

Ryo Kamoi
@RyoKamoi
Followers
833
Following
8K
Media
78
Statuses
1K
#NLProc PhD student @PennStateEECS @RuiZhang_nlp. Trustworthy NLP. Prev: MS @UTCompSci, BE @Keio_ST, Intern @AmazonScience. @RyoKamoi_ja
State College, PA
Joined April 2017
📢 New survey on Self-Correction of LLMs!.😢 LLMs often cannot correct their mistakes by prompting themselves.😢 Many studies conduct unfair experiments.😃 We analyze requirements for self-correction🧵.@YusenZhangNLP @NanZhangNLP Jiawei Han @ruizhang_nlp.


4
62
197
Both OpenAI o1 and Reflection 70B take the approach of refining their own responses. These are great milestones, but this approach has a long history. If you are interested in self-correction of LLMs, check our recent critical survey!.(TACL, to appear).
10
61
368
Curious about LLM self-correction? Check out our reading list!.📚 We feature papers & blogs in.* Key self-correction papers.* Negative results in self-correction.* Projects inspired by OpenAI o1.
1
28
149
海外院試についてブログ記事を書きました。PhD進学を断念したり、Masterでも進学先のUT Austin以外は全部落ちたりとあんまり上手くいかなかった私の経験ですが、参考になる人もいるかなと思います。. 海外院試の記録(修士、CS・機械学習).
2
16
123
New dataset for Doc-level NLI!.Looking for a dataset with realistic claims and premises? Check out WiCE! WiCE annotates claims in Wikipedia with entailment labels wrt cited articles. w/ @tanyaagoyal @juand_r_nlp @gregd_nlp.data: 1/

3
23
124
本日、学位記とともに慶応工学会賞を頂きました。卒業式で表彰された成績優秀者表彰とは別の賞ですが、金時計は密かに目指していたのでとても嬉しいです🥇


5
4
114
Our critical survey on Self-Correction of LLMs has been accepted to TACL!.We analyze when LLMs can/cannot refine their own responses. When Can LLMs Actually Correct Their Own Mistakes? A Critical Survey of Self-Correction of LLMs.[updated!].
📢 New survey on Self-Correction of LLMs!.😢 LLMs often cannot correct their mistakes by prompting themselves.😢 Many studies conduct unfair experiments.😃 We analyze requirements for self-correction🧵.@YusenZhangNLP @NanZhangNLP Jiawei Han @ruizhang_nlp.
4
27
117
📢 New preprint! Do LVLMs have strong visual perception capabilities? Not quite yet. We introduce VisOnlyQA, a new dataset for evaluating the visual perception of LVLMs, but existing LVLMs perform poorly on our dataset. [1/n].


1
19
105
📢 New Preprint! Can LLMs detect mistakes in LLM responses?.We introduce ReaLMistake, error detection benchmark with errors by GPT-4 & Llama 2. Evaluated 12 LLMs and showed LLM-based error detectors are unreliable!.@ruizhang_nlp @Wenpeng_Yin @armancohan +.

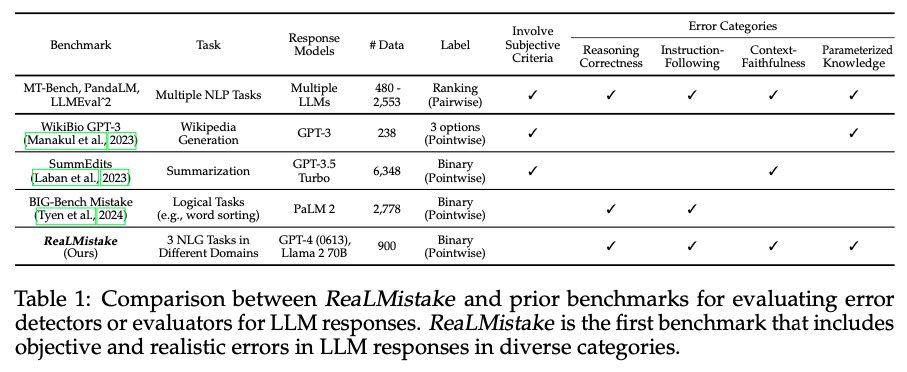
4
25
96
We will present our survey on self-correction (TACL, to appear) at #EMNLP2024! Let's discuss the future of inference-time scaling. When Can LLMs Actually Correct Their Own Mistakes? A Critical Survey of Self-Correction of LLMs.
📢 New survey on Self-Correction of LLMs!.😢 LLMs often cannot correct their mistakes by prompting themselves.😢 Many studies conduct unfair experiments.😃 We analyze requirements for self-correction🧵.@YusenZhangNLP @NanZhangNLP Jiawei Han @ruizhang_nlp.
5
14
91
無事に慶應義塾大学を卒業しました。4月からは東京大学大学院情報理工学系研究科コンピュータ科学専攻に進学し、相澤彰子研究室にお世話になる予定です。.
1
4
75
Our ReaLMistake paper has been accepted at @COLM_conf !.We introduce the ReaLMistake benchmark for evaluating LLMs at detecting errors in LLM responses. Our experiments show that even strong LLMs detect errors in LLM responses with very low recall.
📢 New Preprint! Can LLMs detect mistakes in LLM responses?.We introduce ReaLMistake, error detection benchmark with errors by GPT-4 & Llama 2. Evaluated 12 LLMs and showed LLM-based error detectors are unreliable!.@ruizhang_nlp @Wenpeng_Yin @armancohan +.
2
14
74
Thank you for coming to my oral talk!.It was great to speak in front of a large audience😃. Here is a video if you missed my talk👇.

