

Wenting Zhao
@wzhao_nlp
Followers
2K
Following
201
Media
22
Statuses
297
PhD student @cornell_tech NLP + AI opinions are my own
NYC
Joined June 2013
Introducing the commit0 interactive environment for coding agents. Challenge: generate Python libraries from scratch. Commit0 is designed with interactivity, dependencies, and specifications as first-class considerations. We include a benchmark with 50+ challenging libraries.
13
58
364
Hi friends, for a limited time, our WildChat project will provide free access to GPT-4 turbo: For any data we collect during this period, we will give it back to the community 😊. Paper: Thank @ai2_mosaic for the generous support.
5
21
115
I'm happy to share that WildChat has been accepted as a spotlight paper at #ICLR2024! Since the release of the dataset, it has been able to support so much research such as multi-turn conversation evaluation, cultural analysis, etc. We will release more data soon, stay tuned 💙.

WildChat dataset is out @ai2_mosaic🚀 Explore 650K user-ChatGPT interactions in the wild:.🔗 A huge shoutout to the team @wzhao_nlp @xiangrenNLP @jmhessel @clairecardie @YejinChoinka. Fun fact: The ChatGPT/GPT-4 chatbot often thought it was GPT-3🤣

2
12
106
I’m at #EMNLP2024 this week presenting our work on reformulating unanswerable questions (Nov 12, 16-17:30). These days, I think about how to use formal tools and harder evals to get LMs closer to intelligence. I’m also on the faculty job market for 2024-2025! Please come say hi!

4
12
97
Can you really train a smart LLM without copyrighted material? There has been hope that small LM + retrieval might circumvent data requirements. We think this approach is a bit of a mirage, which only improves performance on simple tasks, but hurts the reasoning capabilities.
6
12
89
Eval platforms like Chatbot Arena attract users to provide preference votes. But what are the incentives of these users? Are they apathetic, or are they adversarial and just aiming to inflate their model rankings? We show 10% adversarial votes change the model rankings by a lot!

3
18
89
📣Announcing VerifAI: AI Verification in the Wild, a workshop at #ICLR2025. VerifAI will gather researchers to explore topics at the intersection of genAI/trustworthyML and verification: @celine_ylee @theo_olausson @ameeshsh @wellecks @taoyds

0
23
86
Thanks for featuring WildChat! I'm really excited about our new release, which includes geographic locations, hashed IP addresses, and HTTP request headers. Thanks @yuntiandeng for being the driving force behind all of this!. Dataset can be downloaded at

WildChat. 1M ChatGPT Interaction Logs in the Wild. Chatbots such as GPT-4 and ChatGPT are now serving millions of users. Despite their widespread use, there remains a lack of public datasets showcasing how these tools are used by a population of users in practice. To bridge this

4
12
74
Reviewing for ARR feels so crazy to me 🥲.1. Two papers in my batch propose exactly the same benchmark. 2. three days after the deadline, and yet I'm still the first one to submit my reviews.3. papers all are weak accept, excitement is low, but no major flaws to point out.
5
3
59
Super excited to see WildChat has powered so many new research directions 🥰 (Although I am a little annoyed that Anthropic made cooler figures for WildChat than I did. )


New Anthropic research: How are people using AI systems in the real world?. We present a new system, Clio, that automatically identifies trends in Claude usage across the world.

1
1
59
Commit0 💻 Leaderboard Update 🔥.OpenHands @allhands_ai solves two Python libraries entirely from scratch by using interactive test feedback 🚀.The best agent on Commit0 (split: all) jumps from 6% to 15%!
3
6
54
shout-out to my amazing mentors @alsuhr @xiang_lorraine I would do another PhD if they were my advisors 🫶.

