

Gabriel Ilharco
@gabriel_ilharco
Followers
4,141
Following
1,270
Media
59
Statuses
451
Building cool things @xAI . Prev. PhD at UW, Google Research
Palo Alto, CA
Joined September 2015
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
England
• 373695 Tweets
Noah Lyles
• 290952 Tweets
ヒロアカ
• 184309 Tweets
Polônia
• 122498 Tweets
フワちゃん
• 101828 Tweets
ジャンプ
• 83682 Tweets
堀越先生
• 76304 Tweets
Corinthians
• 70601 Tweets
Alemania
• 60810 Tweets
Thompson
• 60479 Tweets
Gabi
• 60314 Tweets
Bolt
• 54505 Tweets
Peillat
• 53035 Tweets
Carol
• 51219 Tweets
Rosamaria
• 49935 Tweets
Evandro
• 42008 Tweets
やす子ちゃん
• 40002 Tweets
BAUTI MASCIA EN YOUTUBE
• 37549 Tweets
Tamworth
• 36496 Tweets
RFK Jr.
• 30500 Tweets
Thaisa
• 28174 Tweets
#めざましテレビ
• 24167 Tweets
やす子さん
• 22818 Tweets
ケイくん
• 20578 Tweets
Greggs
• 18219 Tweets
Juventude
• 17614 Tweets
神さま学校の落ちこぼれ
• 16829 Tweets
Solari
• 15529 Tweets
#dilematvi
• 14155 Tweets
#エンタメプレゼンターK
• 12444 Tweets
もちづきさん
• 12292 Tweets
#فضفض_بكلمه
• 11334 Tweets





















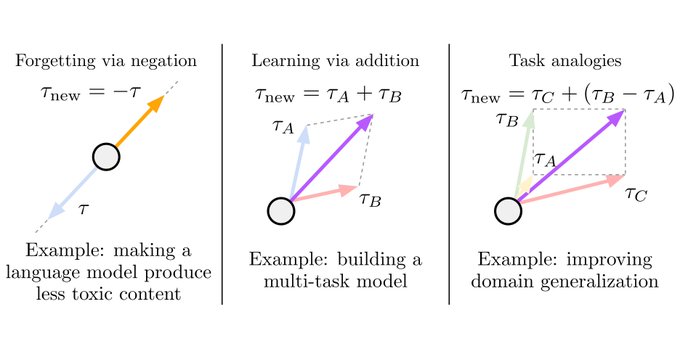
Introducing task vectors!
A new way to steer models by doing arithmetic with model weights. Subtract to make models forget, add to make them learn
📜:
🖥️:
20
273
1K
Introducing DataComp, a new benchmark for multimodal datasets!
We release 12.8B image-text pairs, 300+ experiments and a 1.4B subset that outcompetes compute-matched CLIP runs from OpenAI & LAION
📜
🖥️
🌐

8
190
776
Today we are releasing a CLIP ViT-L/14 model with 79.2% zero-shot accuracy on ImageNet.
Our model outperforms OpenAI's CLIP by a large margin, and outperforms even bigger models (ViT-g/14) trained on LAION-2B
Check it out at !

17
141
739

As good a time as any to say I recently graduated and joined
@xAI
.
It’s going to be an exciting year, buckle up =)

31
50
480
Fine-tuning can make models like CLIP less robust.
A simple idea is highly effective at mitigating that:
averaging zero-shot and fine-tuned models.
Check out our work introducing WiSE-FT, just accepted to CVPR!
Paper:
Code:

4
96
530
Grok is going multimodal!
It’s incredible to see how fast a small, focused team can move. Kudos to the amazing team
@xAI
that made this possible

15
67
374
We are releasing an open-source training implementation of OpenAI’s CLIP!📎
CLIP models learn from language supervision, and are capable of strong zero-shot performance at various vision tasks ()
Our reproduction can be found at

4
77
334
Instead of a single neural network, why not train lines, curves and simplexes in parameter space?
Fantastic work by
@Mitchnw
et al. exploring how this idea can lead to more accurate and robust models:

2
48
293
Another breakthrough in CLIP models, powered by better datasets. Great job
@Vaishaal
,
@AlexFang26
and team!
Paper:

