

niki parmar
@nikiparmar09
Followers
9,954
Following
810
Media
7
Statuses
189
Explore trending content on Musk Viewer
Sinwar
• 933241 Tweets
#يحيي_السنوار
• 337694 Tweets
Bluesky
• 251634 Tweets
Calderón
• 216212 Tweets
Tyler
• 100392 Tweets
Rigathi Gachagua
• 86062 Tweets
#TUDUMNaLata
• 85976 Tweets
غير مدبر
• 80359 Tweets
Monsalve
• 79463 Tweets
Rafah
• 66017 Tweets
HAPPY FOURTH DAY
• 60273 Tweets
ابو ابراهيم
• 39660 Tweets
Riggy G
• 36883 Tweets
対象作品
• 22954 Tweets
Macaya
• 22010 Tweets
Karen Nyamu
• 18218 Tweets
Vural Çelik
• 15673 Tweets
Red Bull
• 14798 Tweets
CASA DA VÓ NEUZA
• 14466 Tweets
Sofía Delgado
• 12975 Tweets
Hakan Fidan
• 12653 Tweets
احمد ياسين
• 12267 Tweets
Kawhi
• 11326 Tweets
Alcaraz
• 11231 Tweets




















Pinned Tweet

Thrilled to announce our company, 🚀
We are in an exciting era of human-computer collaboration evolving the way we will reason with, process and generate information.
At Essential AI, we are passionate on advancing capabilities in planning, reasoning,
36
43
596
New Paper:
Stand-Alone Self-Attention in Vision Models
Can attention work as a stand-alone primitive for vision models?
We develop a pure self-attention model by replacing the spatial convolutions in a ResNet by a simple, local self-attention layer.
15
111
449
Life update: For those who haven’t heard, I left Google Brain!
I’m grateful for the 6+ years I spent there, the peers and friends that are inspiring and the opportunities to push on some of the most important problems in AI.
3
5
380
I’m excited to announce our new startup Adept with the mission to build useful general intelligence. We are a research and product lab that is enabling humans and computers to work together collaboratively.

Hello, world! Adept is a new AI research and product lab that aims to build useful general intelligence. What does that mean? Read on for a short introduction, or see our full launch announcement here:
23
115
1K
8
7
335
Our new paper “Image Transformer”, extends self-attention from the original Transformer to much longer sequences on Image Generation and Super-Resolution tasks. It beats previous SOTA autoregressive models like PixelCNN, PixelRNN.

3
61
283
Our paper, Image Transformer got accepted to ICML! 💃🏻💃🏻💃🏻
Our new paper “Image Transformer”, extends self-attention from the original Transformer to much longer sequences on Image Generation and Super-Resolution tasks. It beats previous SOTA autoregressive models like PixelCNN, PixelRNN.
3
61
283
4
18
199
Our paper got accepted to
#Neurips
!!
Code release coming soon, keep an eye out :)
New Paper:
Stand-Alone Self-Attention in Vision Models
Can attention work as a stand-alone primitive for vision models?
We develop a pure self-attention model by replacing the spatial convolutions in a ResNet by a simple, local self-attention layer.
15
111
449
2
26
197
Our paper "Attention Is All You Need" gets SOTA on WMT!!! Faster to train, better results
#transformer
6
39
178
ACT-1 : Transformers that take actions for you in your browser and sheets. Check out some exciting examples below 👇👇
1/7 We built a new model! It’s called Action Transformer (ACT-1) and we taught it to use a bunch of software tools. In this first video, the user simply types a high-level request and ACT-1 does the rest. Read on to see more examples ⬇️
136
917
5K
6
12
158
Check out an early preview of the models we are building at
The future of interaction with computers is going to be massively redefined, starting with a few tools to anything you do with them. Come shape this future at
@AdeptAILabs
- we are hiring.

We made a fun video of some of the earliest things our system can do! If you want to help us build useful general intelligence, please reach out -- we are hiring.
30
105
713
7
3
102
Check out this paper on how de-noising decoders are useful for downstream vision tasks like segmentation. I'm excited about the future of a single, unified model across modalities and tasks.

