
Yuntian Deng
@yuntiandeng
Followers
7K
Following
8K
Media
47
Statuses
758
Assistant Professor @UWaterloo | Visiting Professor @NVIDIA | Associate @Harvard | Faculty Affiliate @VectorInst | Former Postdoc @ai2_mosaic | PhD @Harvard
Joined September 2016
Can we teach LMs to internalize chain-of-thought (CoT) reasoning steps? We found a simple method: start with an LM trained with CoT, gradually remove CoT steps and finetune, forcing the LM to internalize reasoning. Paper: Done w/ @YejinChoinka @pmphlt 1/5
22
187
1K
Is OpenAI's o1 a good calculator? We tested it on up to 20x20 multiplication—o1 solves up to 9x9 multiplication with decent accuracy, while gpt-4o struggles beyond 4x4. For context, this task is solvable by a small LM using implicit CoT with stepwise internalization. 1/4

198
428
3K
We trained GPT2 to predict the product of two numbers up to 🌟20🌟 digits w/o intermediate reasoning steps, surpassing our previous 15-digit demo! How does a 12-layer LM solve 20-digit multiplication w/o CoT?🤯. Try our demo: Paper:
We built a demo using GPT-2 to directly produce the product of two numbers (up to 15 digits) without chain-of-thought (CoT). CoT is internalized using our method below. Try it out:
10
65
522
Lastly, this task is solvable even by a small language model: Implicit CoT with Stepwise Internalization can solve up to 20x20 multiplication with 99.5% accuracy, using a gpt-2 small architecture (117M parameters). 4/4.

We trained GPT2 to predict the product of two numbers up to 🌟20🌟 digits w/o intermediate reasoning steps, surpassing our previous 15-digit demo! How does a 12-layer LM solve 20-digit multiplication w/o CoT?🤯. Try our demo: Paper:
12
29
502
I am hiring NLP/ML PhD students at UWaterloo, home to 5 NLP professors! Apply by Dec 1. Strong consideration will be given to those who can tackle the below challenge: Can we use LM's hidden states to reason multiple problems simultaneously?. Retweets/shares appreciated🥰

12
133
468
Can LMs solve reasoning tasks without showing their work? "Implicit Chain of Thought Reasoning via Knowledge Distillation" teaches LMs to reason internally to solve tasks like 5×5 multiplication. Here's how we bypass human-like step-by-step reasoning 1/6
12
92
454
How many reasoning tokens does OpenAI o1 use? It turns out they are almost always multiples of 64 (99+% of the time in 100K collected turns)🤔Could it be that the model only uses multiples of 64 tokens to think? Or maybe OpenAI rounds the token count in the returned usage? 1/4

8
47
400
Interestingly, the number of private reasoning tokens grows sublinearly with problem size, but is beyond what human-written CoT requires. For example, for 20x20, o1 uses ~3600 reasoning tokens, but human CoT needs ~400 for partial products and ~400 for sums, totaling ~800. 2/4
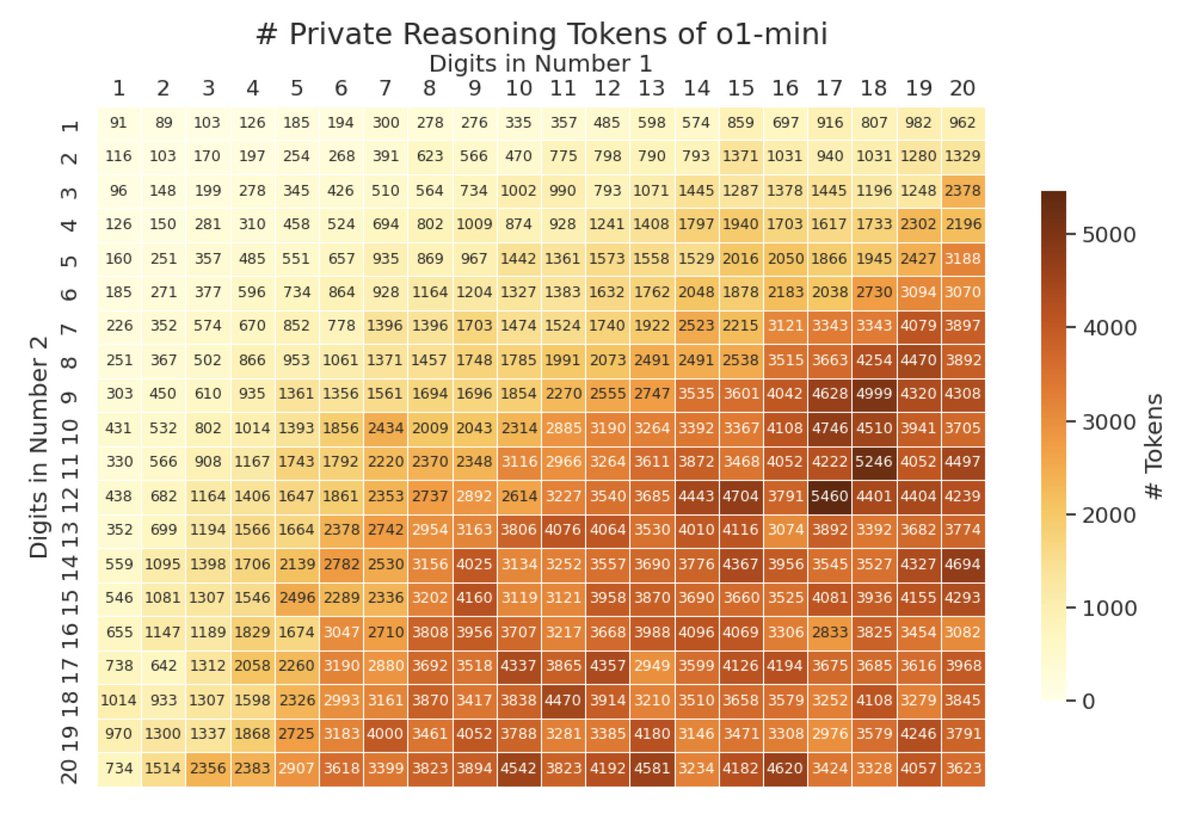
4
18
351
Excited to share that I'm joining @UWCheritonCS as an Assistant Professor and @VectorInst as a Faculty Affiliate in Fall '24. Before that, I'm doing a postdoc at @allen_ai with @YejinChoinka. Immensely grateful to my PhD advisors @srush_nlp and @pmphlt. This journey wouldn't have.
49
19
334
Ever wondered how nondeterministic GPT-4 is even with greedy decoding (T=0)? I built a website that asks GPT-4 to draw a unicorn every hour and tracks if the results stay consistent over time (spoiler alert: they don't! 🦄). Explore the findings:.