📢 New survey on Self-Correction of LLMs!.😢 LLMs often cannot correct their mistakes by prompting themselves.😢 Many studies conduct unfair experiments.😃 We analyze requirements for self-correction🧵.@YusenZhangNLP @NanZhangNLP Jiawei Han @ruizhang_nlp.
1
8
60
We will present our survey on self-correction of LLMs (TACL) at #EMNLP2024 in person!. Oral: Nov 12 (Tue) 11:00- (Language Modeling 1). When Can LLMs Actually Correct Their Own Mistakes? A Critical Survey of Self-Correction of LLMs
📢 New survey on Self-Correction of LLMs!.😢 LLMs often cannot correct their mistakes by prompting themselves.😢 Many studies conduct unfair experiments.😃 We analyze requirements for self-correction🧵.@YusenZhangNLP @NanZhangNLP Jiawei Han @ruizhang_nlp.
1
11
58
色々と手続が進んだのでご報告です。2020年度秋学期からテキサス大学オースティン校のCS修士課程(MSCS)に進学する予定です。新型コロナ感染症の影響で予定通りに進まないことも多いと思いますが、頑張っていきたいと思います。.
1
3
56
I’m thrilled to share that I’ll start my PhD this fall @PennStateEECS under the supervision of @ruizhang_nlp!.
11
2
54
Excited to share that our WiCE paper has been accepted to #EMNLP2023 !.Check out our new dataset for Doc-level NLI!. Many thanks to @gregd_nlp and to my wonderful co-authors @tanyaagoyal @juand_r_nlp!. data: updated!.arxiv: updated!.
New dataset for Doc-level NLI!.Looking for a dataset with realistic claims and premises? Check out WiCE! WiCE annotates claims in Wikipedia with entailment labels wrt cited articles. w/ @tanyaagoyal @juand_r_nlp @gregd_nlp.data: 1/
0
11
53
Our paper "Shortcomings of Question Answering Based Factuality Frameworks for Error Localization" has been accepted at #EACL2023 main track!. arXiv: work with @tanyaagoyal @gregd_nlp.
New preprint.QA metrics are quite popular in factuality eval, in part because it's believed that they are interpretable and can localize errors. We show that this is *not* true! Their localization is worse than simple exact match!.w @tanyaagoyal @gregd_nlp

1
8
50
New preprint.QA metrics are quite popular in factuality eval, in part because it's believed that they are interpretable and can localize errors. We show that this is *not* true! Their localization is worse than simple exact match!.w @tanyaagoyal @gregd_nlp
2
12
48
Our oral talk about self-correction of LLMs (TACL) at #EMNLP2024 is today!. Oral: Nov 12 (Tue) 12:15-12:30 (Ashe Auditorium, Language Modeling 1). When Can LLMs Actually Correct Their Own Mistakes? A Critical Survey of Self-Correction of LLMs

