

Stephanie Chan
@scychan_brains
Followers
3,633
Following
2,008
Media
23
Statuses
531
Staff Research Scientist at Google DeepMind. Artificial & biological brains 🤖 🧠 Views are my own
San Francisco, CA
Joined November 2018
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
#湊あくあ卒業ライブ
• 706228 Tweets
taeil
• 643164 Tweets
ホロライブ
• 195917 Tweets
あくあ色
• 152563 Tweets
Aqua
• 75750 Tweets
伝説のアイドル
• 52418 Tweets
#TaraftarİstifaBekliyor
• 48279 Tweets
BBドバイ
• 42157 Tweets
最高のアイドル
• 35766 Tweets
#笑コラ朝まで同期卍会
• 32272 Tweets
たんのこと
• 26859 Tweets
最高のライブ
• 24126 Tweets
スタテン
• 19692 Tweets
あくたん6年間
• 18999 Tweets
#あついトキメキをあなたに
• 16313 Tweets
西鉄バス
• 13524 Tweets
テイルさん
• 12793 Tweets
#いれいすライブレポ
• 12192 Tweets
オースティン
• 10995 Tweets
おつあくあ
• 10885 Tweets
サイヤ人級
• 10327 Tweets




















Pinned Tweet

Come check out our work at ICML this week:
🔎 What needs to go right for an induction head? A mechanistic study of in-context learning circuits (spotlight Weds)
✨ Many-Shot In-Context Learning (oral @ LCFM workshop)
🧞 Genie: Generative Interactive Environments (oral Tues)
2
5
37
Intriguingly, transformers can achieve few-shot learning (FSL) without being explicitly trained for it.
Very excited to share our new work, showing that FSL emerges in transformers only when the training data is distributed in particular ways!
🧵👇
14
189
1K
New paper 🥳: Transformer inductive biases!
Transformers generalize differently from information stored in:
‣ weights - mostly "rule-based"
‣ context - mostly "exemplar-based"
This effect depends on (a) the training data (b) the size of the transformer
🧵⬇️
3
86
614
We all know that in-context learning emerges in transformers... but our new work shows that it can actually then disappear, after long training times!
We dive into this **transience** phenomenon. 🧵👇1/N

7
94
476
First day at
@DeepMind
tomorrow!! Incredibly excited to be working with
@FelixHill84
, Stephen Clark,
@AndrewLampinen
, and many other amazing researchers!!
13
4
283
This is one of the most meaningful projects I've ever worked on -- aiming to make personalized tutoring universally available. We can use AI to augment human potential and human capital, if we do it responsibly and inclusively, with best practices from education.Still lots to do!


5
25
197
Now on Arxiv -- Google DeepMind's current approach on AI for education:
Also:
* the LearnLM team is hiring! (mostly likely for London)
* Markus Kunesch will be at the GDM booth at ICLR 4pm on Tuesday to answer questions
7
22
174
A beautiful story about winding paths and being guided by the poetry in nature -- made me smile ❤️
"He Dropped Out to Become a Poet. Now He’s Won a Fields Medal."
2
17
147
This is an incredible result. Transformers can meta-learn to do RL, completely from context -- no weight updates.

In our new work - Algorithm Distillation - we show that transformers can improve themselves autonomously through trial and error without ever updating their weights.
No prompting, no finetuning. A single transformer collects its own data and maximizes rewards on new tasks.
1/N
24
249
1K
2
14
122
Pretty paradigm-shifting if this data is replicable.. dopamine doesn't seem to encode reward prediction errors, after all! Open question what it does, in that case..
1
17
105
Apparent progress in ML research doesn't always map to real progress - it often isn't generalizable, usable or meaningful.
Tomorrow at the ML Evaluation Workshop
@iclr_conf
, join our many distinguished speakers in discussing and improving this situation!