11
40
284
o1-preview has similar accuracy to o1-mini despite being more expensive and slower. Both still perform much better than gpt-4o (o1-preview was tested with a small sample size of 7 per cell due to inference speed and cost). 3/4
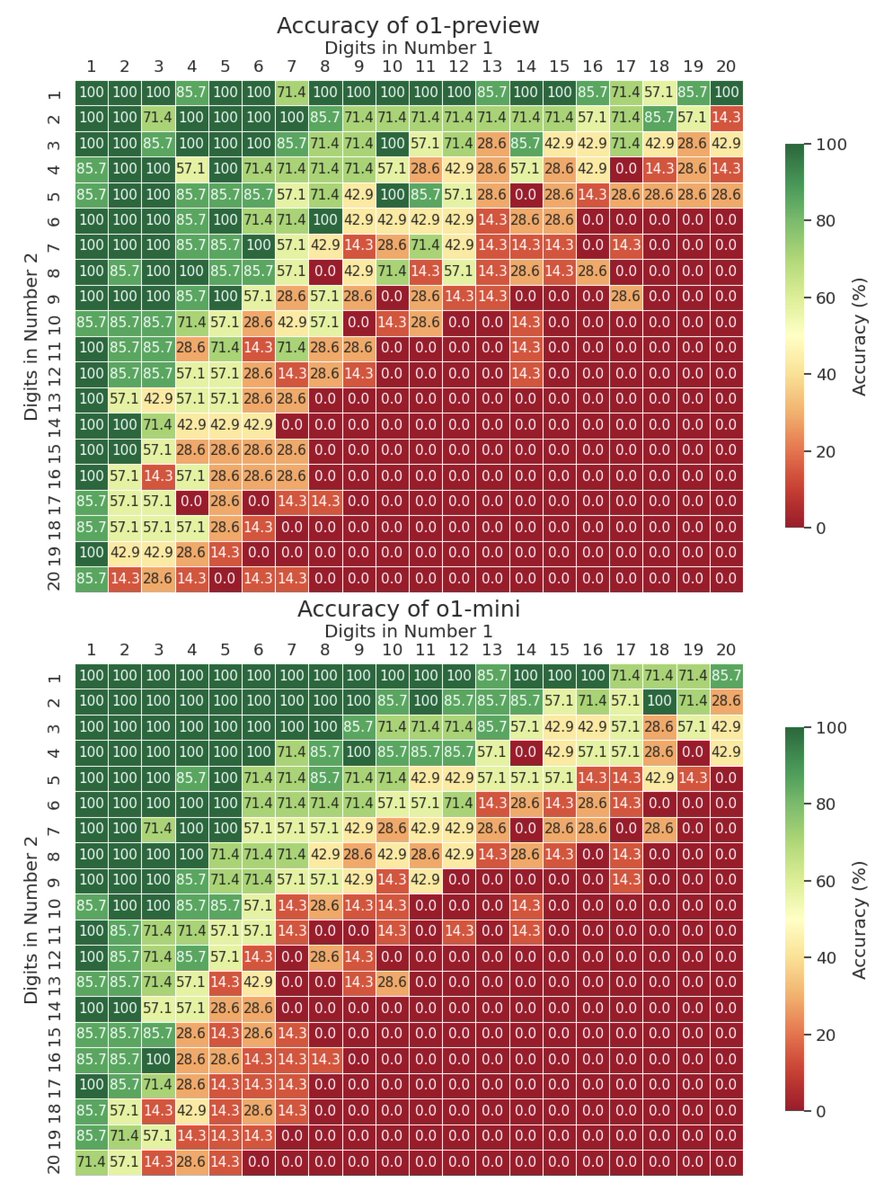
2
6
203
Will your paper catch the eye of @_akhaliq? I built a demo that predicts if AK will select a paper. It has 50% F1 using DeBERTa finetuned on data from past year. As a test, our upcoming WildChat arXiv has a 56% chance. Hopefully not a false positive🤞. 🔗
