

Benjamin Clavié
@bclavie
Followers
2,909
Following
828
Media
63
Statuses
764
regressing linearly on a daily basis @answerdotai | cooking some late interaction RAGatouille | 日本語NLPを通じて日本語を学んでいます。
Tokyo/Lyon
Joined April 2016
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Eminem
• 255787 Tweets
Bielsa
• 107823 Tweets
Zamora
• 105040 Tweets
stevie nicks
• 67266 Tweets
STRAY KIDS HEADLINE I-DAYS
• 65841 Tweets
الاهلي
• 62010 Tweets
harry styles
• 61765 Tweets
Brunson
• 50207 Tweets
Vance
• 49569 Tweets
Célya
• 46782 Tweets
Alec Baldwin
• 31396 Tweets
#JOCHUMテレビアニメ
• 28796 Tweets
日曜劇場
• 24181 Tweets
#GalaAlwaysWithYouMauro
• 23899 Tweets
Ranger
• 11573 Tweets
ALL RISE
• 10935 Tweets
Susan Collins
• 10115 Tweets




















Pinned Tweet

The RAG wave is here to stay, but in practice, it's hard to retrieve the right docs w/ embdings, & better IR models are hard to use!
Let's fix that: Introducing 🪤RAGatouille, a lib to train&use SotA retrieval model, ColBERT, in just a few lines of code!

22
121
807
Document reranking is powerful, but daunting to get started with.
Moreover, trying a new approach requires modifying your pipeline, even though it does the same thing!
Introducing 🔧rerankers: a lightweight library to provide a unified way to use various reranking methods🧵1/?

18
62
426
"Just use a reranker for better retrieval"
...
Yes, but which one?
Someone asked me recently what reranker they should use (with no data to fine-tune it), and I realised just how loaded that question actually was, so I made this (mostly English) "cheatsheet"

18
55
409
🥁🥁 New blog post out (link in thread), w/ two aims:
🤓 Providing a clear, hopefully easy-to-read intro to ColBERT, without assuming you've ever used it.
🏊Introducing ColBERT Token Pooling ✨: You can reduce the size of ColBERT indexes by 66% with barely any performance hit!

7
66
360
"I wish I could use the best retrieval model as a reranker in my RAG pipeline, but I don't have time to redesign it!"
We've all been there and thought that, right?
🪤RAGatouille now lets you do it effortlessly! Retrieve docs as usual&let ColBERT rerank them in a single line⬇️

16
22
219
This was a really fun(/daunting) exercise!
If you’ve ever wanted to hear me talk about rerankers, BM25, metadata and sneak in as many
@lateinteraction
/ColBERT shoutouts as humanly possible, this is the talk for you

This talk by
@bclavie
is the highest value per second talk I have ever watched on RAG
Chapter summaries and additional links in next tweet
15
145
1K
2
13
163
ColBERT's optimised indexes are great, but not for every situation:
What if you want to use it as memory for a single conversation (high CRUD)?
Or even just try it out on a few docs?
✅Not a problem anymore! `encode()` is all you need to treat yourself to late interactions ☺️

3
17
138
After a few more evals and writing, the proper announcement: I'm releasing JaColBERT, a ColBERT-based model for 🇯🇵 Document Retrieval/RAG, trained exclusively on 🇯🇵 Data, and reaching very strong performance! (Report: , arXiv soon!)

3
22
130
🧔♂️(?) ColBERT🤝🪤RAGatouille🤝🛵
@vespaengine
🤝🤗
@huggingface
Wondering how you can use a ColBERT model to support large-scale search?
Now in RAGatouille: push a ColBERT model to the 🤗 hub & export any ColBERT (local or remote) to VespaColBERT, plug&play with
@vespaengine
!

9
13
119
🇯🇵JaColBERTv2 is out 🎉🎉
It's an extension of JaColBERTv1 using distillation - with
@lateinteraction
's MSMarco scores applied to MMARCO-🇯🇵
JaColBERTv2 tops
@hotchpotch
's JQaRa, doing 5.6% better than the best single-vector model & outperforming models w/ 5x the param count!

