

Omar Khattab
@lateinteraction
Followers
18K
Following
12K
Media
269
Statuses
6K
Incoming asst professor @MIT EECS. Research scientist @Databricks. @StanfordNLP CS PhD. Author of https://t.co/VgyLxl0VZz & https://t.co/ZZaSzaRIOF.
Stanford, CA
Joined December 2022
I'm excited to share that I will be joining MIT EECS as an assistant professor in Fall 2025!. I'll be recruiting PhD students from the December 2024 application pool. Indicate interest if you'd like to work with me on NLP, IR, or ML Systems! Stay tuned for more about my new lab.
254
95
2K
🔗 Thoughts on Research Impact in AI. Grad students often ask: how do I do research that makes a difference in the current, crowded AI space?. This is a blogpost that summarizes my perspective in six guidelines for making research impact via open-source artifacts. Link below.

23
267
1K
Introducing Demonstrate–Search–Predict (𝗗𝗦𝗣), a framework for composing search and LMs w/ up to 120% gains over GPT-3.5. No more prompt engineering.❌. Describe a high-level strategy as imperative code and let 𝗗𝗦𝗣 deal with prompts and queries.🧵.
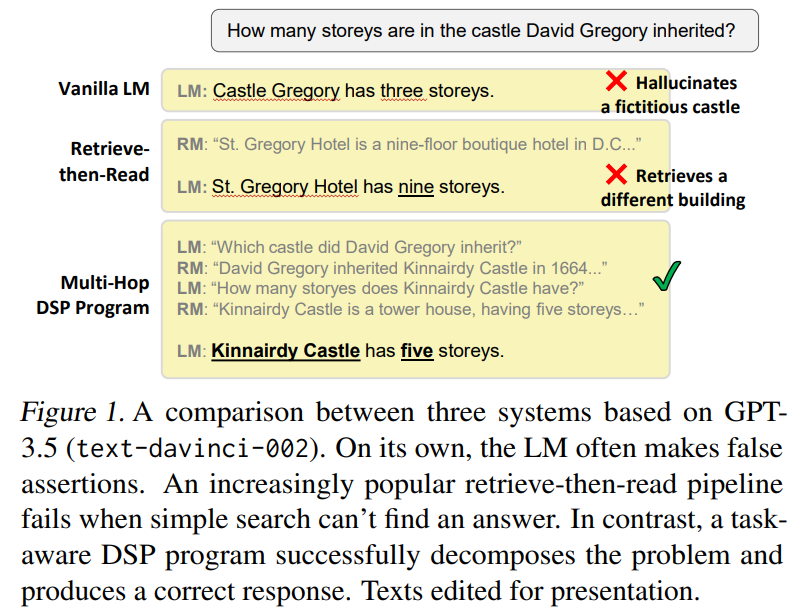
32
194
973
A cool thread yesterday used GPT4 ($50), a 500-word ReAct prompt, and ~400 lines of code to finetune Llama2-7B to get 26% HotPotQA EM. Let's use 30 lines of DSPy—without any hand-written prompts or any calls to OpenAI ($0)—to teach a 9x smaller T5 (770M) model to get 39% EM!. 🧵

18
141
970
We started this project thinking LMs can’t be prompted to do classification tasks with over 10,000 classes — especially when documents are long!. But the incredible @KarelDoostrlnck found this elegant DSPy program that, once optimized on ~50 examples, sets the state of the art.


📢Tasks with > 10k classes (e.g. information extraction) are hard for in-context learning: typically a tuned retriever or many in-context calls per input are used ($$$). Infer-Retrieve-Rank (IReRa) is a SotA program using 1 frozen retriever with a query predictor and reranker.

18
125
907
Progress on dense retrievers is saturating. The best retrievers in 2024 will apply new forms of late interaction, i.e. scalable attention-like scoring for multi-vector embeddings. A🧵on late interaction, how it works efficiently, and why/where it's been shown to improve quality

25
130
704
🚨Announcing 𝗗𝗦𝗣𝘆, the framework for solving advanced tasks w/ LMs. Express *any* pipeline as clean, Pythonic control flow. Just ask DSPy to 𝗰𝗼𝗺𝗽𝗶𝗹𝗲 your modular code into auto-tuned chains of prompts or finetunes for GPT, Llama, and/or T5.🧵.
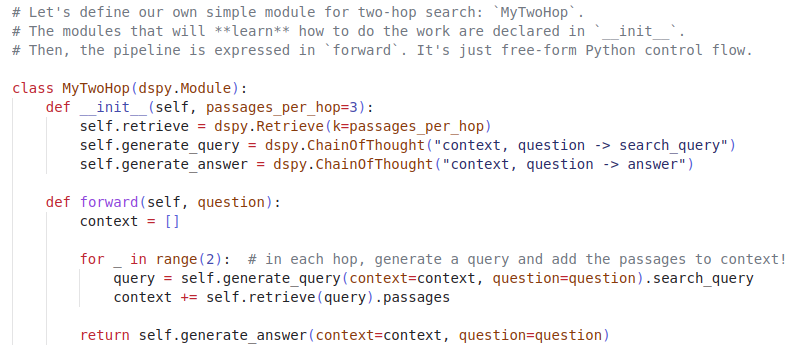

24
138
638
I worry about a bubble burst once people realize that no AGI is near—no reliably generalist LLMs or “agents”. Might seem less ambitious but it's far wiser to recognize: LLMs mainly create opportunities for making *general* progress for building AIs that solve *specific* tasks.
33
60
633
Some personal news: I'm thrilled to have joined @Databricks @DbrxMosaicAI as a Research Scientist last month, before I start as MIT faculty in July 2025!. Expect increased investment into the open-source DSPy community, new research, & strong emphasis on production concerns 🧵.
🧵What's next in DSPy 2.5? And DSPy 3.0?. I'm excited to share an early sketch of the DSPy Roadmap, a document we'll expand and maintain as more DSPy releases ramp up. The goal is to communicate our objectives, milestones, & efforts and to solicit input—and help!—from everyone.