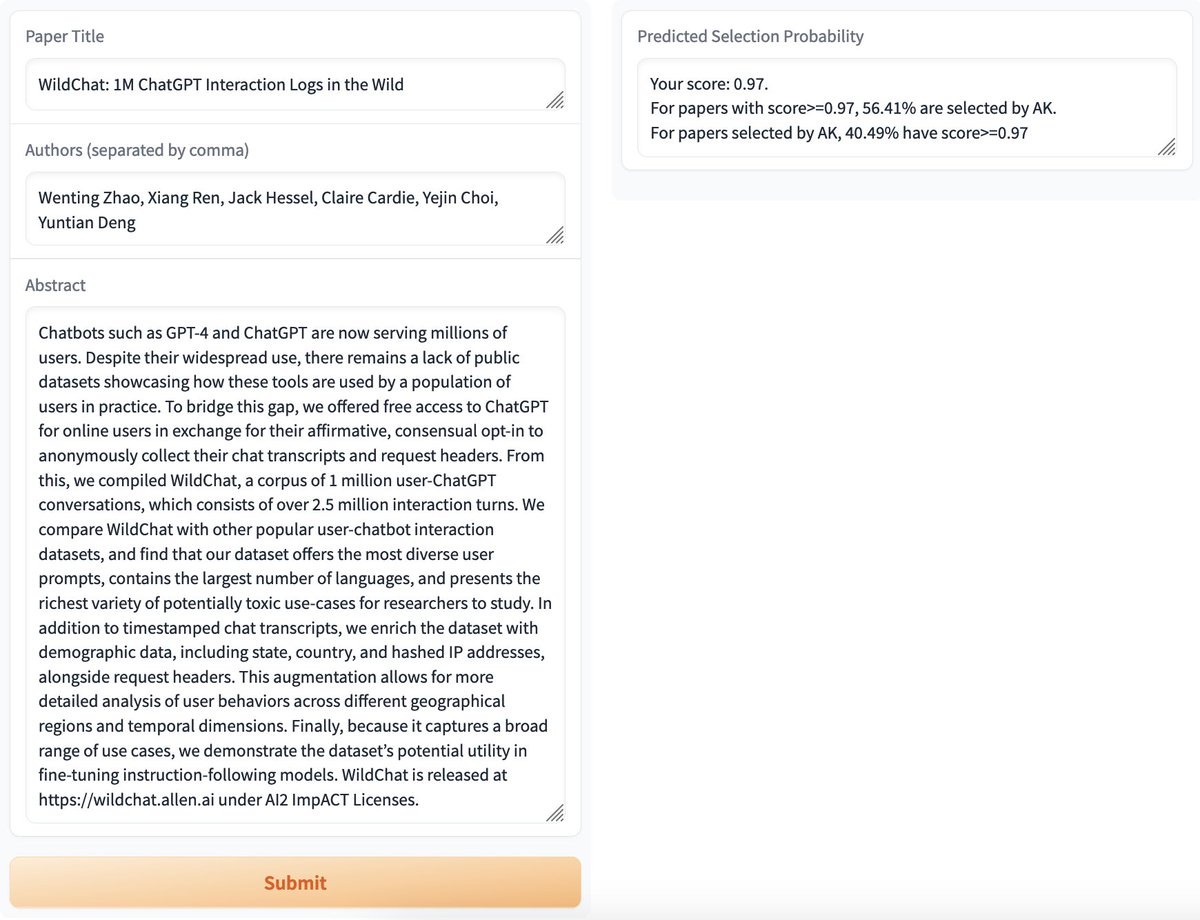
11
20
183
We're providing free access to OpenAI's new o1 reasoning model through our WildChat chatbot:. 🔗 Also, proud that WildChat was referenced in the safety evaluation for o1!.
6
37
182
WildChat dataset is out @ai2_mosaic🚀 Explore 650K user-ChatGPT interactions in the wild:.🔗 A huge shoutout to the team @wzhao_nlp @xiangrenNLP @jmhessel @clairecardie @YejinChoinka. Fun fact: The ChatGPT/GPT-4 chatbot often thought it was GPT-3🤣