3
44
275
I've been seeing a lot of talk around the recent Vision Transformer (ViT) paper, so I thought I'd highlight some of my favorite previous work on self-attention and transformers in computer vision!
Link to ViT:
(thread 👇)
2
52
264
The year is 2032. A model was trained on all images, videos and text on the web, using over 100 yottaFLOPs.
It still thinks this is an image of a dog.
To fix models post-hoc, check out PAINT!🎨
📜
💻
🌐

5
39
179
Vision plays a central role in shaping the meaning of concrete words like "apple" or "banana". Yet, most of today's NLP models learn representations of these concepts from text-only.
Can such representations share similarities with the visual world?
1/n

2
39
145
Forget about messy vision backbones inside vision+language models?
Check out ViLT, a cool work by Kim et al., extending Vision Transformers to multimodal domains.
Link:

1
27
134


Can machines learn language from grounded, untranscribed speech?
I don't know, but we're making fast progress!
Paper:
Thread below (1/n)
1
21
85
🚀Big updates to OpenCLIP! We now support over 100 pretrained models, and many other goodies. Check it out!


v2.23.0 of OpenCLIP was pushed out the door! Biggest update in a while, focused on supporting SigLIP and CLIPA-v2 models and weights. Thanks
@gabriel_ilharco
@gpuccetti92
@rom1504
for help on the release, and
@bryant1410
for catching issues. There's a leaderboard csv now!
2
18
147
1
17
78
A surprisingly simple way to improve generalization when fine-tuning: combine the weights of zero-shot and fine-tuned models.
We find significant improvements across many datasets and model sizes, at no additional computational cost at fine-tuning or inference time!

Can zero-shot models such as CLIP be fine-tuned without reducing out-of-distribution accuracy?
Yes! Our new method for robust fine-tuning improves average OOD accuracy by 9% on multiple ImageNet distribution shifts without any loss in-distribution
(1/9)

5
63
256
0
21
80
A quick reminder that less than 10 years ago, this is what image generation looked like. Things move fast!!

2
5
74
New paper out!
In NLP, fine-tuning large pretrained models like BERT can be a very brittle process. If you're curious about this, this paper is for you!
Work with the amazing
@JesseDodge
,
@royschwartz02
, Ali Farhadi,
@HannaHajishirzi
&
@nlpnoah
1/n

Fine-Tuning Pretrained Language Models: Weight Initializations, Data Orders, and Early Stopping
We found surprisingly large variance just from random seeds when fine-tuning BERT. Both weight inits and the order of the training data have big impact.
1/n
12
107
434
1
23
60
By *negating* a task vector, users can mitigate undesirable behaviors (e.g. toxic generations from a LM), or forget tasks altogether (e.g. OCR).
For instance, by fine-tuning a GPT-2 model on toxic data, negating the resulting task vector reduces toxic generations by 6x. (8/n)

1
3
49
We are hosting a tutorial on High Performance NLP at
#emnlp2020
, covering a bunch of fun stuff in efficiency!
Our first live Q&A session starts in ~1h!
Slides:
With the amazing Cesar Ilharco,
@IuliaTurc
,
@Tim_Dettmers
, Felipe Ferreira and
@kentonctlee
.
0
12
48
Task vectors offer a simple and efficient way of editing models. To create a task vector, we first fine-tune on a downstream task, then subtract the weights of the pre-trained model from the weights of the fine-tuned model. (3/n)

1
0
46
Thrilled that our paper got honorable mention for Best Paper Award for Research Inspired by Human Language Learning and Processing!
@conll2019
#emnlp2019
Can machines learn language from grounded, untranscribed speech?
I don't know, but we're making fast progress!
Paper:
Thread below (1/n)
1
21
85
4
11
47
Much like software, models can be patched, adding support for new tasks with little change elsewhere.
I'll be at NeurIPS this week presenting our patching method, PAINT🎨. Come say hi! 👋

1
7
39

Despite their importance, datasets rarely receive the same research attention as model architectures or training algorithms.
We believe this is a major shortcoming in the
machine learning ecosystem, and that datasets deserve as much rigorous empirical experimentation as models
2
3
37
We are also releasing many other models trained as part DataComp (), you can find them at

2
5
35
Our work builds off and is related to some exciting recent research, like , , , , , , , (16/n)
1
0
35