49
27
634
🚨Announcing the largest study focused on *how* to optimize the prompts within LM programs, a key DSPy challenge. Should we use LMs to… Craft instructions? Self-generate examples? Handle credit assignment? Specify a Bayesian model?. By @kristahopsalong* @michaelryan207* &team🧵

15
126
600
A🧵on beating the hardware lottery for retrieval: the internals of the late interaction stack. ColBERT introduced a quirky multi-vector retrieval architecture. It does wonders for quality. But how can it search 100M docs in 0.1 sec on CPU? Or store 1 billion embeddings in 20GB?

9
78
473
🚨When building LM systems for a task, should you explore finetuning or prompt optimization?. Paper w/ @dilarafsoylu @ChrisGPotts finds that you should do both!. New DSPy optimizers that alternate optimizing weights & prompts can deliver up to 26% gains over just optimizing one!

5
75
451
🚨Introducing the 𝗗𝗦𝗣 compiler (v0.1)🚨. Describe complex interactions between retrieval models & LMs at a high level. Let 𝗗𝗦𝗣 compile your program into a much *cheaper* version!. e.g., powerful multi-hop search with ada (or T5) instead of davinci🧵.
4
96
433
OpenAI released a wrapper of GPT-4o and everyone is going bonkers :P.
26
20
436
Hello. We receive so many questions about agents in DSPy. Did you know you that ~15 lines of DSPy can turn an agent that scores 30% to a prompt-optimized, multi-agent aggregation system that scores 60% EM on a HotPotQA sample?. I released a notebook showing how to do this 🧵⤵️

9
76
426
🧵If you have just 10 labels & want to train a model, what should you do?. Announcing PATH: Prompts as Auto-optimized Training Hyperparameters. Training on synthetic data *whose quality improves over time* via DSPy. Training SoTA-level IR Models w/ 10 Labels, by @jsprxian &team

10
67
423
Want to search PDFs directly (without OCR) and achieve high accuracy?. ColPali (@sibille_hugues @tonywu_71 @ManuelFaysse) is a vision-based ColBERT-style IR model; by far the best method for this. Thanks to @bclavie you can use ColPali over your PDFs w/ a super approachable API.

RAG is increasingly going multi-modal, but document retrieval is tough, and layout gets in your way. But it shouldn't!. Introducing 🪤RAGatouille's Vision-equipped, ColPali-powered sibling: 🐭Byaldi. With just a few lines of code, search through documents, with no pre-processing.

9
48
408
Surprised this is still not a common way to properly evaluate models.

37
18
406
Ah man, I only have 2 years of experience with the framework and its earlier versions….

BTW: @SynthflowAI is hiring a Senior Software Engineer with min. 3years DSPy experience. Please reach out to me. cc/ @cyrusofeden @lateinteraction.
20
23
394
Sometime in '23, LMs switched from "few-shot learners" to aggressive post-training & validation on all benchmarks. Many folks hadn't noticed that—and now feel betrayed. They assumed these MATH/MMLU/ARC scores are "zero-shot", whereas actually LMs are trained & selected on them.

Raising visibility on this note we added to address ARC "tuned" confusion:. > OpenAI shared they trained the o3 we tested on 75% of the Public Training set. This is the explicit purpose of the training set. It is designed to expose a system to the core knowledge priors needed to.
14
43
386
With all the excitement around ColBERT today, thanks to the RAGatouille library, this is a good time to understand:. • What makes ColBERT work so well?.• How is it different from standard dense retriever?.• How can it search 100M docs in 0.1 seconds, with no GPU?.
Progress on dense retrievers is saturating. The best retrievers in 2024 will apply new forms of late interaction, i.e. scalable attention-like scoring for multi-vector embeddings. A🧵on late interaction, how it works efficiently, and why/where it's been shown to improve quality
6
58
361
There's an important missing perspective in the "GPT-4 is still unmatched" conversation:. It's a process (of good engineering at scale), not some secret sauce. To understand, let's go back to 2000s/2010s when the gap between "open" IR and closed Google Search grew very large. 🧵.

The recent releases of many GPT-3.5 class AIs (Grok, Mixtral, Gemini Pro) are oddly unilluminating about the future of frontier AI. It’s been a year & no one has beat GPT-4. Will they? Is there some magic there? Does it indicate a limit to LLMs? Will GPT-4.5 be another huge jump?.
8
44
354
has anyone managed to reunite Kullback and Leibler after their divergence.
21
14
345
🧵What's next in DSPy 2.5? And DSPy 3.0?. I'm excited to share an early sketch of the DSPy Roadmap, a document we'll expand and maintain as more DSPy releases ramp up. The goal is to communicate our objectives, milestones, & efforts and to solicit input—and help!—from everyone.
9
73
340
Exactly. What's surprising even in hindsight is that the difference between working extremely well (81.3% for ColPali) and not working at all (58.8% for BiPali) is the "Col" part of ColPali, i.e. ColBERT late interaction. VLMs & vector representations alone don't do the trick!


It's fascinating how a small 3B model like ColPALI can disrupt the PDF extraction industry overnight.
4
48
337
🚨Announcing 𝗟𝗠 𝗔𝘀𝘀𝗲𝗿𝘁𝗶𝗼𝗻𝘀, a powerful construct by @ShangyinT* @slimshetty_* @arnav_thebigman*. Your LM isn't following complex instructions?. Stop prompting! Add a one-liner assertion in your 𝗗𝗦𝗣𝘆 program: up to 35% gains w auto-backtracking & self-refinement🧵

