
Greg Durrett
@gregd_nlp
Followers
7K
Following
3K
Media
83
Statuses
1K
CS professor at UT Austin. Large language models and NLP. he/him
Joined December 2017
📣 Today we launched an overhauled NLP course to 600 students in the online MS programs at UT Austin. 98 YouTube videos 🎥 + readings 📖 open to all!.w/5 hours of new 🎥 on LLMs, RLHF, chain-of-thought, etc!. Meme trailer 🎬. 🧵.
3
62
309



there's not enough hype around NLP so i made this to kick off my class today:.
17
42
381
Over the past two years at UT I've developed some NLP course materials. I talked to a couple folks at NAACL who had found these useful, so I wanted to give a quick self plug. Still a work in progress, of course:.Grad: Ugrad:
3
87
340



HVAC guy: you need to replace the transformer. do you know what a transformer is?.me: yes of course. wait. .
10
16
218
We ( @bhavana_dalvi , @peterjansen_ai , @danilodnr2 , @_jasonwei , and Lionel Wong from @MITCoCoSci ) are excited to announce the 1st Workshop on Natural Language Reasoning and Structured Explanations, co-located with ACL 2023. 🧵.
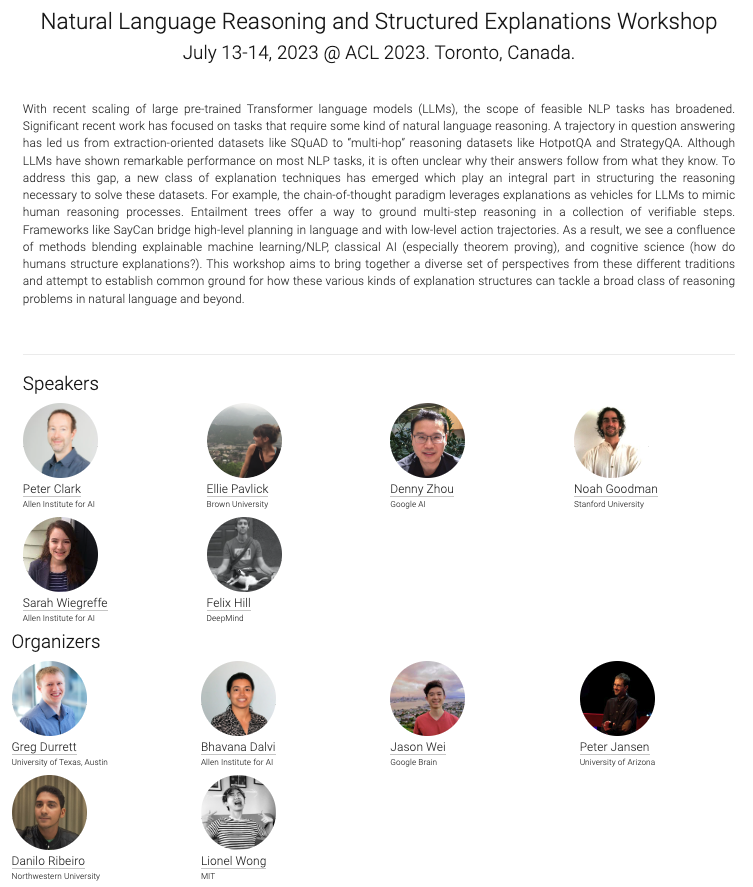
1
51
223


Check out Tanya's paper! GPT-3 is a huge paradigm shift for summarization that the community hasn't fully digested yet. You should play around with davinci-002 for your own summ tasks! If there's something you always wanted to do but didn't have data for, it might work zero-shot!.

✨New preprint✨.Zero-shot GPT-3 does *better* at news summarization than any of our fine-tuned models. Humans like these summaries better. But all of our metrics think they’re MUCH worse. Work/ w/ @jessyjli, @gregd_nlp. Check it out here: [1/6]

4
32
192
This is a cool method, but "superhuman" is an overclaim based on the data shown. There are better datasets than FActScore for evaluating this:.ExpertQA by @cmalaviya11 +al.Factcheck-GPT by Yuxia Wang +al (+ same methodology) 🧵.