3
43
170
o1-mini mostly directly produces the answer, while gpt-4o and o1-preview mostly use CoT. Since mini has similar acc to preview, maybe private reasoning tokens are all it needs?. Also, adding "think step by step" to the prompt didn't seem to help (tested on a tiny sample size).
2
4
153
For those interested, an example prompt used was:. "Calculate the product of 15580146 and 550624703. Please provide the final answer in the format: Final Answer: [result]". Try this out in our o1-mini chatbot:
14
9
146
What do people use ChatGPT for? We built WildVis, an interactive tool to visualize the embeddings of million-scale chat datasets like WildChat. Work done with @wzhao_nlp @jmhessel @xiangrenNLP @clairecardie @YejinChoinka. 📝🔗1/7
2
28
137
In a similar situation. Interviewed for a US visa in Vancouver yesterday, was "checked" due to my AI research, and was told to wait 4 weeks. Just hours away by car from AI2 in Seattle, yet I'm stuck in an airbnb working remotely. This is both an emotional and financial strain😿.

I'm in the same boat and I've waited 4 weeks already for my visa renewal (and because of this I'm very likely to have to miss the workshop that I spent 6 month co-organizing at NeurIPS 🫠 which is a real bummer😿).
6
3
106
⏰In 1 hour @EMNLP posters! Presenting TreePrompt: next LM call is routed by result of previous calls using a decision tree. My first last-author paper, led by Jack Morris @jxmnop & Chandan Singh @csinva, under the guidance of Sasha Rush @srush_nlp & Jianfeng Gao @JianfengGao0217
3
14
107
We built a demo using GPT-2 to directly produce the product of two numbers (up to 15 digits) without chain-of-thought (CoT). CoT is internalized using our method below. Try it out:
Can we teach LMs to internalize chain-of-thought (CoT) reasoning steps? We found a simple method: start with an LM trained with CoT, gradually remove CoT steps and finetune, forcing the LM to internalize reasoning. Paper: Done w/ @YejinChoinka @pmphlt 1/5
3
22
104
@Nacerbs Great catch! We identified the issue as low representation of smaller multiplication problems in data and fixed by upsampling them. The updated model gets 99.5%+ accuracy for all combinations of m and n in m-by-n multiplication (up to 20). Updated demo:

1
3
100
💰12M GSM8K is amazing! We've also released an augmented GSM8K dataset w/ 378K GPT-4 augmented examples. They can train a 117M model to 40.7% acc🔗 I'm curious about how much data we need though. In my experiments, augmenting more data hit a plateau in acc


Microsoft Research announces TinyGSM: achieving >80% on GSM8k with small language models. paper page: Small-scale models offer various computational advantages, and yet to which extent size is critical for problem-solving abilities remains an open

3
14
94
The pace of progress in LM research is astounding. Just a few months ago, I was overjoyed to the point of calling my mom at midnight, excited that a GPT-2 med could solve 5x5 multiplication using our implicit chain-of-thought method. Now we're witnessing models handling 12x12😲.

We trained a small transformer (100M params) for basic arithmetic. W. the right training data it nails 12x12 digits multiplication w/o CoT (that's 10^24 possibilities, so no it's not memorization🤣). Maybe arithmetic is not the LLM kryptonite after all?🤔.
2
5
79
Thrilled to see WildChat featured by @_akhaliq, just as predicted by AKSelectionPredictor!😊. Explore 1 million user-ChatGPT conversations, plus details like country, state, timestamp, hashed IP, and request headers here:.
WildChat. 1M ChatGPT Interaction Logs in the Wild. Chatbots such as GPT-4 and ChatGPT are now serving millions of users. Despite their widespread use, there remains a lack of public datasets showcasing how these tools are used by a population of users in practice. To bridge this

5
15
79
@srush_nlp This tutorial has multiple parts and I found part (1) to be sufficient for understanding the basics. That part might be like a 6 in terms of complexity.
1
5
68
GPT-4o is so fast! 🚀 We've updated the free chatbot behind WildChat to use GPT-4o. Try it out here:
4
13
65
We built a demo to solve grade school math problems (GSM8K) w/o CoT at 52% accuracy by internalizing CoT in a Mistral-7B. Surprisingly, it seems to work in Chinese as well, even tho CoT was only internalized on English! (compare the two gifs). Try it out:


Can we teach LMs to internalize chain-of-thought (CoT) reasoning steps? We found a simple method: start with an LM trained with CoT, gradually remove CoT steps and finetune, forcing the LM to internalize reasoning. Paper: Done w/ @YejinChoinka @pmphlt 1/5
2
10
54
@jxmnop Oh but isn't this the same as implicit chain of thought? We even tried a variant using an autoencoder to compress teacher states and then distill them, but unfortunately it didn't work well.
1
5
52
Pretty late to the party, but just learned about the Hugging Face Community Grant, and now our markup-to-image demo is back online with a GPU supported by the grant. Big thanks to @huggingface!. 🔗

0
7
52
Glad to see WildChat being used in Claude 3 for evaluating refusals. Help us collect more data and release the next version by chatting with our chatbot:

Previous Claude models often made unnecessary refusals. We’ve made meaningful progress in this area: Claude 3 models are significantly less likely to refuse to answer prompts that border on the system’s guardrails.

1
4
48
Neat to see our work "Residual Energy-Based Models for Text Generation" mentioned in Llama2. Interesting to see they used reranked samples to fine-tune the LM, a simple strategy, before using PPO RLHF. (w/ @anton_bakhtin @myleott, @pepollopep @MarcRanzato)


We believe an open approach is the right one for the development of today's Al models. Today, we’re releasing Llama 2, the next generation of Meta’s open source Large Language Model, available for free for research & commercial use. Details ➡️
0
6
46
In light of recent discussions on GPT4's behavior changes post June update, I noticed interesting trends via It seems GPT3.5's unicorn drawings improved while GPT4's declined. Check out these drawings and compare to the preupdate ones in my previous tweet


Ever wondered how nondeterministic GPT-4 is even with greedy decoding (T=0)? I built a website that asks GPT-4 to draw a unicorn every hour and tracks if the results stay consistent over time (spoiler alert: they don't! 🦄). Explore the findings:.
3
9
41
🦄Updates on . 🔹Updated our @huggingface dataset w/ 74.8k entries!.🔹Enhanced navigation with pagination. 🔹+gpt-4-1106-preview, -text-davinci-003. Dive into the journey of GPT's artistic evolution!. 🔗🔗
Ever wondered how nondeterministic GPT-4 is even with greedy decoding (T=0)? I built a website that asks GPT-4 to draw a unicorn every hour and tracks if the results stay consistent over time (spoiler alert: they don't! 🦄). Explore the findings:.
0
4
38
What do people use ChatGPT for? I built a website for interactive search of WildChat, allowing keyword, toxicity, IP, language, and country-based searches. Indexed 1M conversations with Elasticsearch. Based on MiniConf's template. Check it out:
Thrilled to see WildChat featured by @_akhaliq, just as predicted by AKSelectionPredictor!😊. Explore 1 million user-ChatGPT conversations, plus details like country, state, timestamp, hashed IP, and request headers here:.
1
9
39
Results: We finetuned a GPT-2 Small to solve 9-by-9 multiplication with 99% accuracy. This simple method can be applied to any task involving CoT. For example, we finetuned Mistral 7B to achieve 51% accuracy on GSM8K without producing any intermediate steps. 3/5.
1
1
38
Just noticed that ChatGPT sometimes hallucinates responses to empty user inputs🤔@billyuchenlin first noticed this in WildChat: it looked like some inputs were missing. Turns out users didn't input anything, but ChatGPT responded anyway🤣. Try it yourself:

WildChat dataset is out @ai2_mosaic🚀 Explore 650K user-ChatGPT interactions in the wild:.🔗 A huge shoutout to the team @wzhao_nlp @xiangrenNLP @jmhessel @clairecardie @YejinChoinka. Fun fact: The ChatGPT/GPT-4 chatbot often thought it was GPT-3🤣
2
3
38
Proud to share that one of my first students at @UWaterloo, Xin Yan (@cakeyan9), has been awarded a Vector Institute AI Scholarship!.

Meet the 2024-2025 Vector Scholarship in AI recipients who will be studying at @UWaterloo! We are thrilled to have 12 exceptional individuals from the University of Waterloo’s Computer Science, Data Science, Systems Design Engineering, and Electrical and Computer Engineering

0
3
38
WildChat is approaching 1 million conversations! We're planning to release the next version once we reach this milestone. Currently, we have 865K conversations (155K with GPT-4 & 710K with GPT-3.5). Help us by chatting with our chatbot here:

I'm happy to share that WildChat has been accepted as a spotlight paper at #ICLR2024! Since the release of the dataset, it has been able to support so much research such as multi-turn conversation evaluation, cultural analysis, etc. We will release more data soon, stay tuned 💙.
0
5
37
Just got access to #Pika and experienced text-to-video for the first time – quite impressed with the current state of technology! It's truly amazing to think about future possibilities, like generating full-length movies🎥. Prompt: A dinosaur playing guitar on a plane
2
3
34
Approach: Training has multiple stages. -Stage 0: the model is trained to predict the full CoT and the answer. -Stage 1: the first CoT token is removed, and the model is finetuned to predict the remaining CoT and the answer. -This continues until all CoT tokens are removed. 2/5

1
0
33
If you're at #ICLR, come to our poster on WildChat tomorrow afternoon! We collected 1 million user-ChatGPT conversations with geographic info. Presented by @wzhao_nlp and me. 📅 Time: Thursday, May 9, 4:30 PM - 6:30 PM CEST.📍 Location: Halle B #239. 🔗

1
5
34
Meet the Chalk-Diagrams plugin for ChatGPT! Based on @danoneata & @srush_nlp's lib, it lets you create vector graphics with language instructions. Try it with ChatGPT plugins:.1️⃣ Plugin store.2️⃣ Install unverified plugin.3️⃣ Test it out: "draw a pizza" 🍕
3
1
28
The code is available at The data for the first experiment was collected from the WildChat chatbot (. 4/4.
1
0
29
Is GPT-4 Turbo as good at math reasoning as GPT-4? 🤔Inspired by @wangzjeff's SAT reading comparison, I tested on 4×4 and 5×5 multiplications & GSM8K (grade school math problems). Results? 📊 Turbo matches GPT-4's accuracy while being 2-3X faster. Code:



OpenAI claims GPT4-turbo is “better” than GPT4, but I ran my own tests and don’t think that's true. I benchmarked on SAT reading, which is a nice human reference for reasoning ability. Took 3 sections (67 questions) from an official 2008-2009 test (2400 scale) and got the

1
4
28
AKSelectionPredictor now runs on ZeroGPU A100, thanks to the support of @_akhaliq and @huggingface!. 🔗
Will your paper catch the eye of @_akhaliq? I built a demo that predicts if AK will select a paper. It has 50% F1 using DeBERTa finetuned on data from past year. As a test, our upcoming WildChat arXiv has a 56% chance. Hopefully not a false positive🤞. 🔗
0
4
26
Maybe OpenAI rounds reasoning token counts down to the nearest multiple of 64 when reporting usage, which explains why the 192-token case vanished when N=193. But this doesn't explain changes in the 128/64-token counts. 3/4.
2
0
25
To further test, for the prompt "Calculate the product of 100 and 57", we sampled 500 responses w/ & w/o max_completion_tokens limits. Setting threshold to N shouldn't change the frequency of cases below N. Yet when N=193, the 192-token case vanished! How is this possible?🤔2/4