The field of ML has seen massive growth and it is becoming apparent it may be in need of self-reflection to ensure that efforts are directed towards real progress. To this end, we are organizing an
@iclr_conf
workshop on "ML Evaluation Standards". [1/N]

1
101
437
3
21
89
We've released the codebase for the paper "Data Distributional Properties Drive Emergent In-Context Learning in Transformers" 🥳

Intriguingly, transformers can achieve few-shot learning (FSL) without being explicitly trained for it.
Very excited to share our new work, showing that FSL emerges in transformers only when the training data is distributed in particular ways!
🧵👇
14
189
1K
2
14
80
Why do transformers work so well?
@FelixHill84
explains how the architectural features of transformers correspond to features of language!
Alternatively check out his excellent lecture covering similar topics:

1
10
72
Inspired by
@AnthropicAI
's Constitutional AI, I've been thinking of another legal metaphor: "AI alignment as common law"🧑⚖️
Models are trained to be consistent with prior decisions — prev examples of good behavior (SL) or prev judgments of good/bad (RLHF) — i.e. "precedent"
1/
6
8
69
Virtual coding interviews!! Some people have asked for tips, since I happened to do a LOT of them last year 🤣 and developed or gathered some helpful tips and strategies. Some of these were kindly shared by others, so I'm passing it forward here! (thread)
2
10
70
Our new paper delves into the circuits and training dynamics of transformer in-context learning (ICL) 🥳
Key highlights include
1️⃣ A new opensourced JAX toolkit that enables causal manipulations throughout training
2️⃣ The toolkit allowed us to "clamp" different subcircuits to

In-context learning (ICL) circuits emerge in a phase change...
Excited for our new work "What needs to go right for an induction head (IH)?" We present "clamping", a method to causally intervene on dynamics, and use it to shed light on IH diversity + formation.
Read on 🔎⏬
2
44
198
1
10
66
Tokenization really matters for number representation!
E.g. tokenizing numbers right-to-left (instead of left-to-right) improves GPT-4 arithmetic performance from 84% to 99%!!
Awesome important work by
@Aaditya6284
@djstrouse
Ever wondered how your LLM splits numbers into tokens? and how that might affect performance? Check out this cool project I did with
@djstrouse
: Tokenization counts: the impact of tokenization on arithmetic in frontier LLMs.
Read on 🔎⏬
10
33
181
0
9
67
This work was done with the amazing Ishita Dasgupta, Junkyung Kim,
@dharshsky
,
@AndrewLampinen
,
@FelixHill84
📜 Paper:
Curious to hear your thoughts on possible origins of these biases, and their practical consequences!
(6/)

7
5
62
Impressive results by LLMs on causal reasoning benchmarks!
I'm curious though how much this is driven by the LLMs' priors about what causal structures are reasonable (e.g. ), rather than causal reasoning per se. 1/

New paper: On the unreasonable effectiveness of LLMs for causal inference.
GPT4 achieves new SoTA on a wide range of causal tasks: graph discovery (97%, 13 pts gain), counterfactual reasoning (92%, 20 pts gain) & actual causality.
How is this possible?🧵
33
296
1K
2
8
58
Turns out -- a feature is represented more strongly based on factors beyond its relevance to the training task. E.g. whether it's easy vs hard to compute, or learned early vs late in training. This is true even when comparing features that are learned equally well!
These biases

How well can we understand an LLM by interpreting its representations? What can we learn by comparing brain and model representations? Our new paper highlights intriguing biases in learned feature representations that make interpreting them more challenging! 1/

7
51
324
0
5
58
Incredibly exciting and important news. This is the first time in my LIFE that I've been the first Stephanie Chan on any platform!!! 🥇 😄

0
3
57
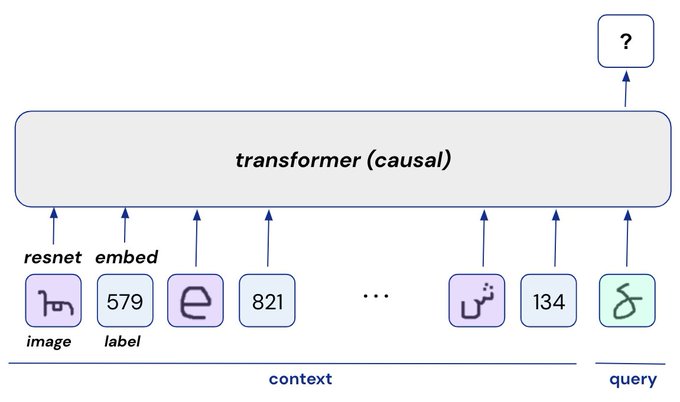
With long contexts of up to a million tokens, we can now move from few-shot to *many-shot learning*
By using 100s or 1000s of shots, we saw significant improvements on math, reasoning, QA, planning, etc. We may not even need labels in many cases!! 🤯

We studied In-Context learning with hundreds to thousands of examples.
My favorite example: I sent *one million* tokens to Gemini 1.5 Pro for linear classification with 64 dimensional integer-valued vectors and many-shot learning performs similarly to k-Nearest Neighbours.