Announcing decoder denoising pretraining for semantic segmentation:
Take a U-Net, pretrain the encoder on classification, pretrain the decoder on denoising, and fine-tune on semantic segmentation. This achieves a new SoTA on label efficient segmentation.
16
116
660
1
11
99
Hilarious. Machine learning course ads appearing at the back of rickshaws (3 wheeled auto) in 🇮🇳! 😂😂


2
11
79
We presented our work on Image Transformer today at ICML’2018. We show self attention based techniques for Image Generation. Great experience with super colleagues
@ashVaswani
and
@dustinvtran
and others :)

1
1
80
tl;dr Check out our new results on Non Autoregressive MT!! We come very close to a greedy Transformer baseline while being >3x faster!

We develop a non-autoregressive machine translation model whose accuracy almost matches a strong greedy autoregressive baseline Transformer, while being 3.3 times faster at inference. Joint work with
@ashVaswani
@nikiparmar09
Aurko Roy
2
50
209
0
9
45
Constantly amazed by the pace of progress, going from training models with 10^5 params to 10^11. Super excited to share more soon on what's next.
2
0
47
Mesh TensorFlow: A sneak peak of what we've been working on with Noam Shazeer,
@topocheng
and others, to make model parallelism easier to scale to really large models. More details to come soon..

Mesh TensorFlow has been open-sourced in Tensor2Tensor. It's a really promising direction for expressing model parallelism and training large models.
0
3
25
1
2
42
Pre-training on large amounts of text using a Transformer and then performing similar or better on a whole range of NLP tasks using little fine tuning! Impressive results , showing again that increasing compute to train bigger pre-trained models are helpful across various tasks.

Unsupervised pre-training + fine-tuning actually works! (in NLP)
0
58
267
0
14
39
This particular example that generates a 2min long video based on a changing story is really cool
Congrats to all the authors!

5/ A most notable feature of Phenaki is its ability to generate long videos with *prompts changing over time*. These can be thought of as stories, where the user narrates and creates dynamically changing scenes. Here's a 2 minute (!) video from :
2
15
151
1
3
33
Come by our talk and poster today to hear more about Image Generation using Self Attention. Paper:
#ICML2018

Check out the Image Transformer by
@nikiparmar09
@ashVaswani
others and me. Talk at 3:20p @ Victoria (Deep Learning). Visit our poster at 6:15-9:00p @ Hall B
#217
!

0
31
119
1
4
32
Super excited to be on this journey with
@ashVaswani
along with our incredible team
@mrinal_iyer_01
,
@ag_i_2211
,
@samcwl
,
@andrewhojel
and Varun Desai.
We believe that a small, focused team of motivated individuals can create outsized breakthroughs. If you want to work on some
2
1
29
Check out HaloNets, local self-attention that is efficient and gets strong results on ImageNet!
*Faster runtimes
*Parameter efficient
*85.6% Top-1 Accuracy

(1/5) In our recent CVPR paper, we develop a new family of parameter-efficient local self-attention models, HaloNets, that outperform EfficientNet in the parameter-accuracy tradeoff on ImageNet. .
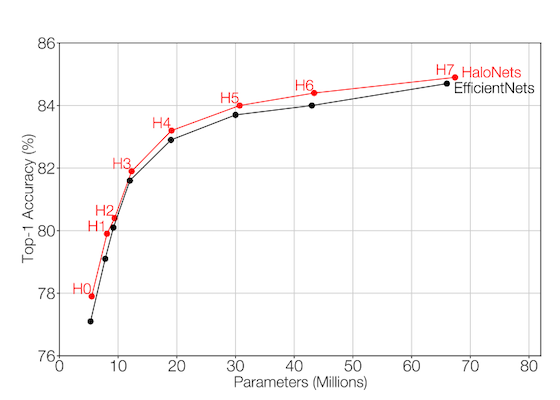
2
44
261
0
1
31
I am at
#NeurIPS18
in Montreal. PM me if you’d like to talk about Generative Models, Model Parallelism or anything else!
We will be presenting our poster on Mesh TensorFlow along with
@topocheng
on Dec 4th, Poster Session A,
#136
.

0
0
25
@ashVaswani
@mrinal_iyer_01
@ag_i_2211
@samcwl
@AndrewHojel
We are thrilled to be partnering with
@MarchCPs
@ThriveCapital
,
@amd
, Franklin Venture Partners (
@FTI_US
), Google, KB Investment,
@nvidia
and the support from our angels,
@amasad
,
@altcap
,
@w_conviction
,
@eladgil
, Francis deSouza, David H. Patraeus,
@GSapoznik
,
@jwmontgomery
,
1
1
24
Great work! Text to text Transformer with a masking loss does better than other Transfer learning techniques.

