Direct Preference Optimization (DPO) by
@rm_rafailov
@archit_sharma97
@ericmitchellai
@StefanoErmon
@chrmanning
and
@chelseabfinn
. This
91
805
5K
21
3
339
High-quality human feedback for RLHF is expensive 💰. AI feedback is emerging as a scalable alternative, but are we using AI feedback effectively?
Not yet; RLAIF improves perf *only* when LLMs are SFT'd on a weak teacher. Simple SFT on a strong teacher can outperform RLAIF! 🧵->

13
53
334
I cannot emphasize how good Mistral 7B is. It has been crushing some of the experiments I have been doing, makes such a huge difference in the fine-tuned performance. Kudos
@MistralAI
for creating and open-sourcing this model!

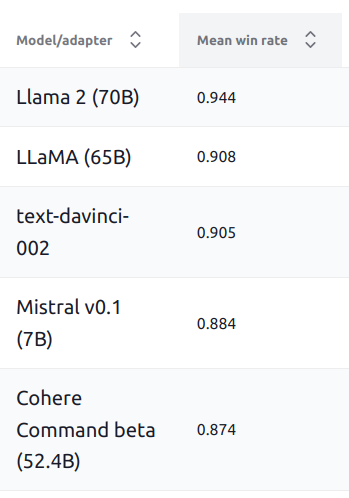
HELM v0.4.0 is out!
1) We have a new frontend (thanks to community contribution from Mike Lay).
2) We have added Mistral 7B, which really is punching above its weight (see ), rivaling models an order of magnitude larger on the 16 core scenarios:
7
43
275
7
28
227
Embodied agents such as humans and robots live in a continual non-episodic world. Why do we continue to develop RL algorithms in episodic settings? This discrepancy also presents a practical challenge -- algorithms rely on extrinsic interventions (often humans) to learn ..
1
31
197
This is the “right” way to interpret DPO, ie. setting Z(x) to 1 and removing the DoF.
But, I think the narrative of removing RL from RLHF has played its part, so I want to course-correct a bit this new year — is DPO still RL(HF), which requires answering, what is RL? 🧵->

DPO's method of removing RL from RLHF is so based
> previously "forced" to sample trajectories with RL bc direct optimization would require an intractable partition fn Z(x)
> observe that the bradley-terry model has a few extra degrees of freedom
> simply set Z(x)=1


7
22
277
3
15
179
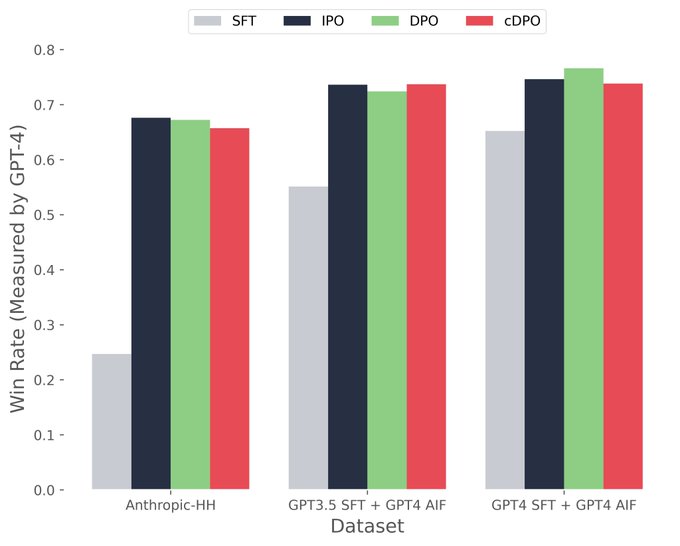
So, since we are posting science straight to twitter now,
@ericmitchellai
and I have some updates for potential overfitting in DPO.
TL;DR: we compared DPO to IPO and cDPO (DPO + label noise) on 3 different datasets, and we didn't observe any significant advantage (yet). 🧵->
7
33
175
I wrote an accessible post on why unsupervised learning is important for reinforcement learning and robotics, and how our work on DADS is improving skill discovery and making it feasible in real life. Check it out here!

