
trieu
@thtrieu_
Followers
2K
Following
8K
Statuses
1K
inventor of #alphageometry. lead of alphageometry 2. thinking about thinking @ deepmind.
Mountain View
Joined April 2014
happy to contribute!

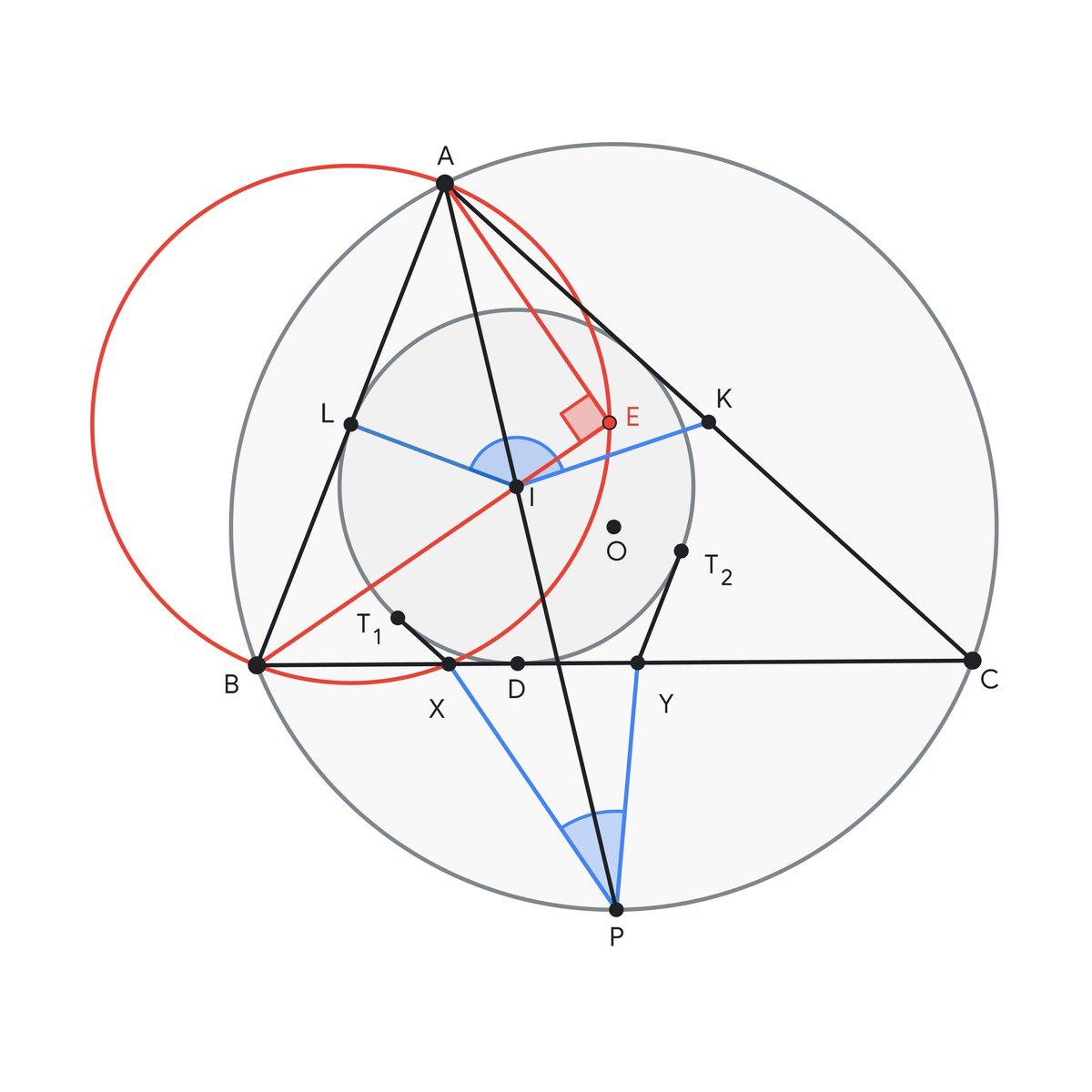
Powered with a novel search algorithm, AlphaGeometry 2 can now solve 83% of all historical problems from the past 25 years - compared to the 53% rate by its predecessor. It solved this year’s IMO Problem 4 within 19 seconds. 🚀 Here’s an illustration showing its solution ↓
5
5
121
RT @jacobaustin132: Making LLMs run efficiently can feel scary, but scaling isn’t magic, it’s math! We wanted to demystify the “systems vie…
0
364
0

RT @bryan_johnson: Here’s another one for you. Blueprint went viral and the second most frequent comment was “I want to do your protocol,…
0
250
0
RT @FelixHill84: Do you work in AI? Do you find things uniquely stressful right now, like never before? Haver you ever suffered from a…
0
109
0
it got me too (vietnam)

Wait this is fucking insane — Claude immediately guessed I was French. How can anyone still think these things are stochastic parrot and not reasoning? Do they really think there is much "people guessing what people's native languages are" in the training data?

0
0
4
RT @Yuchenj_UW: AI is an old field in CS, yet there simply isn't a good textbook out there. Most people don’t know that the best way to le…
0
234
0
RT @KaiyuYang4: 🚀 Excited to share our position paper: "Formal Mathematical Reasoning: A New Frontier in AI"! 🔗 LL…
0
139
0
RT @polynoamial: We announced @OpenAI o1 just 3 months ago. Today, we announced o3. We have every reason to believe this trajectory will co…
0
455
0
RT @recurseparadox: Words can’t describe how legendary @AlecRad is. We live in a world he built
0
5
0
RT @__JohnNguyen__: 🥪New Paper! 🥪Introducing Byte Latent Transformer (BLT) - A tokenizer free model scales better than BPE based models wit…
0
67
0
RT @nathanbenaich: How cool is this: "Researchers have already leveraged the tool to discover that both African savannah elephants (Loxodo…
0
14
0