We're delighted to extend hearty congratulations to the AI2 Outstanding Intern of the Year recipients for 2023! Henry Herzog, Wenting Zhao (@wzhao_nlp), and Yue Yang (@YueYangAI) made exceptional contributions to the team. Learn more about our winners:

5
1
49
Wow! Llama 3 absolutely blows my mind! The retrieval component works so well, and the information is up to date. Meta must have incorporated retrieval in the training to get this level of performance. @yuntiandeng Sorry for picking on you lol

4
3
54
How often do SoTA LLMs generate incorrect information on user-queried topics? To find out, we had LLMs produce information on entities extracted from WildChat. We think that accurate knowledge of these entities is necessary for correctly answering related user queries.
2
6
52
Heading to #ACL2023🚀 My collaborators @megamor2 @billyuchenlin @michiyasunaga @aman_madaan @taoyds and I will be presenting a cutting-edge tutorial on Complex Reasoning in Natural Language - diving into recent methods for accurate, robust & trustworthy reasoning systems🤖 1/2.
2
11
49
I'll be in Philly for COLM 🚀 These days, I think about reasoning, evaluation, the role of scaling, and commit0! If you're also interested in these topics, let's chat:
1
3
44
It took me a good five years to realize these tips. I wish I read this in my first year.

🔗 Thoughts on Research Impact in AI. Grad students often ask: how do I do research that makes a difference in the current, crowded AI space?. This is a blogpost that summarizes my perspective in six guidelines for making research impact via open-source artifacts. Link below.

0
1
42
Sasha’s talk is making informed speculations but I want to give a version where it is all my baseless spicy takes to superintelligence reasoning 😌.

Working Talk: Speculations on Test-Time Scaling. Slides: (A lot of smart folks thinking about this topic, so I would love any feedback.). Public Lecture (tomorrow):




3
2
40
+1 this is absolutely essential and I am happy to see we are finally thinking about infra to support this. Loading and offloading model weights has been a huge bottleneck (like the code below I wrote for a self-training project).


Very real discussions going down on how to improve open source infra for RLHF / post train. Randomly bumped into @johnschulman2 in the comments. Good time to speak up if you're interested. Thanks folks @vllm_project for being proactive here too. TLDR quickly syncing the weights

1
1
40
Join us on developing on commit0! We believe commit0 will push the limits of transformer models and language agents. Install: pip install commit0.Doc: Github: Leaderboard+analysis:
1
3
34
Looking at how users interact with chatbots in the wild is so fun. I can probably generate 100 research ideas by just browsing these real-world conversations 🔥.In case you're also curious: (Fixed the previous link haha didn't expect so much interest!).
2
3
30
I am presenting a few cool projects at #EMNLP2023!!!.1. "Symbolic Planning and Code Generation for Grounded Dialogue" (SPC) led by @justintchiu. He has the best vision for human-robot optimal communication, and he's currently on the job market! He's my no.1 goto collaborator 😍.
1
4
30
The NLP community has created many instruction fine-tuning datasets by imagining what are the use cases of chatbots, but what do the users really ask them to do? Check out WildChat to find out 😍.
WildChat dataset is out @ai2_mosaic🚀 Explore 650K user-ChatGPT interactions in the wild:.🔗 A huge shoutout to the team @wzhao_nlp @xiangrenNLP @jmhessel @clairecardie @YejinChoinka. Fun fact: The ChatGPT/GPT-4 chatbot often thought it was GPT-3🤣
0
2
29
holy ++ 🩷.



1
0
28
We release a new AI coding benchmark, where models are asked to produce Python libraries from scratch, given a specification document and unit tests. commit0 contains 50+ popular Python libraries, from deprecated to networkx.

2
0
26
I will be also presenting our paper (w/ @justintchiu @clairecardie @srush_nlp) on "Abductive Commonsense Reasoning Exploiting Mutually Exclusive Explanations", diving into unsupervised abductive reasoning by leveraging the mutual exclusiveness of explanations. Eager to chat💡.
0
2
24
Personally, I believe in data, but it would be more fun if I could be proven wrong by architecture, optimization, and other learning algorithm researchers.