Finding 3 😯. LLM agents are better factuality annotators than humans!. SAFE achieves superhuman performance, agreeing with 72% of human annotations and winning 76% of randomly-sampled disagreement cases. SAFE is also more than 20× cheaper than human annotators. 4/

3
26
181

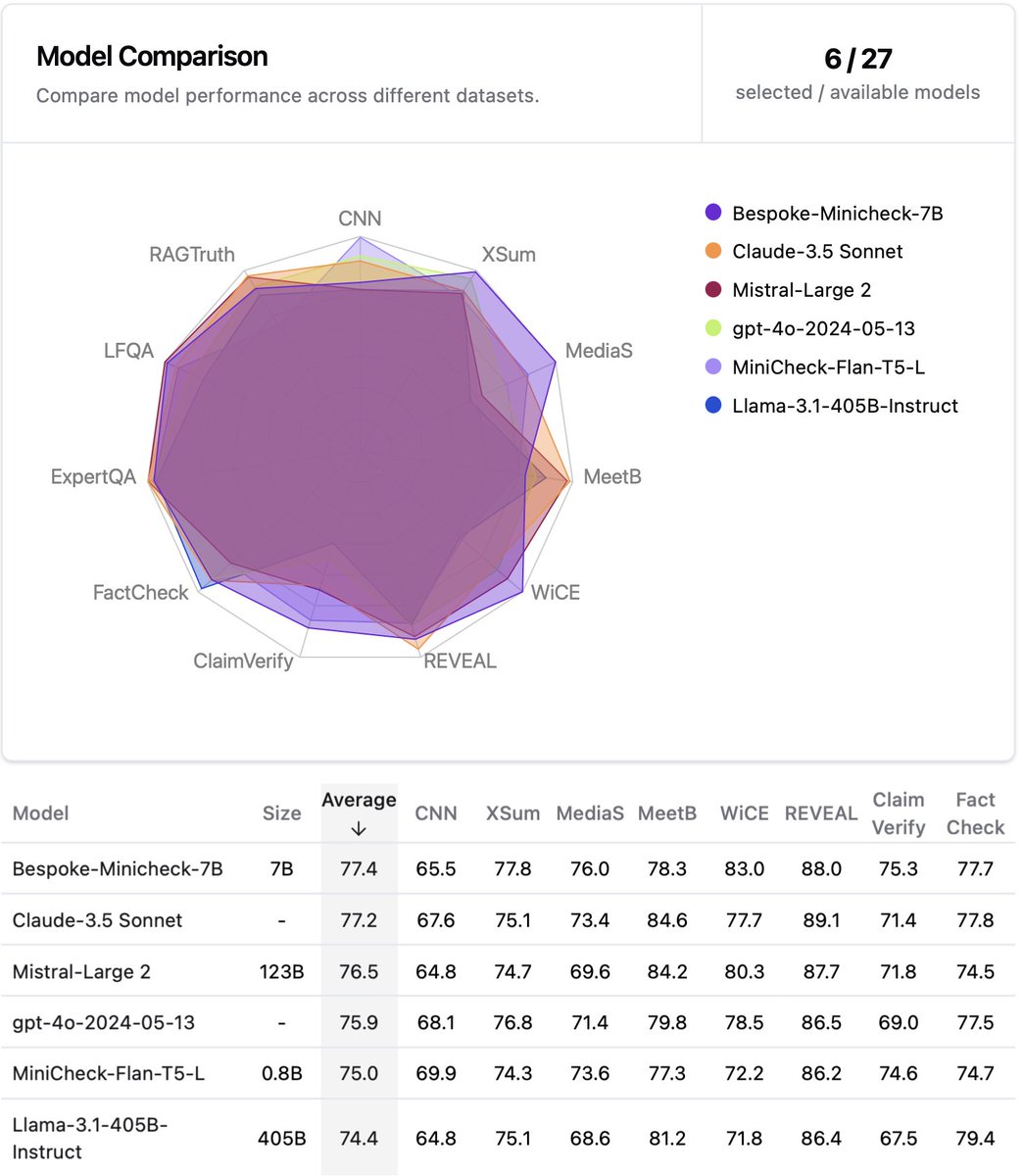
🤔 Want to know if your LLMs are factual? You need LLM fact-checkers. .📣 Announcing the LLM-AggreFact leaderboard to rank LLM fact-checkers. .📣 Want the best model? Check out @bespokelabsai’s’ Bespoke-Minicheck-7B model, which is the current SOTA fact-checker and is cheap and


3
38
168
This project started with us annoyed at papers evaluating CoT "reasoning" with only GSM8k & MATH. We didn't expect to find such strong evidence that these are the only type of problem where CoT helps!. Credit to @juand_r_nlp & @kmahowald for driving the rigorous meta-analysis!.