6
25
165
3
8
55
Come check out our NeurIPS poster today, on hierarchical memory for RL agents!
Interested in how RL agents could recall the past in detail, in order to overcome the challenges of the present? Come chat with us about "Towards mental time travel: A hierarchical memory for RL agents" at
#NeurIPS2021
poster session 1 (4:30 GMT/8:30 PT, spot E1)!

4
31
195
0
4
50
3/ But while certain data distributions could elicit FSL in transformers, the same training data could *not* elicit FSL in RNNs or LSTMs. Thus, FSL emerges only from applying the right architecture to the right data distribution; neither component is sufficient on its own

1
4
45
4/ This work helps us understand emergent FSL in large language models, and how we might induce FSL beyond language. Non-uniform naturalistic distributions are an important challenge for reflecting the real world, but also an opportunity for eliciting powerful new capabilities!

1
1
44
An impressive new kind of generative foundation model!
Trained completely unsupervised, it generates endless *controllable world models* that are (1) controllable via interpretable discrete actions (2) generated based on image prompts including drawings!
So proud of the Genie

I am really excited to reveal what
@GoogleDeepMind
's Open Endedness Team has been up to 🚀. We introduce Genie 🧞, a foundation world model trained exclusively from Internet videos that can generate an endless variety of action-controllable 2D worlds given image prompts.
145
571
3K
1
2
41
How does the brain learn a "model" for planning and model-based decision making? We found evidence that OFC activity is associated with learning the state-to-state transition function

1
13
43
1/ Transformers have at least two modes of learning:
1⃣Few-shot in-context learning in the activations
2⃣Slow, gradient-based updates in the weights
Certain distributional properties, e.g. burstiness and long-tailedness, could bias transformers to learn in one way or the other!

1
4
42
Will be at ICML @ Vienna next week, and Cog Sci @ Rotterdam for one day -- let me know if you'll be there. Would love to meet up with folks!
4
1
41
@AndrewLampinen
is one of my favorite people in the world to collaborate with, and anyone would be lucky to work with him. Please apply to the team if you're interested in any of the cognitively-oriented research described below!
Really excited to share that I'm hiring for a Research Scientist position in our team! If you're interested in the kind of cognitively-oriented work we've been doing on learning & generalization, data properties, representations, LMs, or agents, please check it out!
10
60
336
1
7
39
2/ The properties that encourage FSL are exemplified by natural language, but are actually inherent to many kinds of natural data, including first-person experience. And they are a departure from the uniform i.i.d. distributions that typify standard supervised data

2
1
39
Congratulations to the team for this awesome robotics result!! It really stands out in that (a) it works in an extremely fast-paced setting, unlike most robotics algos (b) it's interesting that it was helpful to have a hierarchical controller that selects different skills and

Meet our AI-powered robot that’s ready to play table tennis. 🤖🏓
It’s the first agent to achieve amateur human level performance in this sport. Here’s how it works. 🧵
139
842
4K
1
5
36
More people should know about this interesting paper! It solves exact learning dynamics for a class of nonlinear networks, and uncovers properties that help subnetworks learn faster and win the race over others. Could eg help explain which ones end up "lottery tickets"
@jefrankle


0
4
35
A big step forward for fast, sample-efficient RL!