2
0
20
Thanks to @modal_labs for their generous support to our project. Their service enables us to auto-scale running any arbitrary number of unit tests simultaneously, hence our interactivity.
Introducing the commit0 interactive environment for coding agents. Challenge: generate Python libraries from scratch. Commit0 is designed with interactivity, dependencies, and specifications as first-class considerations. We include a benchmark with 50+ challenging libraries.
0
4
22
Commit0 provides signal through unit test execution feedback, including both error messages and locations. It also offers comprehensive linting feedback including type checking. Finally, it keeps track of agents' coding progress to allow future backtracking.

1
0
20
Thanks to my awesome collaborators: @nanjiangwill.@celine_ylee @justintchiu @clairecardie @srush_nlp. Nan is an amazing undergrad who has brilliant ideas and gets them executed! He'll be an amazing PhD student. Recruit him to join your lab 😍.
1
2
19
Awww, thanks Jack! ♥️ I’m at EMNLP, happy to chat about reasoning, evaluation, imitation learning, and anything about graduate school 😍.

here are two awesome researchers you should follow: @WeijiaShi2 at UW and @wzhao_nlp at Cornell!! some of their recent work:. weijia shi (@WeijiaShi2): .- built INSTRUCTOR, the embedding model that lots of startups / companies use (.- proposed a more.
0
0
18
In our new paper, we evaluate kNN-LMs with a few state-of-the-art base models + different datastores. We find that kNN-LMs do better in simple tasks like sentiment classification and entailment but perform worse on multi-hop and math reasoning tasks.

1
2
16
Big updates on the commit0 leaderboard are coming! Spoiler alert: OpenHands is really awesome 🚀.

Introducing OpenHands 0.14.3🙌. Exciting updates:.1. One-button click to push to github.2. Incorporation of the commit0 benchmark for building apps from scratch (thanks @wzhao_nlp -- benchmark results soon!).3. Many other smaller robustness improvements

0
2
17
Commit0 is a challenging benchmark. First, the specification given to the model is often hundreds of pages. The specification also has both texts and figures, while understanding figures is not necessary, humans use them to obtain a holistic view of the library.

1
0
16
Commit0 will release interactive testing (per unit test), linting, and coverage feedback for SWE-bench in the coming weeks. And we are going full open-source! What other features would you like? 🤔

0
2
15
On commit0 Lite (an easy split of 10 libraries out of 56), our baseline agent that leverages unit test feedback can pass a portion of the unit tests occasionally. However, the overall pass rate is only ~30%. On commit0 all, the overall pass rate drops to close to 0%.

1
0
15
The last challenge is the actual library generation part. Large Python libraries are quite long and contain up to thousands of modules. The files also have importing dependencies where generating some modules requires identifying which other modules to condition on.
1
0
14
Dear @allhands_ai developers: we would like to get OpenHands to do library generation. Would you suggest just kicking off the agent with a prompt "can you complete all function implementations" or explicitly instruct the agent to fill in file by file? @xingyaow_ @gneubig.
3
0
14
tbh we haven't been able to use any of the models launched by google due to rate limit, and they never get back to us about it. we were able to run deepseek, mistral, o1, etc. and observe reliable improvement over past models. Is it only us who find google models so hard to use?.
Google ships.
4
1
14
And, researchers focus exclusively on perplexity as an indicator of downstream performance. Does this hold in the non-parametric world? We question this assumption and show that although kNN-LMs achieve better in-domain perplexity, this doesn't translate into better reasoning.
2
1
12
try out GPT-4o for free now.
GPT-4o is so fast! 🚀 We've updated the free chatbot behind WildChat to use GPT-4o. Try it out here:
0
1
12
Xi is an amazing mentor! So knowledgeable and caring.

🔔 I'm recruiting multiple fully funded MSc/PhD students @UAlberta for Fall 2025! Join my lab working on NLP, especially reasoning and interpretability (see my website for more details about my research). Apply by December 15!.
0
0
12
🔥.
If you're at #ICLR, come to our poster on WildChat tomorrow afternoon! We collected 1 million user-ChatGPT conversations with geographic info. Presented by @wzhao_nlp and me. 📅 Time: Thursday, May 9, 4:30 PM - 6:30 PM CEST.📍 Location: Halle B #239. 🔗

1
0
11
Come meet and chat with your fellow reasoning researchers ☺️.