3
30
117
And now for personal news: Very happy to announce that I'll be joining in March 🎉
I've spent a lot of time thinking about what's next & how we should build it, and there couldn't be a better place to do it!
17
8
111
RAGatouille release: Community Edition 😎
2 awesome contribs:
🔧
@anmolsj
removing forced multiprocess on indexing, fixing lots of compatibility issues
📄
@ani_dharmarajan
w/ metadata support: assign metadata to docs, keep them consistent across chunks, & retrieve at query-time!

3
14
103
Woah, Colbertv2 has broken into the top 100 most downloaded models on
@huggingface
now.
@lateinteraction
has gone mainstream!

2
16
104
@DynamicWebPaige
The natural progression for anyone doing Python is to use Flask, hear about FastAPI, be sceptical, try it out then go door to door to find out whether or not our neighbours have heard about our lord and saviour FastAPI
2
11
91
🆕 RAGatouille v0.8.0 is out 🪤
- Lots of bug fixes
- Big internal overhaul of how indexing works courtesy of
@jlscheerer
- A new experimental approach to building indexes
This last one fixes nearly half the issues people have reported when trying to use ColBERT+PLAID 🧵

1
12
89
Saw
@JinaAI_
's excellent long context (8192!) ColBERT earlier today? Eager to give long-document ColBERT a shot?
New joint🫅colbert-ai and🪤RAGatouille release now supports any maximum length the underlying model can handle (& dynamically adjusts maxlen when encoding in-memory)

3
17
85
💯
I built RAGatouille because I just didn’t want to wait forever for more convenient ColBERT APIs.
The next step is logical: can’t wait for someone to build ColBERT-as-service!
(if you do it you get to have the final word on whether it’s pronounced Col-BERT or Col-BAIR)

The low-hanging fruits for wrappers, interfaces, startups atop ColBERT & DSPy are so prominent that I get asked daily.
Seems this blocks people who could build cool stuff? So here: I’m not gonna build higher-level tools, I’m here for infra. Go build your ColBERT or DSPy startups
5
7
77
5
7
79
The Encoder(-Decoder) lobby claims a long-awaited comeback with this release.
(credit goes to
@slippylolo
for this masterpiece and
@antoine_chaffin
for reminding me of its existence)


Meet Reka Core, our best and most capable multimodal language model yet. 🔮
It’s been a busy few months training this model and we are glad to finally ship it! 💪
Core has a lot of capabilities, and one of them is understanding video --- let’s see what Core thinks of the 3 body
53
240
1K
1
9
72
Yes we've had ColBERT, and image ColBERT, and OCR + ColBERT, but how about vision-only document representation ColBERT? Do they know about vision-only document representation ColBERT?

🚨 Introducing "ColPali: Efficient Document Retrieval with Vision Language Models" !
We use Vision LLMs + late interaction to improve document retrieval (RAG, search engines, etc.), solely using the image representation of document pages !
🧵(1/N)
13
67
306
0
7
66
RAG is a misunderstood term: it’s not a unified system, it’s Retrieval then Generation.
“My RAG isn’t working” is a vibe, user-felt thing.
It’s akin to “my car isn’t working”: this is how the user sees it, but you’d be pretty annoyed if that was what your mechanic said to you.
@jeffreyhuber
@HamelHusain
So when people try to figure out why their "RAG" is broken, it's a harmful level of abstraction to diagnosis -- what actually is broken? The retrieval pipeline? The LLM generation step? Or the way the information is passed to the LLM (i.e. it doesn't manage to make use of it)?
3
1
10
5
6
64

.
@jobergum
deserves a lot of appreciation for the work he's done and continues to do. While he *does* enjoy the occasional troll post and can adopt an abrasive tone on some topics, he's also immensely knowledgeable and pretty kind.
Plus, he's the best kind of knowledgeable

Actually, I engage positively with founders and engineers across the vector database spectrum. Like
@bobvanluijt
,
@atroyn
or
@frankzliu
. I would call it mutual respect and recognition.
Friendly people with great teams. They don’t write bullshit, or claim this or that.
There
7
4
83
5
8
65
Woah, what a reception🤗! I didn't expect RAGatouille to get so much attention! I'll be a bit slow at replying:I came down w/ a fever yesterday
Thanks for the kind messages & feedback!
Looking forward to continue building to bridge the gap between IR and applications, lots to do!
5
1
47
And it has now landed at your nearest PyPi!
rerankers 0.3, notable changes:
- Now supports metadata through a Document object (s/o to
@anmolsj
for starting this)
- RankLLM support (sorry for the delay,
@rpradeep42
)! RankLLM + GPT is tested, but not Rank{Zephyr, Vicuna}