To CoT or not to CoT?🤔. 300+ experiments with 14 LLMs & systematic meta-analysis of 100+ recent papers. 🤯Direct answering is as good as CoT except for math and symbolic reasoning.🤯You don’t need CoT for 95% of MMLU!. CoT mainly helps LLMs track and execute symbolic computation



6
33
163
what could be scarier than us all losing our jobs of designing bespoke neural network architectures?!?!. also costume not even sota anymore, feels bad

5
4
144
Two teaching materials announcements:.1. We just wrapped up an NLP course for our online MS program at UT. Videos available here:. 2. Paper to appear @TeachingNLP describing the assignments (also used in our grad/ugrad courses):.

2
35
129
*Very* strong results in this work and some cool analysis (looking at how different levels of the LM correlate with different linguistic representations). Seems like using LM representations like this might become part of the standard methodology for neural net modeling in NLP.

Deep contextualized word representations @LukeZettlemoyer @kentonctlee.
2
26
116


🔥 The program for the NLRSE workshop at #ACL2023NLP is posted 🔥.In addition to the 5 invited talks, we have a fantastic technical program with 70 papers being presented! Make sure you stick around on Thursday after the main conference!.
1
18
88
We ( @gregd_nlp , @bhavana_dalvi , @peterjansen_ai , @danilodnr2 , @xiye_nlp , @wzhao_nlp , @ben_lipkin , and Lionel Wong from @MITCoCoSci ) are excited to announce the 2nd Workshop on Natural Language Reasoning and Structured Explanations (NLRSE), co-located with ACL 2024. 🧵

1
25
78
the AC who desk rejected this paper when they open twitter


Just got a desk reject, post-rebuttals, for a paper being submitted to arxiv <30 min late for the anonymity deadline. I talk about how the ACL embargo policy hurts junior researchers and makes ACL venues less desirable for NLP work. I don’t talk about the pointless NOISE it adds.
1
4
77

Xi's was our first project using GPT-3. What was really shocking to me was just how easily GPT-3 would output totally bogus explanations for very simple tasks! In-context learning clearly has potential, but this has definitely made me skeptical about its ability to do “reasoning”.

Can GPT-3 generate reliable explanations for textual reasoning tasks? Not really❌. Check out our (with @gregd_nlp) new preprint “The Unreliability of Explanations of Few-Shot In-Context Learning”: [1/6]

1
10
73
when your character-level LM hasn't converged yet.

AAAAAAAAAAAAAHHHHHRHRGRGRGRRRGURBHJB EORWPSOJWPJORGWOIRGWSGODEWPGOHEPW09GJEDPOKSD!!!!!!!!!!!!!!!0924QU8T63095JRGHWPE09UJ0PWHRGW.
1
7
72
Like long-context LLMs & synthetic data? Lucy's work extends LLM context lengths on synthetic data and connects (1) improvements on long-context tasks; (2) emergence of retrieval heads in the LLM. We're excited about how mech interp insights can help make better training data!.

1/ When does synthetic data help with long-context extension and why?. 🤖 while more realistic data usually helps, symbolic data can be surprisingly effective. 🔍effective synthetic data induces similar retrieval heads–but often only subsets of those learned on real data!


1
9
78
At #NAACL2024 with two orals in Semantics Monday @ 2pm:.1. X-PARADE presented by @juand_r_nlp .2. A full pipeline for real-world claim verification by @Jifan_chen , presented by me.Two hard problems + datasets involving subtle meaning distinctions that LLMs haven't solved yet!


0
10
76
Two papers from my group at #NAACL2022:. @JiachengNLP, Sid J Reddy: lattice decoding for text generation.Sess. 1B talk; @yasumasa_onoe, @mjqzhang, @eunsolc: a cloze task for testing entity knowledge in language models.9F poster;
2
13
73


Wager established. Jonathan Frankle (@jefrankle) stepped up to my Transformer long bet. I'm counting on you. You only have 1700 days!

1
0
72
Our NLP module for high schools was covered in this KXAN piece about generative AI in schools. My first time on TV!


Students heading back to school this semester are entering the classroom with a new tool that experts say could soon be as common as a calculator.
2
7
70
New work in #EMNLP2021 about deduction in natural language! Our first step in a direction I'm super excited about: how can we build textual reasoning systems that actually synthesize conclusions as they go? (Rather than, say, extracting a chain of sentences as a loose rationale.).

In our new work (@ EMNLP ‘21, w/Lucy Zhao, @swarat, @gregd_nlp), we train models to generate deductions from natural language premises without human labeling! (1/8)

2
13
66
Continuing from NAACL21, the #EMNLP2021 publication chairs (incl. me) can assist folks who have changed their names and want to make sure they are cited correctly in camera-readies. If this applies to you, please email or DM me by September 12! More info:
1
10
61

Folks from my lab @ #ACL2023NLP are presenting on generation factuality, knowledge updates in LMs, NL reasoning, efficient generation reranking, etc! Feel free to reach out!.Attending:@prasann_singhal @ManyaWadhwa1 @juand_r_nlp @yasumasa_onoe @ZayneSprague

0
14
68

Anisha spent a lot of time thinking about what we want from "atomic facts" when fact-checking LLM outputs. There's not one magic decomposition for all applications, but minimality & decontextuality are pretty universal criteria, and we present a method that balances them!.