Overwhelmed massive works about reasoning but still feel lack of nutritions? @wzhao_nlp and I are hosting a BoF session regarding "Recipes in Building Language Reasoners" in #EMNLP2023 at Singapore @emnlpmeeting. 1/3

0
1
10
For those who're interested in what's happening after WildChat, I think this is a super cool project 😊.

Interested in how LLMs are really used?. We are starting a research project to find out! In collaboration w/ @sarahookr @AnkaReuel @ahmetustun89 @niloofar_mire and others. We are looking for two junior researchers to join us. Apply by Dec 15th!.
0
0
10
this tangible, actionable roadmap for the open human feedback ecosystem is my favorite outcome from this project. now is so in time to work on these problems.

Then, we hone on 6 crucial areas to develop open human feedback ecosystems:.Incentives to contribute, reducing contribution efforts, getting expert and diverse feedback, ongoing dynamic feedback, privacy and legal issues.

2
0
9
Is your agent good at coding? Show it on commit0! 😈 .Install: pip install commit0.Doc: Github: Leaderboard (includes detailed analysis and generated code): Preprint:
0
2
9
Congrats on the new position! I really love working with Joe. I’ve always learned so much from our collaboration. As a mentor, he is also so knowledgeable and so caring. ☺️.

Thanks Sasha! And yes, I am moving to Stony Brook University this fall. Lmk if you are interested in doing PhD or research with strong technical background and interests in the crazy NLP and related (multimodal, ml, etc.) areas.
1
0
9
0
0
8
(2) Small LLMs with retrieval hallucinate more than large LLMs. Therefore, empirically, retrieval helps to an extent but the room for improvement is large. Most prominent source of RAG errors was genuine generation errors by the base models even provided with correct documents.
1
0
7
Our findings are (1) LLMs hallucinate more on entities without associated Wikipedia pages compared to those with available Wikipedia pages.

1
2
7
such fun papers to read.

Hi ICML! We're presenting papers this week:. - understanding how LMs learn new langs in-context - agents for automated interpretability research: - calibrating LMs by marginalizing over missing context:
0
0
7
@ABosselut I don't know about others, but our second workshop on Natural Language Reasoning and Structured Explanations will be held at ACL'24 (shameless self-promotion🤣).
0
0
7
@ericzelikman we spent so much time to think about star 🤗.

wrote a short blog post on the latent variable model behind STaR:
0
0
6
@gneubig This terminology really bugs me, and we argue a lot when writing papers. To me *S*FT implies FT on human annotations.
0
0
6
Getting high-quality annotations for free-text generations has always been tricky. Open community platforms like Chatbot Arena provide large-scale, rich data, making now a perfect time to study this topic!. Check out our new preprint:
1
1
6
love LLMs as productivity tools.

ChatGPT "Advanced Data Analysis" (which doesn't really have anything to do with data specifically) is an awesome tool for creating diagrams. I could probably code these diagrams myself, but it's soo much better to just sit back, and iterate in English. In this example, I was

