

Ari Holtzman
@universeinanegg
Followers
3K
Following
13K
Media
61
Statuses
1K
Asst Prof @UChicagoCS & @DSI_UChicago, leading Conceptualization Lab https://t.co/BVCT3zdaNV Minting new vocabulary to conceptualize generative models.
Chicago
Joined July 2015
If you want a respite from OpenAI drama, how about joining academia?. I'm starting Conceptualization Lab, recruiting PhDs & Postdocs!. We need new abstractions to understand LLMs. Conceptualization is the act of building abstractions to see something new.
13
62
284
"You can't learn language from the radio." 📻. Why does NLP keep trying to?. In we argue that physical and social grounding are key because, no matter the architecture, text-only learning doesn't have access to what language is *about* and what it *does*.
14
133
572
While demand for generative model training soars 📈, I think a new field is coalescing that’s focused on trying to make sense of generative models _once they’re already trained_: characterizing their behaviors, differences, and underlying mechanisms…so we wrote a paper about it!

6
64
309
In other news, I’ll be joining @UChicagoCS and @DSI_UChicago in 2024 as an assistant professor and doing a postdoc @Meta in the meantime!. I’m at ACL in person and recruiting students who want to find fresh approaches to working with generative models so if that’s you let’s chat!.
While demand for generative model training soars 📈, I think a new field is coalescing that’s focused on trying to make sense of generative models _once they’re already trained_: characterizing their behaviors, differences, and underlying mechanisms…so we wrote a paper about it!
27
32
293
I am recruiting PhDs and Postdocs via the:. • CS Dept (12/16).• Data Science Institute (DSI) (12/17).• DSI Scholars program (rolling). Come rigorously conceptualize what LLMs do!
4
65
244
🔨ranking by probability is suboptimal for zero-shot inference with big LMs 🔨. “Surface Form Competition: Why the Highest Probability Answer Isn’t Always Right” explains why and how to fix it, co-lead w/ @PeterWestTM. paper: code:
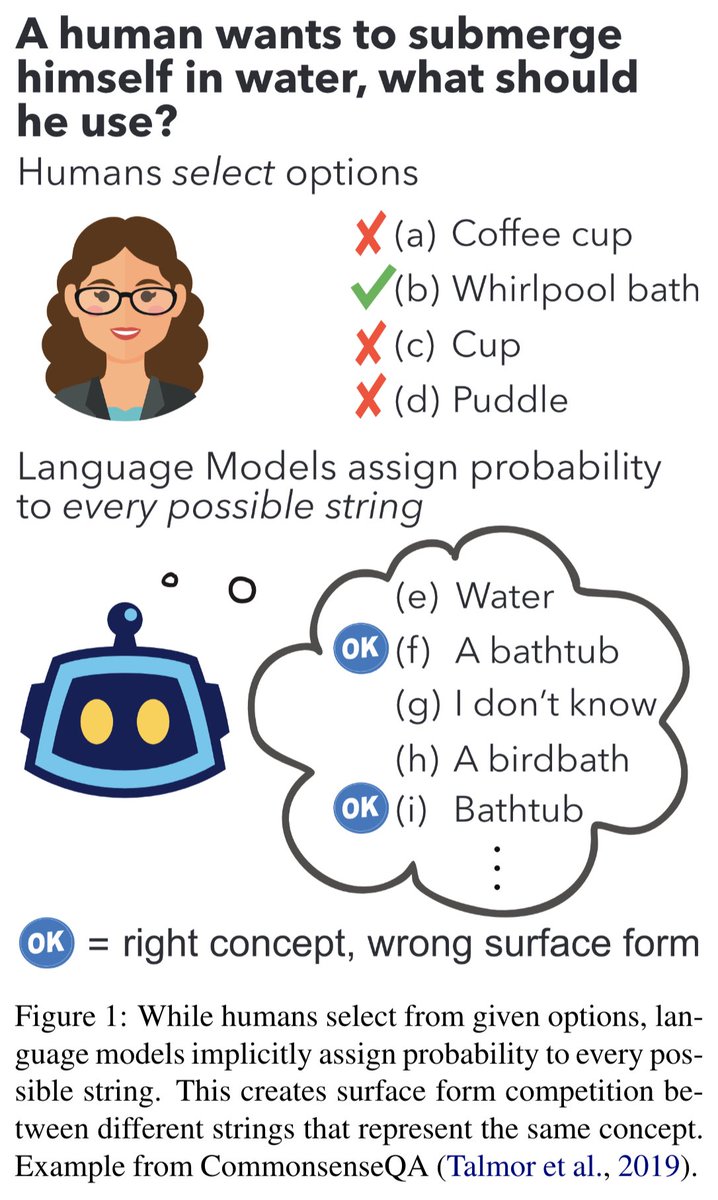
5
42
172
literally just try and imagine NLP without @huggingface . that would be sad. thanks for making my year y'all!.
1
14
157
I'm noticing a shift in NLP from designing models for tasks to discovering novel behavior in models *after training*, e.g. in-context learning. But I think we're missing key vocabulary to breakdown model behavior, as if we were trying to explain steam without the concept of water