Challenges of LLM fact-checking with atomic facts:.👉 Too little info? Atomic facts lack context.👉 Too much info? Risk losing error localization benefits. We study this and present 🧬molecular facts🧬, which balance two key criteria: decontextuality and minimality. w/@gregd_nlp

2
4
64
Check out Fangcong's work leveraging mechanistic interpretability insights for model fine-tuning!. What I find most interesting is that finding the right set of attention heads to tune offsets for *does* make a difference on downstream performance. Reasoning "skills" in LLMs.

🔬LoFiT: Localized fine-tuning of LLM representations. We fine-tune an LLM by.🔍Finding important attn heads for a task (3-10% of the Transformer).🔥Learning offsets to the representations of these heads. Comparable acc. to LoRA w/200x fewer learned params. w/@xiye_nlp @gregd_nlp

1
11
66
I'll be at #NeurIPS2023 Mon-Fri, w/@xiye_nlp presenting on LLM reasoning with SMT solvers + @shankarpad8 presenting on knowledge editing (from @eunsolc's lab). Happy to chat about these + other topics in LLM reasoning/factuality/&c!.
1
11
65
New benchmark for understanding knowledge editing for code! This is a nice testbed for exploring alternatives to RAG: we should be able to teach models about new APIs without having to put all the info in context. But this doesn't work yet and a lot more research is needed!.

Knowledge updates for code LLMs: Code LLMs generate calls to libraries like numpy and pandas. What if these libraries change? Can we update LLMs with modified function definitions?. Test this with our new benchmark, CodeUpdateArena. Findings: updating LLMs’ API knowledge is hard!

0
8
64

Check out Prasann's analysis of length in reward models/RLHF! I think we're still in the early stages of getting reward modeling to work well. Tricks from dataset analysis in NLP (like dataset cartography which we looked at here) and NLG eval principles can help us do this better.

Why does RLHF make outputs longer?. w/ @tanyaagoyal @JiachengNLP @gregd_nlp. On 3 “helpfulness” settings.- Reward models correlate strongly with length.- RLHF makes outputs longer.- *only* optimizing for length reproduces most RLHF gains. 🧵 below:

0
9
62
@yoavartzi @COLM_conf 8 = top 50% of accepted papers.average of 8 = the best paper in the entire conference

2
1
62
Check out @JiachengNLP's latest work on decoding lattices from generation models! I'm super excited about the potential of lattices that encode lots of options. There are great model outputs that are the 1,000,000th most likely candidate but too hard to find with current methods.

☞ New preprint with @gregd_nlp: We propose a new search algorithm for neural text generation models to efficiently produce thousands of outputs encoded as a lattice🕸️. Two key ideas: (1) best first search, (2) hypothesis recombination. Thread 🧵


1
8
57
New #acl2020nlp paper from my student Tanya @tanyaagoyal . Learning how to apply syntactic transformations for diverse paraphrase generation in transformer-based models!.
New work "Neural Syntactic Preordering for Controlled Paraphrase Generation" (with @gregd_nlp) at #acl2020nlp!. Basic Idea: Break paraphrasing into 2 steps: "soft" reordering of input (like preordering in MT) followed by rearrangement aware paraphrasing.1/
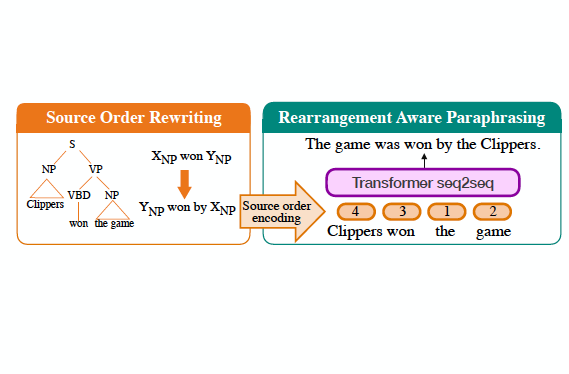
2
9
53
Come chat with my students about their work this week at #emnlp2020 ! Details about their presentations here: First: main conference presentations, including summarization, program synthesis, analysis of pre-trained models, and question generation 1/2

1
10
55
In the ChatGPT era a lot of folks are looking at attribution and factuality lately! We think this paper provides some interesting food for thought if you're contrasting different approaches (QA vs entailment). Beyond ours, there's lots of summarization work on this problem (🧵).