1
0
24
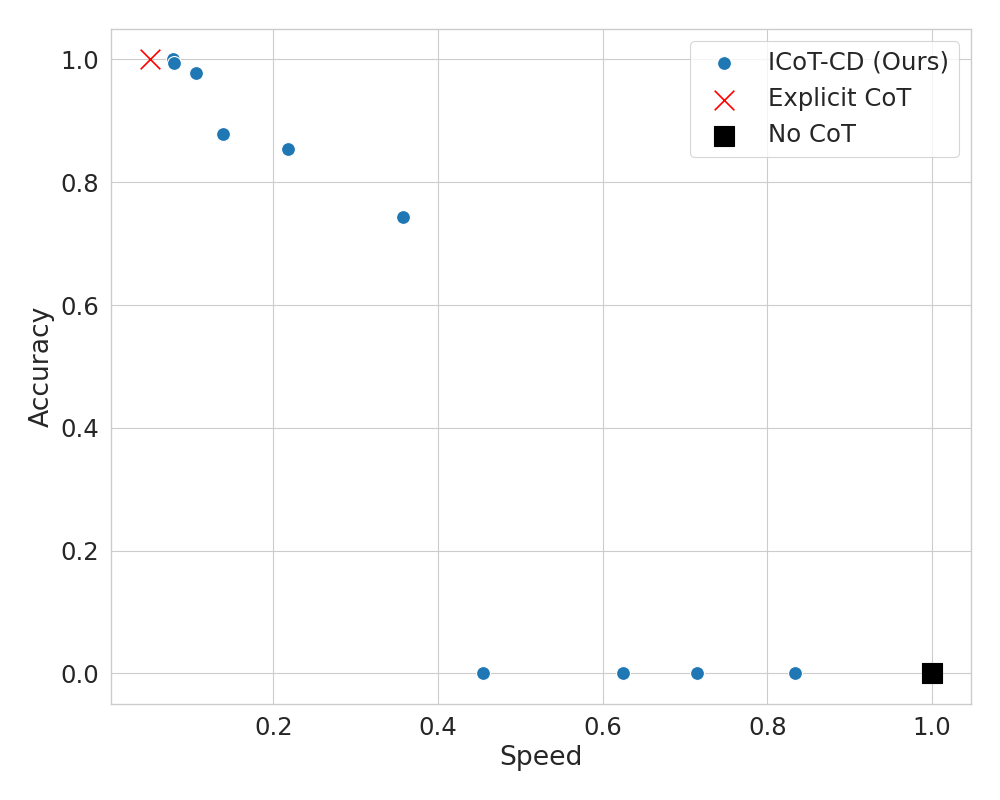
Even if we can't internalize all CoT steps, partial internalization can lead to speedups during generation. For example, on 11-by-11 multiplication, we achieve over 74% accuracy using only 1/7 of the CoT steps (at 4X the speed) by internalizing 6/7 of the CoT tokens. 4/5
1
0
23
Approach: distill a teacher's explicit reasoning into student & emulator's implicit reasoning.a Mind-Reading the Teacher: student learns to use the teacher's states to answer directly.b Thought Emulation: emulator predicts teacher states.c Couple and Optimize: couple a and b 3/6

2
1
22
For those working on NeurIPS benchmarks: I found \usepackage{caption} causes table caption spacing to disappear. Here's a great solution from Pieter van Oostrum (: use \captionsetup[table]{position=below} to trick caption into thinking captions are below.
0
4
21
We received many questions about how WildChat was collected during #ICLR poster. It's gathered through chatbots hosted on @huggingface, using OpenAI's API funded by @ai2_mosaic. Check it out here: Missed our poster? View it here:
If you're at #ICLR, come to our poster on WildChat tomorrow afternoon! We collected 1 million user-ChatGPT conversations with geographic info. Presented by @wzhao_nlp and me. 📅 Time: Thursday, May 9, 4:30 PM - 6:30 PM CEST.📍 Location: Halle B #239. 🔗
0
1
19
Our study also expands the GSM8K dataset with an additional 378K examples generated by GPT-4, making it possible to train small LMs to get reasonable performance. We've made our code, data, and models publicly available at 5/6

2
0
17
Paradigm Comparison (CoT: chain-of-thought):.No CoT: directly produce the answer with no reasoning guidance.Explicit CoT: predict reasoning steps before the answer.Implicit CoT: directly produce the answer with internalized hidden state reasoning 2/6

1
0
18
Results: Implicit CoT outperforms No CoT and is faster than Explicit CoT.No CoT: GPT2-Med struggled at 5×5 mult.Implicit CoT: Accuracy increased to 96%.Explicit CoT: Accurate but slow.Surprisingly, GPT4 got 44% on GSM8K w/ No CoT, suggesting internal reasoning/data leakage 4/6

1
0
18
Happy to see WildChat featured in @washingtonpost by @jeremybmerrill @rachelerman! Read the article here: A huge shoutout to the team @wzhao_nlp @xiangrenNLP @jmhessel @clairecardie @YejinChoinka. Explore 1M indexed conversations:
1
7
17
👀Fascinating read about what users chat with GenAI bots for: from @nngroup (shared by @yuwen_lu). We're equally curious @ai2_mosaic! It'd be amazing if @nngroup could study real-world chats using our WildChat dataset 🔗

Really interesting article on what users talk to GenAI chatbots for. via @nngroup.
1
2
17
Is cursor down now? Didn't realize how much I rely on it---feels like the time I couldn't code without stackoverflow. I really wish they implemented it to call the APIs directly instead of routing everything through their servers.
3
0
17
@jxmnop My experience is that GPT-4 Turbo is better than GPT-4: in math reasoning it's as accurate as GPT-4 but faster (and cheaper). Plus, it draws better unicorns🦄(see and compare to GPT-4's).
Is GPT-4 Turbo as good at math reasoning as GPT-4? 🤔Inspired by @wangzjeff's SAT reading comparison, I tested on 4×4 and 5×5 multiplications & GSM8K (grade school math problems). Results? 📊 Turbo matches GPT-4's accuracy while being 2-3X faster. Code:
3
0
16
@adveisner Great question! I actually sent 4 simultaneous requests every hour (using 4 processes). Interestingly, the results still varied most of the time. This suggests that nondeterminism is present even with concurrent requests.🎲.
1
0
16
Special thanks to my coauthors: Kiran Prasad, Roland Fernandez (@rolandalong), Paul Smolensky (@paul_smolensky), Vishrav Chaudhary (@vishrav), and my PhD co-advisor Stuart Shieber (@pmphlt). 6/6.
1
0
16
@far__el Apologies for the inconvenience. Could you specify which link isn't working? In the meantime, here are the direct links:. Paper: GitHub: Thank you for your interest!.
1
0
15
@goodside Did you discover this independently or did you see Yuchen Lin's post? If it's the latter, I think you should credit the original source.