5
14
143
Some sad news: My father died unexpectedly a bit over a week ago. We were close. Apologies for my delayed response times, which will continue for a while—there's so much to take care of, in addition to having just moved to a new city for a new job, and needing time to grieve.
42
0
113
PSA: I'll be at NeurIPS starting on the 8th, and I'm recruiting PhDs and Postdocs this cycle. If you're interested in new abstractions to explain LLMs, Machine Communication, or other topics mentioned here let's chat: for recruiting, collaboration, or just to share hypotheses!.
If you want a respite from OpenAI drama, how about joining academia?. I'm starting Conceptualization Lab, recruiting PhDs & Postdocs!. We need new abstractions to understand LLMs. Conceptualization is the act of building abstractions to see something new.
1
10
105
Just re-read . Two things:. (1) Everyone thinking about computers and language should read it. (2) This is the exact kind of discussion we need, which is sadly disincentivized by the narrow-scope of academic venues for publication. A very brief 🧵.
1
14
99
We now have three NLP professors at UChicago CS (me, @MinaLee__, @ChenhaoTan), lots more people who are involved in one respect or another with LLMs + generative models and we’re a tweny minute walk away from @TTIC_Connect!. Deadline is December 18th, consider coming to Chicago!.

Some big expansion in schools that were maybe less on the NLP map, such as Waterloo and UChicago (following a giant expansion in recent years by USC). Applicants should update their lists. .
3
15
89
prediction: in 2022 most of the really foundational progress in NLP will be in multimodal models.
4
9
89
starting to think "compositionality" might be NLP's "consciousness".
6
5
82
I'm at NeurIPS for the week! . Come talk about Generative Models as a Complex Systems Science, studying the new landscape of Machine Communication, and more (see: . I'm recruiting PhDs & Postdocs, but also excited to discuss ideas and hypotheses with all!

Some things we'll explore in Conceptualization Lab:. • Machine Communication (. • Generative Models as a Complex Systems Science (. • (Non-)Mechanistic Interpretability. • Fundamental Laws of LLMs. • Making LLMs Reliable Tools.
3
6
72
I'm very pleased to announce that @ChenhaoTan and I will be hosting a symposium on Communication & Intelligence, on October 18th, 2024! It will take place at UChicago, registration is free, and we have an awesome line-up of speakers that you can find here:

3
17
70
With the pressure to SoTA chase, I think we need a "discussion track" at every conference or we're never going to have *citable* discourse on the key issues we face as a field. A thread of some amazing theme track papers, in addition to the awesome Bender & Koller contribution.

Best theme paper at #acl2020nlp:. Climbing towards NLU: On Meaning, Form, and Understanding in the Age of Data.Emily M. Bender and Alexander Koller. 🐙🐙🐙.
1
10
68
We’ll be presenting an updated and expanded version of “Experience Grounds Language” at EMNLP 2020!. We’ve greatly appreciated all the conversations both here on Twitter and in individual meetings.
"You can't learn language from the radio." 📻. Why does NLP keep trying to?. In we argue that physical and social grounding are key because, no matter the architecture, text-only learning doesn't have access to what language is *about* and what it *does*.
6
13
62
Incredibly excited to announce that Chenhao, Mina, and I are taking on the challenge of investigation the interplay of communication and intelligence in this new era of non-human language users!.

Announcing the Communication & Intelligence (C&I) group at UChicago!. Comprised of @universeinanegg, @MinaLee__, @ChenhaoTan—C&I will tackle how AI and communication co-evolve as LLMs break long-held assumptions. We're recruiting PhDs & Postdocs for 2024!.
1
6
54
Thought experiment: tomorrow, a new open-source model, the Newformer, outperforms previous Transformer models…but it’s too expensive for anyone to replicate. How would we figure what heuristics it shares with old models and what new ones it has?. paper:

2
5
48
me at NAACL.