Introducing DADS, a novel unsupervised
#ReinforcementLearning
algorithm for discovering task-agnostic skills, based on their predictability and diversity, that can be applied to learn a broad range of complex behaviors. Learn more at:
15
199
614
2
24
146
It feels hard to do robotics research these days. There seems to be this pressure to deliver "large scale" results to keep up with vision/language, to tie your results to the LLM bandwagon and ride the wave

LLMs have generally sucked the oxygen out of the room, but robotics seems to have been particularly impacted
Been meeting with robotics experts over the last few days, and the mood is gloomy to say the least
45
111
1K
4
7
118
If we want to build autonomous agents that can learn continually in the real-world, we have to build algorithms that can learn efficiently without relying on humans to intervene for resetting environments.
Introducing VaPRL - learn efficiently while minimally relying on resets!
4
25
108
What’s the difference? It’s still a lot cherry picking.

Has your neural net ever NaN’d so hard you thought about chucking your laptop in the trash and moving to British Columbia to be a tree planter instead?
20
22
392
3
9
102
Being able to learn continually without human interventions is critical for building autonomous embodied agents. Introducing MEDAL, an efficient algorithm to do so. Presenting tomorrow
@icmlconf
!
overview/arxiv/code:
w/ Rehaan Ahmad,
@chelseabfinn
1/

1
15
95
I am very excited about this line of work, lots of cool ideas seem to be possible with this simplification!
more details on arxiv:
code release soon!
a wonderful collaboration w/
@rm_rafailov
,
@ericmitchellai
,
@StefanoErmon
,
@chrmanning
,
@chelseabfinn

4
15
92
I am rather excited about this work for a couple reasons:
(1) We have a clear recipe for pre-training on offline data and fine-tuning language conditioned policies in the real world efficiently.
(2) We may be able to scale real robot datasets with minimal supervision...

Announcing RoboFuME🤖💨, a system for autonomous & efficient real-world robot learning that
1. pre-trains a VLM reward model and a multi-task RL policy from diverse off-the-shelf demo data;
2. runs RL fine-tuning online with the VLM reward model.
🔗
🧵↓
1
44
223
2
5
69
Breaking demonstrations into waypoints is a promising way to scale imitation learning methods to longer horizon tasks.
We figured out a way to extract waypoints from demos _without_ any additional supervision so that the robots can do cool stuff like make coffee ☕️->

Our robot can now make you coffee 🤖☕
A short 🧵 on how it works ⬇️
31
132
908
3
9
60
1/ Can we use model-based planning in behavior space rather than action space? DADS can discover skills without any rewards, which can later be composed zero-shot via planning in the behavior space for new tasks.
Paper:
Website:
1
9
47
@4evaBehindSOTA
You can also just do SFT on the preference dataset and then do DPO on the same prompts. The issue often is that the preference distribution is off-policy with respect to the reference distribution, and doing SFT on preference dist before DPO helps address that
2
4
48
This work was accepted to NeurIPS 2021 :)
Come checkout our poster “Autonomous Reinforcement Learning via Subgoal Curricula” on Dec 7, 8.30 am PT.
If we want to build autonomous agents that can learn continually in the real-world, we have to build algorithms that can learn efficiently without relying on humans to intervene for resetting environments.
Introducing VaPRL - learn efficiently while minimally relying on resets!
4
25
108
0
5
40
I will be in Atlanta for CoRL. Surprisingly, this is my first robotics conference ever 🤖! Looking forward to all the cool robot demos, and talking to people about scaling robot data collection, LLMs, and some of the work my collaborators and I are presenting 🧵
2
3
39
This is a reckless and a myopic decision. The stakeholders (us) were not consulted at all, and I do not condone this pivot.
In light of tremendous AI advances & recent calls for pauses on AGI research, I've decided to pivot our lab's direction.
Going forward, we’ll focus entirely on certain real-world applications (see thread 🧵 for details). It was a hard decision but I'm excited for our future work
44
76
1K
5
2
37
Just checked in to New Orleans for
#NeurIPS2023
, and this time i'm looking to settle the debate on the best beignets. Unrelated,
@rm_rafailov
@ericmitchellai
and I will be giving an oral presentation for DPO on Dec 14 3:50pm CT in Session Oral 6B RL, and poster on Dec 14 5pm CT.
Ever wondered if the RL in RLHF is really needed? Worried that you might really need to understand how PPO works?
Worry no more, Direct Preference Optimization (DPO) allows you to fine-tune LMs directly from preferences via a simple classification loss, no RL required.
🧵 ->
16
132
785
2
2
37
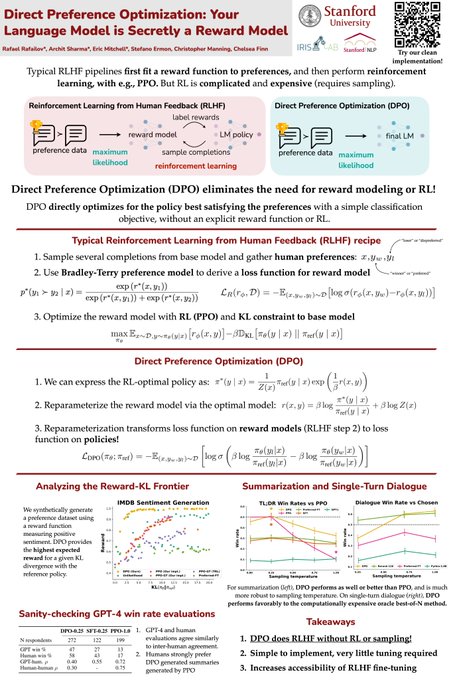
Go ask Eric all the hard questions about DPO, on how you can fine-tune LLMs on preference data without RL using a simple classification loss. Make him sweat and don't let him dodge any questions.