11
50
312
Obligatory ICLR tweet: DSPy accepted as Spotlight. 1. This could be a notable start of a pattern at ML confs—as our metareviewer says, "refreshing to see this unconventional research style (developing programming models) at ICLR". 2. Time for a crisp thread on DSPy & what's new?.
21
29
313
Surprised not to see many say this: OpenAI just declared the *end* of a paradigm, more so than the beginning of a new one. Scaling inference is powerful and interesting; same as two years ago. What's new? Declaring that scaling up the model itself & doing standard RLHF is over.
With the small model size of gpt-turbo, the strong reliance on human feedback, and the addition of tools/plugins, OpenAI (like many others) is silently giving up on the notion that scale is all you need, but without conceding that. This is a welcome step, but it should be noted.
18
33
311
Initiative is often rewarded. Fun story: When we started DSPy, the name `dspy` was taken on pypi, so I went with `pip install dspy-ai`. Many months later, a user (@tom_doerr) was trying to install `dspy` and got the wrong library. Upset with this, he reached out to the owner of.
13
17
297
How does one explain the phenomenon where something like "RAG" can become approximately the hottest area in all of STEM for 2 years, but also there's virtually no representative general RAG benchmark made by literally anyone yet?.
28
22
301
I tweet less often than I used to for now, but man is DSPy 3.0 going to just be awesome.
15
14
284
When building ColBERT, I assumed it will pave the way for hypernetwork-based, pruning-capable retrieval indexes. Let me explain. The big insight in ColBERT is that we can encode each document upfront *not* into a vector, but into a rich scoring function, f: query -> float, which.
12
27
289
Talking to grad students, too many think that long-term projects (not scattered papers), proper code releases, thoughtful benchmarks are "not incentivized". Most often they're mistaken. If we're talking incentives, *nothing* matches demonstrating impact! Will blog on this soon.
9
25
286
This @dhh #RailsWorld quote from last week resonates. “Complexity is actually a necessary ingredient to progress, but it's not where we stop. We're not done by the time we've solved it — we're done by the time we've made it simple.”

8
42
282
If I free an hour to post an annotated explanation of @haizelabs’s DSPy code for doing this, will people be interested? It’s just ~100 lines but it’s doing so much.

🕊️red-teaming LLMs with DSPy🕊️. tldr; we use DSPy, a framework for structuring & optimizing language programs, to red-team LLMs. 🥳this is the first attempt to use an auto-prompting framework for red-teaming, and one of the *deepest* language programs to date
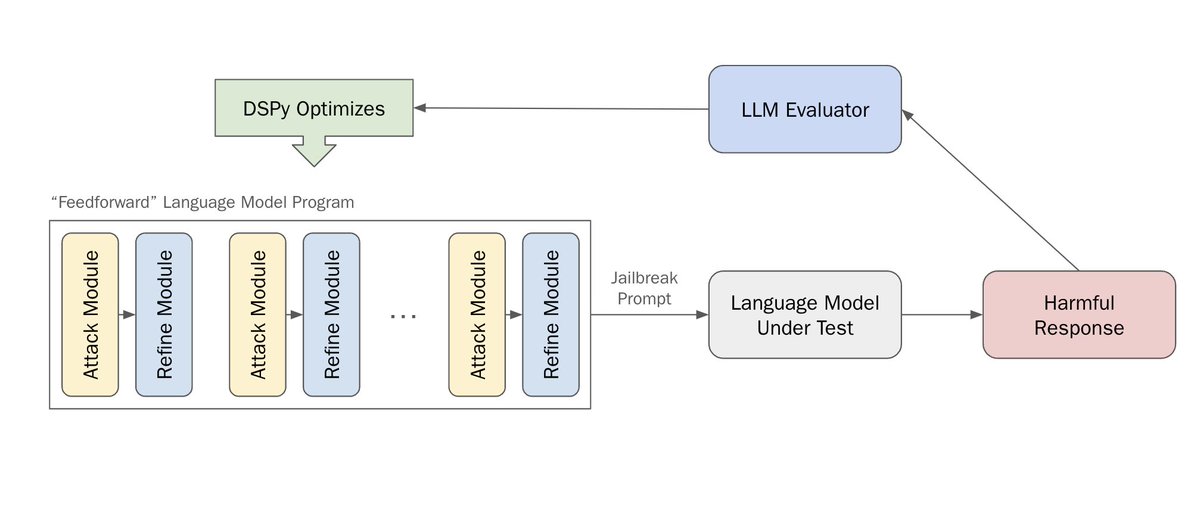
25
16
271
The LM dev stack will soon evolve dramatically. To start, @hwchase17 & I tackle interoperability: Now LangChain users can compile LCEL chains with DSPy optimizers⚡️. To illustrate, we compile LCEL for a long-form RAG app, delivering 10-20% higher output quality. Let's dive in⤵️

12
48
266
Generating long articles with accurate citations is hard!. New paper with @EchoShao8899 & team introducing STORM, a system for *Research*-Augmented Generation—with lots of insightful automatic & human evals. One of my favorite examples of LM Programs solving really hard tasks!


Can we teach LLMs to write long articles from scratch, grounded in trustworthy sources?. Do Wikipedia editors think this can assist them?. 📣Announcing STORM, a system that writes Wikipedia-like articles based on Internet search. I now use STORM in my daily research!🧵
5
56
264
waiting for the day when people start selling Organic Intelligence: 100% certified GPT-free, whole-brain human.
35
34
260
Right, LLMs are fuzzy devices, and everyone writing prompts is coding in assembly. You could be writing well-defined modules instead, and asking a compiler to build and optimize the messy parts:


With many 🧩 dropping recently, a more complete picture is emerging of LLMs not as a chatbot, but the kernel process of a new Operating System. E.g. today it orchestrates:. - Input & Output across modalities (text, audio, vision).- Code interpreter, ability to write & run