One of the most important challenges in machine learning today is figuring out how to control the behavior of pre-trained models, whether to reduce biases, align with human preferences, or simply improve accuracy on downstream tasks. (2/n)
1
0
31
Another key benefit of task vectors is that they enable us to reuse existing fine-tuned models, without the need to re-train or transfer any of the data. This is particularly exciting in light of the fast growth of fine-tuned models in recent years. (5/n)

1
0
32
While it might be surprising at first that we can operate directly in the weight space of neural networks, our research builds on several recent exciting works exploring the geometry of loss landscapes and weight averaging (links at the end!) (6/n)
1
2
32
Once created, task vectors can be combined via arithmetic operations like addition or subtraction, changing model behavior accordingly.
And since all operations are element-wise, editing models with task vectors has no impact on inference time! (4/n)
1
0
31
None of this would be possible without my amazing collaborators, so huge thanks to
@marcotcr
,
@Mitchnw
,
@ssgrn
,
@lschmidt3
,
@HannaHajishirzi
and Ali Farhadi!
Check out our paper and code at
📜:
🖥️:
(n/n)

0
1
31
By *adding* task vectors, we can create multi-task models without any additional training.
Using CLIP, adding task vectors from two different tasks greatly improves the accuracy of the zero-shot model, and almost matches the accuracy of using multiple specialized models (9/n)

1
0
30
Together with DataComp, we are releasing CommonPool, the largest collection of image-text pairs to date.
CommonPool has 12.8 billion samples collected from Common Crawl, and is larger than existing datasets by a factor of 2.5x.

2
4
28
DataComp is a new benchmark for designing multimodal datasets.
Unlike traditional benchmarks, DataComp has data front and center.
The goal of participants is to propose new training sets, while keeping code, hparams & compute constant.

1
4
28
As more task vectors are added together, we can create more powerful multi-task models, without any re-training, and without increasing inference time (10/n)

1
0
28
If you're interested in the next generation of vision datasets, don't miss our workshop today at
#ICCV2023
!
1
1
27
…, , and, one of our main sources of inspiration, (17/n)
1
0
23
We also show that the ranking of many curation approaches is consistent across scales
This suggests that experiments at smaller scales can provide valuable insights for larger scales, thereby accelerating investigations

1
4
21
As a highlight, we find a 1.4B subset of our pool, DataComp-1B, that outcompetes compute-matched models from OpenAI and LAION by a large margin

2
2
21
We present 300+ baseline experiments along with many insights into dataset design
A key result is that smaller, more aggressively filtered datasets can perform *better* than larger datasets coming from the same pool
1
3
19
In our work we edit models using three arithmetic expressions over task vectors: negating a task vector, adding task vectors together, and doing analogies with task vectors. (7/n)
1
0
20
I recently had my last day as a
@GoogleAI
Resident. It has been an amazing year and I'm very thankful to
@jasonbaldridge
,
@vihaniaj
,
@alex_y_ku
,
@quocleix
and other collaborators for teaching me what no book can and making me fall in love with doing research.
1
0
20
Overall, we show that task arithmetic is a simple, efficient and effective way of editing models. It enables us to re-use existing checkpoints without the need to re-train or transfer data, and to combine models without increasing inference time. (14/n)
1
0
20
Finally, much like with word embeddings such as Word2Vec (think "man" is to "woman" as "king" is to "queen"), you can do *analogies* with task vectors! (11/n)
1
0
19
Consider two sentiment analysis datasets. We can improve accuracy on the first by combining three other task vectors, obtained by A) unsupervised ft on the 1st dataset; B) supervised ft on the 2nd and C) unsupervised ft on the 2nd
B+(A-C) improves accuracy on the first! (12/n)

1
0
17
Whoa, this is really cool!
Text-only models often outperform text+vision models in text-only tasks, given the statistical discrepancies in the language used in these domains.
"Vokenization" is a neat way to get some grounded supervision without paying the domain shit price

*Vokenization*: a visually-supervised language model attempt in our
#emnlp2020
paper: (w.
@mohitban47
)
To improve language pre-training, we extrapolate multimodal alignments to lang-only data by contextually mapping tokens to related images ("vokens") 1/4