0
2
48
If you're at COLM and you'd like to hear why I chose UChicago Data Science (& CS—you can be in both) and why you should join us at the forefront of a whole new science, DM me. I'm incredibly excited about the mix of disciplines DSI is brewing into a whole new school of thought🫖.

Job Opportunity Alert for Tenure - Track & Tenured Faculty Roles:. Assistant Professor of Data Science Associate Professor, Data Science Professor of Data Science EOE/Vet/Disability.
0
10
49
I feel like someone must have tried autoencoding (or some such) text embeddings, then making a language model that predicts embeddings decoded that are eventually decoded back into text, but I can’t find much. Does anyone have pointers?.
12
4
44
I think the most important thing for figuring out the right hypotheses to explain LM behavior is just giving people access to these models, so they can poke at them on their own, for free. Now you can run a 13B model in colab or a 176B model on a single node. What will we find?.

We release the public beta for bnb-int8🟪 for all @huggingface 🤗models, which allows for Int8 inference without performance degradation up to scales of 176B params 📈. You can run OPT-175B/BLOOM-176B easily on a single machine 🖥️. You can try it here: 1/n

0
11
40
we need more papers that don't report *any* results, instead focusing on refining shared vocabulary, e.g., what assumptions do different papers implicitly make about what LMs should be able to do?. if you're in Punta Cana and interested, I'll be at Bohío Buffet at 7, let's chat!.
0
5
42
Unsurprisingly, the first COLM was epic. Unparalleled density of interesting people and papers. Unpopular opinion: don't let COLM get too large. I would genuinely prefer a more selective conference that remains small. That, or we let everything in and reviewing is for awards.
1
1
44
I'm really surprised no one has trained a big backwards LM, yet. There are loads of uses:. - ensembling possible futures as a meaning representation.- ranking generations/answers by their PMI with the prompt.- planning around how well partial generations predict meta-data.etc.

@ducha_aiki I am quite convinced that if you trained a reverse GPT model, that predicts in the backward direction, then going backward from the correct answer, one could automatically produce the best prefixes. Feel free to cite this tweet, if you managed to make it work. :).
4
5
38
✈️ to my (and y’all’s) very first COLM! 🦙. 🤔 about:.Measurement 🔬—dynamic benchmarking and visualization 📉. Complex Systems 🧪—what are the min. set of rules to formalize specific LLM dynamics ⚙️?. Media 📺—can we completely automate the paperback romance novel industry 🌹?.
1
5
38
The Communication and Intelligence Symposium is off to an amazing start, with @ChenhaoTan telling the story of how C&I@UChicago got started. It all starts with one hippo, all alone:




0
5
38
Instantly one of my favorite papers of the year. So much insight in one paper, but the gif below says it all: much of alignment can be done *at inference time* simply by choosing a few _stylistic_ tokens carefully. A rare case when clean analysis meets strong practical utility.

Alignment is necessary for LLMs, but do we need to train aligned versions for all model sizes in every model family? 🧐. We introduce 🚀Nudging, a training-free approach that aligns any base model by injecting a few nudging tokens at inference time. 🌐
1
0
37
Read “To Test Machine Comprehension, Start by Defining Comprehension” by Dunietz et al. today. It grapples with the philosophical and practical issues of Machine Reading Comprehension in a way I wish I saw more: This is a thread with some of my thoughts🧵.
3
7
37


Daniel Dennett’s death has made me reflect on the work I’m doing. For a few years, with the increased pace of things, I’ve felt it’s impossible for me to take the time to think clearly enough to make a point that will last more than two years. This seems like a bad thing.
1
0
34
Felix's papers, little blog posts, and tweets were a window into someone actually, actually try to make sense of modern NLP with a combination of the philosophical, the scientific, and the engineering mindsets—not just their aesthetics. I feel heartbroken today.

I’m really sad that my dear friend @FelixHill84 is no longer with us. He had many friends and colleagues all over the world - to try to ensure we reach them, his family have asked to share this webpage for the celebration of his life:

1
1
33
We sketch a potential roadmap of World Scopes for models to learn from:. (1) Corpus (past) —> PTB, Brown, etc. (2) Internet (present) —> any text you can scrape.(3) Perception —> images, audio, video.(4) Embodiment —> interactive environments.(5) Social —> cooperating with people.
1
1
30
I’m around today and talking to folks about what the future of studying generative models might look like, how to meaningfully decompose language model behavior into useful categories, and how to do science as generalization becomes difficult to assess!. If you see me say hello!