4
24
259
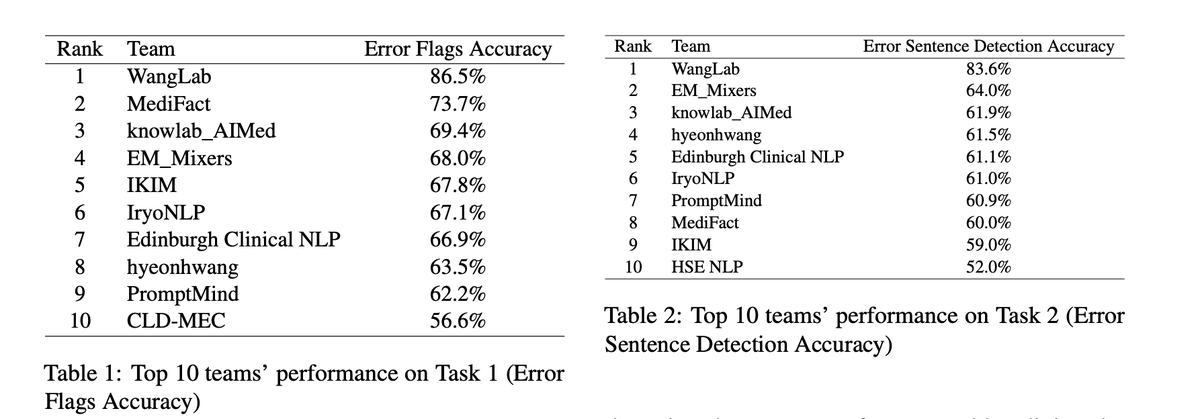
🔥Congratulations to @ugustintoma et al (@BoWang87 Lab) for winning the 1st place in *every* sub-task of the 2024 MEDIQA Clinical NLP competitions. They build & optimize extremely high-quality LM programs in DSPy, outperforming the next best participating system by up to 18 pt!

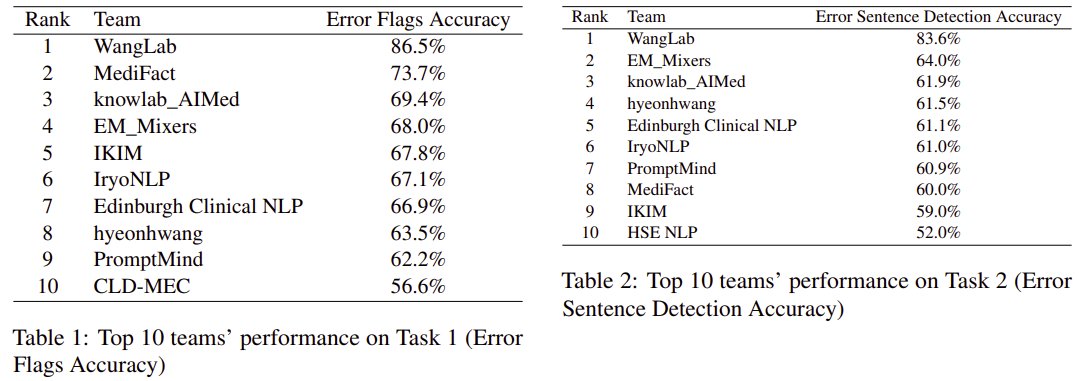

(2/3) The first challenge is about using AI to detect and then correct medical errors. We've developed an innovative method to detect and correct specific medical errors in clinical notes, achieving top results in all three subtasks. 🩺🔍 Key to our success? Utilizing the DSPy


5
47
257
@markopolojarvi This is a surprisingly common take, and I don’t get it. I suspect it’s just bad tooling (do you use conda) or you work with long tail, unpopular packages a lot. In my world, pip and conda install almost always just work. The only exception is when cuda is involved. That’s it.
22
3
250
🚨New features in 𝗖𝗼𝗹𝗕𝗘𝗥𝗧🚨. ‣ Index Updater. Simple API to add/remove documents. By: Xinran Song, Keshav Santhanam. ‣ Base Models. Train ColBERT with encoders like ELECTRA, DeBERTa, etc. By: Deval Srivastava, Teja Gollapudi, @rickbattlephoto.
2
50
253
2012: A @UofT team created AlexNet. It showed the power of DNNs, outperforming ImageNet's runner up by 11 pts. 2024: @BoWang87 Lab at @UofT built & optimized several DSPy programs, beating the next best MEDIQA system by *20 pts*!. The AlexNet moment for optimized LM programs?🧵


(2/3) The first challenge is about using AI to detect and then correct medical errors. We've developed an innovative method to detect and correct specific medical errors in clinical notes, achieving top results in all three subtasks. 🩺🔍 Key to our success? Utilizing the DSPy
3
51
252
Interesting prompt for OpenAI Tasks. Good case study. The issue with this kind of prompt is that it blurs specification and implementation too much. The actual important information the human wanted to express is mixed with the verbiage required to get the model to follow


My notes on the new OpenAI ChatGPT scheduled tasks feature, including a copy of the new tool instructions from a leaked system prompt
10
25
253
Man! Mamba is so cool! 🤩. Sasha's tweet reminds me: Every time you use ColBERTv2, you're using Keshav Santhanam's C++ (or CUDA) kernels implementing PLAID late interaction. No other way it could search multi-vector 140,000,000 documents in 100 milliseconds, even *without* a GPU!


What's neat about the Mamba paper is that they're really exploring the design space outside of PyTorch. Like this model makes no sense if you aren't willing to get your hands dirty and prove it.

1
22
250
Folks ask how this will affect DSPy & ColBERT. Well—extremely positively!. Both grew dramatically in 2024, while I was busy w faculty interviews & a broken (but now almost recovered!) left hand. Looking forward, you should expect *a lot* more research and OSS in both directions!.
I'm excited to share that I will be joining MIT EECS as an assistant professor in Fall 2025!. I'll be recruiting PhD students from the December 2024 application pool. Indicate interest if you'd like to work with me on NLP, IR, or ML Systems! Stay tuned for more about my new lab.
15
11
244
The timing though lol.

This is not good, "Surprisingly, we observe a significant decline in LLMs’ reasoning abilities under format restrictions.". Link:

8
12
245
New major release in DSPy! With a whole lot of new results on a bunch of tasks. Language Model Assertions — work by @arnav_thebigman, @ShangyinT, @slimshetty_. New: DSPy will now teach your LM to follow complex constraints (assertions), and will handle retries on top of that⤵️.

There’s huge interest now in *programming* with LMs, but it’s unclear how to actually enforce constraints like “make sure the output is engaging & has no hallucination”. Just ask the LM nicely??. We built **DSPy LM Assertions** so you have far better control—up to 164% gains!

12
50
239
This is incredibly cool to see! But there's an implicit leap somewhere that needs deeper discussion. If you have an 8B verifier, your system has 8B+ parameters, right? In that case, it's hard to interpret beating an 8B model. Is it faster overall than just asking the 8B model?.