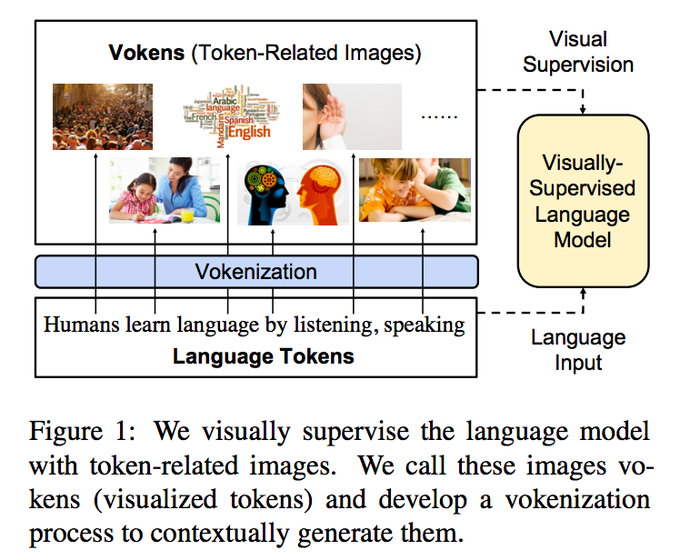
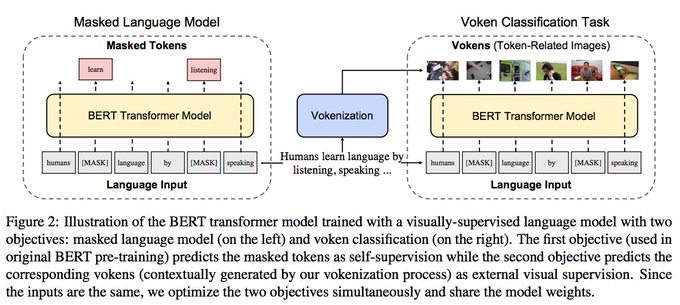
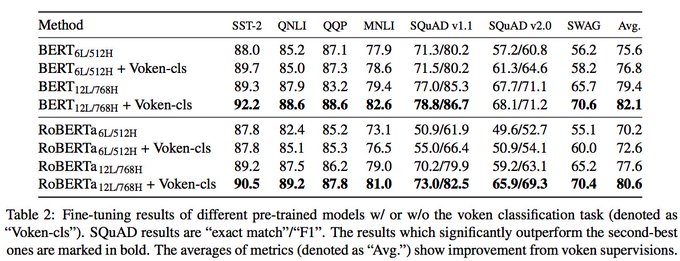
7
89
356
0
2
17
Our benchmark is designed with scale in mind, with 4 levels of compute ranging from 12.8M to 12.8B samples seen in training
At the smallest scale, we can train in a few hours on a single GPU. At the largest, experiments may take up to 40 thousand GPU hours
1
2
16
DataComp is centered around image-text datasets, which have been instrumental in building models like CLIP, DALL-E, Stable Diffusion, Flamingo, and many others.
Our standardized infrastructure trains CLIP models and evaluates them on a diverse suite of 38 downstream tasks.
1
2
16
Large-scale image-text datasets like LAION or DataComp are heavily filtered.
Instead of throwing millions of images away, can we make use of them via image captioning models?
Check out this very cool work led by
@thao_nguyen26
! 👇

Are synthetic captions useful for multimodal training?
In , we show how image captioning can improve the quality of web-scale datasets. Replacing noisy web captions with generated ones outperforms existing filtering methods from the DataComp benchmark 1/n

5
20
117
0
0
16
This massive effort was made possible thanks to the work of many,
@sy_gadre
,
@AlexFang26
,
@JonathanHayase
, Georgios Smyrnis,
@thao_nguyen26
, Ryan Marten,
@Mitchnw
, Dhruba Ghosh,
@JieyuZhang20
, Eyal Orgad,
@rahiment
,
@giannis_daras
,
@sarahmhpratt
,
@RamanujanVivek
, ...
1
2
16
Special thanks to all the DataComp authors for making this possible, and to Stability AI for providing compute!
1
2
16
We will also hold a workshop at ICCV 2023 centered around DataComp in October, and will invite outstanding submissions to give presentations.
Check out to learn more!
1
4
15
Researcher 1: we should show that our system is robust
Researcher 2: how about we simulate what would happen if a giraffe tried to eat the cube?
Researcher 1: excellent idea