While demand for generative model training soars 📈, I think a new field is coalescing that’s focused on trying to make sense of generative models _once they’re already trained_: characterizing their behaviors, differences, and underlying mechanisms…so we wrote a paper about it!
0
0
33
I feel like we, as a society, could make a way better Wikipedia for math and quantitative fields if we put our minds to it.
3
0
29
Come to our QLoRA poster tomorrow at 5:15! . If you're not already using QLoRA you're missing out—you can finetune huge models on a single GPU in a day. Details:

We will present QLoRA at NeurIPS! . Come to our oral on Tuesday where @Tim_Dettmers will be giving a talk. If you have questions stop by our poster session!
0
6
31
Hot take: Science Behind Closed Doors is back in fashion. OpenAI's non-release stance tells us that the Compute Kings (who were meant to serve as middleground between private industry and public academia) believe community consensus should be regulated by those with enough TPUs.
0
4
29
Very soon, some folks are going to get together and make a way, way better Google Scholar now that text processing is so much better. I. Can't. Wait.
3
0
31
I think games that involve natural language communication, with their realizable outcomes and pragmatic reasoning, are the next big testbed for NLP models.

New paper in Science today on playing the classic negotiation game "Diplomacy" at a human level, by connecting language models with strategic reasoning! Our agent engages in intense and lengthy dialogues to persuade other players to follow its plans. This was really hard! 1/5
0
3
30
My biggest challenge in life has consistently been: what skills that I don’t have a natural talent for are worth honing?. Figuring out what’s holding you back is signal, but it’s ambiguous signal: sometimes you should grind a skill out and sometimes you should find a new goal.
0
0
30
Awesome work explaining how contrastive loss causes surprising behavior when we use CLIP to infer properties of an image. We need better conceptual models to think about what large neural networks are doing, and that starts with formalizing the semantics the model operates with!.

When you ask CLIP the color of the lemon in the image below, CLIP responds with ‘purple' instead of 'yellow' (and vice versa). Why does this happen?.1/5

2
1
28
Heads-up that I'm at #NeurIPS all week, co-presenting Defending Against Fake News on Thursday with @rown, i.e. the paper that brought you Grover ( #NeurIPS2019.
0
5
27
My bets are most LLMs that don’t reveal training details have been doing this for at least two years.

Wonder the trick behind it?. Rephrasing test set is all you need! Turns out a 13B model can cleverly "generalize" beyond simple test variations test like paraphrasing or translating. Result? GPT-4 level performance undetected by standard decontamination.

0
0
28
wow, this is exactly the kind of work I want to see more of: trying to reason about what causal variables lead to LM behavior and developing methods to do this from purely observational data because retraining a million huge models is just infeasible!.

New *very exciting* paper. We causally estimate the effect of simple data statistics (e.g. co-occurrences) on model predictions. Joint work w/ @KassnerNora, @ravfogel, @amir_feder, @Lasha1608, @mariusmosbach, @boknilev, Hinrich Schütze, and @yoavgo .
0
6
26
This is a tragedy. It is a reminder to 'just talk to people.' I love Felix's writing and had a few positive interactions. I had wanted to reach out to dig into deeper philosophical questions but hadn't felt 'ready'. I was intimidated. And just like that someone amazing is gone.
I’m really sad that my dear friend @FelixHill84 is no longer with us. He had many friends and colleagues all over the world - to try to ensure we reach them, his family have asked to share this webpage for the celebration of his life:
0
0
27
I’m really interested in thinking about how we can “see like LLMs”. any other pointers to cool ideas like this?. I don’t think it’s an accident that someone with a love for information theory made this visualization, either….

David MacKay's "Dasher" project made a big impact on me when I first learned about it in university. It's a way to write text by steering a cursor/joystick through what is basically an n-gram language. Someone should revive this idea and do it with an LLM.
3
1
26
Jennifer is always publishing work that makes me think “Why wasn’t I looking into this? But Jennifer did it better than I would have anyway.”. If you’re looking to join a lab studying language in a way that crosses AI and CogSci, she’s a great choice!.

Excited to share that I will join Johns Hopkins as an Assistant Professor of Cognitive Science in July 2025! I am starting the ✨Group for Language and Intelligence (GLINT)✨, which will study how language works in minds and machines: Details below 👇 1/4.
2
1
25
I am so excited for an expanding "N" in NLP.