Just 10 days after o1's public debut, we’re thrilled to unveil the open-source version of the groundbreaking technique behind its success: scaling test-time compute 🧠💡 . By giving models more "time to think," LLaMA 1B outperforms LLaMA 8B in math—beating a model 8x its size.

14
11
243
Quick-n-dirty 🧵on understanding DSPy as 4 related but different things. 1. A new category of ML models, Language Programs. 2. A programming model (abstractions) for expressing & optimizing LPs.3. New optimizers: ML algorithms to tune the parameters of LPs.4. A library for 1-3⤵️.
2
45
237
Just merged a small pull request into DSPy. This is the first pull request so far by the CEO of a major LLM provider 👀.
11
6
233
I asked 🌪STORM to write an article on ColBERT. It produced a 3500-word article with 20 references!. 📸 Screenshots:. * Part of the Table of Contents.* Intro.* Funny but important section on how "ColBERT late interaction" is different from "Colbert's Late Show"



Can we teach LLMs to write long articles from scratch, grounded in trustworthy sources?. Do Wikipedia editors think this can assist them?. 📣Announcing STORM, a system that writes Wikipedia-like articles based on Internet search. I now use STORM in my daily research!🧵
10
30
232
Everyone talks about how fast AI progress is, but honestly I can't stop thinking about how unbelievably inefficient we are, collectively, given the incredible amount of investment and concentration in this area.
22
14
225
Apparently this got 900k views. I have no doubt it's the elegance of DSPy code behind that. Jokes aside, we realize many people still don't quite understand how each multi-step prompt optimizer works internally, and we're working on better illustrations alongside new releases.
We started this project thinking LMs can’t be prompted to do classification tasks with over 10,000 classes — especially when documents are long!. But the incredible @KarelDoostrlnck found this elegant DSPy program that, once optimized on ~50 examples, sets the state of the art.
4
17
220
As we gear up for new ColBERT releases, we thought why not have a nice logo too. Thanks to @chuyizhang_, our README now looks like this:

5
18
222
Since it's Llama3 day, I took the fancy multi-agent program below (originally for GPT-3.5) and compiled it with Llama3-8b. Bootstraps its own prompts: while the zero-shot version is at 24% (substantially worse than GPT-3.5), the optimized version gets an extremely high 59%. ⤵️.
Hello. We receive so many questions about agents in DSPy. Did you know you that ~15 lines of DSPy can turn an agent that scores 30% to a prompt-optimized, multi-agent aggregation system that scores 60% EM on a HotPotQA sample?. I released a notebook showing how to do this 🧵⤵️
6
27
213
This is a fantastic paper improving the efficiency of ColBERT retrieval — by authors including @fmnardini @RossanoVent whose work on efficient IR I learned a lot from in my undergrad research years. Probably also one of the best intros into how ColBERTv2+PLAID currently works.

📌 “Efficient Multi-Vector dense retrieval with Bit vectors” (EMVB), a novel framework for efficient query processing in multi-vector dense retrieval. 📌 First, EMVB employs a highly efficient pre-filtering step of passages using optimized bit vectors. 📌 Second, the

5
31
215
In so many ways, good and bad, (LLM-based) Agents are the new object-oriented programming.
11
18
208
Not sure if this is just me, but honestly nothing beats text for most communication. Most meetings could be slack asyncs. Most videos could have been blog posts or even just threads. I don’t get why this isn’t a more common viewpoint.
29
13
204
Can’t overstate the magnitude of this kind of finding. Best-in-class retriever using 100x less data? LM twitter is basically sleeping on the effects of ColBERT. Most IR applications are in low-data domains. Here’s your recipe to do *extremely* well with little resources:.
After a few more evals and writing, the proper announcement: I'm releasing JaColBERT, a ColBERT-based model for 🇯🇵 Document Retrieval/RAG, trained exclusively on 🇯🇵 Data, and reaching very strong performance! (Report: arXiv soon!)
4
13
204
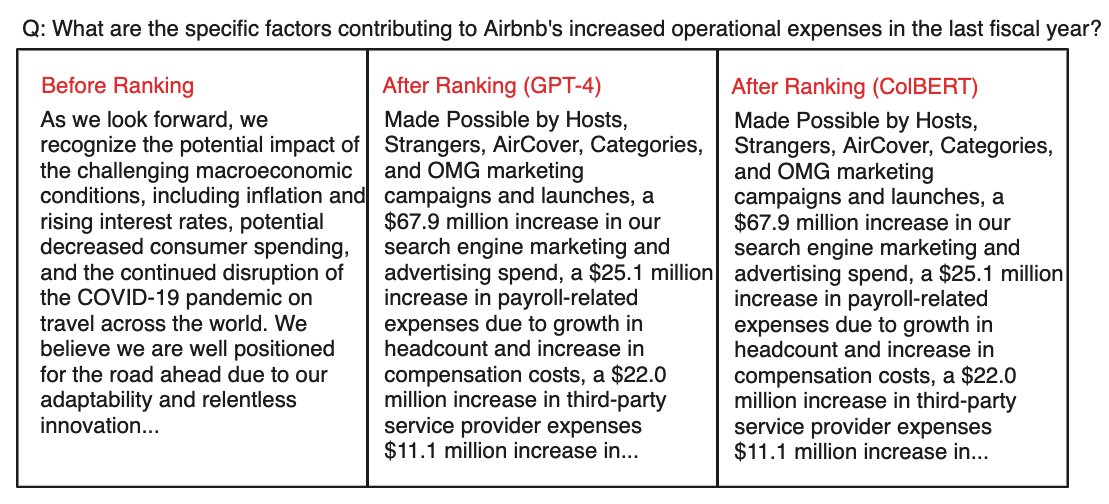
Nice. Quoting:. > ColBERT and GPT-4 were identical in ranking quality but ColBERT was lightning-fast. > ColBERT is a game-changer for re-ranking tasks. I add: also game-changer for retrieval. ColBERT is basically the only “reranker” that can directly search a billion passages.