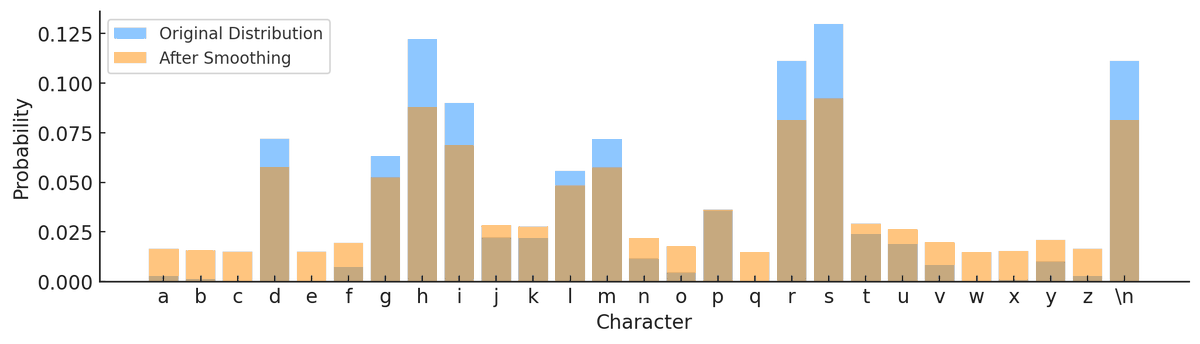
0
0
5
@allhands_ai @xingyaow_ @gneubig our current agent design wraps aider to do each of the following steps. What I am unsure about is if we should just replace aider with openhands, or if you are doing this in an entirely different way?

1
0
5
Thanks to all my awesome collaborators: @justintchiu @saujasv @dan_fried @derek @derekchen14 and my most supportive, helpful, visionary advisors: @clairecardie @srush_nlp.
1
0
5
@Samhanknr Even with memorization and this data is included in pretraining, models do not do well. :).
1
0
4
2. "HOP, UNION, GENERATE (HUG): Explainable Multi-hop Reasoning without Rationale Supervision" RAG is used for retrieval-augmented generation, but RAG retrieves documents independently. By explicitly modeling the multi-hop relationship between documents, HUG beats RAG!.
1
0
5
@WilliamWangNLP I can echo this feeling. I felt very much excluded from the community after going over the slides.
0
0
4
3. "MiniChain: A Small Library for Large LMs" @srush_nlp made a really lightweight and easy-to-use library that allows people to quickly prototype software with LLMs in the loop. @justintchiu uses minichain to build his SPC dialogue system 🚀.
1
0
4
@srush_nlp @paul_cal Using modal for simple script execution is very cheap. Running unit tests for our 50+ repos only costs 1 dollar. Compared to LM API calls, this is a tiny portion of that. Modal also gives $30 free credit every month, which already goes a long way.
1
0
4
Here are example entities that we extracted from WildChat. And wow! I'm truly fascinated by the breadth of topics users talk about.

1
0
4
2
0
2
check it out! from now on, I don't need to memorize all the numbers, cuz I have the language and tools to calculate these numbers 🤗.
Tutorial: Street Fighting Transformers 🥷. A bottleneck for young CS researchers is internalizing the core scale and unit calculations of LLMs. This video is about learning think in a "physics" style. (Its also probably helpful for job interviews. ).
0
0
4
Please also check out @jxmnop's paper on "Text Embeddings Reveal (Almost) As Much as Text" His paper totally changes my belief about embeddings, from which you can exactly reconstruct the text. The experiments in this paper blows my mind 🥳.
0
0
3
@srush_nlp Have you seen this one? "transformer decoders with a logarithmic number of decoding steps (w.r.t. the input length) push the limits of standard transformers only slightly, while a linear number of decoding steps adds a clear new ability. ".
1
0
4
I guess what I really believe in is human intelligence. We can be more data efficient, and we can design models with better inductive biases.
0
0
3
Also thanks to @astral_sh for their amazing developer tools. uv enables fast build of all Python libraries and ruff generates the lint feedback.
Introducing the commit0 interactive environment for coding agents. Challenge: generate Python libraries from scratch. Commit0 is designed with interactivity, dependencies, and specifications as first-class considerations. We include a benchmark with 50+ challenging libraries.
0
1
4
@yoavartzi @sewon__min this paper is also a fun read.