Curious how to take the RL out of RLHF?
Come check out our
#ICML2023
workshop poster for Direct Preference Optimization (aka, how to optimize the RLHF objective with a simple classification loss)!
Meeting Room 316 AB, 10am/12:20/2:45 Hawaii time
5
25
203
2
2
35
This isn’t a party trick! This derivation is principled, optimizing *exactly* the same objective used for RLHF. And it leads to a simple algorithm: Increase prob of pref. completions, and decrease prob of dispref. ones, but only on examples where the model is wrong!

1
1
34
Data processing inequality is often used to dismiss the possibility of self-improving LLMs. Here's a potential counter-argument:
LLMs can be seen as an ensemble of functions indexed by prompts. Every prompt (CoT etc) gives a diff subset of info in the LLM. (cont'd)
3
0
32
Bypassing RL isn’t just about mathematical aesthetics or performance; computational savings are huge too: no value function training, no explicit reward models, never need to sample the model during training.
2
1
31
Despite the simplicity, DPO can perform better than PPO. DPO summaries are preferred 58% over PPO summaries (human evals), 61% over human summs in test set (GPT4 evals). DPO single-turn responses are preferred ~60% on Anthropic HH over chosen completions in test set (GPT4 evals).



2
4
27
Happening in ~3 hours! Come find out how all these instruction following models are trained:

Just checked in to New Orleans for
#NeurIPS2023
, and this time i'm looking to settle the debate on the best beignets. Unrelated,
@rm_rafailov
@ericmitchellai
and I will be giving an oral presentation for DPO on Dec 14 3:50pm CT in Session Oral 6B RL, and poster on Dec 14 5pm CT.
2
2
37
0
2
26
There isn’t a lot of robot data to train on. Human collected demonstrations are important ✅ but the collection does not scale ❌. What if the robots could collect data autonomously? Checkout my post on steps and challenges towards 100x-ing robot learning data in the real world:

Human-supervised demonstration data is hard to collect for embodied agents in the real world. Learn how we can enable robots to autonomously learn in the real world for 100x larger datasets in
@archit_sharma97
's blog post! 🤖
0
7
25
1
4
24
Also fwiw, I wanted to title the post “Leave your agents unsupervised with DADS”. But I guess the editors do not like dads jokes ... strange for an org with
@JeffDean
at its fore.
0
0
23
Can language models search in context? Turns out that explicitly training on search data and fine-tuning with *reinforcement learning* can substantially improve the ability of the model to search. Check out this work led by
@gandhikanishk
!

