
Dustin Tran
@dustinvtran
Followers
42K
Following
5K
Statuses
3K
Research Scientist at Google DeepMind. I lead evaluation at Gemini / Bard.
San Francisco, CA
Joined June 2013
Here is what Gemini can do on *Flash*. My favorite perk: Gemini 2.0 Flash Thinking has significant gains in core capabilities while also excellent in user preferences (co-#1 with gemini-exp-1206 on @lmarena_ai). The best of both worlds.

We’ve been *thinking* about how to improve model reasoning and explainability Introducing Gemini 2.0 Flash Thinking, an experimental model trained to think out loud, leading to stronger reasoning performance. Excited to get this first model into the hands of developers to try out!
2
0
44
We’ve been able to ship models in less than 24 hours. I’ve heard multiple VPs state they’ve never seen Google able to ship so quickly before.
1
0
3
gemini-exp-1206, out now. #1 everywhere. A 1 year anniversary for Gemini!

Gemini-Exp-1206 tops all the leaderboards, with substantial improvements in coding and hard prompts. Try it at !

4
6
94
RT @lmarena_ai: Massive News from Chatbot Arena🔥 @GoogleDeepMind's latest Gemini (Exp 1114), tested with 6K+ community votes over the past…
0
311
0
Nice work on controlling style biases! In this view, many models are no longer inflated (e.g., response length, formatting). Gemini 1.5 Flash also outperforms gpt-4o-mini overall and across all categories except for coding.
Does style matter over substance in Arena? Can models "game" human preference through lengthy and well-formatted responses? Today, we're launching style control in our regression model for Chatbot Arena — our first step in separating the impact of style from substance in rankings. Highlights: - GPT-4o-mini, Grok-2-mini drop below most frontier models when style is controlled - Claude 3.5 Sonnet, Opus, and Llama-3.1-405B rise significantly - In Hard Prompts, Claude 3.5 Sonnet ties for #1 with ChatGPT-4o-latest. Llama-405B climbs to joint #3. More analysis in the thread below👇

1
3
26
0
0
12
Welcome back @NoamShazeer to Google! It'll be a great time working together again since 2018. Let's take Gemini which is #1 and continue expanding the limits of its capabilities.
2
4
90
RT @melvinjohnsonp: Our latest version of Gemini 1.5 Pro in AI Studio is #1 on the LMSys leaderboard. 🚀 This is the result of various advan…
0
17
0
Gemini is #1 overall on both text and vision arena, and Gemini is #1 on a staggering total of 20 out of 22 leaderboard categories. It's been a journey attaining such a powerful posttrained model. Proud to have co-lead the team!
Exciting News from Chatbot Arena! @GoogleDeepMind's new Gemini 1.5 Pro (Experimental 0801) has been tested in Arena for the past week, gathering over 12K community votes. For the first time, Google Gemini has claimed the #1 spot, surpassing GPT-4o/Claude-3.5 with an impressive score of 1300 (!), and also achieving #1 on our Vision Leaderboard. Gemini 1.5 Pro (0801) excels in multi-lingual tasks and delivers robust performance in technical areas like Math, Hard Prompts, and Coding. Huge congrats to @GoogleDeepMind on this remarkable milestone! Gemini (0801) Category Rankings: - Overall: #1 - Math: #1-3 - Instruction-Following: #1-2 - Coding: #3-5 - Hard Prompts (English): #2-5 Come try the model and let us know your feedback! More analysis below👇

10
8
113
@alexandr_wang @karpathy @polynoamial @lmsysorg Top priorities imo: 1. Investigate IF. Results are a bit weird 2. Harder math 3. More non-English languages 4. More capabilities: safety, creativity/writing, long context.
0
0
0
On results: * Spanish is where I expect models at. Gemini is within CI of #1 and should be #1 (it is so good at multilingual and also #1 on LMSYS non-English). * Coding as well. * Math focuses on grade school math which can be saturated. I expect the ranking to change on more complex problems. * Instruction following is surprising. Would be great to iron out whether it's a quirk from eval or generally consistent.
1
0
6
Gemini 1.5 report is out. Lots of progress in pre- and post-training. Gemini 1.5 Pro dominates 1.0 Ultra which was launched only 6 months ago. Even our speediest Gemini 1.5 Flash outperforms 1.0 Ultra on most text and vision tasks.