Faster RAG re-ranking with ColBERT. After re-ranking using GPT-4 yesterday, I tested out ColBERT for re-ranking today. Test: .• Re-ranking Airbnb's 10-K, like before. Results: .• ColBERT and GPT-4 were identical in ranking quality . However, ColBERT was lightning-fast.
3
30
199
Can we teach small, local LMs to *use* large, remote LMs as *tools*? Papillon with @Sylvia_Sparkle & team shows that this can be very consequential for privacy. Using DSPy optimizers, we can teach Llama3-8B to reach 86% of frontier LLMs' quality while hiding your private data!.

Concerned about sending private data to LLM providers, but local LLMs aren't as good?. Introducing PAPILLON 🦋, a system that uses local LLMs to create privacy-preserving LLM queries for you. 🦋 prevents leakage of PII (93%) while retaining response quality on 85% of queries! 🧵

8
23
201
OpenAI changed their *actual API* from system_prompt to developer_prompt because they wanted the *model* to better understand the role that element plays!. The name you give to your abstraction now matters more than ever, because it’s implemented with in-context learning.

@Danmoreng @simonw @OpenAIDevs The reason is that we wanted to make it clearer to the model where instructions were coming from, so it could better reason about what to do with them. We've made the API both forward and backward compatible via autoconversion, so any breakage is minimal, I hope.
18
14
205
Everyone talks about AI engineers but no one appreciates the poor AI plumbers fighting leaky abstractions all day long.
12
2
198
This is not 'pedantic'. It's what we've been saying for 2.5 years. Let me add more: It's not well-defined to speak of LLMs as hallucinating or having a specific accuracy on a task. These are properties of *systems* not *models*. (LM+greedy decoding is a system, but a bad one.).
# On the "hallucination problem". I always struggle a bit with I'm asked about the "hallucination problem" in LLMs. Because, in some sense, hallucination is all LLMs do. They are dream machines. We direct their dreams with prompts. The prompts start the dream, and based on the.
14
9
198
New interview where Sam Altman at 24:12 has an inexplicable epiphany:. > Something about the way we currently talk about [AI] & think about it feels wrong. Maybe if I had to describe it, we will shift from talking about models to talking about systems. But that will take a while.
13
20
194
Prompts blur interface (desired behavior) w/ implementation (how to instruct). DSP lets you invoke LLMs by signatures, not prompts, so you focus on system design. It simulates your code to create good fewshot prompts—or "compiles" it into cheap finetunes.
6
29
190
Announcing the MIPRO optimizer for multi-prompt language programs by @kristahopsalong & @michaelryan207. Learn how the MIPRO optimizer crafts instructions & generates few-shot examples for even complex LM chains — and see how to use it to tune the prompts of your DSPy programs⤵️.

Got a pipeline with **multiple prompts**, like a DSPy program? What's the right way to jointly optimize these prompts?. Introducing MIPRO, a Multi-prompt Instruction Proposal Optimizer. We integrated MIPRO into DSPy. It can deliver +11% gains over existing DSPy optimizers!. 🧵👇
2
46
192
There's a recent surge of interest in quicker replication of ColBERTv2 training. To make this easier, I uploaded the examples file (64-way) and initial checkpoint (colbert v1.9) to HF hub. Here's the full code to launch training, after `pip install colbert-ai`. (links below)

8
26
189
ColBERT is known for particularly strong quality, but RAG apps need more than just a good retrieval model. 🪤RAGatouille by @bclavie is the easiest & cleanest way I've seen to use ColBERT in apps—with a great roadmap too. I'll be user #1, and we'll make sure it works w DSPy.
The RAG wave is here to stay, but in practice, it's hard to retrieve the right docs w/ embdings, & better IR models are hard to use!. Let's fix that: Introducing 🪤RAGatouille, a lib to train&use SotA retrieval model, ColBERT, in just a few lines of code!.

2
12
186
Cool nugget: Expert prompt engineer works for 20 hour vs DSPy!. DSPy achieves "much better [F1 score] than the human prompt engineer’s prompts". The prompt engineer then tweaks the DSPy prompt slightly, trading away precision for high recall, which leads to an even higher F1.


The Prompt Report: A Systematic Survey of Prompting Techniques. Presents a comprehensive vocabulary of 33 vocabulary terms, a taxonomy of 58 text-only prompting techniques, and 40 techniques for other modalities.

4
28
188
I'm glad that a lot more people understand the key ideas behind ColBERT and DSPy now. My only remaining goal is to make sure people can also say them correctly; both are quite tricky😆. * Col-BAIR (it's "the late" interaction retriever, get it?).* Dee-Ess-Pie (like num-pie).
18
11
186
Work like o3 suggests that future foundation models will diverge like RISC and CISC architectures. Developers will express their system specifications in extremely high-level programming languages. And compilers will translate those into a few RISC—or many CISC—instructions.
10
24
194
Just watched this crash course into DSPy by @CShorten30!. Connor's style is great. I can only think we should collab on 2-3 followups on using more advanced optimizers to also tune instructions, craft examples w/o labels via AI feedback, and finetune small LMs for hard tasks.

DSPy is a SUPER exciting advancement for AI and building applications with LLMs!🧩🤯. Pioneered by frameworks such as LangChain and LlamaIndex, we can build much more powerful systems by chaining together LLM calls! This means that the output of one call to an LLM is the input to

5
22
183
new hobby: dspy code golf. super short pseudocode with natural language tasks should just work and be optimizable


For reliability, nothing beats DSPy (thanks to @lateinteraction, @michaelryan207, @ChrisGPotts and rest of the team). Below is a "research analyst" I built using DSPy. Succinct and reliable. Future is "inference time composability"


4
19
184
Karel's DSPy code for prompting LMs to do classification with over 10,000 classes is now released!. He's made it exceptionally easy to plug in different LMs, metrics, and prompt optimizer strategies so this can work for any classification task you have. Check out his thread!