I’m super excited to share our work on AdA: An Adaptive Agent capable of hypothesis-driven exploration which solves challenging unseen tasks with just a handful of experience, at a similar timescale to humans.
See the thread for more details 👇 [1/N]
25
266
1K
1
4
37
@_jasonwei
If you need an antidote to The Bitter Lesson malaise, check out our new work! 💊🙂 We show that it's the *distributional properties* of data, rather than scale per se, that leads to an interesting behavior like few-shot learning in transformers
Intriguingly, transformers can achieve few-shot learning (FSL) without being explicitly trained for it.
Very excited to share our new work, showing that FSL emerges in transformers only when the training data is distributed in particular ways!
🧵👇
14
189
1K
1
0
36
Transformers have the powerful ability to use two different kinds of information:
1⃣ information stored in weights during training (e.g. via gradient descent)
2⃣ information provided in context at inference time (e.g. in a "prompt")
(1/)
1
2
36
Agree so hard that, esp with the advent of extremely long context, we need to think deeply about how information behaves differently when you put it in context vs weights vs other kinds of memory!
Thanks so much
@xiao_ted
for the shout-outs to our work! Check out e.g.

I can’t emphasize enough how mind-blowing extremely long token context windows are. For both AI researchers and practitioners, massive context windows will have transformative long-term impact, beyond one or two flashy news cycles. ↔️
“More is different”: Just as we saw emergent

6
59
310
0
3
32
Excitingly, the ML Evaluation Standards workshop
@iclr_conf
will be collaborating with
@SchmidtFutures
to grant $15k in awards for workshop submissions and reviewers!
More info below 👇

3
11
32
Our paper comparing human and LM reasoning -- now published (open source)!
Pleased to share that the final version of our work "Language models, like humans, show content effects on reasoning tasks" has now been published in
@PNASNexus
(open access)! For a still-mostly-up-to-date summary, see this thread.
1
13
77
0
8
32
To date, it's taken half a century to map 35% of human proteins. Now
@DeepMind
has released predictions on almost the entire human proteome, for free! So many implications.. so proud of the team for this work
Today with
@emblebi
, we're launching the
#AlphaFold
Protein Structure Database, which offers the most complete and accurate picture of the human proteome, doubling humanity’s accumulated knowledge of high-accuracy human protein structures - for free: 1/
99
3K
7K
1
1
31
Updated: our work comparing humans and language models on reasoning tasks!
Neither humans nor LMs are perfect reasoners, and in fact show very similar patterns of errors. E.g., both perform better when the correct answer accords with situations that are familiar and realistic.
Very excited to share a substantial updated version of our preprint “Language models show human-like content effects on reasoning tasks!” TL;DR: LMs and humans show strikingly similar patterns in how the content of a logic problem affects their answers. Thread: 1/

3
51
279
0
1
31
I'll be at
@iclr_conf
in Kigali next week -- message me if you'll be there and would like to meet up! ☺️
2
2
31
By popular demand, the RL Reliability Metrics library now supports processing CSV input data, in addition to TF summaries!
Now you can easily measure the reliability of your RL model outputs from any ML library! CSV is now the default in the example.

2
9
30
We trained on tasks that can be solved by both in-context learning (ICL) and in-weights learning (IWL). The models initially develop emergent ICL... but then asymptotically give way to IWL! All the while the model loss continues to decrease. 2/N

1
0
28
5/ Thanks to my amazing collaborators -- I've really loved working with them on this project ❤️:
@FelixHill84
,
@santoroAI
,
@AndrewLampinen
,
@janexwang
,
@Aaditya6284
,
@TheOneKloud
, and Jay McClelland
1
1
28
Indeed! Weight decay seems to eliminate ICL transience completely, at least for the training times we tried. This is interesting since many large language models are trained with weight decay. 5/N

1
1
28
@ilyasut
I disagree with this! Given the amount of physical analogies that we use in describing these math concepts, even in ML courses, I think it's clear that physics is a more intuitive setting in at least some instances
1
0
27
So many of these researchers are heroes and role models to me, not least my PhD co-advisor
@yael_niv
😊
Thanks so much to all of you for being amazing trailblazers and advocates!
@ashrewards
@natashajaques
@ancadianadragan
@chelseabfinn
@FinaleDoshi
Doina Precup and many others

Really nice initiative by
@ben_eysenbach
, who prepared these posters (hung around
@RL_Conference
) of notable women in RL !