Our paper "Shortcomings of Question Answering Based Factuality Frameworks for Error Localization" has been accepted at #EACL2023 main track!. arXiv: work with @tanyaagoyal @gregd_nlp.
1
7
56
In Vienna for two 🔦 spotlights at #ICLR2024 . 🕵MuSR by @ZayneSprague +al, Tues 10:45am . 🧑💻✍️ Coeditor by @MrVPlusOne with @IsilDillig , Thurs 10:45am (presented by me). DM me if you're interested in chatting about these, reasoning + factuality in LLMs, RLHF, or other topics!


3
13
54
Check out Manya's new work on refining responses with LLMs! The three steps here (detect, critique, refine) involve different LLM competencies, and tailoring models to these steps improves over "standard" refinement (esp. on detect + critique).

Refine LLM responses to improve factuality with our new three-stage process:. 🔎Detect errors.🧑🏫Critique in language.✏️Refine with those critiques. DCR improves factuality refinement across model scales: Llama 2, Llama 3, GPT-4. w/ @lucy_xyzhao @jessyjli @gregd_nlp 🧵

1
6
53
Very proud of everything @xiye_nlp has accomplished during his PhD and super excited to see what he does next! We'll miss him at UT!.
I am very excited to share that I am joining University of Alberta @UAlberta as an assistant professor in Summer 2025. Before that, I will spend a year at Princeton PLI @PrincetonPLI working on language models.
0
0
51
Check out Shankar's #NeurIPS2023 paper on knowledge editing and knowledge propagation in LLMs! Follows on @yasumasa_onoe's ACL 2023 paper ( ) which outlined challenges in this space; now we've made some progress on those challenges!.

How do we teach LMs about new entities? Our #NeurIPS2023 paper proposes a distillation-based method to inject new entities via definitions. The LM can then make inferences that go beyond those definitions!.w/@yasumasa_onoe, @mjqzhang, @gregd_nlp, @eunsolc
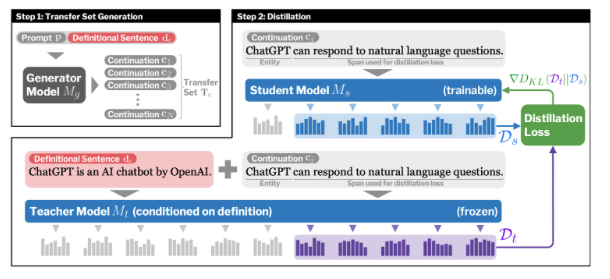
0
7
51
I'll be attending EMNLP in person! My group's papers here focus on QA, automated reasoning, and program synthesis:. Please find my co-authors ( @alephic2 @xiye_nlp @Jifan_chen ) virtually, and feel free to ping us on Twitter or email to find time to chat!

0
4
50
New work with @tanyaagoyal "Annotating and Modeling Fine-grained Factuality in Summarization” in NAACL21:.We study factuality evaluation across 2 different summarization domains to see where current data creation strategies and models succeed and fail.
2
12
49

At COLM w/.@ManyaWadhwa1: work on 🧑⚖️ using NL explanations in evaluation.@prasann_singhal: work on (1) 📈 length correlations in RLHF (oral Mon. pm); (2) ♻️ D2PO: using reward models updated online in DPO. Happy to talk about eval, post-training, factuality & reasoning in LLMs!.
1
11
49
I'm excited about Manya's work on using LLMs to understand NL explanations in annotation. Often when we read an annotator's explanation, we find that the label they picked is well-justified, even if it disagreed with others. Our first foray to take advantage of such explanations!.
Excited to share our updated preprint (w/ @jfchen, @jessyjli , @gregd_nlp). 📜 We show that LLMs can help understand nuances of annotation: they can convert the expressiveness of natural language explanations to a numerical form.🧵

0
7
48
NLP4Prog is tomorrow (Friday) at #ACL2021NLP ; program here:.Beyond the invited talks, let me highlight our four contributed talks that will appear there (purely based on my personal assessment, not an official workshop stance :) ). Thread 🧵.
1
9
48
Nice interview with @kchonyc . Completely agree about reading papers: reading too many other papers "traps" you in the vein of thinking like those other authors. Your own investigation helps you figure out what incorrect assumptions they made and lets you find new directions.