Language models struggle to search, not due to an architecture problem, but a data one! They rarely see how to search or backtrack. We show how LLMs can be taught to search by representing the process of search in language as a flattened string, a stream of search (SoS)!
7
113
581
0
0
22
We are moving unsupervised learning to real-world robotics! In our new work, we present off-DADS which enables sample-efficient skill discovery on real robots without any rewards.
paper:
overview:
website:
1
0
21
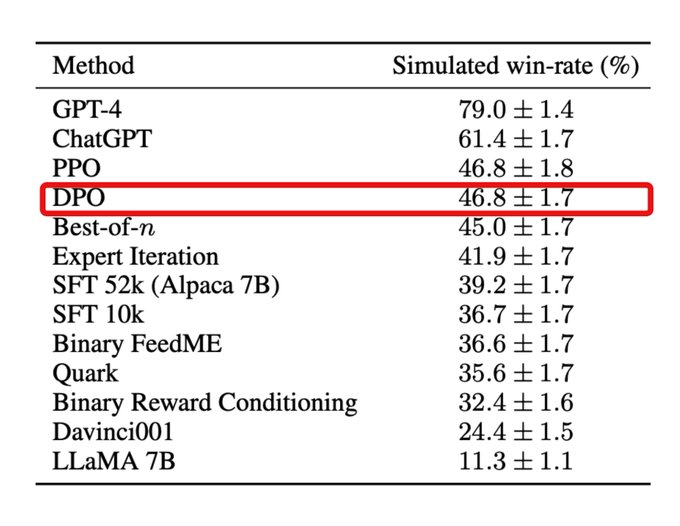
Some explicit evidence comparing DPO vs PPO :) My bias rn is that given tuned implementations for PPO and DPO and "right" preference datasets, DPO should be sufficiently performant. It would be good to find situations where PPO's computational complexity is justified over DPO.

Belatedly, I finally had a chance to update the AlpacaFarm paper with DPO results.
TL;DR: DPO performs similarly to RLHF+PPO but is much more memory-friendly. Previously, PPO fine-tuning took ~2 hours on 8 A100 GPUs. Our DPO runs take about the same time on 4 GPUs. DPO with LoRA
4
28
236
1
1
20
How? The key idea is that language models can ALREADY be used as reward models (see below). The binary cross-entropy loss function used for fitting a reward model to preference data can now be used to fine-tune the language models directly!

1
3
20
Our bandit experiments suggest the following hypothesis: when the student model is much weaker than the teacher, the student generations are *not* sufficiently exploratory -- we just don't sample high-reward completions! In such a case, simple SFT would just outperform RL.

1
1
18
What if we want to change a LLM’s behavior using high-level verbal feedback like “can you use less comments when generating python code”? Check out our work on RLVF led by
@at_code_wizard
on how to fine-tune LLMs on such feedback without **overgeneralizing**!

[1/6] Excited to share “RLVF: Learning from Verbal Feedback without Overgeneralization”
Our method C3PO fine-tunes an LLM from 1 sentence of feedback and decreases overgeneralization (=applying the feedback when it should not be applied).
Details:
2
19
91
1
2
17
Our paper provides a formal problem, and analyzes the failure of current algorithms on it: . Interestingly, we also find that autonomous agents can be more "robust".
EARL is open-sourced!
Git:
Website:

2
5
18
Have people tried encrypting their benchmarks?
download -> decrypt -> evaluate
This should quell any perf boosts from benchmarks leaking into training data, as long as LLM providers are not *intentionally* doping their models
ofc till AGI makes encryption meaningless

Academic benchmarks are losing their potency. Moving forward, there’re 3 types of LLM evaluations that matter:
1. Privately held test set but publicly reported scores, by a trusted 3rd party who doesn’t have their own LLM to promote.
@scale_AI
’s latest GSM1k is a great example.
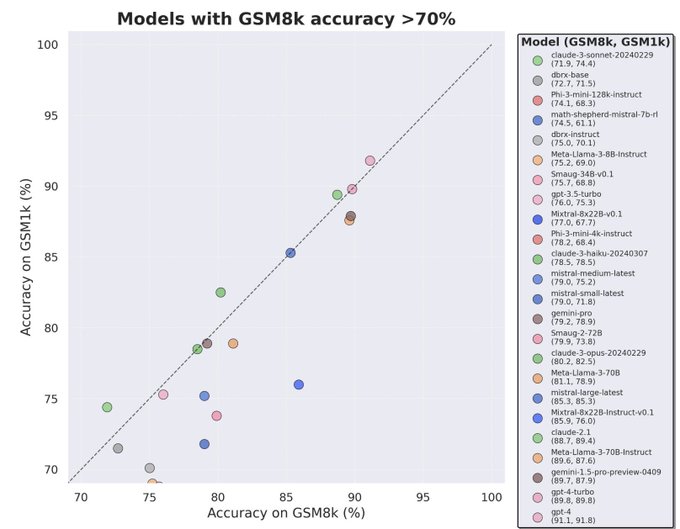
41
157
881
5
1
19
We introduce "Autonomous Reinforcement Learning", a problem setting representative of the continual non-episodic nature of the real-world. The agents learn autonomously, with humans intervening only occasionally (potentially never) throughout the lifetime.