4
41
249
1
1
27
It's finally here!! "Ada and the Supercomputer", written by my dear friend Doris and now Amazon
#1
for teen fiction!
The book is inspired by Doris's math PhD, startups, her immense ambition.. The result is adventure+STEM+coming-of-age, and fully a story about resiliency.
link👇

1
1
27
This is so great..
@kpeteryu
et al took our insights on data distributions + in-context learning to videos, and improved few-shot learning for video narration!!
Amazing to be part of a vibrant research community where others can take our work much farther than we can ourselves 😍

Ever wondered what it would take to train a VLM to perform in-context learning (ICL) over egocentric videos 📹? Check out our work EILEV!
@SLED_AI
@michigan_AI
Website:
Technical Report:
A thread 🧵
1
12
28
2
1
23
As a practical matter, these distinctions are important to recognize, so that we know where and how to provide information to transformers (in weights vs in context), depending on what generalization behaviors we prefer.
(5/)
2
0
23
Language models are influenced by prior beliefs when they perform reasoning tasks... in similar ways to humans!
Important for understanding the limitations of LMs, and parallels with human reasoning. And demonstrates how ML can usefully borrow ideas from cognitive science
Abstract reasoning is ideally independent of content. Language models do not achieve this standard, but neither do humans. In a new paper ( co-led by Ishita Dasgupta) we show that LMs in fact mirror classic human patterns of content effects on reasoning. 1/
7
56
378
1
3
22
Learning without gradients 😊 Submit for the 1st Workshop on In-Context Learning at ICML -- July 27 in Vienna!

1
9
34
0
4
22
Amazing work by the Astra AI Assistant team!! Huge potential for accessibility or for folks who have low vision
We’re sharing Project Astra: our new project focused on building a future AI assistant that can be truly helpful in everyday life. 🤝
Watch it in action, with two parts - each was captured in a single take, in real time. ↓
#GoogleIO
223
1K
4K
1
1
22
In fact, pretrained language models are much more rule-based from context, compared to the "neutrally trained" transformers - perhaps due to the combinatorial nature of language.
But this effect is modulated by model size: larger language models are more rule-based!
(4/)

1
0
22
It's often said that causal learning requires active intervention.. but e.g. many of us learn how to do science just from reading about it!
This is a more nuanced take on how passive learning (as in language models) can lead to learning about causality and experimentation
What can be learned about causality and experimentation from passive data? What could language models learn from simply passively imitating text? We explore these questions in our new paper: “Passive learning of active causal strategies in agents and language models”
Thread: 1/

11
74
401
0
3
22
This phenomenon of transience is pretty surprising! And may have important ramifications, esp if we continue moving towards "overtraining" small models for long training times. Excited to continue investigating what is happening here! 📈📉 9/9

1
0
21
Second, if we apply regularization selectively to different parts of the model, we see mitigation only when weight decay is applied to the MLP layers... and in fact this is where in-weights learning may largely reside (e.g. Geva et al, 2020). 8/N

2
0
20
Can we eliminate ICL transience? It's the opposite of "grokking", where models use *more* general solutions after long train times -- whereas here we might consider IWL the *less* general solution. Regularization may drive grokking.. could it also keep our models using ICL? 4/N
2
0
21
Transformers tend to generalize in a "rule-based" way from information stored in weights, but in an "exemplar-based" way from information stored in context!
However, you can overcome the exemplar-based bias and by training a transformer explicitly on a rule-based task.
(3/)
1
0
21
@AlexGDimakis
If you'd like your faith restored in the endeavor of ML research, check out our new work! We show that the *distributions* of data matter, rather than scale, for eliciting an interesting behavior like few-shot learning
Intriguingly, transformers can achieve few-shot learning (FSL) without being explicitly trained for it.
Very excited to share our new work, showing that FSL emerges in transformers only when the training data is distributed in particular ways!
🧵👇
14
189
1K
1
1
21
@YiTayML
@jacobmbuckman
Agree with
@YiTayML
that you'd have a hard time getting the same results with LSTMs. See our results showing that LSTMs don't exhibit in-context/few-shot learning when transformers do, matched on data + num params (Fig 7)
2
1
20
❤️ Yes thank you
@WiMLworkshop
for the feature!
Surprising results about surprise.. OFC aids learning about state transitions, but not via prediction errors. Instead OFC activity correlated with humans correctly expecting a more probable outcome.. i.e. more optimal predictions!