😅Math Olympiad becomes easier for AI; Common sense is still hard.

1
0
14
@jxmnop Lol i missed your msg. To me implicit CoT is generating soft CoT vectors in the vertical direction, which isn't that different from generating them in the horizontal direction if we think about the computation graph, since in vertical there's still a recurrent dependency.
1
2
11
@zdhnarsil My intuition is that continuous relaxations can only point to local perturbations that lead to an increase in reward, but it might be hard to explore a large search space such as entire sequences of text in open-ended generation.
0
0
12
GPT-4 excels at creating epanadiplosis, i.e., sentences that begin and end with the same word, compared to ChatGPT (success rate of 92% vs 22%). However, this comes at the cost of diversity: over 90% of its generations start with the word "Dreams".


1
1
12
@_TobiasLee @YejinChoinka @pmphlt Thanks for the kind words! Yes, we applied this to GSM8K. It can finetune Mistral 7B to achieve 51% accuracy without CoT steps (compared to 68% with explicit CoT and 38% with No CoT). The paper can be found at
0
0
11
Data: Model: I think it's possible to train stronger/more interpretable models. For example, this might be a good application for tree prompting (.

1
0
10
Excited to see what the 128K token limit of #GPT4Turbo unlocks! Proud of Wenting's initiative with our WildChat project @ai2_mosaic to give back to the community🚀.
Hi friends, for a limited time, our WildChat project will provide free access to GPT-4 turbo: For any data we collect during this period, we will give it back to the community 😊. Paper: Thank @ai2_mosaic for the generous support.
0
0
11
@lateinteraction @jxmnop Implicit CoT reasons using hidden states across different transformer layers, so it is autoregressive in the sense that every soft CoT vector depends on previous ones. I think collapsing/discretizing to actual tokens, or doing search as in ToT are indeed ideas worth exploring.
0
1
11
For those at EMNLP, we are presenting WildVis now at D3 (riverfront hall)!.
What do people use ChatGPT for? We built WildVis, an interactive tool to visualize the embeddings of million-scale chat datasets like WildChat. Work done with @wzhao_nlp @jmhessel @xiangrenNLP @clairecardie @YejinChoinka. 📝🔗1/7
0
1
10
@jxmnop Although I agree that it's more expressive to generate more soft vectors in the horizontal direction, like instead of generating 1 step X L vectors in implicit CoT we can generate N steps X L vectors, which offers more scratch space.
1
2
10
Update on our #GPT4Turbo chatbot: the daily limit has been upped to 10K requests🚀 Explore what 128K tokens can do:
Hi friends, for a limited time, our WildChat project will provide free access to GPT-4 turbo: For any data we collect during this period, we will give it back to the community 😊. Paper: Thank @ai2_mosaic for the generous support.
0
1
10
Has anyone encountered context length limit issues with OpenAI's Moderation API? I'm unable to find details on its limit/tokenizer. It seems to error out for inputs exceeding 7k Chinese characters. Example: Discussing here as well:
0
0
9
Handling data at scale always presents edge cases. In preparing WildChat-1M, besides Moderation issues↓, we found a curse word repeated thousands of times w/o spaces, causing the Presidio analyzer in PII removal to hang. Stay tuned for the upcoming release of WildChat-1M!
Update on Moderation API issue: length errors seem to link to non-Latin characters. E.g., Moderation can handle 1M Latin characters but fails for a few K non-Latin characters on WildChat (Korean, Chinese, etc). Code for reproducing the err & a workaround:
0
1
9
Starting now, Halle B #239.
If you're at #ICLR, come to our poster on WildChat tomorrow afternoon! We collected 1 million user-ChatGPT conversations with geographic info. Presented by @wzhao_nlp and me. 📅 Time: Thursday, May 9, 4:30 PM - 6:30 PM CEST.📍 Location: Halle B #239. 🔗
0
1
9
I noticed o1's reasoning can be slow even for simple tests (e.g., typing random words like "tet"). I wonder if this is a good application for internalizing chain of thought reasoning (implicit CoT):.
Can we teach LMs to internalize chain-of-thought (CoT) reasoning steps? We found a simple method: start with an LM trained with CoT, gradually remove CoT steps and finetune, forcing the LM to internalize reasoning. Paper: Done w/ @YejinChoinka @pmphlt 1/5
0
0
9
We're moving the WildChat dataset to the ODC-BY license to make it easier for the community to build upon this resource. Check out the updated documentation here:
What do people use ChatGPT for? I built a website for interactive search of WildChat, allowing keyword, toxicity, IP, language, and country-based searches. Indexed 1M conversations with Elasticsearch. Based on MiniConf's template. Check it out:
0
2
8

@jxmnop Because it's unstable and doesn't work? This paper shows MLE is usually better Over the years I've reviewed several papers claiming they are the first to make language GAN work. .
1
1
8
@sytelus That's surprising. Taking it to the extreme with zero downstream training data, wouldn't the proposed approach result in random performance, while pretraining on external data has the potential for a decent zero-shot performance?.
1
0
8
Thanks for mentioning our work! We have a demo showing that math CoT can indeed be internalized (compiled):

System 2 distillation can ‘compile’ tasks, freeing up LLM time to work on harder things, in analogy to humans. It doesn’t always work - it’s harder to distill e.g. CoT for math – also like for humans (although see . Have fun distilling this work!.🧵(5/5)

1
1
7
Interesting analysis by @NZZTech on WildChat, focusing on German-language conversations! They found that most German-language users treat ChatGPT like a search engine, with 45% of queries seeking concrete information. Grateful to see our work featured!.