1
3
16
What if we use strong teachers like GPT-4 for SFT? Not only does it outperform RLAIF (as above), but also further improvements become minimal, if any, as shown in the plot below.

2
1
16
friends, please don’t try to write > 16 first author papers, you are wasting your and everybody else’s time
1
1
16
@Teknium1
@huggingface
Nice set of experiments! I think the range of betas for IPO needs to be much smaller for better performance.
For KTO, has anyone run an experiment with unpaired preferences? It is generally pretty hard, so would be quite cool to see some progress on that
3
1
16
@mblondel_ml
1/ My tweet simplifies the discussion; our main contribution is that the OG RLHF prob statement can be solved exactly with supervised learning, when viewed from a weighted regression POV. Our derivation yields a principled choice for ranking loss (amongst many possible ones).
2
0
16
Sasha is really setting the standard for research videos!
Check out the DROID dataset — robot learning has been missing data collection in diverse natural scenes!

🧵[2/9] If you wanna learn about DROID the fun way, here’s a video explaining what the heck is going on. Otherwise, keep on scrolling!
3
1
49
1
1
16
A lot of popular datasets like ShareGPT, UltraChat, Alpaca etc are constructed using GPT-3.5, however AI feedback is collected using stronger models like GPT-4. This *exact* discrepancy allows RLAIF to substantially improve upon SFT for a variety of models: Llama, Yi, Mistral etc
1
0
15
Progress is hard, requires less sexy, small scale results. There's little attention leftover for these results, and even that is split as there is little consensus on how to make any progress: sim, real, online, offline, imitation, RL, model-based/free, we keep splitting hair
2
1
15
@ericmitchellai
If someone wants an exp to go along with this, I ran something which seemed to indicate that this might be helpful, notice how adding the noise (orange curve) regularizes the DPO margin and DPO reward acc to be reasonable. For this exp, win rate w/o and w/ noise was 20% and 45%.

1
2
13
This is a great talk! My research these days is very much motivated by moving towards truly autonomous agents. Check it out if you are interested in building generally capable agents for the real world.

I'm posting my talk from the deep RL workshop here for anyone who didn't catch it:
The Case for Real-World Reinforcement Learning
Or: Why Robinson Crusoe didn't need to be good at chess
in the hopes we can all keep it real when it comes to RL
9
75
481
0
0
12
Sometimes I wonder what it would have been like to talk to von neumann. I'm glad I can hear
@jacobcollier
play music to get a sense what it would have been like:

2
0
12
This was an interesting project; we started off trying to understand why AI feedback is *effective*. We experimented a bit more carefully, and found that maybe we are not doing this effectively (**yet!**). This just means more work to do, the journey continues 🦾🦾!
1
0
12
For HH, we run DPO for 1 epoch and 2 epochs on AI feedback datasets (prev works like Zephyr have also found more DPO epochs helpful on synthetic datasets). DPO likely overfits on large datasets, and IPO/cDPO *might* help. But, we don’t have any datasets to test this on.
1
0
12
A gentle reminder for ML / RL folks:
Continuous probability distributions can take values > 1! Unless I’m missing something, I don’t see why the (continuous) action distribution or stochastic dynamics should map to [0,1] (esp when it’s assumed to be normally distributed)
1
1
12
Based on these results, it isn’t clear if these methods provide substantial advantage over DPO, though we need bigger datasets. The performance degrades for all these methods if you keep training, and early stopping may already be sufficiently regularizing DPO.
1
0
11
Besides my little fanboy moment and this incessant desire to get this joke out and feed tpot zeitgeist, it was a fun and enlightening discussion :)
0
0
12
with the amazing team:
@sedrickkeh2
,
@ericmitchellai
,
@chelseabfinn
,
@karora4u
,
@tkollar
!
the full paper:
the code:

1
3
12
Episode horizons are typically 200-1000 steps. Naively increasing the episode horizon (to reduce extrinsic interventions) does not work for current RL algorithms, as the performance depreciates drastically:

1
0
12
DPO is still a RL problem IMO as (1) it optimizes for a blackbox objective of human preferences and (2) the data for labeling preferences is generated by LLMs (a question that has received far less attention than it should)
2
0
11
We spent most of our compute tuning IPO/cDPO:
- clip the IPO gradients, the norm of the gradients can be enormous.
- the beta / margin hyperparameter needs to be much lower for IPO (0.005 vs 0.05 for DPO)
- cDPO: can approximate IPO, if uncertainty and beta are set correctly!
1
0
10
Autonomous RL is a hard problem -- we introduce EARL (Environments for Autonomous RL) along with two evaluation schemes (deployed and continuing evaluation) to benchmark current algorithms and to aid the development of future ones (hopefully more suitable for the real world).