2
3
47
GLiNER is amazing — reliable zero shot entity detection (on par with the best LLMs) that won’t even make your CPU sweat.
Great work by
@urchadeDS
, and definitely worth checking out

0
0
11
3
2
46
I missed this, another great short illustration of how (non-finetuned!) ColBERT's representation method helps it capture semantic relationships.
Here, the Veganism == Diet == Chicken McSpicy relationship is missed by the dense embedder, but caught by ColBERT⤵️

Ok, ColBERT passes this test but how does it compare to a simple single vector based retriever (vanilla retriever)? I did another test. 👇
1
1
10
0
6
42
What a fantastic paper ❤️

BERTs are not dead!🧟 But just misunderstood and overshadowed by their GPT siblings. In this paper, we travel back into 2020 and speculate on an alternative history where DeBERTa is the first model to show in-context learning abilities.
Paper:
1/6

17
96
569
4
2
44
@marktenenholtz
We’re planning on doing something about it! Figuring out the logistics but will be doing this in the open quite soon
@Dorialexander
@antoine_chaffin
@ncooper57
@GriffinAdams92
Shall we get it going ourselves then? There’s no limit to what spite can allow a group of strongly opinionated people to achieve
5
1
10
3
3
44
Definitely one of the most pleasant endorsements possible, thanks
@jeremyphoward
😊
Very happy to be joining soon, check this post out for my reasoning if you haven't yet!
3
2
42
This is my first
@answerdotai
blog post/release and I'm very excited about it! You can find it at
It's full of everything you'd want from a blog post! It has a conclusion at the start, a really long introduction to ColBERT, then ends on a cool new thing!

2
4
42
`pip install "rerankers[all]"` to jump in.
The README contains pretty much all you need to get started, and you can find the repo here:

1
1
40
The roadmap isn't quite cleaned up, but by popular demand: opening a 🪤 RAGatouille Discord.
Join us to talk features, bug reports, or simply discuss late interaction & integrations (DSPy 👀)! (link below)
3
4
37
This is ever-relevant in the current embeddings evaluation landscape


@andriy_mulyar
@abacaj
It has been shown in various studies that embedding models can perform strong in domain, but have a hard time out-of-domain. Eg in the BEIR paper, DPR was trained on Wikipedia retrieval and is strong there. But on any other dataset it is worse than lexical search.
I also did a
2
15
76
2
6
38
And I forgot to mention in this tweet: it's already available in the ColBERT repository, and will come to RAGatouille (along with a set of bug fixes!) in the next few days 👀
It's dead simple to use: just add a single extra config parameter!

🥁🥁 New blog post out (link in thread), w/ two aims:
🤓 Providing a clear, hopefully easy-to-read intro to ColBERT, without assuming you've ever used it.
🏊Introducing ColBERT Token Pooling ✨: You can reduce the size of ColBERT indexes by 66% with barely any performance hit!
7
66
360
0
4
37
DSPy x LangChain 😍
This is pretty big! If you haven't taken a look at DSPy yet, this might be the moment.
LLMs are complex beasts and no amount of prompt engineering will get you the results a compiler like DSPy will!
The LM dev stack will soon evolve dramatically.
To start,
@hwchase17
& I tackle interoperability: Now LangChain users can compile LCEL chains with DSPy optimizers⚡️
To illustrate, we compile LCEL for a long-form RAG app, delivering 10-20% higher output quality.
Let's dive in⤵️

12
50
274
1
3
33
There's a new exciting reranking API from
@Voyage_AI_
!
It's already supported in `rerankers` v0.1.2, try it out in your pipelines!
`pip install --upgrade rerankers`


Rerankers refine the retrieval in RAG.
🆕📢 Excited to announce our first reranker, rerank-lite-1: state-of-the-art in retrieval accuracy on 27 datasets across domains (law, finance, tech, long docs, etc.), enhancing various search methods, vector-based or lexical. 🧵