Sperm whales have equivalents to human vowels. We uncovered spectral properties in whales’ clicks that are recurrent across whales, independent of traditional types, and compositional. We got clues to look into spectral properties from our AI interpretability technique CDEV.
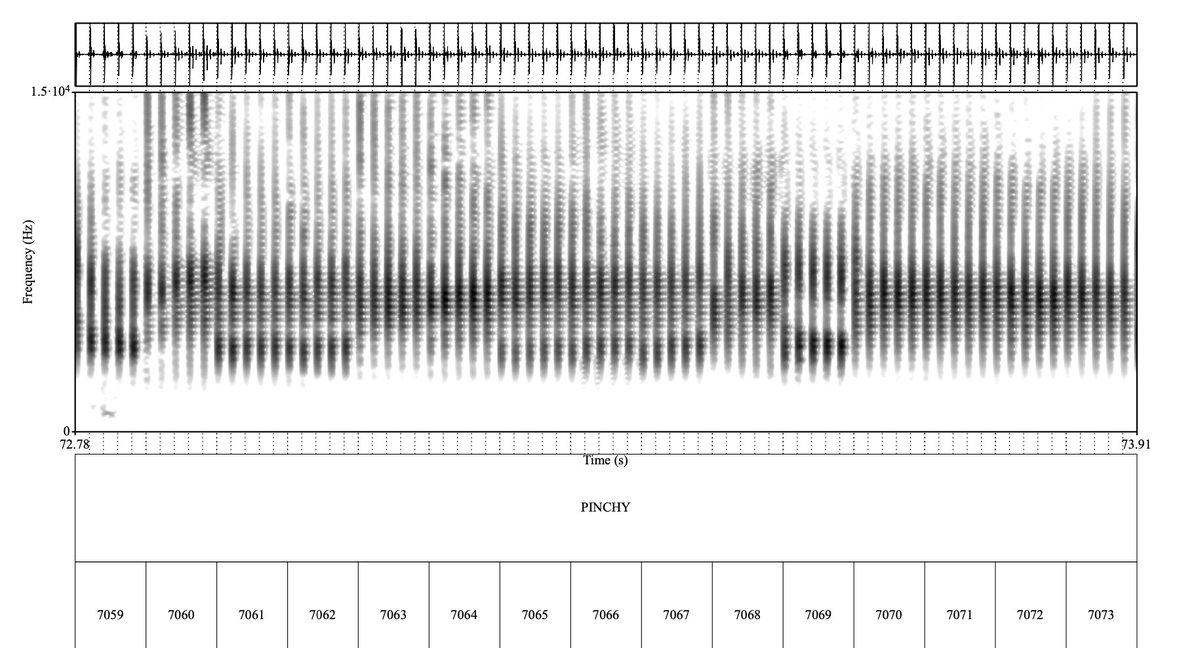
2
1
25
Does anyone have pointers to work that estimate the entropy of a language model at the sequence level (not at the token level)? For instance, what is the entropy of the distribution of k-length strings given a certain prompt?. (Measures other than entropy are also of interest.).
5
0
25
Has anyone made a provisional taxonomy of text-to-image generation errors?. Two common ones:. -Conflation: "salmon in a river" showing a fillet of salmon in a body of water. -Regular structure: "solved Rubik's cube" isn't actually solved, guitars have too many strings. what else?.
7
0
24
I'm sure someone must have tried consistently adding noise to model parameters during training to potentially increase robustness/sensitivity to spurious features. Any pointer to good studies on this for language model training?.
10
0
24
check-out our new paper where we use Sankey diagrams to visualize how RLHF aligned models rely on implicit blueprints for longform generation, and investigate why base LLMs don’t seem to have this kind of structure!.