🧵Let me explain why the early ascent phenomenon occurs🔥. We must first understand that in-context learning exhibits two distinct modes. When given samples from a novel task, the model actually learns the pattern from the examples. We call this mode the "task learning" mode.
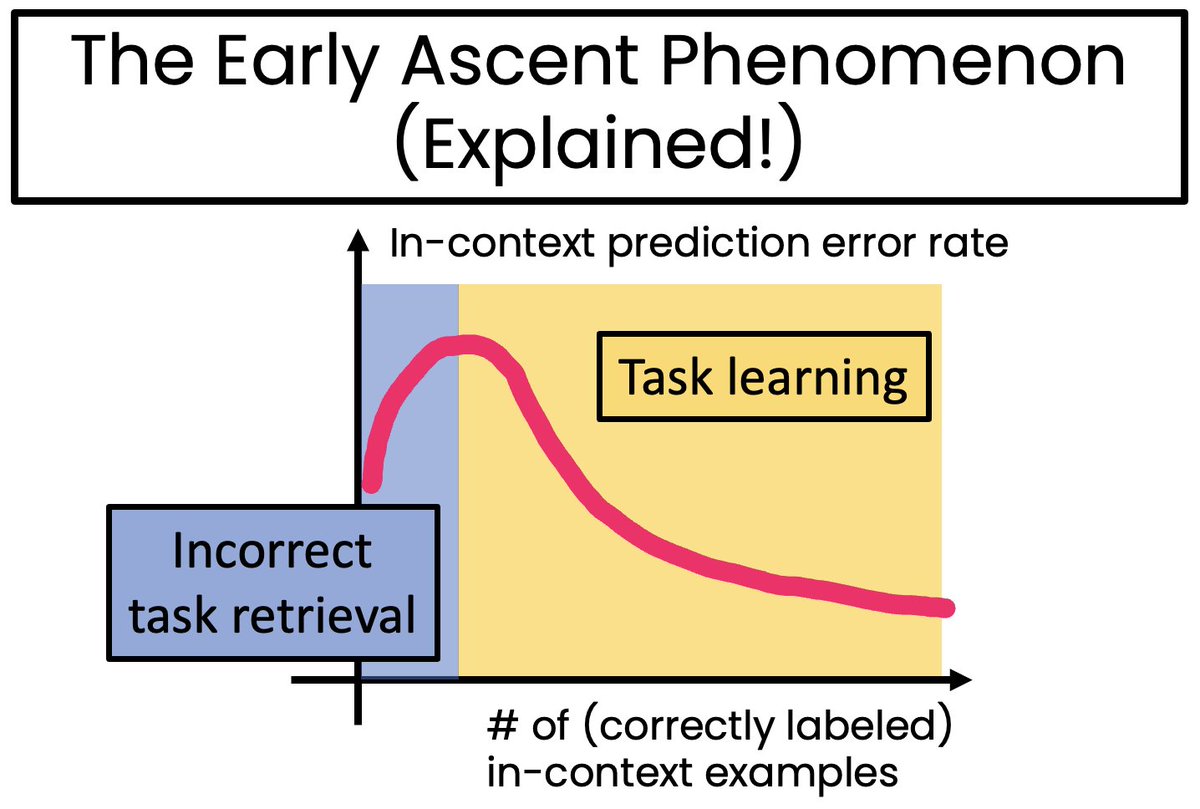
0
0
4
(3) LLMs exhibit varying hallucination rates across different domains, with higher rates in the people and finance domains, and lower rates in geographic and computing-related domains.
1
0
4
This is mind-blowing.

We replicated the DeepSeek-R1-Zero and DeepSeek-R1 training on 7B model with only 8K examples, the results are surprisingly strong. 🚀 Starting from Qwen2.5-Math-7B (base model), we perform RL on it directly. No SFT, no reward model, just 8K MATH examples for verification, the