Thoughts on ML research from @kchonyc. “Excessively reading papers can hold back a researcher from trying out new ideas. Hence a researcher might step back from trying a model, because someone did not succeed previously in the same direction.”.
0
9
45
Come see our presentations at EMNLP!.All of these papers represent directions in textual reasoning and summarization that have been in the works for a while and I'm excited that we're finally sharing them! Up tomorrow: @tanyaagoyal and @ZayneSprague

0
11
45
Important, understudied problem: what sorts of faithfulness errors show up in *extractive* summaries? Really thorough study and interesting taxonomy! (Hot take: extractive summ is still much more useful than abstractive in most applications, despite less research attention now.).

Are extractive summaries always faithful? Turns out that is not the case! We introduce a typology, human error annotations & new evaluation metric for 5 broad faithfulness problems in extractive summarization! .w/ @meetdavidwan @mohitban47. Paper: 🧵👇


1
5
46
Is there a recipe (especially dataset) for getting a good fine-tune out of an 8B parameter base model? It seems academic-scale PPO or DPO runs on HH-RLHF/UltraFeedback/etc only move the needle on certain narrow capabilities, not making big deltas like the Llama fine-tune 🧵.
7
7
46
Check out Liyan's system + benchmark! Strong LLM fact-checking models like MiniCheck will allow response refinement and training for better factuality (work in progress!). LLM-AggreFact collects 10 high-quality labeled datasets of LLM errors in the literature to evaluate them!.

🔎📄New model & benchmark to check LLMs’ output against docs (e.g., fact-check RAG). 🕵️ MiniCheck: a model w/GPT-4 accuracy @ 400x cheaper. 📚LLM-AggreFact: collects 10 human-labeled datasets of errors in model outputs. w/ @PhilippeLaban, @gregd_nlp 🧵

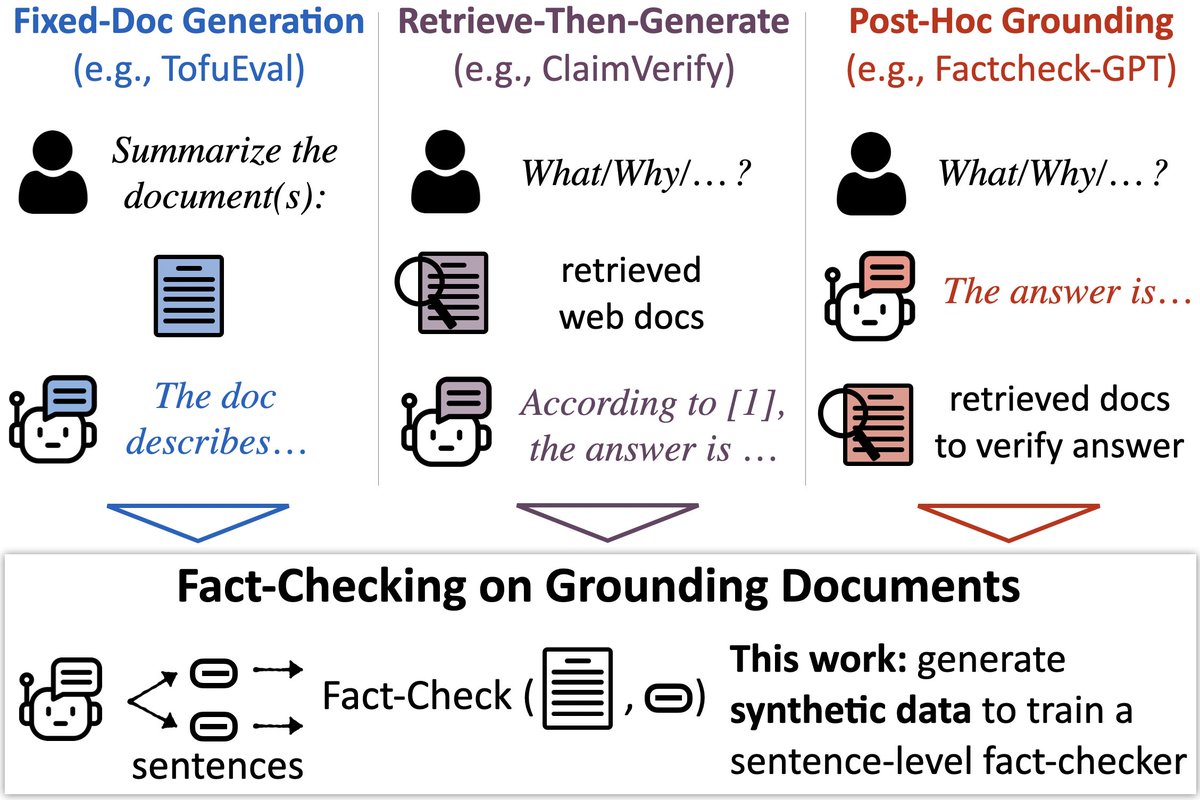
1
9
44

This is chilling. We already had plans to discuss Timnit's incredible work in my NLP course tomorrow, and this is definitely being brought up.