4
10
60
0
4
33
So glad RAGatouille is unleashing the potential of
@lateinteraction
’s ColBERT!
Try your own needle-in-a-haystack in seconds in
@LangChainAI
thanks to
@hwchase17
’s integration!
More to come soon, stay tuned 👀
Just did a simple 'needle in the haystack' test with this and it's been pretty impressive! I hid a little random sentence within Paul Graham's essay and tested if it can effectively retrieve it. (continued below)
4
10
66
2
5
31
Shameless 🪤RAGatouille GPU-poor message: if anyone's got some spare cloud GPU compute, please do reach out, trying to think of ways to fully reduce friction in trying out ColBERT!
4
2
29
I'm deciding to claim this one as a moral victory 🤩

Love how RAGatouille makes it so easy to train new ColBERTs.
ColBERT's real power is you can train it with as little as a few hundred queries. Other dense retrievers need tens of thousands!
Maybe the test for
@bclavie
's library is whether we see an uptick in ColBERT downloads😆

7
16
158
3
2
28
I can hardly think of a more deserved appointment. This might actually make me break my I-won’t-visit-Boston rule
I'm excited to share that I will be joining MIT EECS as an assistant professor in Fall 2025!
I'll be recruiting PhD students from the December 2024 application pool. Indicate interest if you'd like to work with me on NLP, IR, or ML Systems! Stay tuned for more about my new lab.
250
95
2K
3
1
29
Hamel knows how to be very convincing...
I'll be ranting about keyword matching, reranking documents, ColBERT, fine-tuning your embeddings and many other things!
(P.S I absolutely do not look like that anymore, that picture is four years old)
/14
@bclavie
is one of the leading thinkers about RAG, and has created RAGatouille, a framework that optimizes retrieval for RAG.
He'll be talking about optimizing RAG

1
1
23
4
4
29
Very fun intersection of both my worlds!
@KarelDoostrlnck
showing that optimisation via
@lateinteraction
(&al)’s DSPy can do XMLC tasks with >13k labels even better than trained retrievers+rerankers!
Great paper, easy to implement, and very applicable to real world use cases!

📢Tasks with > 10k classes (e.g. information extraction) are hard for in-context learning: typically a tuned retriever or many in-context calls per input are used ($$$)
Infer-Retrieve-Rank (IReRa) is a SotA program using 1 frozen retriever with a query predictor and reranker.
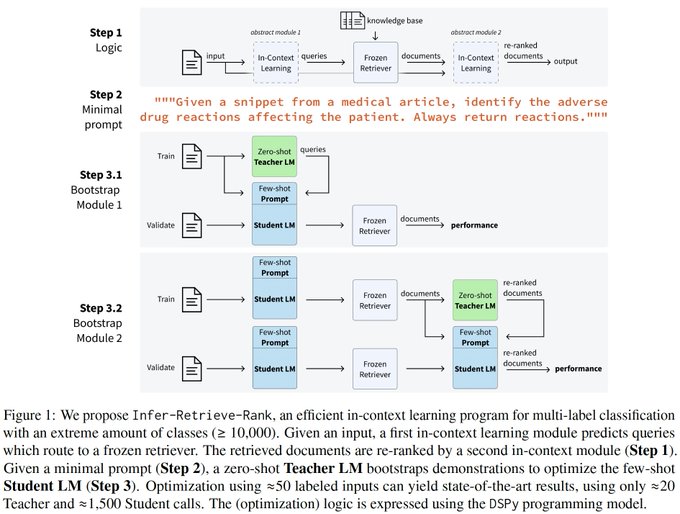
8
82
523
1
7
28
Woah, ColBERTv2 has made it to the top 300(? I think!) models on Huggingface🤯Exciting times for late interaction models and
@lateinteraction
researchers

0
4
28
RAGPretrainedModel and RAGTrainer are the two key classes. In the example above, it handles you need to load a model, embed and query documents.
Do you need to train or fine-tune a model? It's not any harder, let RAGTrainer do the heavy lifting! (more on this in the thread)

1
1
26
@jobergum
Fwiw I think this is good and the right choice for their users. BM25 is tricky to get right and robust, tantavy is a great lib with few dependencies and it saves them time on reinventing the wheel (esp since lance has never claimed to not rely on external deps)
0
0
26
Neural-Cherche is a really cool, lightweight way to explore a slightly different flavour of ColBERT & other cool retrieval models (SparseEmbed!).
@raphaelsrty
's work is pretty cool in general, check it out!