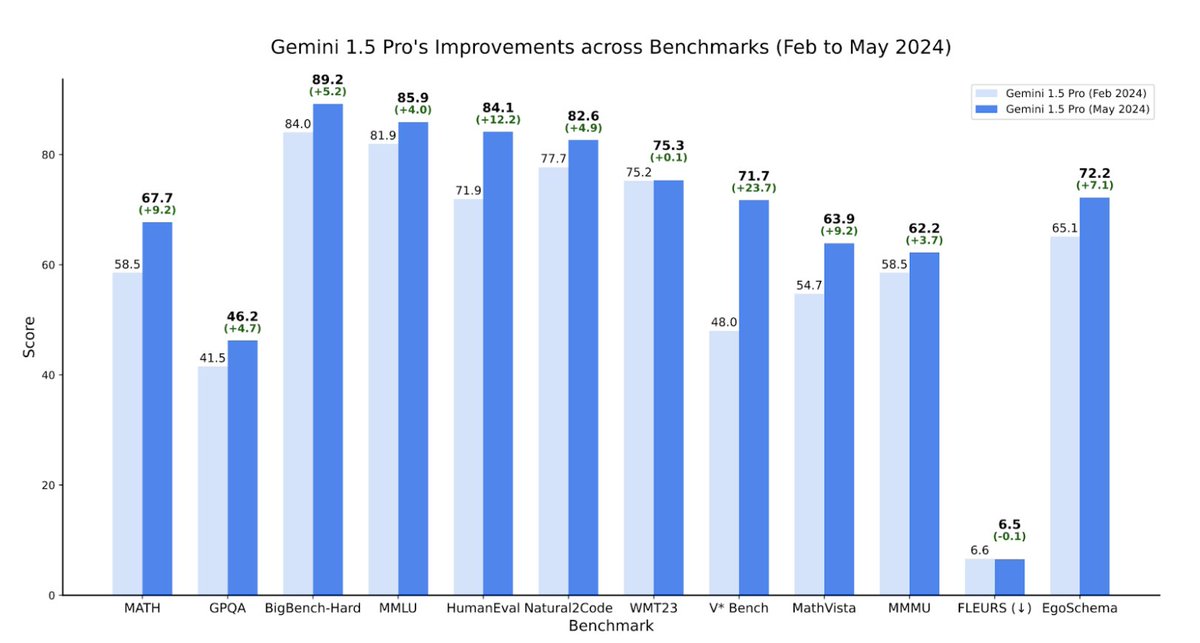
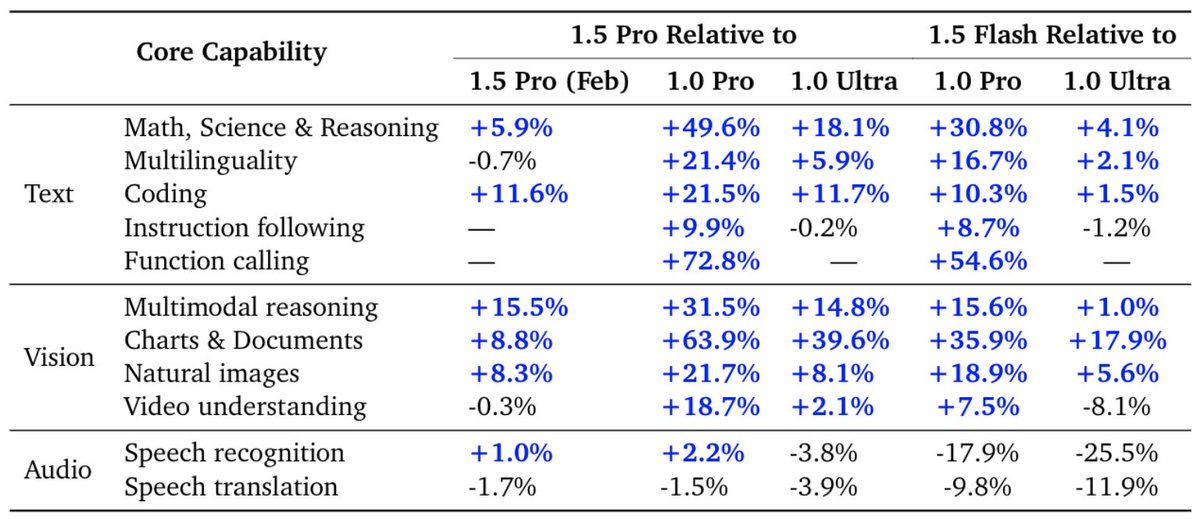
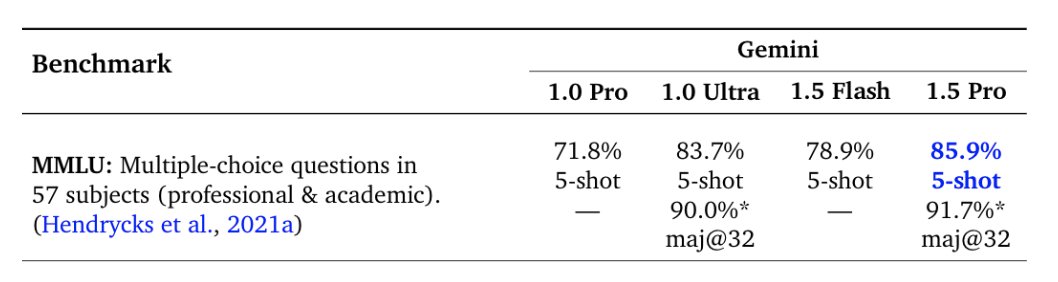
Gemini 1.5 Model Family: Technical Report updates now published In the report we present the latest models of the Gemini family – Gemini 1.5 Pro and Gemini 1.5 Flash, two highly compute-efficient multimodal models capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Our latest report details notable improvements in Gemini 1.5 Pro within the last four months. Our May release demonstrates significant improvement in math, coding, and multimodal benchmarks compared to our initial release in February. Furthermore, the 1.5 Pro Model is now stronger than 1.0 Ultra. The latest Gemini 1.5 Pro is now our most capable model for text and vision understanding tasks, surpassing 1.0 Ultra on 16 of 19 text benchmarks and 18 of 21 of the vision understanding benchmarks. The table below highlights the improvement in average benchmark performance for different categories in 1.5 Pro since Feb, and also shows the strength of the model relative to the 1.0 Pro and 1.0 Ultra models. The 1.5 Flash model also compares very well against the 1.0 Pro and 1.0 Ultra models. One clear example of this can be seen on MMLU On MMLU we find that 1.5 Pro surpasses 1.0 Ultra in the regular 5-shot setting scoring 85.9% versus 83.7%. However with additional inference compute, via majority voting on top of multiple language model samples, we can get a performance of 91.7% versus Ultra’s 90.0%, which extends the known performance ceiling of this task. @OriolVinyalsML and I are very proud of the whole Gemini team, and it’s fantastic to see this progress and to share these highlights from our Gemini Model Family. Read the updated report here:
2
2
30
@_jasonwei Actually, not true in Gemini era. Most innovations have come bottom-up from O(10) brilliant researchers and executors
1
1
46
RT @mmmbchang: Gemini and I also got a chance to watch the @OpenAI live announcement of gpt4o, using Project Astra! Congrats to the OpenAI…
0
248
0
@soumithchintala It’s roughly the same class as models like GPT 3.5 Turbo and Claude 3 Sonnet. It’s free on AI Studio with 1M context
1
0
3