📢 New survey on Self-Correction of LLMs!.😢 LLMs often cannot correct their mistakes by prompting themselves.😢 Many studies conduct unfair experiments.😃 We analyze requirements for self-correction🧵.@YusenZhangNLP @NanZhangNLP Jiawei Han @ruizhang_nlp.
1
9
44
I'll be at @COLM_conf and present our work on Tuesday 11am-1pm (Poster #50)!.Looking forward to chatting about LLM safety, self-correction, etc. Also feel free to DM me🙌. Evaluating LLMs at Detecting Errors in LLM Responses.
📢 New Preprint! Can LLMs detect mistakes in LLM responses?.We introduce ReaLMistake, error detection benchmark with errors by GPT-4 & Llama 2. Evaluated 12 LLMs and showed LLM-based error detectors are unreliable!.@ruizhang_nlp @Wenpeng_Yin @armancohan +.
1
8
44
いずれ公式から情報が出ると思いますが、今日から「慶應義塾大学AI・高度プログラミングコンソーシアム」の相談員を開始します。僕の担当は以下の通りです。.火曜5限 日吉・藤原記念館 F11.金曜5限 矢上・34-407. ほとんど情報が出ていないと思うので、拡散お願いします。.
1
12
41
Miami is living in the future with self-driving delivery cars 😳😍 #EMNLP2024.(btw I’m already back in state college)



2
1
39

Our poster presentation @COLM_conf is today 11am-1pm (Poster #50)! Just outside the theater. Come to our poster if you are interested in LLMs safety, self-correction, evaluation, or any related topics!. Evaluating LLMs at Detecting Errors in LLM Responses.
📢 New Preprint! Can LLMs detect mistakes in LLM responses?.We introduce ReaLMistake, error detection benchmark with errors by GPT-4 & Llama 2. Evaluated 12 LLMs and showed LLM-based error detectors are unreliable!.@ruizhang_nlp @Wenpeng_Yin @armancohan +.
2
4
29

📢 Oral on Dec 10, 9am at East #EMNLP2023.I will be presenting WiCE, a new dataset in Doc-level NLI! Check it out if you are interested in methods to attribute content to documents. 🔗 w/ @tanyaagoyal @juand_r_nlp @gregd_nlp.
Excited to share that our WiCE paper has been accepted to #EMNLP2023 !.Check out our new dataset for Doc-level NLI!. Many thanks to @gregd_nlp and to my wonderful co-authors @tanyaagoyal @juand_r_nlp!. data: updated!.arxiv: updated!.
0
5
21

こんな状況ですが2月からオースティンに行く予定です。.ようやく今日になって寮の契約ができたので一安心。.いろいろあって渡航することを決めましたが、オースティンでも寮からオンラインで授業を受けるだけになりそうです。.
1
1
22
インターンで取り組んだ研究についてSenseTime Japan TECH blogに投稿しました。. インターンで取り組んだ “Efficient Unknown Object Detection with Discrepancy Networks for Semantic Segmentation” がNeurIPS 2021 Workshopに採択されました
0
4
21



I’ll present my work on factuality evaluation for text summarization in Poster Session 3 (9am May 3)! #eacl2023.

📣 At #EACL this week from our lab:. 1. @ryokamoi (w/@tanyaagoyal) analyzing QA/QG methods for factuality eval in summarization:. 2. @prasann_singhal (w/Jarad Forristal + @xiye_nlp) predicting OOD performance w/feature attributions:.
0
3
17

ワクチン1回目を大学で接種しました。.日本と同じPfizer-Biontech製みたいです。副反応はちょっと腕が腫れているような気がするくらいでしょうか。. I received my first dose of the vaccine.

0
0
16

慶応義塾大学理工学部等に所属する学生に向けて、TOEFLのオンライン講座の受講と(条件付きで)TOEFLの本試験の受験を無料で提供するプログラムが来年度から始まるそうです。TOEFLは高いので、やる気がある人には良さそう。.
1
5
16
今週末から授業なので朝6時就寝くらいの生活にシフトしていかないといけないんだけど、徐々に遅くしていま朝3時寝くらいまできた。体に悪そうなので睡眠時間はいつも以上に取っている。.しかし午前っていつも作業効率わるいので、午後から深夜に作業するのは悪くない。.
0
1
15
初回授業なので小規模クラスだと自己紹介とかしているんですが、教員から「自己紹介で夏はどんなインターンをしていたか教えて」っていう質問をされた時点で驚いたのに、履修者全員がインターンをしていたので更に驚いた。そういう感じなのか。みんな2年生の夏休みのはずなんだけど。.
1
1
15