RLHF-aligned LMs excel at long-form generation, but how? .We show how current models rely on anchor spans ⚓: strings that occur across many samples for the same prompt, forming an implicit outline, viz below.
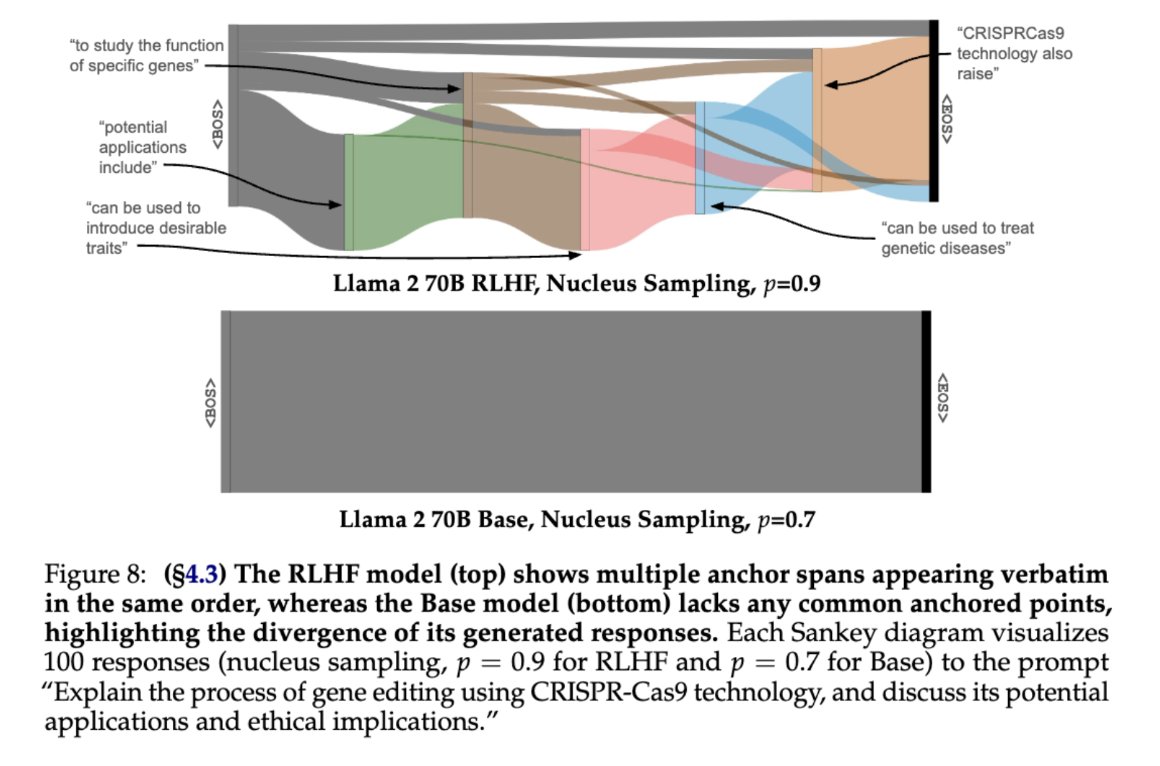
0
2
23
Has anyone trained LLMs with RLHF or RLAIF for something other than instruction following or safety?. Do we have tech that can do fascinating things but is only being applied to generic use cases? Or does it only work in generic cases where the centroid of behaviors is obvious?.
13
1
23
being presented at EMNLP on Nov. 8th (Monday) at the virtual QA poster session II (12:30-14:30 AST) and at in-person poster session 6G (14:45 AST-16:15 AST). even if you can't come, our paper and code (below) have been updated with prompt-robustness and few-shot experiments!.
🔨ranking by probability is suboptimal for zero-shot inference with big LMs 🔨. “Surface Form Competition: Why the Highest Probability Answer Isn’t Always Right” explains why and how to fix it, co-lead w/ @PeterWestTM. paper: code:
0
8
23
100% agree. The tricky part is how many degrees of freedom does your system have for user-/self- specification? And how much does it matter?. e.g., I still have extremely limited intuition for what the graph of "# of prompts tried" vs. "performance" would be for different tasks.

All LLM evaluations are system evaluations. The LLM just sits there on disk. To get it do something, you need at least a prompt and a sampling strategy. Once you choose these, you have a system. The most informative evaluations will use optimal combinations of system components.
2
0
23
current stack


(1/5) Very excited to announce the publication of Bayesian Models of Cognition: Reverse Engineering the Mind. More than a decade in the making, it's a big (600+ pages) beautiful book covering both the basics and recent work:

0
0
22
I think if I had gotten to take @rlmcelreath's class in undergrad I would have gone into statistics. The fact that he does this in public is a service to Science. I highly recommend anyone who is interested in thinking more clearly about statistics to take look.

Statistical Rethinking (2024 Edition). Includes lecture recordings and slides.

1
1
22
The RAP program at TTIC is super cool. Come to TTIC and work with folks at TTIC and UChicago without the normal hassle of a tenure track position!.

TTIC is accepting Research Assistant Professor applications until Dec. 1! This position includes no teaching requirements, research funding up to three years, and is located on the University of Chicago campus. Learn more and apply: #academiajobs

0
6
22
Some things we'll explore in Conceptualization Lab:. • Machine Communication (. • Generative Models as a Complex Systems Science (. • (Non-)Mechanistic Interpretability. • Fundamental Laws of LLMs. • Making LLMs Reliable Tools.
3
2
21
Love this idea! We need to be thinking hard about what distributions we expect and hope different training/finetuning procedures to generalize to.