Neural-Cherche 1.1.0 is out 🥳
ColBERT is available as a retriever and as a ranker.
New pre-trained checkpoint @ "raphaelsty/neural-cherche-colbert" built from "all-mpnet-base-v2".
Good default parameters and improved loss function for all models.
5
15
81
1
1
25
Vik’s work on OSS document parsing is really cool much needed.
He’s joining us at
@answerdotai
(😊) and sharing his thoughts on his journey so far in this nice post

I wrote a blog post on going from not knowing anything about deep learning last year to training state of the art OSS models - .
Hope it helps you.
tldr; read the deep learning book, implemented papers + taught, built open source tools
27
158
1K
3
1
24
New open source ColBERT model! So nice to see the model family grow 😁

ColBERTus Maxiums - Introducing mxbai-colbert-large-v1
This is something for the ColBERT fans! We took our SOTA embedding model and colbertialized it. Learn more:
Model:
Blog:
5
20
121
2
3
23
@vboykis
When you join ML twitter you have a starter quest where you pick a side between the Alliance of Overly Heated Debates (which doesn't have a leader for obvious reasons) or the Federation of Data Shitposting led by
@vboykis
and
@chrisalbon
. No going back once your call is made.
2
0
23
Interested in a few course videos giving an overview of IR methods, how ColBERT works and what led to it in the long lineage of retrieval methods? Look no further! ⬇️
@420_gunna
@bclavie
I have IR course material on youtube, 5 videos starting with this one, from stanford CS224U Spring 2021. The material covers things from BM25 to ColBERT.
2
4
30
1
1
21
I hear
@mixedbreadai
🥖 has another pretty cool open source release ready to come out of the oven.
If you like open source retrieval models it could be worthwhile to have them on your radar 👀 they’re even
@jobergum
-approved!
1
1
21
@jobergum
@qdrant_engine
I'm still of two minds about the findings. I want to believe because the idea doesn't sound horribly flawed (it's a very simplified SPLADE in a way), but Precision
@10
on Quora is probably just about the worst metric I could think of if I wanted to demonstrate something new,
3
1
21
Avoid it, hide from it, run away from it, but the universal truth that Markup Languages are all you need™️ will catch up with you eventually
At first when I saw xml for Claude I was like "WTF Why XML". Now I LOVE xml so much, can't prompt without it.
Never going back
31
19
378
2
0
19
@marktenenholtz
@lateinteraction
I actually have a checkpoint here trained off MiniLMv2 on MS-Marco! I just haven't gotten around to running evals and making sure everything looks good, but "the loss seemed fine" ™️
4
2
19
Check this out, Raphael’s work is really under appreciated for how cool it is
Introducing LeNLP, a natural language processing toolbox written in Rust for Python.
LeNLP is ⚡️
LeNLP vs Sklearn TfIdfVectorizer:

3
18
90
2
0
18
I think ML is now infrastructure, and I've ended up writing down a lot of the thoughts I've been having recently around this topic (and how great a match this feels like!) on my inaugural blog post, feel free to check it out:
1
0
18
This is a fantastic benchmark — highly recommend checking it out!
Real world users often have ways of burying the lede as an innocuous tiny comment tacked on to their query, and that’s usually a very hard thing to benchmark against 🥲


0
2
18
I'm also more than happy for 🪤RAGatouille to be a home for the fully OSS wrappers!
We've got some help wanted issues: and DSPy support is deffo the next big milestone 👀
(If you're making a commercial wrapper, feel free to just bundle RAGatouille too😁)

💯
I built RAGatouille because I just didn’t want to wait forever for more convenient ColBERT APIs.
The next step is logical: can’t wait for someone to build ColBERT-as-service!
(if you do it you get to have the final word on whether it’s pronounced Col-BERT or Col-BAIR)
5
7
79
1
3
16
Spending a couple weeks working with
@devstein64
& team at
@dosu_ai
on code retrieval, so I thought I'd give them a shoutout!
Dosu basically does what I've been doing since RAGatouille came out: scour GitHub issues and desperately try to figure out what's causing them. Link
2
1
17
This is massive news! BEIR-2024 🤩