Seit zwei Jahren gibt es Chat-GPT. Nun liefert ein Datensatz Einblick in die Konversationen zwischen Mensch und KI. Wir haben ihn analysiert und dabei ein paar überraschende Erkenntnisse gewonnen.
2
0
7
Code is available at Built on @hen_str & @srush_nlp's MiniConf, with Elasticsearch, text-embedding-3, and UMAP. To reduce clutter, only a subset of conversations is visualized, but when there aren't enough matches, search extends to the full dataset. 7/7.
0
1
7
@agarwl_ I think "Training Chain-of-Thought via Latent-Variable Inference" (TRICE) might also be relevant.
1
0
7
Update on Moderation API issue: length errors seem to link to non-Latin characters. E.g., Moderation can handle 1M Latin characters but fails for a few K non-Latin characters on WildChat (Korean, Chinese, etc). Code for reproducing the err & a workaround:
Has anyone encountered context length limit issues with OpenAI's Moderation API? I'm unable to find details on its limit/tokenizer. It seems to error out for inputs exceeding 7k Chinese characters. Example: Discussing here as well:
0
0
7
@ai_bites Indeed, our current evidence mainly supports the speed argument, but my deeper aim is to break from the notion that LMs must adhere to human-like reasoning. Instead, I hope to enable LMs to develop their own reasoning pathways, leveraging their capabilities very different from us.
1
0
7
@realmrfakename @YejinChoinka @pmphlt Yes, the multiplication model weights are on huggingface now. You can find them linked in this huggingface demo:.
We built a demo using GPT-2 to directly produce the product of two numbers (up to 15 digits) without chain-of-thought (CoT). CoT is internalized using our method below. Try it out:
0
0
5
@fredahshi @davlanade ThX for the resources! They confirm that teaching an LM to internalize CoT in English helps it to internalize in other languages, especially those the base LM understands. The figure shows the top 5 languages the base LM understands (measured by fewshot CoT acc on MGSM/AFRIMGSM).

0
3
6
@WenhuChen Thanks, Wenhu! Excited to be a part of the soon-to-be biggest NLP group in Canada 🚀. Looking forward to contributing and collaborating! 🎉.
0
0
5
@ShunyuYao12 At least then we could version control model weights for consistent results across experiments. No more "Hey, why doesn't it work like last month?" moments. Case in point: (notice the different results of GPT-4 0613 between June and October).

Result: Abysmal performance by even the best LLMs. CoT does improve model performance, but it falls short of bridging the gap with human performance. While FANToM is not for training purposes, we observe that fine-tuning alone is insufficient for achieving coherent ToM reasoning.

0
0
6
@GaryMarcus @mosesjones Thank you for the discussion! Our evaluation was done using APIs, where models don't have access to tools (such as Python) available in the ChatGPT web UI. A similar observation was made in another work from @YejinChoinka's group (Figure 2(a)):.

🚀📢 GPT models have blown our minds with their astonishing capabilities. But, do they truly acquire the ability to perform reasoning tasks that humans find easy to execute? NO⛔️. We investigate the limits of Transformers *empirically* and *theoretically* on compositional tasks🔥

1
0
6
This is so cool---great to see WildChat extended in such a big way! Incredible that 10,000 H100 hours went into this. Excited to see what comes out of WildChat-50M!. Check out their dataset here:

(trying again since butter fingers thread fail). Excited to announce WildChat-50m: A one-of-its-kind dataset with over 50 million (!!) multi-turn synthetic conversations. Congratulations to star NYU PhD student @FeuerBenjamin for assembling this! 🧵.
0
0
5
We can compare topic clusters across datasets. WildChat (green) has a Midjourney cluster (red, top panel, discovered by @jeremybmerrill @rachelerman), while LMSYS-Chat (blue) has chemistry outliers (red, bottom panel, discovered by @Francis_YAO_). 🔍4/7

1
1
5
@besanushi @OpenAI This seems to be a plausible explanation in the discussion thread on tracking unicorns (:

@yuntiandeng @adveisner IIUC, the inherent parallelism in GPU matrix multiplication could introduce some tiny numerical perturbations, which means there’s a small chance the “most likely” token can flip when there’re a few of them with *very close* probabilities.
0
0
5
@rljfutrell Isn't the most probable sample likely to be a replication of previous strings? The issue might be a lack of sufficient preceding strings to serve as training examples. Perhaps experimenting with a substantially long prompt as "training data" could yield more meaningful results.
1
0
5
@WenhuChen @wzhao_nlp Lol I thought only my committee members had read my thesis---glad to see LLMs also do that these days😄.
0
0
5
@Patticus We recently published 650K real user-ChatGPT conversations, which can be used to explore how others use ChatGPT:
0
1
5
@jxmnop @PsyNetMessage Right implicit CoT doesn't produce green tokens, but only soft CoT vectors in the vertical direction per 1 step, and they are distilled from a teacher doing CoT. I only considered 1 step as I thought for LLMs w/ many layers, even the soft vectors produced per 1 step is enough.
0
0
4