Easy few-shot classification with ≥10k classes? The Infer-Retrieve-Rank (IReRa) code is now online at . Optimize an IReRa system on your dataset, configure different student and teacher LMs, use custom retrievers, and pick your optimization logic!.
2
29
181
This is an AMAZING tutorial video on using the latest DSPy optimizers *and* on building advanced DSPy metrics with AI feedback. @CShorten30 improved his RAG program over Weaviate FAQ by 28%, from 2.71/4 to 3.46/4. I'll postpone another announcement to tomorrow; watch *this*⤵️.
Hello world, DSPy! I am SUPER excited to share a new video walking through the end-to-end of how to use DSPy to optimize the CIFAR-10 for LLM programs, RAG with FAQs! 🛠️. This tutorial contains *4 major parts*: (1) library installation, settings, and creating a dataset with

4
35
179
I haven't looked into Devin, but “GPT-4 wrapper” makes as much sense for a design of this complexity as “H100 wrapper” makes sense for GPT-4. At some tradeoff, both can swap out the device (the GPU/LM) for alternatives, without their real power (composition) going anywhere.

given that Devin/Cognition appears to be a GPT-4 wrapper from all accounts, this goes to show how we are barely scratching the surface of what's possible with today's models. even if AGI research plateaus at present levels, massive impacts are yet to come.
7
18
179
Exactly. Folks often ask "ColBERT is great but wouldn't the embeddings take a lot of space?". Nope. ColBERTv2 with PLAID (see QT) can use as little as *20 bytes* per vector. Same size as 5 floats. Can fit 140,000,000 passages in 200GB and search them in 100 milliseconds on CPU.

@TheSeaMouse @cto_junior You can do a lot more than just simple quantization!
2
19
172
Now that DSPy is popular, some nuance. DSPy is *not* a prompting framework. It proposes a new paradigm: a framework for expressing & optimizing Language Programs. Think neural networks but with LM "layers", i.e. abstract modules that *learn* prompts/finetunes given a metric.
4
36
177
I'm really grateful to the many amazing people working to make DSPy better. We just crossed 100 contributors.

The DSPy community is truly remarkable:. Here, @weaviate_io's @CShorten30 is using observability add-ons contributed by @ArizePhoenix's @axiomofjoy to explore new DSPy optimizers implemented by Stanford's @michaelryan207 and @kristahopsalong.
5
12
176
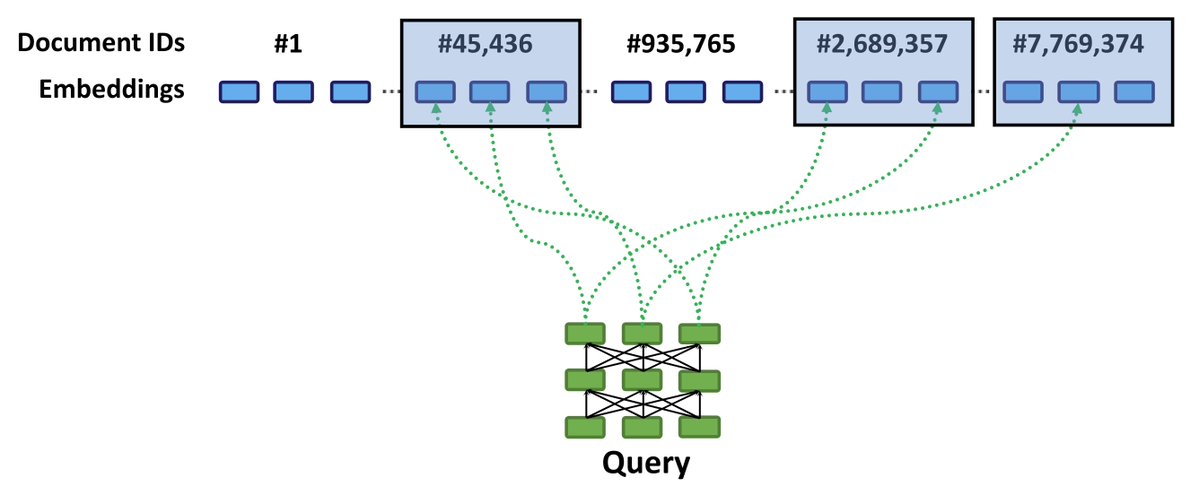
Over the past 4 years, we built a massive stack around ColBERT: a retrieval paradigm that performs robustly on hard queries, adapts easily to hard domains, and searches billions of tokens in milliseconds. Watch closely as ColBERT et al become accessible to application builders⤵️.

🐀Improved RAGatouille <> LangChain Integration. We really enjoyed @bclavie's new RAGatouille library. It makes advanced retrieval techniques (like ColBERT - more on that below) really easy to use. We've worked on a tighter integration to make it *super simple* to use RAGatouille

4
20
166
I’m seeing so many “should I switch from framework X to DSPy?”. Well, we’ve written extensively—mainly CMU composable systems lab’s @Lambda_freak and @HaozeHe_Hector—on the emerging LM stack. Different frameworks tackle fundamentally different concerns.


“I’m taking this from Jason Liu”! via @YouTube.@jxnlco @ConnorShorten So please help me understand how much is DSPy doing what Instructor does, and how much something different??.
3
22
170

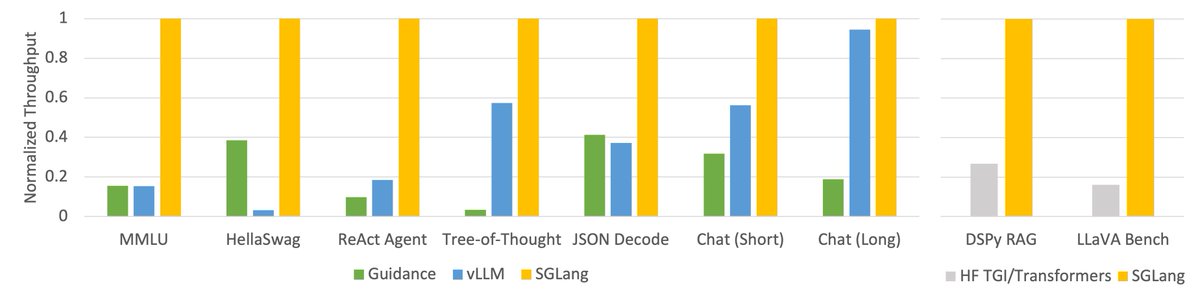
This is big. I'm personally excited about it: Massive speedups for local model inference (throughput) in ways that will affect you today. @lmsysorg already contributed a backend in DSPy. This will make your runs 4-5x faster if you're running DSPy optimizers with local models.