World-class search needs world-class metrics 🚀
And great metrics need to be constantly evolved to avoid overfitting 🤟
As we build out a great search experience at
@SnowflakeDB
AI research, we are excited to join forces with
@lintool
and the University of Waterloo 🙌
Our
9
16
106
0
1
16
Finally updated the 🇯🇵JaColBERT readme so it now highlights how to use it with RAGatouille, which is the way I've been using (&fine-tuning it 👀) myself!
Check it out if you've been meaning to try it (link below), the out-of-domain results are strong 💪 (~= in-domain mE5-large)
1
3
16
Immense thanks to
@LightOnIO
's
@antoine_chaffin
and our own
@GriffinAdams92
and
@ncooper57
for very useful exchanges -- and
@antoine_chaffin
again for help with implementation! (and shoutout to
@lateinteraction
for reading over this prior to release too!)
1
0
16
Exciting few days in the late interaction multiverse! ColBERT-XM from
@antoinelouis_
& friends use XMOD as a ColBERT backbone for multilingual retrieval and show it not only performs very well, but considerably outperforms similarly initialised dense retrievers!

Need a dense multi-vector retrieval model in your language? We've got you covered with ColBERT-XM, a new modular retriever that supports 81+ languages and can easily be extended to many more. [1/4]
📑 Paper:
🤗 Model:
5
47
203
0
2
14
A very active late interaction kitchen is setting up…


1
1
16
Super excited to get to work with Nathan! Chatting with him had already taught me a lot about one of the most wonderful things known to man (bidirectional attention)

Big life update! I'm super excited to announce I have joined the awesome crew at
@answerdotai
🤓
10
4
84
0
0
15
Well this was really fun! Not sure I made a lot of sense in my current fevery state, but
@altryne
and
@CShorten30
made up for it ☺️

2
3
14
This is the HN post for RAGatouille, with some more details there, feel free to check it out! ⬇️
0
1
14

Want to try it out yourself? It's already merged upstream!
And I forgot to mention in this tweet: it's already available in the ColBERT repository, and will come to RAGatouille (along with a set of bug fixes!) in the next few days 👀
It's dead simple to use: just add a single extra config parameter!
0
4
37
0
3
14
Don’t trust big causal, demand the best, demand bidirectionality

0
2
14
And now for a quick Friday mini-release: rerankers v0.2.0!
⚡Added support for FlashRank rerankers to leverage
@prithivida
's excellent work!
🥖Added mixedbread API
🔁
@TarunAmasa
's contribution adds a basic `rank_async()` method (
@jxnlco
👀)
`pip install --upgrade rerankers`
2
0
14
RAGatouille's heavily based on
@lateinteraction
's excellent work on ColBERT, and I also thank him for being really helpful during development!
You can find more information on why you should use ColBERT (and RAGatouille!) on the GitHub repo and the docs welcome page at
2
2
13
some days are harder than others when you're the French person at
@answerdotai

Wow just now I tried GPT-4o for a creative task for the 1st time, and it was *terrible*! 😧
I asked GPT-4, Claude, and GPT-4o for a French-themed name (like a person's name) for an OpenAI model library. Results L-to-R in that order:



33
10
170
1
0
13
@jobergum
UDAPDR is definitely the way to build the most powerful single-model retrieval method at the right now (&can't wait the wonders you could do with it in Vespa).
It's a bit unwieldy and went under the radar, but it's definitely going to have its time in the spotlight!
0
2
13

@Dorialexander
I've been constantly ranting about this (sorry
@antoine_chaffin
@ncooper57
@GriffinAdams92
). All we need is BERT-2024-0.5b, ColBERTv3 (👀) and deberta-v4
1
1
11
Hamel was kind enough to share an early draft of this, & I think he makes a really important point here.
There's enormous value in abstractions, but it's dangerous when finding out what's going on is hard.
(but I'm still bullish on DSPy, the DX will keep improving!)
New blog post 📰: Understanding what LLM frameworks are doing is difficult (digging through code, docs, etc).
I show how intercept API calls with
@mitmproxy
to quickly understand how popular frameworks work and find interesting results.
I walk through examples with Guardrails,
20
67
490
0
0
12
As the name indicates, JaColBERT is based on
@lateinteraction
's ColBERT architecture. It's not fully ColBERTv2 (2way training, no distillation...) but not quite ColBERTv1 either, as it makes use of quite a few tricks introduced to the codebase by V2.
1
0
12
@hotchpotch
What a coincidental timing, I've been working on getting JaColBERTv2 up! Results are looking promising (this is the same size as JaColBERTv1), I think this gets the top score on every metric 🎉 (, the weights might still get updated but it's functional!)