Apparently my manager’s manager sent an email my direct reports saying she accepted my resignation. I hadn’t resigned—I had asked for simple conditions first and said I would respond when I’m back from vacation. But I guess she decided for me :) that’s the lawyer speak.
0
2
43
This Sunday at #AAAI2020, Yasumasa Onoe will be presenting his paper "Fine-Grained Entity Typing for Domain-Independent Entity Linking". Poster attached, description follows. 1/

2
5
44
Learned a valuable lesson from the EMNLP deadline. nah who am I kidding we're definitely gonna keep submitting papers like 2 minutes before the deadline.
1
0
43
The DeepLo workshop@EMNLP submission deadline is this coming Monday, August 19. Details: All work related to low-resource deep learning techniques welcome! Send in your brilliant EMNLP rejects!. Also, register! We have a great lineup of invited speakers.
0
17
43
Sad to miss EMNLP, but folks who are there can catch @RyoKamoi presenting WiCE.(w/ @tanyaagoyal there). @xiye_nlp's paper on ICL. and @YatingWu96 + @ritikarmangla + @jessyjli on QUD discourse parsing eval.
0
8
44

New dataset focused on commonsense claims surrounding entities! I think there's a nice intersection of entity knowledge + properties (what this entity is) with affordances (what can something with those properties do), plus lots of other types of reasoning here!.

We've created CREAK, a dataset of commonsense statements about entities, -- this is an easy dataset for people, so why can't LMs get 100% accuracy? Better entity modeling and representation is needed!. Paper: w/ @mjqzhang, @eunsolc, @gregd_nlp

0
11
43
Excited to be a part of the NSF-Simons AI Institute for Cosmic Origins!! Great interdisciplinary team, and already some exciting projects in progress on specialized foundation models, coding assistants for researchers, scientifically-grounded LLMs. stay tuned!.

A new institute coming to the Forty Acres will harnesses artificial intelligence to explore some of the leading mysteries of the universe, including dark matter and the fundamentals related to the search for life 🌌🤘. @OdenInstitute | #TexasAI .
0
2
42
As the NLP community grows, having a winter NLP conference is really a natural step to take. Reduces pressure on existing conferences that come towards the end of the current "cycle" (EMNLP) and lets folks get their work out there more promptly (esp. internship projects).

@SeeTedTalk @NAACLHLT how wd y'all react to even earlier? like early Jan? the main two ways that, eg, LSA keeps their costs down are a) early jan conference and b) book locations waaaay in advance. we'd then have, roughly:.01 -- naacl.04 -- eacl.07 -- acl.10 -- emnlp.11/12 -- ijcnlp.reasonably balaced.
2
5
40
New preprint with Shih-Ting Lin and @NateChambers about modeling temporally-ordered event sequences:.We train a BART-based denoising autoencoder over linearized SRL event representations to make several.kinds of temporal-related event inferences 1/2

1
5
42
Next week at EMNLP, Aditya Gupta will be presenting his work on "Effective Use of Transformer Networks for Entity Tracking". This paper studies procedural text: descriptions of processes involving complex entity interactions like recipes, scientific processes, etc 1/n.
1
7
42
Also, if you're an author of an EMNLP camera-ready, you can help by using rebiber to make sure you're citing everything and everyone correctly! (Thanks @billyuchenlin for the great tool!) .
0
11
38

New at #EMNLP2020 Findings by @yasumasa_onoe : "Interpretable Entity Representations through Large-Scale Typing". Entity mentions are represented as vectors of type posteriors: each coordinate is the posterior prob of a type under a typing model 1/4

1
8
38
Missing the main NAACL deadline? If you're a student, consider submitting to the NAACL Student Research Workshop. New this year there is a non-archival option so you can submit work in progress, get mentorship, and later submit to a main conf. Details:

Call for Papers for the Student Research Workshop is out! .Pre-submission applications for mentorship due January 11.
0
22
39
Check out Jiacheng + Shrey's #EMNLP2020 paper about entropy as a way of analyzing text generation models. Nucleus/top-k showed us that there's a lot going on in the next-word distributions -- I think this is a nice technique for "reading the tea leaves" and getting some insights.
In our #EMNLP2020 paper “Understanding Neural Abstractive Summarization Models via Uncertainty“ (w/ @shreydesai @gregd_nlp), we investigate the behavior of abstractive summarization models by measuring the *uncertainty* of the model prediction. arXiv:
0
3
39
Congrats Tanya! Prospective NLP students, you now have even more reason to apply to Cornell!.
I will join Cornell CS @cs_cornell as an assistant professor in Fall 2024 after spending a year at @princeton_nlp working on all things language models. I will be posting about open positions in my lab soon but you can read about my research here:
0
2
38
newest track at ICML.