We’re all used to robots that fail when their environment changes unpredictably. Our robotic system is adaptable enough to handle unexpected situations not seen during training, such as being prodded by a stuffed giraffe:
46
387
2K
0
2
15
Also, when data from the target task is available, using analogies with task vectors can provide a better starting point for fine-tuning. (13/n)

1
0
15
@peterjliu
A lot of it is data! E.g. in DataComp we saw big gains with better datasets without changing the training recipe
0
0
14
New sota open-source CLIP model just dropped 🔥
0
1
14
...
@YonatanBitton
,
@Kalyani7195
,
@MussmannSteve
,
@rvencu
,
@mehdidc
,
@RanjayKrishna
,
@PangWeiKoh
,
@osaukh
, Alexander Ratner,
@SongShuran
,
@HannaHajishirzi
, Ali Farhadi,
@rom1504
,
@sewoong79
,
@AlexGDimakis
,
@JJitsev
,
@Vaishaal
, Yair Carmon and
@lschmidt3
1
2
13
Along with filtering CommonPool, we have a separate Bring Your Own Data (BYOD) track. In BYOD, any data can be used as long as it doesn’t overlap with our evaluation suite.
We show that adding data sources such as RedCaps and CC12M can improve performance of some baselines
1
2
13
A special thanks to Stability AI and the Gauss Centre for Supercomputing e.V for providing us with compute resources for training our models.
3
2
13
Personally, I'm excited about the potential of self-attention in vision, especially given recent indication that, in some scenarios, it can scale better than convolutions.
It's great to see all this recent progress, and I hope it shows up to its promise in the near future!
1
0
12
Apparently GPT-2 thinks it's a good idea to initialize weights with zeros 🤔


1
1
11
If your at
@ACL2019_Italy
and multimodal learning and natural language grounding interests you, come check out our presentation of !
1
3
11
While I'm sad to leave this incredible environment, I'm very excited to be joining
@uwcse
as a PhD student this Fall!
1
0
11
1) Image Transformer (2018), by
@nikiparmar09
,
@ashVaswani
,
@kyosu
,
@lukaszkaiser
, Noam Shazeer,
@alex_y_ku
,
@dustinvtran
.
Local attention at the pixel level for image generation and super-resolution
Link:

1
0
11
Why is reaching the target the only thing most people worry about in navigation? Find out more in our ACL 2019 paper
1/

1
2
11
@ericjang11
@colinraffel
Some of our recent papers that might interest you!
Merging a finetuned and a pretrained model:
Merging models finetuned on the same task:
Merging models finetuned on different tasks:
1
0
11
There is much more in our paper, and we think this is just the beginning! I’m excited for a future where we have cheap and reliable ways of controlling how models behave, without needing to re-train them from scratch (15/n)
1
0
11
2) Attention Augmented CNNs (2019), by
@IrwanBello
,
@barret_zoph
,
@ashVaswani
, Jonathon Shlens,
@quocleix
Augmenting CNNs with self-attention yields considerable improvements on ImageNet
Link:

1
1
11
There is much more in the links below.
We are beyond excited to build the next generation of multimodal datasets rigorously and collaboratively, and hope you join us in this journey!
📜:
🖥️:
🌐:
1
2
11
Check out model soups, a new recipe for fine-tuning! 🍜
Our recipe leads to 90.98% accuracy on ImageNet when fine-tuning BASIC
Introducing a new recipe for fine-tuning --- model soups 🍜
TL;DR: we average the weights of multiple fine-tuned models to improve accuracy without increasing inference time
Paper:
Code:
To appear at ICML
(1/10)

5
42
266
0
1
10
0
0
10
Packed room today at our
#KDD
tutorial on Deep Learning for
#NLProc
with
#TensorFlow
! Great to talk to such a broad and intelligent audience!

1
2
9
New state of the art on nine Vision+Language tasks, including VQA, VCR, Visual Entailment, and NLVR2!
Browsing ICLR papers is always a treat

0
7
9
Languages are beautiful. In classic Tupi, spoken by native Amerindians in Brazil, all verbs are in the present tense. Time is generally expressed by the suffixes "rama" (future) and "ûera" (past). (1/2)
1
0
9
It has been incredibly fun to put this together!
Huge shout-out to the amazing people involved
@Mitchnw
, Nicholas Carlini,
@rtaori13
, Achal Dave,
@Vaishaal
, John Miller, Hongseok Namkoong,
@HannaHajishirzi
, Ali Farhadi &
@lschmidt3
. Special thanks to
@_jongwook_kim
and
@AlecRad
0
0
9
This is a big steps towards democratizing access to large models. Congrats on the great work, Tim!