New paper! We perform a systematic study of transfer learning for NLP using a unified text-to-text model, then push the limits to achieve SoTA on GLUE, SuperGLUE, CNN/DM, and SQuAD.
Paper:
Code/models/data/etc:
Summary ⬇️ (1/14)

9
368
1K
0
5
23

Further studies show that self-attention is the most useful in later layers while convolutions better capture lower-level features. Combining their will be an interesting research direction.
1
2
18
Amazing results by OpenAI on using the GPT Language Model across so many tasks!
It's surprising to see how far, simple unsup LM models with scale, can take us :)

We've trained an unsupervised language model that can generate coherent paragraphs and perform rudimentary reading comprehension, machine translation, question answering, and summarization — all without task-specific training:
172
2K
6K
0
2
14
Particularly excited to see that the model can learn to use a new function based on some documentation from the web.
0
1
14
Thanks Nathan, excited to have you on this journey!

Enter
@AdeptAILabs
' and its brilliant co-founders
@jluan
and
@nikiparmar09
and
@ashVaswani
who building machines to work together with people in the driver's seat: discovering new solutions, enabling more informed decisions, and giving us more time for the work we love.

2
0
14
2
0
13
@ashVaswani
@mrinal_iyer_01
@ag_i_2211
@samcwl
@AndrewHojel
@MarchCPs
@ThriveCapital
@AMD
@FTI_US
@nvidia
@amasad
@altcap
@w_conviction
@eladgil
@GSapoznik
@jwmontgomery
Follow
@essential_ai
for future updates and announcements!
1
0
11
Our human evaluation result is 3x better than Pixel Super Resolution. We beat ppl by a significant margin on ImageNet and match PixelCNN++ on Cifar10 image generation.
1
1
13
This is only a start, I'm excited to see the future of having natural language based interfaces that help you do more complex tasks better.
2
1
12
We are hosting a competition to build efficient neural networks at NeurIPS’19. Submit your entries to help design future hardware and models!

The neural networks we build are designed for the hardware we have, and the hardware we build is designed for the neural networks we have. Help break the wheel — build networks that influence the design of future hardware.
0
21
61
0
2
11
Open-source version of our latest models (Transformer, SliceNet etc)

Announcing the Tensor2Tensor open-source system for training a wide variety of deep learning models in
#TensorFlow
6
500
840
1
0
11
Also attaching our poster from
#NeurIPS18

“Mesh-TensorFlow: Deep Learning for Supercomputers" by Noam Shazeer,
@topocheng
,
@nikiparmar09
and others from
@GoogleAI
. Accepted by
#NeurIPS2018
Read the full paper at


0
1
3
1
1
8
Check out the examples and their attention distributions.

0
1
8


Useful application of model-parallelism for large inputs.

A nice collaboration between
@GoogleAI
researchers and engineers and
@MayoClinic
to use Mesh TensorFlow to deal with very high resolution images that show up when doing machine learning on some kinds of medical imaging data.
0
34
218
0
0
7

Effective Machine Learning With Cloud TPUs. Tune in to find out more about the different tasks you can run on TPUs. Bonus: Performance numbers of various models in terms of time+cost including the Transformer and Image Transformer!!

0
0
6
Simulation of Universe unfolding using MeshTF

The Universe in your hand 🔭💫
Learn how researchers from
@UCBerkeley
and
@NERSC
are using a new simulation code, FlowPM, to create fast numerical simulations of the Universe in TensorFlow.
Read the blog →
0
55
205
0
0
6
To all the women sharing their stories,
#MeToo
. I literally don't know any women who haven't experienced this.
0
0
6
My fantastic peer group who support me and amaze me! Including
@KathrynRough
,
@timnitGebru
, Victoria Fossum and many more!

@JeffDean
s/o to the amazing women I get to work with who inspire and support me. I’ve had so many fantastic mentors, and wanted to highlight how important my peer group has been for my everyday
@huangcza
@nikiparmar09
@ermgrant
@annadgoldie
@yasamanbb
@catherineols
@collinsljas
, & more!
1
2
17
1
0
5
Congratulations
@geoffreyhinton
. This is awe-inspiring.

Yoshua Bengio, Geoffrey Hinton and Yann LeCun, the fathers of
#DeepLearning
, receive the 2018
#ACMTuringAward
for conceptual and engineering breakthroughs that have made deep neural networks a critical component of computing today.