Thank you,
@WiMLworkshop
, for highlighting this work by
@scychan_brains
, inspired by rodent experiments from Geoff Schoenbaum's lab, first piloted in humans in our lab by
@ninalopatina
maybe 13 years ago!! This was one of those long projects... All the kudos to
@scychan_brains
!!
0
0
8
0
1
19
So awesome to see how RL is now effective on complex real world problems. Still remember reading
@AlexIrpan
's superb essay "Deep RL doesn't work yet", and the general uncertainty around RL's efficacy, just a few years ago!

Excited to share the details of our work at
@DeepMind
on using reinforcement learning to help large-scale commercial cooling systems save energy and run more efficiently: .
Here’s what we found 🧵
9
77
485
1
3
19
Join us for the
#NeurIPS
panel today on transformer-related topics!
@tsiprasd
and I will discuss our two papers on in-context learning in transformers, both selected as orals!
This year, orals will be presented as 15-min deep-dive discussions 🥽🫧🫧
Intriguingly, transformers can achieve few-shot learning (FSL) without being explicitly trained for it.
Very excited to share our new work, showing that FSL emerges in transformers only when the training data is distributed in particular ways!
🧵👇
14
189
1K
1
3
18
Just out: Our new commentary on how AI and Psychology can learn from each other to address challenges in generalizability. "Fast publishing" (more common in AI) promotes rapid iteration and inclusivity, while "slow publishing" (more common in Psych) integrates knowledge over time
New commentary on "The Generalizability Crisis" by
@talyarkoni
: "Publishing fast and slow: A path toward generalizability in psychology and AI." We argue that these fields share similar generalizability challenges, and could learn from each other.
2
11
51
0
1
17
Congrats to
@agarwl_
et al on the Outstanding Paper award
@NeurIPS
!! It's such important work.
If you're a fan of rigorous RL evaluation, you may also be interested in our ICLR 2020 work on measuring the reliability of RL itself:

Congratulations to the authors of “Deep RL at the Edge of the Statistical Precipice”, a
#NeurIPS2021
Outstanding Paper ()! You can learn more about it in the blog post below, and we look forward to sharing more of our research at this year’s
@NeurIPSConf
.
7
75
384
2
0
18
We investigate inductive biases using a paradigm that allows us to distinguish between:
📏"rule-based" generalization, based on parsimonious rules
💠"exemplar-based" generalization, based on direct comparison with the features of observed examples
(2/)

2
0
18
Amazing how far language-conditioned robotics has come, from just a couple years ago!
@coreylynch
was one of the earliest to see the potential. Congrats to him,
@peteflorence
, and the other authors!

"Interactive Language: Talking to Robots in Real Time"
- Real-time, interactive, open-vocabulary, language+pixels -> actions
- A new scale (~600,000 traj.) for language-conditioned behavior
- Dataset, sim, models, code all to be released!
(1/n)...
8
184
837
1
1
16
Absolutely. We will inevitably need additional new methods, but newer larger LMs (based on the same architectures) can already solve a number of tasks that were previously deemed out of reach (i.e. not tailored for LMs)

This ignores a huge body of work.
We have seen new abilities emerge with every new SOTA language model. New abilities will keep emerging.
BIG-Bench claims to target weaknesses of language models, and 540B PaLM beat avg. human rater on more than half just by scaling.
10
25
256
0
0
17
This work was done with my amazing collaborators!!!
@Aaditya6284
@ted_moskovitz
@ermgrant
@saxelab
@FelixHill84
N/N
1
0
17
New preprint with
@AndrewLampinen
, Andrea Banino, and
@FelixHill84
!
How can RL agents recall the past in detail, in order to behave appropriately in the present? In our new preprint "Towards mental time travel: A hierarchical memory for RL agents" () we propose a memory architecture that steps in this direction.
3
69
339
0
0
16
First, we can mitigate ICL transience by increasing the width of the model (hence relieving competition between ICL and IWL).
(Increasing width does not affect ICL if IWL is not a valid strategy for the training problem, i.e. width is not helping ICL directly) 7/N