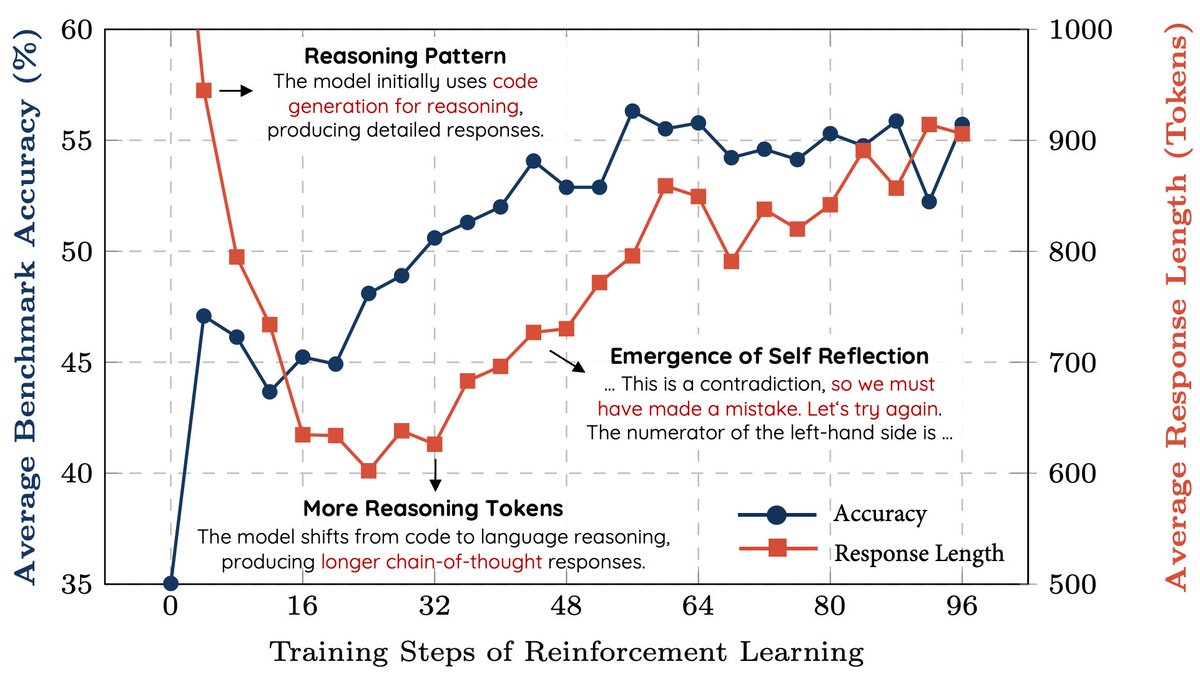
0
0
3
@ScottWu46 Will Devin consider showing its coding capabilities on commit0? It is really good at differentiating agent's capabilities! Swe-agent got 2.98% while OpenHands got 15% on Commit0 (split: all).
Commit0 💻 Leaderboard Update 🔥.OpenHands @allhands_ai solves two Python libraries entirely from scratch by using interactive test feedback 🚀.The best agent on Commit0 (split: all) jumps from 6% to 15%!
0
0
3
mine is a different issue. My learning node and generation node are the same node, loading and offloading new weights takes a lot of time.
3
0
3
@jxmnop lol i know how you feel, i can probably earn a million $ by managing people's wandb accounts to reduce their stress.
0
0
3
@yanaiela Can you also include the projects that were killed and didn't even make to submission stages? 🤔.
1
0
3
@random_walker @maria_antoniak @aryaman2020 @lmsysorg We actually have evidence that users regularly use this external APIs given that otherwise the users would have to pay money out of their own pockets to use GPT-4. For example, there was an editor used our service to draft emails for a few times.
0
0
2
@NirantK @arankomatsuzaki Thanks for your interest. We will release the dataset and model once we get internal clearance. Stay tuned 😊.
0
0
3
@ReviewAcl @koustavagoswami @soldni We received a meta-review that contains factual errors. It also only summarizes the pre-rebuttal reviews and misses corrections and acknowledgments from the reviewers made during the rebuttal. The way it lists bullet points also seems to be ChatGPT generated.
1
0
3
This is super exciting!.
sneak preview 🍿 of our new embedding model: cde-small-v1 . cde-small-v1 is the text embedding model that we (@srush_nlp and i) have been working on at Cornell for about a year. tested the model yesterday on MTEB, the text embeddings benchmark; turns out we have state-of-the-art



0
0
3