明日AAAIに参加するために出国して13日に帰国します。僕が発表するのは初日のワークショップだけですが本カンファも楽しんできますね。.
0
0
14
次年度の慶応での履修予定を立てていて再認識するけれど、低学年の頃に「この授業って必要なのか?」と思っていた内容も凄く重要なやつだったんだなぁということに後から気付く。.
1
2
14
アメリカ、制度が適当なので「その授業は取れません」って言われてから「お願いお願いお願いその授業本当にとりたいの」って3回メールを送ったら履修できた。.
0
0
13
僕の英語力が低すぎて返答があまりにも限られていたらしく、ML専攻のCMU生に「あなたを模したチャットボットなら直ぐに作れそうね」というお言葉を頂いた。.
0
0
13



奨学金は母校慶應義塾のKeio University Global Fellowshipを頂く予定です。中学から10年間お世話になった上に奨学金まで頂いてしまいました。今後も塾員として貢献できるよう頑張ります。.併給可の奨学金は引き続き応募しているので、良い情報を知っている方はぜひ教えてください🙏.
1
0
12
お世話になっている「慶應義塾大学グローバルフェローシップ(私費留学助成)」への報告が公開されました. 海外大学院で活躍する Keio University Global Fellow 2020からの報告:[慶應義塾]
1
0
11

日程は暫定ですが、AIコンソーシアム(@AI58677691).で僕が担当する機械学習輪講が秋学期の金曜6限に矢上で開催予定です。参加者のみなさんに交代で発表してもらう形式です。ぜひ金曜日の放課後の時間は空けておいてください。.詳細は9月24日のガイダンスなどで説明されます。.
1
1
11
VLMEvalKit now supports our VisOnlyQA dataset 🔥🔥🔥. VisOnlyQA reveals that even recent LVLMs like GPT-4o and Gemini 1.5 Pro stumble on simple visual perception questions, e.g., "What is the degree of angle AOD?"🧐.

📢 New preprint! Do LVLMs have strong visual perception capabilities? Not quite yet. We introduce VisOnlyQA, a new dataset for evaluating the visual perception of LVLMs, but existing LVLMs perform poorly on our dataset. [1/n].
0
2
13
今週日曜日の米国大学院学生会2021冬季大学留学説明会にパネリストとして参加します。.CS(人工知能)のパネルで海外修士課程への進学や海外インターンについて話す予定です。.まだ参加登録ができると思うので、興味のある方はぜひ。.
テーマ『コンピュータ・サイエンス(人工知能)』のパネリスト紹介. ・古賀樹(Ph.D.在籍) Universirty of California, San Diego.・齋藤優太(Ph.D.在籍) Cornell Universiry.・鴨井遼(Master休学) University of Texas, Austin. 詳細はHPを参照ください .
0
0
8
NLPの授業の最終課題がチーム戦のKaggleだったんですが、うちのチームは(深層学習の授業ではなかったので)特徴量設計を頑張って分類器も色々試してチューニングして・・・ってやっていたんですが、「LSTM使いました、終わり笑」っていうチームに完敗した。.
1
0
8


I'm presenting our poster at the NeurIPS 2021 @NeurIPSConf Workshop on Machine Learning for Autonomous Driving!.This is my work as a research intern at @SensetimeJ.
0
1
7



+1! @gregd_nlp repeatedly told me to manually check raw data and model outputs carefully (maybe because I did not do that sufficiently🙃). It is often very time-consuming and painful for non-native NLP students like me, but haste makes waste (with my self-reflection).

This is one of the most important things I learnt through my PhD. I practice in my everyday’s work. Many thanks to my advisor @gregd_nlp @eunsolc.
0
0
7


We also experimentally show that claim splitting can reduce the complexity of the entailment classification problem. We show that claim splitting can improve evaluation performance without additional training by decomposing claims and aggregating sub-claim level scores!.[5/n]

1
0
7
Thanks to my great coauthors! @sarkarssdas, @Reza20000722, @ahn_janice030, @YilunZhao_NLP, Xiaoxin Lu, @NanZhangNLP, @YusenZhangNLP, Ranran Haoran Zhang, Sujeeth Reddy Vummanthala, Salika Dave, Shaobo Qin, @armancohan, @Wenpeng_Yin, and @ruizhang_nlp [n/n].
0
2
7
東大は秋学期から休学する予定です。もちろん指導教員には入学前から相談していたのですが、春学期のみの在籍にもかかわらず受け入れていただいて本当に感謝しています。現在進行形で貴重な指導を頂いています。(当然ですが様々な状況で受け入れの可否は変わると思うので各自で相談してください).
1
0
7