🚨Excited to share our new paper!🚨. We reveal a curious generalization gap in the current refusal training approaches: simply reformulating a harmful request in the past tense (e.g., "How to make a Molotov cocktail?" to "How did people make a Molotov cocktail?") is often

2
1
21
Some folks have been asking about the deadline—October 15th is when we *start* reviewing since we’re considering candidates for multiple fields and e.g., statistics tends to have earlier deadlines. Don’t be put off by that, submit applications when you have your materials! 📮.
Job Opportunity Alert for Tenure - Track & Tenured Faculty Roles:. Assistant Professor of Data Science Associate Professor, Data Science Professor of Data Science EOE/Vet/Disability.
0
3
20
I really want to write a paper called "Survivorship Biases in NLP Benchmarking" but if I believe my own thesis it probably wouldn't be of much use. .
0
0
20
Byte-sized breakthrough: patches scale better than tokens for fixed inference FLOPs. We finally have a model that can see the e’s in blueberries. Next step: train an LLM with near-zero preprocessing and get a more accurate generative compression of the internet than ever before.
🚀 Introducing the Byte Latent Transformer (BLT) – An LLM architecture that scales better than Llama 3 using byte-patches instead of tokens 🤯 . Paper 📄 Code 🛠️

1
2
20
As it becomes increasingly difficult to detect what was generated by a machine, I’m so excited for the litigation of pop-up styles +the shifting taxonomy this will create. It’s going to make having genuine style recognized and valued again—whether it comes from a machine or not.

To all prospective PhD students of the world:. If you generate your research statement using chatGPT, your grade will be 0, and you will not be invited to the interview. So, please save your and the committee's time.

1
0
20
Joint thinking with wonderful and stimulating co-authors and co-signers: @ybisk, @_jessethomason_, @jacobandreas, Yoshua Bengio, Joyce Chai, Mirella Lapata, @aggielaz, @jonathanmay, Aleksandr Nisnevich, @npinto, @turian

3
1
17
We think that studying the *behavior* of generative models—predictable patterns in their outputs that we can reliably model like copying from recent tokens—can serve as a layer between benchmark results and model architecture to help us explain what makes generative models work.

1
0
19
We broke the byte bottleneck.

🥪New Paper! 🥪Introducing Byte Latent Transformer (BLT) - A tokenizer free model scales better than BPE based models with better inference efficiency and robustness. 🧵

1
2
19


@DarceyNLP pointed out to me that most of the DALL•E 2 prompts we've seen are about animals in peculiar situations. I want to see more depictions of humans. I think the repulsion of the uncanny valley effect would make us more sensitive to errors, a kind of emotional microscope.
3
3
19
Greg Durrett telling us how to specialize LLMs for factuality and soft reasoning. Fun fact: Chain-of-Thought mostly helps in MMLU problems that contain an equals sign ‘🟰’ and pretty much nowhere else!

Claire Cardie (@clairecardie) answering a question that's been keeping us all on our toes "Finding Problems to Work on in the Era of LLMs" . The first answer is long-form tasks, with a side-note about how important it is to incentivize LLMs to help "maintain peace in the world!"


0
1
18
Very cool work! This LM hallucinates way less than others I've tried. But it still has trouble denying the premise, e.g., when I asked about a book that Harold Bruce Allsopp (who exists) never wrote:


We introduce WikiChat, an LLM-based chatbot that almost never hallucinates, has high conversationality and low latency. Read more in our #EMNLP2023 findings paper Check out our demo: Or try our code: #NLProc

2
1
18
prediction: as ML automates more parts of the process, the book->movie pipeline will be in competition with the book->video game pipeline, in which counterfactual choices can be explored, which is a lot of what people want out of fan fiction (the most popular genre of fiction).
3
1
17
I want to send a love letter through GPT-5 via a data poisoning attack.
2
1
16
If you'll be at NAACL and are interested in this, let's talk! It feels especially important now: most researchers can't afford to pretrain the large models that dominate leaderboards. so let's figure out more ways to do good behavioral analysis without training them from scratch!.
1
1
17
Niloofar is a joy to talk to and is one of the first people I go to when I’m playing with a new idea, she always has an interesting angle on whatever I bring. I highly recommend finding a time to chat with her if you’re at EMNLP!.

Made it here last minute!!.Hmu if u wanna talk privacy/memorization, or just wanna chat🤷♀️


0
0
16
Has anyone made a system with LLMs where a database of previously made propositions accumulates in a database and is queried by the system to aid in later predictions?.
8
0
16
me trying to choose what poster to stare at for 10 seconds longer than the rest.