We are thrilled to introduce SGLang, our next-generation interface and runtime for LLM inference! It greatly improves the execution and programming efficiency of complex LLM programs by co-designing the front-end language and back-end runtime. On the backend, we propose
3
26
168
The way NotebookLM generates podcasts under the hood is a modular system quite similar to STORM.



3
36
170
AI agents — please hold while we connect you to the next available GPU. *music plays*.
7
10
169
In my blog on impactful AI research, I talk about selecting high-fanout, large-headroom problems that aren't yet receiving too much attention. For grad students looking for problems this Fall, the whole vision late interaction thing as applied in ColPali is pretty ideal.

there's a new blog on @huggingface on document similarity search that goes through lower level of how things work (primarily MaxSim and how it's calculated) 🥹. at huggingface .co/blog/fsommers 📖

4
19
167
Met some folks who didn't realize that Demonstrate–Search–Predict (DSP) changed drastically in its second iteration, 𝗗𝗦𝗣𝘆. DSPy has a new paper on *compiling* LM programs into automatically optimized chains of prompts or finetunes. Worth a 🧵 soon.
2
25
166
👀 I'm being called out. But I agree. DSPy *will* be so huge pretty soon, @mbusigin. I'm spending winter break revamping docs/examples, and doing much-needed refactoring. The abstraction is incredibly elegant, as many have noted. The DX (developer experience) will soon match.

I think DSPy would be so huge if it had applied any thought to the DX at all.
10
13
164
Lots of requests for richer observability in DSPy. In March, @mikeldking & I are holding a DSPy <> @arizeai meetup in SF to show you how to do that w @ArizePhoenix-DSPy integration. Video by @axiomofjoy. Good chance to show something cool with DSPy. What would you like to see?
5
27
162
People still talk about zero-shot instruction, few-shot prompting, fine-tuning, retrieval augmentation, and complex pipelines thereof like distinct things you have to choose from. But the DSP programming model unifies them all in a powerful abstraction:.
RE: "how often do you see teams actually fine tuning LLMs?".It's an interesting question, about how prompting (optimization over prefix tokens) and finetuning (optimization over weights) will be used over time. If people have data points please pitch in. I expect that finetuning.
3
27
161
The DSPy GitHub gets a little over 200,000 views a month — I don’t know how many of them read the DSPy papers, but I’d like to raise that fraction. Maybe starting with this one:.
4
29
159
👀.
Replit’s new code repair LLM uses DSPy for a few-shot prompt pipeline to synthesize diffs. Pretty cool!

2
16
158
oh no, sorry openai.

OpenAI released a wrapper of GPT-4o and everyone is going bonkers :P.
5
11
162
Traditionally, when you optimize your ML model on one GPU and then shift to a newer (or cheaper) GPU, it just works. You get same accuracy. With LM programs, that’s not true. If you spend a week tuning your pipeline’s. prompts for GPT-3.5, nothing says it’ll work for Mistral-7B.
5
11
159
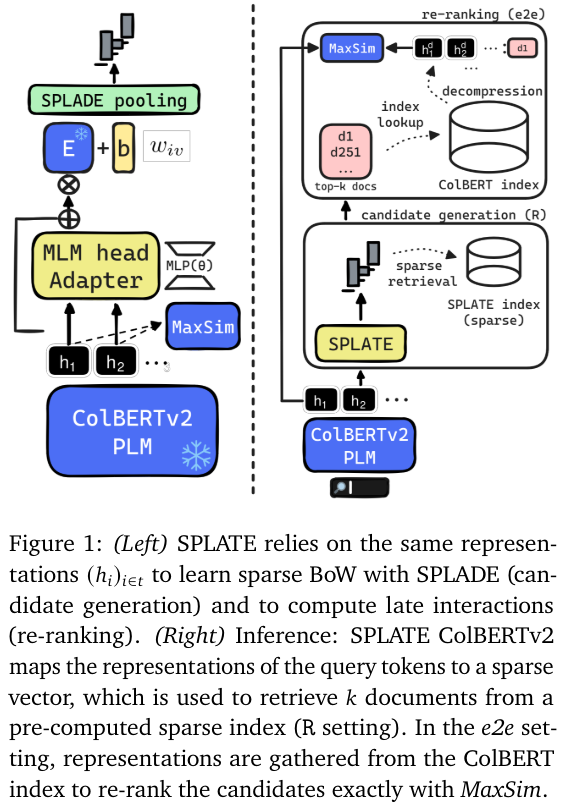
Sparse late interaction retrieval. Fastest ColBERTv2 numbers ever. I think this changes a lot of things, and I’m not surprised it comes from this team. At all.

SPLATE: Sparse Late Interaction Retrieval. Adapts the ColBERTv2 model to map its embeddings to a sparse space, enabling efficient sparse retrieval for candidate generation in the late interaction paradigm. 📝

2
18
157
My vision for DSPy is to become the "PyTorch" for Language Programs. In some ways, our task is much easier: far less infrastructure is needed to work w LMs than GPUs. In other ways, our task is harder: we are creating the paradigm itself (e.g. optimizers) not only abstractions.
Now that DSPy is popular, some nuance. DSPy is *not* a prompting framework. It proposes a new paradigm: a framework for expressing & optimizing Language Programs. Think neural networks but with LM "layers", i.e. abstract modules that *learn* prompts/finetunes given a metric.
4
18
159
Well, we finally have a backronym for DSPy. 𝗗𝗦𝗣𝘆 now stands for 𝗗eclarative 𝗦elf-improving Language 𝗣rograms (in p𝘆thon). What's the impact of this? Nothing. You still `pip install dspy-ai` and work. It's just nice to be able to answer that exceedingly common question.
10
12
157