We release LLM.int8(), the first 8-bit inference method that saves 2x memory and does not degrade performance for 175B models by exploiting emergent properties. Read More:
Paper:
Software:
Emergence:

17
250
1K
0
1
9
6) DETR: End-to-End Object Detection with Transformers (2020), by
@alcinos26
,
@fvsmassa
,
@syhw
, Nicolas Usunier,
@kirillov_a_n
,
@szagoruyko5
)
Object detection as a set prediction problem and a transformer on top of a CNN backbone
Link:

1
1
9
7) Group Equivariant Stand-Alone Self-Attention for Vision (2020) by
@davidwromero
,
@jb_cordonnier
Self-attention with equivariance to arbitrary symmetries by carefully defining the positional encodings
Link:

1
0
9
If you haven't been following it,
@wightmanr
,
@CadeGordonML
and others have been doing amazing work with the OpenCLIP library!
They recently trained two ViT models on LAION-400M, the first large-scale, open-source CLIP models where the data is also publicly available!
OpenCLIP () has been updated with the latest results from a ViT-B/16 training run with the LAION400M dataset. Reaching zero-shot top-1 of 67.07 for In1k validation set. Further zero-shot analysis pending...
3
35
222
0
1
8
5) Axial-DeepLab (2020), by Huiyu Wang, Yukun Zhu, Bradley Green, Hartwig Adam,
@YuilleAlan
, Liang-Chieh Chen)
Factorizing 2-d attention into two faster 1-d operations. Strong results on classification and segmentation
Link:

1
0
8
Models available at .
Full results here:
0
2
8
Fantastic work by
@OfirPress
,
@nlpnoah
and
@ml_perception
showing when it's helpful to use shorter sequences for language modeling!
Thread 👇

Everyone thinks that you have to increase the input length of language models to improve their performance. Our new Shortformer model shows that by *shortening* inputs performance improves while speed and memory efficiency go up. ⬇(1/n) (code below)

8
89
547
0
0
8
Overall, DataComp provides a controlled environment that enables rigorous experimentation over dataset design choices.
The large improvements we see from simple baselines highlight the power of careful empirical studies with datasets.
1
2
8

More details in the great thread below by
@Mitchnw
.
We added a number of new experiments and results in our paper, including additional models such as ALIGN and BASIC, along with further discussions on the role of hyperparameters.
Can zero-shot models such as CLIP be fine-tuned without reducing out-of-distribution accuracy?
Yes! Our new method for robust fine-tuning improves average OOD accuracy by 9% on multiple ImageNet distribution shifts without any loss in-distribution
(1/9)
5
63
256
1
1
6
Our codebase matches the ImageNet zero-shot accuracy from OpenAI (32.7% ours vs 31.3%) when training on the same data at medium scales (~15M samples from YFCC).
As shown by the scaling trends below, performance is far from saturated at this scale.

1
0
7
Me:
Reviewer number 2:

jonathan frakes telling you you're wrong for 47 seconds
1K
24K
82K
1
0
7
Getting started with research can be challenging, especially if you come from underrepresented communities. I was fortunate to have amazing people guiding me in this process and I’m happy to help ambitious people do the same. Feel free to contact me =)
1
0
7
If you're interested in robustness, don't miss
@anas_awadalla
's great work! Tons of models and evaluations, and lots of practical insights!

I am excited to share our paper on evaluating the distributional robustness of QA models, where we evaluate 350+ SQuAD models on 15 distribution shifts and find that in-context learning provides the best performance-robustness tradeoff.
More details below ⬇️

3
11
65
0
0
7
Even the best pre-trained models are not perfect.
For instance, CLIP has strong zero-shot accuracy on ImageNet, but is worse than logistic regression with pixels on MNIST.
In some cases, like in typographic attacks, simply scaling up can make things worse📉

1
0
7
One particularly exciting property of small-medium scale CLIP models is that they still exhibit atypically high effective robustness! ()
This scale invariance means we don't need massive amounts of compute to study what makes these models robust

1
0
7