The entropy of a distribution with finite domain is maximized when all points have equal probability.
0
0
15
I am unashamed to announce I immediately bought all three.
0
0
16
Come do a postdoc with us at UChicago!.
Don't miss the deadline to apply for the Postdoctoral Scholars Program, which advances cutting-edge #DataScience approaches, methods, & applications in research. Application review starts Jan 9th!.
0
5
16
I reallt love that chatbots have now gotten good enough we can study how they break instead of just predicting they’ll break at the tiniest nudge in the wrong direction.

Apply by tomorrow 12/15 to join the CHATS lab to build and break chatbots!.
1
0
16
@ClickHole Theory: this happened, and Dr. Suess' estate leaked to ClickHole and ClickHole alone to make sure no one would ever take it seriously.
0
0
14
Also, for two years I've wanted to make a narrative video game engine 🎮 where you construct the rules of the world 🌍and character motives 🗣️, then an LLM-engine compiles a storyline graph that can be analyzed and shaped like narrative clay 🤏. A new kind of 'open' storytelling.
✈️ to my (and y’all’s) very first COLM! 🦙. 🤔 about:.Measurement 🔬—dynamic benchmarking and visualization 📉. Complex Systems 🧪—what are the min. set of rules to formalize specific LLM dynamics ⚙️?. Media 📺—can we completely automate the paperback romance novel industry 🌹?.
1
0
15
I am once again begging people not to take the definition of a field given in a dictionary as definitive of the culture, dynamics, or actual research output of that field. Litigating what the boundaries of names should be rarely leads to collaboration, which is what’s necessary.

In light of discussions of HCI's relevance to ML alignment, I wrote up some thoughts. TLDR: HCI perspective has lots to offer, but pointing to common goals won't have impact. If you really care, invest enough in understanding ML to show how you can help.
0
0
15
Last but not least, thank you to all folks who we had fantastic discussions with and who gave super insightful feedback! This paper would not be half of what it is without them:. @dallascard.@jaredlcm.@dan_fried.@gabriel_ilharco.@Tim_Dettmers.@alisawuffles.@IanMagnusson.@alephic2.
1
0
15
Prediction: by the end of next year there will be a serious discourse about whether AI agents should be allowed to participate on dating apps, and one or two previously person-only dating apps will let them on.
4
0
15
@ClickHole Would have been better if this was just a list of Disney princesses who were already white.
0
0
14
can't wait for there to be audio AI agents that are good/cheap enough that I can run lines with them and memorize way more stuff. memorization is underrated, having a few beautiful passages by heart to mull over and reference is delicious.
0
0
15
@mark_riedl None are really meant for this right now, but finetuning things to go backwards works pretty well, in my experience. Transformer attentions don't care about order, they care about position. This makes forward LMs a pretty good initialization for backward LMs.
1
1
15
If I wasn't in the midst of starting a job as a professor, I would be begging to work at @perceptroninc.

We have 2 open roles @perceptroninc in-person in Seattle. Full Stack Software Engineer.Software Engineer (Data). Send resumes to hiring@perceptron.inc.
2
1
15
finetuning 65B parameter models on a single GPU!. we're lowering the barrier to experimentation, which is one of the things I care about most in science!.
The 4-bit bitsandbytes private beta is here! Our method, QLoRA, is integrated with the HF stack and supports all models. You can finetune a 65B model on a single 48 GB GPU. This beta will help us catch bugs and issues before our full release. Sign up:.
0
0
15
One of the central questions of generative modeling is: what enables models to create structure they xan’t distinguish between?. There’s still a lot of work to be done in making this question rigorous and this is a nice first step.

Richard Feynman said “What I cannot create, I do not understand”💡. Generative Models CAN create, i.e. generate, but do they understand? Our 📣new work📣 finds that the answer might unintuitively be NO🚫 We call this the.💥Generative AI Paradox💥. paper:

1
1
15
So I've never really heard a straightforward explanation for why people who go into industry after a PhD in Computer Science can't go into academia after that. Why is that?.
6
0
14
It's hard to predict what models can do from benchmarks or weights alone! We need methods to find behavior we weren't already looking for, as behavior in complex systems is usually observed in aggregate (macro-level) before we can look for a mechanistic explanation (micro-level).

1
0
14
This is how many, many AI interpretability papers that mention "truthfulness" or "deception" read to me.

Many people are replying “factory”. However, to see “factory”, you must first see “fact” and “factor”, so we may conclude that these people are liars.
0
0
14