2
6
37

New paper out on calibration from @shreydesai , with a particular focus on challenging cross-domain settings. Shrey got me interested in this problem, and I think it should be studied more -- something to look at beyond cross-domain accuracy as a piece of the BERTology puzzle.

New preprint--"Calibration of Pre-trained Transformers" (. We show BERT and RoBERTa's posterior probabilities are relatively calibrated (i.e., consistent with empirical outcomes) on three tasks with both in-domain and challenging out-of-domain settings. 1/


1
3
37
Papers at ACL being presented by my students over the next few days: tonight/tomorrow, learn about diversifying paraphrase generation through better syntactic control by @tanyaagoyal .Paper link: Talk: (Session 1A, 4B) 1/n

1
9
37
Strongly agree with this, especially test-only benchmarks! If I have all QA/summarization/etc. corpora in the world available to me, how quickly can I as a practitioner make a system work well for a new setting with <N human hours of work? This is what I want to see!.

I wrote a position piece for the ACL (as part of the "taking stock" thematic session) that argues for a greater focus on generalization in evaluating natural language understanding models:
2
5
37
Check out Yasu's latest paper at #ACL2023NLP ! If you're interested in fact editing in LMs, we think our datasets and analysis show a new side of what's going on. We've been learning a lot from this investigation and we think it can lead to better knowledge updating methods soon!.
Knowledge in LMs can go out of date. Our #ACL2023NLP paper investigates teaching LMs about new entities via definitions, and whether LMs can then make inferences that go beyond those definitions. w/@mjqzhang, @shankarpad8, @gregd_nlp, @eunsolc

0
6
37
NLRSE starts in 12 hours! Virtual posters at 8am, then starting at 9am in Pier 4!. 5 great invited talks, 4 oral papers, and many posters! See the finalized schedule at. Posters, Zoom link, and Gathertown at.(requires registration)

🔥 The program for the NLRSE workshop at #ACL2023NLP is posted 🔥.In addition to the 5 invited talks, we have a fantastic technical program with 70 papers being presented! Make sure you stick around on Thursday after the main conference!.
0
8
36
UT is adding an MSAI to its online offerings. I've been teaching NLP for the online MSCS/MSDS and it's a lot of fun. We get great students with interesting backgrounds who wouldn't pursue an on-campus program (e.g., mid-career folks). Newly overhauled NLP course coming this fall!.

The University of Texas at Austin will start a large-scale, low-cost online Master of Science degree program in artificial intelligence, the institution announced. The new program could help swiftly expand the AI work force in the U.S.
0
3
35
Bespoke-MiniCheck now available in ollama!.

ollama run bespoke-minicheck. @bespokelabsai released Bespoke-Minicheck, a 7B fact-checking model is now available in Ollama! It answers with Yes / No and you can use it to fact check claims on your own documents. How to use the model with examples: .
3
1
35
Excited for the 2nd edition of Natural Language Reasoning and Structured Explanations #ACL2024NLP this Thursday August 15!. Invited talks by @tongshuangwu @karthik_r_n Thomas Icard @xiang_lorraine . Plus 6 oral talks and 39 total accepted papers! See schedule below and link in🧵


1
10
35
@mark_riedl My group enjoyed reading this paper from @timo_schick and Hinrich Schütze:.where they compare to and beat GPT-3 at few-shot learning without having access to it (see footnote 6). (100% agree with your concern though, as a "loser". ).
1
0
34
Check out @tanyaagoyal 's new work on factuality in generation! I'm excited to explore these more fine-grained notions of what it means for a summary/paraphrase to be correct. Tanya has work in progress on broadening this and using it for downstream tasks -- stay tuned!.
Our paper "Evaluating Factuality in Generation with Dependency-level Entailment" (w/ @gregd_nlp) to appear in Findings of #EMNLP2020!.We decompose the sen-level factuality into entailment evaluation of smaller units (dependency arcs) of the hypotheses

0
5
35
Really excited about this dataset, unifying a flexible specification of discourse structure with existing reading comprehension work. We see lots of intersections between this and our other projects in areas like summarization, so we're optimistic that it can be broadly useful!.

Excited to share DCQA (Discourse Comprehension by Question Answering), a scalable data collection framework + 22K training data capturing semantic and discursive relationships between sentences via free-form questions and their answers (1/2)


0
2
35