1
0
17
We observed this behavior across a range of settings (model depth, dataset size, language model embeddings vs image inputs) 3/N

1
0
17
Pet peeve: Anyone doing multiple-choice evals needs to account for "surface form competition"!
TLDR: the highest probability answer isn't always the one with highest model "belief", because a single concept can take multiple forms in text. The good news: it's easy to account for

🔨ranking by probability is suboptimal for zero-shot inference with big LMs 🔨
“Surface Form Competition: Why the Highest Probability Answer Isn’t Always Right” explains why and how to fix it, co-lead w/
@PeterWestTM
paper:
code:

5
43
175
0
2
17
But why does ICL transience happen in the first place? We find two pieces of evidence which indirectly but convergently point to the same cause: competition with IWL circuits. 6/N
1
0
17
These are great resources for teachers and for educating kids about AI -- the
@RaspberryPi_org
team has been so impressively thoughtful in creating them, and I'm really excited to see them released today!!

EXCITING NEWS 🎉
Experience AI launches today in partnership with
@DeepMind
.
Our new AI and machine learning programme for teachers, students, and other educators.
Find out more 👉
#AI
#MachineLearning
#DeepMind
#ExperienceAI

18
232
985
0
3
16
One of those gems that is both theoretically interesting and has practical import!

📣📣📣 We are excited to announce our new paper, “Grokfast: Accelerated Grokking by Amplifying Slow Gradients”! 🤩
Reinterpreting ML optimization processes as control systems with gradients acting as signals, we accelerate the
#grokking
phenomenon up to X50, making a step

5
14
121
1
1
16
*Transformer inductive biases*
Come check out our
#NeurIPS
poster today at the MemARI workshop! (and check out the rest of the workshop too -- a really interesting lineup!)
Video for those who can't make it in person:

New paper 🥳: Transformer inductive biases!
Transformers generalize differently from information stored in:
‣ weights - mostly "rule-based"
‣ context - mostly "exemplar-based"
This effect depends on (a) the training data (b) the size of the transformer
🧵⬇️
3
86
614
1
1
15
Pause the excitement about language models for a second -- lots of innovative and exciting things are still happening in control!
Co-evolving a mechanical body with a neural network (but using gradient descent!). Read to the last animation

Super excited to introduce Neuromechanical Autoencoders! We build "artificial mechanical intelligence" by coupling parametric neural networks with parametric mechanical metamaterials, accepted to ICLR 2023 as a Spotlight!
3
41
223
0
0
15
Very cool work on controlling the balance between in-context and in-weights learning

How robust are in-context algorithms? In new work with
@michael_lepori
,
@jack_merullo
, and
@brown_nlp
, we explore why in-context learning disappears over training and fails on rare and unseen tokens. We also introduce a training intervention that fixes these failures.

2
11
79
0
1
15
Come to Rotterdam and chat about in-context learning with us!

Excited to announce our full-day workshop on “In-context learning in natural and artificial intelligence” at CogSci (
@cogsci_soc
) 2024 in Rotterdam (with
@JacquesPesnot
@akjagadish
@summerfieldlab
and Ishita Dasgupta).
4
20
83
1
1
14
I think this paper hasn't gotten enough attention (prompt tuning models for new tasks when you only have API access). Prediction: lots of small actors will be doing this soon
1
1
13
Really excited to participate in these discussions next week.. registration is still open (and free!)

Program now live!
June 29 – Why Compositionality Matters for AI
w/
@AllysonEttinger
,
@paul_smolensky
,
@GaryMarcus
& myself
June 30 – Can Language Models Handle Compositionality?
w/
@_dieuwke_
,
@tallinzen
,
@elliepavlick
,
@scychan_brains
&
@LakeBrenden
4
28
110
0
0
12
Like many others, we argue that ML could benefit from slower, more careful publishing. But also -- perhaps unfashionably -- we argue that "fast science" has benefits too.. for inclusivity, rapid iteration, and more
Excited that our commentary "Publishing fast and slow: A path toward generalizability in psychology and AI" is out now!
The legendary
@talyarkoni
even agrees with some of it.
1
9
37
1
1
11
@DeepMind
@santoroAI
@AndrewLampinen
@janexwang
@Aaditya6284
@TheOneKloud
@FelixHill84
Also see our related work, on Zipfian environments for reinforcement learning! Code will be released soon, for those of you itching to start exploring non-uniform distributions for RL:

0
2
11
This is a game changer. Replace RLHF with a theoretically identical (and much cheaper to train) form of supervised learning

Ever wondered if the RL in RLHF is really needed? Worried that you might really need to understand how PPO works?
Worry no more, Direct Preference Optimization (DPO) allows you to fine-tune LMs directly from preferences via a simple classification loss, no RL required.
🧵 ->
16
132
785
0
1
10
Check out our new work on how **generating explanations** can help RL agents, by enabling better representations of the causal and relational structure of the world!
Explanations play a critical role in human learning, particularly in challenging areas—abstractions, relations and causality. We show they can also help RL agents in "Tell me why!—Explanations support learning of relational and causal structure" (). Thread:
3
38
213
1
1
10
I'm trying to find a paper I briefly saw, proposing a potential hypothesis for why many-shot learning might eventually decrease in performance -- could anyone point me to it? 🙏
6
0
10
Come intern at DeepMind!
DeepMind internship applications are open!
(Deadline October 4th)
0
4
21
0
1
10
Maybe this analogy helps us think about the pros and cons of this type of "stare decisis" in training (e.g. self-consistency and predictability, vs difficulty with novel cases) 2/
1
0
8
@OwainEvans_UK
Very cool results!! Do you have thoughts on why the models succeeded zero-shot on these tasks, but the e.g. reversal curse is still an issue?
3
2
9
@_jasonwei
Our work (and now others' replications in multiple domains) show that this would significantly harm in-context learning abilities, unfortunately
Intriguingly, transformers can achieve few-shot learning (FSL) without being explicitly trained for it.
Very excited to share our new work, showing that FSL emerges in transformers only when the training data is distributed in particular ways!
🧵👇
14
189
1K
0
0
9
Stay tuned ;)
Excited for our transience work to be highlighted in the update from
@ch402
@AnthropicAI
.
Their Transfomer Circuits thread has always been an inspiration to me -- actively working on mechanistic analyses of transience and should have updates soon :)

1
4
28
0
0
9
Great overview by
@weidingerlaura
on how to think more precisely about the potential risks of LLMs

Had a great time talking to
@weidingerlaura
about some of the recent papers she and her colleagues at
@DeepMind
have published about LLMs - big fan!
0
4
7
0
2
8
RLAIF may not be beneficial if you do SFT with a strong teacher
High-quality human feedback for RLHF is expensive 💰. AI feedback is emerging as a scalable alternative, but are we using AI feedback effectively?
Not yet; RLAIF improves perf *only* when LLMs are SFT'd on a weak teacher. Simple SFT on a strong teacher can outperform RLAIF! 🧵->

13
52
335
0
0
9
Super impressive work led by
@thtrieu_
on solving IMO geometry problems
Introducing AlphaGeometry: an AI system that solves Olympiad geometry problems at a level approaching a human gold-medalist. 📐
It was trained solely on synthetic data and marks a breakthrough for AI in mathematical reasoning. 🧵
126
1K
4K
0
0
8
Really loved the "compositionality gap" metric in this paper, where (correctness on final answer)/(correctness on subproblems) stayed constant at 40% across model sizes! Very curious whether this holds for GPT-4 as well

We've found a new way to prompt language models that improves their ability to answer complex questions
Our Self-ask prompt first has the model ask and answer simpler subquestions. This structure makes it easy to integrate Google Search into an LM. Watch our demo with GPT-3 🧵⬇️
52
306
2K
1
0
8
Blog post with more info and link to our tech report:

1
1
8
YC is a careful, thoughtful scientist bringing together social psychology and neuroscience in new and interesting ways, and I've always thought that he would be an exceptional mentor -- I highly recommend taking a look at his lab opening!

I am looking to hire a lab manager to help set up my new lab
@UChicagoPsych
! If you’re interested in studying how motivation influences how we see, think, decide, and interact with others, please consider applying. More info: . Please help spread the word!
38
164
311
0
0
8