1
0
11
Paper:
website:
shoutout to my amazing collaborators:
@abhishekunique7
,
@svlevine
,
@hausman_k
,
@chelseabfinn

1
1
11
fwiw, I am quite excited about some of the things I am involved in! The outlook feels dim, fear of getting sucked into the doom of oblivion. But, current research seems to be driven mostly by beliefs and curiosity, not so much by attention/impact/progress (which is good??)
1
0
10
Try out our simple, principled supervised learning recipe for learning from preference data:
DPO (fast, simple, performant RLHF) code is here!
With DPO there's 𝗻𝗼 𝗿𝗲𝘄𝗮𝗿𝗱 𝗺𝗼𝗱𝗲𝗹 𝗼𝗿 𝗥𝗟 𝗻𝗲𝗲𝗱𝗲𝗱.
It's finally easy to fine-tune llama from human preferences 😊
Can't wait to see the cool models people train with it 🤓
7
81
405
0
1
11
@scottniekum
If you are still troubled about this question in a few days, we will have a paper soon that you might like :)
1
0
11
@sherjilozair
@natolambert
@finbarrtimbers
As an example, PPO and various actor-critic algorithms can be understood to minimize a reverse KL divergence, whereas weighted regression methods often imply a forward KL divergence. This has implications for mode-covering / collapse.
0
0
11
First, the methods
DPO: Direct preference optimization
IPO: Modifies the DPO loss such that policies are optimized upto a certain margin (and not optimized beyond that)
cDPO: conservative DPO, where preference labels are assumed to have some uncertainty (related to label noise)
1
0
9
vaguely reminds me of the quote: everyone knew it was impossible, until a fool who didn’t know came along and did it.
1
0
10
Had a fun time talking with
@kanjun
and
@joshalbrecht
!! Check it out for some in-depth overview of why autonomous agents are important, what the challenges are in building them and some (spicy? lukewarm?) takes about ML research and ecosystem

Learn about agents that can figure out what to do in unseen situations without human help with
@archit_sharma97
from Stanford!
0
1
7
0
2
10
Our work was accepted to
#RSS2020
!
I’m really excited for the future of unsupervised learning for robotics.
We are moving unsupervised learning to real-world robotics! In our new work, we present off-DADS which enables sample-efficient skill discovery on real robots without any rewards.
paper:
overview:
website:
1
0
21
1
0
10
Persistent RL (aka reset-free RL) is a relatively understudied problem and this opens up several questions about when/why do we need resets, how should we explore...Overall, I am pretty excited about building algorithms that learn with more autonomy!
1
0
10
This is slightly strange, why would this happen? Note, we collect training preferences using GPT-4 and then evaluate models using GPT-4 with the *exact same prompt template*. Why would SFT outperform RL in such a setup, given that the RL training is closer to evaluation?
1
0
9
I have been thinking about how people allocate blame when they encounter a problem. I’ll take an example: TurboTax et al consistently lobbying to keep tax filing complicated.
The dominant narrative is that this is an inevitable consequence of unfettered capitalism, maybe true.
3
1
9
We tried these methods on 3 datasets, Anthropic HH and 2 GPT-4 annotated preference datasets. All results use Mistral 7B, SFT’d and then preference fine-tuned. The win rate compares the output of two models and asks GPT-4 which one is better.
2
0
8
The high idea level is to create a curriculum of increasingly harder tasks such that the agent can leverage prior experience solving simpler tasks for harder ones, learning the behaviors we care about in the process. All this, done without assuming arbitrary access to resets!
1
0
8
@teortaxesTex
This paper flew under the radar. Some of the points they are making seem pretty nice (lack of effectiveness of KL reg for finite data). But, I am surprised by their claim that DPO overfits while conventional reward models underfit -- this claim seems central but unsubstantiated
0
2
8
@yingfan_bot
Great question, something we are in the process of understanding as well. It's important to note that you can continue to use the language model as a reward model, and we have no reason to believe that it will generalize worse.
1
0
8
I am not subtweeting anyone here, there indeed has been impressive progress on large scale robotics/LLM front. But, there are issues on every level if we want to reach any level of generality for robotics: hardware/perception, algorithms, data
1
0
7
RL is overloaded as a term, we use it to talk about the “problem” (maximize expected sum of rewards) and the “algorithms” (PPO, SAC etc). When saying DPO removes RL from RLHF, it’s the latter that is implied.
(the overloading of the RL term is discussed in Sutton/Barto)
1
0
7
LLMs can self-improve by using "info accessible via prompt p1" to improve the "function indexed by prompt p2", *without* violating DPI.
1
0
7
The definition above may have edge cases, for example, offline RL (CQL etc) might seem to disobey (2), but offline RL becomes interesting when we start including suboptimal autonomous data. I can think of more, but curious to hear if this disambiguation makes sense.
0
0
7
@abacaj
Two things:
(1) try early stopping, potentially even before an epoch
(2) try doing SFT on preferred completions before doing DPO (or SFT on both preferred and dispreferred)
1
0
7
@generatorman_ai
That’s a great question! We have evaluations on Anthropic HH dataset (only single-turn dialogue). However, the questions around diversity of generations are still valuable and interesting to understand.
0
0
7
VaPRL healthily outperforms other reset-free RL methods on several tasks. The surprising observation here is that VaPRL can match or even outperform the oracle RL, a method that trains in the episodic setting with arbitrary access to resets! (needing almost 1000x more resets)

