
Yusen Zhang
@YusenZhangNLP
Followers
330
Following
217
Statuses
79
PhD Candidate @PennStateEECS | NLP Lab @NLP_PennState #NLProc | Prev Research Intern @MSFTResearch, @AmazonScience @GoogleAI
State College, PA
Joined November 2022
Chain-of-Agents has been accepted by NeurIPS 2024! 📣We propose Chain-of-Agents, a training-free, task-agnostic, highly interpretable framework for Long Context. CoA improves significantly over RAG/Long LLM/Multi-Agent. Link:
Chain-of-Agents (CoA) consists of multiple worker agents who sequentially communicate to handle different segmented portions of the text, followed by a manager agent who synthesizes these contributions into a coherent final output.

3
24
124
Very interesting founding! More interestingly, in our recent paper: we found a similar behavior termed "Verbosity Compensation" that the recall of verbose - concise > 20%! To explain, we found this behavior is related to the model uncertainty.

Discovered a very interesting thing about DeepSeek-R1 and all reasoning models: The wrong answers are much longer while the correct answers are much shorter. Even on the same question, when we re-run the model, it sometimes produces a short (usually correct) answer or a wrong verbose one. Based on this, I'd like to propose a simple idea called Laconic decoding: Run the model 5 times (in parallel) and pick the answer with the smallest number of tokens. Our preliminary results show that this decoding gives +6-7% on AIME24 with only a few parallel runs. I think this is better (and faster) than consensus decoding.
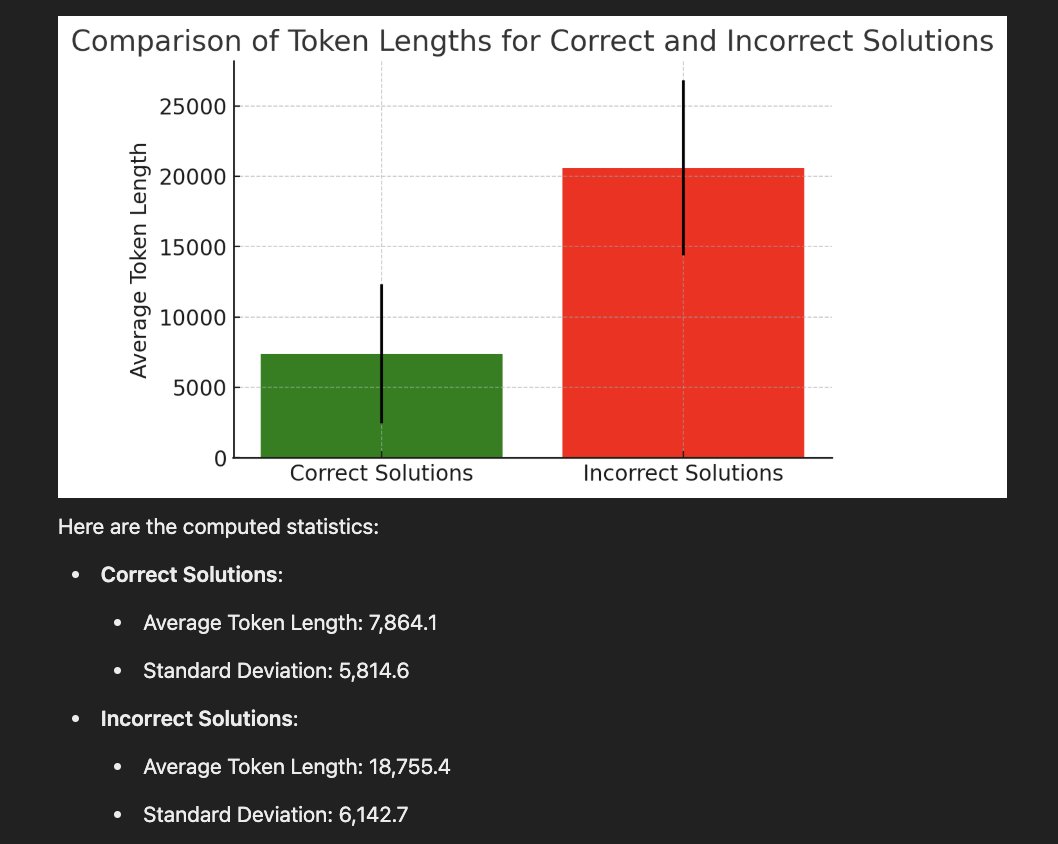
0
1
6
@AlexGDimakis Very interesting founding! Interestingly, we found a similar behavior in our recent paper: We found that the recall of verbose responses can be more than 20 percent lower than that of concise responses! And this is connected to the uncertain of the model.
0
0
1
RT @vipul_1011: Wohhoo, our work got accepted at NAACL 2025! 🥳 TLDR: we built a methodology to improve reliability of any dataset by selec…
0
10
0
RT @GoogleAI: Large language models are often limited by restrictions on the length of their inputs. To address this, we propose Chain-of-A…
0
195
0
RT @NanZhangNLP: Thanks @SFResearch for sharing our SiReRAG paper ( accepted by #ICLR2025! We proposed a RAG indexi…
0
6
0
RT @RyoKamoi: 📢 New preprint! Do LVLMs have strong visual perception capabilities? Not quite yet... We introduce VisOnlyQA, a new dataset…
0
19
0
RT @RyoKamoi: Curious about LLM self-correction? Check out our reading list! 📚 We feature papers & blogs in * Key…
0
28
0
RT @vipul_1011: The fan-boy in me was really happy (and a bit nervous) while organizing the talk by @srush_nlp and having discussions with…
0
4
0
RT @momergul_: This still feels very surreal! I would like to thank @emnlpmeeting for this great honor, @yoavartzi and my labmates for all…
0
9
0
RT @vipul_1011: The code and SMART-Filtered datasets are now open-sourced! 🚀✨ 🔗Code: 🤗SMART-Filtered datasets on…
0
11
0
RT @RyoKamoi: We will present our survey on self-correction of LLMs (TACL) at #EMNLP2024 in person! Oral: Nov 12 (Tue) 11:00- (Language Mo…
0
11
0
RT @PennStateEECS: NSF CAREER award: Centering people while advancing artificial intelligence Computer science researcher Rui Zhang to buil…
0
11
0
RT @Reza0843: 🚨New Paper Alert! As AI/ML researchers, we often juggle "brain-intensive" research tasks in our daily work 🤯, like crafting…
0
40
0
RT @vipul_1011: 🚨 New paper alert 🚨 Ever struggled with quick saturation or unreliability in benchmark datasets? Introducing SMART Filteri…
0
13
0
I will be there as well! Welcome to join and talk.

Our poster presentation @COLM_conf is today 11am-1pm (Poster #50)! Just outside the theater. Come to our poster if you are interested in LLMs safety, self-correction, evaluation, or any related topics! Evaluating LLMs at Detecting Errors in LLM Responses
0
1
4
RT @RyoKamoi: I'll be at @COLM_conf and present our work on Tuesday 11am-1pm (Poster #50)! Looking forward to chatting about LLM safety, se…
0
8
0
RT @MingZhong_: Excited to share our recent work! We define and benchmark cross capabilities in LLMs, revealing the "Law of the Weakest Lin…
0
19
0