28
1K
3K
0
0
4


@rsprasad
@Google
@GoogleIndia
@PMOIndia
@PIB_India
@_DigitalIndia
@MEAIndia
@vijai63
@ofbjp_usa
@sundarpichai
@RajanAnandan
@DDNewsLive
I saw you outside the Office yesterday. I work at Google and interested to solve problems in weather and farming using AI. Need help with data and resources. Can we connect?
0
0
3
@jekbradbury
The ImageNet experiments are also on 32x32 resolution. The current full autoregressive nature prevents us from going to bigger images. But we want to expand this to bigger images and stronger conditioning in the future
0
0
3
@prafdhar
Congratulations! this is very impressive. Why are the last 5 pixels out of place? Is it the model signature :)
1
0
3
Beating previous ensemble models for En->De by 2 BLEU points and previous single model for En->Fr
1
0
3
A much needed first attempt to compare the effectiveness of different GANs and the effect of hyperparameter tuning on final results.

0
0
3
1
0
3
Impressive

Untethered 'Atlas' robot backflip. Pretty incredible stuff from Boston Dynamics.

32
235
488
1
0
3
Sold out! 😲😱


0
1
3
Content-based interactions prove useful again and hoping to see more of attention for vision in the future!
0
0
2
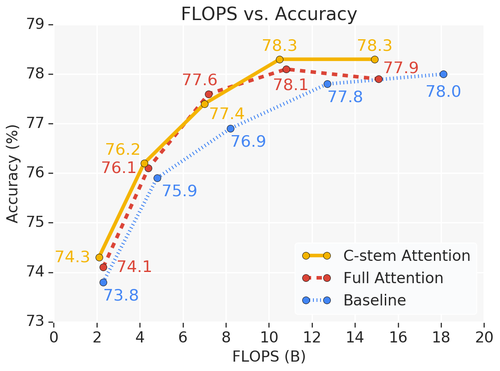
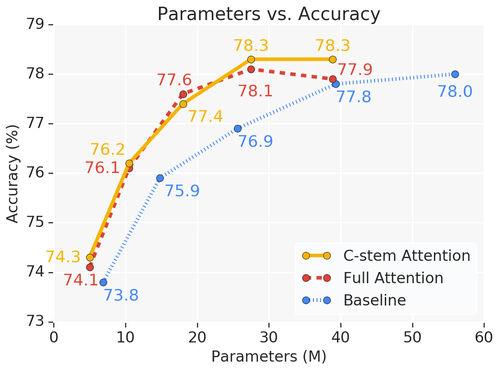
This model outperforms the baseline on ImageNet classification with fewer parameters and FLOPS. On COCO object detection, it matches the mAP of a baseline RetinaNet while having 39% fewer FLOPS and 34% fewer parameters.
1
1
2
Rip

Stephen Hawking once said, "I'm not afraid of death, but I'm in no hurry to die. I have so much I want to do first." RIP Professor Hawking, and may we all strive to live as fully as he did.
32
4K
13K
0
0
2
P.S. We are actively working on this and also have a wish list, contact us if you'd like to help!
1
0
2
Nice extension! Results look much worse but looking forward to parallel generation.
Interesting use of the Transformer () towards non-autoregressive decoding in machine translation!
1
82
208
0
1
2
@MortezDehghani
@USC
@GoogleBrain
I wish I could :) really packed on time, spent the day at ISI. Next time around, I’ll plan well in advance and inform you. Apologies :)
0
0
1
AI principles by Google!

Today we’re sharing our AI principles and practices. How AI is developed and used will have a significant impact on society for many years to come. We feel a deep responsibility to get this right.
223
3K
9K
0
0
1
Reviews on
#iPhonex
after 2 weeks of use
Good: amazing camera, colors and sharpness brilliant, good battery life, Face ID unlock works mostly
Bad: charging slow, feels a bit heavy, Face ID struggles in low battery mode, when using it in bed and when phone is a bit further away
1
0
1
@aertherks
We train both the baseline and our model for the same number of epochs with the same learning rate and scheme and other regularizations.
1
0
0
@kalpeshk2011
@MohitIyyer
@andrewmccallum
@HamedZamani
@YejinChoinka
@Google
Congratulations, Kalpesh! 🎓
0
0
1
@VFSGlobal
I keep getting "User already logged in" or "data not found " error. It's hard to navigate your website and follow the steps.
1
1
1
0
0
1