1
0
6
As usual, this work would not have been possible without my amazing collaborators:
@imkelvinxu
, N. Sardana,
@abhishekunique7
,
@hausman_k
,
@svlevine
,
@chelseabfinn
.
1
0
6
@teortaxesTex
@ericmitchellai
@yacineMTB
@erhartford
@Teknium1
@ethayarajh
@natolambert
@abacaj
@arankomatsuzaki
@_lewtun
@AnthropicAI
@akbirthko
@thomasahle
@cohere
@tszzl
@rasbt
@ClementDelangue
@Thom_Wolf
@main_horse
@4evaBehindSOTA
Eric and I have discussed this several times, feel free to checkout the experiment snapshot I posted in the comments :)
1
0
6
10 different pieces need to fit together to get robotics right, and there are 10 different ways to do each. The road ahead seems so long. I would love to be proven wrong but I don't see an ImageNet/GPT moment for robotics. And to what end either (see financials in QT)?
1
0
6
let me just casually play 5 different rhythms on each finger, how is this legal good sir
0
0
6
@Teknium1
@huggingface
Oh implementation wise it is fine, I haven’t seen a model improve meaningfully from *just* unpaired data. I’d love to see some experiments!
2
0
6
@Teknium1
In all seriousness, if you have preference data, DPO fine-tuning runs are a miniscule fraction of pre-training costs. So, I would just send it. But, do some SFT first :)
1
0
6
@VAribandi
@4evaBehindSOTA
Yeah, this balance is tricky. I am not aware of controlled experiments for this, but usually I do only 1 epoch of SFT on preferred data.
0
0
6
@norabelrose
There is a fair amount of bias against change from what I have gathered re: DPO vs RLHF in places that started aligning their models pre-DPO. But, this is good for newer places, they can build their alignment pipelines off of DPO :)
0
0
6
@teortaxesTex
@Teknium1
I am generally critical of this practice of using AI feedback indiscriminately (esp when the feedback is from the same model you are evaluating under), but the paper's algorithmic improvements seem nice and meaningful -- someone should try it on some real RLHF settings
1
0
6
@lucy_x_shi
did an incredible job leading the experiments. Look out for her PhD app this cycle, you don't want to miss it!
And ofc,
@tonyzzhao
created this surprisingly easy and effective bi-arm setup, which allowed us to go from simulation to real-robot results in < 1 week!
0
0
5
“Uncertainty about the world doesn’t imply uncertainty about the best course of action!” -
@slatestarcodex

1
0
5
@sherjilozair
@natolambert
@finbarrtimbers
Generally agree with the sentiment in this thread, but Q-learning, actor-critic and weighted regression methods have differences in efficiency and optima you reach for finite sample + FA. I wouldn't rule out their being meaningful differences for LLMs between method classes.
1
0
5
I am not trying to start a capitalism v communism debate, but how we assign blame leads to different soln: one blame allocation leads to more regulation, the other leads to less lobbying. (To be fair, more regulation camp is generally less lobbying too)
2
0
5