1
0
11
@zehavoc
PLAID is the geekier add-on () which greatly explains how (V2 specifically) is so computationally efficient. In terms of a lighter read, check out this recent thread by ColBERT's author
@lateinteraction
2/2
Progress on dense retrievers is saturating.
The best retrievers in 2024 will apply new forms of late interaction, i.e. scalable attention-like scoring for multi-vector embeddings.
A🧵on late interaction, how it works efficiently, and why/where it's been shown to improve quality

25
121
643
1
1
11
Jeremy’s put a lot of the issues with the California SB 1407 bill into excellent, well explained words with this article.
I’m by no means anti regulation, but there are glaring issues with the bill as it exists, and the consequences could be massive
I've done a deep dive into SB 1047 over the last few weeks, and here's what you need to know:
*Nobody* should be supporting this bill in its current state. It will *not* actually cover the largest models, nor will it actually protect open source.
But it can be easily fixed!🧵
10
104
497
0
0
11
If you need a ColBERT for French, check out
@antoinelouis_
’s JeanBaptisteColBERT (it’s what it’s called in my heart)
@EYangTW
@macavaney
@lateinteraction
@bclavie
@acc_doom
@neuclir
Amazing! And for people looking for a checkpoint specifically for French, you can checkout the model I trained a few weeks back on mMARCO-fr starting from CamemBERT:
I was surprised to see it outperforms all the single vector representation models I
3
3
24
0
1
11
If you're not a fan of fully magical abstractions, you can find more info in the examples on what actually goes on, and I'II be posting more docs in the coming days!
Everything is actually handled by fully-fledged components, which you can use on their own (or write your own!)
1
0
10
@simonw
@marktenenholtz
@jobergum
This is really cool, thanks for checking out RAGatouille too!
It’s very early stages and the README is due an overhaul — you might like the encode()/search_encoded_docs() combo to try it out without an index too
3
0
11
There are many components, sometimes built on other people's excellent work: documents are automatically chunked to either your existing model's context size, or your specified max size by using
@llama_index
's SentenceSplitter, but nothing stops you from using something else

1
0
10
The highest form of endorsement is releasing something entirely unrelated to XGBoost and
@marktenenholtz
liking it (maybe
@tunguz
next?)
@lateinteraction
’s work is amazing, very happy to be helping people use it

I’ve been preaching this for a while now but only recently has ColBERT become so easy to use. Check out this awesome project
(Thanks
@lateinteraction
@bclavie
!)
2
18
196
4
0
10
@jeffreyhuber
@HamelHusain
So when people try to figure out why their "RAG" is broken, it's a harmful level of abstraction to diagnosis -- what actually is broken? The retrieval pipeline? The LLM generation step? Or the way the information is passed to the LLM (i.e. it doesn't manage to make use of it)?
3
1
10
A big shout-out and thank you to the people who actually build these amazing models, and who make both their implementation (re-used in rerankers within their licenses) and weights available!
This lib's just an interface, built on other people's fantastic work:
-
@lintool
and
1
1
10
Finally, some thanks are in order: thanks to
@jobergum
's relentless advocacy for hybrid retrieval (RAGatouille-trained models can be slotted into Vespa!),
@jeremyphoward
because has been a huge influence on how I write ML code, and
@jxnlco
(though I know
5
2
10
But the goal of RAGatouille was always to democratise the use of ColBERT model, and the average user has a fairly small document collection, which likely doesn't need the kind of overoptimised engineering faiss provides at the cost of user-friendliness.
So v0.0.8 ships with a
0
0
8
@Dorialexander
@antoine_chaffin
@ncooper57
@GriffinAdams92
Shall we get it going ourselves then? There’s no limit to what spite can allow a group of strongly opinionated people to achieve
5
1
10